«Сколько байт занимает один символ и как это влияет на память компьютера» — Сколько места в памяти компьютера занимает код одного символа
Одним из важнейших аспектов информатики является понимание работы компьютера. Одним из инструментов этой работы является кодировка символов. Эта кодировка позволяет компьютеру отображать текст на экране, сохранять и передавать данные в электронном формате.
Символ, на первый взгляд, кажется простой и универсальной единицей. Однако, каждый символ в кодировке занимает разное количество места в памяти компьютера. Знание этой информации позволяет оптимизировать работу с данными, уменьшить размер файлов и повысить производительность системы в целом.
В данной статье мы рассмотрим, сколько места в памяти занимает кодировка одного символа в различных кодировках, и какие факторы влияют на размер этих данных.
Изучаем ёмкость памяти компьютера: сколько занимает один символ в Unicode
Что такое Unicode?
Unicode — это международный стандарт для представления символов и текста на компьютере. Его цель — описать каждый символ в любом языке мира. Например, включены символы для таких письменных систем, как кириллица, латиница, арабица, иероглифика и многих других. Таким образом, компьютер может понимать и обрабатывать текст на разных языках.
Каков размер одного символа в Unicode?
Размер одного символа в Unicode зависит от его кодировки. Например, для символов в кодировке UTF-8 размер может быть от 1 до 4 байт, в то время как в кодировке UTF-32 размер каждого символа — 4 байта.
Наиболее распространённой кодировкой на Западе является UTF-8. При использовании этой кодировки размер одного символа может быть 1, 2, 3 или 4 байта. Например, английская буква «A» занимает всего 1 байт, а иероглиф «восход солнца» — 3 байта.
Каково значение размера одного символа в Unicode?
Размер одного символа в Unicode — это важный фактор при оценке потребления памяти. Чем больше размер символа, тем больше памяти он занимает. При использовании кодировки UTF-8, размер символа варьируется от 1 до 4 байт. При оценке количества символов и объёма памяти, занимаемого текстом, необходимо учитывать размер каждого символа и выбирать кодировку, которая наилучшим образом соответствует задачам.
В таблице ниже представлены значения размера символов в Unicode для различных кодировок:
| Кодировка | Размер символа |
|---|---|
| UTF-8 | 1-4 байта |
| UTF-16 | 2 или 4 байта |
| UTF-32 | 4 байта |
Сколько места занимает 1 символ в кодировке ASCII
Кодировка ASCII (American Standard Code for Information Interchange) является одной из самых распространенных кодировок, используемых для представления символов в памяти компьютера. В ASCII кодировке каждому символу соответствует уникальный битовый код, который занимает один байт или 8 бит.
Следовательно, для хранения одного символа необходимо выделить 8 бит (1 байт) памяти компьютера. Это позволяет представлять в кодировке ASCII 256 различных символов, включая буквы английского алфавита, цифры, знаки препинания и специальные символы.
Для сравнения, в других кодировках, таких как Unicode, которая используется для представления символов разных языков, каждому символу может соответствовать от 1 до 4 байтов памяти, в зависимости от используемого набора символов (например, кодировка UTF-8).
Таким образом, при работе с кодировкой ASCII нужно помнить, что каждому символу следует выделять ровно 1 байт памяти компьютера, что может быть важно при написании программ и работы с большими объемами текстовой информации.
Объем памяти для написания символов в кодировках ASCII и Unicode
Каждый символ, который мы набираем на клавиатуре или видим на экране монитора, занимает определенное количество памяти в компьютере. Для различных кодировок это значение разное, и важно понимать, сколько места может занять один символ в оперативной памяти.
Кодировка ASCII
Кодировка ASCII (American Standard Code for Information Interchange) включает в себя только основные символы латинского алфавита, цифры и знаки препинания. Для представления каждого символа используется 7 бит, что равно 1 байту. Таким образом, ASCII-символы занимают минимальное количество памяти — всего 1 байт.
Кодировка Unicode
Кодировка Unicode используется для представления символов практически всех языков мира, включая кириллицу, арабский, китайский и т.д. Для создания такого многоязычного набора символов используется 16-битный формат, который занимает два байта. Однако, у Unicode есть различные форматы, такие как UTF-8, в котором выделено 1-4 байта на каждый символ в зависимости от его кода. Таким образом, размер памяти, который займет символ в Unicode, может быть разным, в зависимости от выбранного формата кодировки.
- В UTF-8 первые 128 символов занимают всего 1 байт, а остальные — от 2 до 4 байтов.
- В UTF-16 каждый символ занимает 2 байта.
- В UTF-32 каждый символ занимает 4 байта.
Таким образом, в зависимости от выбранного формата кодировки, символ в Unicode может занимать от 1 до 4 байтов памяти в компьютере.
Сколько байтов занимает один символ в ASCII
ASCII – это таблица символов, которая включает в себя 128 различных знаков, таких как буквы, числа и знаки пунктуации. Но сколько же байт занимает каждый символ в этой таблице?
Ответ на этот вопрос прост: каждый символ в ASCII занимает 1 байт, то есть 8 бит. Это связано с тем, что таблица ASCII была создана еще в 60-х годах прошлого века, когда компьютеры развивались не так быстро, как сегодня, и не были способны обрабатывать большое количество информации.
В связи с этим, таблица ASCII ограничена всего лишь 128 знаками, и каждый знак занимает всего 1 байт. Это позволяет компьютерам быстро и легко работать с текстом на английском языке, и некоторых других языках, которые используют только символы из таблицы ASCII.
Однако, если вы работаете с текстом на других языках, таких как китайский, русский или тайский, то вы должны использовать другие кодировки, такие как UTF-8. В этом случае каждый символ может занимать разное количество байтов в зависимости от языка и уровня символа.
Чему равняется 1 символ в памяти компьютера
В информатике единицей измерения объема памяти является байт. Один байт содержит 8 бит информации, которые могут принимать два возможных значения — 0 или 1.
Для хранения одного символа используется один байт. Это означает, что каждый символ в текстовом документе или программном коде занимает ровно один байт в памяти компьютера.
Существуют различные кодировки символов, такие как ASCII, Unicode и UTF-8, которые определяют способ представления символов в памяти компьютера. Но независимо от используемой кодировки, размер одного символа всегда равен одному байту.
Это важно учитывать при разработке программ и веб-приложений, так как размер текста непосредственно влияет на объем занимаемой памяти и может иметь значительное значение для производительности и скорости работы программы.
Объём памяти, занимаемый одним символом
Объём памяти, занимаемый одним символом, зависит от нескольких факторов: кодировки, которую использует компьютер, и типа символа.
Для кодировки ASCII (American Standard Code for Information Interchange), которая используется в большинстве современных компьютеров, каждый символ занимает по 1 байту (8 бит). Это означает, что в памяти компьютера для хранения одного символа используется 8 бит информации. Символы в ASCII включают буквы латинского алфавита, цифры, знаки препинания и специальные символы.
В то же время, кодировки UTF-8 и UTF-16, которые широко используются для работы с многобайтовыми символами (например, для работы с текстовыми файлами на разных языках), занимают больше места в памяти. UTF-8 кодирует символы в зависимости от их значения, используя от 1 до 4 байтов, а UTF-16 позволяет использовать от 2 до 4 байтов на символ.
