Возможные причины проблем с поиском слов в PDF и как их устранить
PDF-файлы очень удобны для чтения и обмена информацией. Они могут содержать множество элементов, включая текст, изображения, графики и многое другое. Однако, при использовании PDF-файлов вы можете столкнуться с проблемой поиска текста в файле. В этой статье мы рассмотрим возможные причины проблем с поиском слов в PDF и предложим способы их устранения.
Причина №1: Несоответствие языка системы и языка текста
Один из наиболее распространенных факторов, которые могут привести к проблемам с поиском слов в PDF-файле, — это несоответствие языка системы и языка текста в файле. Если системный язык отличается от языка текста в PDF, поиск текста может не работать должным образом.
Устранение: Измените язык системы на язык, на котором написан текст PDF-файла. Для Windows это можно сделать с помощью панели управления, а для Mac OS — с помощью настроек системы.
Причина №2: Неправильный OCR (распознавание символов)
Другой распространенной причиной проблем с поиском текста в PDF является неправильная работа OCR-системы (распознавание символов). OCR-система используется для распознавания отсканированного или изображенного текста в PDF-файле. Если OCR-система не может правильно распознать символы текста, поиск также не будет работать.
Устранение: Попробуйте использовать другую OCR-систему. Это может помочь улучшить качество распознавания. Другим вариантом может быть перенос текста в другой формат и повторное распознавание символов с помощью другой OCR-системы.
Причина №3: Неправильный формат PDF-файла
Еще одна возможная причина проблем с поиском слов в PDF-файле — это неправильный формат файла. Если PDF-файл был создан неправильно или имеет неподходящий формат, функция поиска может не работать.
Устранение: Попробуйте пересоздать PDF-файл с помощью другого инструмента или проверьте формат файла на предмет ошибок.
Причина №4: Плохое качество сканирования
Если PDF-файл создавался из отсканированных страниц, то проблемой с поиском могут стать их низкое качество сканирования. Если на отсканированных страницах есть много шума или пятен, OCR-системы могут неправильно распознавать символы.
Устранение: Попробуйте повторно отсканировать документ с лучшим качеством или использовать программы для последующей обработки изображений, которые позволяют удалить шум и пятна с отсканированных страниц.
Причина №5: Необходимо обновление Adobe Reader
Adobe Reader — это наиболее популярное приложение для чтения PDF-файлов. Если у вас установлена устаревшая версия Adobe Reader, функция поиска может работать неправильно.
Устранение: Обновите Adobe Reader до последней версии или используйте другое приложение для чтения PDF-файлов.
В заключение
Поиск текста в PDF-файлах — это важная функция, которая может помочь вам быстро найти нужную информацию в больших документах. Однако, если вы столкнулись с проблемами при поиске слов в PDF-файлах, эти возможные причины и способы их устранения могут помочь вам решить проблему.
Win 10 не ищет текст в PDF файлах (проверил три программы)
Добавлено через 15 минут
Похоже именно проблема с созданными PDF как "печать в PDF". В обычных файлах ищет. Что может быть не так?
Ищет ли Index Server в asp файлах?
Посоветуйте пожалуйста ищет ли Index Server в asp файлах? Если да, то киньте пожалуйста ссылку на.
 Программа ищет в двух текстовых файлах одинаковые слова и записывает их в третий
Программа ищет в двух текстовых файлах одинаковые слова и записывает их в третий
Здравствуйте.Мне нужна помощь по преобразованию кода с++ на си. Сам я изучаю С.Пытался сам.
Написать программу, которая с помощью цикла FOR /D ищет в log-файлах Windows сообщения.
Написать программу, которая с помощью цикла FOR /D ищет в log-файлах Windows сообщения, задаваемые.
Как посчитать количество страниц в PDF-файлах
Мне необходимо посчитать количество страниц в PDF-файлах (в данной дирректории и во всех вложениях).
Захват экрана воспринимается как графический файл. Получается так называемый "нераспознанный PDF"
Добавлено через 1 минуту
Распознать можно, обработав ABBY FineReader
Сообщение было отмечено Maks как решение
Решение
Нашел причину. Пусть останется тема, может кому пригодится.
При печати "Сохранить как PDF" создается PDF файл, в котором поиск работает.
При печати "Microsoft print to PDF" создается PDF файл, в котором поиск НЕ РАБОТАЕТ! Ни в какой программе чтения PDF файлов.
Проверял в Акробате-защиты на файле никакой нет. Почему не работает поиск. хбз (((
Сообщение от Laz2516
Сообщение от Laz2516
Возможно я не полноценно выразился, хотя написано по русски "ПРИ ПЕЧАТИ В PDF"
Где здесь слово картинка? Не нужно считать человека полным идиотом, пытающимся открывать картинку в Акробате!
