Вероятность, энтропия, информация. Ликбез, ч.2.
Главным свойством случайных событий является отсутствие полной уверенности в их наступлении, создающее известную неопределенность при выполнении связанных с этими событиями опытов. Однако совершенно ясно, что степень этой неопределенности в различных случаях будет совершенно разной. Если наш опыт состоит в определении цвета первой встретившейся нам вороны, то мы можем почти с полной уверенностью рассчитывать, что этот цвет будет черным — хотя зоологи и утверждают, что встречаются иногда белые вороны, вряд ли кто-нибудь усомнится в исходе такого опыта. Несколько менее определенен опыт, состоящий в выяснении того, окажется ли первый встреченный нами человек левшой или нет — здесь тоже предсказать результат опыта можно почти не колеблясь, но опасения относительно правильности этого предсказания будут более обоснованны, чем в первом случае. Значительно труднее предсказать заранее, будет ли первый встретившийся нам на улице города человек мужчиной или женщиной. Но и этот опыт имеет относительно небольшую степень неопределенности по сравнению, например, с попыткой заранее указать победителя в турнире с двадцатью совершенно незнакомыми нам участниками или определить номер лотерейного билета, на который выпадет наибольший выигрыш в предстоящем тираже лотереи: если, скажем, предсказав, что первый встреченный нами на улице человек будет мужчиной, мы еще можем надеяться угадать, то вряд ли кто-нибудь рискнет сделать прогноз в предпоследнем или, тем более, в последнем случае.
Для практики важно уметь численно оценивать степень неопределенности самых разнообразных опытов, чтобы иметь возможность сравнить их с этой стороны. Мы начнем здесь с рассмотрения опытов, имеющих k равновероятных исходов. Очевидно, что степень неопределенности каждого такого опыта определяется числом k: если при k = 1 исход опыта вообще не является случайным, то при большом k, т. е. при наличии большого числа разных исходов, предсказание результата опыта становится весьма затруднительным. Таким образом, совершенно ясно, что искомая численная характеристика степени неопределенности должна зависеть от k, т. е. являться функцией f(k) числа k. При этом для k = 1 эта функция должна обращаться в нуль (ибо в этом случае неопределенность полностью отсутствует), а при возрастании числа k она должна возрастать.
Для более полного определения функции f(k) надо предъявить к ней дополнительные требования. Рассмотрим два независимых опыта: α и β (т. е. такие два опыта, что любые сведения об исходе первого из них никак не меняют вероятностей исходов второго). Пусть опыт α имеет k равновероятных исходов, а опыт β имеет l равновероятных исходов; рассмотрим также сложный опыт αβ, состоящий в одновременном выполнении опытов α и β. Очевидно, что неопределенность опыта αβ больше неопределенности опыта α, так как к неопределенности α здесь добавляется еще неопределенность исхода опыта β. Естественно считать, что степень неопределенности опыта αβ равна сумме неопределенностей, характеризующих опыты α и β. А так как опыт α и β имеет, очевидно, kl равновероятных исходов (они получаются, если комбинировать каждый из k возможных исходов опыта α c l исходами β, то мы приходим к следующему условию, которому должна удовлетворять наша функция f(k):
Последнее условие наталкивает на мысль принять за меру неопределенности опыта, имеющего k равновероятных исходов, число log k (ибо log (kl) = log k + log l). Такое определение меры неопределенности согласуется также с условиями, что при k = 1 она равна нулю и что при возрастании k она возрастает. Впрочем, нетрудно строго показать, что логарифмическая функция является единственной функцией аргумента k, удовлетворяющей условиям f(kl) = f(k) + f(l), f (1) = 0 и f (к) > f (l) при k > l.
Заметим, что выбор основания системы логарифмов здесь несуществен, так как в силу известной формулы
переход от одной системы логарифмов к другой сводится лишь к умножению функции f(k) = log k на постоянный множитель (модуль перехода logba), т. е. равносилен простому изменению единицы измерения степени неопределенности. В конкретных применениях «меры степени неопределенности» обычно используются логарифмы при основании два (другими словами — считается, что f (k) = Iog2k). Это означает, что за единицу измерения степени неопределенности здесь принимается неопределенность, содержащаяся в опыте, имеющем два равновероятных исхода (например, в опыте, состоящем в подбрасывании монеты и выяснении того, какая сторона ее оказалась сверху, или в выяснении ответа «да» или «нет» на вопрос, по поводу которого мы с равными основаниями можем ожидать, что ответ будет утвердительным или отрицательным). Такая единица измерения неопределенности называется двоичной единицей (сокращенно дв. ед.) или битом (binary digit); в немецкой литературе используется также выразительное ее название «Ja-Nein Einheit» («да- нет единица»). Подобная «да-нет единица» является в каком-то смысле самой естественной. Мы тоже в дальнейшем будем все время пользоваться двоичными единицами (битами); таким образом запись log k (где мы, как правило, не будем указывать основания системы логарифмов) будет обычно означать log2 k. Заметим только, что практически ничего не изменилось бы, если бы мы использовали более привычные десятичные логарифмы; это лишь означало бы, что за единицу степени неопределенности принимается неопределенность опыта, имеющего 10 равновероятных исходов (таким является, например, опыт, состоящий в извлечении шара из урны с десятью перенумерованными шарами, или опыт по отгадыванию одной цифры, если любая из десяти цифр имеет одинаковую вероятность быть загаданной). Эта последняя единица степени неопределенности (которую называют десятичной единицей или дитом) примерно в 3.3 раза крупнее двоичной единицы (ибо log2 10 ≈ 3,32).
Таблица вероятностей для опыта, имеющего k равновероятных исходов, имеет вид:
| исходы опыта | А1 | А2 | А3 | … | Ak |
| вероятности | 1/k | 1/k | 1/k | … | 1/k |
Так как общая неопределенность опыта по нашему условию равна log к, то можно считать, что каждый отдельный исход, имеющий вероятность 1/k, вносит неопределенность, равную р(1/k) log к = — (1/k) log (1/k) . Но тогда естественно считать, что в результат опыта, таблица вероятностей для которого имеет вид
| исходы опыта | А1 | А2 | А3 |
| вероятности | 1/2 | 1/3 | 1/6 |
исходы А1, А2 и А3 вносят неопределенность, равную соответственно, —(1/2) log (1/2), —(1/3)log (1/3) и —(1/6) log (1/6) , так что общая неопределенность этого опыта равна
—(1/2) log (1/2) — (1/3)log (1/3) — (1/6) log (1/6)
Аналогично этому можно положить, что в самом общем случае, для опыта α с таблицей вероятностей

мера неопределенности равна
Это последнее число мы, руководствуясь некоторыми глубокими физическими аналогиями, несущественными, впрочем, для всего дальнейшего, будем называть энтропией опыта α и обозначать через Н(α).
lim (— р log р) = 0 ( при р → 0)
Можно доказать, что функция
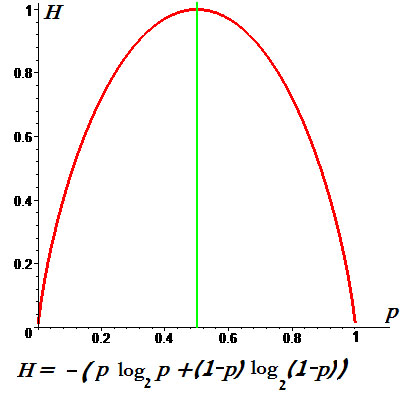
h (р) = — p log р — (1 — р) log (1 — р),
определяющая энтропию опыта с двумя исходами (вероятности которых равны р и 1 — р), принимает наибольшее значение (равное log 2 = 1) при р = 1/2. На рис. 1 изображен график этой функции, показывающии, как меняется энтропия k (р) при изменении р от 0 до 1.

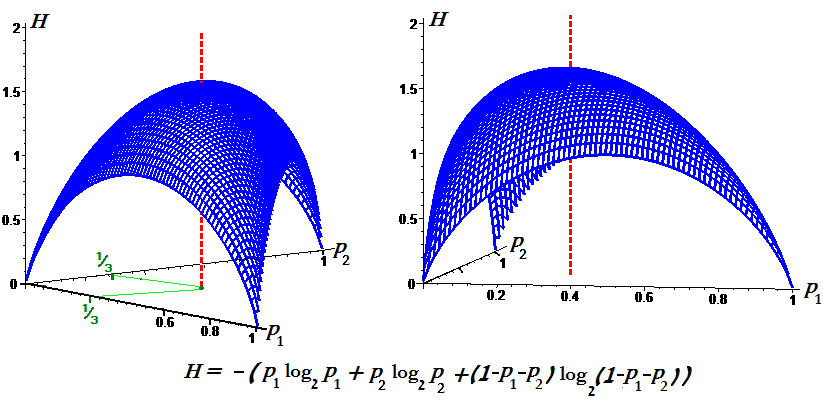
В случае опыта с k возможными исходами энтропия задается формулой
где р1, р2, . . ., pk — вероятности отдельных исходов, так что всегда
В этом более общем случае также можно доказать, что функция Н (р1, р2, . . ., pk) принимает наибольшее значение (равное log k) при р1 = р2 = . . . = pk = 1/k. Иными словами, максимум неопределенности возникает при равномерном распределении вероятностей событий.
Задача. Имеются две урны, содержащие по 20 шаров — 10 белых, 5 черных и 5 красных в первой и 8 белых, 8 черных и 4 красных во второй. Из каждой урны вытаскивают по одному шару. Исход какого из этих двух опытов следует считать более неопределенным?
Таблицы вероятностей для соответствующих опытов (обозначим их через α1 и α2) имеют вид: опыт α1 (извлечение шара из 1-й урны):
| цвет вынутого шара | белый | черный | красный |
| вероятность | 1/2 | 1/4 | 1/4 |
опыт α2 (извлечение шара из 2-й урны):
| цвет вынутого шара | белый | черный | красный |
| вероятность | 2/5 | 2/5 | 1/5 |
Энтропия первого опыта равна
Н (α1) = — (1/2) log (1/2) — (1/4) log (1/4) — (1/4) log (1/4) = 1,5 бита, а энтропия второго несколько больше:
Н (α2) = — (2/5) log (2/5) — (2/5) log (2/5) — (1/5) log (1/5) = 1,52 бита.
Поэтому, если оценивать (как мы это условились делать) степень неопределенности исхода опыта его энтропией, то надо считать, что исход второго опыта является более неопределенным, чем исход первого.
Задача. Пусть из многолетних наблюдений за погодой известно, что для определенного пункта вероятность того, что 15 июня будет идти дождь, равна 0,4, а вероятность того, что в указанный день дождя не будет, равна 0,6. Пусть далее для этого же пункта вероятность того, что 15 ноября будет идти дождь равна 0,65, вероятность того, что 15 ноября будет идти снег, равна 0,15 и вероятность того, что 15 ноября вовсе не будет осадков, равна 0,2. Если из всех характеристик погоды интересоваться лишь вопросом о наличии и о характере осадков, то в какой из двух перечисленных дней погоду в рассматриваемом пункте следует считать более неопределенной?
