Как использовать API сайта, когда его нет
В этой статье мы разберем, как получить и использовать API сайта, если по нему нет документации или оно еще не открыто официально. Руководство написано для новичков, которые еще не пробовали зареверсить простой API. Для тех же кто сам занимался подобным ничего нового здесь нет.
Разбор проведем на примере API сервиса https://www.captionbot.ai/ который недавно открыл Microsoft (спасибо им за это). Многие могли прочитать о нем в статье на Geektimes. Сайт использует ajax запросы в формате JSON, поэтому скопировать их будет легко и приятно. Поехали!
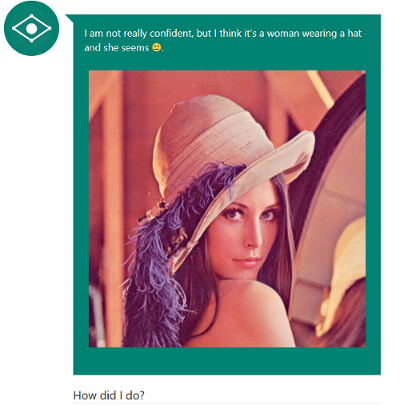
Анализируем запросы
В первую очередь открываем инструменты разработчика и анализируем запросы, которые сайт посылает на сервер.
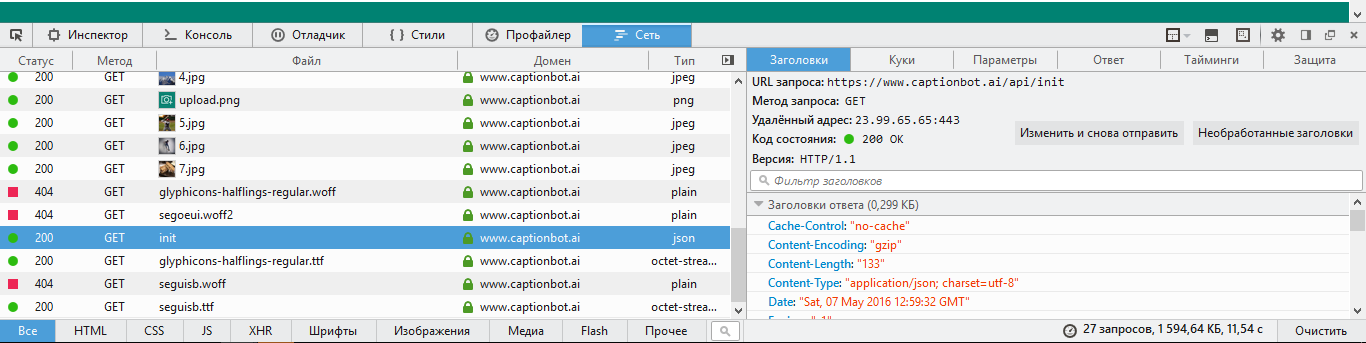
В нашем случае все интересующие нас запросы имеют базовый URL https://www.captionbot.ai/api
Инициализация
При первом открытии сайта идет GET запрос на /api/init без параметров.
Ответ имеет Content-Type: application/json , при этом в теле ответа нам приходит просто строка вида:
Запомним это и идем дальше.
Отправка URL
У нас есть два способа загрузить изображение: через URL и через загрузку файла. Для теста берем URL изображения Лены с вики и отсылаем. В сетевой активности появляется POST запрос на /api/message со следующими параметрами:
Ага, говорим себе мы, значит метод init вернул нам строку для conversationId , а в userMessage попала наша ссылка. Что такое waterMark пока непонятно. Смотрим на данные ответа:
Зачем-то закодировали JSON дважды, ну да ладно. В человеческом виде это выглядит так:
Все параметры по пути поменяли манеру написания, но это мелочи жизни. Итак, нам вернули некоторое значение WaterMark , почему-то пустой ConversationId , собственно подпись к фото в поле UserMessage и некий пустой статус.
Загрузка изображения
Далее, не закрывая вкладку, пробуем ту же операцию с загрузкой фото из локального файла. Видим POST запрос на /api/upload в формате multipart/form-data с названием поля file :
В ответ получаем строку URL нашего загруженного файла, можем перейти по нему и убедиться в этом:
Затем отсылается уже знакомый нам запрос на /api/message :
Вот и пригодился waterMark из предыдущего ответа, а URL тот, что нам вернул метод upload . Данные ответа аналогичны предыдущим.
