Сколько весит один символ?
1 символ компьютерного алфавита «весит» 8 битов.
Сколько весит один символ в тексте?
Достаточный алфавит Т. к. 256 = 28, то вес 1 символа – 8 бит. Единице в 8 бит присвоили свое название — байт.
Сколько весит 1 символ ascii?
Обычно символ ASCII расширяют до 8 бит, просто добавляя один нулевой бит в качестве старшего. 0.
Сколько весит один символ в Юникод?
Определить в этой кодировке информационный объем сообщения в этой кодировке: Где родился, там и сгодился.
Сколько занимает код символа?
Расширенная ASCII позволяет использовать все 8 бит для кодирования. В таблице Unicode используется 2 байта, поэтому можно сказать, что 1 символ в компьютере занимает 1 или 2 байта.
Сколько весит один символ в кодировке UTF-16?
Один символ кодировки UTF-16 представлен последовательностью двух байтов или двух пар байтов.
1. Введение в Unicode (опять?)
Всем здравствуйте, меня зовут Антон, и этой статьей я открываю новый цикл публикаций про Unicode. Сразу может возникнуть вопрос — зачем? Их же и так море?
На Хабре, как и вообще в русскоязычном сегменте Интернета, в основном можно найти обзорные статьи, дающие лишь общее представление о Юникоде, но о том, как с ним работать — информации крайне мало. Сами же его разработчики, Unicode Consortium, предоставляют довольно подробную… но очень объемную документацию, которую при этом мало просто прочитать — для полного понимания много чего в ней стоит прокодить.
Мы, разработчики, очень любим изобретать велосипеды и заглядывать в мануалы в самый последний момент. Полагаемся на сторонние библиотеки, зачастую не до конца понимая, что там под происходит под капотом.
В работе с текстом, таких велосипедов, к сожалению, наделано много. Наверняка вы сталкивались с чем‑то подобным:
поиск не находит казалось бы одни и те же слова.
в поле ввода безобразно работает ограничение на количество введённых символов, в зависимости от выбранного языка. Классика.
куда‑то пропадают эмодзи в базе данных, в текстах всплывают ромбики‑квадратики… Перечислять можно бесконечно.
Что в статьях:
Основная мысль — нет ничего лучше, чем разобрать что‑то на практике. Какие‑то темы будут упомянуты вскользь (например, из кодировок мы плотно затронем лишь UTF-8), какие‑то темы оставим сильно на потом (например, системы ввода), а про что‑то вообще забудем (например, про историю — на Хабре есть что почитать на эту тему, например, тут или тут).
Итак, ближайший план:
разберём, что из себя представляет Unicode, его символы и их свойства, кодировки. Напишем валидацию строк UTF-8, научимся преобразовывать запись символа в кодировке UTF-8 в код символа (кодпоинт) Unicode и обратно.
выясним, что представляет собой нормализация текста, зачем она нужна и где её применять. расскажу про каноническую эквивалентность символов и эквивалентность совместимости, разберём как делается декомпозиция/композиция, быстрые проверки, под конец — напишем реализацию алгоритмов нормализации.
узнаем, что такое сопоставление (collation) строк, алгоритм сопоставления (UCA), что такое DUCET и CLDR; уровни и веса сопоставлений, различные подходы к взвешиванию весов, немного затронем тему баз данных, и, наконец, напишем пример.
Код примеров — на языке Rust, все примеры будут выложены на гитхаб.
�� небольшой оффтопик
по мере продвижения в статьях, я буду использовать термины, которые в различных источниках в силу не менее различных причин (например, переводов) могут быть обозначены по‑разному. использовать буду те, которые считаю наиболее точными, но если я где‑то не прав — пожалуйста, не стесняйтесь мне на это указать.
Что такое Unicode
Юникод — стандарт кодирования символов, который включает в себя символы огромного количества письменностей, различные графические символы, эмодзи, управляющие символы.
На момент написания этой статьи, актуальная версия Unicode — 15.0.0, и по мере развития стандарта было сломано немало копий в обсуждениях — начиная с избыточности (стоит‑ли включать в него мёртвые языки), продолжая вопросами организации размещения кодпоинтов в таблице, и заканчивая вечным обсуждением эмодзи.
✍️ кодпоинт — code point, кодовая точка — в контексте кодирования символов — числовое значение, соответствующее определенному символу.
Кодпоинты Unicode обозначаются как U+xxxx , где xxxx — шестнадцатеричный код символа. По префиксу U+ мы можем определить, что имеется ввиду именно кодпоинт Unicode.
Плоскости Unicode
Unicode — это в первую очередь про символы. Кодпоинты символов Unicode принадлежат диапазону от U+0000 до U+10FFFF включительно.
Этот диапазон разбит на крупные части, которые называются плоскостями (planes) — непрерывные диапазоны, состоящими из (65 536) последовательно расположенных кодпоинтов.
Плоскости, в свою очередь, дробятся на блоки — диапазоны кодпоинтов, сгруппированных по назначению.
аббр.
диапазон
название
BMP
Основная многоязычная плоскость
Basic Multilingual Plane
SMP
Дополнительная многоязычная плоскость
Supplementary Multilingual Plane
SIP
Дополнительная идеографическая плоскость
Supplementary Ideographic Plane
TIP
Третичная идеографическая плоскость
Tertiary Ideographic Plane
SSP
Специализированная дополнительная плоскость
Supplementary Special‑purpose Plane
SPUA‑A/B
Дополнительные области для частного использования — A/B
Supplementary Private Use Area, SPUA‑A/B
BMP — основной диапазон символов, который встретится нам в 99% случаев.
Заметим и запомним — для записи значения кодпоинта из плоскости BMP достаточно 16 бит.
Некоторые блоки плоскости (и пара особенных символов), о которых стоит упомянуть:
C0 Controls and Basic Latin
128 символов таблицы ASCII, единственный блок в Unicode, на кодирование символов которого достаточно 1 байта. Включает в себя управляющие коды C0 и символ удаления.
С1 Controls and Latin-1 Supplement
Дополнения к латинице, включает в себя дополнительные управляющие символы (C1 Control).
Суррогатные пары
Используется только в UTF-16, по сути — легаси. С помощью суррогатной пары в UTF-16 можно составить код символа, выходящий за пределы U+FFFF . А вот в кодировках, отличных от UTF-16, использование символов этого диапазона считается ошибкой, и добавляет нам пару лишних сравнений для каждого символа при валидации.
ZERO WIDTH NO‑BREAK SPACE
Пусть вас не вводит в заблуждение то, что символ находится в блоке Arabic Presentation Forms‑B. К арабскому он отношения не имеет. Зато непонимание, зачем он нужен и как его обрабатывать, привело к куче ошибок в различного рода программах. Именно этот символ используется в качестве Byte Order Mark (маркер последовательности байтов), или сокращенно — BOM.
� — REPLACEMENT CHARACTER
тот самый символ, который наверняка встречался хоть раз каждому. Этим символом заменяется неподдерживаемый символ Unicode / невалидная последовательность байт в кодировке.
