Найти все простые числа из промежутка от 1 до n
Как найти все простые числа из промежутка от a до b?
создать программу в методах Даны натуральные числа от a до b (a < b). Найти все простые числа из.
 Получить все простые числа из промежутка
Получить все простые числа из промежутка
Написать програму, использую цикл for. Задача: Даны натуральные числа a, b (a<b). Получить все.
Найдите все простые числа из промежутка (a,b)
Здравствуйте. Я только учусь программировать. Запуталась с одной задачкой. Помогите, пожалуйста.
Алгоритмы поиска простых чисел
 «Самое большое простое число 2 32582657 -1. И я с гордостью утверждаю, что запомнил все его цифры… в двоичной форме».
«Самое большое простое число 2 32582657 -1. И я с гордостью утверждаю, что запомнил все его цифры… в двоичной форме».
Карл Померанс
Натуральное число называется простым, если оно имеет только два различных делителя: единицу и само себя. Задача поиска простых чисел не дает покоя математикам уже очень давно. Долгое время прямого практического применения эта проблема не имела, но все изменилось с появлением криптографии с открытым ключом. В этой заметке рассматривается несколько способов поиска простых чисел, как представляющих исключительно академический интерес, так и применяемых сегодня в криптографии.
Решето Эратосфена
Решето Эратосфена — алгоритм, предложенный древнегреческим математиком Эратосфеном. Этот метод позволяет найти все простые числа меньше заданного числа n. Суть метода заключается в следующем. Возьмем набор чисел от 2 до n. Вычеркнем из набора (отсеим) все числа делящиеся на 2, кроме 2. Перейдем к следующему «не отсеянному» числу — 3, снова вычеркиваем все что делится на 3. Переходим к следующему оставшемуся числу — 5 и так далее до тех пор пока мы не дойдем до n. После выполнения вышеописанных действий, в изначальном списке останутся только простые числа.
Алгоритм можно несколько оптимизировать. Так как один из делителей составного числа n обязательно , алгоритм можно останавливать, после вычеркивания чисел делящихся на .
Иллюстрация работы алгоритма из Википедии:
Сложность алгоритма составляет , при этом, для хранения информации о том, какие числа были вычеркнуты требуется памяти.
Существует ряд оптимизаций, позволяющих снизить эти показатели. Прием под названием wheel factorization состоит в том, чтобы включать в изначальный список только числа взаимно простые с несколькими первыми простыми числами (например меньше 30). В теории предлагается брать первые простые примерно до . Это позволяет снизить сложность алгоритма в раз. Помимо этого для уменьшения потребляемой памяти используется так называемое сегментирование. Изначальный набор чисел делится на сегменты размером и для каждого сегмента решето Эратосфена применяется по отдельности. Потребление памяти снижается до .
Решето Аткина
Более совершенный алгоритм отсеивания составных чисел был предложен Аткином и Берштайном и получил название Решето Аткина. Этот способ основан на следующих трех свойствах простых чисел.
Если n — положительное число, не кратное квадрату простого числа и такое, что . То n — простое, тогда и только тогда, когда число корней уравнения нечетно.
Если n — положительное число, не кратное квадрату простого числа и такое, что . То n — простое, тогда и только тогда, когда число корней уравнения нечетно.
Если n — положительное число, не кратное квадрату простого числа и такое, что . То n — простое, тогда и только тогда, когда число корней уравнения нечетно.
Доказательства этих свойств приводятся в этой статье.
На начальном этапе алгоритма решето Аткина представляет собой массив A размером n, заполненный нулями. Для определения простых чисел перебираются все . Для каждой такой пары вычисляется , , и значение элементов массива , , увеличивается на единицу. В конце работы алгоритма индексы всех элементов массива, которые имеют нечетные значения либо простые числа, либо квадраты простого числа. На последнем шаге алгоритма производится вычеркивание квадратов оставшихся в наборе чисел.
Из описания алгоритма следует, что вычислительная сложность решета Аткина и потребление памяти составляют . При использовании wheel factorization и сегментирования оценка сложности алгоритма снижается до , а потребление памяти до .
Числа Мерсенна и тест Люка-Лемера
Конечно при таких показателях сложности, даже оптимизированное решето Аткина невозможно использовать для поиска по-настоящему больших простых чисел. К счастью, существуют быстрые тесты, позволяющие проверить является ли заданное число простым. В отличие от алгоритмов решета, такие тесты не предназначены для поиска всех простых чисел, они лишь способны сказать с некоторой вероятностью, является ли определенное число простым.
Один из таких методов проверки — тест Люка-Лемера. Это детерминированный и безусловный тест простоты. Это означает, что прохождение теста гарантирует простоту числа. К сожалению, тест предназначен только для чисел особого вида , где p — натуральное число. Такие числа называются числами Мерсенна.
Тест Люка-Лемера утверждает, что число Мерсенна простое тогда и только тогда, когда p — простое и делит нацело -й член последовательности задаваемой рекуррентно: для .
Для числа длиной p бит вычислительная сложность алгоритма составляет .
Благодаря простоте и детерминированности теста, самые большие известные простые числа — числа Мерсенна. Самое большое известное простое число на сегодня — , его десятичная запись состоит из 24,862,048 цифр. Полюбоваться на эту красоту можно здесь.
Теорема Ферма и тест Миллера-Рабина
Простых чисел Мерсенна известно не очень много, поэтому для криптографии с открытым ключом необходим другой способ поиска простых чисел. Одним из таким способов является тест простоты Ферма. Он основан на малой теореме Ферма, которая гласит, что если n — простое число, то для любого a, которое не делится на n, выполняется равенство . Доказательство теоремы можно найти на Википедии.