Согласно тому, как понимается здесь слово «погода», опыты α1 и α2, состоящие в выяснении того, какая погода имела место 15 июня и 15 ноября, характеризуются следующими таблицами вероятностей:
| исходы опыта | дождь | отсутствие осадков |
| вероятность | 0,4 | 0,6 |
| исходы опыта | дождь | снег | отсутствие осадков |
| вероятность | 0,65 | 0,15 | 0,2 |
Поэтому энтропии наших двух опытов равны
H (α1) = — 0,4 log 0,4 — 0,6 log 0,6 ≈ 0,97 бита,
H (α2) = — 0,65 log 0,65 — 0,15 log 0,15 — 0,2 log 0,2 ≈1,28 бита > H(α1).
Следовательно, погоду 15 ноября в рассматриваемом пункте следует считать более неопределенной, чем 15 июня.
2. Энтропия сложных событий. Условная энтропия
Пусть α и β — два независимых опыта с таблицами вероятностей:
| исходы опыта | А1 | А2 | …… | Аk |
| вероятности | p(А1) | p(А2) | ……. | p(Аk) |
| исходы опыта | B 1 | B 2 | …… | B l |
| вероятности | p(B1) | p(B2) | ……. | p(Bl) |
Рассмотрим сложный опыт αβ, состоящий в том, что одновременно осуществляются опыты α и β. Этот опыт может иметь kl исходов:
где, например, А1В1 означает, что опыт α имел исход А1, а опыт β — исход В1. Очевидно, что неопределенность опыта αβ больше неопределенности каждого из опытов α и β, так как здесь осуществляются сразу оба эти опыта, каждый из которых может иметь разные исходы в зависимости от случая.
В математической теории энтропии доказывается правило сложения энтропий независимых опытов α и β, которое хорошо согласуется со смыслом энтропии как меры степени неопределенности.
Предположим теперь, что опыты α и β не независимы (например, что α и β — последовательные извлечения двух шаров иэ одной урны). В этом более общем случае мы не можем ожидать, что энтропия сложного опыта αβ будет равна сумме энтропий α и β. В самом деле, здесь может представиться такой случай, когда результат второго опыта полностью определяется результатом первого (например, если опыты α и β состоят в последовательном извлечении шаров из урны, содержащей всего два разноцветных шара). В этом случае после осуществления α опыт β уже не будет содержать никакой неопределенности; поэтому здесь естественно предполагать, что энтропия (мера степени неопределенности) сложного опыта αβ будет равна энтропии одного опыта α, а не сумме энтропий опытов α и β (можно убедиться, что это на самом деле так). Постараемся выяснить, чему равна энтропия сложного опыта αβ в общем случае.
Здесь уже нельзя заменить вероятности р (AiBj) просто произведениями соответствующих вероятностей: теперь р (AiBj) равно не р (Ai) р (Bj), а р (Ai) рAi (Bj), где рAi (Bj) — условная вероятность события Bj при условии Ai.
Энтропия опыта β зависит от исхода опыта α, так как от исхода α зависят вероятности отдельных исходов β. Полученное из этих соображений выражение естественно назвать условной энтропией опыта β при условии Ai и обозначить через HAi(β).
Учитывая сказанное, назовем условной энтропией β при условии выполнения α (мы будем обозначать его через Нα (β)) выражение:
Таким образом, окончательно имеем:
Это и есть общее правило для определения энтропии сложного опыта αβ. Его тоже можно назвать правилом сложения энтропий, аналогично выведенному выше правилу, относящемуся к тому частному случаю, когда опыты α и β независимы.
Следует отметить, что именно средняя условная энтропия Нα (β) играет существенную роль в рассматриваемых в этой книге вопросах. Дело в том, что коль скоро мы знаем заранее, какой именно исход Ai опыта α имел место, то при последующем определении условной энтропии НAi (β) опыта β мы можем полностью игнорировать все строки таблицы условных вероятностей, кроме единственной строки, отвечающей исходу Ai. Поэтому условная энтропия НAi (β) совсем не зависит от того, как изменяются вероятности отдельных исходов β при k — 1 исходах опыта α (из общего числа k исходов) и, следовательно, она лишь в весьма малой степени характеризует связь между опытами α и β , полное выражение которой дается всей таблицей условных вероятностей. Напротив того, средняя условная энтропия Нα (β), вычисление которой не предполагает известным исход α, глубоко отражает взаимную зависимость опытов α и β .
Энтропия как мера степени неопределенности системы
Понятия возможности, случайности, вероятности находятся в определенном отношении с понятием неопределенности. Неопределенность существует объективно. Она всегда имеет место тогда, когда производится выбор из некоторой совокупности элементов одного элемента. Степень неопределенности выбора характеризуется отношением числа выбранных элементов к общему числу элементов совокупности (множества). Если множество состоит из одного элемента, то степень неопределенности равна нулю. Вероятность выбора в этом случае равна 1. Множество из двух элементов имеет вероятность выбора, равную p = . Степень неопределенности здесь будет равна 2. Вообще увеличение числа элементов в множестве ведет к росту степени неопределенности и к уменьшению вероятности выбора одного элемента. Бесконечное число элементов в множестве соответствует бесконечной неопределенности и нулевой вероятности. Из этого видно, что степень неопределенности и степень вероятности связаны друг с другом. Зная вероятность, можно определить степень неопределенности. Если мы должны угадать одно из 20 чисел, то, исходя из соображений равновозможности, вероятность угадать задуманное число будет составлять , а степень неопределенности равна 20. Однако при этом простой зависимости H=не получается (здесь Н — степень неопределенности и р — вероятность выбора элемента). При р = 0 степень неопределенности равна бесконечности: Н = = Если же р = 1, то Н = = 1, что является неверным, так как при р = 1 степень неопределенности должна быть равна 0, ибо в множестве один элемент выбирать не из чего. В связи с этим зависимость между неопределенностью Н и вероятностью р измеряется логарифмом величины :
H=log=-log p. (4.1)
При этом можно брать логарифмы по любому основанию, но принято брать логарифмы по основанию два.
Изучением степени неопределенности и связи ее с вероятностью занимается статистическая теория информации. Формула Н = log2 является логарифмической мерой количества информации. В теории информации рассматриваются любые события, в результате которых уменьшается, уничтожается, исчезает неопределенность.
Для оценки количества информации, связанной с появлением одного сообщения, пользуются формулой:
где pi — вероятность появления события St.
Такую оценку индивидуального количества информации называют индивидуальной энтропией. Индивидуальная энтропия события тем больше, чем меньше вероятность его появления. Однако статистическую теорию информации не интересует индивидуальное количество информации. Существенной для характеристики любого опыта являются не информации n1, n2. nN, связанные с отдельными исходами опыта, а средняя информация, которая определяется следующим образом.
Пусть для некоторого события х известно, что количество различных исходов равно N, а вероятности их равны соответственно pl,p2,-,pN, причем Pl +р2 +. + pN = 1.
В результате достаточно большого числа испытаний (их число равно М) получено, что первый исход наступил m1 раз, второй — т2 раз. N-й — тN раз (m1, + т2 +. + тN = М). Известно, что в результате единичного наступления i-го исхода опыта получаем индивидуальное количество информации:
ni=-logpi, (i=1, 2, …, N).
Поскольку первый исход наступил m1 раз, то полученное при этом суммарное количество информации равно n1m1 где n1 — индивидуальное количество информации, полученное в результате одного наступления первого исхода опыта. Аналогично получаем суммарное количество информации, полученное при наступлении второго исхода опыта и т. д. Общее количество информации, полученное в результате М испытаний, равно
а среднее количество информации, полученное в одном испытании, равно
Отсюда получаем среднее количество информации, характеризующее событие х:
Предположим, что опыт состоит в извлечении одного шара из ящика, в котором находится один черный и два белых шара. Исходя из классического подхода, вероятность выбора черного шара равна , а вероятность выбора белого шара равна . Среднее значение неопределенности получается, если вероятность отдельного исхода умножается на его неопределенность, и эти произведения складываются:
В общем виде формула степени неопределенности (количества информации в битах) имеет следующий вид:
Эта формула предложена в 1948 г. К. Шенноном. Ее называют еще формулой абсолютной негэнтропии. Она аналогична формуле энтропии, только имеет отрицательный знак.
Знак минус в правой части приведенного уравнения использован для того, чтобы сделать величину H положительной (поскольку pi <1, log2pi, ≤0, =l). Понятие энтропии ввел немецкий физик-теоретик Р. Клаузиус в 1865 г. Термин происходит от греческого слова — entrope — «замкнуть внутри». Он обозначает меру деградации какой-либо системы. В 1872 г. австрийский физик Л. Больцман связал энтропию с вероятностью состояния. Изменения энергии в изолированной системе описываются вторым законом термодинамики, который был сформулирован следующим образом: теплота не может сама собою перейти от более холодного тела к более теплому. Суть этого закона состоит в том, что способность изолированных систем совершать работу уменьшается, так как происходит рассеивание энергии. Формула энтропии определяет степень беспорядка, хаотичности молекул газа в сосуде. Естественным поведением любой системы является увеличение энтропии. Если энтропия имеет тенденцию к возрастанию, то система теряет информацию и деградирует. Чтобы система не деградировала, необходимо внести в нее дополнительную информацию (негэнтропию). Отсюда энтропия есть мера дезорганизации, а информация есть мера организованности. Всякий раз, когда в результате наблюдения система получает какую-либо информацию, энтропия этой системы уменьшается, а энтропия источника информации увеличивается.
По приведенной формуле определяется среднее количество информации в сообщениях при неравновероятных исходах опыта. Легко заметить, что при равновероятности исходов формула
превращается в формулы:
H = — log p u Hmax = log N,
поскольку сумма всех p всегда равна 1 и каждое рi = р. Запишем формулу Шеннона в виде:
Пусть все исходы равновероятны, тогда:
подставив эти значения в формулу, получим:
Из формулы степени неопределенности видно, что среднее количество информации в битах в дискретном сообщении о простом событии определяется как отрицательная сумма вероятностей всех возможных событий, умноженных на их логарифмы по основанию 2. Количество информации выше среднего приходится на события, вероятность которых ниже. Более высокую информационную емкость имеют редкие события. Формулой подтверждается также более низкая неопределенность систем с более высокой вероятностью событий. Поскольку вероятность одних событий повышается за счет снижения вероятности других (так как сумма всех вероятностей равна 1), энтропия становится тем ниже, чем менее вероятны события, а максимума она достигает при равновероятности всех событий.
Покажем, что Нmаx, получаемое при равновероятных исходах события, является верхней границей значений Н. Для этого найдем максимальное значение функции
используя множитель Лагранжа l.
Приравняем к нулю частные производные функции по рi:
Отсюда log pi =-loge-l и легко видеть, что все pi =, следовательно, Н = Нmax. Если же событие является достоверным (при этом pi = 1, а остальные pi =0, i j, то
Н = -0 * log0 — 0 * log0 +. -1 * logl +. — 0 * log0.