Пишем обертку
Чтобы использовать полученные знания с удобством, делаем простую обертку на вашем любимом языке программирования. Я сделаю это на Python. Для запросов к сайту использую requests, так как он удобный и в нем есть сессии, которые хранят cookie за меня. Сайт использует SSL, но по дефолту requests будет ругаться на сертификат:
Поиск открытого API сайта или Ускоряем парсинг в 10 раз

Цель статьи — описать алгоритм действий поиска открытого API сайта.
Целевая аудитория статьи — программисты, которым интересен парсинг и анализ уязвимостей сайтов.
В статье рассмотрим пример поиска API сайта edadeal.ru, познакомимся с протоколом google protobuf и сравним скорость различных подходов парсинга
1. Введение
Парсинг (в контексте статьи) — это автоматизированный процесс извлечение данных из Интернета.
Существует 2 подхода к извлечению данных со страниц сайта
Извлекать данные из HTML-кода страницы сайта
Плюсы — этот способ прост и работает всегда, так как код страницы всегда доступен пользователю
Минусы — этот способ может работать долго (несколько секунд), если часть данных генерирует java script (например, данные появляются только после прокручивания страницы или нажатия кнопки)
Использовать API сайта
Плюсы — быстрее первого способа и не зависит от изменений структуры html-страницы
Минус — не у всех сайтов есть открытое API
В статье рассмотрим пример поиска API сайта edadeal.ru, познакомимся с протоколом google protobuf и сравним скорость двух подходов парсинга
2. Постановка задачи
Задача — извлечь данные о продуктах с сайта Едадил (название продукта, цена, размер скидки, магазин, город и т.д)
3. Решение
1 Делаем запрос к странице, которую мы хотим парсить.
2 Перебираем все запросы, которые делает сайт. Для этого используем DevTools браузера 
3 Анализируем запросы
Из названия запроса понимаем, что нам нужен запрос
https://squark.edadeal.ru/web/search/offers?count=30&locality=moskva&page=1&retailer=5ka
В ответ на запрос получаем файл (назовем его binary_file.bin). Как узнать кодировку этого файла?
Формат файла из пункта 3 нам подсказывает строка-хедер content-type: application/x-protobuf
4 Определим структуру данных (.proto файл)
с помощью утилиты protoc (http://google.github.io/proto-lens/installing-protoc.html) преобразуем закодированный файл в понятный человеку формат
protoc —decode_raw < binary_file.bin
Получаем список словарей:
5 Формируем .proto файл
Используем номера из предыдущего пункта, по контенту из предыдущего пункта нужно догадаться, какие поля, что означают (например 3 — это ссылка на изображение продукта)
Методом проб и ошибок получаем следующую структуру:
4 Переходим к написанию кода
Создаем питоновский файл с описанием структуры из .proto файла
protoc —proto_path=proto_files —python_out=proto_structs offers.proto
proto_files — имя директории с .proto файлами
proto_structs — в этой директории сохраняются результаты (_pb2.py файлы)
Код работает следующим образом:
- Делает запрос к API сайта
- Преобразует ответ сайта в json
- Выводит результат
Результат работы программы — список продуктов с описанием
5 Сравним результаты
Время выполнения кода из предыдущего пункта 0.3 — 0.4 секунды
Альтернативный вариант парсинга — загрузка всего html-кода страницы и извлечения нужной информации из этого кода
Время полной загрузки страницы 5 — 6 секунд.
6 Выводы
Лучше использовать API сайта для извлечения данных, если есть такая возможность
Использование API сайта позволяет не зависеть от изменений в html-коде страниы
Я хочу стянуть информацию с сайта. Как это сделать?
Допустим, нам нужно получить данные с сайта, сбор которых вручную нецелесообразен или невозможен из-за объёма. В таком случае мы можем автоматизировать процесс, используя инструменты, описанные далее.
Библиотека requests
Python-библиотека для выполнения запросов к серверу и обработки ответов. Фундамент скрипта для парсинга и наше основное оружие. Пользуясь данной библиотекой мы получаем содержимое страницы в виде html для дальнейшего парсинга.
