Преобразование запятых в десятичные разделители в точки в Dataframe
Я импортирую файл CSV, как показано ниже, используя pandas.read_csv :
Пример файла CSV:
Проблема в том, что когда я позже в своем коде пытаюсь использовать эти значения, я получаю эту ошибку: TypeError: can’t multiply sequence by non-int of type ‘float’
Ошибка в том, что число, которое я пытаюсь использовать, написано не с точкой ( . ) в качестве десятичного разделителя, а с запятой ( , ) . После ручной замены запятых на точки моя программа работает.
Я не могу изменить формат ввода и, следовательно, должен заменить запятые в моем DataFrame, чтобы мой код работал, и я хочу, чтобы python делал это без необходимости делать это вручную. У Вас есть какие-то предложения?
3 ответа
pandas.read_csv имеет параметр decimal для этого: doc
То есть попробуйте с:
Я отвечаю на вопрос о том, как заменить десятичную comma на десятичную dot с помощью Python Pandas.
Где мы указываем чтение в десятичном разделителе в виде запятой, а выходной разделитель указывается в виде точки. Так
Где вы видите, что разделитель изменился на точку.
Я думаю, что упомянутый ранее ответ о включении decimal=»,» в панды read_csv является предпочтительным вариантом.
Однако я обнаружил, что это несовместимо с механизмом синтаксического анализа Python. например при использовании skiprow= read_csv прибегнет к этому движку, и поэтому вы не можете использовать skiprow= и decimal= в одном и том же операторе read_csv, насколько мне известно. Кроме того, я не смог заставить оператор decimal= работать (возможно, из-за меня)
Долгий путь, который я использовал для достижения того же результата, — это списки, .replace и .astype . Основным недостатком этого метода является то, что он должен выполняться по одному столбцу за раз:
Теперь столбец А будет иметь ячейки с плавающей точкой. Столбец b все еще содержит строки.
Обратите внимание, что .replace , используемый здесь, это не pandas, а встроенная версия Python. Версия Pandas требует, чтобы строка была точным соответствием или регулярным выражением.
Convert commas decimal separators to dots within a Dataframe
I am importing a CSV file like the one below, using pandas.read_csv :
Example of CSV file:
The problem is that when I later on in my code try to use these values I get this error: TypeError: can’t multiply sequence by non-int of type ‘float’
The error is because the number I’m trying to use is not written with a dot ( . ) as a decimal separator but a comma( , ). After manually changing the commas to a dots my program works.
I can’t change the format of my input, and thus have to replace the commas in my DataFrame in order for my code to work, and I want python to do this without the need of doing it manually. Do you have any suggestions?
5 Answers 5
pandas.read_csv has a decimal parameter for this.
![]()
![]()
I think the earlier mentioned answer of including decimal=»,» in pandas read_csv is the preferred option.
However, I found it is incompatible with the Python parsing engine. e.g. when using skiprow= , read_csv will fall back to this engine and thus you can’t use skiprow= and decimal= in the same read_csv statement as far as I know. Also, I haven’t been able to actually get the decimal= statement to work (probably due to me though)
The long way round I used to achieving the same result is with list comprehensions, .replace and .astype . The major downside to this method is that it needs to be done one column at a time:
Now, column a will have float type cells. Column b still contains strings.
Note that the .replace used here is not pandas’ but rather Python’s built-in version. Pandas’ version requires the string to be an exact match or a regex.
How to Convert Decimal Comma to Decimal Point in Pandas DataFrame
In this quick tutorial, we’re going to convert decimal comma to decimal point in Pandas DataFrame and vice versa. It will also show how to remove decimals from strings in Pandas columns.
Different people in the world are using different decimal separator like:
- decimal point — more often
- decimal comma — in the Francophone area
Setup
Let’s work with the following DataFrame:
We have two columns with float data:
- decimal comma
- decimal point
1: read_csv — decimal point vs comma
Let’s start with the optimal solution — convert decimal comma to decimal point while reading CSV file in Pandas.
Method read_csv() has parameter three parameters that can help:
- decimal — the decimal sign used in the CSV file
- delimiter — separator for the CSV file (tab, semi-colon etc)
- thousands — what is the symbol for thousands — if any
To use them we can do:
This will ensure that the correct decimal symbol is used for the DataFrame.