Тест простоты Ферма — вероятностный тест, который заключается в переборе нескольких значений a, если хотя бы для одного из них выполняется неравенство , то число n — составное. В противном случае, n — вероятно простое. Чем больше значений a использовано в тесте, тем выше вероятность того, что n — простое.
К сожалению, существуют такие составные числа n, для которых сравнение выполняется для всех a взаимно простых с n. Такие числа называются числам Кармайкла. Составные числа, которые успешно проходят тест Ферма, называются псевдопростыми Ферма. Количество псевдопростых Ферма бесконечно, поэтому тест Ферма — не самый надежный способ определения простых чисел.
Тест Миллера-Рабина
Более надежных результатов можно добиться комбинируя малую теорему Ферма и тот факт, что для простого числа p не существует других корней уравнения , кроме 1 и -1. Тест Миллера-Рабина перебирает несколько значений a и проверяет выполнение следующих условий.
Пусть p — простое число и , тогда для любого a справедливо хотя бы одно из условий:
- Существует целое число r < s такое, что
Чем больше свидетелей простоты найдено, тем выше вероятность того, что n — простое. Согласно теореме Рабина вероятность того, что случайно выбранное число a окажется свидетелем простоты составного числа составляет приблизительно .
Следовательно, если проверить k случайных чисел a, то вероятность принять составное число за простое .
Сложность работы алгоритма , где k — количество проверок.
Благодаря быстроте и высокой точности тест Миллера-Рабина широко используется при поиске простых чисел. Многие современные криптографические библиотеки при проверке больших чисел на простоту используют только этот тест и, как показал Мартин Альбрехт в своей работе , этого не всегда оказывается достаточно.
Он смог сгенерировать такие составные числа, которые успершно прошли тест на простоту в библиотеках OpenSSL, CryptLib, JavaScript Big Number и многих других.
Тест Люка и Тест Baillie–PSW
Чтобы избежать уязвимости, связанные с ситуациями, когда сгенерированное злоумышленником составное число, выдается за простое, Мартин Альбрехт предлагает использовать тест Baillie–PSW. Несмотря на то, что тест Baillie–PSW является вероятностным, на сегодняшний день не найдено ни одно составное число, которое успешно проходит этот тест. За нахождение подобного числа в 1980 году авторы алгоритма пообещали вознаграждение в размере $30. Приз пока так и не был востребован.
Ряд исследователей проверили все числа до и не обнаружили ни одного составного числа, прошедшего тест Baillie–PSW. Поэтому, для чисел меньше тест считается детерминированным.
Суть теста сводится к последовательной проверке числа на простоу двумя различными методами. Один из этих методов уже описанный выше тест Миллера-Рабина. Второй — тест Люка на сильную псевдопростоту.
Тест Люка на сильную псевдопростоту
Последовательности Люка — пары рекуррентных последовательностей , описываемые выражениями:
Пусть и — последовательности Люка, где целые числа P и Q удовлетворяют условию
Найдем такие r, s для которых выполняется равенство
Для простого числа n выполняется одно из следующих условий:
- n делит
- n делит для некоторого j < r
Вероятность того, что составное число n успешно пройдет тест Люка для заданной пары параметров P, Q не превышает 4/15. Следовательно, после применения теста k раз, эта вероятность составляет .
Тесты Миллера-Рабина и Люка производят не пересекающиеся множества псевдопростых чисел, соответственно если число p прошло оба теста, оно простое. Именно на этом свойстве основывается тест Baillie–PSW.
Заключение
В зависимости от поставленной задачи, могут использоваться различные методы поиска простых чисел. К примеру, при поиске больших простых чисел Мерсенна, сперва, при помощи решета Эратосфена или Аткина определяется список простых чисел до некоторой границы, предположим, до . Затем для каждого числа p из списка, с помощью теста Люка-Лемера, на простоту проверяется .
Чтобы сгенерировать большое простое число в криптографических целях, выбирается случайное число a и проверяется тестом Миллера-Рабина или более надежным Baillie–PSW. Согласно теореме о распределении простых чисел, у случайно выбранного числа от 1 до n шанс оказаться простым примерно равен . Следовательно, чтобы найти простое число размером 1024 бита, достаточно перебрать около тысячи вариантов.
Теория чисел
Простым называется натуральное число, которое делится только на единицу и на себя. Единица при этом простым числом не считается. Составным числом называют непростое число, которое еще и не единица.
Примеры простых чисел: \(2\) , \(3\) , \(5\) , \(179\) , \(10^9+7\) , \(10^9+9\) .
Примеры составных чисел: \(4\) , \(15\) , \(2^<30>\) .
Еще одно определение простого числа: \(N\) — простое, если у \(N\) ровно два делителя. Эти делители при этом равны \(1\) и \(N\) .
Проверка на простоту за линию
С точки зрения программирования интересно научиться проверять, является ли число \(N\) простым. Это очень легко сделать за \(O(N)\) — нужно просто проверить, делится ли оно хотя бы на одно из чисел \(2, 3, 4, \ldots, N-1\) . \(N > 1\) является простым только в случае, если оно не делится на на одно из этих чисел.
Проверка на простоту за корень
Алгоритм можно ускорить с \(O(N)\) до \(O(\sqrt
Пусть \(N = a \times b\) , причем \(a \leq b\) . Тогда заметим, что \(a \leq \sqrt N \leq b\) .
Почему? Потому что если \(a \leq b < \sqrt
Иными словами, если число \(N\) равно произведению двух других, то одно из них не больше корня из \(N\) , а другое не меньше корня из \(N\) .