Легко показать, что выражение0 * log0 = 0• () = 0. Раскроем неопределенность, используя правило Лопиталя:
Тогда получим Н = 0 для достоверного события.
Следовательно, среднее количество информации находится в пределах
Теперь можно сформулировать определение условной вероятности. Если случайная величина х принимает значения x1, x2. xN а случайная величина y принимает значения y1, y2. yN, то условной вероятностью называется вероятность того, что х примет значение xi если известно, что у приняло значение yi.
Безусловная вероятность р (xi) равна условной вероятности, усредненной по всем возможным значениям y:
где p(yi) — вероятность j-го значения величины у, величина — вероятность того, что у примет значение yj a x -значение хi Она называется совместной вероятностью события (xiyi) и обозначается p (xiyi).
Очевидно, если события х и у независимы, то
Неопределенность события х определяется по формуле:
Если события x и y зависимы, и событие y приняло значение yi, то неопределенность события x становится равной
Так как событие у может принимать значение y1, y2. yM c вероятностями р(1), р(у2), … p(yM), средняя неопределенность события х при любых возможных исходах события у равна:
Это условная негэнтропия случайной величины х при задании случайной величины у. Она всегда не больше безусловной
причем равенство имеет место только в том случае, когда знание величины у не меняет вероятностей значений величины х, т. е.
каким бы ни было значение уi. Это условие означает, что неопределенность события х не возрастает от того, что событие у становится известно.
Для двух случайных событий х и у энтропия совместного события равна:
В полученном выражении
а второе слагаемое есть не что иное, как H(x/y).
Равенство достигается тогда, когда события х и у независимы.
В качестве меры количества информации в случайной величине у о случайной величине х принимается величина, на которую уменьшается в среднем неопределенность величины х, если нам становится известным значение величины у:
Эта формула выражает количество информации в случайной величине у о случайной величине х, как разность между безусловной и условной негэнтропией.
По формуле условной негэнтропии строится вся современная статистическая теория информации. Переход от абсолютной негэнтропии к условной приобретает фундаментальное решающее значение. Формула условной негэнтропии выражает количество информации относительно заданной системы отсчета, системы координат. Иначе говоря, она характеризует количество информации, содержащееся в одном объекте относительно другого объекта.
Классическая теория информации дает полезный аппарат, но он не универсален и множество ситуаций не укладываются в информационную модель Шеннона. Далеко не всегда можно заранее установить перечень возможных состояний системы и вычислить их вероятности. Кроме того, основным недостатком этой теории является то, что, занимаясь только формальной стороной сообщений, она оставляет в стороне их ценность и важность. Например, система радиолокационных станций ведет наблюдение за воздушным пространством с целью обнаружения самолета противника. Система S, за которой ведется наблюдение, может быть в одном из двух состояний: x1 — противник есть, х2 — противника нет. Выяснение фактического состояния системы принесло бы в рамках классической теории информации 1 бит, однако первое сообщение гораздо важнее, что оценить невозможно с помощью вероятностного подхода.
Статистическая теория информации оперирует лишь вероятностями исходов рассматриваемых опытов и полностью игнорирует содержание этих исходов. Поэтому эта теория не может быть признана пригодной во всех случаях. Понятие информации в ней трактуется весьма односторонне.
Следовательно, уничтожение неопределенности, т. е. получение информации, может происходить не только в результате вероятностного процесса, но и в других формах. Понятие неопределенности оказывается шире понятия вероятности. Неопределенность — понятие, отражающее отсутствие однозначности выбора элементов множества. Если этот выбор имеет случайный характер, то мы имеем дело со статистической теорией информации. Если же этот выбор не случаен, то необходим невероятностный подход к определению информации. Существуют следующие невероятностные подходы к определению информации: динамический, топологический, алгоритмический. Мы не будем рассматривать эти невероятностные подходы к определению количества информации, отметим только, что каждый из этих методов обнаруживает нечто общее со статистическим подходом. Оно состоит в том, что эти методы изучают переход от неопределенности к определенности. Но все же эти методы отличаются от статистического подхода. Один из невероятностных подходов к определению количества информации принадлежит советскому ученому А. Н. Колмогорову. По аналогии с вероятностным определением количества информации как функции связи двух систем, он вводит определение алгоритмического количества информации.
Количество информации, содержащееся в сообщении, можно связывать не только с мерой неопределенности системы, но и с ее структурной сложностью и точностью измерений. Такой подход предлагается к оценке научной информации, возникающей в результате анализа процесса наблюдений и эксперимента.
Количество различных признаков, характеризующих данный предмет, т. е. его размерность или число степеней свободы, является мерой структурной информации. Ясно, что цветное изображение содержит в себе больше информации по сравнению с черно-белым изображением того же объекта. Единица структурной информации — логон — означает, что к имеющемуся представлению можно добавить одну новую различимую группу или категорию.
Количество метрической информации связано с разрешающей способностью измерений. Например, эксперимент, результат которого обладает погрешностью, равной 1 %, дает больше информации, чем эксперимент, характеризующийся погрешностью в 10 %.
Единицей измерения метрической информации является метрон. В случае числового параметра эта единица служит мерой точности, с которой этот параметр определен.
Статистический и нестатистический подходы в теории информации касаются только количества информации, но информация имеет еще и качественный аспект. Объединение элементов в множество всегда предполагает наличие у них некоторого свойства, признака, благодаря чему они образуют данное множество, а не иное. Следовательно, каждый элемент множества обладает определенным качественным отличием от элемента другого множества. Кроме того, внутри множества различие элементов друг от друга носит тоже качественный характер. Поиск качественного аспекта информации как раз и состоит в учете природы элементов, объединяемых в множества, в учете качественного многообразия материи.
До сих пор информация рассматривалась как снятая, устраняемая неопределенность. Именно то, что устраняет, уменьшает любую неопределенность и есть информация. Однако информацию можно рассматривать не только как снятую неопределенность, а несколько шире. Например, в биологии информация — это, прежде всего, совокупность реальных сигналов, отображающих качественное или количественное различие между какими-либо явлениями, предметами, процессами, структурами, свойствами. Такой более широкий подход к определению понятия информации сделал У. Росс Эшби. Он считает, что понятие информации неотделимо от понятия разнообразия. Природа информации заключается в разнообразии, а количество информации выражает количество разнообразия. Одно и то же сообщение при разных обстоятельствах может содержать различное количество информации. Это зависит от разнообразия, которое наблюдается в системе.
Слово «разнообразие» означает число различных элементов в множестве. Так, например, множество с, b, с, а, с, с, а, b, с, b, b, а, если не принимать во внимание порядок расположения элементов, содержит 12 элементов, и только три из них различные: а, b, с. Такое множество имеет разнообразие в три элемента.
Множество с разнообразием и множество с вероятностями имеют эквивалентные свойства. Так, множество, у которого все элементы различны, имеет максимальное количество разнообразия. Чем больше в системе разнообразия, тем больше неопределенность в поведении такой системы. Уменьшение разнообразия уменьшает неопределенность системы. Вероятность выбрать наугад данный элемент из множества с максимальным разнообразием равна единице, деленной на количество всех элементов множества . Нетрудно видеть, что это аналогично статистической совокупности с равномерным распределением вероятностей. Количество информации в этом случае имеет максимальное значение. Множество, у которого все элементы одинаковы, содержит минимальное количество разнообразия — всего в один элемент. Аналогией такого множества является статистическая совокупность с таким распределением вероятностей, когда одна из них равна единице, а остальные нулю. Количество информации в такой совокупности равно нулю. В множестве информация появляется только тогда, когда один элемент отличается от другого. Подобно вероятности разнообразие может измеряться как число различных элементов и как логарифм этого числа, например, по основанию два. Между минимальным и максимальным количеством разнообразия во множестве существует ряд промежуточных состояний, которые появляются в результате ограничения разнообразия. Понятие ограничения разнообразия является очень важным. Оно представляет собой отношение между двумя множествами. Это отношение возникает, когда разнообразие, существующее при одних условиях, меньше, чем разнообразие, существующее при других условиях.
Ограничения разнообразия весьма обычны в окружающем нас мире. Любой закон природы подразумевает наличие некоторого инварианта, поэтому всякий закон природы есть ограничение разнообразия.
Окружающий мир чрезвычайно богат ограничениями разнообразия. Без ограничений разнообразия мир был бы полностью хаотичным. Ограничение разнообразия соответствует уменьшению количества информации, поэтому ограничение разнообразия равносильно установившемуся в статистической теории понятию избыточности. Избыточность тем больше, чем больше ограничение разнообразия. Если же элементы в множестве одинаковы, то избыточность равна единице. Если в ящике все шары оказываются одинакового цвета, то их избыточность по цвету равна единице, если же все шары будут разного цвета, то избыточность равна нулю. Наличие у информации качества вызывает необходимость в классификации видов информации. Различают элементарную информацию, т. е. информацию в неживой природе, биологическую, логическую, человеческую, или социальную. Для социальной информации характерно выделение двух аспектов: семантического, связанного с содержанием сообщений, и прагматического, связанного с полезностью их для получателя.
Какое понятие вводят для того чтобы охарактеризовать степень неопределенности случайного события
Установив, что случайные процессы являются адекватной моделью сигналов, мы получаем возможность воспользоваться результатами и мощным аппаратом теории случайных процессов. Это не означает, что теория вероятностей и теория случайных процессов дают готовые ответы на все вопросы о сигналах: подход с новых позиций выдвигает такие вопросы, которые просто не возникали. Так и родилась теория информации, специально рассматривающая сигнальную специфику случайных процессов. При этом были построены принципиально новые понятия и получены новые, неожиданные результаты, имеющие характер научных открытий.
Понятие неопределенности
Первым специфическим понятием теории информации является понятие неопределенности случайного объекта, для которого удалось ввести количественную меру, названную энтропией. Начнем с простейшего примера — со случайного события. Пусть, например, некоторое событие может произойти с вероятностью 0,99 и не произойти с вероятностью 0,01, а другое событие имеет вероятности соответственно 0,5 и 0,5. Очевидно, что в первом случае результатом опыта «почти наверняка» является наступление события, во втором же случае неопределенность исхода так велика, что от прогноза разумнее воздержаться.
Для характеристики размытости распределения широко используется второй центральный момент (дисперсия) или доверительный интервал. Однако эти величины имеют смысл лишь для случайных числовых величин и не могут применяться к случайным объектам, состояния которых различаются качественно. Следовательно, мера неопределенности, связанной с распределением, должна быть некоторой его числовой характеристикой, функционалом от распределения, никак не связанным с тем, в какой шкале измеряются реализации случайного объекта.
Энтропия и ее свойства
Примем (пока без обоснования) в качестве меры неопределенности случайного объекта А с конечным множеством возможных состояний А1. Аn с соответствующими вероятностями P1,P2. Pn величину
которую и называют энтропией случайного объекта А (или распределения < >. Убедимся, что этот функционал обладает свойствами, которые вполне естественны для меры неопределенности.
