Яндекс теперь будет знать всех по именам.
Итак, как известно, Яндекс выпустил свой новый браузер. Как многие и ожидали, этот браузер собирает статистическую информацию об использовании пользователем Интернета.
Как я выяснил, теперь эта статистическая информация не такая уж и «анонимная», как было заявлено. Но об этом чуть позже. Начнем с того, что же по факту Яндекс.Браузер отсылает себе.
Сам я пользуюсь Убунтой, но по такому случаю установил себе Windows 7 на VirtualBox, туда впихнул Яндекс.Браузер, а также программу CharlesProxy для просмотра трафика.
Итак, заходим с браузера на http://vk.com/ и видим, что происходит.

Посылаются запросы на следующие хосты:
Прошу обратить внимание: отправляются не только урлы, но заголовки Title страниц.
Спустя буквально минуту простоя (т.е. я ничего нигде не нажимал) — начинают делаться запросы, каждую секунду новый.

Запросы идут в больших количествах на адреса, в которых присутствует ydx-malware-shavar, видимо что-то с антивирусной проверкой, но ведь я только что включил компутер и никуда кроме родного вконтактика не заходил! Что-то тут неладное.
Ну а теперь собсно перейдем к названию топика. Как вы уже могли догадаться, теперь и приватные данные уходят к Яндексу. Яркий пример. Я залогинился в контакте, и вот что ушло в Яндекс:

Ушли имя и фамилия моей страницы! Иными словами, т.к. заголовки посещаемых страниц отправляются в Яндекс, они теперь знают, как меня зовут. (аккаунт на скрине «левый», если что).
Да, имя и фамилию из «ВКонтакте» можно было узнать и просто по URL часто посещаемой страницы, так что и всякие там счетчки типа LiveInternet’a тоже знают всех поимённо. НО! Ведь даже если ваши имя и фамилия указаны не настоящие, все равно отправка Title — это откровенно говоря наглость со стороны Яндекса. В тайтле может содержаться часть текста ваших электронных писем, да и вообще любая приватная информация.
Я не помню, простые счетчики на сайтах отправляют Title посещаемых страниц или нет?
В связи с этим, есть сильные основания полагать, что в огромном количестве зашифрованных переменных, отправляемых в Яндекс (видно на скринах), есть еще куча приватной информации.
Веб-серфинг под надзором. Какие данные собирают о нас разработчики браузеров

Когда речь идет о веб-серфинге, следует различать два принципиально разных типа сбора данных: тот, что выполняет сам браузер, и тот, что производят скрипты на сайтах. О втором аспекте ты можешь почитать в статье «Тотальная слежка в интернете — как за тобой следят и как положить этому конец», а здесь мы сосредоточимся на первом.
Определиться с кругом основных подозреваемых нам помогла статистика OpenStat. Мы отобрали самые популярные в России браузеры, выделив из них версии для настольных компьютеров с Windows. Самыми распространенными оказались Google Chrome (его доля составляет почти половину), «Яндекс.Браузер», назойливо устанавливающийся за компанию с другими программами, Mozilla Firefox и Opera.
В список OpenStat входит и браузер Apple Safari, но его версия для Windows перестала обновляться в 2012 году и почти не используется. Предустановленный же в Windows 10 браузер Edge едва набрал полтора процента поклонников, но именно от него мы больше всего ожидали проявлений «шпионской активности». От Edge и его старшего брата Internet Explorer, популярность которого всегда оказывается завышенной благодаря умению разных программ идентифицировать себя как IE.
