Скачать защищенный Pdf
Как я могу скачать защищенный Pdf (просмотр разрешен, загрузка нет)? Ссылка на PDF-файл следующая:
3 ответа 3
Я предполагаю, что у вас есть разрешение и вы не нарушаете никаких законов.
Ссылка, которую вы хотите
Тем не менее, вы не должны получить к нему доступ, если у вас нет разрешения.
Способ найти это — использовать браузер с инструментами разработки (большинство так и делают). В этом случае в Chrome нажмите F12
Затем на вкладке Elements вы можете найти URL-адрес ссылки, развернув элементы HTML, пока не найдете соответствующий раздел.
Обновить
Другой способ — отключить просмотрщик PDF в браузере (это вряд ли сработает для веб-сайта в вашем вопросе, но может работать для других веб-сайтов). Это означает, что при запросе PDF в браузере нет инструмента / метода для открытия файла, и поэтому он будет предоставлять его для загрузки.
Как скачать pdf книгу с браузера?

Для хрома
F12 дальше по картинке
- Вконтакте

- Вконтакте

скриптом можно скачать.
через JQuery загрузить контент всей книги на одну страницу.
возможно потребуется iframe чтобы выбрать только нужные блоки.
Принудительное скачивание файла вместо просмотра в браузере

Рекомендуем почитать: 
Xakep #292. Flipper Zero
Современные браузеры всё чаще берут на себя лишнюю работу, открывая медиафайлы и .PDF во встроенном проигрывателе вместо того, чтобы просто сохранить их на диск. Результат может быть плачевным. Попытка открыть большой PDF в браузере может привести к сбою — браузер вылетит с ошибкой.
Браузеры становятся умнее, и это осложняет жизнь пользователям. Если раньше они щёлкали по файлу не задумываясь, то теперь рискуют встретить PDF, поэтому для страховки нажимают правой кнопкой и выбирают в меню «Сохранить как. ». Это неудобно, потому что приходится делать лишние нажатия.
К счастью, есть довольно простой способ решить эту проблему на стороне сервера, пишет шведский веб-разработчик Джонатан Сварден (Jonathan Svärdén)
Достаточно использовать команду вида:
<a href=»https://xakep.ru/wp-content/uploads/post/60499/hugemothereffinpdf.pdf» download>Скачать файл</a>
В этом случае по нажатию левой кнопки браузер автоматически начнёт скачивание файла.
Можно даже сменить атрибуты файла, например, изменить его название.
<a href=»https://xakep.ru/wp-content/uploads/post/60499/9fd-f32ff322.pdf» download=»invoice»>Скачать файл</a>
В этом случае файл 9fd-f32ff322.pdf будет сохранён как invoice.pdf .
Некоторые пользователи могут предпочесть открытие файла в браузере, так что можно предоставить им выбор.
Как скачать pdf с сайта если можно только читать

Добрый день! Уважаемые читатели и гости одного из крупнейших IT блогов в России Pyatilistnik.org. В прошлый раз мы с вами научились запрещать автовоспроизведение видео в браузере Chrome, так как все понимают на сколько это может раздражать, и может быть несвоевременно, на Youtube для этого была отдельная кнопка, а вот в плане всего интернета пришлось выбирать любой из понравившихся методов. Сегодня я хочу вас научить скачивать защищенный PDF файл с Google Drive (Google Диска). Под защищенным понимается, что у вас есть возможность читать его с правами только на чтение и скачать или сохранить себе на Google диск вы его не можете. Но как выяснилось все очень просто решается и уже все придумано за нас.
Постановка задачи
И так у нас с вами есть ссылка на PDF файл, который располагается на облачном хранилище Google Диск, вот пример ссылки:
Как вы можете обратить внимание, это книга «Дешифровка критской письменности (Пеластско-лезгинский язык)». Все, что вы можете сделать это вызвать панель с меню и выбрать свойства документа.