Из этого следует, что если число \(N\) не делится ни на одно из чисел \(2, 3, 4, \ldots, \lfloor\sqrt
Разложение на простые множители
Любое натуральное число можно разложить на произведение простых, и с такой записью очень легко работать при решении задач. Разложение на простые множители еще называют факторизацией.
\[11 = 11 = 11^1\] \[100 = 2 \times 2 \times 5 \times 5 = 2^2 \times 5^2\] \[126 = 2 \times 3 \times 3 \times 7 = 2^1 \times 3^2 \times 7^1\]
Рассмотрим, например, такую задачу:
Условие: Нужно разбить \(N\) людей на группы равного размера. Нам интересно, какие размеры это могут быть.
Решение: По сути нас просят найти число делителей \(N\) . Нужно посмотреть на разложение числа \(N\) на простые множители, в общем виде оно выглядит так:
\[N= p_1^
Теперь подумаем над этим выражением с точки зрения комбинаторики. Чтобы «сгенерировать» какой-нибудь делитель, нужно подставить в степень \(i\) -го простого число от 0 до \(a_i\) (то есть \(a_i+1\) различное значение), и так для каждого. То есть делитель \(N\) выглядит ровно так: \[M= p_1^
Алгоритм разложения на простые множители
Применяя алгоритм проверки числа на простоту, мы умеем легко находить минимальный простой делитель числа N. Ясно, что как только мы нашли простой делитель числа \(N\) , мы можем число \(N\) на него поделить и продолжить искать новый минимальный простой делитель.
Будем перебирать простой делитель от \(2\) до корня из \(N\) (как и раньше), но в случае, если \(N\) делится на этот делитель, будем просто на него делить. Причем, возможно, нам понадобится делить несколько раз ( \(N\) может делиться на большую степень этого простого делителя). Так мы будем набирать простые делители и остановимся в тот момент, когда \(N\) стало либо \(1\) , либо простым (и мы остановились, так как дошли до корня из него). Во втором случае надо еще само \(N\) добавить в ответ.
Напишем алгоритм факторизации:
Задание
За сколько работает этот алгоритм?
Решение
За те же самые \(O(\sqrt
А итераций деления \(N\) на делители будет столько, сколько всего простых чисел в факторизации числа \(N\) . Понятно, что это не больше, чем \(O(\log
Задание
Докажите, что число \(N\) имеет не больше, чем \(O(\log
Разные свойства простых чисел*
Вообще, про простые числа известно много свойств, но почти все из них очень трудно доказать. Вот еще некоторые из них:
- Простых чисел, меньших \(N\) , примерно \(\frac
<\ln N>\) . - N-ое простое число равно примерно \(N\ln N\) .
- Простые числа распределены более-менее равномерно. Например, если вам нужно найти какое-то простое число в промежутке, то можно их просто перебрать и проверить — через несколько сотен какое-нибудь найдется.
- Для любого \(N \ge 2\) на интервале \((N, 2N)\) всегда найдется простое число (Постулат Бертрана)
- Впрочем, существуют сколь угодно длинные отрезки, на которых простых чисел нет. Самый простой способ такой построить — это начать с \(N! + 2\) .
- Есть алгоритмы, проверяющие число на простоту намного быстрее, чем за корень. равно примерно \(O(\sqrt[3]
)\) . Это не математический результат, а чисто эмпирический — не пишите его в асимптотиках. - Максимальное число делителей у числа на отрезке \([1, 10^5]\) — 128
- Максимальное число делителей у числа на отрекзке \([1, 10^9]\) — 1344
- Максимальное число делителей у числа на отрезке \([1, 10^<18>]\) — 103680
- Наука умеет факторизовать числа за \(O(\sqrt[4]
)\) , но об этом как-нибудь в другой раз. - Любое число больше трёх можно представить в виде суммы двух простых (гипотеза Гольдбаха), но это не доказано.
Решето Эратосфена
Часто нужно не проверять на простоту одно число, а найти все простые числа до \(N\) . В этом случае наивный алгоритм будет работать за \(O(N\sqrt N)\) , так как нужно проверить на простоту каждое число от 1 до \(N\) .
Но древний грек Эратосфен предложил делать так:
Запишем ряд чисел от 1 до \(N\) и будем вычеркивать числа: * делящиеся на 2, кроме самого числа 2 * затем деляющиеся на 3, кроме самого числа 3 * затем на 5, затем на 7, и так далее и все остальные простые до n. Таким образом, все незачеркнутые числа будут простыми — «решето» оставит только их.
Задание
Найдите этим способом на бумажке все простые числа до 50, потом проверьте с программой:
У этого алгоритма можно сразу заметить несколько ускорений.
Во-первых, число \(i\) имеет смысл перебирать только до корня из \(N\) , потому что при зачеркивании составных чисел, делящихся на простое \(i > \sqrt N\) , мы ничего не зачеркнем. Почему? Пусть существует составное \(M \leq N\) , которое делится на %i%, и мы его не зачеркнули. Но тогда \(i > \sqrt N \geq \sqrt M\) , а значит по ранее нами доказанному утверждению \(M\) должно делиться и на простое число, которое меньше корня. Но это значит, что мы его уже вычеркнули.
Во-вторых, по этой же самое причине \(j\) имеет смысл перебирать только начиная с \(i^2\) . Зачем вычеркивать \(2i\) , \(3i\) , \(4i\) , …, \((i-1)i\) , если они все уже вычеркнуты, так как мы уже вычеркивали всё, что делится на \(2\) , \(3\) , \(4\) , …, \((i-1)\) .