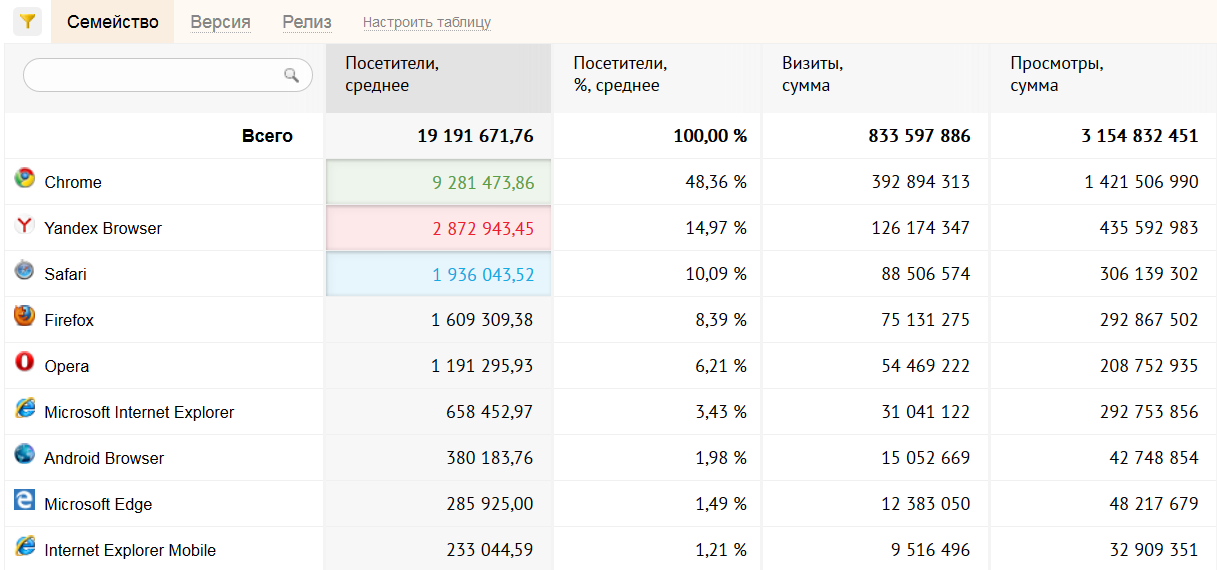
Рейтинг популярности браузеров
Другие статьи в выпуске: 
Xakep #217. Сценарий для взлома
Оценивали «шпионское» поведение браузеров в несколько этапов. Сначала мы скачивали последние версии дистрибутивов с официальных сайтов, устанавливали их в чистых ОС и запускали с настройками по умолчанию. Затем меняли начальную страницу на пустую и повторяли эксперимент. На финальном этапе устраивали час сидения в засаде, во время которого браузер просто был открыт с пустой страничкой (about:blank) и не должен был выполнять никаких сетевых запросов, кроме проверок доступности собственных обновлений.
Все тесты проводились в виртуальных машинах. Нам пришлось использовать как Windows 10, так и старую Windows XP для того, чтобы отсеять весь фоновый трафик. Как ты можешь помнить из статьи, где мы подобным образом исследовали Windows 10, эта ОС сама очень пристально следит за пользователем и отсылает на серверы Microsoft все данные, которые технически может собрать. В этом потоке трафика активность браузера просто теряется, потому что Edge (и, как выяснилось, не только он) умеет отсылать часть запросов от имени системных процессов, используя их в качестве посредников. Поэтому простые средства (например, установка веб-прокси и фильтрация трафика по именам процессов) не гарантировали возможность отловить весь интересующий нас трафик.
Нам пришлось подстраховаться и применить сразу несколько инструментов для отслеживания сетевой активности браузеров. Диспетчер TCPView показывал все сетевые подключения в реальном времени. С его помощью было удобно определять, какие именно действия вызывают появление новых соединений и какие IP-адреса используются браузером чаще всего.
Львиная доля трафика отправляется браузерами в зашифрованном виде. Поэтому при помощи MakeCert мы сгенерировали и установили в систему левый сертификат безопасности, благодаря которому расшифровали весь перехваченный HTTPS-трафик.
В отдельных случаях потребовалось использовать утилиту AppContainer Loopback Exemption, чтобы обойти встроенную в Windows 10 технологию изоляции приложений и гарантированно перехватывать трафик средствами Fiddler. В первую очередь это было необходимо сделать для Edge и Internet Explorer.