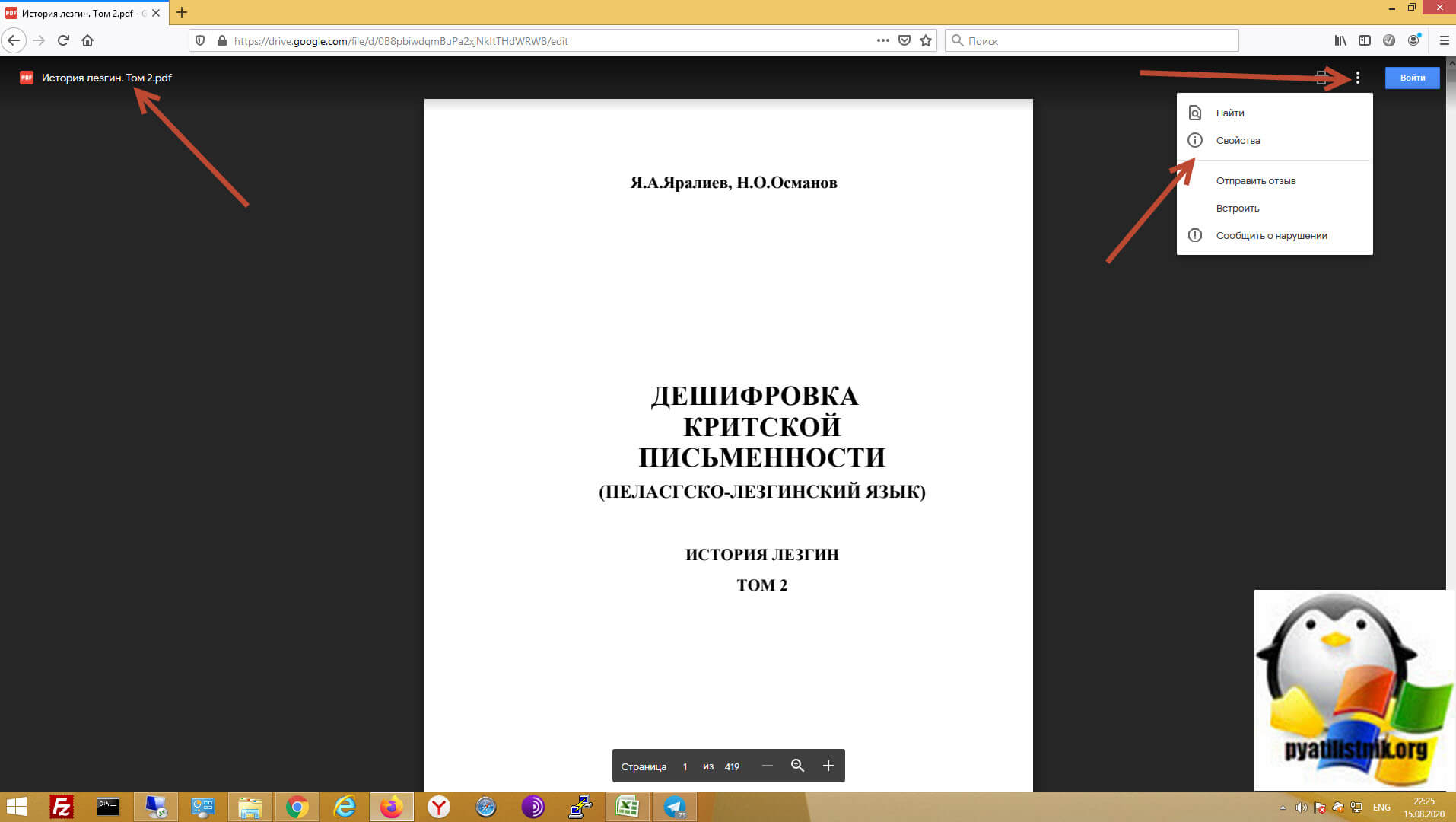
Как видно тип документа PDF, и вы максимум можете его просматривать, так как владелец просто запретил скачивать файл. Мы с вами научимся это обходить, так как мы уже с легкостью умеем скачивать ограниченное видео с Google диска, методология будет похожа, но не полностью.