Таким образом, место, занимаемое одним символом в памяти компьютера, может быть разным в зависимости от типа символа и используемой кодировки. Важно учитывать эту информацию при работе с большим количеством текстовых данных.
Сколько места занимает 1 символ в памяти компьютера?
Один символ в компьютерных терминах называется байтом. Байт — это минимальный участок данных, который может быть обработан компьютером. Таким образом, 1 символ занимает 1 байт.
Байт может содержать информацию о 256 уникальных символах, таких как буквы алфавита, цифры и специальные символы. Однако, современные компьютеры используют специальные кодировки, такие как Unicode, которые позволяют представлять в памяти больше символов.
Кроме того, размер одного символа может отличаться в зависимости от того, каким образом он представлен в памяти. Например, при использовании более сложных форматов, таких как изображения или звуковые файлы, размер одного символа может составлять несколько килобайт или мегабайт.
Суммируя вышеизложенное, можно сказать, что 1 символ в компьютерной памяти занимает 1 байт, но размер символа может меняться в зависимости от конкретной ситуации и используемых форматов данных.
Сколько весит один символ в кодировке UTF-8
Кодировка UTF-8 является одной из наиболее распространенных в компьютерных системах и интернете.
Каждый символ в UTF-8 кодируется последовательностью из одного или нескольких байтов, в зависимости от его кодовой точки.
Для ASCII-символов, у которых кодовая точка находится в диапазоне от 0 до 127, кодировка UTF-8 использует только один байт.
В то же время для некоторых символов, например для символа «Ё» с кодовой точкой U+0401, кодировка UTF-8 использует три байта.
Размер одного символа в кодировке UTF-8 может варьироваться от 1 до 4 байтов.
Для более точного определения размера символа в конкретном тексте необходимо проанализировать последовательность байтов и определить их кодовые точки.
Таким образом, для точного ответа на вопрос, сколько весит один символ в кодировке UTF-8, необходимо знать его кодовую точку и, соответственно, количество байтов, которые используются для его кодирования.
Какова величина одного символа в кодировке UTF-16?
Кодировка UTF-16 — это одна из самых распространенных кодировок, используемых в интернет-технологиях. Она представляет собой способ кодирования символов Юникода, который поддерживает практически все современные операционные системы и браузеры.
Один символ в кодировке UTF-16 состоит из одной или двух 16-битных значений. Если символ состоит только из символов латиницы, то он занимает ровно 2 байта (16 бит). Если же это символ из другой пунктуации, например, кириллицы, то он занимает 4 байта (32 бита).
Вычисление размера символа в кодировке UTF-16 в байтах может быть полезно, если вы работаете с большим количеством текстовых данных или веб-страниц, содержащих много текста. Например, если вы знаете, что каждый символ будет занимать 4 байта, то вы можете оптимизировать процесс хранения и передачи данных, используя более компактный формат, который позволит сократить объем передаваемых данных и снизить нагрузку на сервер.
Более подробную информацию о весе символов в кодировке UTF-16 можно найти в таблице символов, которая позволяет сравнить размер всех символов в этой кодировке.
| Символ | Вес в байтах (UTF-16) |
|---|---|
| A | 2 |
| Д | 4 |
| € | 4 |
| 4 |
Таким образом, в зависимости от используемой кодировки и символа, его вес может быть разным. Кодировка UTF-16 занимает 2 или 4 байта на каждый символ, что учитывается в процессе обработки и передачи информации в интернете.
UTF 32: сколько весит один символ?
UTF-32 — один из форматов кодировки символов, используемых в компьютерах. Он представляет каждый символ в виде 32-битной последовательности байтов. Но сколько же весит один символ в этом формате?
Ответ на этот вопрос прост — один символ в UTF-32 занимает 4 байта, что эквивалентно 32 битам. Это достаточно много, учитывая, что в других форматах кодировки символов, таких как UTF-8 или UTF-16, один символ может занимать меньше места в памяти компьютера.
Необходимость использования UTF-32 возникает, когда нужно представить символы более чем в 2 байта в системах, которые не поддерживают другие форматы кодировки. Также, UTF-32 может быть более удобен для некоторых задач обработки текста, таких как поиск и замена символов, благодаря простоте его структуры.
Конечно, занимаемое каждым символом место в памяти компьютера не всегда критично, но в определенных случаях это может иметь значение, особенно если мы работаем с большим объемом данных. Поэтому при выборе формата кодировки символов необходимо учитывать требования конкретной задачи и возможности используемой системы.
Сколько бит на символ
Количество бит на один символ зависит от используемой кодировки. Кодировка – это способ представления символов на компьютере в виде битовой последовательности. Существует множество кодировок, но самые распространенные – ASCII, UTF-8 и UTF-16.
ASCII (American Standard Code for Information Interchange) использует один байт (8 бит) для представления одного символа. В ASCII входят только латинские буквы, цифры, знаки препинания и некоторые специальные символы.
UTF-8 (Unicode Transformation Format) использует переменное количество байтов для представления символов, в зависимости от символа и его номера в таблице Unicode. Например, для представления символов латинского алфавита UTF-8 использует один байт, а для китайских иероглифов – до 4 байтов.
UTF-16 также использует переменное количество байтов, но минимальный размер для каждого символа – 2 байта, что делает данную кодировку более объемной, чем UTF-8.
Таким образом, количество бит на символ может колебаться от 8 до 32 бит в зависимости от кодировки и конкретного символа. При написании программ или разработке сайтов важно учитывать выбранную кодировку, чтобы не только правильно отображать символы, но и не занимать избыточное место в памяти компьютера.
Сколько символов может хранить ASCII
ASCII — это стандарт кодирования символов, используемый в компьютерной технике. Он состоит из 128 символов — алфавитных, цифровых и специальных. Все символы имеют свой код, представленный в двоичном виде.
Все символы в ASCII занимают один байт (8 бит), что позволяет хранить 256 различных значений. Стандарт ASCII использует только первые 7 бит, используя оставшийся восьмой бит для контроля ошибок.
Символы ASCII включают в себя прописные и строчные буквы английского алфавита, цифры, знаки препинания и специальные символы. Всего 95 печатаемых символов и 33 управляющих символа.
Таким образом, ASCII может хранить 128 различных символов, каждый занимает один байт места в памяти компьютера. Поэтому, чтобы хранить код одного символа ASCII, потребуется 8 бит или 1 байт памяти.
Сколько весит один символ
Вес одного символа зависит от его кодировки. Например, в кодировке ASCII каждый символ занимает 1 байт (8 бит), значит его вес равен 8 бит.
В кодировке ISO-8859-1 каждый символ также занимает 1 байт, а в кодировке UTF-8 существуют символы, которые могут занимать от 1 до 4 байт. Поэтому вес символа в UTF-8 зависит от его кода и диапазона использования.
Если рассматривать вес символа как количество памяти, занимаемой на его хранение, то его вес будет равен количеству бит, необходимых для его представления в определенной кодировке.
Количество памяти, занимаемое символами, важно для оптимизации работы программ и уменьшения объема передаваемых данных в сети. Чем меньше вес символа, тем быстрее работает программа и меньше трафика тратится на передачу информации.
Почему 1 символ равен 1 байту
Байт — это минимальная единица хранения данных в компьютере. Когда мы говорим о размере файла в байтах, мы говорим о том, сколько байт занимает каждый символ в этом файле. И почти всегда один символ занимает один байт.