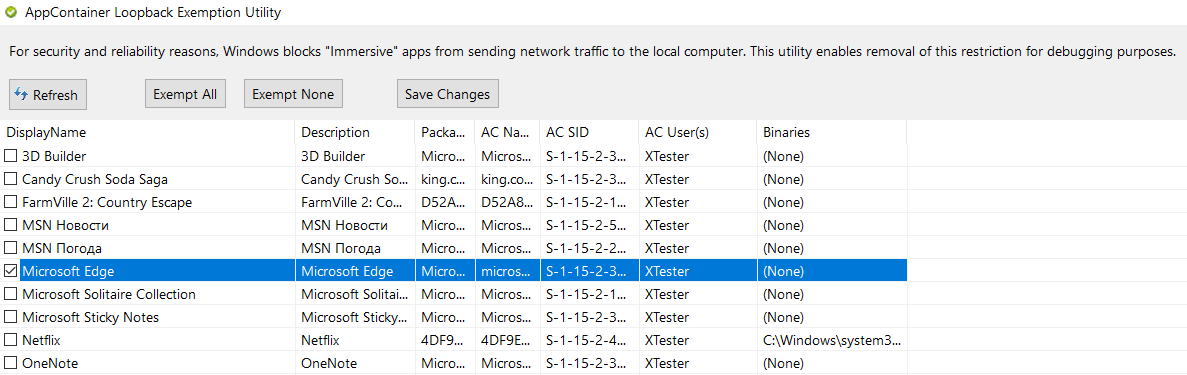
Перенаправляем трафик Edge на локальный прокси в обход защиты Windows
Мы также использовали сниффер Wireshark — для детального анализа логов и поиска закономерностей. Это мощнейший инструмент, который, помимо всего прочего, умеет собирать отдельные пакеты в потоки. Поэтому, найдя один подозрительный пакет, мы легко восстанавливали весь процесс обмена браузера с выбранным удаленным узлом.
Перечисленные программы уже стали стандартом де-факто для выполнения тестов. Однако работу программ ограничивает операционная система. Браузеры Internet Explorer и Edge так тесно интегрированы в Windows 10, что могут использовать ее компоненты для отправки данных обходными путями. Поэтому для гарантии того, что ни один пакет не ушел незамеченным, мы дополнительно использовали аппаратный сниффер.

Промежуточный роутер как сниффер
Им стал портативный роутер TP-Link MR3040 v. 2.5, который мы перепрошили последней версией OpenWrt и подключили «в разрыв», выбрав режим WISP. Весь трафик от тестовых систем шел через него. Роутер показывал все сетевые соединения в реальном времени и вел подробный лог.
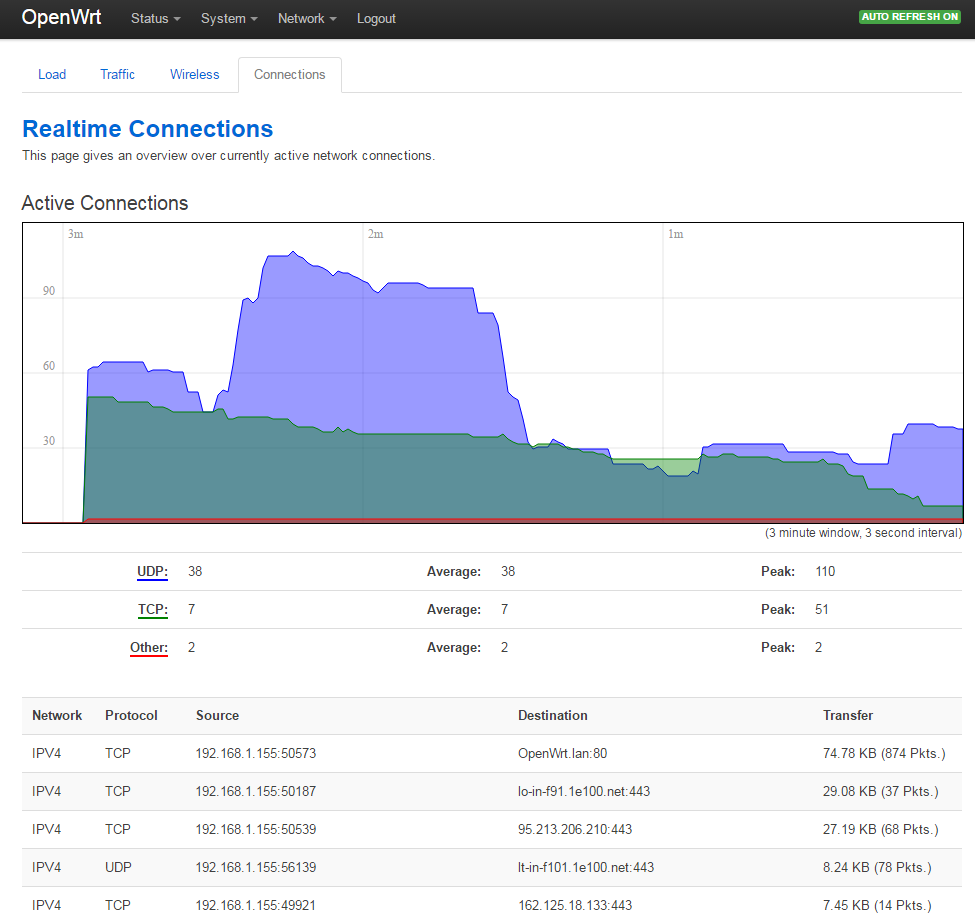
Все соединения в реальном времени (фрагмент списка)
Узаконенная слежка
