Как рассчитать ранговую корреляцию Спирмена в Excel
В статистике корреляция относится к силе и направлению связи между двумя переменными. Значение коэффициента корреляции может варьироваться от -1 до 1 со следующими интерпретациями:
- -1: идеальная отрицательная связь между двумя переменными
- 0: нет связи между двумя переменными
- 1: идеальная положительная связь между двумя переменными
Один особый тип корреляции называется ранговой корреляцией Спирмена и используется для измерения корреляции между двумя ранжированными переменными. (например, оценка балла учащегося на экзамене по математике и оценка его оценки на экзамене по естественным наукам в классе).
В этом руководстве объясняется, как рассчитать ранговую корреляцию Спирмена между двумя переменными в Excel.
Пример: ранговая корреляция Спирмена в Excel
Выполните следующие шаги, чтобы вычислить ранговую корреляцию Спирмена между результатами экзамена по математике и результатами экзамена по естественным наукам 10 учащихся в определенном классе.
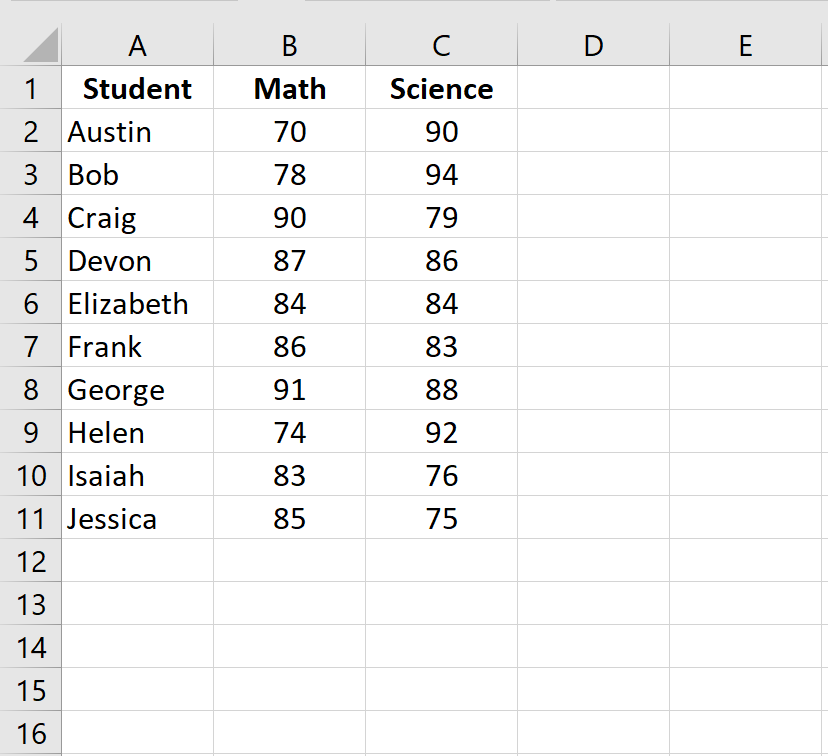
Шаг 1: Введите данные.
Введите экзаменационные баллы для каждого учащегося в два отдельных столбца:
Шаг 2: Рассчитайте ранги для каждого экзаменационного балла.
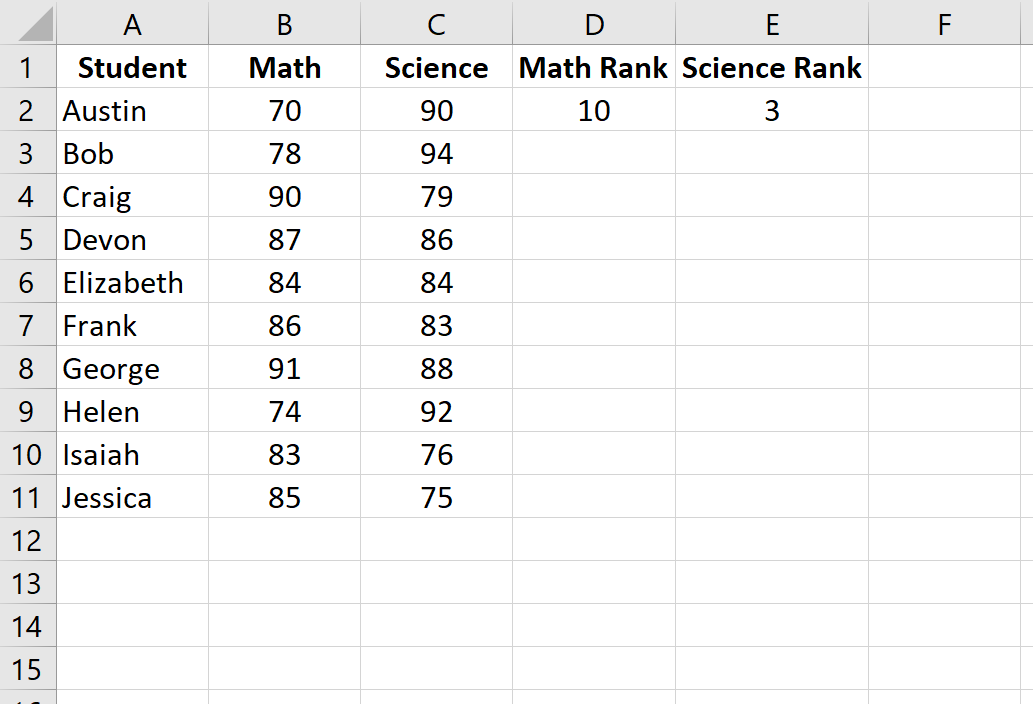
Далее мы рассчитаем рейтинг для каждого экзаменационного балла. Используйте следующие формулы в ячейках D2 и E2, чтобы вычислить рейтинги по математике и естественным наукам для первого ученика, Остина:
Ячейка D2: =RANK.AVG(B2, $B$2:$B$11, 0)
Ячейка E2: =RANK.AVG(C2, $C$2:$C$11, 0)
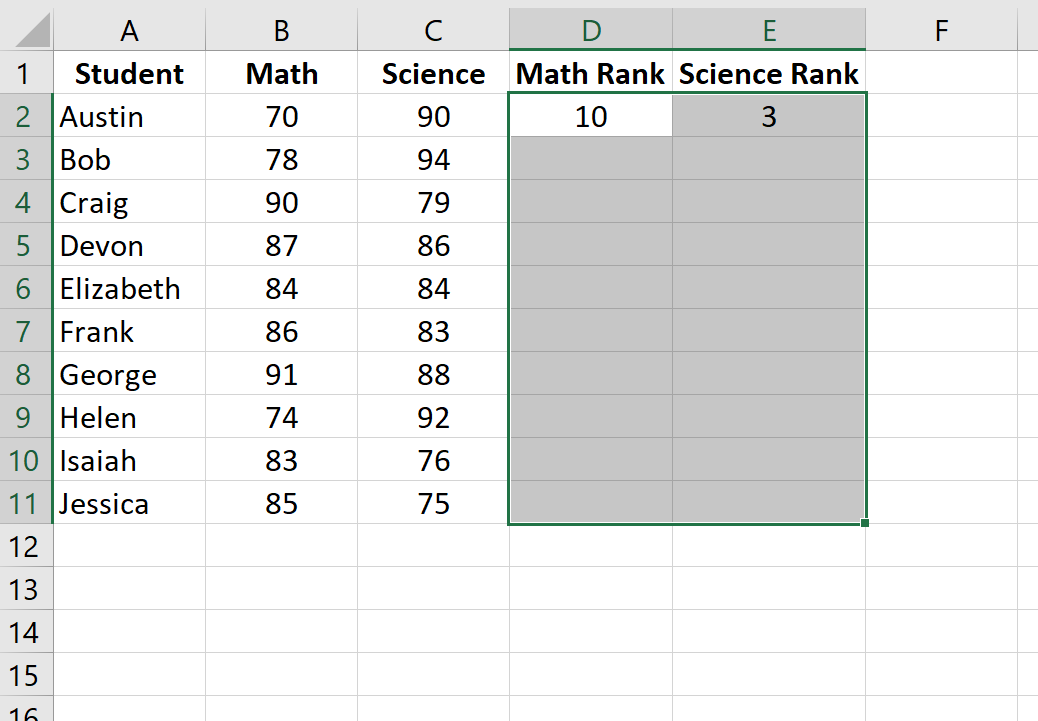
Затем выделите оставшиеся ячейки для заполнения:
Затем нажмите Ctrl+D, чтобы заполнить ранги для каждого ученика:
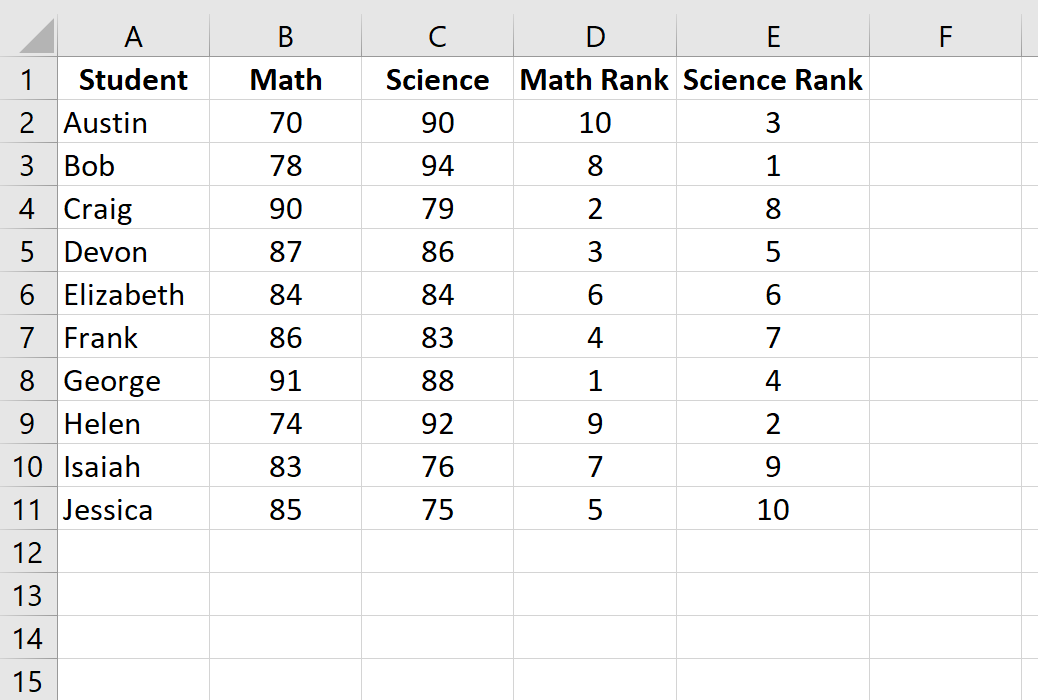
Шаг 3: Рассчитайте коэффициент ранговой корреляции Спирмена.
Наконец, мы рассчитаем коэффициент ранговой корреляции Спирмена между оценками по математике и по естественным наукам с помощью функции CORREL() :
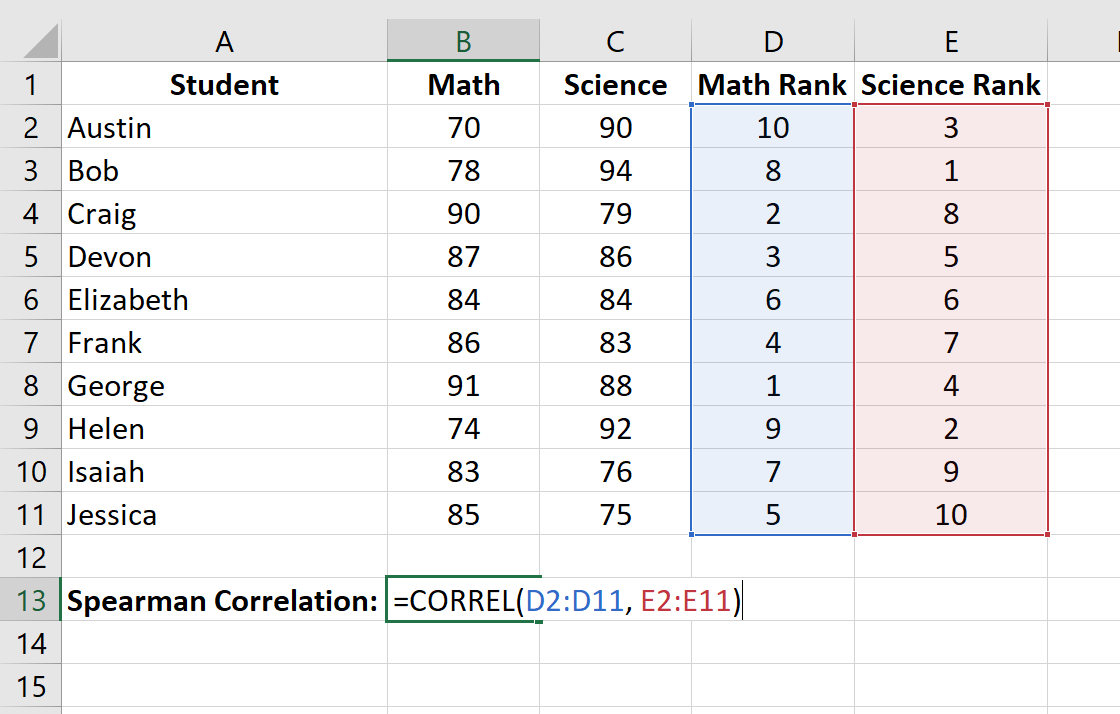
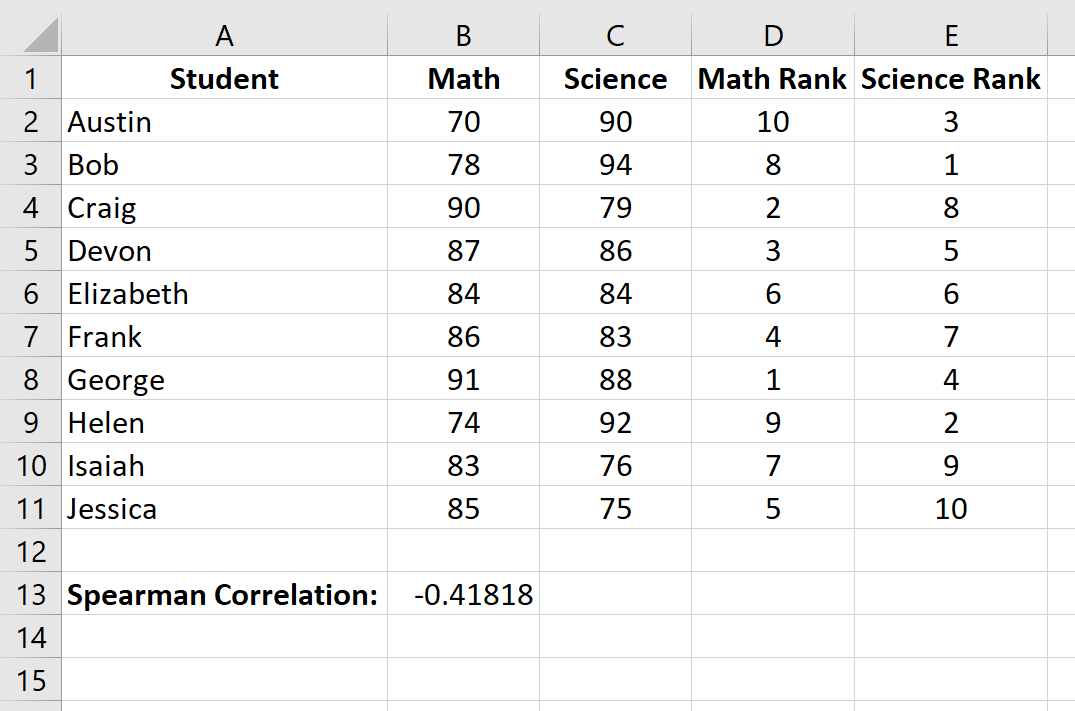
Ранговая корреляция Спирмена оказывается равной -0,41818 .
Шаг 4 (необязательно): Определите, является ли ранговая корреляция Спирмена статистически значимой.
На предыдущем шаге мы обнаружили, что ранговая корреляция Спирмена между результатами экзаменов по математике и естественным наукам составляет -0,41818 , что указывает на отрицательную корреляцию между двумя переменными.
Однако, чтобы определить, является ли эта корреляция статистически значимой, нам нужно будет обратиться к таблице ранговой корреляции Спирмена критических значений, которая показывает критические значения, связанные с различными размерами выборки (n) и уровнями значимости (α).
Если абсолютное значение нашего коэффициента корреляции больше критического значения в таблице, то корреляция между двумя переменными является статистически значимой.
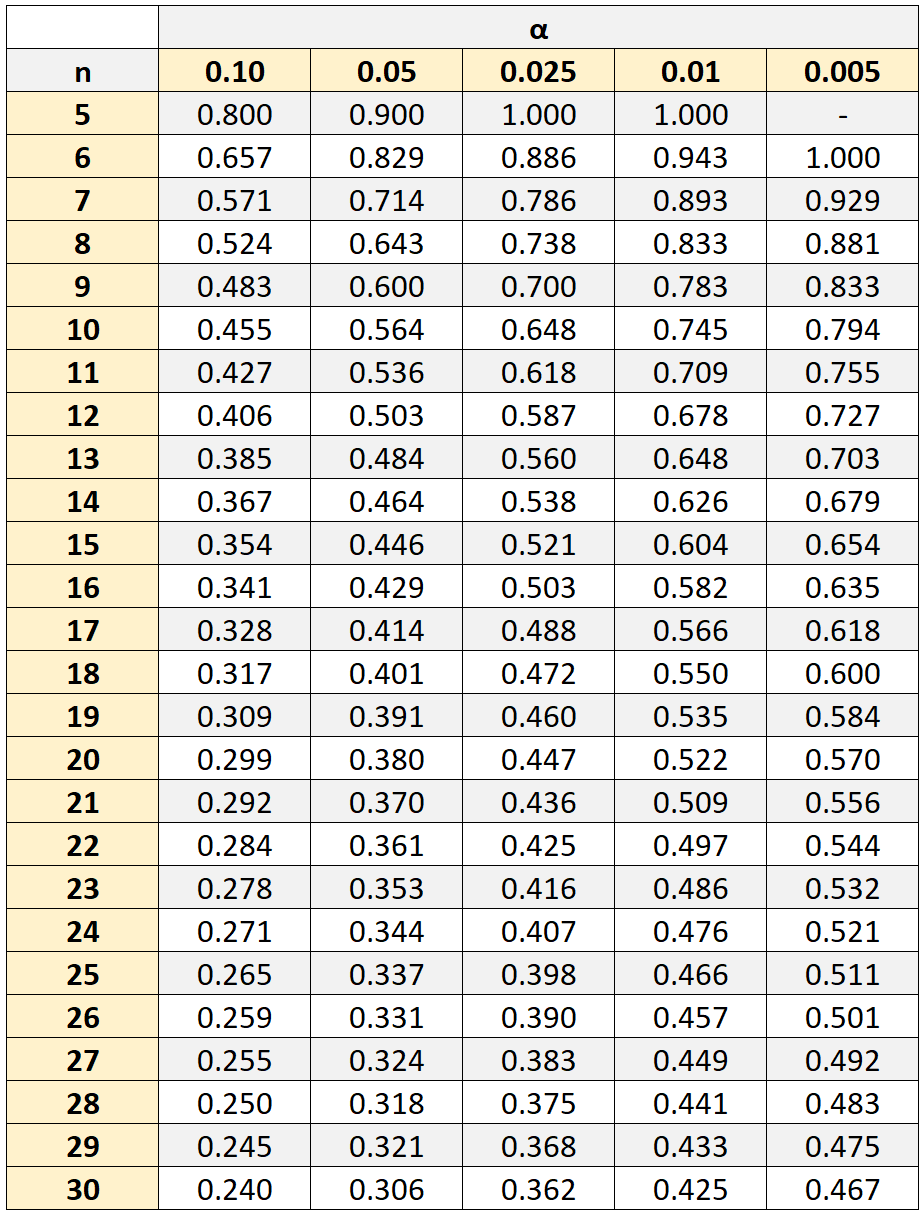
В нашем примере размер выборки составлял n = 10 студентов. Используя уровень значимости 0,05, мы находим, что критическое значение равно 0,564 .
Поскольку рассчитанное нами абсолютное значение рангового коэффициента корреляции Спирмена ( 0,41818 ) не превышает этого критического значения, это означает, что корреляция между баллами по математике и естественным наукам не является статистически значимой.
24. Коэффициент ранговой корреляции Спирмена