Почему же так происходит? Дело в том, что компьютер не может «понимать» символы напрямую. Он работает только с двоичными числами — наборами нулей и единиц. Каждый символ в компьютере хранится в виде числа, которое соответствует этому символу в кодировке. И размер числа (то есть количество бит, которые нужны для хранения этого числа) зависит от размера используемой кодировки.
Наиболее распространенная сейчас кодировка для хранения текста — это UTF-8. В UTF-8 каждый символ занимает от 1 до 4 байт, в зависимости от его кода. Однако, большинство символов в тексте, с которым мы имеем дело каждый день — это символы из обычной английской раскладки клавиатуры, которые занимают ровно один байт. Поэтому мы можем сказать, что обычно 1 символ занимает 1 байт — это соответствует распространенным кодировкам и символам, которыми мы пользуемся в повседневной жизни.
- Следует отметить, что в некоторых языках (например, китайском или японском) один символ может занимать несколько байт, даже в английских кодировках. Это происходит потому, что эти языки имеют большое количество уникальных символов и не могут обойтись однобайтовыми кодировками.
- Также стоит учитывать, что размер файла может быть сильно завышен, если в файле используется особенно крупный шрифт, выравнивание текста и множество других параметров форматирования, которые не являются частью текста.
Таким образом, можно с уверенностью сказать, что в большинстве случаев один символ занимает ровно один байт. Однако, стоит помнить, что это не всегда так и размер файла зависит от множества факторов, включая используемый язык, кодировку и форматирование текста.
Сколько символов может содержаться в 1 бите информации?
Бит – это минимальная единица хранения информации в компьютере. Однако просто хранение нулей и единиц часто недостаточно. Информацию нужно преобразовывать в символы, цифры, буквы и другие знаки, которые можно прочитать и понять. Так вопрос – сколько символов может содержаться в 1 бите информации?
Ответ на этот вопрос простой – только один. Но это только в случае, если использовать кодировку ASCII (American Standard Code for Information Interchange). Данный стандарт кодирует буквы, цифры, знаки препинания и другие символы, которые в ходе работы с компьютером представляются в виде 8-битных комбинаций. Существует всего 256 таких комбинаций (2 в степени 8), и каждая из них отвечает за один символ в кодировке ASCII.
Однако существуют и другие кодировки, в которых возможно кодировать гораздо больше символов на 1 бите. Например, в кодировке Unicode стандарта UTF-8 каждый символ кодируется на 1-4 байтах, в зависимости от его кода в таблице символов Unicode. В данном случае в 1 байте может содержаться до 4 символов (до 32 бит), что позволяет кодировать не только основные языки, но и символы из более редких алфавитов и даже эмодзи.
Таким образом, ответ на вопрос, сколько символов может содержаться в 1 бите информации, зависит от выбранной кодировки символов.
Вес одного символа на клавиатуре
Символ на клавиатуре представляет собой определенную комбинацию битов, которые хранятся в виде кода в памяти компьютера. В зависимости от типа клавиатуры и стандарта кодировки этот код может занимать разное количество бит.
Кодировка ASCII, которая используется для представления символов на клавишах стандартной американской раскладки, занимает один байт или 8 бит. Таким образом, вес одного символа на такой клавиатуре составляет 8 бит или 1 байт.
В то же время, для других языков и кодировок, таких как Unicode, код символа может занимать больше места в памяти компьютера. Например, для китайского языка используется стандарт GB2312, который использует два байта на символ. Следовательно, вес одного символа на клавиатуре для китайского языка будет составлять 16 бит или 2 байта.
- ASCII: 8 бит или 1 байт на символ
- Unicode: от 8 до 32 бит на символ в зависимости от стандарта кодировки
- Китайский язык: 16 бит или 2 байта на символ
Таким образом, ответ на вопрос «сколько весит один символ на клавиатуре» зависит от типа клавиатуры и используемой кодировки. В среднем, вес символа на стандартной клавиатуре составляет 8 бит или 1 байт.
Сколько весит один пробел
В процессе программирования и верстки веб-страниц возникают вопросы веса отдельных символов, таких как пробелы, буквы, цифры и знаки препинания.
Один пробел в коде занимает всего лишь 1 байт, что эквивалентно 8 битам.
В современных компьютерах при обработке текста один пробел обычно не составляет большой проблемы для памяти. Однако, применение множества пробелов в тексте, особенно в больших объемах, может значительно увеличить размер файлов и снизить быстродействие веб-сайта.
Так же стоит учитывать, что размер пробела может изменяться в зависимости от используемого шрифта. Например, в моноширинных шрифтах, каждый символ имеет одинаковую ширину, в то время как в других шрифтах размер пробела может быть разным.
Вес символа в строке: сколько места он занимает в памяти компьютера
Каждый символ в строке занимает определенный объем памяти в компьютере. Этот объем зависит от используемой системы кодирования символов. Самым распространенным является кодировка ASCII, которая отображает каждый символ на 8 бит (или 1 байт) памяти. Таким образом, каждый символ ASCII занимает ровно 1 байт в памяти компьютера.
Однако, в других кодировках вес символа может быть больше. Например, кодировка Unicode отображает каждый символ на 16 бит (или 2 байта) памяти. Таким образом, каждый символ Unicode занимает 2 раза больше места, чем символ ASCII. Это означает, что использование Unicode может привести к более быстрому заполнению жесткого диска или уменьшению доступной памяти для программ.
Также вес символа может зависеть от формата файла, в котором он хранится. Некоторые форматы файлов, например, текстовые документы, могут использовать сжатие данных, чтобы уменьшить размер файла. В этом случае, размер каждого символа может быть еще меньше, чем если бы он хранился в некомпрессированной форме.
В целом, размер символа в строке может иметь значительное значение при работе с большими файлами или приложениями. Чем меньше объем памяти занимает каждый символ, тем больше информации может быть сохранено в компьютере. Это может быть особенно важно для мобильных приложений или устройств с ограниченной памятью. Поэтому, выбор правильной системы кодирования или формата файла может быть критически важным для эффективной работы с текстом и данными в целом.
Сколько памяти занимает кодировка символа в таблице Unicode?
Unicode — это универсальная система кодирования символов, которая назначает каждому символу уникальный номер. В данной системе существует более 143 тыс. символов, включая символы разных языков и пиктограммы. Каждый символ в Unicode занимает два байта (16 бит), что немного больше по сравнению с кодировкой ASCII, которая занимает 1 байт (8 бит) на символ.
Количество места, занимаемого для кодирования 1 символа в таблице Unicode, может различаться в зависимости от конкретного типа кодировки. Например, в UTF-8 количество места, задействованных для кодирования символа, зависит от типа самого символа. Если символу ASCII соответствует 1 байт, то более сложные символы занимают более 2 байт или даже 3-4 байта.
В целом, Unicode является более универсальным стандартом для кодирования символов и обеспечивает более широкий диапазон символов и языков, чем ASCII или другие, более узконаправленные системы кодирования.
| Кодировка | Размер символа |
|---|---|
| ASCII | 1 байт (8 бит) |
| Unicode | 2 байта (16 бит) |
| UTF-8 | 1-4 байта (8-32 бита) |
Сколько символов есть в различных кодировках
Каждый символ представлен в компьютерных системах определенным числовым значением. Однако, различные кодировки могут использовать разное количество бит и байт для представления одного и того же символа.