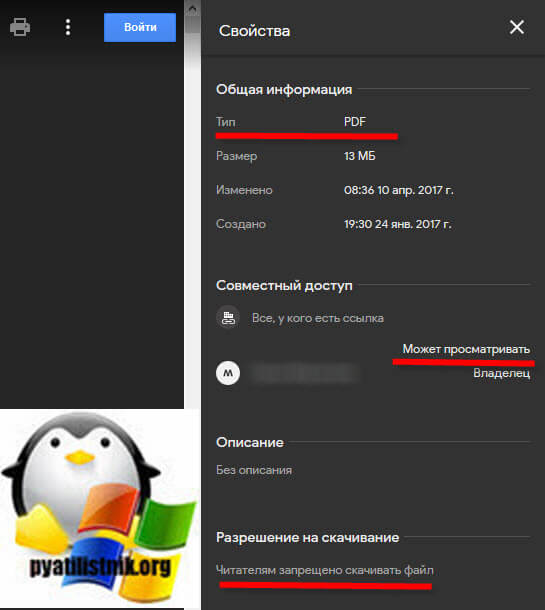
Суть метода по скачиванию ограниченного PDF файла на Гугл диске
Как оказалось Гугл диск хранит все PDF файлы в виде отдельных файлов картинок и когда пользователь начинает просматривать документ, его просто собирает в веб интерфейсе, на уровне файлового хранилище, это просто картинки. Проверить это легко, вы должны открыть защищенный PDF документ, вызвать режим разработчика, через клавишу «F11» и перейдя на вкладку «Network«, где после чего нужно обновить страницу с файлом. Делается это через клавишу «F5«. Теперь если вы зайдете в раздел «XHR», то увидите там кучу ссылок типа «xhr». Открыв любую из них вас перекинет на страницу, которую вы уже успели промотать в книжке.
Теперь, что мы делаем поэтапно:
- Откройте ваш защищенный PDF документ, я покажу, как это делается в Mozilla Firefox и Google Chrome
- Перейдите в режим разработчика
- Нажмите клавишу F5 для обновления страницы
- Полностью пролистайте весь PDF документ, все страницы. Так как они должны попасть в локальный кэш вашего браузера