На предыдущих уроках мы познакомились с линейным коэффициентом корреляции Пирсона, линейной регрессией, а также потренировались в построении нелинейных моделей. Но эти методы далеко не всегда подходят для описания зависимости признака-результата от признака-фактора . Не всегда понятна форма зависимости (Линейная? Гиперболическая? Экспоненциальная? Какая-то другая?). Эта форма бывает сложной, а то и вовсе не определИма (в принципе). И вообще, мы можем исследовать не количественный, а некоторый качественный признак.
Представьте, что в вазе лежит яблоко, киви, банан, апельсин и мандарин. Как можно проранжировать это множество? Напрашивается пронумеровать фрукты по возрастанию (либо убыванию) их массы. На первом месте самый лёгкий, на втором подобрее, на третьем – ещё добрее, … и на последнем – самый добрый: 
Таким образом, каждому фрукту присвоен свой ранг (порядковый номер) по количественному критерию – массе, а именно, по возрастанию массы.
Но есть более вкусный качественный критерий. Сейчас я расположу эти фрукты в порядке моего ЛИЧНОГО вкусового предпочтения: что бы я съел в первую, вторую, третью, четвёртую и, наконец, последнюю очередь: 
Таким образом, каждому фрукту тоже присвоен свой ранг.
И здесь любопытно сравнить качественный признак с количественным – выяснить, насколько я склонен считать лёгкие фрукты более вкусными. Для этого нужно сопоставить соответствующие ранги по фруктам и оценить степень их близости: 
Иными словами, нужно определить, насколько теснА корреляционная зависимость моего вкуса от массы фрукта? Или она близка к нулю?
Но это, конечно, не самое интересное. Теперь ВЫ расположите те же фрукты в порядке СВОИХ вкусовых предпочтений. …Есть? Вероятнее всего, вы предпочли употребить фрукты в другой последовательности и проранжировали их иначе, например, так: 
После чего появляется возможность сравнить ранги – чтобы выяснить, насколько коррелируют (совпадают) наши вкусы. Визуально можно сразу сказать, что коррелируют они слабо, т. к. читатель явно не жалует цитрусовые. Но, разумеется, есть математическая оценка этой связи, и называется она коэффициент ранговой корреляции Спирмена.
Оставим вкусное на десерт и начнём с более прозаичной задачи, где сопоставляются два количественных признака:
Имеются выборочные данные по студентам: – количество прогулов за некоторый период времени и – суммарная успеваемость за этот период: 
Найти коэффициент ранговой корреляции Спирмена, сделать вывод.
В Примере 67 мы вычислили линейный коэффициент корреляции , что говорит о сильной обратной корреляционной зависимости – суммарной успеваемости от – количества прогулов. Далее было найдено уравнение линейной регрессии – это прямая, которая наилучшим образом (по сравнению с другими прямыми) приближает эмпирические точки : 
Но у такого подхода могут быть изъяны. Во-первых, прогулы и успеваемость – это величины дискретные (прерывные), но мы приблизили их непрерывной функцией (линейной). И во-вторых, зависимость может быть гораздо более сложной. Когда прогулов немного, успеваемость, вероятно, падает несущественно; когда их количество растёт – ситуация начинает ухудшаться, и, наконец, с некоторого момента достижения стремительно падают к плинтусу. Возможно, удастся подобрать кривую, удачно приближающую точки, но у нас мало данных (8 наблюдений всего), и по чертежу сомнительно, что удастся.
Поэтому в качестве альтернативы уместно рассмотреть ранговый подход. И я расскажу вам как о ручном решении этой задачи, так и о машинном – с помощью MS Excel.
Сначала рассмотрим признак-фактор и для удобства упорядочим количество прогулов по возрастанию: 
Это можно сделать на черновике или в Экселе. Теперь каждому значению легко присвоить свой ранг и записать ранги на чистовик, для примера парочка синих линий:

Следует заметить, что записывать числа по возрастанию (справа) вовсе не обязательно, это сделано чисто для удобства. Значения несложно проранжировать в уме (при небольшой выборке) или опять же с помощью специальной функции Экселя (кино будет ниже).
И ещё заметим такой момент, у нас есть одинаковые значения , но ранги у них разные (7 и 8) и возникает вопрос, а почему не наоборот? В подобных ситуациях обычно находят средний арифметический ранг, который присваивают каждой варианте. В нашей задаче одинаковых значений два, поэтому их средний ранг составит: – вот теперь всё справедливо, относим дробный ранг 7,5 и к варианте и к варианте
Аналогично ранжируем значения признака-результата – тоже и ОБЯЗАЛЬНО по возрастанию значений. Ранги легко проставить устно (что я только что сделал), без фактической сортировки «игрековых» значений: 
Среди значений нет одинаковых, и поэтому ранги не нуждаются в дополнительной корректировке. После ранжирования полезно выполнить проверку. Суммы «иксовых» и «игрековых» рангов должны совпадать и равняться , в нашей задаче объём выборки составляет и обе суммы равны .
Оценим тесноту связи между рангами. Для этого нужно вычислить коэффициент ранговой корреляции Спирмена, и это – есть в точности линейный коэффициент корреляции Пирсона* между рангами и .
* а коль скоро так, то минимальный объем совокупности должен равняться 6-7.
Технически вычисления можно провести разными способами. Если вас устраивает результат «на скорую руку», то просто забиваем в Экселе:
= КОРРЕЛ(выделяем мышкой массив ; выделяем массив ) и жмём Enter.
Но в учебных задачах, как правило, нужны подробные расчёты. Если нет дробных рангов, то коэффициент ранговой корреляции Спирмена удобно вычислить по упрощенной формуле:
, где – объем совокупности, а – квадраты разностей между соответствующими рангами.
Если же дробные ранги есть (это означает, что есть одинаковые значения и / или ), то возможны варианты. В том случае, если точность вычислений не критична и дробных рангов не так много, можно пользоваться той же формулой, но она будет давать приближённый результат: .
Но если вам необходимы абсолютно точные и подробные расчёты, то лучше расписать нахождение линейного коэффициента корреляции подробно – по образцу, только не между значениями и , а между их рангами . Кроме того, существуют специальные модификации вышеприведённой формулы – с поправкой на повторяющиеся значения , но лишь для некоторых частных случаев. И да, должен предупредить, что формулы, приведённые во многих источниках Интернета, некорректны. Поэтому лучше потратить время и получить стопудовый результат.
В нашей задаче дробные ранги есть, и мы выберем упрощенный вариант. Для этого вычислим разности соответствующих рангов , их квадраты и сумму . Заполним расчётную таблицу: 
Так как среди рангов есть дробные, то формула даёт лишь приближенный результат:
Более точное значение, вычисленное с помощью функции =КОРРЕЛ() приложения MS Excel: . И, как видите, погрешность вполне приемлемая, одна сотая всего.
Поскольку – это линейный коэффициент корреляции между рангами, то его интерпретация будет такой же. Коэффициент ранговой корреляции изменяется в пределах и чем он ближе по модулю к единице, тем теснее ранговая корреляционная зависимость. Для оценки тесноты связи используем ту же шкалу Чеддока: 
при этом если , то корреляционная связь обратная, а если , то прямая
Теперь смотрим кино, как это всё быстро подсчитать в Экселе:
и записываем ответ: , таким образом, существует сильная обратная корреляционная зависимость – суммарной успеваемости от – количества прогулов.
Напомню значение линейного коэффициента корреляции , и сейчас мы получили примерно такой же, даже более убедительный результат.
По аналогии с линейным коэффициентом, можно проверить статистическую значимость рангового коэффициента корреляции и построить соответствующие доверительные интервалы. Но это уже немного дебри статистики, с которыми можно ознакомиться, например, в учебном пособии Гмурмана (поздние издания) и других источниках. …Ловко я модернизировал метод Ивана Сусанина 🙂
К недостатку рангового коэффициента корреляции Спирмена можно отнести тот факт, что он практически ничего не говорит о форме зависимости. Но повторюсь, эта форма может быть трудноопределима или не определИма вовсе. Как, например, при сопоставлении качественных признаков. По этой причине ранговый подход нашёл широчайшее применение в психологии, социологии и других гуманитарных направлениях. К слову, Чарльз Спирмен был именно психологом, и в его честь мы рассмотрим как раз простенькую задачу по психологии. На совместимость двух людей:
Коле и Оле было предложено проранжировать свои увлечения – от самого любимого до самого скучного / неприятного. В результате были получены следующие результаты: 
! В подобных задачах объекты принято ранжировать по убыванию их «качества» – от самого «хорошего» до самого «плохого».
С помощью коэффициента корреляции Спирмена определить совместимость Коли и Оли в плане увлечений.
Это задача для самостоятельного решения! – все числа уже в Экселе. Образец для сверки внизу.
В наиболее благоприятном случае все ранги по увлечениям совпадают, их разности равны нулю и посему , это говорит о практически идеальной совместимости. По мере убывания совместимость будет падать до нейтрального околонулевого значения, где нельзя сказать, что увлечения как-то сильно совпадают или наоборот, разнятся. И в отрицательной зоне начинает нарастать негатив – вплоть до значения , при котором Коля и Оля – совершенно разные люди.
Помимо подхода Спирмена, существует и другой принцип ранжированию объектов, который выражается ранговым коэффициентом корреляции Кендалла. Но он не слишком распространен в массовой практике (по крайне мере, технической), поэтому едем дальше:
Решения и ответы:
Пример 79. Решение: вычислим разности соответствующих рангов , их квадраты и сумму : 
Так как среди рангов нет дробных, то:
Ответ: , таким образом, Коля и Оля имеют слабо-умеренно-негативную совместимость по интересам.
Как посчитать корреляцию спирмена в excel
Как рассчитать ранговую корреляцию Спирмена в Excel
В статистике корреляция относится к силе и направлению связи между двумя переменными. Значение коэффициента корреляции может варьироваться от -1 до 1 со следующими интерпретациями:
- -1: идеальная отрицательная связь между двумя переменными
- 0: нет связи между двумя переменными
- 1: идеальная положительная связь между двумя переменными
Один особый тип корреляции называется ранговой корреляцией Спирмена и используется для измерения корреляции между двумя ранжированными переменными. (например, оценка балла учащегося на экзамене по математике и оценка его оценки на экзамене по естественным наукам в классе).
В этом руководстве объясняется, как рассчитать ранговую корреляцию Спирмена между двумя переменными в Excel.
Пример: ранговая корреляция Спирмена в Excel
Выполните следующие шаги, чтобы вычислить ранговую корреляцию Спирмена между результатами экзамена по математике и результатами экзамена по естественным наукам 10 учащихся в определенном классе.
Шаг 1: Введите данные.
Введите экзаменационные баллы для каждого учащегося в два отдельных столбца:
Шаг 2: Рассчитайте ранги для каждого экзаменационного балла.
Далее мы рассчитаем рейтинг для каждого экзаменационного балла. Используйте следующие формулы в ячейках D2 и E2, чтобы вычислить рейтинги по математике и естественным наукам для первого ученика, Остина:
Ячейка D2: =RANK.AVG(B2, $B$2:$B$11, 0)
Ячейка E2: =RANK.AVG(C2, $C$2:$C$11, 0)
Затем выделите оставшиеся ячейки для заполнения:
Затем нажмите Ctrl+D, чтобы заполнить ранги для каждого ученика:
Шаг 3: Рассчитайте коэффициент ранговой корреляции Спирмена.
Наконец, мы рассчитаем коэффициент ранговой корреляции Спирмена между оценками по математике и по естественным наукам с помощью функции CORREL() :
Ранговая корреляция Спирмена оказывается равной -0,41818 .
Шаг 4 (необязательно): Определите, является ли ранговая корреляция Спирмена статистически значимой.
На предыдущем шаге мы обнаружили, что ранговая корреляция Спирмена между результатами экзаменов по математике и естественным наукам составляет -0,41818 , что указывает на отрицательную корреляцию между двумя переменными.
Однако, чтобы определить, является ли эта корреляция статистически значимой, нам нужно будет обратиться к таблице ранговой корреляции Спирмена критических значений, которая показывает критические значения, связанные с различными размерами выборки (n) и уровнями значимости (α).
Если абсолютное значение нашего коэффициента корреляции больше критического значения в таблице, то корреляция между двумя переменными является статистически значимой.
В нашем примере размер выборки составлял n = 10 студентов. Используя уровень значимости 0,05, мы находим, что критическое значение равно 0,564 .
Поскольку рассчитанное нами абсолютное значение рангового коэффициента корреляции Спирмена ( 0,41818 ) не превышает этого критического значения, это означает, что корреляция между баллами по математике и естественным наукам не является статистически значимой.
24. Коэффициент ранговой корреляции Спирмена
На предыдущих уроках мы познакомились с линейным коэффициентом корреляции Пирсона, линейной регрессией, а также потренировались в построении нелинейных моделей. Но эти методы далеко не всегда подходят для описания зависимости признака-результата от признака-фактора . Не всегда понятна форма зависимости (Линейная? Гиперболическая? Экспоненциальная? Какая-то другая?). Эта форма бывает сложной, а то и вовсе не определИма (в принципе). И вообще, мы можем исследовать не количественный, а некоторый качественный признак.
Представьте, что в вазе лежит яблоко, киви, банан, апельсин и мандарин. Как можно проранжировать это множество? Напрашивается пронумеровать фрукты по возрастанию (либо убыванию) их массы. На первом месте самый лёгкий, на втором подобрее, на третьем – ещё добрее, … и на последнем – самый добрый:
Таким образом, каждому фрукту присвоен свой ранг (порядковый номер) по количественному критерию – массе, а именно, по возрастанию массы.
Но есть более вкусный качественный критерий. Сейчас я расположу эти фрукты в порядке моего ЛИЧНОГО вкусового предпочтения: что бы я съел в первую, вторую, третью, четвёртую и, наконец, последнюю очередь:
Таким образом, каждому фрукту тоже присвоен свой ранг.
И здесь любопытно сравнить качественный признак с количественным – выяснить, насколько я склонен считать лёгкие фрукты более вкусными. Для этого нужно сопоставить соответствующие ранги по фруктам и оценить степень их близости:
Иными словами, нужно определить, насколько теснА корреляционная зависимость моего вкуса от массы фрукта? Или она близка к нулю?
Но это, конечно, не самое интересное. Теперь ВЫ расположите те же фрукты в порядке СВОИХ вкусовых предпочтений. …Есть? Вероятнее всего, вы предпочли употребить фрукты в другой последовательности и проранжировали их иначе, например, так:
После чего появляется возможность сравнить ранги – чтобы выяснить, насколько коррелируют (совпадают) наши вкусы. Визуально можно сразу сказать, что коррелируют они слабо, т. к. читатель явно не жалует цитрусовые. Но, разумеется, есть математическая оценка этой связи, и называется она коэффициент ранговой корреляции Спирмена.
Оставим вкусное на десерт и начнём с более прозаичной задачи, где сопоставляются два количественных признака:
Имеются выборочные данные по студентам: – количество прогулов за некоторый период времени и – суммарная успеваемость за этот период:
Найти коэффициент ранговой корреляции Спирмена, сделать вывод.
В Примере 67 мы вычислили линейный коэффициент корреляции , что говорит о сильной обратной корреляционной зависимости – суммарной успеваемости от – количества прогулов. Далее было найдено уравнение линейной регрессии – это прямая, которая наилучшим образом (по сравнению с другими прямыми) приближает эмпирические точки :
Но у такого подхода могут быть изъяны. Во-первых, прогулы и успеваемость – это величины дискретные (прерывные), но мы приблизили их непрерывной функцией (линейной). И во-вторых, зависимость может быть гораздо более сложной. Когда прогулов немного, успеваемость, вероятно, падает несущественно; когда их количество растёт – ситуация начинает ухудшаться, и, наконец, с некоторого момента достижения стремительно падают к плинтусу. Возможно, удастся подобрать кривую, удачно приближающую точки, но у нас мало данных (8 наблюдений всего), и по чертежу сомнительно, что удастся.
Поэтому в качестве альтернативы уместно рассмотреть ранговый подход. И я расскажу вам как о ручном решении этой задачи, так и о машинном – с помощью MS Excel.
Сначала рассмотрим признак-фактор и для удобства упорядочим количество прогулов по возрастанию:
Это можно сделать на черновике или в Экселе. Теперь каждому значению легко присвоить свой ранг и записать ранги на чистовик, для примера парочка синих линий:
Следует заметить, что записывать числа по возрастанию (справа) вовсе не обязательно, это сделано чисто для удобства. Значения несложно проранжировать в уме (при небольшой выборке) или опять же с помощью специальной функции Экселя (кино будет ниже).
И ещё заметим такой момент, у нас есть одинаковые значения , но ранги у них разные (7 и 8) и возникает вопрос, а почему не наоборот? В подобных ситуациях обычно находят средний арифметический ранг, который присваивают каждой варианте. В нашей задаче одинаковых значений два, поэтому их средний ранг составит: – вот теперь всё справедливо, относим дробный ранг 7,5 и к варианте и к варианте
Аналогично ранжируем значения признака-результата – тоже и ОБЯЗАЛЬНО по возрастанию значений. Ранги легко проставить устно (что я только что сделал), без фактической сортировки «игрековых» значений:
Среди значений нет одинаковых, и поэтому ранги не нуждаются в дополнительной корректировке. После ранжирования полезно выполнить проверку. Суммы «иксовых» и «игрековых» рангов должны совпадать и равняться , в нашей задаче объём выборки составляет и обе суммы равны .
Оценим тесноту связи между рангами. Для этого нужно вычислить коэффициент ранговой корреляции Спирмена, и это – есть в точности линейный коэффициент корреляции Пирсона* между рангами и .
* а коль скоро так, то минимальный объем совокупности должен равняться 6-7.
Технически вычисления можно провести разными способами. Если вас устраивает результат «на скорую руку», то просто забиваем в Экселе:
= КОРРЕЛ(выделяем мышкой массив ; выделяем массив ) и жмём Enter.
Но в учебных задачах, как правило, нужны подробные расчёты. Если нет дробных рангов, то коэффициент ранговой корреляции Спирмена удобно вычислить по упрощенной формуле:
, где – объем совокупности, а – квадраты разностей между соответствующими рангами.
Если же дробные ранги есть (это означает, что есть одинаковые значения и / или ), то возможны варианты. В том случае, если точность вычислений не критична и дробных рангов не так много, можно пользоваться той же формулой, но она будет давать приближённый результат: .
Но если вам необходимы абсолютно точные и подробные расчёты, то лучше расписать нахождение линейного коэффициента корреляции подробно – по образцу, только не между значениями и , а между их рангами . Кроме того, существуют специальные модификации вышеприведённой формулы – с поправкой на повторяющиеся значения , но лишь для некоторых частных случаев. И да, должен предупредить, что формулы, приведённые во многих источниках Интернета, некорректны. Поэтому лучше потратить время и получить стопудовый результат.
В нашей задаче дробные ранги есть, и мы выберем упрощенный вариант. Для этого вычислим разности соответствующих рангов , их квадраты и сумму . Заполним расчётную таблицу:
Так как среди рангов есть дробные, то формула даёт лишь приближенный результат:
Более точное значение, вычисленное с помощью функции =КОРРЕЛ() приложения MS Excel: . И, как видите, погрешность вполне приемлемая, одна сотая всего.
Поскольку – это линейный коэффициент корреляции между рангами, то его интерпретация будет такой же. Коэффициент ранговой корреляции изменяется в пределах и чем он ближе по модулю к единице, тем теснее ранговая корреляционная зависимость. Для оценки тесноты связи используем ту же шкалу Чеддока:
при этом если , то корреляционная связь обратная, а если , то прямая
Теперь смотрим кино, как это всё быстро подсчитать в Экселе:
и записываем ответ: , таким образом, существует сильная обратная корреляционная зависимость – суммарной успеваемости от – количества прогулов.
Напомню значение линейного коэффициента корреляции , и сейчас мы получили примерно такой же, даже более убедительный результат.
По аналогии с линейным коэффициентом, можно проверить статистическую значимость рангового коэффициента корреляции и построить соответствующие доверительные интервалы. Но это уже немного дебри статистики, с которыми можно ознакомиться, например, в учебном пособии Гмурмана (поздние издания) и других источниках. …Ловко я модернизировал метод Ивана Сусанина ��
К недостатку рангового коэффициента корреляции Спирмена можно отнести тот факт, что он практически ничего не говорит о форме зависимости. Но повторюсь, эта форма может быть трудноопределима или не определИма вовсе. Как, например, при сопоставлении качественных признаков. По этой причине ранговый подход нашёл широчайшее применение в психологии, социологии и других гуманитарных направлениях. К слову, Чарльз Спирмен был именно психологом, и в его честь мы рассмотрим как раз простенькую задачу по психологии. На совместимость двух людей:
Коле и Оле было предложено проранжировать свои увлечения – от самого любимого до самого скучного / неприятного. В результате были получены следующие результаты:
! В подобных задачах объекты принято ранжировать по убыванию их «качества» – от самого «хорошего» до самого «плохого».
С помощью коэффициента корреляции Спирмена определить совместимость Коли и Оли в плане увлечений.
Это задача для самостоятельного решения! – все числа уже в Экселе. Образец для сверки внизу.
В наиболее благоприятном случае все ранги по увлечениям совпадают, их разности равны нулю и посему , это говорит о практически идеальной совместимости. По мере убывания совместимость будет падать до нейтрального околонулевого значения, где нельзя сказать, что увлечения как-то сильно совпадают или наоборот, разнятся. И в отрицательной зоне начинает нарастать негатив – вплоть до значения , при котором Коля и Оля – совершенно разные люди.
Помимо подхода Спирмена, существует и другой принцип ранжированию объектов, который выражается ранговым коэффициентом корреляции Кендалла. Но он не слишком распространен в массовой практике (по крайне мере, технической), поэтому едем дальше:
Решения и ответы:
Пример 79. Решение: вычислим разности соответствующих рангов , их квадраты и сумму :
Так как среди рангов нет дробных, то:
Ответ: , таким образом, Коля и Оля имеют слабо-умеренно-негативную совместимость по интересам.
Автор: Емелин Александр
(Переход на главную страницу)
 Contented.ru – онлайн школа дизайна
Contented.ru – онлайн школа дизайна
SkillFactory – получи востребованную IT профессию!
Расчет коэффициента корреляции Спирмена в Excell
Для того, чтобы рассчитать коэффициент корреляции в Excell необходимо сделать следующие шаги:
1.Вносим значения для двух переменных в таблицу (Например Переменная 1 и Переменная 2)
2. Ставим курсор в пустую ячейку
3. На панеле инструментов нажимаем кнопку fx (вставить формулу)
4. В открывшемся окне «Мастер функций» в поле «Категории» выбираем Полный алфавитный перечень
5. Затем в поле «Выберите функцию» находим функцию КОРЕЛЛ
5.1. Нажимаем Ок
6. В открывшемся окне «Аргументы функции» в поле Массив1 вносим номера ячеек, содержащие значения Переменной 1, в поле Массив2 вносим номера ячеек, содержащие значения Переменной2.
Корреляционный анализ в Excel. Пример выполнения корреляционного анализа
Корреляционный анализ позволяет найти зависимость одного показателя от другого, и в случае ее обнаружения – вычислить коэффициент корреляции (степень взаимосвязи), который может принимать значения от -1 до +1:
-
если коэффициент отрицательный – зависимость обратная, т.е. увеличение одной величины приводит к уменьшению второй и наоборот.
Сила зависимости определяется по модулю коэффициента корреляции. Чем больше значение, тем сильнее изменение одной величины влияет на другую. Исходя из этого, при нулевом коэффициенте можно утверждать, что взаимосвязь отсутствует.
Выполняем корреляционный анализ
Для изучения и лучшего понимания корреляционного анализа, давайте попробуем его выполнить для таблицы ниже.