Асимптотика
Такой код будет работать за \(O(N \log \log N)\) по причинам, которые мы пока не хотим объяснять формально.
Гармонический ряд
Научимся оценивать асимптотику величины \(1 + \frac<1> <2>+ \ldots + \frac<1>
Возьмем \(N\) равное \(2^i — 1\) и запишем нашу сумму следующим образом: \[\left(\frac<1><1>\right) + \left(\frac<1> <2>+ \frac<1><3>\right) + \left(\frac<1> <4>+ \ldots + \frac<1><7>\right) + \ldots + \left(\frac<1><2^> + \ldots + \frac<1><2^i - 1>\right)\]
Каждое из этих слагаемых имеет вид \[\frac<1> <2^j>+ \ldots + \frac<1> <2^
Таким образом, наша сумма не превосходит \(1 + 1 + \ldots + 1 = i \le 2\log_2(2^i — 1)\) . Тем самым, взяв любое \(N\) и дополнив до степени двойки, мы получили асимптотику \(O(\log N)\) .
Оценку снизу можно получить аналогичным образом, оценив каждое такое слагаемое снизу значением \(\frac<1><2>\) .
Попытка объяснения асимптотики** (для старших классов)
Мы знаем, что гармонический ряд \(1 + \frac<1> <2>+ \frac<1> <3>+ \ldots + \frac<1>
А что такое асимптотика решета Эратосфена? Мы как раз ровно \(\frac
\) раз зачеркиваем числа делящиеся на простое число \(p\) . Если бы все числа были простыми, то мы бы как раз получили \(N \log N\) из формули выше. Но у нас будут не все слагаемые оттуда, только с простым \(p\) , поэтому посмотрим чуть более точно.
Известно, что простых чисел до \(N\) примерно \(\frac
Но вообще-то решето можно сделать и линейным.
Задание
Решите 5 первых задач из этого контеста:
Линейное решето Эратосфена*
Наша цель — для каждого числа до \(N\) посчитать его минимальный простой делитель. Будем хранить его в массиве min_d. Параллельно будем хранить и список всех найденных простых чисел primes — это ровно те числа \(x\) , у которых \(min\_d[x] = x\) .
Основное утверждение такое:
Пусть у числа \(M\) минимальный делитель равен \(a\) . Тогда, если \(M\) составное, мы хотим вычеркнуть его ровно один раз при обработке числа \(\frac
\) .
Мы также перебираем число \(i\) от \(2\) до \(N\) . Если \(min\_d[i]\) равно 0 (то есть мы не нашли ни один делитель у этого числа еще), значит оно простое — добавим в primes и сделаем \(min\_d[i] = i\) .
Далее мы хотим вычеркнуть все числа \(i \times k\) такие, что \(k\) — это минимальный простой делитель этого числа. Из этого следует, что необходимо и достаточно перебрать \(k\) в массиве primes, и только до тех пор, пока \(k < min\_d[i]\) . Ну и перестать перебирать, если \(i \times k > N\) .
Алгоритм пометит все числа по одному разу, поэтому он корректен и работает за \(O(N)\) .
Этот алгоритм работает асимптотически быстрее, чем обычное решето. Но на практике, если писать обычное решето Эратсфена с оптимизациями, то оно оказывается быстрее линейнего. Также линейное решето занимает гораздо больше памяти — ведь в обычном решете можно хранить просто \(N\) бит, а здесь нам нужно \(N\) чисел и еще массив primes.
Зато один из «побочных эффектов» алгоритма — он неявно вычисляет факторизацию всех чисел от \(1\) до \(N\) . Ведь зная минимальный простой делитель любого числа от \(1\) до \(N\) можно легко поделить на это число, посмотреть на новый минимальный простой делитель и так далее.
НОД и НОК
Введем два определения.
Наибольший общий делитель (НОД) чисел \(a_1, a_2, \ldots, a_n\) — это максимальное такое число \(x\) , что все \(a_i\) делятся на \(x\) .
Наименьшее общее кратное (НОК) чисел \(a_1, a_2, \ldots, a_n\) — это минимальное такое число \(x\) , что \(x\) делится на все \(a_i\) .
Например, * НОД(18, 30) = 6 * НОД(60, 180, 315) = 15 * НОД(1, N) = 1 * НОК(12, 30) = 6 * НОК(1, 2, 3, 4) = 12 * НОК(1, \(N\) ) = \(N\)
Зачем они нужны? Например, они часто возникают в задачах.
Условие: Есть \(N\) шестеренок, каждая \(i\) -ая зацеплена с \((i-1)\) -ой. \(i\) -ая шестеренка имеет \(a_i\) зубчиков. Сколько раз нужно повернуть полносьтю первую шестеренку, чтобы все остальные шестеренки тоже вернулись на изначальное место?
Решение: Когда одна шестеренка крутится на 1 зубчик, все остальные тоже крутятся на один зубчик. Нужно найти минимальное такое число зубчиков \(x\) , что при повороте на него все шестеренки вернутся в изначальное положение, то есть \(x\) делится на все \(a_i\) , то есть это НОК( \(a_1, a_2, \ldots, a_N\) ). Ответом будет \(\frac
Еще пример задачи на применение НОД и НОК:
Условие: Город — это прямоугольник \(n\) на \(m\) , разделенный на квадраты единичного размера. Вертолет летит из нижнего левого угла в верхний правый по прямой. Вертолет будит людей в квартале, когда он пролетает строго над его внутренностью (границы не считаются). Сколько кварталов разбудит вертолёт?