✍️ Совет из разряда «Хозяйке на заметку»
Обратим внимание, что, как указано выше, первые 2 блока включают в себя управляющие символы (Control characters): U+0000 — U+001F , U+007F , U+0080 — U+009F . Хоть это и не относится к теме статьи, но будет полезным напомнить себе, что их стоит при необходимости экранировать.
SMP — преимущественно неиспользуемые языки. Однако, есть одна причина, по которой символы этой плоскости довольно‑таки часто встречаются: эмодзи.
SIP, TIP, SSP — устаревшие / редко используемые символы CJK, символы специального назначения.
⛩ CJK расшифровывается как Chinese Japanese Korean. Символы CJK имеют ряд особенностей, с первыми из которых мы столкнемся, когда доберёмся до нормализации.
SPUA‑A/B — Область частного использования (название которой говорит само за себя) можно использовать по собственному усмотрению. А можно и не использовать, что чаще всего и происходит.
Главное здесь тот факт, что авторы Unicode обязуются не задействовать Private Use при обновлениях стандарта; таким образом, значение любого уже определённого в Unicode кодпоинта занимает максимум 20 бит (так как последний кодпоинт перед началом области, U+EFFFF , требует именно столько).
Символы Unicode
До Unicode мы могли быть уверены, что за один графический символ отвечает один кодпоинт. Однако с его появлением ситуация изменилась, и та же буква Й может быть представлена как:
отдельный кодпоинт U+0419 CYRILLIC CAPITAL LETTER SHORT I ,
буква И, U+0418 CYRILLIC CAPITAL LETTER I в сочетании с бреве, U+0306 COMBINING BREVE .
На картинке мы видим 2 кодпоинта, которые, очевидно, относятся к разным категориям символов. А ведь ещё есть цифры, пунктуация, графические символы и разделители, управляющие символы и суррогатные пары, и все они отображаются (или не отображаются) по‑разному, по‑разному ведут себя при сортировке, имеют разную направленность в тексте.
Свойства символов
Стандарт Unicode очень детально описывает свойства всех включённых в него кодпоинтов, но мы же пока остановимся на некоторых из них. Очень часто в документации / коде используются сокращения названий этих свойств, они приведены в скобках.
У каждого символа есть название. Название символа является уникальным, и может содержать только прописные буквы латинского алфавита (A‑Z), цифры (0–9), пробелы и знаки дефиса (‑).
Например, название кодпоинта латинской буквы A — LATIN CAPITAL LETTER A .
General Category (Gc)
Упомянутая ранее основная категория символа. Значения этого свойства можно объединить в несколько групп по их типу:
все буквы (L)
буквы, имеющие регистр (LC)
Lu — прописная буква (Letter, uppercase)
Ll — строчная буква (Letter, lowercase)
Lt — заглавная буква (Letter, titlecase)
Lm — буква‑модификатор (Letter, modifier)
Lo — буква, прочие (Letter, other)
знаки (M)
Mn — неразрывный знак (Mark, nonspacing)
Mc — сочетаемый знак с интервалом (Mark, spacing combining)
Me — закрывающий знак (Mark, enclosing)
цифры, числа (N)
Nd — десятичная цифра (Number, decimal digit)
Nl — буквенно‑числовой символ (Number, letter)
No — число, прочие (Number, other)
пунктуация (P)
Pc — соединительный символ (Punctuation, connector)
Pd — знаки тире и дефиса (Punctuation, dash)
Ps — открывающая пунктуация (Punctuation, open)
Pe — закрывающая пунктуация (Punctuation, close)
Pi — открывающие кавычки (Punctuation, initial quote)
Pf — закрывающие кавычки (Punctuation, final quote)
Po — пунктуация, прочее (Punctuation, other)
символы (S)
Sm — математический символ (Symbol, math)
Sc — символ валюты (Symbol, currency)
Sk — символ‑модификатор (Symbol, modifier)
So — символ, прочие (Symbol, other)
разделители (Z)
Zs — пробел (Separator, space)
Zl — разделитель строк (Separator, line)
Zp — разделитель параграфов (Separator, paragraph)
разное (C)
Cc — управляющие символы (Other, control)
Cf — символы форматирования (Other, format)
Cs — суррогаты (Other, surrogate)
Co — частное использование (Other, private use)
Cn — не назначенные, в том числе не‑символы (Other, not assigned (including noncharacters))
Canonical Combining Class (ССС)
Важнейшее из свойств — класс канонического комбинирования символов. Относится к свойствам нормализации, и используется, как несложно догадаться, в алгоритмах нормализации. Значением является число от 0 до 240, которое отвечает за расположение в последовательности кодпоинтов, составляющих букву.
Кодпоинт с CCC = 0 называется стартером (starter), все прочие — не‑стартерами (non‑starter). Стартером может являться какая‑либо буква, цифра — основной символ, к которому могут быть добавлены дополнительные знаки, либо символ, вообще не подразумевающий комбинирования с чем‑либо, — например, пробел. Стартеры не подлежат сортировке при декомпозиции символа / нормализации текста.
Значение CCC не‑стартера может нести какую‑то смысловую нагрузку — например, что кодпоинт перекрывает основной знак (ССС = 1), или является диакритическим знаком для чтения CJK (ССС = 2), или указывать расположение знака относительно стартера (ССС находятся в диапазоне 202–240), или быть просто весом для сортировки в последовательности (10–132).

В практическом плане, чаще всего нас будет интересовать, является‑ли кодпоинт стартером или нет. Тем не менее, приведём полный список значений CCC:
Не подлежащие сортировке: пробелы и обрамляющие знаки, а также множество гласных и согласных знаков, даже если они не образуют отдельных символов.
Наложение: знаки, накладывающиеся на базовую букву или символ.
Чтение китайских иероглифов: диакритические знаки для китайских, японских и корейских иероглифов.
Точки нукта в письменности, основанной на брахми.
Фонетические знаки Хираганы/Катаканы.
Вирамы: знаки, обозначающие отсутствие звука между символами в санскрите, хинди и ряде других индийских языков.
Классы фиксированного положения в комбинируемой последовательности.
Знаки, прикрепленные внизу слева.
Знаки, прикрепленные под базовым символом.
Знаки, прикрепленные внизу справа.
Знаки, прикрепленные слева.
Знаки, прикрепленные справа.
Знаки, прикрепленные сверху слева.
Знаки, прикрепленные над базовым символом.
Знаки, прикрепленные сверху справа.
Отдельные знаки снизу слева.
Отдельные знаки под базовым символом.
Отдельные знаки снизу справа.
Отдельные знаки слева.
Отдельные знаки справа.
Отдельные знаки сверху слева.
Отдельные знаки над базовым символом.
Отдельные знаки сверху справа.
Двойные знаки снизу. Отдельные знаки, которые располагаются ниже двух других диакритических знаков.
Двойные знаки сверху. Отдельные знаки, которые располагаются выше двух других диакритических знаков.