Здесь указаны данные по среднесуточной температуре и средней влажности по месяцам года. Наша задача – выяснить, существует ли связь между этими параметрами и, если да, то насколько сильная.
Метод 1: применяем функцию КОРРЕЛ
В Excel предусмотрена специальная функция, позволяющая сделать корреляционный анализ – КОРРЕЛ. Ее синтаксис выглядит следующим образом:
Порядок действий при работе с данным инструментом следующий:
-
Встаем в свободную ячейку таблицы, в которой планируем рассчитать коэффициент корреляции. Затем щелкаем по значку “fx (Вставить функцию)” слева от строки формул.


Метод 2: используем “Пакет анализа”
Альтернативным способом выполнения корреляционного анализа является использование “Пакета анализа”, который предварительно нужно включить. Для этого:



Все готово, “Пакет анализа” активирован. Теперь можно перейти к выполнению нашей основной задачи:
- Нажимаем кнопку “Анализ данных”, которая находится во вкладке “Данные”.


-
“Входной интервал”. Выделяем весь диапазон анализируемых ячеек (т.е. сразу оба столбца, а не по одному, как это было в описанном выше методе).


Заключение
Таким образом, выполнение корреляционного анализа в Excel – достаточно автоматизированная и простая в освоении процедура. Все что нужно знать – где найти и как настроить необходимый инструмент, а в случае с “Пакетом решения”, как его активировать, если до этого он уже не был включен в параметрах программы.
Назначение корреляционного анализа
Зависимость устанавливается тогда, когда начинается выявление коэффициента корреляции. Этот метод отличается от анализа регрессии, так как здесь только один показатель, рассчитываемый при помощи корреляции. Интервал изменяется от +1 до -1. Если она плюсовая, то повышение первой величины способствует повышению 2-й. Если минусовая, то повышение 1-й величины способствует понижению 2-й. Чем выше коэффициент, тем сильнее одна величина влияет на 2-ю.
Важно! При 0-м коэффициенте зависимости между величинами нет.
Несколько важных замечаний
1. Коэффициент корреляции Пирсона чувствителен к выбросам. Одно аномальное значение может существенно исказить коэффициент. Поэтому перед проведением анализа следует проверить и при необходимости удалить выбросы. Другой вариант – перейти к ранговому коэффициенту корреляции Спирмена. Рассчитывается также, только не по исходным значениям, а по их рангам (пример показан в ролике под статьей).
2. Синоним корреляции – это взаимосвязь или совместная вариация. Поэтому наличие корреляции (r ≠ 0) еще не означает причинно-следственную связь между переменными. Вполне возможно, что совместная вариация обусловлена влиянием третьей переменной. Совместное изменение переменных без причинно-следственной связи называется ложная корреляция.
3. Отсутствие линейной корреляции (r = 0) не означает отсутствие взаимосвязи. Она может быть нелинейной. Частично эту проблему решает ранговая корреляция Спирмена, которая показывает совместный рост или снижение рангов, независимо от формы взаимосвязи.
В видео показан расчет коэффициента корреляции Пирсона с доверительными интервалами, ранговый коэффициент корреляции Спирмена.
Расчет коэффициента корреляции
Разберем расчёт на нескольких образцах. К примеру, есть табличные данные, где по месяцам описаны в отдельных столбцах траты на рекламное продвижение и объём продаж. Исходя из таблицы, будем выяснять уровень зависимости объема продаж от денег, затраченных на рекламное продвижение.
Способ 1: определение корреляции через Мастер функций
КОРРЕЛ – функция, позволяющая реализовать корреляционный анализ. Общий вид — КОРРЕЛ(массив1;массив2). Подробная инструкция:
- Необходимо произвести выделение ячейки, в которой планируется выводить итог расчета. Нажать «Вставить функцию», находящуюся слева от текстового поля для ввода формулы.
- Открывается «Мастер функций». Здесь необходимо найти КОРРЕЛ, кликнуть на нее, затем на «ОК».

2
- Открылось окошко аргументов. В строку «Массив1» необходимо ввести координаты интервалы 1-го из значений. В рассматриваемом примере — это столбец «Величина продаж». Нужно просто произвести выделение всех ячеек, которые находятся в этой колонке. В строку «Массив2» аналогично необходимо добавить координаты второй колонки. В рассматриваемом примере — это столбец «Затраты на рекламу».

3
- После введения всех диапазонов кликаем на кнопку «ОК».
Коэффициент отобразился в той ячейке, которая была указана в начале наших действий. Полученный результат 0,97. Этот показатель отображает высокую зависимость первой величины от второй.

4
Способ 2: вычисление корреляции с помощью Пакета анализа
Существует еще один метод определения корреляции. Здесь используется одна из функций, находящаяся в пакете анализа. Перед ее использованием нужно провести активацию инструмента. Подробная инструкция:
- Переходим в раздел «Файл».

5
- Открылось новое окошко, в котором нужно кликнуть на раздел «Параметры».
- Жмём на «Надстройки».
- Находим в нижней части элемент «Управление». Здесь необходимо выбрать из контекстного меню «Надстройки Excel» и кликнуть «ОК».

6
- Открылось специальное окно надстроек. Ставим галочку рядом с элементом «Пакет анализа». Кликаем «ОК».
- Активация прошла успешно. Теперь переходим в «Данные». Появился блок «Анализ», в котором необходимо кликнуть «Анализ данных».
- В новом появившемся окошке выбираем элемент «Корреляция» и жмем на «ОК».

7
- На экране появилось окошко настроек анализа. В строчку «Входной интервал» необходимо ввести диапазон абсолютно всех колонок, принимающих участие в анализе. В рассматриваемом примере — это столбики «Величина продаж» и «Затраты на рекламу». В настройках отображения вывода изначально выставлен параметр «Новый рабочий лист», что означает показ результатов на другом листе. По желанию можно поменять локацию вывода результата. После проведения всех настроек нажимаем на «ОК».