Решение: Вертолет пересечет по вертикали \((m-1)\) границу. С этим ничего не поделать — каждое считается как новое посещение какого-то квартала. По горизонтали то же самое — \((n-1)\) переход в новую ячейку будет сделан.
Однако еще есть случай, когда он пересекает одновременно обе границы (то есть пролетает над каким-нибудь углом) — ровно тот случай, когда нового посещения квартала не происходит. Сколько таких будет? Ровно столько, сколько есть целых решений уравнения \(\frac
Пусть \(t = НОД(n, m)\) , тогда \(n = at, m = bt\) .
Значит, итоговый ответ: \((n-1) + (m-1) — (t-1)\) .
Кстати, когда \(НОД(a, b) = 1\) , говорят, что \(a\) и \(b\) взаимно просты.
Алгоритм Евклида
Осталось придумать, как искать НОД и НОК. Понятно, что их можно искать перебором, но мы хотим хороший быстрый способ.
Давайте для начала научимся искать \(НОД(a, b)\) .
Мы можем воспользоваться следующим равенством: \[НОД(a, b) = НОД(a, b — a), b > a\]
Оно доказывается очень просто: надо заметить, что множества общих делителей у пар \((a, b)\) и \((a, b — a)\) совпадают. Почему? Потому что если \(a\) и \(b\) делятся на \(x\) , то и \(b-a\) делится на \(x\) . И наоборот, если \(a\) и \(b-a\) делятся на \(x\) , то и \(b\) делится на \(x\) . Раз множства общих делитей совпадают, то и максимальный делитель совпадает.
Из этого равенства сразу следует следующее равенство: \[НОД(a, b) = НОД(a, b \operatorname <\%>a), b > a\]
(так как \(НОД(a, b) = НОД(a, b — a) = НОД(a, b — 2a) = НОД(a, b — 3a) = \ldots = НОД(a, b \operatorname <\%>a)\) )
Это равенство дает идею следующего рекурсивного алгоритма:
\[НОД(a, b) = НОД(b \operatorname <\%>a, a) = НОД(a \operatorname <\%>\, (b \operatorname <\%>a), b \operatorname <\%>a) = \ldots\]
Например: \[НОД(93, 36) = \] \[= НОД(36, 93\space\operatorname<\%>36) = НОД(36, 21) = \] \[= НОД(21, 15) = \] \[= НОД(15, 6) = \] \[= НОД(6, 3) = \] \[= НОД(3, 0) = 3\]
Задание:
Примените алгоритм Евклида и найдите НОД чисел: * 1 и 500000 * 10, 20 * 18, 60 * 55, 34 * 100, 250
По-английски наибольший общий делитель — greatest common divisor. Поэтому вместо НОД будем в коде писать gcd.
Вообще, в C++ такая функция уже есть в компиляторе g++ — называется __gcd . Если у вас не Visual Studio, то, скорее всего, у вас g++ . Вообще, там много всего интересного.
А за сколько оно вообще работает?
Задание
Докажите, что алгоритм Евклида для чисел \(N\) , \(M\) работает за \(O(\log(N+M))\) .
Кстати, интересный факт: самыми плохими входными данными для алгоритма Евклида являются числа Фибоначчи. Именно там и достигается логарифм.
Как выразить НОК через НОД
По этой формуле можно легко найти НОК двух чисел через их произведение и НОД. Почему она верна?
Посмотрим на разложения на простые множители чисел a, b, НОК(a, b), НОД(a, b).
\[ a = p_1^
Из определений НОД и НОК следует, что их факторизации выглядят так: \[ НОД(a, b) = p_1^
Как посчитать НОД/НОК от более чем 2 чисел
Для того, чтобы искать НОД или НОК у более чем двух чисел, достаточно считать их по цепочке:
Почему это верно?
Ну просто множество общих делителей \(a\) и \(b\) совпадает с множеством делителей \(НОД(a, b)\) . Из этого следует, что и множество общих делителей \(a\) , \(b\) и еще каких-то чисел совпадает с множеством общих делителей \(НОД(a, b)\) и этих же чисел. И раз совпадают множества общих делителей, то и наибольший из них совпадает.
С НОК то же самое, только фразу “множество общих делителей” надо заменить на “множество общих кратных”.
Задание
Решите задачи F, G, H, I из этого контеста:
Расширенный алгоритм Евклида*
Очень важным для математики свойством наибольшего общего делителя является следующий факт:
Для любых целых \(a, b\) найдутся такие целые \(x, y\) , что \(ax + by = d\) , где \(d = \gcd(a, b)\) .
Из этого следует, что существует решение в целых числах, например, у таких уравнений: * \(8x + 6y = 2\) * \(4x — 5y = 1\) * \(116x + 44y = 4\) * \(3x + 11y = -1\)
Мы сейчас не только докажем, что решения у таких уравнений существуют, но и приведем быстрый алгоритм нахождения этих решений. Здесь нам вновь пригодится алгоритм Евклида.
Рассмотрим один шаг алгоритма Евклида, преобразующий пару \((a, b)\) в пару \((b, a \operatorname <\%>b)\) . Обозначим \(r = a \operatorname <\%>b\) , то есть запишем деление с остатком в виде \(a = bq + r\) .
Предположим, что у нас есть решение данного уравнения для чисел \(b\) и \(r\) (их наибольший общий делитель, как известно, тоже равен \(d\) ): \[bx_0 + ry_0 = d\]
Теперь сделаем в этом выражении замену \(r = a — bq\) :
\[bx_0 + ry_0 = bx_0 + (a — bq)y_0 = ay_0 + b(x_0 — qy_0)\]
Tаким образом, можно взять \(x = y_0\) , а \(y = (x_0 — qy_0) = (x_0 — (a \operatorname b)y_0)\) (здесь \(/\) обозначает целочисленное деление).