- Выполните специальный код, который объединит все страницы в кэше в единый PDF файл и позволит его загрузить на компьютер
Текст кода для скачивания защищенного PDF файла с Google Диска
Как загрузить ограниченный PDF из Google Drive через Mozilla
- Откройте ваш защищенный PDF документ, я покажу, как это делается в Mozilla Firefox
- Перейдите в режим разработчика. В Mozilla Firefox это делается, через одновременное нажатие клавиш CTRL+Shift+I или вызов соответствующего меню «Веб разработка — Инструменты разработчика«

- Далее нажмите клавишу F5 и обновите страницу
- Полностью, по порядку пролистайте все страницы данного PDF файла
Перейдите на вкладку «Консоль«. Именно сюда нам нужно будет вставлять код, но по умолчанию политика безопасности Mozilla Firefox запрещает выполнение неподписанных скриптов. Чтобы это обойти вам нужно, это разрешить.
Вам нужно ввести «разрешить вставку» и нажать Enter.
Теперь вставляем код. Для его выполнения нажмите одновременно CTRL и Enter.
Начинается процесс скачивания картинок и объединение их в единый PDF-файл.
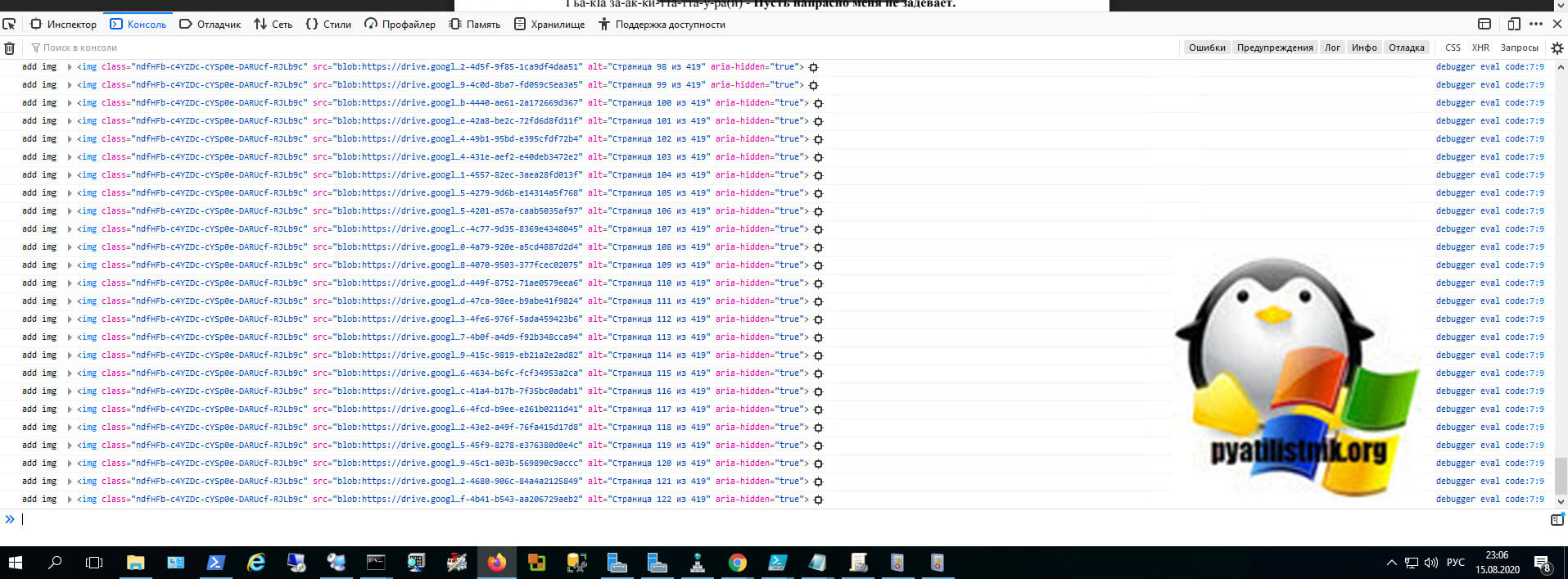