Application programming interface — программный интерфейс приложения, предоставляемый владельцем веб-приложения для других разработчиков. Отсутствие API, способного удовлетворить наши нужды — первое в чем стоит убедиться прежде чем бросаться анализировать исходный код страницы и писать для нее парсер. Множество популярных сайтов имеет собственное api и документацию, которая объясняет как им пользоваться. Мы можем использовать api таким образом — формируем http-запрос согласно документации, и получаем ответ при помощи requests.
Beautifulsoup4 — это библиотека для парсинга html и xml документов. Позволяет получить доступ напрямую к содержимому любых тегов в html.
Selenium Web Driver
Данные на сайте могут генерироваться динамически при помощи javascript. В таком случае спарсить эти данные силами requests+bs4 не удастся. Дело в том, что bs4 парсит исходный код страницы, не исполняя js. Для исполнения js кода и получения страницы, идентичной той, которую мы видим в браузере, можно использовать selenium web driver — это набор драйверов для различных браузеров, снабжающийся библиотеками для работы с этими драйверами.
А что делать, если там авторизация?
Предварительно авторизоваться, отправив post-запрос и инициировать сессию:
А что, если сайт банит за много запросов?
- Установить задержку между запросами:
- Притвориться браузером, используя selenium web driver или передав содержимое заголовка user-agent, формируя запрос:
- Использовать прокси:
Попробуйте бесплатные уроки по Python
Получите крутое код-ревью от практикующих программистов с разбором ошибок и рекомендациями, на что обратить внимание — бесплатно.
Извлечение данных сайта и создание API с помощью WrapAPI
Сегодня почти все сервисы, которые мы используем, имеют своего рода API. Некоторые веб-приложения даже создаются только из точек API и передаются в какое-то интерфейсное представление. Если вы являетесь пользователем службы, предоставляющей API, вам иногда понадобятся дополнительные функции или ограничения, которые может предложить API. В этой статье мы расскажем о сервисе, который полезен как пользователям, так и создателям API.
Я всегда говорю, что если есть веб-интерфейс, вы можете создать собственный API. WrapAPI пытается сделать этот процесс проще. Если вы знакомы с процессом очистки / сканирования (или извлечения данных с веб-сайтов), вы увидите магию WrapAPI.