В конце алгоритма Евклида мы всегда получаем пару \((d, 0)\) . Для нее решение требуемого уравнения легко подбирается — \(d * 1 + 0 * 0 = d\) . Теперь, используя вышесказанное, мы можем идти обратно, при вычислении заменяя пару \((x, y)\) (решение для чисел \(b\) и \(a \operatorname <\%>b\) ) на пару \((y, x — (a / b)y)\) (решение для чисел \(a\) и \(b\) ).
Это удобно реализовывать рекурсивно:
Но также полезно и посмотреть, как будет работать расширенный алгоритм Евклида и на каком-нибудь конкретном примере. Пусть мы, например, хотим найти целочисленное решение такого уравнения: \[116x + 44y = 4\] \[(2\times44+28)x + 44y = 4\] \[44(2x+y) + 28x = 4\] \[44x_0 + 28y_0 = 4\] Следовательно, \[x = y_0, y = x_0 — 2y_0\] Будем повторять такой шаг несколько раз, получим такие уравнения: \[116x + 44y = 4\] \[44x_0 + 28y_0 = 4, x = y_0, y = x_0 — 2y_0\] \[28x_1 + 16y_1 = 4, x_0 = y_1, y_0 = x_1 — y_1\] \[16x_2 + 12y_2 = 4, x_1 = y_2, y_1 = x_2 — y_2\] \[12x_3 + 4y_3 = 4, x_2 = y_3, y_2 = x_3 — y_3\] \[4x_4 + 0y_4 = 4, x_3 = y_4, y_3 = x_4 — 3 y_4\] А теперь свернем обратно: \[x_4 = 1, y_4 = 0\] \[x_3 = 0, y_3 =1\] \[x_2 = 1, y_2 =-1\] \[x_1 = -1, y_1 =2\] \[x_0 = 2, y_0 =-3\] \[x = -3, y =8\]
Действительно, \(116\times(-3) + 44\times8 = 4\)
Задание
Решите задачу J из этого контеста:
Операции по модулю
Выражение \(a \equiv b \pmod m\) означает, что остатки от деления \(a\) на \(m\) и \(b\) на \(m\) равны. Это выражение читается как « \(a\) сравнимо \(b\) по модулю \(m\) ».
Еще это можно опрделить так: \(a\) сравнимо c \(b\) по модулю \(m\) , если \((a — b)\) делится на \(m\) .
Все целые числа можно разделить на классы эквивалентности — два числа лежат в одном классе, если они сравнимы по модулю \(m\) . Говорят, что мы работаем в «кольце остатков по модулю \(m\) », и в нем ровно \(m\) элементов: \(0, 1, 2, \cdots, m-1\) .
Сложение, вычитение и умножение по модулю определяются довольно интуитивно — нужно выполнить соответствующую операцию и взять остаток от деления.
С делением намного сложнее — поделить и взять по модулю не работает. Об этом подробнее поговорим чуть дальше.
Задание
Посчитайте: * \(2 + 3 \pmod 5\) * \(2 * 3 \pmod 5\) * \(2 ^ 3 \pmod 5\) * \(2 — 4 \pmod 5\) * \(5 + 5 \pmod 6\) * \(2 * 3 \pmod 6\) * \(3 * 3 \pmod 6\)
Для умножения (в C++) нужно ещё учитывать следующий факт: при переполнении типа всё ломается (разве что если вы используете в качестве модуля степень двойки).
- int вмещает до \(2^ <31>— 1 \approx 2 \cdot 10^9\) .
- long long вмещает до \(2^ <63>— 1 \approx 8 \cdot 10^<18>\) .
- long long long в плюсах нет, при попытке заиспользовать выдает ошибку long long long is too long .
- Под некоторыми компиляторами и архитектурами доступен int128 , но не везде и не все функции его поддерживают (например, его нельзя вывести обычными методами).
Зачем нужно считать ответ по модулю
Очень часто в задаче нужно научиться считать число, которое в худшем случае гораздо больше, чем \(10^<18>\) . Тогда, чтобы не заставлять вас писать длинную арифметику, автор задачи часто просит найти ответ по модулю большого числа, обычно \(10^9 + 7\)
Кстати, вместо того, чтобы писать \(1000000007\) удобно просто написать \(1e9 + 7\) . \(1e9\) означает \(1 \times 10^9\)
Быстрое возведение в степень
Задача: > Даны натуральные числа \(a, b, c < 10^9\) . Найдите \(a^b\) (mod \(c\) ).
Мы хотим научиться возводить число в большую степень быстро, не просто умножая \(a\) на себя \(b\) раз. Требование на модуль здесь дано только для того, чтобы иметь возможность проверить правильность алгоритма для чисел, которые не влезают в int и long long.