Греческая подстрочная йота. единственный кодпоинт с этим CCC — U+0345
Может возникнуть вопрос — а чем, собственно, разница между, например, 214 и 230? Дело в том, что символы, имеющие класс канонического комбинирования от 200 до 212 — это диакритические знаки, являющиеся частью отображения символа, как, например, хвостик (ogonek) в польском языке ( U+0328 COMBINING OGONEK ). А вот, например, две точки в букве Ë ( U+0308 COMBINING DIAERESIS ) — расположены над символом, отдельно, и его CCC будет равен 230.

Прочие свойства
У символа также есть свойства, относящиеся к отображению текста (например, Bidirectional Class (Bidi class), отвечающее за направление текста); свойства числовых символов; связанные с кодпоинтом строчная/прописная/заглавная буква. Пока просто упомянем, что они существуют, и вернёмся к ним в дальнейших статьях.
Другое важнейшее свойство — декомпозицию символа (Decomposition Mapping + Decomposition Type), мы рассмотрим уже в следующей статье про нормализацию.
Полную информацию по свойствам символов можно найти в четвертой главе спецификации Unicode: https://www.unicode.org/versions/Unicode15.0.0/ch04.pdf
Хранятся данные о символах Unicode в Unicode Character Database (UCD), и найти её можно здесь: https://www.unicode.org/Public/UCD/latest/ucd/.
Описанию форматов файлов UCD посвящёно приложение #44 стандарта: https://www.unicode.org/reports/tr44/.
Кодировки
Спецификация Unicode описывает три формата кодирования кодпоинтов (UTF, Unicode Transformation Format): UTF-8, UTF-16 и UTF-32.
С помощью каждой из них можно закодировать любой кодпоинт, находящийся в диапазоне от U+0000 до U+10FFFF . Самой распространенной из них является UTF-8, тем не менее, и у UTF-16, и у UTF-32 находится свое применение.
well-formed и ill-formed
Строка текста, закодированная в любой из кодировок считается хорошо сформированной (well‑formed), когда для строки выполняются следующие условия:
Для любой из кодировок недопустимы кодпоинты, выходящие за пределы таблицы символов Unicode (> U+10FFFF ).
В UTF-16 недопустимо наличие одного из элементов суррогатной пары без дополняющего его элемента. Отсюда также можно вывести правило, что младший суррогат не может стоять впереди старшего.
В UTF-8 и UTF-32 недопустимо присутствие символов суррогатных пар ( U+D800 — U+DFFF ).
В UTF-8 последовательности недопустимо избыточное кодирование. если кодпоинт можно закодировать, используя меньшее количество байт — такое кодирование является недопустимым.
Старшие биты байтов последовательности UTF-8 должны соответствовать его формату.
Некорректно закодированная строка называется ill‑formed.
UTF-32
Ключевым преимуществом UTF-32 можно назвать скорость и возможность быстрого доступа к любому символу в тексте по его индексу. Платой за это будет повышенное использование памяти, так как кодирование любого кодпоинта требует 4 байт.
Учитывая, что большинство символов в тексте (если не все) скорее всего будут относиться к плоскости BMP, значение кодпоинта которого укладывается в 2 байта, — мы увидим, что до половины объема памяти будет использоваться для хранения нулей.
Порядок байт, используемый при записи 32-битного значения кодпоинта может быть как little‑endian, так и big‑endian — кодировка в таком случае обозначается как UTF-32LE и UTF-32BE соответственно. По умолчанию считается, что используется big‑endian.
Для того, чтобы однозначно определить, какой порядок байт используется, в начале текста в качестве маркера записывается символ U+FEFF ZERO WIDTH NO‑BREAK SPACE в выбранном формате. Этот маркер называется BOM — Byte Order Mark.
Приведём пример записи кодпоинта в различных форматах:
Код символа (HEX)
Кодировка
Последовательность байт
00 00 FE FF 00 01 02 03
FF FE 00 00 03 02 01 00
00 01 02 03
UTF-16
Формат появился в тот момент, когда в 1996 году стало понятно, что 2 байта на символ — недостаточно (первая версия Юникода представляла собой 16-битную кодировку с фиксированной шириной символа).
Главные недостатки кодировки:
по сравнению с UTF-8, кодировка избыточна, так как даже для кодирования ASCII‑символов используется 2 байта — так что она меньше подходит для хранения и передачи текстов.
когда требуется скорость — UTF-16 стоит рядышком с UTF-32, при этом требуя меньше ресурсов, но не имеет главного преимущества UTF-32 — возможности быстрого доступа к символу по его индексу, так как кодпоинт Unicode может быть закодирован в UTF-16 как двумя, так и четырьмя байтами.
Алгоритм кодирования:
В случае, если кодпоинт Unicode находится в плоскости BMP, то он кодируется как есть, двумя байтами.
Если значение кодпоинта лежит за пределами 16 бит — то такое значение кодируется с помощью суррогатной пары — двух слов, первое из которых называется старший суррогат — high surrogate code point, и имеет значение в диапазоне U+D800 — U+DBFF , и младший суррогат — low surrogate code point, и имеет значение в диапазоне U+DC00 — U+DFFF .
Кодирование суррогатной пары осуществляется по следующей схеме распределения бит:
битовое представление кодпоинта
битовое представление суррогатной пары
В данной схеме wwww = uuuuu — 1 . Это работает потому, что максимальное значение кодпоинта — 0×10FFFF , в битовом представлении — только 21-й бит имеет значение 1, таким образом, после вычитания единицы для хранения значения кодпоинта нам потребуется на один бит меньше.
Как и в случае с UTF-32, UTF-16 так же может быть записан в BE и LE виде, и для определения, какой порядок байт используется можно так же использовать BOM.
Код символа (HEX)
Кодировка
Последовательность байт
FE FF 00 4D
FF FE 4D 00
00 4D
FE FF D8 00 DC 00
FF FE 00 D8 00 DC
D8 00 DC 00
Перед тем, как перейти к UTF-8, немного поговорим о BOM.
Причины, которые привели к его появлению понятны: смысл был в том, чтобы дать понять программе, в каком формате читать текстовый файл, учитывая, что он может быть получен из стороннего источника.
На практике же — UTF-8 занял нишу формата для хранения и передачи текстовых данных, а там, где используется UTF-32 / UTF-16 — порядок байт заранее известен и BOM излишен.
Порядок байт в UTF-8 определен заранее, и BOM в UTF-8 файлах ( EF BB BF ) выполняет только функцию обозначения, что текст — в кодировке UTF-8. Загвоздка в том, что практически всегда мы и так знаем, что текст — в UTF-8.
Проблем же он создаёт огромное количество:
Если текстовые данные имеют какой‑то формат (например, JSON), они в большинстве случаев обрабатываются программно. библиотека‑же, обрабатывающая этот JSON может не ожидать BOM.
То же самое относится и к компиляторам / интерпретаторам: там, где при токенизации ожидаются whitespace‑символы, не самое место метке, которая является всё‑таки специальным, но тем не менее валидным символом.
Определение длины текста, переход по индексу символа в тексте, замусоривание метками при конкатенации строк — везде BOM может изрядно помешать.
На данный момент, использование BOM не рекомендовано, и это хорошо.