Через некоторое время браузер вам предложит сохранить DPF файл к вам на компьютер.
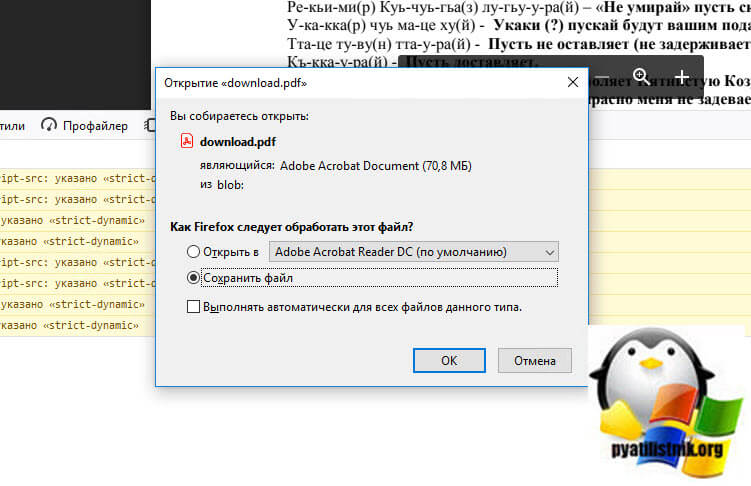
Как видите я успешно загрузил ограниченный владельцем PDF документ, все прекрасно работает.
Как загрузить ограниченный PDF из Google Drive через Chrome
- Откройте ваш защищенный PDF документ, я покажу, как это делается в Google Chrome
- Перейдите в режим разработчика. В Google Chrome это делается, через нажатие клавиши F11 или вызов соответствующего меню «Дополнительные — Инструменты разработчика (CTRL+SHOFT+I)«
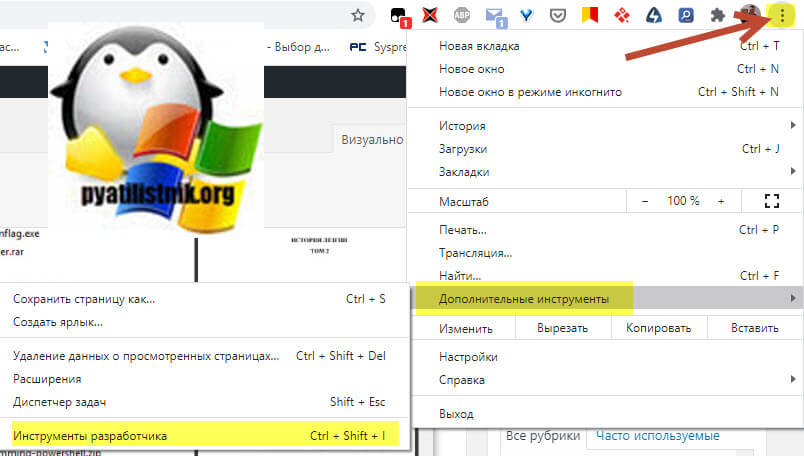
- Обязательно выберите режим iPad Pro для максимального разрешения и выставите масштаб 100%, в противном случае вы скачаете документ не с очень хорошим качеством. Далее нажмите клавишу F5 и обновите страницу
- Полностью, по порядку пролистайте все страницы данного PDF файла
- Далее перейдите на вкладку «Console»
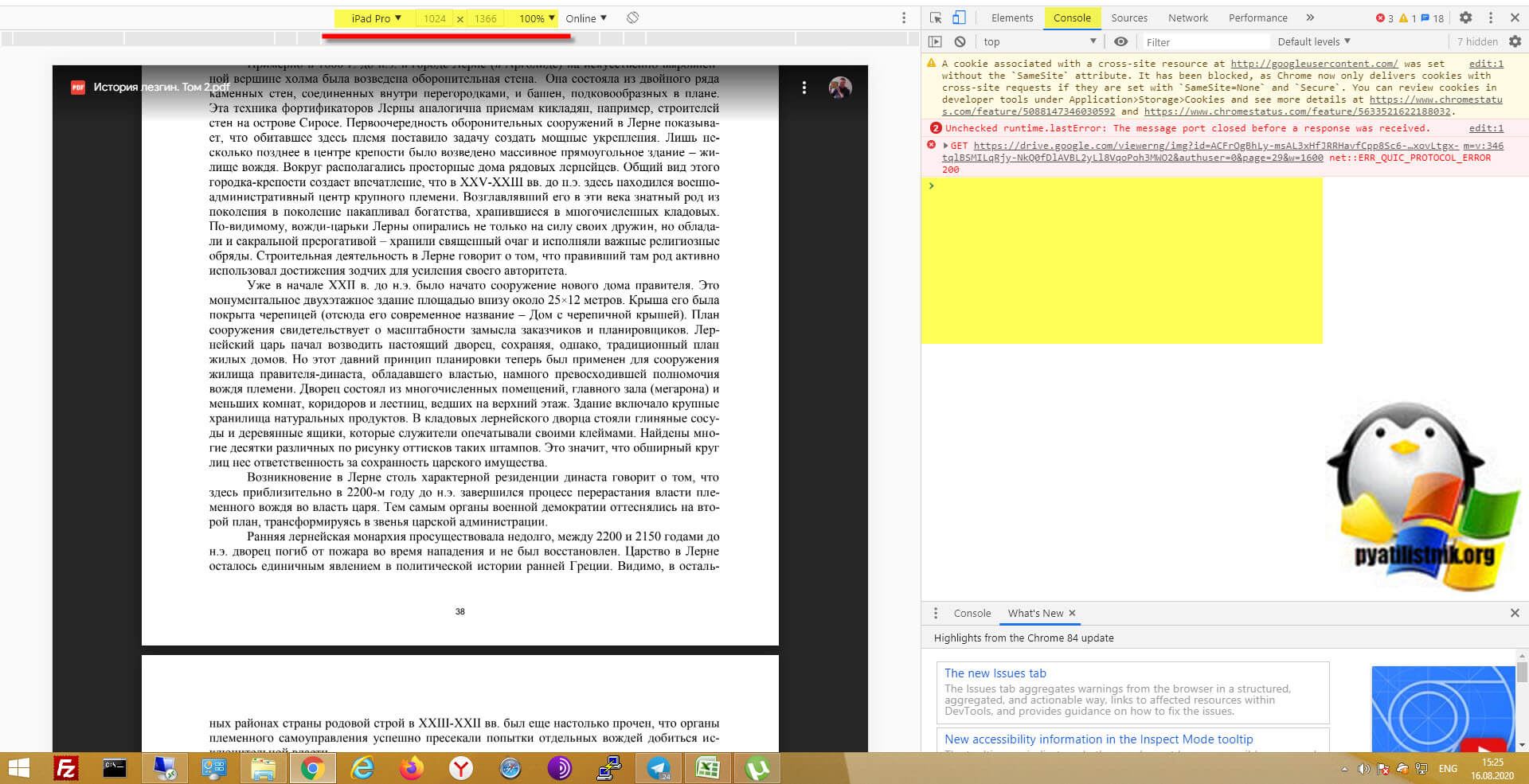
Вам необходимо вставить представленный выше код для скачивания ограниченного PDF файла, после чего просто нажать Enter.