Сам алгоритм довольно простой и рекурсивный, постарайтесь его придумать, решая вот такие примеры (прямо решать необязательно, но можно придумать, как посчитать значение этих чисел очень быстро):
- \(3^2\)
- \(3^4\)
- \(3^8\)
- \(3^<16>\)
- \(3^<32>\)
- \(3^<33>\)
- \(3^<66>\)
- \(3^<132>\)
- \(3^<133>\)
- \(3^<266>\)
- \(3^<532>\)
- \(3^<533>\)
- \(3^<1066>\)
Да, здесь специально приведена такая последовательность, в которой каждое следующее число легко считается через предыдущее: его либо нужно умножить на \(a=3\) , либо возвести в квадрат. Так и получается рекурсивный алгоритм:
- \(a^0 = 1\)
- \(a^<2k>=(a^
)^2\) - \(a^<2k+1>=a^<2k>\times a\)
Нужно только после каждой операции делать mod: * \(a^0 \pmod c = 1\) * \(a^ <2k>\pmod c = (a^
Этот алгоритм называется быстрое возведение в степень. Он имеет много применений: * в криптографии очень часто надо возводить число в большую степень по модулю * используется для деления по простому модулю (см. далее) * можно быстро перемножать не только числа, но еще и матрицы (используется для динамики, например)
Асимптотика этого алгоритма, очевидно, \(O(\log c)\) — за каждые две итерации число уменьшается хотя бы в 2 раза.
Задание
Решите задачу K из этого контеста:
Задание
Решите как можно больше задач из практического контеста:
Деление по модулю*
Давайте все-таки научимся не только умножать, но и делить по простому модулю. Вот только что это значит?
\(a / b\) = \(a \times b^<-1>\) , где \(b^<-1>\) — это обратный элемент к \(b\) .
Определение: \(b^<-1>\) — это такое число, что \(bb^ <-1>= 1\)
Утверждение: в кольце остатков по простому модулю \(p\) у каждого остатка (кроме 0) существует ровно один обратный элемент.
Например, обратный к \(2\) по модулю \(5\) это \(3\) ( \(2 \times 3 = 1 \pmod 5\) ))
Задание
Найдите обратный элемент к: * числу \(3\) по модулю \(5\) * числу \(3\) по модулю \(7\) * числу \(1\) по модулю \(7\) * числу \(2\) по модулю \(3\) * числу \(9\) по модулю \(31\)
Давайте докажем это утверждение: надо заметить, что если каждый ненулевой остаток \(1, 2, \ldots, (p-1)\) умножить на ненулевой остаток \(a\) , то получатся числа \(a, 2a, \ldots, (p-1)a\) — и они все разные! Они разные, потому что если \(xa = ya\) , то \((x-y)a = 0\) , а значит \((x — y) a\) делится на \(p\) , \(a\) — ненулевой остаток, а значит \(x = y\) , и это не разные числа. И из того, что все числа получились разными, это все ненулевые, и их столько же, следует, что это ровно тот же набор чисел, просто в другом порядке!
Из этого следует, что среди этих чисел есть \(1\) , причем ровно один раз. А значит существует ровно один обратный элемент \(a^<-1>\) . Доказательство закончено.
Это здорово, но этот обратный элемент еще хочется быстро находить. Быстрее, чем за \(O(p)\) .
Есть несколько способов это сделать.
Через малую теорему Ферма
Малая теорема Ферма: > \(a^
Доказательство: В предыдущем пункте мы выяснили, что множества чисел \(1, 2, \ldots, (p-1)\) и \(a, 2a, \ldots, (p-1)a\) совпадают. Из этого следует, что их произведения тоже совпадают по модулю: \((p-1)! = a^
\((p-1)!\neq 0 \pmod p\) а значит на него можно поделить (это мы кстати только в предыдущем пункте доказали, поделить на число — значит умножить на обратный к нему, который существует).
А значит, \(a^
= 1 \pmod p\) .
Как это применить Осталось заметить, что из малой теоремы Ферма сразу следует, что \(a^
Обобщение У малой теоремы Ферма есть обобщение для составных \(p\) :
Теорема Эйлера: > \(a^ <\varphi(p)>= 1 \pmod p\) , \(a\) — взаимно просто с \(p\) , а \(\varphi(p)\) — это функция Эйлера (количество чисел, меньших \(p\) и взаимно простых с \(p\) ).
Доказывается теорема очень похоже, только вместо ненулевых остатков \(1, 2, \ldots, p-1\) нужно брать остатки, взаимно простые с \(p\) . Их как раз не \(p-1\) , а \(\varphi(p)\) .
Для нахождения обратного по этой теореме достаточно посчитать функцию Эйлера \(\varphi(p)\) и найти \(a^ <-1>= a^<\varphi(p) - 1>\) .
Но с этим возникают большие проблемы: посчитать функцию Эйлера сложно. Более того, на предполагаемой невозможности быстро ее посчитать построены некоторые криптографические алгоритм типа RSA. Поэтому быстро делить по составному модулю этим способом не получится.
Через расширенный алгоритм Евклида
Этим способом легко получится делить по любому модулю! Рекомендую.
Пусть мы хотим найти \(a^ <-1>\pmod p\) , \(a\) и \(p\) взаимно простые (а иначе обратного и не будет существовать).
Давайте найдем корни уравнения
Они есть и находятся расширенным алгоритмом Евклида за \(O(\log p)\) , так как \(НОД(a, p) = 1\) , ведь они взаимно простые.
Тогда если взять остаток по модулю \(p\) :
А значит, найденный \(x\) и будет обратным элементом к \(a\) .
То есть надо просто найти \(x\) из решения того уравнения по модулю \(p\) . Можно брать по модулю прямо походу решения уравнения, чтобы случайно не переполниться.
Научный форум dxdy
Если Вы хотите задать новый вопрос, то не дописывайте его в существующую тему, а создайте новую в корневом разделе "Помогите решить/разобраться (М)".
Если Вы зададите новый вопрос в существующей теме, то в случае нарушения оформления или других правил форума Ваше сообщение и все ответы на него могут быть удалены без предупреждения.
Не ищите на этом форуме халяву , правила запрещают участникам публиковать готовые решения стандартных учебных задач. Автор вопроса обязан привести свои попытки решения и указать конкретные затруднения.