Сама мысль о том, что действия пользователя за компьютером становятся известными кому-то еще, для многих стала привычной. Отчасти люди так спокойно к этому относятся, потому что не понимают объем и характер отправляемых данных об их активности. Справедливо и обратное утверждение: фанатично настроенные правозащитники готовы увидеть нарушение тайны частной жизни в любой отправке лога с чисто техническими сведениями. Как обычно, истина где-то посередине, и мы постарались приблизиться к ней настолько, насколько это возможно.
Большинство опрошенных нами пользователей считают, что все ограничивается некоей абстракцией — «анонимной статистикой, собираемой в целях улучшения качества продукта». Именно так и указано в формальном предупреждении, которое браузеры (да и другие программы) выводят на экран при установке. Однако формулировки в них используются довольно витиеватые, а длинный перечень часто заканчивается словами «. и другие сведения», что полностью развязывает руки юристам компании-разработчика.
Google знает обо всех контактах, адресах своих пользователей и их состоянии здоровья. Microsoft — еще и почерк идентифицирует по «образцам рукописного ввода». Бесплатные антивирусы (да и многие платные тоже) вообще могут законно отправить своим разработчикам любой файл в качестве подозрительного. Браузеры на этом фоне выглядят не шпионами, а относительно безобидными вуайеристами. Однако и от их подглядываний могут быть ощутимые последствия. Посмотрим, что и куда они отправляют.
Google Chrome
При первом запуске браузер Chrome 56.0 устанавливает девять подключений к серверам Google, расположенным в четырех подсетях.