8
Вывелись итоговые показатели. Результат такой же, как и в первом методе – 0,97.
Негативное влияние на головной мозг
Медицинские исследователи решили узнать о вреде роутеров вай-фай на сосуды головного мозга с помощью специальных экспериментов. Опыт провели на школьниках. Детям предложили оставить под подушкой мобильный с работающим wi-fi на всю ночь. Утром у детей выяснили их состоянием
Большинство деток испытывали неприятные симптомы, отмечались спазмы и усталость, появление проблем с памятью и вниманием
Эксперимент проводили на детях, у которых костная ткань головы тоньше и обеспечивает меньшую защиту мозга. Поэтому назвать результат абсолютно точным нельзя. Не исключено, что большая часть излучений была получена от мобильного устройства, а не от сигнала вай-фай. Точных результатов исследования и доказательств у взрослых не существует, но по предварительным итогам – излучение неблагоприятно воздействует на мозговую деятельность.
Определение и вычисление множественного коэффициента корреляции в MS Excel
Для выявления уровня зависимости нескольких величин применяются множественные коэффициенты. В дальнейшем итоги сводятся в отдельную табличку, именуемую корреляционной матрицей.
Коэффициент ранговой корреляции спирмена excel
В статистике корреляция относится к силе и направлению связи между двумя переменными. Значение коэффициента корреляции может варьироваться от -1 до 1 со следующими интерпретациями:
- -1: идеальная отрицательная связь между двумя переменными
- 0: нет связи между двумя переменными
- 1: идеальная положительная связь между двумя переменными
Один особый тип корреляции называется ранговой корреляцией Спирмена и используется для измерения корреляции между двумя ранжированными переменными. (например, оценка балла учащегося на экзамене по математике и оценка его оценки на экзамене по естественным наукам в классе).
В этом руководстве объясняется, как рассчитать ранговую корреляцию Спирмена между двумя переменными в Excel.
Пример: ранговая корреляция Спирмена в Excel
Выполните следующие шаги, чтобы вычислить ранговую корреляцию Спирмена между результатами экзамена по математике и результатами экзамена по естественным наукам 10 учащихся в определенном классе.
Шаг 1: Введите данные.
Введите экзаменационные баллы для каждого учащегося в два отдельных столбца:
Шаг 2: Рассчитайте ранги для каждого экзаменационного балла.
Далее мы рассчитаем рейтинг для каждого экзаменационного балла. Используйте следующие формулы в ячейках D2 и E2, чтобы вычислить рейтинги по математике и естественным наукам для первого ученика, Остина:
Ячейка D2: =RANK.AVG(B2, $B$2:$B$11, 0)
Ячейка E2: =RANK.AVG(C2, $C$2:$C$11, 0)
Затем выделите оставшиеся ячейки для заполнения:
Затем нажмите Ctrl+D, чтобы заполнить ранги для каждого ученика:
Шаг 3: Рассчитайте коэффициент ранговой корреляции Спирмена.
Наконец, мы рассчитаем коэффициент ранговой корреляции Спирмена между оценками по математике и по естественным наукам с помощью функции CORREL() :
Ранговая корреляция Спирмена оказывается равной -0,41818 .
Шаг 4 (необязательно): Определите, является ли ранговая корреляция Спирмена статистически значимой.
На предыдущем шаге мы обнаружили, что ранговая корреляция Спирмена между результатами экзаменов по математике и естественным наукам составляет -0,41818 , что указывает на отрицательную корреляцию между двумя переменными.
Однако, чтобы определить, является ли эта корреляция статистически значимой, нам нужно будет обратиться к таблице ранговой корреляции Спирмена критических значений, которая показывает критические значения, связанные с различными размерами выборки (n) и уровнями значимости (α).
Если абсолютное значение нашего коэффициента корреляции больше критического значения в таблице, то корреляция между двумя переменными является статистически значимой.
В нашем примере размер выборки составлял n = 10 студентов. Используя уровень значимости 0,05, мы находим, что критическое значение равно 0,564 .
Поскольку рассчитанное нами абсолютное значение рангового коэффициента корреляции Спирмена ( 0,41818 ) не превышает этого критического значения, это означает, что корреляция между баллами по математике и естественным наукам не является статистически значимой.
We have noticed a general trend that with an increase in the height of a person, its weight also increases. This happens because there is a positive correlation between height and weight. As one variable increases, the other one also increases, but with this, we only get the quality measure of the data and not quantity, that by how much they are related. To solve this problem, we have a Spearman Rank Correlation coefficient whose value will tell by how two variables are related. In this article, we will learn how to calculate Spearman Rank Correlation Coefficient in excel.
What is Spearman Rank Correlation Coefficient?
Spearman rank correlation coefficient is a non-parametric measure by which we can have a numerical value of how much two variables are related. Spearman’s rank correlation coefficient works on the ranks and not the data set provided. It would be better to say that Spearman works on ordinal data.
Range of Spearman Rank Correlation Coefficient
- If the graph is monotonically increasing, then the spearman coefficient tends to 1.
- If the graph is monotonically decreasing, then the spearman coefficient tends to -1.
- If the graph is both increasing and decreasing, the spearman coefficient tends to be 0.
- A perfect 1 value signifies that data is said to have a perfect positive correlation.
- A perfect -1 value signifies that data is said to have a perfect negative correlation.
- A perfect 0 value signifies that data is said to have no relation between two variables.
Hence, the spearman coefficient value lies in the range of [-1, 1], where -1 and 1 are included.
Advantages of Spearman Rank Correlation Coefficient
As spearman works on ordinal data, so it’s a non-parametric test. The test has no relation to the actual values in the data set. This coefficient test works well with outliers. The correlation value is not distorted if there are significant outliers in the data set.
The formula for Spearman Rank Correlation Coefficient
A formula has been provided to calculate the Spearman rank coefficient. The formula is:
![r_s = 1 - frac<6Σd_i^2><n(n^2-1)>» width=»183″ height=»46″ /></p>
<p>r<sub>s</sub> = Spearman Rank Correlation Coefficient,</p>
<p>d<sub>i</sub> = Difference of the rank of the values in the data set,</p>
<p>n = Size of the data set.</p>
<blockquote>
<p><strong>Note:</strong> The Formula works only if there are no tie ranks in your data set, i.e. there should be only distinct values for each Variable.</p>
<p>For example:</p>
<p>DataSet 1: Variable1: [1, 4, 3, 5], Variable2: [3, 4, 2, 5]</p>
<p>DataSet 2: Variable1: [1, 2, 2, 2], Variable2: [3, 4, 2, 5]</p>
<p>In the above two given data sets, DataSet1 satisfies the condition, and hence the formula could be applied to find spearman coefficient, but DataSet2 do not satisfies the condition, as there are duplicate values in Variable1 of second data set, hence the formula could not be applied to find spearman coefficient.</p>
</blockquote>
<h3>How to Calculate Spearman Rank Correlation in Excel?</h3>
<p>Before following the procedure to calculate the spearman coefficient, we need to understand two functions in excel, which will be helpful in calculating the coefficient.</p>
<h4>Rank Function</h4>