Самая распространенная кодировка — ASCII, использует всего 7 бит для представления основных латинских символов, что соответствует 128 различным символам. Однако, с появлением необходимости использовать более разнообразные символы, были созданы более расширенные кодировки.
- UTF-8 — самая популярная кодировка, используемая в Интернете. Она способна хранить до 1 112 064 различных символов и большинство символов кодируются всего одним байтом.
- UTF-16 — кодировка, использующая 2 байта для кодирования символов, способна хранить до 65 536 различных символов.
- UTF-32 — самая «тяжелая» кодировка, использующая 4 байта для хранения символов. Позволяет хранить до 4 294 967 296 символов.
Кроме того, некоторые языки имеют свои собственные кодировки, например, китайский язык использует кодировку GB2312, которая способна хранить более 6 000 символов китайского иероглифа.
| Кодировка | Количество символов | Размер символа (байт) |
|---|---|---|
| ASCII | 128 | 1 |
| UTF-8 | 1 112 064 | 1-4 |
| UTF-16 | 65 536 | 2 |
| UTF-32 | 4 294 967 296 | 4 |
Выбор кодировки зависит от конкретных задач, необходимости использования определенных символов и поддержки кодировки в используемых программных средствах.
Информационная емкость символа: сколько места нужно для кодирования?
Когда мы пишем текст на компьютере, для каждого символа нужен соответствующий код, чтобы компьютер мог его обработать и хранить в памяти. Но какое количество информации нужно для кодирования одного символа?
Ответ на этот вопрос не так прост, как может показаться на первый взгляд. В зависимости от системы кодирования, количество бит, необходимых для представления одного символа, может варьироваться. Например, в ASCII каждый символ кодируется одним байтом (8 битами), в то время как в Unicode для некоторых символов может понадобиться два и более байта.
Кроме того, информационная емкость символа может быть разной в зависимости от контекста. В текстовых документах, где символы используются в алфавитном порядке, информационная емкость символа будет ниже, чем в случае использования символов в качестве ключей шифрования или в компьютерной графике.
Таким образом, ответ на вопрос о том, сколько места в памяти компьютера занимает код одного символа, зависит от различных факторов, включая систему кодирования, тип используемого символа и контекст его использования.
- ASCII – 1 байт (8 бит)
- Unicode – от 1 до 4 байт (8–32 бит)
- UTF-8 – от 1 до 4 байт (8–32 бит), в зависимости от символа
В итоге, количество информации, необходимое для кодирования одного символа, зависит от множества факторов и может изменяться в разных условиях использования.
Сколько весит один символ в Unicode 16?
Для эффективного хранения текстовой информации на компьютере необходимо знать, сколько памяти занимает каждый символ. В случае с Unicode 16 – это очень важно, потому что этот стандарт используется для хранения текста на множестве языков, включая китайский, японский и корейский.
Итак, сколько весит один символ в Unicode 16? Ответ – 2 байта (или 16 бит). Это означает, что каждый символ занимает 2 раза больше места, чем в ASCII-кодировке, где каждый символ весит всего 1 байт (8 бит).
Это также означает, что размер Unicode-текста может быть в два раза больше, чем текст, закодированный в ASCII. Например, если у вас есть текст на русском языке, который занимает 1 КБ в ASCII-кодировке, то при перекодировании в Unicode 16, он займет уже 2 КБ памяти.
Таким образом, если вы работаете с текстом на разных языках, использующих разные символы, обязательно учитывайте, что каждый символ в Unicode 16 занимает 2 байта.
Сколько байт занимает один символ в UTF-8?
Кодировка UTF-8 используется наиболее широко в Интернет-технологиях, таких как HTML, CSS, JavaScript. Она предоставляет универсальный механизм кодирования символов для любых языков мира. Однако, размер одного символа в UTF-8 зависит от используемого символа.
Если это символ латинского алфавита (например, буква «a»), то он занимает 1 байт. Однако, если это символ из другого языка, например, китайского или японского алфавитов, то его размер будет варьироваться от 3 до 4 байтов.
Более сложные символы в UTF-8 могут занимать до 6 байтов. Некоторые символы, такие как символы эмодзи (смайлики), занимают 4 байта. Поэтому, при разработке программных продуктов и веб-приложений необходимо учитывать размер каждого символа в UTF-8, чтобы избежать проблем с производительностью или размером файла.
UTF-8: сколько весит один символ?
UTF-8 – это стандарт кодировки символов, который используется в большинстве современных операционных систем и приложений. Он поддерживает более 100 000 различных символов, включая буквы разных алфавитов, цифры, знаки препинания, символы математических операций и т.д.
Для кодирования символов в UTF-8 применяются переменные длины кодов – это означает, что длина кода может быть разной для разных символов. Но в среднем, один символ в UTF-8 занимает 1-4 байта (8-32 бита).
Для английских букв, цифр и некоторых знаков препинания код UTF-8 занимает 1 байт – т.е. 8 бит. Для кириллических букв – 2 байта (16 бит), для японских и китайских иероглифов – 3 байта (24 бита), для эмодзи – 4 байта (32 бита).
Стоит отметить, что размер символа в памяти компьютера не всегда соответствует его физическому размеру – например, если символы хранятся в сжатом формате, их размер может быть сильно уменьшен.
В целом, один символ в UTF-8 не занимает много места в памяти компьютера, а благодаря разнообразию кодировки, ее можно использовать для отображения символов на разных языках и в разных культурах.
Отзывы
Михаил Сергеев
Обычно, я не обращаю внимания на технические детали в работе компьютера, но эта статья заставила меня задуматься. Я действительно удивлен тем, что каждый символ занимает разный объем памяти. Неожиданно выяснить, что некоторые символы могут занимать до 8 байт, в то время как другие — только 1 байт. Однако, у статьи есть и недостатки. Например, мне кажется, что она слишком сжата. Я хотел бы узнать больше о том, как файловые форматы влияют на размер символа в памяти. Может быть, использование изображений, таблиц или других специальных символов также может изменить их размер? В целом, я доволен, что прочел эту статью. Я получил много новой информации и остался с большим количеством вопросов. Я надеюсь, что буду иметь возможность продолжить изучение темы и сделать свои выводы на основе полученных знаний.
Дмитрий
Статья действительно важна для программистов, однако, мне кажется, она может быть более подробной. Я бы желал узнать, почему определенные символы требуют больше места в памяти, а другие — меньше. Несмотря на это, статья все же содержит много полезной информации, и я заинтересован в дальнейшем изучении темы.
Vox
Интересная статья, но хотелось бы узнать больше деталей о том, сколько места занимает код не только одного символа, но и целой строки текста.
Maximus
Интересная статья, но я думал, что ответ будет более предсказуемым. В целом, я доволен, что узнал новое информацию.
Артём Иванов
Спасибо автору за полезную статью! Очень интересно узнать, что каждый символ занимает разную память в зависимости от типа кодировки. Теперь понятно, почему сохранение файла в разных форматах может сильно влиять на его размер. Однако хотелось бы добавить, что помимо текста, в памяти компьютера занимают место и другие типы данных, такие как изображения и видео. Было бы интересно узнать, сколько места они занимают на диске в зависимости от их разрешения и формата.