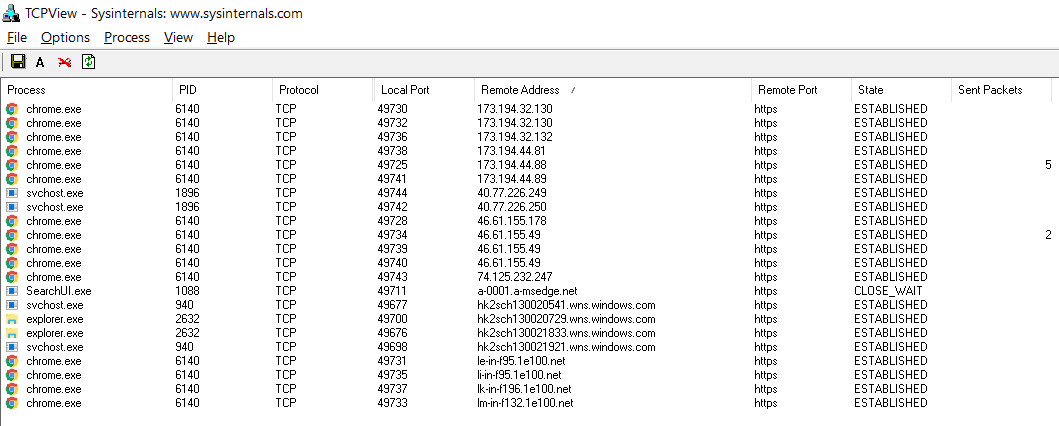
Подключения Chrome при запуске браузера
Одна из подсетей находится в России и обслуживается провайдером «Ростелеком».

Chrome всегда соединяется с этими IP-адресами
В подсеть 173.194.44.0/24 браузер отправляет сведения о своей версии, версии ОС и недавней сетевой активности пользователя. Если ее не было (первый запуск Google Chrome), то в логе появляется запись «No recent network activity».
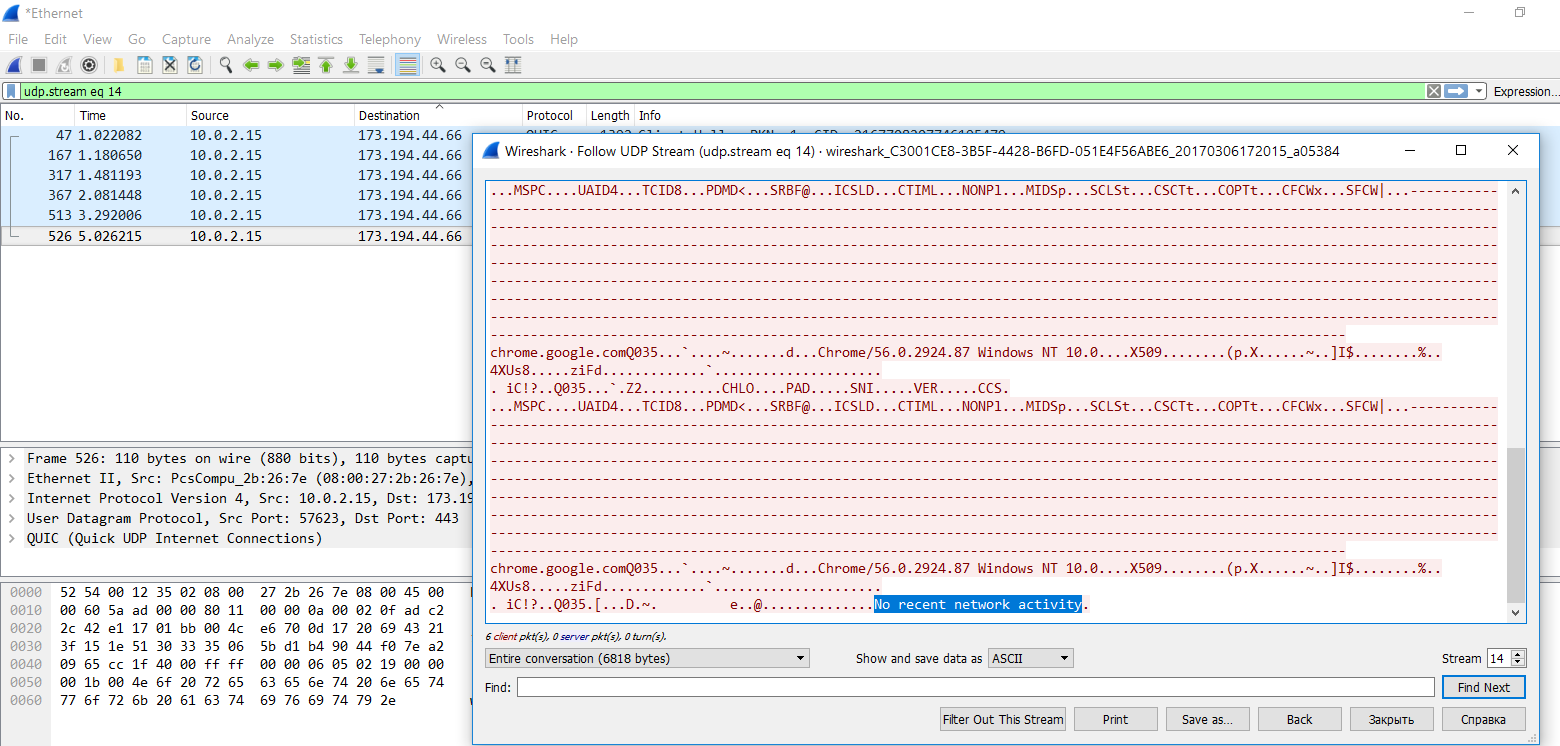
Chrome отправляет лог своей активности
В подсеть 46.61.155.0/24 отправляется запрос сертификата для проверки подлинности сайта Google.com и десятков его зеркал (включая сайты сбора статистики *.gstatic.com, google-analytics.com и другие). По ходу дальнейшей работы браузера с ними периодически устанавливаются отдельные соединения.
Если ты авторизовался в Google через браузер, то дополнительный трафик пойдет в подсеть 74.125.232.0/24 и на серверы с адресами вида http://clients#.google.com , где # — порядковый номер пула. Аналогичные соединения Chrome устанавливает и с подсетью 46.61.155.0/24 — вероятно, чтобы распределить нагрузку.
При открытии новой вкладки Chrome всегда устанавливал соединения с серверами из тех же самых подсетей.