Наиболее используемый формат для кодирования Unicode, имеющий свои плюсы и минусы:
плюсы:
Совместим с ASCII.
Использует от 1 до 4 байт для кодирования символов, что обеспечивает рациональное использование памяти.
минусы:
Использование переменного размера байт, помимо положительной стороны, имеет и отрицательную — в UTF-8 невозможно быстро перейти к символу по его индексу или узнать количество кодпоинтов без итерации по всем его байтам.
распределение бит в схеме кодирования кодпоинта в UTF-8:
биты кодпоинта
1 байт
2 байт
3 байт
4 байт
0000 0yyy yyxx xxxx
zzzz уууу ууxx xxxx
000u uuuu zzzz yyyy yyxx xxxx
Таким образом мы видим:
Если мы кодируем ASCII значение ( U+0000 — U+007F ), нам потребуется только один байт.
Для кодирования символа из плоскости BMP за пределами ASCII ( U+0080 — U+FFFF ) нам потребуется от 2 до 3 байт.
Кодирование символов, выходящих за плоскость BMP ( U+10000 — U+10FFFF ) всегда потребует 4 байта.
Если первый байт не соответствует указанной выше форме, или старшие биты 2, 3, 4 байтов не равны 10 , то текст, содержащий UTF-8-последовательность с такими байтами считается ill‑formed.
✍️ Если старшие биты встретившегося нам байта в well‑formed строке не равны 10 , то это говорит нам о том, что мы встретили первый байт UTF-8-последовательности для символа, в противном случае — мы встретили 2, 3 или 4 байт последовательности.
В практическом применении это полезно, когда мы хотим разбить UTF-8-текст на части, и не нарушить его целостности (здесь мы говорим только о UTF-8, последовательность кодпоинтов в составных символах это всё‑таки нарушит).
Давайте определим, какие последовательности UTF-8 допустимы, а какие — нет (хотя можно просто посмотреть в табличку 3–7 третьей главы официальной документации).
первый байт не может начинаться с битов 10 — исключаем диапазон 0x80 — 0xBF для него.
2, 3 и 4 байты последовательности должны начинаться с битов 10 — т. е. их диапазоны значений — 0x80 — 0xBF .
начиная с U+0080 , символы кодируются несколькими байтами.
так как UTF-8 не допускает избыточного кодирования, то должны быть задействованы биты первого байта, что исключает некоторые его значения:
2 байта на символ, диапазон начинается с U+0080 :
U+0080 — 1100 0010 1000 0000 .
таким образом, первый байт не может быть равным 0xC0 и 0xC1 .
3 байта на символ, диапазон начинается с U+0800 :
U+0800 — 1110 0000 1010 0000 1000 0000 .
вывод: если первый байт — 0xE0 , то диапазон значений второго байта — от 0xA0 до 0xBF .
4 байта на символ, диапазон начинается с U+10000 :
U+10000 — 1111 0000 1001 0000 1000 0000 1000 0000 .
похоже на предыдущий случай: если первый байт — 0xF0 , то диапазон значений второго байта — от 0x90 до 0xBF .
так как UTF-8 позволяет напрямую кодировать символы, находящиеся за пределами BMP, использование символов суррогатных пар ( U+D800 — U+DFFF ) не допускается.
запишем их в UTF-8:
U+D800 — 1110 1101 1010 0000 1000 0000
U+DFFF — 1110 1101 1011 1111 1011 1111
таким образом, последовательность UTF-8 некорректна, если первый байт равен 1110 1101 ( 0xED ), а второй байт находится в диапазоне 0xA0 — 0xBF .
последний кодпоинт в таблице Unicode — U+10FFFF , а максимальное значение, которое можно закодировать в UTF-8 — 0x1FFFFF . следовательно, существует возможность записать в UTF-8 символ, выходящий за пределы таблицы, чего допустить нельзя.
запишем последний символ таблицы Unicode в UTF-8:
U+10FFFF — 1111 0100 1000 1111 1000 1111 1011 1111
отсюда становится очевидно, что мы вышли за пределы таблицы, если:
первый байт равен 1111 0100 ( 0xF4 ), и во втором байте записано значение, больше чем 1000 1111 ( 0x8F ).
первый байт больше 1111 0100 ( 0xF4 ) — заодно мы убеждаемся в валидности последовательности старших бит первого байта.
Если записать это в виде таблицы, то мы получим ту самую таблицу 3–7:
A0 — BF
80 — 9F
90 — BF
80 — 8F
В таблице выделены значения (во втором байте последовательностей), на которые стоит обратить внимание при имплементации валидации UTF-8.
�� расширяем кругозор: Ill‑formed UTF-8 и MySQL старых версий
В старых версиях MySQL по‑умолчанию использовалась кодировка, которая обозначалась как utf8 . Казалось‑бы, какие могут быть проблемы? Но проблемы стали всплывать, когда в моду вошли эмодзи — оказалось, что MySQL под кодировкой utf8 в целях оптимизации понимал её ill‑formed версию, utf8mb3 , допускающую кодирование только BMP плоскости (т. е. максимум 3 байта на символ).
На смену utf8 пришла кодировка utf8mb4 , полноценно поддерживающая диапазон символов Unicode, utf8mb3 же, в свою очередь, объявлена deprecated.
Если интересно узнать побольше, можно заглянуть в официальную документацию MySQL.
Обработка ошибок при валидации UTF-8
Согласно официальной документации (и я с ней полностью согласен), допустимо 2 варианта действий при столкновении с невалидным UTF-8.
Первый — не обрабатывать ничего, и просто сообщить об ошибке. Вероятность получения «битой» UTF-8 по техническим причинам обычно крайне мала, в то же время какие‑то злонамеренные попытки прощупать валидацию пользовательского ввода на некорректность, а как следствие — пробелы в безопасности, встречаются довольно часто.
Второй — при нахождении ошибки определить максимально длинную цепочку некорректных байт, и заменить их на специально предназначенный для этого символ U+FFFD REPLACEMENT CHARACTER (�).
В любом случае, выбор варианта обработки ошибок всецело зависит от контекста.
Особенно актуально соблюдать осторожность и не игнорировать ill‑formed UTF-8 в случаях, где возможны инъекции исполняемого кода, вроде JavaScript.
Более детально вопросы безопасности рассматриваются в приложении #36 — Unicode Security Considerations.
Немного практики
Теперь, давайте подведём некоторые итоги, и напишем конвертацию UTF-8 в кодпоинты и обратно, и валидацию UTF-8.
Конечно, Rust, как и практически любой другой язык, умеет работать с Unicode.
Но почему‑бы не попробовать написать реализацию некоторых функций самим? Вторая причина, по которой это может понадобиться — бывают ситуации, когда собственные имплементации решают какую‑то специфичную задачу, и использование стандартных сценариев не совсем оптимально по скорости / памяти.
Репозиторий, и что там находится:
В v1 и v2 некоторый код дублируется, это не ошибка, — на мой взгляд, так нагляднее.
cargo bench из папки benches
UTF-8 → кодпоинт и наоборот
Алгоритм кодирования / декодирования сам по себе ничего особо интересного не представляет — обычные битовые сдвиги и маски.