Иван
Статья очень познавательная и полезная для тех, кто интересуется компьютерной тематикой. Хотелось бы отметить, что объем памяти, занимаемый одним символом, может быть существенным при работе с массивами большого объема. Например, если мы сохраняем в таблицу базы данных миллионы записей, каждая из которых содержит десятки символов текста, то даже небольшое увеличение объема памяти, занимаемой каждым символом, может значительно увеличить общий объем использованной памяти. Однако, хотелось бы подчеркнуть, что не только текстовые данные занимают место в памяти. Мы живем в эпоху высоких технологий, и сегодня самыми популярными типами данных являются изображения и видео. При этом, объем памяти, занимаемый этими данными, может быть колоссальным. Например, если мы сохраняем в базу данных большие изображения или видеофайлы, то даже небольшое увеличение объема каждого файла может привести к серьезному увеличению общего объема использованной памяти. Поэтому, при проектировании и разработке программного обеспечения необходимо учитывать не только объем данных, а также их тип и формат. Правильное использование кодировок и форматов позволит значительно оптимизировать работу программы и уменьшить объем занимаемой памяти. Очень надеюсь, что автор продолжит писать на эту тему, раскрывая все новые и интересные аспекты компьютерной технологии.
Представление символов, таблицы кодировок
В вычислительных машинах символы не могут храниться иначе, как в виде последовательностей бит (как и числа). Для передачи символа и его корректного отображения ему должна соответствовать уникальная последовательность нулей и единиц. Для этого были разработаны таблицы кодировок.
Количество символов, которые можно задать последовательностью бит длины [math]n[/math] , задается простой формулой [math]C(n) = 2^n[/math] . Таким образом, от нужного количества символов напрямую зависит количество используемой памяти.
Таблицы кодировок
На заре компьютерной эры на каждый символ было отведено по пять бит. Это было связано с малым количеством оперативной памяти на компьютерах тех лет. В эти [math]32[/math] символа входили только управляющие символы и строчные буквы английского алфавита.
С ростом производительности компьютеров стали появляться таблицы кодировок с большим количеством символов. Первой семибитной кодировкой стала ASCII7. В нее уже вошли прописные буквы английского алфавита, арабские цифры, знаки препинания. Затем на ее базе была разработана ASCII8, в которым уже стало возможным хранение [math]256[/math] символов: [math]128[/math] основных и еще столько же расширенных. Первая часть таблицы осталась без изменений, а вторая может иметь различные варианты (каждый имеет свой номер). Эта часть таблицы стала заполняться символами национальных алфавитов.
Но для многих языков (например, арабского, японского, китайского) [math]256[/math] символов недостаточно, поэтому развитие кодировок продолжалось, что привело к появлению UNICODE.
Кодировки стандарта ASCII
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа [math]n = 8[/math] бит. |
- ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского алфавита и служебных символов, содержит большие буквы английского языка, цифры, знаки препинания и другие символы.
Кодировки стандарта ASCII ( [math]8[/math] бит):
- ASCII — первая кодировка, в которой стало возможно использовать символы национальных алфавитов.
- КОИ8-R — первая русская кодировка. Символы кириллицы расположены не в алфавитном порядке. Их разместили в верхнюю половину таблицы так, чтобы позиции кириллических символов соответствовали их фонетическим аналогам в английском алфавите. Это значит, что даже при потере старшего бита каждого символа, например, при проходе через устаревший семибитный модем, текст остается «читаемым».
- CP866 — русская кодировка, использовавшаяся на компьютерах IBM в системе DOS.
- Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
Структурные свойства таблицы
- Цифры 0-9 представляются своими двоичными значениями (например, [math]5=0101_2[/math] ), перед которыми стоит [math]0011_2[/math] . Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева [math]0011_2[/math] к каждому двоично-десятичному полубайту.
- Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в двоичной системе счисления, перед которыми стоит [math]0100_2[/math] (для букв верхнего регистра) или [math]0110_2[/math] (для букв нижнего регистра).
Кодировки стандарта UNICODE
Юникод или Уникод (англ. Unicode) — это промышленный стандарт обеспечивающий цифровое представление символов всех письменностей мира, и специальных символов.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.). Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей. Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set) и семейство кодировок (англ. UTF, Unicode transformation format). Универсальный набор символов задаёт однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа.Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F. Часть кодов зарезервирована для использования в будущем.
Кодовое пространство
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до [math]2^<31>[/math] [math](2\ 147\ 483\ 648)[/math] кодовых позиций, было принято решение использовать лишь [math]1\ 112\ 064[/math] для совместимости с UTF-16. Впрочем, даже и этого на текущий момент более чем достаточно — в версии 6.0 используется чуть менее [math]110\ 000[/math] кодовых позиций ( [math]109\ 242[/math] графических и [math]273[/math] прочих символов).
Кодовое пространство разбито на [math]17[/math] плоскостей (англ. planes) по [math]2^<16>[/math] [math](65\ 536)[/math] символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей, вторая — для для редко используемых иероглифов китайского письма, третья зарезервирована для архаичных китайских иероглифов. Плоскости [math]15[/math] и [math]16[/math] выделены для частного употребления.
Для обозначения символов Unicode используется запись вида «U+xxxx» (для кодов [math]0000_<16>..FFFF_<16>[/math] ) или «U+xxxxx» (для кодов [math]10000_<16>..FFFFF_<16>[/math] ) или «U+xxxxxx» (для кодов [math]100000_<16>..10FFFF_<16>[/math] ), где xxx — шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код [math]044F_ <16>= 1103_<10>[/math] .
| Плоскости Юникода | ||
|---|---|---|
| Плоскость | Название | Диапазон символов |
| Plane 0 | Basic multilingual plane (BMP) | U+0000…U+FFFF |
| Plane 1 | Supplementary multilingual plane (SMP) | U+10000…U+1FFFF |
| Plane 2 | Supplementary ideographic plane (SIP) | U+20000…U+2FFFF |
| Planes 3-13 | Unassigned | U+30000…U+DFFFF |
| Plane 14 | Supplementary special-purpose plane (SSP) | U+E0000…U+EFFFF |
| Planes 15-16 | Supplementary private use area (S PUA A/B) | U+F0000…U+10FFFF |
Модифицирующие символы
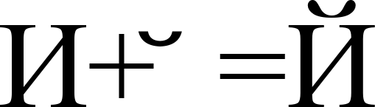
Графические символы в Юникоде делятся на протяжённые и непротяжённые. Непротяжённые символы при отображении не занимают дополнительного места в строке. К примеру, к ним относятся знак ударения. Протяжённые и непротяжённые символы имеют собственные коды, но последние не могут встречаться самостоятельно. Протяжённые символы называются базовыми (англ. base characters), а непротяженные — модифицирующими (англ. combining characters). Например символ «Й» (U+0419) может быть представлен в виде базового символа «И» (U+0418) и модифицирующего символа « ̆» (U+0306).
Способы представления
Юникод имеет несколько форм представления (англ. Unicode Transformation Format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт.