<p>The rank specifies the rank of a given number in a dataset; one can also select the order in which rank has to appear. <strong>=RANK.AVG()</strong> takes three arguments: <strong>number</strong>, <strong>ref</strong>, and <strong>order</strong>.</p>
<p><strong>Argument 1:</strong> Number is the first argument in the rank function, which specifies for which number rank has to be estimated.</p>
<p><strong>Argument 2:</strong> Reference is the second argument in the rank function. One needs to provide the absolute range of the data set.</p>
<p><strong>Argument 3:</strong> Order is the third argument in the rank function. The order can be either <strong>ascending(1)</strong> or <strong>descending(0)</strong>.</p>
<h4>Correl function</h4>
<p>Similar to the spearman rank correlation coefficient, we also have the <strong>Pearson correlation coefficient</strong>. Pearson correlation coefficient is a parametric test to calculate the correlation value of two variables. Both the test is nearly the same. Just the difference lies in that spearman works on ranks of the data, and Pearson works on the actual data. The <strong>=CORREL()</strong> function calculates the Pearson correlation coefficient. This could be very useful in finding the spearman correlation coefficient, which we will talk about in the later stage of the article. <strong>=CORREL()</strong> function takes two arguments, <strong>array1</strong> and <strong>array2</strong>.</p>
<p><strong>Argument 1:</strong> Array1 is the first argument in the correlation function. It takes the entire data set of the variable1.</p>
<p><strong>Argument 2:</strong> Array2 is the second argument in the correlation function. It takes the entire data set of the variable2.</p>
<h3>Different methods to find Spearman Coefficient in Excel</h3>
<p>There are two different methods by which we can find the Spearman correlation rank coefficient.</p>
<h4>Method 1: Using the Formula</h4>
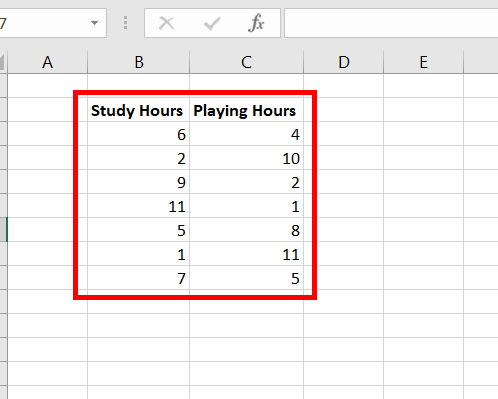
<p>Spearman rank coefficient can be found with the help of a formula, as we have mentioned in the above article, but this formula can only be used if each data set does not contain duplicate values so that the rank of each value is unique. For example, <strong>Arushi</strong> is an aspiring <strong>Chartered Accountant</strong>, daily, she used to spend her entire day either <strong>studying</strong> or <strong>playing</strong>. For <strong>7</strong> days, she kept track of how many hours does she study and play. On a daily basis, her study hours and playing hours vary. <strong>Arushi</strong> wants to find whether her playing hours and studying hours are <strong>positively</strong> or <strong>negatively</strong> <strong>correlated</strong> with the help of the <strong>Spearman correlation rank coefficient</strong>.</p>
<p><img decoding=](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-cd37307d8873fd524a276f6eaa965638_l3.png)
Following are the steps
Step 1: Create a new column name Study Rank. In cell D3, use the formula =RANK.AVG(B3, $B$3:$B$9, 1). This finds the rank of cell B3 for Study Hours. Press Enter.
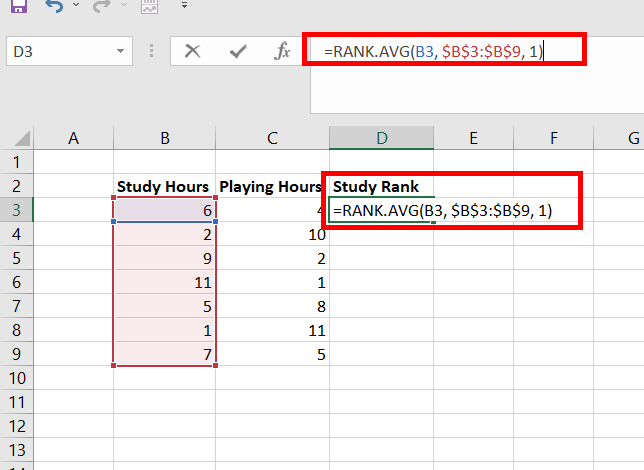
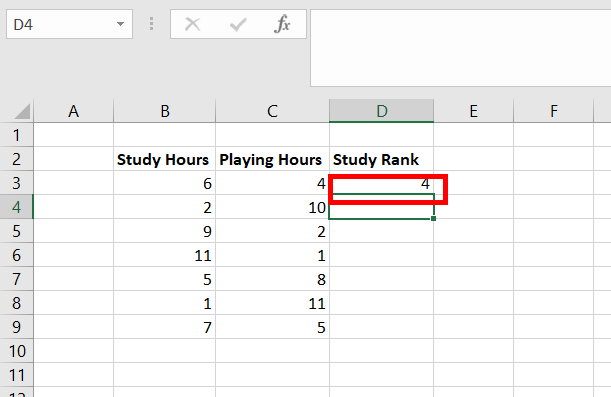
Step 2: The number 4 appears in cell D3. This number has ranked 4 in the Study Hours data set.
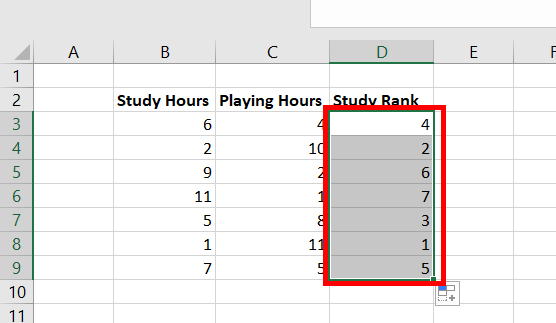
Step 3: Copy the same formula of D3 to cells D4:D9.
Step 4: Create a new column name Play Rank. In cell E3, use the formula =RANK.AVG(C3, $C$3:$C$9, 1). This finds the rank of cell C3 for Play Hours. Press Enter.
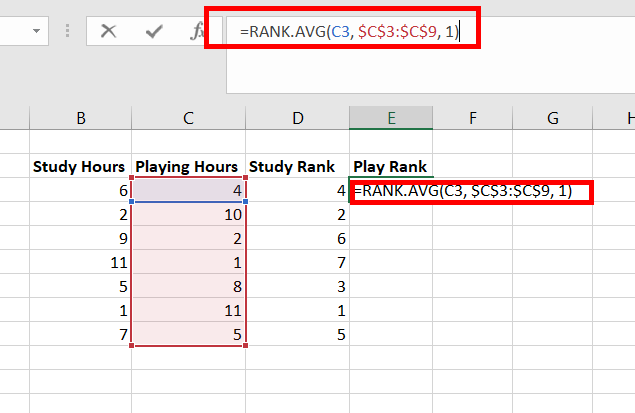
Step 5: The number 3 appears in cell E3. This number has ranked 3 in the Play Hours data set.
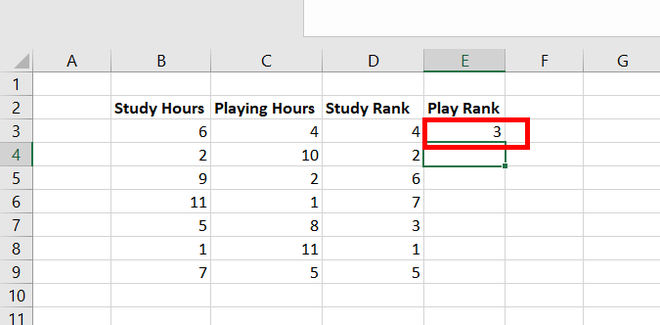
Step 6: Copy the same formula of E3 to cells E4:E9.
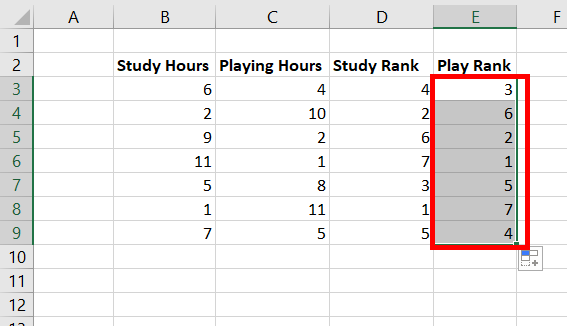
Step 7: Create a new column, name, d. In cell F3, use the formula =D3-E3. This calculates the difference in the ranks. Press Enter.
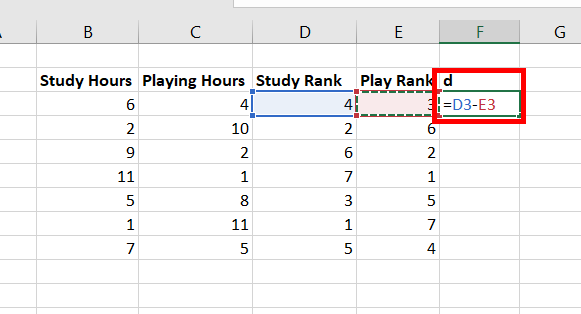
Step 8: Copy the same formula of F3 to cells F4:F9.
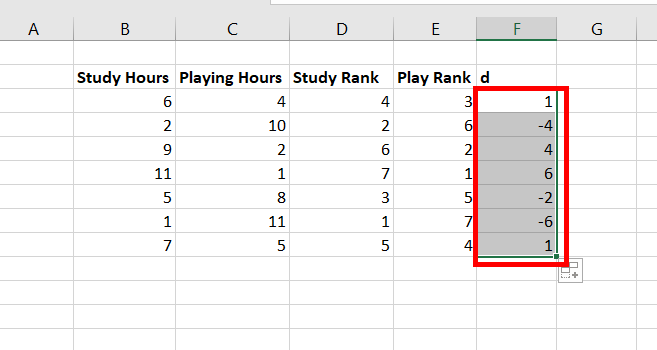
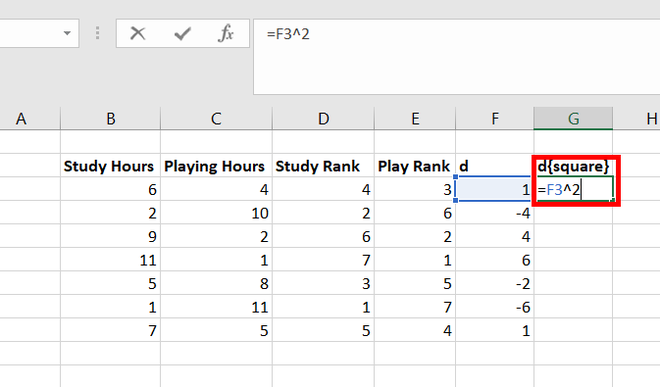
Step 9: Create a new column, name, d . In cell G3, use the formula =F3^2. This calculates the square of the difference. Press Enter.
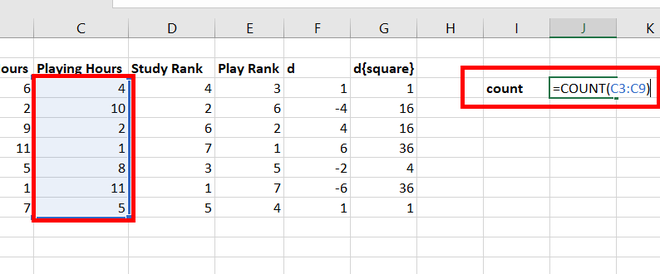
Step 11: Use =COUNT(C3:C9) function to calculate the size of the data set. Press Enter.
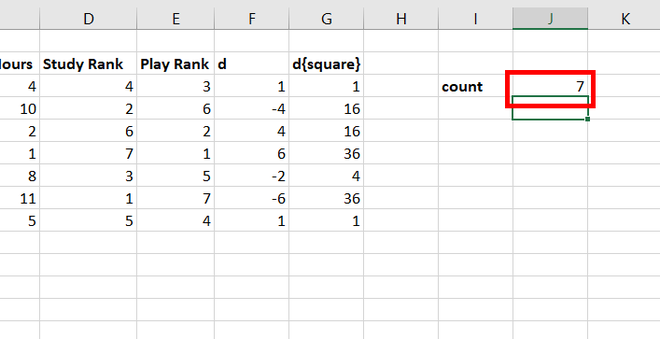
Step 12: In the cell, J3, 7 appears, which is the size of the data set.
Step 13: Use =SUM(G3:G9) function to calculate the sum of the difference between the ranks. Press Enter.
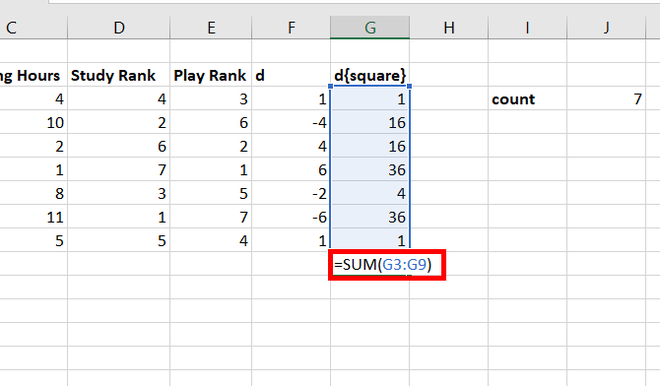
Step 14: In the cell, G10, 110 appears.
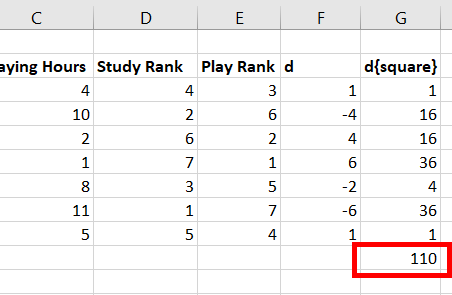
Step 15: In cell J5, apply the Spearman formula as mentioned above in the article, i.e., =1-(6*G10/(J3*(J3^2-1))). Press Enter.
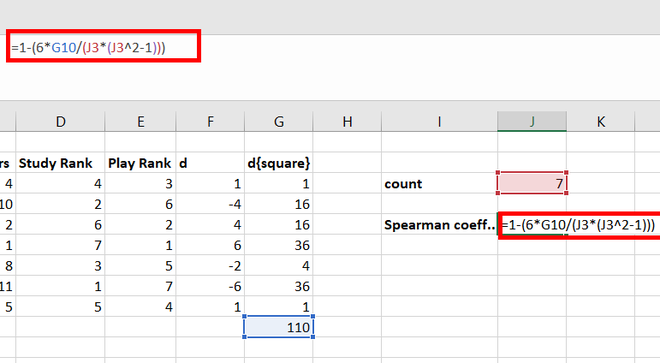
Step 16: We get the spearman correlation rank coefficient as -0.96429, which proves that studying hours and playing hours are negatively correlated.
Method 2: Using =CORREL() function
We previously saw that correlated function finds the value of Pearson correlated coefficient by using arguments as data set values. We also know that the spearman coefficient works on the ranks and is a non-parametric test. The correlated function can also be used to find the spearman correlation coefficient by using arguments as data set rank values. For example, Arushi is an aspiring Chartered Accountant, daily she used to spend her entire day either studying or playing. For 7 days, she kept track of how many hours does she study and play. On a daily basis, her study hours and playing hours vary. Arushi wants to find whether her playing hours and studying hours are positively or negatively correlated with the help of the Spearman correlation rank coefficient.
Following are the steps
Step 1: Create a new column, name Study Rank. In cell D3, use the formula =RANK.AVG(B3, $B$3:$B$9, 1). This finds the rank of cell B3 for Study Hours. Press Enter.
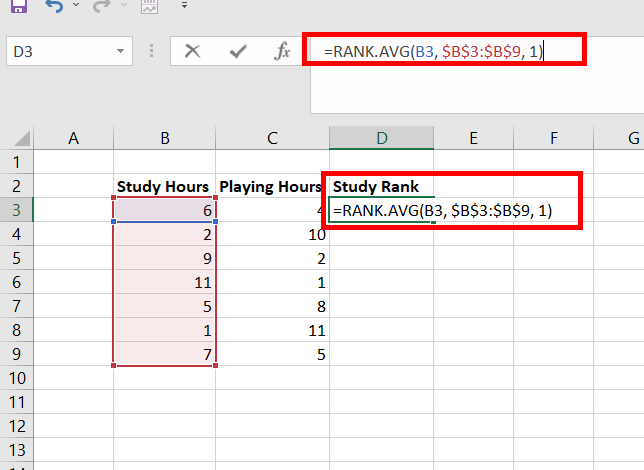
Step 2: The number 4 appears in cell D3. This number has ranked 4 in the Study Hours data set.
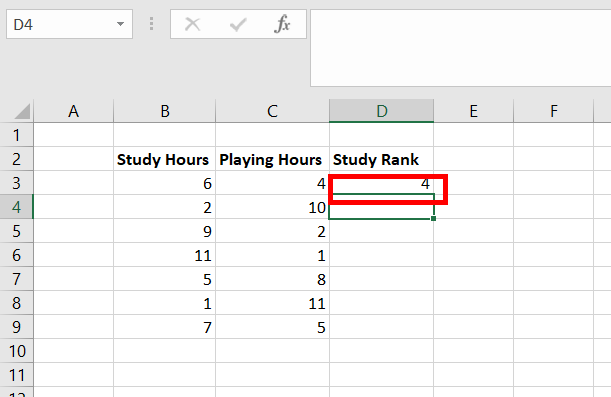
Step 3: Copy the same formula of D3 to cells D4:D9.
Step 4: Create a new column, name Play Rank. In cell E3, use the formula =RANK.AVG(C3, $C$3:$C$9, 1). This finds the rank of cell C3 for Play Hours. Press Enter.
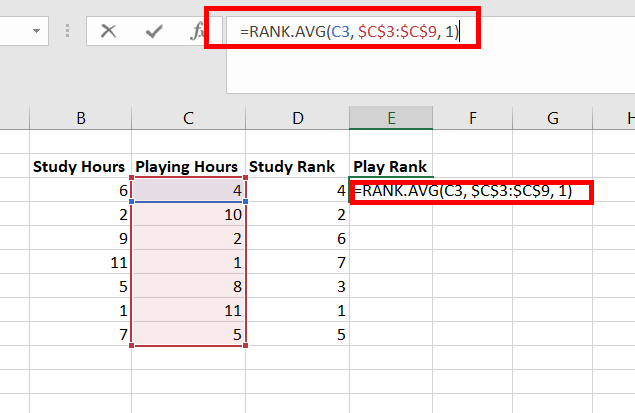
Step 5: The number 3 appears in cell E3. This number has ranked 3 in the Play Hours data set.
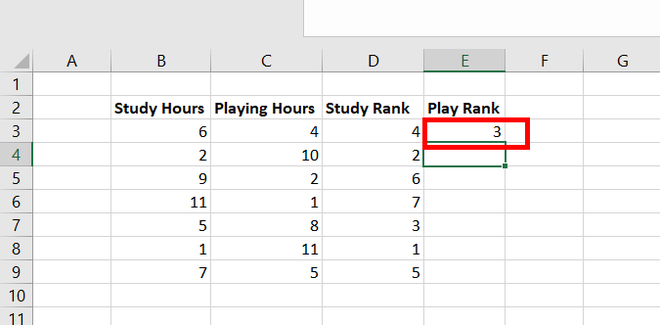
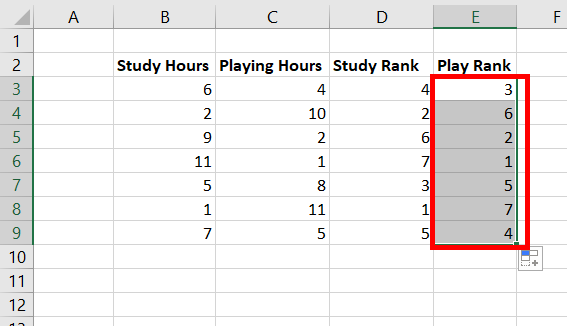
Step 6: Copy the same formula of E3 to cells E4:E9.
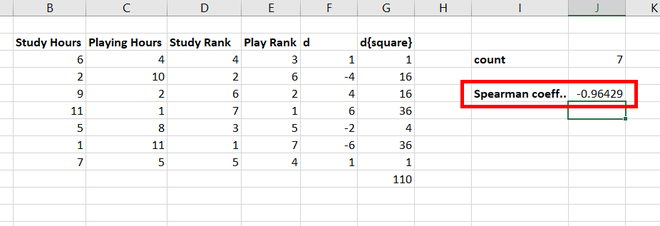
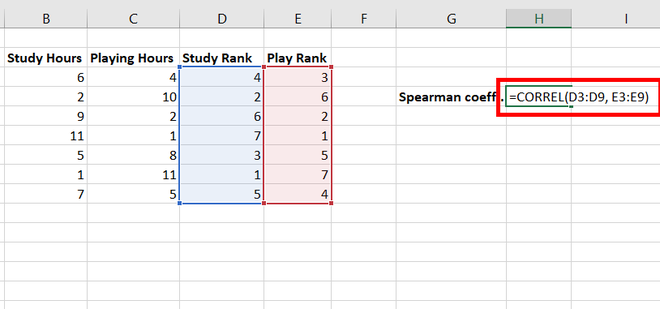
Step 7: In cell H4, use =CORREL(D3:D9, E3:E9) function to find the spearman correlation rank coefficient. Press Enter.
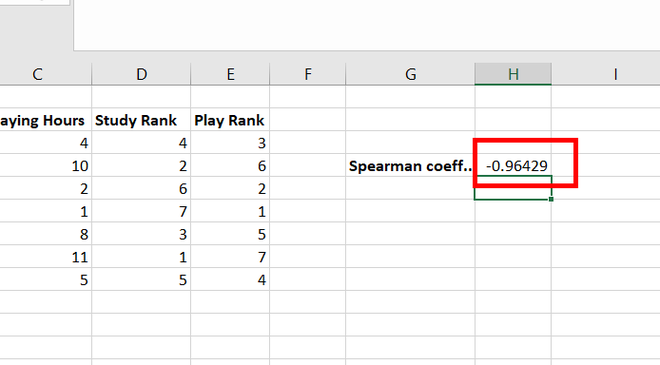
Step 8: We get the spearman correlation rank coefficient as -0.96429, which proves that studying hours and playing hours are negatively correlated.
Коэффициент корреляции ранга Спирмена позволяет определить, существует ли между двумя переменными зависимость, выражаемая монотонной функцией (то есть при росте одной переменной увеличивается и вторая, и наоборот). Приведенные в статье простые шаги позволят вам производить расчеты вручную, а также вычислять коэффициент корреляции при помощи программ Excel и R.