- Н(p1. pn)=0 в том и только в том случае, когда какое-нибудь одно из
- Н(p1. pn) достигает наибольшего значения при p1=. pn=1/n т.е. в случае максимальной неопределенности. Действительно, вариация Н по pi при условии ∑pi = 1 дает pi = const = 1/n.
- Если А и В — независимые случайные объекты, то H(A∩B) = H(
- Если А и В — зависимые случайные объекты, то H(A∩B) = H(A) + H(B/A) = H(B) + H(A/B), где условная энтропия H(А/В) определяется как математическое ожидание энтропии условного распределения. Это свойство проверяется непосредственно.
- Имеет место неравенство Н(А) > Н(А/В), что согласуется с интуитивным предположением о том, что знание состояния объекта В может только уменьшить неопределенность объекта А, а если они независимы, то оставит ее неизменной.
Как видим, свойства функционала Н позволяют использовать его в качестве меры неопределенности.
Дифференциальная энтропия
Обобщение столь полезной меры неопределенности на непрерывные случайные величины наталкивается на ряд сложностей, которые, однако, преодолимы. Прямая аналогия
не приводит к нужному результату: плотность p(x) является размерной величиной (размерность плотности p(x) обратно пропорциональна x а логарифм размерной величины не имеет смысла. Однако положение можно исправить, умножив p(x) под знаком логарифма на величину К, имеющую туже размерность, что и величина х:
Теперь величину К можно принять равной единице измерения х, что приводит к функционалу
который получил название «дифференциальной энтропии». Это аналог энтропии дискретной величины, но аналог условный, относительный: ведь единица измерения произвольна. Запись (3) означает, что мы как бы сравниваем неопределенность случайной величины, имеющей плотность p(x), с неопределенностью случайной величины, равномерно распределенной в единичном интервале. Поэтому величина h(X) в отличие от Н(Х) может быть не только положительной. Кроме того, h(X) изменяется при нелинейных преобразованиях шкалы х, что в дискретном случае не играет роли. Остальные свойства h(X) аналогичны свойствам Н(Х), что делает дифференциальную энтропию очень полезной мерой.
Пусть, например, задача состоит в том, чтобы, зная лишь некоторые ограничения на случайную величину (типа моментов, пределов области возможных значений и т.п.), задать для дальнейшего (каких-то расчетов или моделирования) конкретное распределение. Один из подходов к решению этой задачи дает «принцип максимума энтропии»: из всех распределений, отвечающих данным ограничениям, следует выбирать то, которое обладает максимальной дифференциальной энтропией. Смысл этого критерия состоит в том, что, выбирая максимальное по энтропии распределение, мы гарантируем наибольшую неопределенность, связанную с ним, т.е. имеем дело с наихудшим случаем при данных условиях.
Фундаментальное свойство энтропии случайного процесса
Особое значение энтропия приобретает в связи с тем, что она связана с очень глубокими, фундаментальными свойствами случайных процессов. Покажем это на примере процесса с дискретным временем и дискретным конечным множеством возможных состояний.
Назовем каждое такое состояние «символом», множество возможных состояний — «алфавитом», их число m — «объемом алфавита». Число возможных последовательностей длины n, очевидно, равно mn. Появление конкретной последовательности можно рассматривать как реализацию одного из mn возможных событий. Зная вероятности символов и условные вероятности появление следующего символа, если известен предыдущий (в случае их зависимости), можно вычислить вероятность P(C) для каждой последовательности С. Тогда энтропия множества
На множестве
Математическое ожидание этой функции
Это соотношение является одним из проявлений более общего свойства дискретных эргодических процессов. Оказывается, что не только математическое ожидание величины fn(C) при n стремящемся к бесконечности имеет своим пределом H, но и сама эта величина fn(C) стремится к H при n стремящемся к бесконечности. Другими словами, как бы малы ни были e > 0 и s > 0, при достаточно большом n справедливо неравенство
т.е. близость fn(C) к H при больших n является почти достоверным событием.
Для большей наглядности сформулированное фундаментальное свойство случайных процессов обычно излагают следующим образом. Для любых заданных e > 0 и s > 0 можно найти такое no, что реализация любой длины n > no распадаются на два класса:
- группа реализаций, вероятность P(C) которых удовлетворяет неравенству |[1/n]⋅log(P(C))+H| < ε
- группа реализаций, вероятности которых этому неравенству не удовлетворяют.
Cуммарные вероятности этих групп равны соответственно 1-s и s, то первая группа называется «высоковероятной», а вторая — «маловероятной».
Это свойство эргодических процессов приводит к ряду важных следствий, из которых три заслуживают особого внимания.
- независимо от того, каковы вероятности символов и каковы статистические связи между ними, все реализации высоковероятной группы приблизительно равновероятны. Это следствие, в частности, означает, что при известной вероятности P(C) одной из реализаций высоковероятной группы можно оценить число N1 реализаций в этой группе: N1 = 1 / P(C).
- Энтропия Hn с высокой точностью равна логарифму числа реализаций в высоковероятной группе: Hn = n * H = log N1
- При больших n высоковероятная группа обычно охватывает лишь ничтожную долю всех возможных реализаций (за исключением случая равновероятных и независимых символов, когда все реализации равновероятны и и H = log m).
Действительно, из соотношения (9) имеем
Число N всех возможных реализаций есть
Доля реализаций высоковероятной группы в общем числе реализаций выражается формулой
и при H < logm эта доля неограниченно убывает с ростом n. Например, если a = 2, n = 100, H = 2,75, m = 8, то
т.е. к высоковероятной группе относится лишь одна тридцати миллионная доля всех реализаций!
Строгое доказательство фундаментального свойства эргодических процессов здесь не приводится. Однако следует отметить, что в простейшем случае независимости символов это свойство является следствием закона больших чисел. Действительно, закон больших чисел утверждает, что с вероятностью, близкой к 1, в длиной реализации i-й символ, имеющий вероятность pi встретится примерно npi раз. Следовательно вероятность реализации высоковероятной группы есть
что и доказывает справедливость фундаментального свойства в этом случае.
Подведем итог
Связав понятие неопределенности дискретной величины с распределением вероятности по возможным состояниям и потребовав некоторых естественных свойств от количественной меры неопределенности, мы приходим к выводу, что такой мерой может служить только функционал (1), названный энтропией. С некоторыми трудностями энтропийный подход удалось обобщить на непрерывные случайные величины (введением дифференциальной энтропии) и на дискретные случайные процессы.
Количество информации
В основе всей теории информации лежит открытие, что «информация допускает количественную оценку». В простейшей форме эта идея была выдвинута еще в 1928г. Хартли, но завершенный и общий вид придал ее Шэннон в 1948г. Не останавливаясь на том, как развивалось и обобщалось понятие количества информации, дадим сразу ее современное толкование.
Количество информации как мера снятой неопределенности
Процесс получения информации можно интерпретировать как «изменение неопределенности в результате приема сигнала». Проиллюстрируем эту идею на примере достаточно простого случая, когда передача сигнала происходит при следующих условиях:
- полезный (передаваемый) сигнал является последовательностью статистически независимых символов с вероятностями p(xi),i = 1,m ;
- принимаемый сигнал является последовательностью символов Yk того же алфавита;
- если шумы (искажения) отсутствуют, то принимаемый сигнал совпадает с отправленным Yk=Xk ;
- если шум имеется, то его действие приводит к тому, что данный символ либо остается прежним (i-м), либо подменен любым другим (k-м) с вероятностью p(yk/xi) ;
- искажение данного символа является событием статистически независимым от того, что произошло с предыдущим символом.
Итак, до получения очередного символа ситуация характеризуется неопределенностью того, какой символ будет отправлен, т.е. априорной энтропией Н(Х). После получения символа yk неопределенность относительно того, какой символ был отправлен, меняется: в случае отсутствия шума она вообще исчезает (апостериорная энтропия равна нулю, поскольку точно известно, что был передан символ yk=xi), а при наличии шума мы не можем быть уверены, что принятый символ и есть переданный, т.е. возникает неопределенность, характеризуемая апостериорной энтропией H(X/yk)=H(
В среднем после получения очередного символа энтропия H(X/Y)=My
Определим теперь количество информации как меру снятой неопределенности: числовое значение количества информации о некотором объекте равно разности априорной и апостериорной энтропии этого объекта, т.е. I(X,Y) = H(X)-H(X/Y). (1)
Используя свойство 2 энтропии, легко получить, что I(X,Y) = H(Y) — H(Y/X) (2)
В явной форме равенство (1) запишется так:
а для равенства (2) имеем:
Количество информации как мера соответствия случайных процессов
Представленным формулам легко придать полную симметричность: умножив и разделив логарифмируемое выражение в (3) на p(yk), а в (4) на p(xi) сразу получим, что
Эту симметрию можно интерпретировать так: «количество информации в объекте Х об объекте Y равно количеству информации в объекте Y об объекте Х. Таким образом, количество информации является не характеристикой одного из объектов, а характеристикой их связи, соответствия между их состояниями. Подчеркивая это, можно сформулировать еще одно определение: «среднее количество информации, вычисляемое по формуле (5), есть мера соответствия двух случайных объектов».
Это определение позволяет прояснить связь понятий информации и количества информации. Информация есть отражение одного объекта другим, проявляющееся в соответствии их состояний. Один объект может быть отражен с помощью нескольких других, часто какими-то лучше, чем остальными. Среднее количество информации и есть числовая характеристика степени отражения, степени соответствия. Подчеркнем, что при таком описании как отражаемый, так и отражающий объекты выступают совершенно равноправно. С одной стороны, это подчеркивает обоюдность отражения: каждый из них содержит информацию друг о друге. Это представляется естественным, поскольку отражение есть результат взаимодействия, т.е. взаимного, обоюдного изменения состояний. С другой стороны, фактически одно явление (или объект) всегда выступает как причина, другой — как следствие; это никак не учитывается при введенном количественном описании информации.
Формула (5) обобщается на непрерывные случайные величины, если в отношении (1) и (2) вместо Н подставить дифференциальную энтропию h; при этом исчезает зависимость от стандарта К и, значит, количество информации в непрерывном случае является столь же безотносительным к единицам измерения, как и в дискретном:
где р(x), p(y) и p(x,y) — соответствующие плотности вероятностей.
Свойства количества информации
Отметим некоторые важные свойства количества информации.
- Количество информации в случайном объекте Х относительно объекта Y равно количеству информации в Y относительно Х: I(X,Y) = I(Y,X)
- Количество информации неотрицательно: I(X,Y) > 0. Это можно доказать по-разному. Например, варьированием p(x,y) при фиксированных p(x) и p(y) можно показать, что минимум I, равный нулю, достигается при p(x,y) = p(x) p(y).
- Для дискретных Х справедливо равенство I(X,X) = H(X).