UTF-8 — представление Юникода, обеспечивающее наилучшую совместимость со старыми системами, использовавшими [math]8[/math] -битные символы. Текст, состоящий только из символов с номером меньше [math]128[/math] , при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше [math]128[/math] изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от двух до шести байт (на деле, только до четырех байт, поскольку в Юникоде нет символов с кодом больше [math]10FFFF_<16>[/math] , и вводить их в будущем не планируется), в которых первый байт всегда имеет вид [math]11xxxxxx[/math] , а остальные — [math]10xxxxxx[/math] .
Символы UTF-8 получаются из Unicode cледующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
| 0x00000000 — 0x0000007F | 0xxxxxxx | ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры |
| 0x00000080 — 0x000007FF | 110xxxxx 10xxxxxx | кириллица, расширенная латиница, арабский алфавит, армянский алфавит, греческий алфавит, еврейский алфавит и коптский алфавит; сирийское письмо, тана, нко; Международный фонетический алфавит; некоторые знаки препинания |
| 0x00000800 — 0x0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx | все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
| 0x00010000 — 0x001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
| 111111xx | служебные символы c, d, e, f |
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы, называемые overlong sequence, отвергаются по соображениям безопасности.
Принцип кодирования
Правила записи кода одного символа в UTF-8
1. Если размер символа в кодировке UTF-8 = [math]1[/math] байт
Код имеет вид (0aaa aaaa), где «0» — просто ноль, остальные биты «a» — это код символа в кодировке ASCII;
2. Если размер символа в кодировке в UTF-8 [math]\gt 1[/math] байт (то есть от [math]2[/math] до [math]6[/math] ):
2.1 Первый байт содержит количество байт символа, закодированное в единичной системе счисления; 2.2 «0» — бит терминатор, означающий завершение кода размера 2.3 далее идут значащие байты кода, которые имеют вид (10xx xxxx), где «10» — биты признака продолжения, а «x» — значащие биты.
В общем случае варианты представления одного символа в кодировке UTF-8 выглядят так:
Определение длины кода в UTF-8
| Количество байт UTF-8 | Количество значащих бит |
|---|---|
| [math]1[/math] | [math]7[/math] |
| [math]2[/math] | [math]11[/math] |
| [math]3[/math] | [math]16[/math] |
| [math]4[/math] | [math]21[/math] |
| [math]5[/math] | [math]26[/math] |
| [math]6[/math] | [math]31[/math] |
В общем случае количество значащих бит [math]C[/math] , кодируемых [math]n[/math] байтами UTF-8, определяется по формуле:
[math]C = 7[/math] при [math]n=1[/math]
[math]C = n\cdot5+1[/math] при [math]n\gt 1[/math]
UTF-16
UTF-16 — один из способов кодирования символов (англ. code point) из Unicode в виде последовательности [math]16[/math] -битных слов (англ. code unit). Данная кодировка позволяет записывать символы Юникода в диапазонах U+0000..U+D7FF и U+E000..U+10FFFF (общим количеством [math]1\ 112\ 064[/math] ), причем [math]2[/math] -байтные символы представляются как есть, а более длинные — с помощью суррогатных пар (англ. surrogate pair), для которых и вырезан диапазон [math]D800_<16>..DFFF_<16>[/math] .
В UTF-16 символы кодируются двухбайтовыми словами с использованием всех возможных диапазонов значений (от [math]0000_<16>[/math] до [math]FFFF_<16>[/math] ). При этом можно кодировать символы Unicode в диапазонах [math]0000_<16>..D7FF_<16>[/math] и [math]E000_<16>..10FFFF_<16>[/math] . Исключенный отсюда диапазон [math]D800_<16>..DFFF_<16>[/math] используется как раз для кодирования так называемых суррогатных пар — символов, которые кодируются двумя [math]16[/math] -битными словами. Символы Unicode до [math]FFFF_<16>[/math] включительно (исключая диапазон для суррогатов) записываются как есть [math]16[/math] -битным словом. Символы же в диапазоне [math]10000_<16>..10FFFF_<16>[/math] (больше [math]16[/math] бит) уже кодируются парой [math]16[/math] -битных слов. Для этого их код арифметически сдвигается до нуля (из него вычитается минимальное число [math]10000_<16>[/math] ). В результате получится значение от нуля до [math]FFFFF_<16>[/math] , которое занимает до [math]20[/math] бит. Старшие [math]10[/math] бит этого значения идут в лидирующее (первое) слово, а младшие [math]10[/math] бит — в последующее (второе). При этом в обоих словах старшие [math]6[/math] бит используются для обозначения суррогата. Биты с [math]11[/math] по [math]15[/math] имеют значения [math]11011_2[/math] , а [math]10[/math] -й бит содержит [math]0[/math] у лидирующего слова и [math]1[/math] — у последующего. В связи с этим можно легко определить к чему относится каждое слово.
UTF-16LE и UTF-16BE
Один символ кодировки UTF-16 представлен последовательностью двух байт или двух пар байт. Который из двух байт в словах идёт впереди, старший или младший, зависит от порядка байт. Подробнее об этом будет сказано ниже.
UTF-32
UTF-32 — один из способов кодирования символов из Юникод, использующий для кодирования любого символа ровно [math]32[/math] бита. Остальные кодировки, UTF-8 и UTF-16, используют для представления символов переменное число байт. Символ UTF-32 является прямым представлением его кодовой позиции (англ. code point).
Главное преимущество UTF-32 перед кодировками переменной длины заключается в том, что символы Юникод непосредственно индексируемы. Получение [math]n[/math] -ой кодовой позиции является операцией, занимающей одинаковое время. Напротив, коды с переменной длиной требует последовательного доступа к [math]n[/math] -ой кодовой позиции. Это делает замену символов в строках UTF-32 простой, для этого используется целое число в качестве индекса, как обычно делается для строк ASCII.
Главный недостаток UTF-32 — это неэффективное использование пространства, так как для хранения символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства не оправдано.
Хотя использование неменяющегося числа байт на символ удобно, но не настолько, как кажется. Операция усечения строк реализуется легче в сравнении с UTF-8 и UTF-16. Но это не делает более быстрым нахождение конкретного смещения в строке, так как смещение может вычисляться и для кодировок фиксированного размера. Это не облегчает вычисление отображаемой ширины строки, за исключением ограниченного числа случаев, так как даже символ «фиксированной ширины» может быть получен комбинированием обычного символа с модифицирующим, который не имеет ширины. Например, буква «й» может быть получена из буквы «и» и диакритического знака «крючок над буквой». Сочетание таких знаков означает, что текстовые редакторы не могут рассматривать [math]32[/math] -битный код как единицу редактирования. Редакторы, которые ограничиваются работой с языками с письмом слева направо и составными символами (англ. Precomposed character), могут использовать символы фиксированного размера. Но такие редакторы вряд ли поддержат символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства и вряд ли смогут работать одинаково хорошо с символами UTF-16.
Порядок байт
В современной вычислительной технике и цифровых системах связи информация обычно представлена в виде последовательности байт. В том случае, если число не может быть представлено одним байтом, имеет значение в каком порядке байты записываются в памяти компьютера или передаются по линиям связи. Часто выбор порядка записи байт произволен и определяется только соглашениями.