WrapAPI предлагает сервис, который позволяет легко извлекать информацию с веб-сайтов и создавать API-интерфейсы из данных. Он предоставляет простой, интерактивный способ выбора того, какую информацию вы хотите получить. Всего несколькими щелчками мыши вы можете подключить свой API онлайн.
Чтобы следовать этому руководству, я рекомендую вам перейти на wrapapi.com и создать учетную запись.
Как обойти WrapAPI
На сайте WrapAPI вы увидите, что можете приступить к созданию своего проекта сразу, хотя, если вы не создадите учетную запись, ваша работа не будет сохранена.
После того, как вы зарегистрировались, нажмите кнопку Построить API .
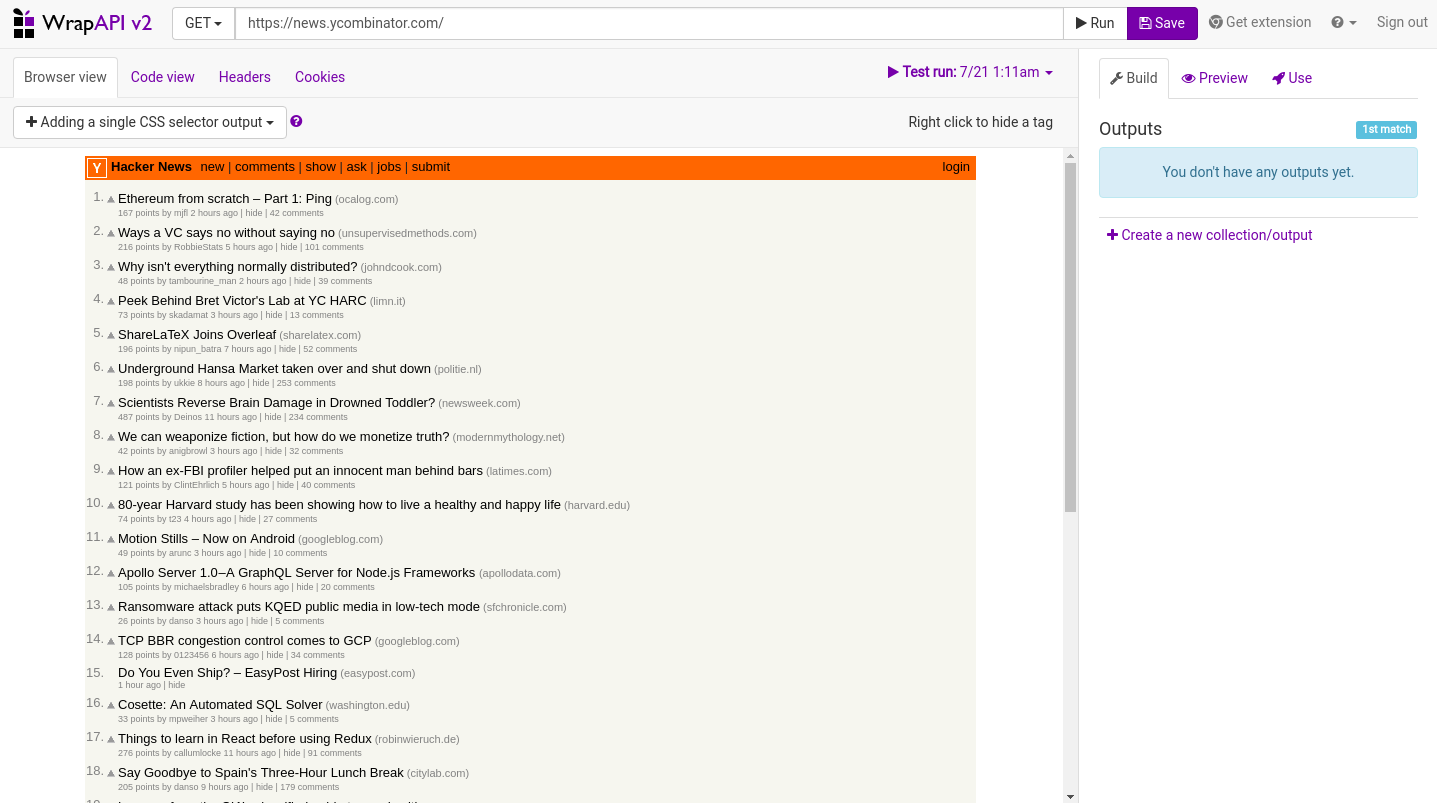
Вы будете представлены интерфейсом, похожим на браузер. В верхней части сайта мы представляем адресную строку. В качестве примера WrapAPI использует Hacker News ( https://news.ycombinator.com/ Если щелкнуть URL-адрес, чтобы изменить его на что-то другое, вы увидите больше параметров, связанных с запросом, который вы хотите сделать. Мы будем использовать параметры по умолчанию и изменим только URL-адрес на https://www.sitepoint.com/javascript/ Мы рассматриваем только метод GET , поскольку мы хотим получить данные только в этом примере.
Под строкой URL-адреса расположены четыре кнопки, которые предоставляют различную информацию о просматриваемом сайте. Вид браузера отображает сайт так же, как вы заходите на него из браузера. Представление «Код» отображает исходный код сайта. Заголовки показывают ответ, который вы получаете от сервера. Это полезно, если вы хотите посмотреть, какой ответ вы получите от сервера: он предоставляет вам такую информацию, как коды состояния HTTP (200, 404, 400 и т. Д.), Типы контента, веб-серверы и так далее. Вы также можете просмотреть куки-файлы запроса непосредственно от застройщика.
Получение данных
Теперь вы должны видеть SitePoint внутри фрейма просмотра браузера .

Давайте создадим очень простой API, который показывает нам последние заголовки сообщений канала JavaScript. Если вы наводите курсор на заголовки, изображения или любой другой элемент на сайте, вы заметите выделение цвета, покрывающее его. Давайте прокрутим немного вниз, до самой последней статьи. Наведите указатель мыши на заголовок одной из статей и нажмите на него. Вы заметите, что он не переключается на ту ссылку, на которую мы нажали. Мы видим, что каждый заголовок в этом разделе выделен. WrapAPI догадался, что это все названия, которые мы хотим. Иногда он также может выбирать части сайтов, которые нам не нужны. Это обычно тот случай, когда селекторы класса CSS не определены или не используются другими элементами сайта.