Файлы создаются в обеих случаях как PDF, причем тут функция распознавания? Даже если посчитать что второй вариант делает снимок экрана и дает ему расширение pdf, тоже не сходится. Ибо создается файл с экрана имеющего несколько страниц. (с прокруткой экрана)
Я так понимаю в обеих случаях "печать" идет на виртуальный принтер, сохраняющий файл в pdf.
Сообщение от Jel
Возможно открыл мир. Открой любой сайт с длинным текстом чтобы скролить надо было, и попробуй сделать просто сохранение в картинку или принт скрин. Получишь ровно то, что сейчас видишь на экране. Все что ниже, не сохранится.
Сообщение от Laz2516
Чем эти способы отличаются? (по твоему во втором случае создается просто картинка? Имеющая расширение pdf. )
Возможно.
Добавлено через 7 минут
Возможно. ( ибо текст в таком файле выделить нельзя).
Сообщение от Laz2516
Не уверен что до сегодняшнего дня ты сам знал разницу в —
"Сохранить как PDF"
"Microsoft print to PDF".
Для меня, например, это явилось открытием. Оба способа создают одинаковый файл, если его читать просто. Внешне ничем не отличаются.
Сообщение от Laz2516
Гм. Прикольно. Попробовала поиск на файле с конфигурацией "текст с картинкой". В PDF и DOCX. Если искомое слово перед картинкой — поиск в папке такой файл находит. Если слово за картинкой — не находит. В обоих типах файлов. А поиск по файлу находит слово в любом случае.
Добавлено через 2 часа 59 минут
Упс. Это был какой-то глюк
Попробуйте кто нибудь оба варианта-
"Сохранить как PDF"
"Microsoft print to PDF"..
И потом проверьте поиск в созданных файлах.
(это у меня учеба и там не возможно сохранить из вэб браузера текст в doc , только вот таким образом. И видимо первым виртуальным принтером у меня оказался "Microsoft print to PDF". 5 лет назад еще на Win 7 сохранял таким образом и поиск работал. Тут же перебрал кучу читалок и не работает. И уже после создания темы обратил внимание, что сохранял то не так. Надо печать — "Сохранить как PDF".
Но что интересно, чем же эти два способа отличаются? Никогда бы не подумал, что есть такая разница. Файлы создаются одинаковые, но в варианте печать "Microsoft print to PDF".. текст в файле выделять не возможно и поиск не работает.
Как сделать поиск в ПДФ файле который не подается поиску?

Ваш случай еще простой. Хуже когда текст — это картинка.
Встраиваемый шрифт — это шрифт, который упакован в PDF-файл как ресурс. Внедрение гарантирует, что PDF-текст будет одинаково выглядеть везде, где бы он ни выводился или рассматривался, но это увеличивает размер файла документа. Нет смысла упаковывать в PDF-документ полный шрифт, если фактически из него используются несколько символов. Также для снижения размера документа использована однобайтовая кодировка вместо UTF-8.
Как починить поиск в русском PDF
Начинающий пользователь Help+Manual, пишущий документацию на русском языке, рано или поздно сталкивается с ситуацией, когда в созданном PDF-документе не работает поиск. Русский текст отображается корректно, но после копирования вставляется из буфера кракозябрами. В этой статье я расскажу, как это исправить и почему так получается.
Настройки по инструкции разработчика
Чтобы в PDF документах на русском языке, сгенерированных Help+Manual, корректно работал поиск, задайте следующие настройки:
- В языковых настройках проекта Configuration \ Common Properties \ Language Settings выберите русский язык и русскую кодировку. Это нужно для корректной работы Help+Manual с кириллицей.
- В параметрах публикации Configuration \ Publishing Options \ Adobe PDF \ Fonts Embedding включите внедрение шрифтов. Используйте режимы:
- Embed CID Fonts (обеспечивает максимальное качества текста при увеличении);
- Embed Type3 fonts (выберите, если поиск не заработал с предыдущим режимом; работает всегда, но качество текста при увеличении будет ниже).
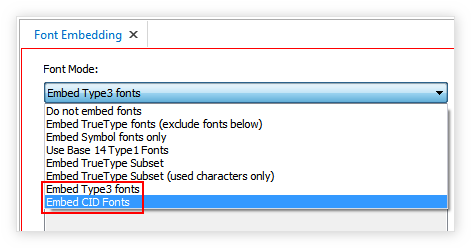
- Проверьте список исключений Do NOT embed these fonts. Он должен быть пустым. Все шрифты, использованные для оформления текста на русском языке, должны быть внедрены в документ*.