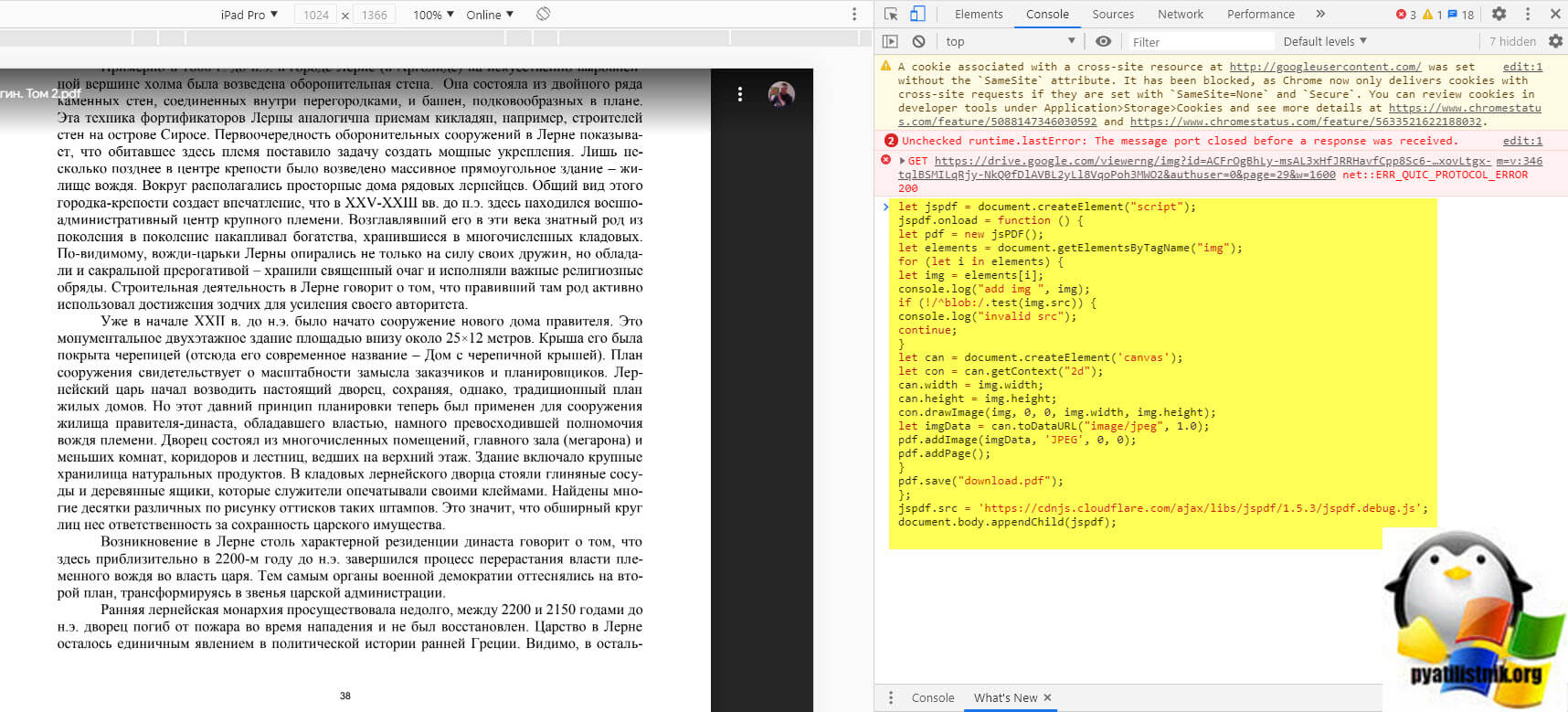
Начнется процесс сборки вашего PDF документа.