В общем случае, для представления числа [math]M[/math] , большего [math]255[/math] (здесь [math]255=2^8-1[/math] — максимальное целое число, записываемое одним байтом), приходится использовать несколько байт. При этом число [math]M[/math] записывается в позиционной системе счисления по основанию [math]256[/math] :
[math]M = \sum_
Набор целых чисел [math]A_0,\dots,A_n[/math] , каждое из которых лежит в интервале от [math]0[/math] до [math]255[/math] , является последовательностью байт, составляющих [math]M[/math] . При этом [math]A_0[/math] называется младшим байтом, а [math]A_n[/math] — старшим байтом числа [math]M[/math] .
Варианты записи
Порядок от старшего к младшему
Порядок от старшего к младшему (англ. big-endian): [math]A_n,\dots,A_0[/math] , запись начинается со старшего и заканчивается младшим. Этот порядок является стандартным для протоколов TCP/IP, он используется в заголовках пакетов данных и во многих протоколах более высокого уровня, разработанных для использования поверх TCP/IP. Поэтому, порядок байт от старшего к младшему часто называют сетевым порядком байт (англ. network byte order). Этот порядок байт используется процессорами IBM 360/370/390, Motorola 68000, SPARC (отсюда третье название — порядок байт Motorola, Motorola byte order).
В этом же виде (используя представление в десятичной системе счисления) записываются числа индийско-арабскими цифрами в письменностях с порядком знаков слева направо (латиница, кириллица). Для письменностей с обратным порядком (арабская) та же запись числа воспринимается как «от младшего к старшему».
Порядок байт от старшего к младшему применяется во многих форматах файлов — например, PNG, FLV, EBML.
Порядок от младшего к старшему
Порядок от младшего к старшему (англ. little-endian): [math]A_0,\dots,A_n[/math] , запись начинается с младшего и заканчивается старшим. Этот порядок записи принят в памяти персональных компьютеров с x86-процессорами, в связи с чем иногда его называют интеловский порядок байт (по названию фирмы-создателя архитектуры x86).
В противоположность порядку big-endian, соглашение little-endian поддерживают меньше кросс-платформенных протоколов и форматов данных; существенные исключения: USB, конфигурация PCI, таблица разделов GUID, рекомендации FidoNet.
Переключаемый порядок
Многие процессоры могут работать и в порядке от младшего к старшему, и в обратном, например, ARM, PowerPC (но не PowerPC 970), DEC Alpha, MIPS, PA-RISC и IA-64. Обычно порядок байт выбирается программно во время инициализации операционной системы, но может быть выбран и аппаратно перемычками на материнской плате. В этом случае правильнее говорить о порядке байт операционной системы. Переключаемый порядок байт иногда называют англ. bi-endian.
Смешанный порядок
Смешанный порядок байт (англ. middle-endian) иногда используется при работе с числами, длина которых превышает машинное слово. Число представляется последовательностью машинных слов, которые записываются в формате, естественном для данной архитектуры, но сами слова следуют в обратном порядке.
Классический пример middle-endian — представление [math]4[/math] -байтных целых чисел на [math]16[/math] -битных процессорах семейства PDP-11 (известен как PDP-endian). Для представления двухбайтных значений (слов) использовался порядок little-endian, но [math]4[/math] -хбайтное двойное слово записывалось от старшего слова к младшему.
В процессорах VAX и ARM используется смешанное представление для длинных вещественных чисел.
Различия

Существенным достоинством little-endian по сравнению с big-endian порядком записи считается возможность «неявной типизации» целых чисел при чтении меньшего объёма байт (при условии, что читаемое число помещается в диапазон). Так, если в ячейке памяти содержится число [math]00000022_<16>[/math] , то прочитав его как int16 (два байта) мы получим число [math]0022_<16>[/math] , прочитав один байт — число [math]22_<16>[/math] . Однако, это же может считаться и недостатком, потому что провоцирует ошибки потери данных.
Обратно, считается что у little-endian, по сравнению с big-endian есть «неочевидность» значения байт памяти при отладке (последовательность байт (A1, B2, C3, D4) на самом деле значит [math]D4C3B2A1_<16>[/math] , для big-endian эта последовательность (A1, B2, C3, D4) читалась бы «естественным» для арабской записи чисел образом: [math]A1B2C3D4_<16>[/math] ). Наименее удобным в работе считается middle-endian формат записи; он сохранился только на старых платформах.
Для записи длинных чисел (чисел, длина которых существенно превышает разрядность машины) обычно предпочтительнее порядок слов в числе little-endian (поскольку арифметические операции над длинными числами производятся от младших разрядов к старшим). Порядок байт в слове — обычный для данной архитектуры.
Маркер последовательности байт
Для определения формата представления Юникода в начало текстового файла записывается сигнатура — символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый маркером последовательности байт (англ. byte order mark (BOM)). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует.
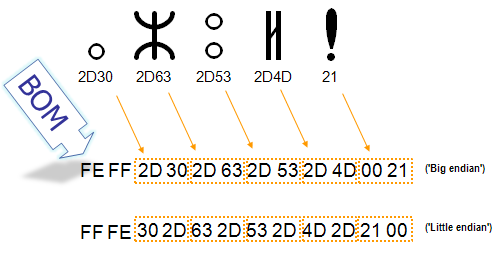
| Кодирование | Представление (Шестнадцатеричное) |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16 (BE) | FE FF |
| UTF-16 (LE) | FF FE |
| UTF-32 (BE) | 00 00 FE FF |
| UTF-32 (LE) | FF FE 00 00 |
В кодировке UTF-8, наличие BOM не является существенным, поскольку, нет альтернативной последовательности байт. Когда BOM используется на страницах или редакторах для контента закодированного в UTF-8, иногда он может представить пробелы или короткие последовательности символов, имеющие странный вид (такие как ). Именно поэтому, при наличии выбора, для совместимости, как правило, лучше упустить BOM в UTF-8 контенте.Однако BOM могут еще встречаться в тексте закодированном в UTF-8, как побочный продукт перекодирования или потому, что он был добавлен редактором. В этом случае BOM часто называют подписью UTF-8.
Когда символ закодирован в UTF-16, его [math]2[/math] или [math]4[/math] байта можно упорядочить двумя разными способами (little-endian или big-endian). Изображение справа показывает это. Byte order mark указывает, какой порядок используется, так что приложения могут немедленно расшифровать контент. UTF-16 контент должен всегда начинатся с BOM.
BOM также используется для текста обозначенного как UTF-32. Аналогично UTF-16 существует два варианта четырёхбайтной кодировки — UTF-32BE и UTF-32LE. К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом
Проблемы Юникода
В Юникоде английское «a» и польское «a» — один и тот же символ. Точно так же одним символом (но отличающимся от «a» латинского) считаются русское «а» и сербское «а». Такой принцип кодирования не универсален; по-видимому, решения «на все случаи жизни» вообще не может существовать.
Примеры
Если записать строку ‘hello мир’ в файл exampleBOM, а затем сделать его hex-дамп, то можно убедиться в том, что разные символы кодируются разным количеством байт. Например, английские буквы,пробел, знаки препинания и пр. кодируются одним байтом, а русские буквы — двумя
Подробнее о единицах измерения количества информации

Данные и их хранение необходимы для работы компьютеров и цифровой техники. Данные — это любая информация, от команд до файлов, созданных пользователями, например текст или видео. Данные могут храниться в разных форматах, но чаще всего их сохраняют как двоичный код. Некоторые данные хранятся временно и используются только во время исполнения определенных операций, а потом удаляются. Их записывают на устройствах временного хранения информации, например, в оперативной памяти, известной под названием запоминающего устройства с произвольным доступом (по-английски, RAM — Random Access Memory) или ОЗУ — оперативное запоминающее устройство. Некоторую информацию хранят дольше. Устройства, обеспечивающие более длительное хранение — это жесткие диски, твердотельные накопители, и различные внешние накопители.