2: Convert comma to point
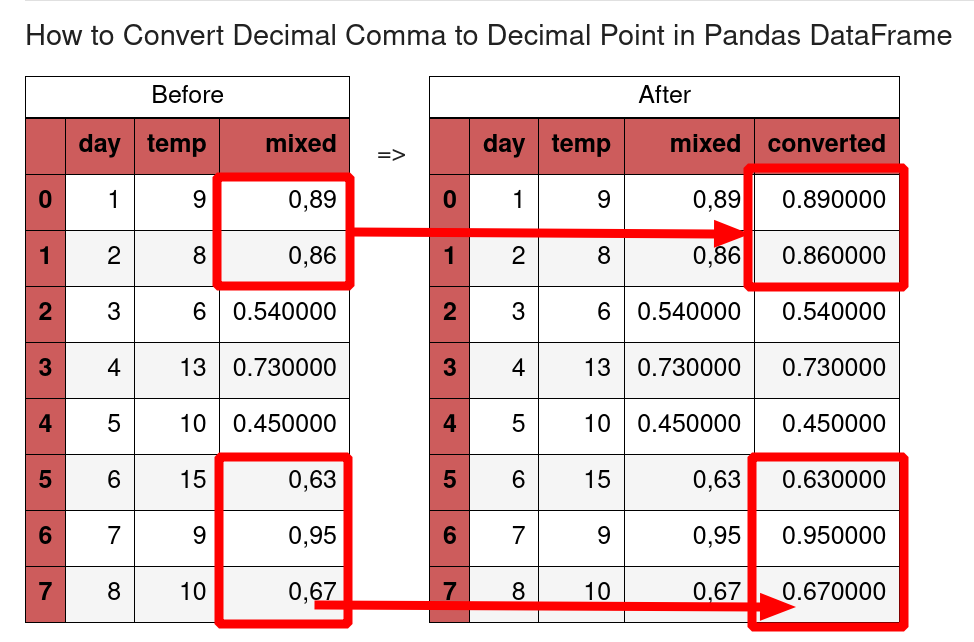
If the DataFrame contains values with comma then we can convert them by .str.replace() :
3: Mixed decimal data — point and comma
What can we do in case of mixed data in a given column? For this example we can use: list comprehensions and pd.to_numeric() .
This can help us to identify the problematic values and keep the rest the same.
For example we can do:
to replace the comma in all string records:
Then we can convert the Series by:
4: Detect decimal comma in mixed column
To detect which are the problematic values we can use:
the result of to_numeric is:
while the final result is showing all values with decimal comma:
5: to_csv — decimal point vs comma
Finally if we like to write CSV file by method to_csv we can use parameters:
- decimal
- sep
to control the decimal symbol.
To convert CSV values from decimal comma to decimal point with Python and Pandas we can do :
ValueError: could not convert string to float: ‘0,89’
The error: "ValueError: could not convert string to float: ‘0,89’" is raised when we try to parse decimal comma to float.
The error is given by method s.astype(float) :
ValueError: Unable to parse string "0,89" at position 0
The error is the result of the pd.to_numeric(s) method — when a decimal comma is present in the input values.
Conclusion
In this article we saw how to replace, change and convert decimal symbols in Pandas. We saw how to detect problematic values in mixed columns — which have decimal commas and points simultaneously.
Typical errors were explained.
For further reference you can check also:
By using DataScientYst — Data Science Simplified, you agree to our Cookie Policy.
Преобразование запятых в точки в Dataframe
Проблема в том, что когда я позже в моем коде попытаюсь использовать эти значения, я получаю эту ошибку: TypeError: не может умножить последовательность на non-int типа ‘float’.
Я получаю эту ошибку, потому что число, которое я пытаюсь использовать, не написано с точкой (.) как разделитель десятичной дроби, а запятой (,). После ручной смены запятых на точки, которые выполняет моя программа.
Я не могу изменить формат ввода и, следовательно, должен заменить запятые в моем DataFrame, чтобы мой код работал, и я хочу, чтобы python сделал это без необходимости делать это вручную. У вас есть предложения?
3 ответа
pandas.read_csv имеет параметр decimal для этого: doc
Я думаю, что ранее упомянутый ответ включения decimal=»,» в pandas read_csv является предпочтительным вариантом.
Однако я обнаружил, что он несовместим с механизмом синтаксического анализа Python. например при использовании skiprow= read_csv вернется к этому движку, и поэтому вы не можете использовать skiprow= и decimal= в том же самом read_csv, насколько я знаю. Кроме того, мне не удалось заставить оператор decimal= работать (возможно, из-за меня)
Длинный путь, который я использовал для достижения такого же результата, — это списки, .replace и .astype . Основной недостаток этого метода заключается в том, что он должен выполняться по одному столбцу за раз:
Теперь столбец a будет иметь ячейки типа float. Столбец b все еще содержит строки.
Обратите внимание, что используемый здесь .replace не pandas ‘, а встроенная версия Python. pandas ‘требует, чтобы строка была точным совпадением или регулярным выражением.