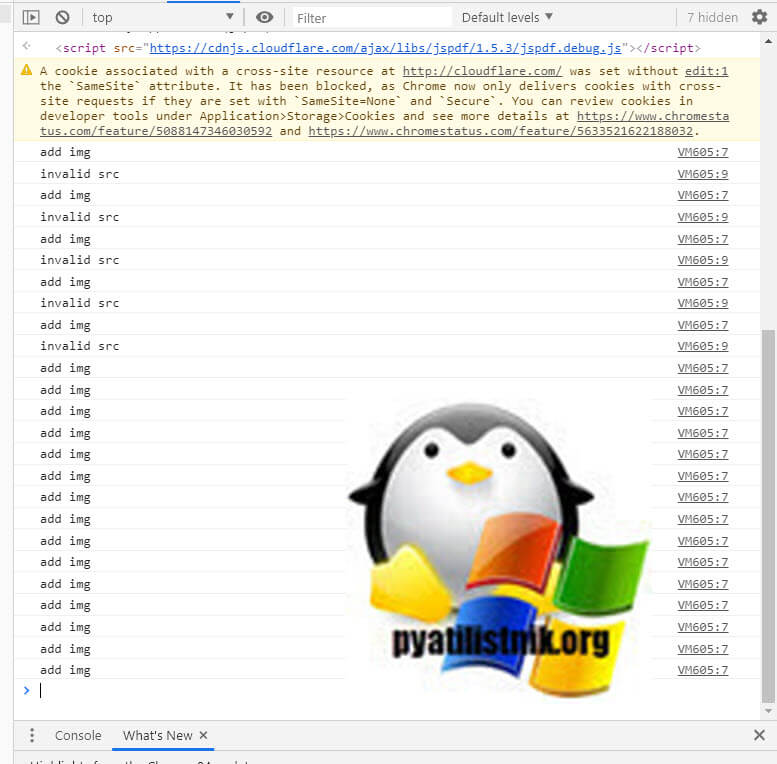
Через пару мгновений вы получите нужный вам PDF документ.
Что делать если не работает в Chrome
Тут я посоветую использовать Mozilla или же найдите версию Chrome до 100-110, главное у них отключить обновление, как вариант можно сделать из них и портативные версии.
На этом у меня все, скачивание ограниченных файлов с гугл диска через другие браузеры очень похоже, поэтому я не буду их описывать. С вами был Иван Семин, автор и создатель IT портала Pyatilistnik.org.
Популярные Похожие записи:
71 Responses to Как скачать защищенный PDF файл с Google Диска, за минуту
Очень хочется узнать как таким образом можно скачать презентацию а не pdf документ? В презентации есть много картинок+видео и текст
А это вызов, с вас пример ссылки
Спасибо, очень круто, только не много качество хуже становиться
Просто шик, спасибо за подробную инструкцию! Очень пригодилось и заняло несколько минут. Качество на уровне.
все сделала по инструкции, файл сохраняется в плохом качестве в левом углу на листе, что то с кодом не так?
Увеличьте размер документа, поставьте 100-120%
Да ты неимоверно крут! Готов перечислить даже малость денег
Если хотите задонатить, то на странице об авторе есть реквизиты!
А ты хороший человек. )))
Хочется скачать вот такой документ
_ttps://docs.google.com/spreadsheets/u/0/d/1XMyVTv5hb9-nJZhHmHASHEyFDfpDneSfqu—mSlqJcU/htmlview#
Это гугл-таблицы. Возможно ли?
Нет не получиться, тут нет прав на это
Когда файл сохраняется, по низу обрезается 30% информации, по тексту это 4 строчки. От чего метод становится не рабочим, т.к. суть теряется на первом листе.
у меня такого нет, книжка скачивается на ура
У меня не получается — я вижу XHR — отдельные страницы, образуется
download.pdf — но он пустой — 1 страница пустая
Google Chrome ubuntu 20.04
Да скрипт запускается в Tampermonkey — привязанного к веб странице с книжкой в момент refresh.
add img 0
VM1068 userscript.html:24 invalid src
VM1068 userscript.html:22 add img ƒ item() < [native code] >
VM1068 userscript.html:24 invalid src
VM1068 userscript.html:22 add img ƒ namedItem() < [native code] >
VM1068 userscript.html:24
add img 0
VM943 userscript.html:24 invalid src
VM943 userscript.html:22 add img ƒ item() < [native code] >
VM943 userscript.html:24 invalid src
VM943 userscript.html:22 add img ƒ namedItem() < [native code] >
VM943 userscript.html:24 invalid src
Navigated to _ttps://drive.google.com/file/d/0B5yKZ3bWyNe6SHB2T1BHYVdsT1k/view
VM1027 userscript.html:22 add img 0
VM1027 userscript.html:24
Получилось — но после некоторых усилий. На ubuntu 20.04 — у меня не работает из GOOGLE CHROME но работает из CHROMIUM и MOZILLA. Скрипт надо каждый раз руками копировать открыв инструменты разработчика и закладку консоль. Там нет надписи paste если правую кнопку мыши жать. Надо скопировать просто скрипт левой кнопкой мыши и нажать на среднюю — и RETURN. Ну конечно предварителино освежив, пролистав, перед этим настроив размер ctrl++. (извиняюсь за занудство).