Помимо селекторов CSS, WrapAPI поддерживает регулярные выражения, селекторы JSON, заголовки, файлы cookie, выходные данные форм и множество других опций. Вы можете использовать их все вместе и извлекать именно то, к чему вы стремитесь. В этом примере мы будем использовать только селекторы CSS.
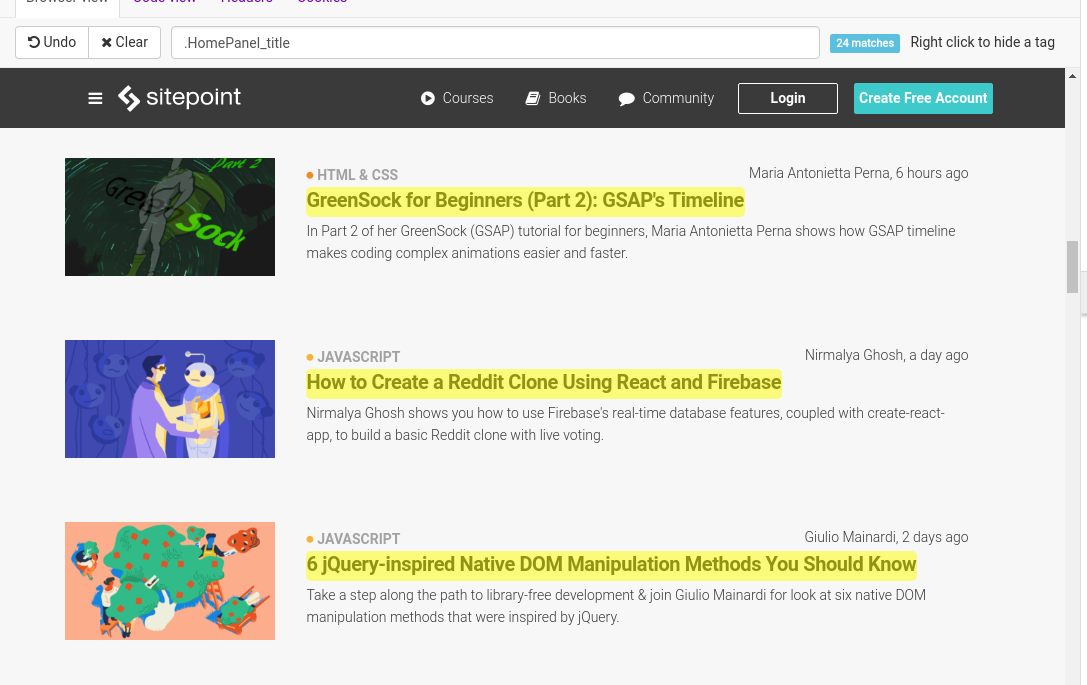
В правой части интерфейса вы увидите три вкладки. Давайте посмотрим на текущую вкладку Build . Результаты покажут нам селекторы (в нашем случае селекторы CSS), и вы получите более подробную информацию о том, что вы хотели бы выбрать. Мы заинтересованы только в извлечении заголовка, который является текстом. Есть и другие варианты очистки результатов, но мы не будем вдаваться в эти детали. Если вы хотите создать другой селектор, чтобы выбрать описание, автора, дату и т. Д., Просто нажмите Создать новую коллекцию / вывод . Называние ваших селекторов также важно, так как это облегчит использование нескольких селекторов на сайте. Нажав на значок карандаша, вы можете редактировать ваши селекторы.

На вкладке « Предварительный просмотр » будет показано представление наших данных в формате JSON, и вы, вероятно, получите представление о том, как будет выглядеть API. Если вы довольны результатами, вы можете нажать кнопку Сохранить , чтобы сохранить версию API.