- Преобразование y (.) одной случайной величины не может увеличить содержание в ней информации о другой, связанной с ней, величине: I[y (X),Y] < I(X,Y) (9)
- Для независимых пар величин количество информации аддитивно: I(
Единицы измерения энтропии и количества информации
Рассмотрим теперь вопрос о единицах измерения количества информации и энтропии. Из определений I и H следует их безразмерность, а из линейности их связи — одинаковость их единиц. Поэтому будем для определенности говорить об энтропии. Начнем с дискретного случая. За единицу энтропии примем неопределенность случайного объекта, такого, что
Легко установить, что для однозначного определения единицы измерения энтропии необходимо конкретизировать число m состояний объекта и основание логарифма. Возьмем для определенности наименьшее число возможных состояний, при котором объект еще остается случайным, т.е. m=2, и в качестве основания логарифма также возьмем число 2. Тогда из равенства
вытекает, что p1=p2=1/2. Следовательно, единицей неопределенности служит энтропия объекта с двумя равновероятными состояниями. Эта единица получила название «бит». Бросание монеты дает количество информации в один бит. Другая единица «нит» получается, если использовать натуральные логарифмы. Обычно она употребляется для непрерывных величин.
Количество информации в индивидуальных событиях
Остановимся еще на одном важном моменте. До сих пор речь шла о среднем количестве информации, приходящемся на пару состояний (xi,yk) объектов X и Y. Эта характеристика естественна для рассмотрения особенностей стационарно функционирующих систем, когда в процессе функционирования принимают участие все возможные пары (xi,yk). Однако в ряде практических случаев оказывается необходимым рассмотреть информационное описание конкретной пары состояний, оценить содержание информации в конкретной реализации сигнала. Тот факт, что некоторые сигналы несут информации намного больше, чем другие, виден на примере того, как отбираются новости средствами массовой информации (о рождении шестерых близнецов сообщают практически все газеты мира, а о рождении двойни не пишут).
Допуская существование количественной меры информации (xi,yk), в конкретной паре (xi,yk) естественно потребовать, чтобы индивидуальное и среднее количество информации удовлетворяли соотношению
Хотя равенство имеет место не только при равенстве всех слагаемых, сравнение формул (5) и, например, (4) наталкивает на мысль, что мерой индивидуальной информации в дискретном случае может служить величина
называемая «информационной плотностью». Свойства этих величин согласуются с интуитивными представлениями и, кроме того, доказана единственность меры, обладающей указанными свойствами. Полезность введения понятия индивидуального количества информации проиллюстрируем на следующем примере.
Пример
Пусть по выборке (т.е. совокупности наблюдений x=x1. xn требуется отдать предпочтение одной из конкурирующих гипотез (H или H1), если известны распределения наблюдений при каждой из них, т.е. p(x/H0) и p(x/H1). Как обработать выборку? Из теории известно, что никакая обработка не может увеличить количество информации, содержащегося в выборке x (см. формулу (9). Следовательно, выборке x следует поставить в соответствие число, содержащее всю полезную информацию, т.е. обработать выборку без потерь. Возникает мысль о том, чтобы вычислить индивидуальное количество информации в выборке x о каждой из гипотез и сравнить их:
Какой из гипотез теперь отдать предпочтение зависит теперь от величины 7d 0i и от того, какой порог сравнения мы назначим. Оказывается, что мы получили статистическую процедуру, оптимальность которой специально доказывается в математической статистике, — именно к этому сводится содержание фундаментальной леммы Неймана-Пирсона. Данный пример иллюстрирует эвристическую силу теоретико-информационных представлений.
Подведем итог
Для системного анализа теория информации имеет двоякое значение. Во-первых, ее конкретные методы позволяют провести ряд количественных исследований информационных потоков в изучаемой или проектируемой системе. Однако более важным является эвристическое значение основных понятий теории информации — неопределенности, энтропии, количество информации, избыточности, пропускной способности и пр. Их использование столь же важно для понимания системных процессов, как и использование понятий, связанных с временными, энергетическими процессами. Системный анализ неизбежно выходит на исследование ресурсов, которые потребуются для решения анализируемой проблемы. Информационные ресурсы играют далеко не последнюю роль наряду с остальными ресурсами — материальными, энергетическими, временными, кадровыми.
Теория информации по Шеннону
Пусть случайное событие заключается в осуществлении одного из несовместимых состояний $ S_<1>,\dots,S_n $, вероятности появления которых даются таблицей $$ \begin
Если наше событие (опыт) состоит в определении цвета первой встретившейся нам вороны, то мы можем почти с полной уверенностью рассчитывать, что этот цвет будет черным. Несколько менее определено событие (опыт), состоящее в выяснении того, окажется ли первый встреченный нами человек левшой или нет — здесь тоже предсказать результаты опыта можно, почти не колеблясь, но опасения в относительно правильности этого предсказания будут более обоснованны, чем в предыдущем случае. Значительно труднее предсказать заранее пол первого встретившегося нам на улице человека. Но и этот опыт имеет относительно небольшую степень неопределенности по сравнению, например с попыткой определить победителя в чемпионате страны по футболу с участием двадцати совершенно незнакомых нам команд.
Для практики важно уметь численно оценивать степень неопределенности самых разнообразных случайных событий (опытов), чтобы иметь возможность сравнивать их с этой стороны. Искомая численная характеристика должна быть функцией числа $ n_<> $ возможных состояний. Некоторые свойства этой функции $ f(n) $ определяются соображениями здравого смысла. При $ n_<>=1 $ событие вообще не является случайным, т.е. следует положить $ f(1)=0 $. При возрастании числа $ n_<> $ возможных состояний эта функция должна возрастать поскольку увеличение количества возможных исходов опыта увеличивает неопределенность в предсказании его результатов.
Идем далее: рассмотрим два независимых события $ A_<> $ и $ B_<> $. Пусть событие $ A_<> $ имеет $ k_<> $ равновероятных исходов, а событие $ B_<> $ имеет $ \ell_<> $ равновероятных исходов. Рассмотрим событие, состоящее в произведении (совместном осуществлении) событий $ A_<> $ и $ B_<> $, обозначим это событие $ AB_<> $. Например, если событие $ A_<> $ заключается в появлении масти карты — бубновой ♦ , червовой ♥ , трефовой ♣ или пиковой ♠ — при выборе ее из колоды в $ 36_<> $ карт, а событие $ B_<> $ заключается в появлении достоинства карты — шестерки,семерки, восьмерки, девятки, десятки, валета, дамы, короля или туза — при выборе ее из той же колоды, то событие $ AB_<> $ заключается в появлении конкретной карты колоды. Очевидно, что неопределенность события $ AB_<> $ больше неопределенности события $ A_<> $, так как к неопределенности $ A_<> $ добавляется неопределенность события $ B_<> $. Естественно потребовать, чтобы мера неопределенности события $ AB_<> $ была равна сумме неопределенностей, характеризующих события $ A_<> $ и $ B_<> $. Это требование обеспечивается следующим следующим свойством функции $ f_<> $: $$ f(k\ell)=f(k)+f(\ell) \ , $$ имеющего тот смысл, что число $ k\ell $ как раз и дает число возможных исходов события $ AB_<> $.
Последнее равенство наталкивает на мысль принять за меру неопределенности опыта, имеющего $ n_<> $ равновероятных исходов, число $ \log n $. Можно доказать, что логарифмическая функция является единственной непрерывной функцией аргумента $ n\in \mathbb R $, удовлетворяющей такому функциональному уравнению. При этом выбор основания системы логарифмов несуществен, так как, в силу известной формулы $ \log_b n = \log_b a \cdot \log_a n $, переход от одной системы логарифмов к другой сводится лишь к умножению функции $ f(n)=\log n $ на постоянный множитель $ \log_b a $, т.е. равносилен простому изменению единицы измерения степени неопределенности. Единственным ограничением является естественное требование, чтобы основание было большим $ 1 $: число $ \log_b n $ должно быть положительным
Таблица вероятностей события, имеющего $ n_<> $ равновероятных состояний, имеет вид $$ \begin
Можно проверить, что функция $ H(P_1,P_2,\dots,P_n) $ симметрична относительно своих переменных; этот факт имеет тот смысл, что мера неопределенности события не зависит от способа нумерации его возможных состояний. Кроме того эта функция обладает следующими свойствами.
1. $ H_<> $ непрерывна по каждой своей переменной;
2. Если все вероятности одинаковы: $ P_1=1/n,P_2=1/n,\dots,P_n=1/n $, то $ H_<> $ монотонно возрастающая функцией по $ n_<> $: $$H \bigg(\underbrace<\frac<1>
3. При распадении какого-то события на два последовательных, величина $ H_<> $ должна вычисляться как взвешенная сумма составляющих значений $ H_<> $. Иллюстрирую на примере, который беру у Шеннона, но при этом излагаю в русском фольклорном стиле.
Мера неопределенности этого события $ H(1/3,1/6,1/2) $. Теперь посчитаем меру неопределенности по-другому, объединив сначала первые два состояния в одно. Лягушка в течение минуты
Кроме того известно, что если лягушка точно превратилась в женщину, то ( условная ) вероятность того, что она стала бабой-Ягой равна $ 2/3 $, и, следовательно, вероятность появления Василисы Премудрой оказывается равной $ 1/3 $. В результате получаем два значения для функции $ H_<> $, именно $ H(1/2,1/2 ) $ и $ H(2/3 , 1/3 ) $. 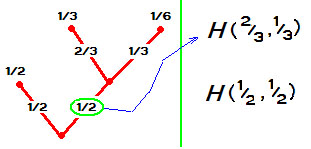 Как должны быть связаны эти новые величины со старой — с $ H(1/3,1/6,1/2) $? Конечный результат у обоих событий одинаков, во втором случае мы просто искусственно «вставили» одно промежуточное событие. Так вот, имеет место равенство: $$H(1/3,1/6,1/2)=H(1/2,1/2 )+\frac<1> <2>H(2/3 , 1/3 ) \ , $$ здесь весовой множитель $ 1/2 $ в составе второго слагаемого возникает из-за того, что ситуация второго события происходит только в половине случаев. ♦
Как должны быть связаны эти новые величины со старой — с $ H(1/3,1/6,1/2) $? Конечный результат у обоих событий одинаков, во втором случае мы просто искусственно «вставили» одно промежуточное событие. Так вот, имеет место равенство: $$H(1/3,1/6,1/2)=H(1/2,1/2 )+\frac<1> <2>H(2/3 , 1/3 ) \ , $$ здесь весовой множитель $ 1/2 $ в составе второго слагаемого возникает из-за того, что ситуация второго события происходит только в половине случаев. ♦
Формализуем: утверждается, что функция $ H_<> $ удовлетворяет условию $$ H(P_1,P_2,P_3,\dots,P_n)=H(P_1+P_2,P_3,\dots,P_n)+(P_1+P_2)H\left(\frac
Перечисленные свойства 1 — 3 оказываются настолько «жесткими», что будучи формально наложенными на произвольную функцию $ H_<> $, задают ее, фактически, однозначно:
Теорема [Шеннон]. Единственной функцией, удовлетворяющей условиям 1 — 3 , является функция $$ H=- K \sum_
После приведения этой формулировки, Шеннон пишет:
Происхождение слова «энтропия» ☞ ЗДЕСЬ.