Тем не менее, декодирование
(битовые операции — в макросе, т.к. этот макрос нам ещё пригодится в следующей статье):
… и кодирование:
Общий алгоритм валидации
Если он — валидный первый байт последовательности UTF-8 — уточняем количество символов последовательности и читаем их. Проверяем.
Повторяем, пока не закончатся данные.
базовая функция:
Прогоняем бенчмарки… видим — на языках, которые используют преимущественно латинский алфавит, встроенная функция валидации отрабатывает в 2 раза быстрее. как они этого добились?
Давайте предположим, что текст — в ASCII. Такой текст можно попробовать валидировать не побайтово, а блоками, что и используется в core::str::validations::run_utf8_validation ‑ почему‑бы не взять оптимизацию оттуда и не сравнить результаты?
В ней, если найден ASCII‑символ, а адрес следующего байта имеет выравнивание в памяти по usize, валидируются 2 usize‑блока с помощью битовой маски (только у ASCII‑символов старший бит равен нулю).
Что нужно сделать:
Определим границу в тексте, после которой применять оптимизацию не нужно (после неё нет достаточного количества символов).
Добавляем проверку — если адрес выровнен по usize, индекс меньше границы — читаем блок и проверяем с помощью маски, являются‑ли элементы этого блока ASCII‑символами.
Повторяем, если проверка была успешной.
проверка:
добавляем границу:
добавляем блочные проверки:
Как и ожидалось по бенчмаркам, затраты на валидацию текста с UTF-8-последовательностями, не входящими в ASCII возросли — появилась дополнительная проверка. Также замедляется проверка за счет того, что если встречается ASCII‑символ в не‑ASCII тексте (никто не отменял знаки пунктуации, пробелы, переносы строк — ну или язык может сочетать в себе символы латиницы и диакритические знаки, лежащие за пределами ASCII).
Что можно ещё сделать?
Например, можно заменить функцию проверки количества символов get_utf8_sequence_width на получение количества символов последовательности из заранее построенного массива, как это делается в Rust:
Можно вместо количества байт попробовать получать готовый кейс для сравнения последующих байт последовательности:
Можно попробовать заменить проверки диапазона допустимых значений
на проверки старших бит по битовой маске:
или, что равнозначно,
Вобщем, оптимизация — отличное занятие, когда требуется отвлечься, пробуйте, сравнивайте!
Что дальше
На этом — закончу первую часть. Следующая будет посвящена декомпозиции и нормализации; возможно, эту тему разобью на два части — в первой затронем алгоритмы декомпозиции и NFD/NFKD, во второй же части поиграемся с канонической композицией и NFC/NFKC.
Сколько весит 1 символ в txt
1 символ компьютерного алфавита «весит» 8 битов.
Сколько весит один символ в тексте?
Достаточный алфавит Т. к. 256 = 28, то вес 1 символа – 8 бит. Единице в 8 бит присвоили свое название — байт.
Сколько весит 1 символ ascii?
Обычно символ ASCII расширяют до 8 бит, просто добавляя один нулевой бит в качестве старшего. 0.
Сколько весит один символ в Юникод?
Определить в этой кодировке информационный объем сообщения в этой кодировке: Где родился, там и сгодился.
Сколько занимает код символа?
Расширенная ASCII позволяет использовать все 8 бит для кодирования. В таблице Unicode используется 2 байта, поэтому можно сказать, что 1 символ в компьютере занимает 1 или 2 байта.
Сколько весит один символ в кодировке UTF-16?
Один символ кодировки UTF-16 представлен последовательностью двух байтов или двух пар байтов.
Сколько весит один символ? Ответы пользователей
Все предыдущие ответы — ПОЛНЫЙ БРЕД! допустим любой символ (точка или буква) весит 8 бит (1байт) — это точно. 21. 21. Нравится. Посмотрите еще 12 ответов.
Сколько весит 1 символ в Unicode . 2 либо 4 байта, смотря какой юникод. . Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 .
Т.к. 256 = 2 8 , то вес 1 символа – 8 бит. Единице в 8 бит присвоили свое название — байт. 1 .
Сколько весит один символ в UTF-8? 2 либо 4 байта, смотря какой юникод. Текст, состоящий только из символов Юникода с.
При написании сообщения известно,что один символ весит 5 бит,сколько символов в алфавите?сколько весит сообщение если. — ответ на этот и другие вопросы .
Один символ алфавита «весит» 10 бит. Сколько символов в этом алфавите? — ответ на этот и другие вопросы получите онлайн на сайте Uchi.ru.
В алфавит мощностью 256 символов можно поместить практически все символы, которые есть на клавиатуре. Такой алфавит называется достаточным. Т.к.
Вес одного символа, набранного на компьютере, зависит от того, какую кодировку используют. Чаще всего используется восьмиразрядная кодировка, т. е. один .
Знаете сколько весит (кб) вордовский или екселевский файл с одной буквой или символом? Стало интересно узнать сколько же? Вот результаты:
Сколько весит один символ? Видео-ответы
Сколько весит 1 символ в блокноте?
Всем привет! В этом видео мы узнаем, сколько символов нужно чтобы заполнить блокнот 1 килобайтом.
Сколько весит информация?
Если заполнить флешку информацией, станет ли она тяжелее? Можно ли посчитать, сколько килограммов весит весь .
Сколько байт занимает один символ Юникода?
Я немного запутался в кодировках. Насколько я знаю, старые символы ASCII занимали один байт на символ. Сколько байт требуется для символа Юникода?
Я предполагаю, что один символ Юникода может содержать все возможные символы из любого языка — я прав? Итак, сколько байтов нужно для каждого символа?
а что делают UTF-7, UTF-6, UTF-16 и др. в смысле? Это разные версии Юникода?
прочитал статья в Википедии о Unicode но это довольно сложно для меня. Я с нетерпением жду простого ответа.
10 ответов:
вы не увидите простой ответ, потому что его нет.
во-первых, Unicode не содержит «каждый символ из каждого языка», хотя он обязательно пытается.
Юникод сам по себе является отображением, он определяет кодовые точки, А кодовая точка-это число, связанное с обычно символ. Я говорю обычно, потому что есть такие понятия, как сочетание символов. Вы можете быть знакомы с такими вещами, как акценты, или умляуты. Они могут быть использованы с другим персонажем, такие как a или u для создания нового логического символа. Поэтому символ может состоять из 1 или более кодов.
чтобы быть полезным в вычислительных системах, нам нужно выбрать представление для этого информацию. Это различные кодировки Юникода, такие как utf-8, utf-16le, utf-32 и т. д. Они отличаются в основном размером своих кодовых единиц. UTF-32-это самая простая кодировка, она имеет кодовый модуль, который составляет 32 бит, что означает, что индивидуальная кодовая точка подходит комфортно в центр. Другие кодировки будут иметь ситуации, когда кодовая точка будет нуждаться в нескольких кодовых единицах, или эта конкретная кодовая точка вообще не может быть представлена в кодировке (это проблема, например, с UCS-2).