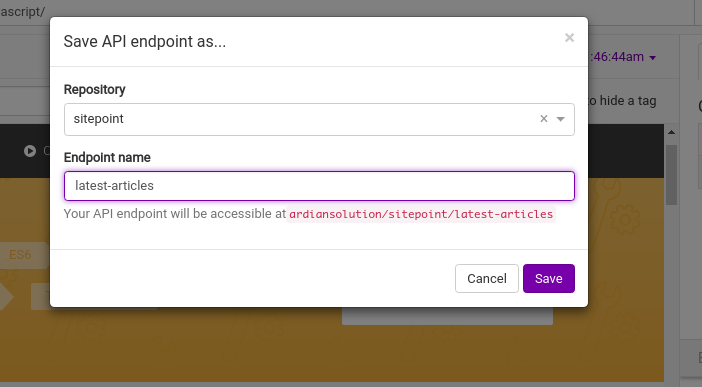
Вам нужно будет ввести репозиторий и имя конечной точки API. Это помогает вам управлять и организовывать свои API. Это также будет частью имени вашего API в конце. После ввода информации вы вернетесь к застройщику. Наш API сохранен, но теперь нам нужно протестировать и опубликовать его.
Советы
- Если на сайте есть нумерация страниц (предыдущая / следующая страница), вы можете использовать параметры строки запроса. (Подробнее об этом здесь .)
- Назовите ваши селекторы правильно, так как они будут частью вывода JSON.
Расширение WrapAPI Chrome
Расширение WrapAPI chrome – это еще одно средство для создания API. Это позволяет вам захватывать запросы, сделанные с помощью Chrome. Полезно для сайтов, использующих JavaScript (Ajax) для вызова данных, также отлично подходит для сайтов, которые находятся за логинами. Вы можете установить его из интернет- магазина Chrome.
На этот раз давайте воспользуемся Hacker News. Посетите сайт, с которого вы хотите получить данные, а затем выполните следующие действия:
Откройте Chrome DevTools и перейдите на вкладку WrapAPI на самой правой вкладке.
Разблокируйте его в отдельном окне.
Войдите с вашими учетными данными WrapAPI.

Когда вы будете готовы, нажмите кнопку Запустить захват запросов .
Обновите главную вкладку, где вы используете.
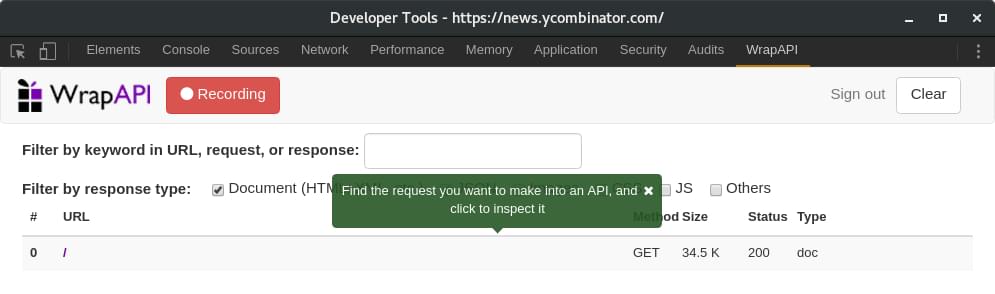
Выберите запрос, который вы хотите сделать в API (используя GET
Нажмите кнопку Сохранить в конечную точку API и сохраните ее в хранилище.
Наконец, щелкните ссылку: нажмите здесь, чтобы использовать ее для определения входов и выходов конечной точки API…
Вы будете перенаправлены к строителю, чтобы извлечь данные. Преимущество использования этого метода заключается в том, что вы можете обходить страницы входа и использовать уже назначенные файлы cookie.
Публикация API
Перед публикацией нашего API мы должны заморозить его. Выбор номера выпуска, такого как 0.0.1, работает нормально. Обратите внимание, что любые изменения, которые вы вносите в API, вам придется заморозить как новую версию, также увеличив номер версии. Предоставьте простое описание того, что представляет собой ваш API, или, если это обновление, какие изменения оно содержит. Наконец, нажмите Опубликовать .
Последний шаг перед публикацией – это генерация ключа. Нажмите Создать ключ API .