Составьте таблицу данных. Таким образом вы упорядочите информацию, необходимую для расчета коэффициента корреляции ранга Спирмена. При этом вам понадобится:
- 6 колонок, озаглавленных так, как показано выше на рисунке.
- Количество строк, соответствующее числу пар переменных.

Заполните первые две колонки парами переменных.

В третьей колонке запишите номера (ранги) пар переменных от 1 до n (общее число пар). Присвойте номер 1 паре с наименьшим значением в первой колонке, 2 — следующему за ним значению, и так по возрастанию величин переменной из первой колонки.

В четвертой колонке сделайте то же, что и в третьей, но на этот раз пронумеруйте пары переменных по второй колонке таблицы.


В колонке «d» вычислите разность между двумя рангами из предыдущих двух колонок. Например, если ранг в третьей колонке равен 1, а в четвертой – 3, то разница между ними составит 2. Знак не имеет значения, поскольку на следующем шаге эти числа будут возведены в квадрат.

Возведите каждое значение из колонки «d» в квадрат и запишите полученные величины в колонку «d 2 «.
Просуммируйте все значения из колонки «d 2 «. Вы определите сумму Σd 2 .

Воспользуйтесь одной из следующих формул:
Проанализируйте результат. Полученное значение находится между -1 и 1.
- Если оно близко к -1, корреляция отрицательна.
- Если близко к 0, корреляция отсутствует.
- Если близко к 1, наблюдается положительная корреляция.
- Не забудьте поделить на сумму переменных и взять корень. После этого поделите на Σd 2 .
Создайте новые колонки с рангами, соответствующими колонкам данных. Например, если данные внесены в Колонку A2:A11, используйте функцию «=RANK(A2,A$2:A$11)» и занесите результаты для всех строк в новую колонку.
Найдите ранги для одинаковых величин, как описано в шагах 3 и 4 метода 1.
В новой ячейке определите корреляцию между двумя колонками рангов с помощью функции «=CORREL(C2:C11,D2:D11)». В данном случае C и D – это колонки, содержащие ранги. Таким образом, в данной ячейке вы получите коэффициент ранговой корреляции Спирмена.
Если у вас еще нет программы R для обработки статистических данных, приобретите ее (см. http://www.r-project.org).
Сохраните данные в формате CSV, расположив их в двух колонках, корреляцию между которыми вы собираетесь исследовать. Сохранить файл в данном формате легко посредством опции «Сохранить как».
Откройте редактор R. Если вы еще не вошли в программу R, просто запустите ее. Для этого достаточно нажать иконку R на рабочем столе.
Наберите команды:
- d <- read.csv(«NAME_OF_YOUR_CSV.csv») и нажмите клавишу ввода
- cor(rank(d[,1]),rank(d[,2]))
- Как правило, набор данных должен состоять не менее чем из 5 пар для того, чтобы можно было достоверно установить какую-либо корреляцию (3 пары было использовано в примере выше для простоты).
- Коэффициент ранговой корреляции Спирмена позволяет установить лишь то, растут ли обе переменные или уменьшаются одновременно. Если разброс данных слишком велик, этот коэффициент не даст точного значения корреляции.
- Приведенная функция даст верный результат при отсутствии одинаковых значений в массиве данных. Если такие значения существуют, как в рассмотренном нами примере, необходимо использовать следующее определение: коэффициент корреляции, основанный на рангах.
Об этой статье
Эту страницу просматривали 68 110 раз.
Была ли эта статья полезной?
Для того, чтобы рассчитать коэффициент корреляции в Excell необходимо сделать следующие шаги:
1.Вносим значения для двух переменных в таблицу (Например Переменная 1 и Переменная 2)
2. Ставим курсор в пустую ячейку
3. На панеле инструментов нажимаем кнопку fx (вставить формулу)
4. В открывшемся окне «Мастер функций» в поле «Категории» выбираем Полный алфавитный перечень
5. Затем в поле «Выберите функцию» находим функцию КОРЕЛЛ
5.1. Нажимаем Ок
6. В открывшемся окне «Аргументы функции» в поле Массив1 вносим номера ячеек, содержащие значения Переменной 1, в поле Массив2 вносим номера ячеек, содержащие значения Переменной2.
7. Нажимаем Ок
8. Смотрим получившийся результат
Корреляция
Очень
часто психолога интересуют связи,
существующие между изучаемыми
явлениями. Если каждому значению одного
признака соответствует вполне
определенное значение другого признака,
то связь называется функциональной.
Так, площадь круга S
однозначно определяется его радиусом
R,
так как S
= nR
2
.
Когда
каждому значению одного признака
соответствует несколько более или
менее отличных значений другого признака,
связь именуется вероятностной или
корреляционной. Так, например,
представляются взаимозависимыми
вариации величины роста и веса тела
людей (прямая связь), силы мышц и их
подвижности (обратная связь).
Степень
варьирования значений одного признака
при данном значении другого может быть
различной, если эта степень варьирования
относительно мала, то связь близка к
функциональной.
При большом варьировании связь между
изучаемыми явлениями менее выражена,
степень связи меньше. Если любому
значению одного признака может
соответствовать любое значение другого
признака, то связь между такими признаками
отсутствует. Корреляцонные связи, таким
образом, могут быть разной степени
выраженности, разной степени тесноты.
Предельным
случаем наибольшей тесноты связи
является функциональная. Наименьшая
теснота связи соответствует случаю
отсутствия связи, когда варьирование
обоих признаков осуществляется взаимно
независимо. Степень тесноты связи может
быть выражена с помощью специальных
коэффициентов корреляции.
Линейный коэффициент корреляции по Пирсону
При
изучении тесноты связи между двумя
взаимно зависимыми признаками
применяется линейный коэффициент
корреляции, который показывает, существует
ли и сколь велика связь между этими
признаками [5;6].
Коэффициент
корреляции принимает значения от — 1 до
+ 1. В этих пределах возможны все числовые
значения коэффициента корреляции. Если
никакой связи между признаками не
существует, то коэффициент равен 0.
При положительной корреляции при
увеличении числовых значений одного
признака соответственно увеличиваются
числовые значения другого признака.
При отрицательной корреляции увеличению
числовых значений одного признака
соответствует уменьшение числовых
значений другого признака.
Пример
3.
Приводятся
данные о продолжительности ознакомления
(в секундах) и времени восприятия (в
секундах) системы пространственных
линий.
Ознакомление
X:
2,5 1,9 3,7 2,0 4,3 2,4 2,3 4,8 1,7 3,2 3,6 2,3 4,9 1,8 2,8 4,0 1,8
3,0 2,4 4,5 2,3 3,4 2,0 2,5; п1
=24.
Восприятие
Y:
3,2 1,5 2,4 3,6 4,5 3,0 3,1 4,2 2,9 3,5 4,0 3,0 4,3 2,5 2,9 3,6
2,5 3,2 2,9 3,9 2,7 3,6 2,4 3,0; п2
=24.
Что
можно сказать о существовании связи
между этими параметрами деятельности?
Покажем, как решить
эту задачу с помощью линейного
коэффициента корреляции по Пирсону.
Для решения задачи
с помощью линейного коэффициента
корреляции по Пирсону составим таблицу.