Подробнее о данных
Данные представляют собой информацию, которая хранится в символьной форме и может быть считана компьютером или человеком. Бо́льшая часть данных, предназначенных для компьютерного доступа, хранится в файлах. Некоторые из этих файлов — исполняемые, то есть они содержат программы. Файлы с программами обычно не считают данными.
Избыточность
Во избежание потери данных при поломках используют принцип избыточности, то есть хранят копии данных в разных местах. Если эти данные перестанут читаться в одном месте, то их можно будет считать в другом. На этом принципе основывается работа избыточного массива независимых дисков RAID (от английского reduntant array of independent discs). В нем копии данных хранятся на двух или более дисках, объединенных в один логический блок. В некоторых случаях для большей надежности копируют сам RAID-массив. Копии иногда хранят отдельно от основного массива, иногда в другом городе или даже в другой стране, на случай уничтожения массива во время катаклизмов, катастроф, или войн.
Форматы хранения данных
Иерархия хранения данных
Данные обрабатываются в центральном процессоре, и чем ближе к процессору устройство, которое их хранит, тем быстрее их можно обработать. Скорость обработки данных также зависит от вида устройства, на котором они хранятся. Пространство внутри компьютера рядом с микропроцессором, где можно установить такие устройства, ограничено, и обычно самые быстрые, но маленькие устройства находятся ближе всего к микропроцессору, а те, что больше но медленнее — дальше от него. Например, регистр внутри процессора очень мал, но позволяет считывать данные со скоростью одного цикла процессора, то есть, в течение нескольких миллиардных долей секунды. Эти скорости с каждым годом улучшаются.

Первичная память
Первичная память включает память внутри процессора — кэш и регистры. Это — самая быстрая память, то есть время доступа к ней — самое низкое. Оперативная память также считается первичной памятью. Она намного медленнее регистров, но ее емкость гораздо больше. Процессор имеет к ней прямой доступ. В оперативную память записываются текущие данные, постоянно используемые для работы выполняемых программ.
Вторичная память
Устройства вторичной памяти, например накопитель на жестких магнитных дисках (НЖМД) или винчестер, находятся внутри компьютера. На них хранятся данные, которые не так часто используются. Они хранятся дольше, и не удаляются автоматически. В основном их удаляют сами пользователи или программы. Доступ к этим данным происходит медленнее, чем к данным в первичной памяти.
Внешняя память
Внешнюю память иногда включают во вторичную память, а иногда — относят в отдельную категорию памяти. Внешняя память — это сменные носители, например оптические (CD, DVD и Blu-ray), Flash-память, магнитные ленты и бумажные носители информации, такие как перфокарты и перфоленты. Оператору необходимо вручную вставлять такие носители в считывающие устройства. Эти носители сравнительно дешевы по сравнению с другими видами памяти и их часто используют для хранения резервных копий и для обмена информацией из рук в руки между пользователями.
Третичная память
Третичная память включает в себя запоминающие устройства большого объема. Доступ к данным на таких устройствах происходит очень медленно. Обычно они используются для архивации информации в специальных библиотеках. По запросу пользователей механическая «рука» находит и помещает в считывающее устройство носитель с запрошенными данными. Носители в такой библиотеке могут быть разные, например оптические или магнитные.
Виды носителей

Оптические носители
Информацию с оптических носителей считывают в оптическом приводе с помощью лазера. Во время написания этой статьи (весна 2013 года) самые распространенные оптические носители — оптические диски CD, DVD, Blu-ray и Ultra Density Optical (UDO). Накопитель может быть один, или их может быть несколько, объединенных в одном устройстве, как например в оптических библиотеках. Некоторые оптические диски позволяют осуществлять повторную запись.
Полупроводниковые носители
Полупроводниковая память — одна из наиболее часто используемых видов памяти. Это вид памяти параллельного действия, позволяющий одновременный доступ к любым данным, независимо в какой последовательности эти данные были записаны.
Почти все первичные устройства памяти, а также устройства флеш-памяти — полупроводниковые. В последнее время в качестве альтернативы жестким дискам становятся более популярными твердотельные накопители SSD (от английского solid-state drives). Во время написания этой статьи эти накопители стоили намного дороже жестких дисков, но скорость записи и считывания информации на них значительно выше. При падениях и ударах они повреждаются намного меньше, чем магнитные жесткие диски, и работают практически безшумно. Кроме высокой цены, твердотельные накопители, по сравнению с магнитными жесткими дисками, со временем начинают работать хуже, и потерянные данные на них очень сложно восстановить, по сравнению с жесткими дисками. Гибридные жесткие диски совмещают твердотельный накопитель и магнитный жесткий диск, увеличивая тем самым скорость и срок эксплуатации, и уменьшая цену, по сравнению с твердотельными накопителями.

Магнитные носители
Поверхности для записи на магнитных носителях намагничиваются в определенной последовательности. Магнитная головка считывает и записывает на них данные. Примерами магнитных носителей являются накопители на жестких магнитных дисках и дискеты, которые уже почти полностью вышли из употребления. Аудио и видео также можно хранить на магнитных носителях — кассетах. Пластиковые карты часто хранят информацию на магнитных полосах. Это могут быть дебетовые и кредитные карты, карты-ключи в гостиницах, водительские права, и так далее. В последнее время в некоторые карты встраивают микросхемы. Такие карты обычно содержат микропроцессор и могут выполнять криптографические вычисления. Их называют смарт-картами.
Бумажные носители
До появления магнитных и других носителей данные хранили на бумаге. Обычно в таком виде были записаны машинные команды, и их могли читать как люди, так и машины, например компьютеры или ткацкие станки. В основном для этих целей использовали перфокарты и перфоленты, где информация хранилась в виде чередующихся отверстий, и отсутствия отверстий. Перфоленту использовали, чтобы записывать текст на телеграфе и в типографии или редакции газет, а также в кассовых аппаратах. Постепенно с конца 50-x и до конца 80-х их заменили магнитные носители. Сейчас бумажные носители используют для подсчета голосов на выборах и для автоматической проверки контрольных работ, ответы к которым записываются на специальную карту, а потом читаются компьютером.
Определить объём текста
Онлайн калькулятор легко и непринужденно вычислит объем текста в битах, байтах и килобайтах. Для перевода в другие единицы измерения данных воспользуйтесь онлайн конвертером.
Информационный вес (объем) символа текста определяется для следующих кодировок:
Unicode UTF-8
Unicode UTF-16
ASCII, ANSI, Windows-1251
Почему на windows сохраняя текст блокноте перенос строки занимает — 4 байта в юникоде или 2 байта в анси?
Это историческое явление, которое берёт начало с дос, последовательность OD OA (\n\r ) в виндовс используются чтоб был единообразный вывод на терминал независимо консоль это или принтер. Но для вывода просто на консоль достаточно только \n.
В юникоде есть символы которые весят 4 байта, например эмоджи: 🙃