Пример. Графики энтропии для $ n_<>=2 $
Свойства энтропии
Проанализируем теперь формулу для энтропии.
Теорема 1. $ H=0 $ тогда и только тогда, когда одна из вероятностей равна $ 1_<> $ при всех остальных, равных нулю (мера недостоверности наверняка осуществимого события равна $ 0_<> $).
Теорема 2. При фиксированном $ n_<> $ максимум функции $ H_<> $ достигается при всех вероятностях одинаковых: $$ \max_
Теорема 3. Пусть случайные события $ A_<> $ и $ B_<> $ независимы. Тогда энтропия произведения (совместного осуществления) событий $ A \cdot B $ равна сумме энтропий перемножаемых событий:
$$ H ( A \cdot B) = H(A) + H(B) \ . $$
Доказательство. Пусть случайное событие $ A_<> $ может находиться в состояниях $ S_1,\dots,S_n $ с вероятностями, заданными таблицей $$ \begin
Для любых случайных событий $ A_<> $ и $ B_<> $ энтропия их произведения (совместного появления) $ A \cdot B $ не превосходит суммы энтропий перемножаемых событий:
$$ H ( A \cdot B) \le H(A) + H(B) \ . $$
Условная энтропия
Предположим теперь, что события $ A_<> $ и $ B_<> $ не являются независимыми. Выясним, чему равна энтропия произведения этих событий. Общая формула для энтропии дает $$ H(AB)=-\sum_
Перепишем теперь все эти определения с использованием матричного формализма. Если обозначить $$ P_
Теорема 4. Для энтропии произведения случайных событий $ A_<> $ и $ B_<> $ имеет место правило сложения энтропий: $$ H(AB)=H(A)+ H_A(B) \ . $$
Проиллюстрируем результат теоремы на примере, который подробно будем разбирать во всех последующих пунктах. Источник приведенных в нем данных ☞ ЗДЕСЬ.
Пример. Пусть случайный процесс заключается в ежесекундном появлении на экране монитора одной буквы русского алфавита в соответствии с приведенными ниже вероятностями
| и | м | о | т | пробел | |
|---|---|---|---|---|---|
| $ P_<> $ | 0.219 | 0.104 | 0.295 | 0.148 | 0.234 |
Таким образом, случайным событием $ A_<> $ является появление какой-то из указанных букв и $$ H(A) = — \sum_
| ии | им | ио | ит | и_ | ми | мм | мо | мт | м_ | ои | ом | оо | от | о_ | ти | тм | то | тт | т_ | _и | _м | _o | _т | _ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| $ \hat P $ | 0.037 | 0.028 | 0.031 | 0.014 | 0.108 | 0.027 | 0.003 | 0.024 | 0.011 | 0.038 | 0.060 | 0.034 | 0.079 | 0.061 | 0.061 | 0.024 | 0.011 | 0.077 | 0.008 | 0.028 | 0.071 | 0.027 | 0.084 | 0.053 | 0.000 |
Имеем: $$H(AB)=- \sum_
Пока мы только лишь формально осваиваем введенный математический аппарат, оставляя обсуждение лежащего под ним здравого смысла до следующих пунктов.
Теорема 5. Для условной энтропии выполняются неравенства $$ 0 \le H_A(B) \le H(B) \ . $$
Это утверждение хорошо согласуется со смыслом энтропии как меры неопределенности: предварительное осуществление события $ A_<> $ может лишь уменьшить степень неопределенности события $ B_<> $, но никак не может ее увеличить. Здесь необходимо отметить, что частная условная энтропия $ H_
Поскольку события $ AB_<> $ и $ BA_<> $ одинаковы, то $$ H(AB)=H(A)+ H_A(B) =H(B)+H_B(A) \ . $$ Из последнего равенства можно определить и условную энтропию события $ A_<> $ при условии осуществления события $ B_<> $: $$ H_B(A)=H(A)-H(B)+H_A(B) \ . $$
Пример. Пусть события $ A_<> $ и $ B_<> $ заключаются в извлечении одного шара из ящика, содержащего $ m_<> $ черных и $ n-m $ белых шаров. Чему равны энтропии $ H(A), H(B), H_A(B), H_B(A) $?
Понятие об информации
Рассмотрим величину $ H(B) $, характеризующую степень неопределенности события $ B_<> $. Равенство этой величины нулю означает, что состояние события $ B_<> $ заранее известно; большее или меньшее значение числа $ H(B) $ отвечает большей или меньшей неопределенности события. Какое-либо состояние события $ A_<> $, предшествующее событию $ B_<> $, может ограничить количество возможных состояний для события $ B_<> $ и тем самым уменьшить степень его неопределенности. Для того чтобы состояние события $ A_<> $ могло сказаться на последующем событии $ B_<> $, необходимо, чтобы это состояние не было известно заранее; поэтому $ A_<> $ можно рассматривать как вспомогательное событие, также имеющее несколько допустимых состояний. Тот факт, что осуществление $ A_<> $ уменьшает степень неопределенности $ B_<> $, находит свое отражение в том, что условная энтропия $ H_A(B) $ события $ B_<> $ при условии выполнения события $ A_<> $ оказывается не больше первоначальной энтропии $ H(B) $ того же события. При этом, если событие $ B_<> $ не зависит от $ A_<> $, то $ H_A(B)=H(B) $; если же состояние события $ A_<> $ полностью предопределяет событие $ B_<> $, то $ H_A(B)=0 $. Таким образом, разность $$ I(A,B)=H(B)-H_A(B) $$ указывает, насколько осуществление события $ A_<> $ уменьшает неопределенность $ B_<> $, т.е. сколько нового мы узнаем о событии $ B_<> $, осуществив событие $ A_<> $. Эту разность называют количеством информации относительно события $ B_<> $, содержащимся в событии $ A_<> $.
Введенное таким образом определение можно «развернуть», определив энтропию $ H(B) $ события как информацию о событии $ B_<> $, содержащуюся в самом этом событии (поскольку осуществление события $ B_<> $ полностью определяет его исход и, следовательно, $ H_B(B)=0 $), или как наибольшую информацию относительно $ B_<> $, какую только можно иметь. Иными словами, энтропия $ H(B) $ события $ B_<> $ равна той информации, которую мы получаем при осуществлении этого события, т.е. средней информации, содержащейся в состояниях $ U_1,\dots, U_m $ события $ B_<> $. Чем больше неопределенность какого-то события, тем бóльшую информацию дает определение его состояния.
Следует также иметь в виду, что информация относительно события $ B_<> $, содержащаяся в событии $ A_<> $, по определению представляет собой среднее значение (математическое ожидание) случайной величины $ \< H(B)-H_
Информационная избыточность
Задача. Имея сообщение, записанное символами некоторого алфавита $ \
Если считать, что коммуникация каждого из символов нового алфавита «стоит» одинакового количества ресурсов (энергии, времени), то наиболее выгодный код позволит сэкономить эти ресурсы.
Пример. Пусть $ n=10, m=2 $, т.е., к примеру, исходный алфавит, состоящий из цифр $ 0,1,\dots, 9 $, мы кодируем двоичным кодом. Кодовая таблица
$$ \begin
Рассмотрим теперь вопрос о выгодности (т.е. экономности) построенного кода. Каждая цифра числового сообщения, записанного в привычной десятичной системе счисления, может принимать одно из десяти значений, т.е. может содержать информацию, равную, самое большее, $ \log_2 10 \approx 3.32 $ бит. Следовательно, сообщение, состоящее из $ N_<> $ десятичных цифр, может содержать, самое большее, $ N \log_2 10 \approx 3.32 N $ бит. Каждый разряд закодированного сообщения может принимать одно из двух значений, т.е. может содержать информацию, равную, самое большее $ \log_2 2=1 $ биту. Но при использовании рассмотренного нами двоичного кода мы затрачиваем на передачу одного символа алфавита $ 4_<> $ разряда, а на передачу сообщения из $ N_<> $ символов алфавита — $ 4\, N $ разрядов. Однако с помощью $ 4\, N $ двоичных разрядов можно было бы передать информацию, равную $ 4\, N $ бит. Разность $ 4\,N-3.32\, N=0.68\, N $ отражает величину неэкономичности нашего кода. Нетрудно также объяснить, почему предложенный код не будет наиболее экономичным: в нем значения $ 0_<> $ и $ 1_<> $ не являются равновероятными: если в кодируемом сообщении все цифры $ 0,1,\dots, 9 $ равновероятны, то в закодированном сообщении $ 0_<> $ будет встречаться в $ 25/15=5/3 $ раз чаще, чем $ 1_<> $. Между тем для того, чтобы последовательность из определенного количества символов $ 0_<> $ и $ 1_<> $ содержала наибольшую информацию, требуется, чтобы все цифры этой последовательности принимали оба значения с одинаковой вероятностью (и были взаимно независимы).
Легко понять, как можно построить более выгодный двоичный код. Разобьем наше сообщение на последовательные пары цифр и будем переводить в двоичную систему счисления не отдельно каждую цифру, к каждое двузначное десятичное число разбиения. Число двоичных разрядов кодовых блоков, требуемое для записи всех двузначных чисел $ 00,01,\dots,99 $ равно $ 7_<> $: $$ \begin
Еще выгоднее было бы разбить передаваемое число на триплеты — блоки из трех цифр. В этом случае «стоимость» кодирования понижается до $ \approx 3.33 N $ бит. Выгода от перехода к разбиению сообщения на еще более крупные блоки практически оказывается уже совсем небольшой. При переходе от триплетов к квадруплетам (блокам из четырех цифр) экономность кодирования даже уменьшается: на передачу последних требуются $ 14 $-тиразрядные двоичные блоки. Тем не менее, применяя разбиение кодируемого $ N_<> $-значного числа на еще более крупные блоки, мы можем еще более «сжать» получаемый двоичный, подойдя максимально близко к значению $ N \log_2 10 $. ♦
Эта последняя граница может быть получена и из других соображений — без использования понятия информации. Количество всевозможных $ N_<> $-буквенных слов, составленных из букв алфавита $ \ < S_1,\dots,S_n \>$, равно $ n^N $, количество всевозможных $ k_<> $-разрядных двоичных блоков равно $ 2^k $. Для однозначности кодирования необходимо, чтобы $ 2^k \ge n^N $.
Способ кодирования $ k_<> $-разрядными двоичными блоками фактически заключается в том, что мы разбиваем множество всевозможных $ k_<> $-значных чисел на две равные части и числам из одной части сопоставляем первую разрядную цифру равную $ 0_<> $, а числам из второй части — равную $ 1_<> $. Далее, каждая из половинок множества снова разбивается на две равные части, каждой из которых приписывается $ 0_<> $ или $ 1_<> $.