Гениально просто!
И работает! Спасибо.
Виноват! Адрес страницы не гугл диск.
Доброго времени суток. Вопрос : а есть ли скрипт , чтобы проделать ту же операцию , только с дропбокс … тоже стоит запрет на скачивание и запрет на печать… а страниц много 150+ (я их вижу по отдельности и даже номера есть… но как их в кучку собрать и автоматически ? )
Подставлял ваш скрипт — выдает ошибку : мол дропбоксом запрещено использовать скрипты или чтото такое.
Refused to load the script ‘(тут ваш скрипт) ‘ because it violates the following Content Security Policy directive: «script-src ‘unsafe-eval'(и далее ссылки видимо на правила сервиса)
Для стандартной ориентации страниц работает супер! А для альбомной не получается ((( — обрезает.
Добрый день. А как excel файл скачать?
Тоже вопрос какую функцию в код добавить, что бы альбомная ориентация получилась пдф при скачивании
для альбомной ориентации ребят:
pdf.addPage(», ‘landscape’);
Вот это нужно вставить вместо
pdf.addPage();
Спасибо большое очень помог
не получается альбомный лист ввести pdf.addPage(», ‘landscape’); ошибка((
если вводить как вы писали(с книжным вариантом) все получается.
Спасибо
Спасибо за статью! Очень полезно.
Есть еще вызов для Вас.
А можно сделать тоже самое, но для произвольного сайта? Чтобы скрипт сохранял все закешированные картинки при том, что они закачиваются не в виде BLOB, а в виде обычных файлов. Например, запускаем скрипт через консоль для новостного сайта и получаем все картинки со страницы. Сейчас скрипт работает только с гугл документами, а если запустить его на другом сайте, то сформируется пустой документ.
И второе, тоже очень важное. Можно картинки не собирать в единый PDF, а сохранить в исходном виде (JPG) отдельным файлами и без запроса на сохранение каждого файла?
Поясню для чего это нужно. Есть защищенный онлайн просмотрщик документов, в котором сделано все, чтобы пользователь не мог скачать просматриваемый материал. Смотреть можно, скачать нет. Но, по сути, этот сервис работает точно также, как и сервис гугла из Вашей статьи. При каждом нажатии на кнопку “следующая страница”, подгружается отдельная картинка и используется кеширование. Названия картинок и адреса меняются при каждой загрузке и состоят из сотни символов. Угадать адрес картинки не получается. Можно уже загруженные картинки скачивать из кэша. Вручную я из кэша картинки смог вытащить. Но нужно как-то автоматизировать процесс. В одном документе может быть 1000 страниц. А таких документов может быть много. Сами скачанные картинки удобней хранить отдельными файлами, чтобы их можно было переименовывать, пересылать, раскладывать по папочкам итп. При этом важно сохранить очерёдность скачивания файлов и при сохранении желательно называть их 0001, 0002, 0003 итп.
Адрес для тестирования есть, но я его не хочу публиковать в открытом доступе. Если сделать универсальный скрипт для сохранения картинок произвольного сайта, то и для своей задачи я его смогу адаптировать. Некоторый опыт в программировании есть, но на других языках.
Я пробовал решить задачу без скриптов, с помощью утилиты просмотра кэша браузера (MZCacheView). Частично работает, но не так как надо. Копировать выбранные файлы получается. Но утилита не умеет их в нужном порядке сохранять в папку, а это важно. Оригинальные названия файлов состоят из сотен символов. Утилита обрезает название файла до какой-то длинны. У них получается одинаковое называние и тогда каждому файлу добавляется числовой индекс. Вроде бы так и надо. Но проблема в том, что файлы сохраняются в последовательности по времени закачки с точностью до секунды. В одну секунду может быть закачано несколько файлов и в результате внутри каждого секундного интервала последовательность сохраненных файлов сбивается на произвольную.