Обязательно просмотрите тему Правила данного раздела, иначе Ваша тема может быть удалена или перемещена в Карантин, а Вы так и не узнаете, почему.
Существует ли формула для определения кол-ва простых чисел?
формулы не встречал, но при не очень больших N , можно применить решето эратосфена! конечно не очень удобно.
— Вс авг 16, 2009 02:04:08 —
формулы не встречал, но при не очень больших N , можно применить решето эратосфена! конечно не очень удобно.
Если через  , непревышающих
, непревышающих  , то количество простых чисел, непревышающих
, то количество простых чисел, непревышающих 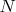 , можно точно подсчитать по бесконечной формуле:
, можно точно подсчитать по бесконечной формуле:
 — простые числа 2, 3, 5, 7. непревышающие
— простые числа 2, 3, 5, 7. непревышающие  равно
равно  , это будет «формулой» или нет?
, это будет «формулой» или нет?
Просто я пытался вывести формулу и она у меня получилась. Стал искать подобную формулу в интернете, нашёл различные формулы, но точно такую же, как и у меня не нашёл.
Вот она:![$\pi(N) = [N]-[\dfrac<N-2><2>]-[\dfrac<N-3><2*3>]-[\dfrac<N-5><2*3*5>]-[\dfrac<N-7><2*3*5*7>]. $» /></p>
<p>Где <img decoding=](https://dxdy-03.korotkov.co.uk/f/a/2/5/a25ecf065e2109b17038257fac74c52082.png) — это количество простых чисел от 1 до N.
— это количество простых чисел от 1 до N.
Что это за формула? Наверняка, её вывели лет 150-200 назад. Дайте, пожалуйста, ссылки на сайты, где она упомянута.
Можно ли считать эту формулу тривиальной?
И ещё вопрос, как поставить знак праймориал «#» в коде math?
— Пн авг 17, 2009 16:42:24 —
Батороев
Мне кажется, что формула, написанная мной выше, куда более проста и эффективна,чем упомянутая вами Или же я всё-таки ошибаюсь?
Профессор Снэйп
«Бесконечная формула» — это я сказал детским, «школьным» языком, дабы сам в этом году только окончил 11 класс
Вот она:— это количество простых чисел от 1 до N.
Что это за формула? Наверняка, её вывели лет 150-200 назад. Дайте, пожалуйста, ссылки на сайты, где она упомянута.
В очень старом «Кванте»(60е-70е гг)была такая:![$\pi(N) = N-[\dfrac<N><2>]-[\dfrac<N><3>]+[\dfrac<N><2*3>]-[\dfrac<N><5>]+[\dfrac<N><2*5>]+[\dfrac<N><3*5>]-[\dfrac<N><2*3*5>]. $» /><br />Только статья даже не на тему»К-во простых» а про «Формулу включений и исключений»<br />
Просто я пытался вывести формулу и она у меня получилась. Стал искать подобную формулу в интернете, нашёл различные формулы, но точно такую же, как и у меня не нашёл.<br />Вот она:<img decoding=](https://dxdy-01.korotkov.co.uk/f/8/6/9/869c9cdcab23549a9841836d8eea172182.png) Ваша формула даст
Ваша формула даст 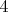 (
(  ), если я правильно понял Ваши обозначения, конечно.
), если я правильно понял Ваши обозначения, конечно.

P.P.S. То есть у Вас в знаменателе праймориал? А для его вычисления Вам же нужно будет знать те же N простых чисел, что является более сложной задачей, разве нет?
Формулу необходимо подкорректировать.
Правильнее будет так:![$\pi(N) = [N]-[\dfrac<N-2><2\#>]-[\dfrac<N-3><3\#>]-[\dfrac<N-5><5\#>]-[\dfrac<N-7><7\#>]. -1$» /></p>
<p>То есть в конце необходимо вычесть 1, так как 1 — это не простое число. Поэтому в конце в формулу нужно добавить «-1». <br />Обозначения:<br /> <img decoding=](https://dxdy-01.korotkov.co.uk/f/c/c/0/cc046ea1e798038dcb667b579fa8c5fa82.png) — количество простых чисел от 1 до N;
— количество простых чисел от 1 до N;
![$[x]$](https://dxdy-04.korotkov.co.uk/f/7/e/1/7e1c4a3a07c941625c2f20c594cb9f7c82.png) — целая часть числа
— целая часть числа  ;
;
 — праймориал, то есть произведение простых чисел от 1 до
— праймориал, то есть произведение простых чисел от 1 до 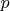 (
( )
)
Важное замечание.
— это именно целая часть числа , а не округление числа .
То есть ![$[\dfrac<1><2>]=0;$» /> <img decoding=](https://dxdy-02.korotkov.co.uk/f/1/e/6/1e6e31e0f3abd31103d3fda0f6fd510482.png) — наибольшее простое, не превышающее
— наибольшее простое, не превышающее  (если речь идет о точной формуле расчета количества простых).
(если речь идет о точной формуле расчета количества простых).
Заодно спрошу, какой ответ получается по Вашей формуле для  ?
?
Я тут проверил, формула начинает превышать правильное количество простых чисел при  , и это расхождение постепенно увеличивается, при расхождение составляет
, и это расхождение постепенно увеличивается, при расхождение составляет 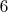 , при
, при  —
—  .
.
Cкачки происходят при  . Видимо, Вы в доказательстве где-то не учитываете степени простых чисел и произведения простых чисел, идущих не подряд.
. Видимо, Вы в доказательстве где-то не учитываете степени простых чисел и произведения простых чисел, идущих не подряд.