Теорема [Хартли]. Если в заданном множестве $ \mathbb S $, состоящем из $ \mathfrak N $ элементов:
$$ \operatorname
На первый взгляд кажется, что если число букв в исходном алфавите равно $ n_<> $, а в кодирующем алфавите равно $ m_<> $, то число $ \log_m n $ характеризует наиболее экономичный код. Однако это утверждение ошибочно. Разумеется, верно, что текст из $ N_<> $ букв $ n_<> $-буквенного алфавита может содержать информацию, самое большее равную $ N \log_2 n $ бит, но в действительности такой текст, если только он является осмысленным, никогда такой информации не содержит. Это ясно из свойств энтропии: каждая буква текста может содержать наибольшую информацию $ \log_2 n $ бит лишь в том случае, когда все буквы алфавита будут встречаться одинаково часто. Известно, однако, что частоты встречаемости букв o или е во много раз больше частот встречаемости букв ф или щ.
Частота встречаемости букв в обычном (неспециальном) тексте (без учета пробелов) [2]:
| a | б | в | г | д | е,ё | ж | з | и | й | к | л | м | н | о | п | р |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.075 | 0.017 | 0.046 | 0.016 | 0.030 | 0.087 | 0.009 | 0.018 | 0.075 | 0.012 | 0.034 | 0.042 | 0.031 | 0.065 | 0.110 | 0.028 | 0.048 |
| с | т | у | ф | х | ц | ч | ш | щ | ъ,ь | ы | э | ю | я | |||
| 0.055 | 0.065 | 0.025 | 0.002 | 0.011 | 0.005 | 0.015 | 0.007 | 0.004 | 0.017 | 0.019 | 0.003 | 0.007 | 0.022 |
Энтропия достигает своего максимума, если все символы алфавита $ \
Аналогичные результаты справедливы и для других языков. Если латинский алфавит содержит $ 26_<> $ букв и, следовательно, $ H_0 = \log_2 26 \approx 4.700 $ бит, то значения $ H_ <1>$ для основных европейских языков приведены в таблице
| английский | французский | немецкий | |
|---|---|---|---|
| $ H_ <1>$ | 4.126 | 3.986 | 4.096 |
Однако, даже с учетом частот появления букв в тексте языков, мы все равно получим значение средней удельной информации на единицу текста, превосходящую фактическое значение этой величины. В самом деле, для русского алфавита, например, информация в $ 4.460 $ бит на одну букву получилась бы, если бы каждая буква текста определялась с помощью извлечения карточки из ящика с перемешанными $ 1000 $ карточками, среди которых на $ 110 $ карточках написана буква о, на $ 87 $ карточках — буква е, и т.д., на $ 2_<> $ карточках — буква ф. Энтропия каждого такого события (извлечения карточки) $ A_1 $ примерно равна $ 4.460 $ бит; если $ [A_1,A_2,\dots,A_N] $ обозначают $ N_<> $ последовательных событий 3) , то $$ H([A_1, A_2, \dots , A_N])= \sum_<\ell=1>^N H(A_<\ell>) \approx N \cdot 4.460 \ \mbox < бит >\ . $$ Однако, появление каждой буквы текста на «естественном'' языке не является независимым событием: вероятности появления каждой буквы зависят от предыдущих букв. Так, например, в русском языке после появления гласной буквы, существенно увеличивается вероятность появления согласной; если последняя появившаяся буква ч, то следующей уже никак не может быть ы, ю, или я, а весьма вероятно появление одной из букв и, е или т. Аналогичные закономерности имеются и во всех других языках. Поэтому, если $ [A_1,A_2] $ — сложное событие, состоящее в последовательном появлении двух, то информация, содержащаяся в этом событии, равна $$ H([A_1,A_2])=H(A_1)+H_
Можно переписать последнюю формулу в матричном виде с использованием условных вероятностей. По правилу умножения вероятностей: $$ P([S_j,S_<\ell>])=P(S_j)P_
Пример. Обратимся к примеру сокращенного русского языка из букв $ S_1= $и, $ S_2= $м, $ S_3= $о, $ S_4= $т и $ S_5= $пробел, рассмотренному ☞ ЗДЕСЬ. Сделаем сначала «привязку» к только что введенным обозначениям:
$$ P_1=0.219,\ P_2=0.104,\ P_3= 0.295,\ P_4=0.148, \ P_5=0.234 \ . $$ Матрица условных вероятностей: $$ \mathfrak P=\left[P_
Продолжаем дальнейшее продвижение в намеченном направлении. Если учесть информацию о двух предыдущих буквах текста, то для средней информации на одну букву получается формула: $$ H_3=H_
Нетрудно понять как строятся величины $ H_M $ при $ M> 3 $. Также понятно, что с возрастанием $ M_<> $ величины $ H_M $ будут убывать, приближаясь к некоторому предельному значению $ H_ <\infty>$, которое и можно считать теоретическим значением средней удельной информации при передаче длинного текста.
Значения $ H_
| $ M $ | $ 0_<> $ | $ 1_<> $ | $ 2_<> $ | $ 3_<> $ |
|---|---|---|---|---|
| русский | 5.000 | 4.348 | 3.521 | 3.006 |
| английский | 4.754 | 4.029 | 3.319 | 3.099 |
Учтя также и статистические данные о частотах появления различных слов в английском языке, Шеннон сумел приблизительно оценить и значения величин $ H_5 $ и $ H_8 $: $$ H_ <5>\approx 2.1,\ H_ <8>\approx 1.9 \ . $$
Пример [обезьяна за клавиатурой]. Известна теорема о бесконечных обезьянах: абстрактная обезьяна, ударяя случайным образом по клавишам печатной машинки 7) в течение неограниченно долгого времени, рано или поздно напечатает любой наперёд заданный текст (например «Войны и мира»). В указанной ссылке приводятся оценки времени наступления этого события. Следующие примеры 8) показывают, что может произойти, если обезьяна будет бить по клавиатуре специально сконструированной машинки, в которой клавиши соответствуют биграммам, триграммам и т.п. русского языка и при этом размеры клавиш пропорциональны частотам встречаемости в русском языке (а обезьяна будет чаще ударять по большим клавишам).
Приближения нулевого порядка (символы независимы и равновероятны):
ФЮНАЩРЪФЬНШЦЖЫКАПМЪНИФПЩМНЖЮЧГПМ ЮЮВСТШЖЕЩЭЮКЯПЛЧНЦШФОМЕЦЕЭДФБКТТР МЮЕТ
Приближение первого порядка (символы независимы, но с частотами, свойственными русскому языку):
ИВЯЫДТАОАДПИ САНЫАЦУЯСДУДЯЪЛЛЯ Л ПРЕЬЕ БАЕОВД ХНЕ АОЛЕТЛС И
Приближение второго порядка (частотность диграмм такая же как в русском языке):
ОТЕ ДОСТОРО ННЕДИЯРИТРКИЯ ПРНОПРОСЕБЫ НРЕТ ОСКАЛАСИВИ ОМ Р ВШЕРГУ П
Приближение третьего порядка (частотности триграмм такие же как в русском языке):
С ВОЗДРУНИТЕЛЫБКОТОРОЧЕНЯЛ МЕСЛОСТОЧЕМ МИ ДО
Вместо того, чтобы продолжить процесс приближения с помощью тетраграмм, пентаграмм и т.д., легче и лучше сразу перейти к словарным единицам. Приближение первого порядка на уровне слов 9) : cлова выбираются независимо, но с соответствующими им частотами.
СВОБОДНОЙ ДУШЕ ПРОТЯНУЛ КАК ГОВОРИТ ВСПОМНИТЬ МИЛОСТЬ КОМНАТАМ РАССКАЗА ЖЕНЩИНЫ МНЕ ТУДА ПОНЮХАВШЕГО КОНЦУ ИСКУСНО КАЖДОМУ РЯСАХ К ДРУГ ПЕРЕРЕЗАЛО ВИДНО ВСЕМ НАЧИНАЕТЕ НАД ДВУХ ЭТО СВЕТА ХОДУНОМ ЗЕЛЕНАЯ МУХА ЗВУК ОН БЫ ШЕЮ УТЕР БЕЗДАРНЫХ
Приближение второго порядка на уровне слов. Переходные вероятности от слова к слову соответствуют русскому языку, но «более дальние» зависимости не учитываются:
ОБЩЕСТВО ИМЕЛО ВЫРАЖЕНИЕ МГНОВЕННОГО ОРУДИЯ К ДОСТИЖЕНИЮ ДОЛЖНОСТЕЙ ОДИН В РАСЧЕТЫ НА БЕЗНРАВСТВЕННОСТИ В ПОЭЗИИ РЕЗВИТЬСЯ ВСЕ ГРЫЗЕТ СВОИ БРАЗДЫ ПРАВЛЕНИЯ НАЧАЛА ЕГО ПОШЛОЙ
С каждым проделанным шагом сходство с обычным текстом заметно возрастает. До текста «Войны и мира» осталось совсем немного… ♦
Уменьшение информационной нагрузки на один символ алфавита вследствие неравновероятности, а также взаимозависимости появления, символов называют избыточностью языка 10) . Информационная избыточность рассчитывается по формуле $$ R_<>= \frac
Код Шеннона — Фано
Для решения задачи наиболее экономичного кодирования приходится расширять алфавит. Поясню эту фразу. Если считать, что «исходный» алфавит состоит из символов $ S_1,\dots,S_
чаще встречаемость — короче кодовая последовательность.
Реализация последнего принципа возможна различными способами. Исторически первым является кодирование по методу Шеннона-Фано. Чтобы не вводить новых обозначений, будем считать что алфавит состоит из «букв» $ S_1,\dots,S_
Пример. Рассмотрим пример с кодированием $ 10_<> $ букв русского алфавита с частотами, полученными на основании искусственного текста, созданного ☞ ЗДЕСЬ.
| е | и | а | в | д | к | з | б | г | ж | всего | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| количество | 236 | 231 | 195 | 111 | 94 | 94 | 46 | 42 | 40 | 30 | 1119 |
| вероятность | 0.211 | 0.206 | 0.174 | 0.099 | 0.084 | 0.084 | 0.041 | 0.038 | 0.036 | 0.027 |
Множество этих букв разобьем на два подмножества, (примерно) одинаковые по вероятности. Например, суммарная вероятность букв е, и, д равна $ 0.51 $. Так что два образуемых подмножества: $ \ < \mbox< е, >\mbox < и, >\mbox < д >\> $ и $ \ < \mbox< а, >\mbox < б, >\mbox < г, >\mbox < в, >\mbox < ж, >\mbox < к, >\mbox < з >\> $. Каждое из этих подмножеств снова разобьем на два подмножества (примерно) одинаковые по вероятности. Первое подмножество делится плохо, но что поделать — делим как получится! Продолжаем процесс деления пока не дойдем в таких разбиениях до отдельных букв. Последовательность построения схемы разбиения приведена на рисунке.