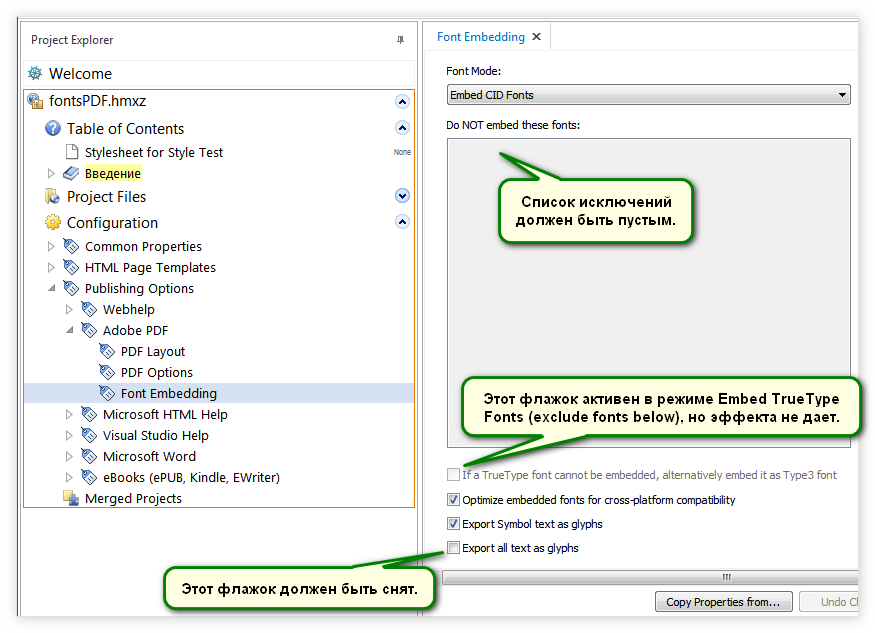
- В нижней части окна проверьте флажок Export all text as glyphs (Экспортировать весь текст как глифы). Он должен быть снят.
- В настройках Help+Manual View \ Program Options \ PDF Export проверьте драйвер принтера, используемый для генерации PDF**.
Дополнительная информация
*1. Разработчики формата PDF в документации указывают, что поиск в pdf-файлах, содержащих Кириллицу, должен работать и без внедрения шрифтов:
**2. В моей практике проблему поиска в русских PDF помогал решить только правильно выбранный режим внедрения шрифтов. Но этот пункт есть в инструкции разработчика по наладке поиска в PDF-документах с Кириллицей. Полный текст инструкции можно посмотреть на форуме поддержки.
3. Я пользуюсь Help+Manual с 2005 года, начиная с версии 4. С проблемой поиска в русских PDF-файлах сталкивался только в приложениях Adobe. В других бесплатных программах для просмотра PDF-файлов (например, STDU PDF Viewer и Foxit PDF Reader) поиск текста на русском языке всегда работал корректно. Русский текст также корректно копировался и вставлялся.
В чем причина
Новое — это хорошо забытое старое. Проблема с поиском в русских PDF была в Help&Manual 4 и 5. Решалась она аналогичным образом. И нет ничего удивительного, что версии 7 и 8 ее унаследовали.
Дело в том, что в Help&Manual начиная с версии 3 для генерации PDF-файлов используется компонент wPDF от компании WPCubed GmbH (Мюнхен).
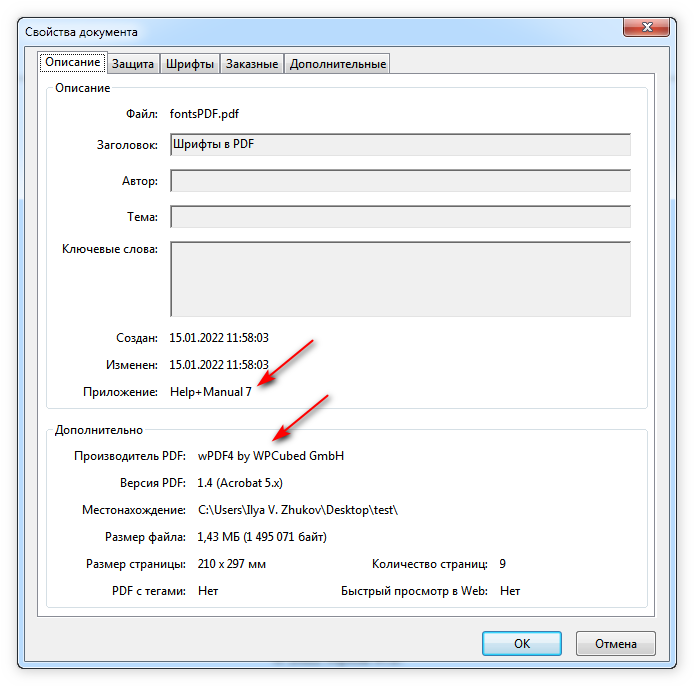
Дальше можно строить только предложения, начиная с кодовой таблицы и неюникодных шрифтов, которые могли использоваться для генерации PDF с русским текстом. Думаю, что у ребят из Мюнхена в списке задач вряд ли есть проблема с кодировкой в русских PDF, поэтому ограничусь приведенным выше решением.