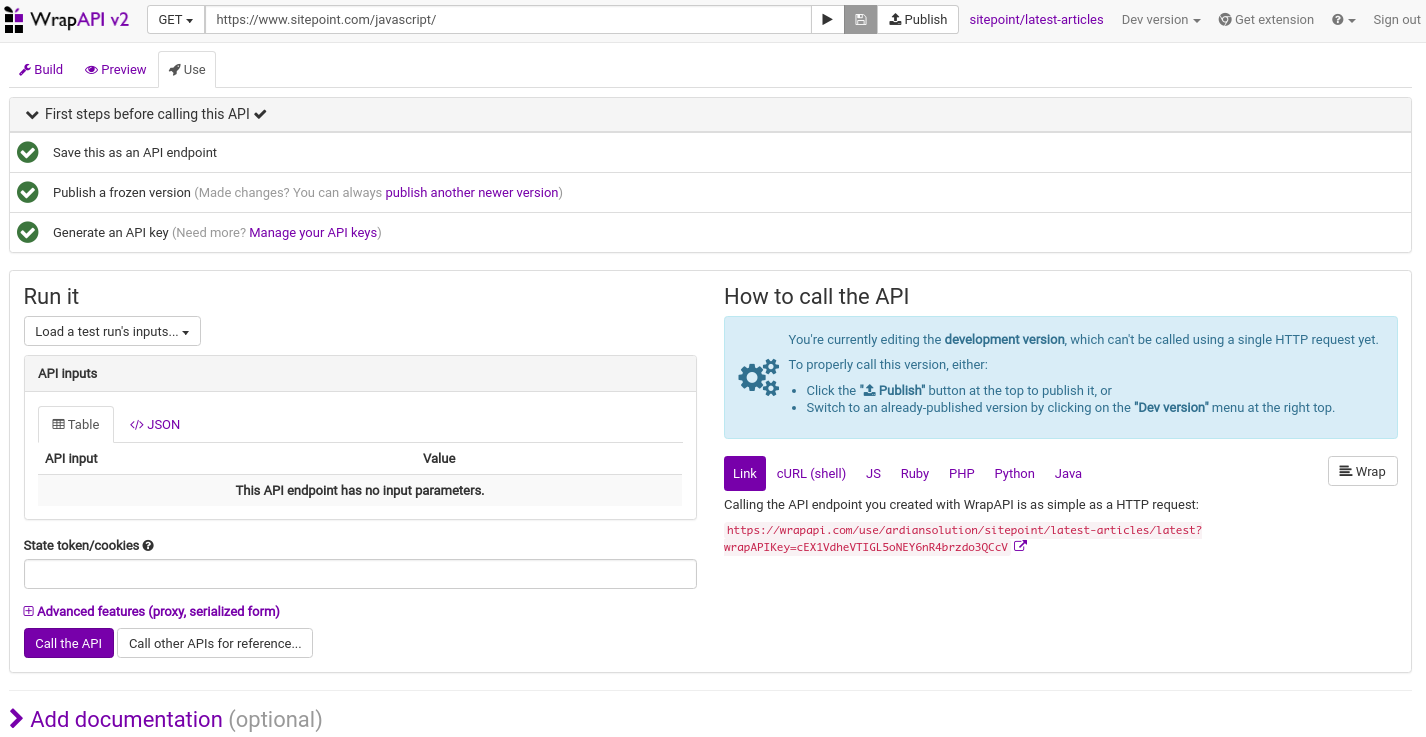
Все зеленые? это должно означать, что мы успешно выполнили шаги, необходимые для публикации нашего API, и это почти правильно. Последний шаг – нажать кнопку « Опубликовать» вверху после строки URL. Вы уже можете видеть различные языки программирования, которые вы можете использовать для тестирования API. Я буду использовать свой браузер с расширением для лучшего представления JSON.
И вот наш последний API:

Вывод
В течение минуты мы смогли создать API из простого веб-интерфейса.
Есть некоторые вещи, которые вы должны рассмотреть. Очистка / извлечение данных с веб-сайтов может иногда иметь юридические последствия для содержимого, найденного на веб-сайте. Если вам случается использовать веб-сайт в качестве службы для вашего API, рассмотрите вопрос о разрешении использовать этот контент, особенно при распространении его в виде API.
WrapAPI предоставляет некоторые действительно замечательные и простые в использовании функции, но они не обходятся без цены. Бесплатные учетные записи и учетные записи сообщества предоставляются бесплатно, но вы можете создавать только открытые API, и существует ограничение в 30 000 вызовов API в месяц. Есть несколько тарифных планов . Вы всегда можете создать свои собственные API и скребки, но если вам не хватает навыков или у вас нет времени, то, возможно, вы захотите попробовать WrapAPI.