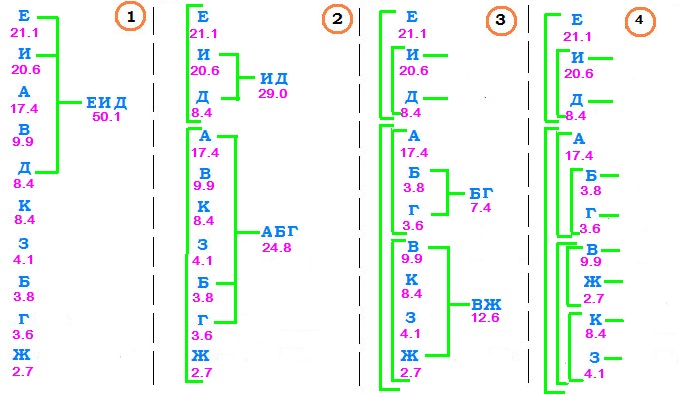
Оформляем эту схему в виде дерева и, идя от корня к листьям, нумеруем ветви после каждого узла (точки ветвления): верхней даем номер $ 0_<> $, а нижней — номер $ 1_<> $.
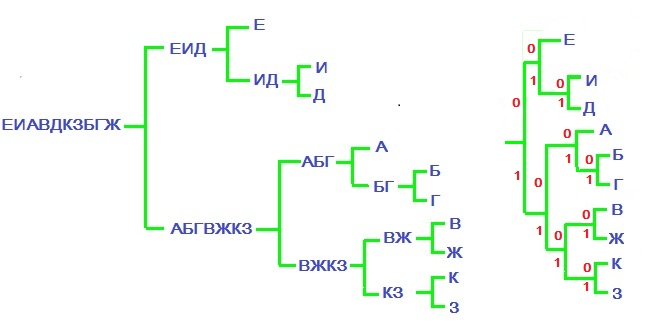
Результатом оказывается кодовая таблица
| е | и | д | а | б | г | в | ж | к | з |
|---|---|---|---|---|---|---|---|---|---|
| 00 | 010 | 011 | 100 | 1010 | 1011 | 1100 | 1101 | 1110 | 1111 |
Стоимость кодирования текста по такой таблице равна $$ 236\cdot 2+231\cdot 3+94 \cdot 3+195 \cdot 3+42 \cdot 4+40 \cdot 4+111 \cdot 4+30 \cdot 4+94 \cdot 4+46 \cdot 4=3423 \mbox < бит, >$$ то есть, в среднем, $ 3.11_<> $ бит на букву. Это неплохое достижение, но оно всё-таки хуже полученного использованием кода Хаффмана, также основанного на частотном анализе букв алфавита. ♦
А теперь перейдем к фундаментальному результату теории кодирования, связав код Шеннона-Фано с понятием энтропии.
Теорема [Шеннон]. Сообщение из большого количества $ N_<> $ букв алфавита $ \
$$ \begin
Доказательство (совершенно нестрогое: очень сильная «выжимка» из рассуждений, приведенных в [2]; которые, в свою очередь, тоже не абсолютно строги). Пусть источник сообщений случайным образом генерирует символы из алфавита $ \
Будем для простоты считать, что это — вероятность любого сообщения из подмножества $ \mathbb S_<> $, т.е. количество элементов во множестве $ \mathbb S_<> $ примерно совпадает с $ 1/Q $: $$ \mathfrak N = \operatorname
Теперь обсудим полученный результат. Итак, «на входе» имеем документ — самый произвольный, содержащий возможно осмысленный, но не обязательно нам понятный текст (он записан на неизвестном языке, содержит специфические символы из неизвестной нам научной отрасли и т.п.). Наша цель — закодировать его бинарным кодом, с тем, чтобы иметь возможность передать по каналу связи. Первое, что мы делаем — строим алфавит. Слово «алфавит» понимается в том смысле, что упомянут в начале пункта. Пытаемся, по-возможности, определять часто повторяющиеся блоки — их будем включать в состав алфавита целиком, как отдельные «буквы». Стоп. Стоп! — Что же получается: для каждого документа — делать свой отдельный алфавит?! — Вообще говоря, да 12) . Другое дело, что если этот документ не единствен, а предполагается коммуникация целой серии документов, и эти документы написаны на одном языке, и в них содержится разве лишь строго ограниченное количество специальных символов,… — и вот при всех при этих обстоятельствах имеет смысл предварительным анализом составить алфавит общий для всех документов. После того как алфавит создан, вычисляем частоты вхождений составляющих его букв в исходный документ. Кодируем по методу Шеннона-Фано. Кодовую таблицу храним в надежном файле и передаем адресату (на бумажном (электронном) носителе при личной встрече, курьером, по электронной почте и т.п.). И что у нас имеется для оценки стоимости кодирования нашего документа? — Оценка снизу для количества бит на букву: $ H_<> $. Что такое $ H_<> $? — Энтропия случайного события, состоящего в появлении в тексте букв алфавита при известных их вероятностях (т.е. как если бы случайный источник генерировал буквы алфавита независимо друг от друга, но с частотами, примерно соответствующими их вероятностям). Хорошо подобрали алфавит, каждый документ — достаточно длинный, этих документов много — тогда, в среднем, результаты нашего кодирования не должны слишком уж сильно превосходить этой величины. Сколько это: «слишком сильно»? — Решает заказчик. Если ему хочется улучшить результат — придется увеличивать алфавит. Но тогда решение одной проблемы приведет к появлению другой…
Пример. Обратимся к рассмотренному ☞ ЗДЕСЬ примеру сокращенного русского языка
| и | м | о | т | пробел | |
|---|---|---|---|---|---|
| $ P_<> $ | 0.219 | 0.104 | 0.295 | 0.148 | 0.234 |
Для алфавита, состоящего из этих букв, с указанными в таблице вероятностями величина энтропии $ H \approx 2.237 $. Следовательно, кодирование приведенного ЗДЕСЬ текста из $ 1050 $ букв по теореме Шеннона оценивается в $ 2349 $ двоичных разряда. Код Шеннона-Фано для этого алфавита имеет вид
| и | м | о | т | пробел |
|---|---|---|---|---|
| 11 | 010 | 10 | 011 | 00 |
и точная стоимость кодирования — $ 2364 $ разряда.
Если же перейти к алфавиту, составленному из биграмм
| ии | им | ио | ит | и_ | ми | мм | мо | мт | м_ | ои | ом | оо | от | о_ | ти | тм | то | тт | т_ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| $ \hat P $ | 0.037 | 0.028 | 0.031 | 0.014 | 0.108 | 0.027 | 0.003 | 0.024 | 0.011 | 0.038 | 0.060 | 0.034 | 0.079 | 0.061 | 0.061 | 0.024 | 0.011 | 0.077 | 0.008 | 0.028 |
| _и | _м | _o | _т | __ | ||||||||||||||||
| $ \hat P $ | 0.071 | 0.027 | 0.084 | 0.053 | 0.000 |
то код Хаффмана этого алфавита (уже из $ 25_<> $ «букв») имеет вид
| ии | им | ио | ит | и_ | ми | мм | мо | мт | м_ | ои | ом | оо | от | о_ | ти | тм | то | тт | т_ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 11000 | 10001 | 10100 | 010001 | 000 | 01101 | 0010100 | 00100 | 010000 | 11001 | 0101 | 10101 | 1110 | 0111 | 1001 | 01001 | 001011 | 1101 | 0010101 | 10000 |
| _и | _м | _o | _т | ||||||||||||||||
| 1011 | 01100 | 1111 | 0011 |
и стоимость кодирования текста, разбитого на $ 525 $ биграмм по схеме
Ои | то | ми | и_ | о_ | им | и_ | оо | ои | тм | и_ | о_ | о_ | о_ | оо | ии | им | то | ми | им | от | ои | м_ | …
будет равна $ 2193 $ бит. Величина энтропии $ H \approx 2.036 $ бит и теорема Шеннона дает оценку в $ 2138 $ двоичных разрядов. ♦
Пропускная способность канала связи
Рассуждения предыдущего пункта относились к случаю, когда процесс коммуникации происходит без искажений. Обратимся теперь от теории к реальности: помехи всегда будут.
Предполагаем, что по каналу связи передается последовательность бит (т.е. $ 0_<> $ или $ 1_<> $), задающая символы (или буквы некоторого алфавита) $ S_<1>,\dots, S_n $. Предполагается, что символ $ S_j $ представлен набором из $ t_
Пример. Шеннон рассматривает пример из телеграфии, где имеется всего $ 4_<> $ «символа алфавита»:
Если заменить слова «замыкание линии» на $ 1_<> $, а «размыкание линии» — на $ 0_<> $, то получим двоичную кодировку алфавита
$ \mathfrak C ( $ точка $ )=10 $, $ \mathfrak C ( $ тире $ )=1110 $, $ \mathfrak C ( $ пробел между буквами $ )=000 $,
$ \mathfrak C ( $ пробел между словами $ )=000000 $.
Таким образом, используя в качестве вспомогательного алфавита для передачи латинских букв азбуку Морзе, получаем кодировку сообщения:
Дополнительно вводятся ограничения на допустимые к передаче последовательности — например, запрет двух пробелов подряд между словами. ♦
Пропускная способность канала связи без помех задается формулой $$ C=\lim_
Эта формула определяет линейное разностное уравнение порядка $$ \tau= \max_
Пример. Для рассмотренного выше «телеграфного» примера имеем разностное уравнение в виде
$$ N(t)=N(t-2)+N(t-4)+N(t-5)+N(t-7)+N(t-8)+N(t-10) \ . $$ Это уравнение имеет порядок $ 10_<> $, его характеристический полином $$ \lambda^<10>=\lambda^<8>+\lambda^<6>+\lambda^<5>+\lambda^<3>+\lambda^<2>+1 $$ имеет максимальный по модулю корень $ \lambda_ <\ast>\approx 1.453 $. Таким образом, пропускная способность канала равна $ \approx 0.539 $. ♦
Пусть символы алфавита имеют вероятности появления в любом месте сообщения, заданные таблицей $$ \begin
При наличии помех в линии связи дело будет обстоять иначе. В этом случае только наличие избыточности в передаваемой последовательности сигналов может помочь нам точно восстановить переданное сообщение по принятым данным. Ясно, что использование кода, приводящего к наименьшей избыточности закодированного сообщения здесь уже нецелесообразно и скорость передачи сообщения должна быть уменьшена. Насколько уменьшена?
Для ответа на этот вопрос придется предварительно описать линию связи с помехами. Пусть линия связи использует $ m_<> $ различных элементраных сигналов $ A_1,A_2,\dots,A_m $, но из-за наличия помех переданный сигнал $ A_j $ может оказаться по выходе из канала каким-то другим сигналом $ A_k $; пусть известна вероятность этого события $ \hat P_
Предположим, для простоты, что по линии связи передается два элементарных сигнала — $ A_1=0 $ и $ A_<2>=1 $ (и на выходе канала связи других сигналов быть не может). Предположим, что вероятность безошибочного приема любого из передаваемых сигналов равна $ 1-p_<> $, а вероятность ошибки равна $ p_<> $. Можно составить матрицу переходных вероятностей: $$ \begin

Статья не закончена!
Источники
[1]. Шеннон К. Математическая теория связи. (Shannon C.E. A Mathematical Theory of Communication. Bell System Technical Journal. — 1948. — Т. 27. — С. 379-423, 623–656.)
[2]. Яглом А.М., Яглом И.М. Вероятность и информация. М. Наука. 1973.