из-за гибкости комбинирования символов, даже в пределах заданной кодировки количество байтов на символ может варьироваться в зависимости от символа и формы нормализации. Это протокол для работы с персонажами, которые имеют более чем одно представление (можно сказать «an ‘a’ with an accent» который является 2 кодовыми точками, одна из которых является объединяющим символом или «accented ‘a’» который является одной кодовой точкой).
Как ни странно, никто не указал, как рассчитать сколько байт занимает один символ Юникода. Вот правило для кодированных строк UTF-8:
Итак, быстрый ответ: он занимает от 1 до 4 байт, в зависимости от первого, который укажет, сколько байтов он займет.
обновление
Как prewett указано, что это правило применяется только к UTF-8
я знаю, этот вопрос старый и уже есть принятый ответ, но я хочу предложить несколько примеров (надеюсь, что это будет полезно кому-то).
насколько я знаю, старые символы ASCII занимали один байт на символ.
право. На самом деле, поскольку ASCII является 7-битным кодированием, он поддерживает 128 кодов (95 из которых можно распечатать), поэтому он использует только половину байта (если это имеет смысл).
сколько байт делает Юникод характер требуют?
Unicode просто отображает символы в кодовые точки. Он не определяет, как их кодировать. Текстовый файл не содержит символов Юникода, но байты/октеты, которые могут представлять символы Юникода.
я полагаю, что один символ Юникода может содержать все возможные символ из любого языка — я прав?
нет. Но почти. Так что в принципе да. Но все равно нет.
Так сколько байты это нужно на символ?
то же, что и ваш 2-й вопрос.
а что означают UTF-7, UTF-6, UTF-16 и т. д.? Они что-то вроде Юникода версии?
нет, это кодировки. Они определяют, как байты / октеты должны представлять символы Юникода.
пара примеров. Если некоторые из них не могут быть отображены в вашем браузере (вероятно, потому, что шрифт не поддерживает их), перейдите в http://codepoints.net/U+1F6AA (заменить 1F6AA с кодовой точкой в шестнадцатеричном формате), чтобы увидеть изображение.
-
- U + 0061 ЛАТИНСКАЯ СТРОЧНАЯ БУКВА A: a
- Nº: 97
- UTF-8: 61
- UTF-16: 00 61
- U + 0061 ЛАТИНСКАЯ СТРОЧНАЯ БУКВА A: a
-
- U+00A9 ЗНАК АВТОРСКОГО ПРАВА: ©
- Nº: 169
- UTF-8: C2 A9
- UTF-16: 00 A9
- U+00AE ЗАРЕГИСТРИРОВАННЫЙ ЗНАК: ®
- Nº: 174
- UTF-8: C2 AE
- UTF-16: 00 AE
- U+00A9 ЗНАК АВТОРСКОГО ПРАВА: ©
-
- U+1337 ЭФИОПСКИЙ СЛОГ PHWA: ጷ
- Nº: 4919
- UTF-8: E1 8C B7
- UTF-16: 13 37
- U + 2014 EM DASH: —
- Nº: 8212
- UTF-8: E2 80 94
- UTF-16: 20 14
- U+2030 ЗА МИЛЛЬ ЗНАК: ‰
- Nº: 8240
- UTF-8: E2 80 B0
- UTF-16: 20 30
- ЗНАК ЕВРО U+20AC: €
- Nº: 8364
- UTF-8: E2 82 AC
- UTF-16: 20 AC
- U+2122 ЗНАК ТОРГОВОЙ МАРКИ: ™
- Nº: 8482
- UTF-8: E2 84 A2
- UTF-16: 21 22
- U+2603 СНЕГОВИК: ☃
- Nº: 9731
- UTF-8: E2 98 83
- UTF-16: 26 03
- U + 260E ЧЕРНЫЙ ТЕЛЕФОН: ☎
- Nº: 9742
- UTF-8: E2 98 8E
- UTF-16: 26 0E
- U+2614 ЗОНТИК С КАПЛЯМИ ДОЖДЯ: ☔
- Nº: 9748
- UTF-8: E2 98 94
- UTF-16: 26 14
- U + 263A БЕЛОЕ УЛЫБАЮЩЕЕСЯ ЛИЦО: ☺
- Nº: 9786
- UTF-8: E2 98 BA
- UTF-16: 26 3A
- U + 2691 ЧЕРНЫЙ ФЛАГ: ⚑
- Nº: 9873
- UTF-8: E2 9A 91
- UTF-16: 26 91
- U+269B СИМВОЛ АТОМА: ⚛
- Nº: 9883
- UTF-8: E2 9A 9B
- UTF-16: 26 9B
- U+2708 САМОЛЕТ: ✈
- Nº: 9992
- UTF-8: E2 9C 88
- UTF-16: 27 08
- U + 271E ЗАТЕНЕННЫЙ БЕЛЫЙ ЛАТИНСКИЙ КРЕСТ: ✞
- Nº: 10014
- UTF-8: E2 9C 9E
- UTF-16: 27 1E
- U + 3020 ПОЧТОВЫЙ ЗНАК ЛИЦО: 〠
- Nº: 12320
- UTF-8: E3 80 А0
- UTF-16: 30 20
- U+8089 CJK UNIFIED IDEOGRAPH-8089: 肉
- Nº: 32905
- UTF-8: E8 82 89
- UTF-16: 80 89
- U+1337 ЭФИОПСКИЙ СЛОГ PHWA: ጷ
-
- U + 1F4A9 КУЧА КАКАШЕК:
- Nº: 128169
- UTF-8: F0 9F 92 A9
- UTF-16: D8 3D DC A9
- U+1F680 ROCKET:
- Nº: 128640
- UTF-8: F0 9F 9A 80
- UTF-16: D8 3D DE 80
- U + 1F4A9 КУЧА КАКАШЕК:
ОК Я уже увлекся.
- если вы ищете конкретный символ, вы можете скопировать и вставить его на http://codepoints.net/.
- я потратил много времени на этот бесполезный список (но он отсортирован!).
- MySQL имеет кодировку под названием «utf8», которая на самом деле не поддерживает символы длиной более 3 байт. Так что вы не можете вставить кучу ПУ, поле будет просто обрезаются. Использовать «utf8» вместо этого.
- здесь тестовая страница снеговика (unicodesnowmanforyou.com).
проще говоря Unicode — это стандарт, который присваивает один номер (называемый кодовой точкой) всем символам мира (его работа все еще продолжается).
теперь вам нужно представить этот код точки с помощью байтов, что называется character encoding . UTF-8, UTF-16, UTF-6 способы представления этих символов.
UTF-8 — это многобайтовая кодировка. Символы могут иметь от 1 до 6 байт (некоторые из них могут не потребоваться прямо сейчас).
UTF-32 каждый символ имеет 4 байта характер.
UTF-16 использует 16 бит для каждого символа, и он представляет только часть символов Unicode, называемых BMP (для всех практических целей его достаточно). Java использует эту кодировку в своих строках.
- составленные символы, где вместо использования объекта символа, который уже акцентирован / диакритический (À), пользователь решил объединить акцент и базовый символ (`A).
- кодовые точки. Кодовые точки-это метод, с помощью которого UTF-кодировки позволяют кодировать больше, чем обычно позволяет количество бит, которое дает им их имя. Например, UTF-8 обозначает определенные байты, которые сами по себе являются недопустимыми, но когда за ними следует допустимый байт продолжения, это позволит описать символ за пределами 8-битного диапазона 0..255. Смотрите примеры и слишком длинные кодировки ниже в статье Википедии на UTF-8.
- отличный пример, приведенный там, что € символ (кодовая точка U+20AC может быть представлена как три-байт последовательность E2 82 AC или четыре-байт последовательность F0 82 82 AC .
- оба действительны, и это показывает, насколько сложным является ответ, когда речь идет о «Unicode», а не о конкретной кодировке Unicode, такой как UTF-8 или UTF-16.
в UTF-8:
в UTF-16:
в UTF-32:
10FFFF-это последняя кодовая точка unicode по определению, и она определена таким образом, потому что это Технический предел UTF-16.
Это также самая большая кодовая точка UTF-8 может кодироваться в 4 байта, но идея кодирования UTF-8 также работает для 5 и 6 байтовых кодировок для покрытия кодовых точек до 7FFFFFFF, т. е. половина того, что может UTF-32.
Ну я просто вытащил страницу Википедии на нем тоже, и в вводной части я увидел «Unicode может быть реализован различными кодировками символов. Наиболее часто используемые кодировки-UTF-8 (который использует один байт для любых символов ASCII, которые имеют одинаковые значения кода как в кодировке UTF-8, так и в кодировке ASCII, и до четырех байтов для других символов), теперь устаревший UCS-2 (который использует два байта для каждого символа, но не может кодировать каждый символ в текущем Unicode стандартный)»
Как показывает эта цитата, ваша проблема заключается в том, что вы предполагаете, что Unicode является единственным способом кодирования символов. На самом деле существует несколько форм Юникода, и, опять же в этой цитате, один из них даже имеет 1 байт на символ, как и то, к чему вы привыкли.
Итак, ваш простой ответ, который вы хотите, заключается в том, что он меняется.
для UTF-16 символу требуется четыре байта (две единицы кода), если он начинается с 0xD800 или больше; такой символ называется «суррогатной парой».»Более конкретно, суррогатная пара имеет вид:
где [. ] обозначает двухбайтовый кодовый блок с заданным диапазоном. Все, что = 0xE000 недопустимо (за исключением маркеров спецификации, возможно).
посмотреть http://unicodebook.readthedocs.io/unicode_encodings.html, раздел 7.5.
зацените Unicode code converter. Например, введите 0x2009 , где 2009-Это номер Юникода для тонкого пространства, в «0x. поле «нотация» и нажмите кнопку Преобразовать. Шестнадцатеричное число E2 80 89 (3 байта) появляется в поле «кодовые единицы UTF-8».
1 символ в Microsoft Word!
Знаете сколько весит (кб) вордовский или екселевский файл с одной буквой или символом?
Стало интересно узнать сколько же? Вот результаты:
* Microsoft Word — 11,5 кб. или 11 818 байт;
* Microsoft Excel — 8,02 кб. или 8 221 байт;
* Microsoft PowerPoint — 32,5 кб. или 33 523 байт;
* Блокнот — 1 байт😎
С блокнотом и поинтом понятно. Файл екселя легче чем вордовский — не понятно почему.
Ведь в екселе больше функций
Вы как думаете?
Проверено было на Windows 10
Когда коту делать нехуй, он яйца лижет
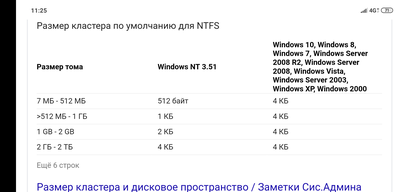
1 хуй 1 байт экселя весь кластер займет. 4кб если не ошибаюсь дефолтные. Поэтому у блокнота 4Кб. Эксель в 2 раза больше. Ворд в 3.
Уважаемый /-ая/, /-ые/ гр.
Я получил и прочел ваше интересное письмо. Сообщаемые вами факты хорошо известны науке и интереса для нее не представляют. Тем не менее я горячо благодарю вас за ваше наблюдение и желаю вам успехов в работе и в личной жизни.
переименуй docx и xlsx в zip, разархивируй, и узнаешь
Функции-то в программе, а не в документе.
А в документе помимо самого текста что может быть? Форматирование.
А вот форматирования в вроде больше, чем в экселе.
Wildberries. Печальный опыт
Доброго времени суток! Работали мы с супругой осенью 2022 года на складе Вайлдберриз Невинномысск. Занимались тем что принимали возвращенные с пунктов выдачи товары. Проверяли целостность и внешний вид. Товары разнообразные, была и электроника и бытовые приборы, украшения, но в основном одежда. Работа была не сложная, но монотонная. Вскрываешь смотришь если все в порядке, то перекладываешь в специальную тару, если нет то относишь куда следует в зависимости от того брак это или несоответствие с программой и т.д. начиналось все неплохо, но нас сразу предупредили что пока мы новички у нас штрафов не будет, но потом появятся. Штрафы в основном это разделение ответственности. Ввели их незадолго до нашего прихода и заключались они в том что если на каком то этапе с товаром что то случается то ответственность разделяется на всех кто к нему прикасался и имел с ним дело независимо виноват ты или нет. Тогда мы этого еще не понимали. А зря)) прошло пару недель и наш рейтинг в программе стал расти а вместе с рейтингом начали поступать и первые неприятные звоночки. 200-500 рублей штрафов за смену. Ну не страшно подумали мы и продолжили доблестно трудиться. Первый удар в колокол случился когда мне прилетел штраф в 3800 разделение ответственности. Я прифигел и пошел разбираться к старшей которая поведала что по этому штрафу разбираться никто не будет т.к. кто накосячил и что с товаром приключилось не известно. Просто смирись и расслабься. Ладно работаем дальше. Начинаю спрашивать у коллег, а собственно как у вас дела и оказывается что дела так себе. Коллега поведал печальную историю, как он проверяя дорогую шубу не проверил карман. А там оказалась дырочка. Повесили 130 тыс. штрафа. Причем шубу эту больше никто не видел и где она находится не известно. Т.е. сотруднику падает на его баланс штраф 130 тыс и пока он эти деньги не отработает то в плюс не уйдет и деньги зарабатывать не начнет. И даже отработав штраф шубу он эту не увидит — такая политика. Другая коллега проверяла часы от Эпл и попала на 50 т.р. и тоже часы эти канули в лету а долг остался.
Еще более прифигев от этих историй продолжили работать. Теперь к работе плюсом пришел страх что нибудь пропустить и попасть на огромный штраф. В общем доработали мы еще пару недель, почти все заработанное списывалось на разделение ответственности, служба поддержки и старшие говорили что списания верные, но при этом где товар и что с ним случалось никто не знал.
Итог: вместо заработка получили лютое расстройство психики на фоне ожидания штрафов и списаний. Компания списывает все свои потери на сотрудников и не утруждает себя объяснениями, многие сотрудники сутками работают бесплатно в надежде отработать долги и выйти в плюс. К этому добавляется скотское отношение. Шмоны при входе и выходе(нужно раздеваться до трусов и выворачивать одежду). И полное безразличие к нашей судьбе кого либо из начальства. Кстати кто начальство я так и не узнал))) Строго не судите. Первый пост)
Сколько весит один символ в UTF-8
UTF-8, по сравнению с UTF-16, наибольший выигрыш в компактности даёт для текстов на латинице, поскольку латинские буквы без диакритических знаков, цифры и наиболее распространённые знаки препинания кодируются в UTF-8 лишь одним байтом, и коды этих символов соответствуют их кодам в ASCII.
- UTF-8 кодирует символы переменной длины, от 1 до 4 байт на символ.
- Один символ в информационном весе достаточного алфавита равен 1 байту.
- Латинские буквы без диакритических знаков, цифры и распространённые знаки препинания кодируются UTF-8 лишь одним байтом, соответствующим кодам в ASCII.
- Unicode использует два варианта кодирования: 8-битный и 16-битный. По умолчанию используется 16-битное кодирование, где каждый символ занимает 16 бит (два байта).
- Символ ASCII расширяется до 8 бит, дополнительно добавляя один нулевой бит в качестве старшего бита.
- Расширенная ASCII использует 2 байта в таблице Unicode. Так что 1 символ в компьютере занимает 1 или 2 байта.
- Один символ кодировки UTF-16 представлен последовательностью двух байт или двух пар байт.
- UTF-32 использует ровно 32 бита для кодирования любого символа, в отличие от UTF-8 и UTF-16, которые используют переменное число байтов для представления символов.
Сколько весит один символ
Таким образом, информационный вес одного символа достаточного алфавита равен 1 байту.
Сколько байт один символ UTF-8
UTF-8 — это кодировка символов переменной длины, что, в данном случае, означает длину от 1 до 4 байт на символ.
Чему равен 1 символ в Unicode
Unicode использует два варианта кодирования: 8-битный и 16-битный. По умолчанию используется 16-битное кодирование, то есть каждый символ занимает 16 бит (два байта); обычно его записывают как U+hhhh, где hhhh — шестнадцатеричный код символа.
Сколько весит 1 символ ASCII
Представление ASCII в ЭВМ
Обычно символ ASCII расширяют до 8 бит, просто добавляя один нулевой бит в качестве старшего.
Какой объем занимает 1 символ
Расширенная ASCII позволяет использовать все 8 бит для кодирования. В таблице Unicode используется 2 байта, поэтому можно сказать, что 1 символ в компьютере занимает 1 или 2 байта.
Сколько байт требуется для 1 символ
Один символ кодировки UTF-16 представлен последовательностью двух байт или двух пар байт.
Сколько весит один символ в UTF 32
Universal Character Set) в информатике — один из способов кодирования символов Юникода, использующий для кодирования любого символа ровно 32 бита. Остальные кодировки, UTF-8 и UTF-16, используют для представления символов переменное число байтов.
Сколько весит символ в UTF-16
Один символ кодировки UTF-16 представлен последовательностью двух байтов или двух пар байтов.
Сколько бит будет весить один символ
Один символ алфавита «весит» 10 бит.
Чем UTF-8 отличается от Unicode
Таблица Юникод каждому символу UCS сопоставляет кодовую точку, которая является номером ячейки таблицы, содержащей символ. UTF-8 — стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит: 8, 16, 24 или 32.
Сколько весит один пробел
Заметим, что пробел занимает 1 байт.
Сколько весит символ Unicode
В кодировке unicode на каждый символ отводится 2 байта.
Сколько весит один символ в КОИ-8
Определите количество символов в сообщении, если информационный
Сколько бит на символ
Каждый из этих символов представлен 7 битами данных. Для пересылки символов из расширенной таблицы ASCII (128-255) нужно использовать 8 битов.
Сколько весит один символ двоичного кода
К. 256 = 2^8, то вес 1 символа — 8 бит. Этот вес можно воспринимать как разрядность двоичного слова. То есть двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти (или 8 бит).
Сколько бит в UTF-8
UTF-8 является лишь представлением Юникода в 8-битном виде. Символы с кодами меньше 128 представляются одним байтом, а так как в Юникоде они повторяют ASCII, то текст написанный только этими символами будет являться текстом в ASCII.
Сколько весит символ текста
Один символ компьютерного алфавита весит \(8\) бит или \(1\) байт.
Сколько бит отводится в Unicode
В заданной кодировке Unicode каждый символ алфавита занимает 2 байта = 16 бит памяти. Согласно условию заданное слово состоит из 24 символов, то оно будет занимать в памяти 24 * 2 байта = 48 байт. 48 байт = 384 бит (так как 1 байт = 8 бит). Ответ: 1) 384 бита.
Сколько байт занимает ASCII
В этой форме юникодные символы кодируются одиночными байтами. Но поскольку одного байта для кодирования миллиона символов слегка мало, разные символы кодируются разным количеством байтов. Те, которые входят в старый ASCII, кодируются одним байтом и их значения полностью с ASCII совпадают.
Сколько весит символ в Unicode 16
Один символ кодировки UTF-16 представлен последовательностью двух байтов или двух пар байтов.
Сколько весит символ в строке
В современных системах 1 символ строки занимает 1 байт информации.
Чему равен символ
«≈» — «приблизительно равно». Используется при обозначении двух величин, разницей между которыми в данной задаче можно пренебречь. «≃» — используется для обозначения гомеоморфных пространств в топологии.
UTF-8 — самая популярная кодировка символов в Интернете. Она используется для кодирования текста на любых языках, включая китайский, японский и корейский, а также для хранения и передачи данных. Кодировка представляет собой переменную длину символов, что означает, что каждый символ может занимать от 1 до 4 байт.
Для сравнения, ASCII использует один байт для каждого символа, но только для символов на латинице и некоторых знаков препинания. Символы на других языках, например, кириллические, требуют расширенного набора символов, который использует более чем один байт.
UTF-16 использует два байта для каждого символа, однако не включает всех символов Юникода, в отличие от UTF-8. UTF-32 использует 32 бита (четыре байта) для каждого символа, что делает его самым «затратным» с точки зрения хранения данных. Однако UTF-32 предоставляет полную поддержку всех символов Юникода.
В первую очередь UTF-8 предназначен для использования в Интернете, поскольку компактность кодировки позволяет сократить количество передаваемой информации, сэкономить место на серверах и повысить скорость загрузки страниц. Также UTF-8 позволяет работать с множеством различных языков и использовать одинаковый формат для хранения и передачи данных на всех уровнях Интернета.
Таким образом, количество байт, занимаемых одним символом в UTF-8, зависит от самого символа, а не от кодировки в целом, и может варьироваться от 1 до 4 байтов. В случае, если символ находится в диапазоне ASCII, то используется только 1 байт. В случае, когда символы не входят в диапазон ASCII, подразумевается использование двух или более байтов для их кодирования.