Подключения Chrome при создании новой вкладки
При этом браузер генерирует уникальный идентификатор вида X-Client-Data: CJC2yPGIprbJAQjBtskBCK2KygEIwcdKAQj6nMoBCKmdygE= , а сайт google.ru дополнительно использует куки с идентификатором NID= . Все открытые в одном браузере вкладки получают общий идентификатор X-Client-Data .
Время от времени Chrome устанавливал подключение к серверу storage.mds.yandex.net , однако в нашем тесте, кроме пустых пакетов с заголовком connection keep alive , на него ничего не отправлялось. Остальной трафик, не связанный с действиями пользователя в Chrome, был обусловлен работой антифишинговой системы Google SafeBrowsing и проверкой доступности обновлений.
Yandex Browser
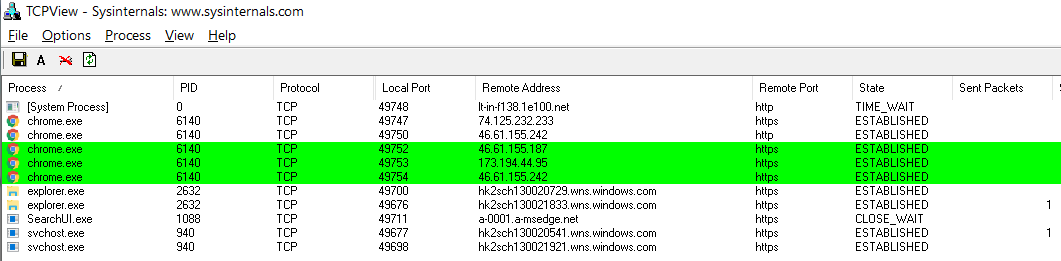
«Яндекс.Браузер» 17.3 с самого начала ведет себя более активно. При первом же старте он устанавливает десятки подключений.
«Яндекс.Браузер» и сорок подключений
Интересно, что многие из них ведут не на сайты «Яндекса», а на серверы других компаний. Mail.ru, «ВКонтакте» и даже Google. Видимо, так происходит из-за разных партнерских соглашений, в рамках которых «Яндекс.Браузер» обеспечивает альтернативные варианты поиска и рекламирует сторонние ресурсы на панели быстрого доступа в каждой новой вкладке.

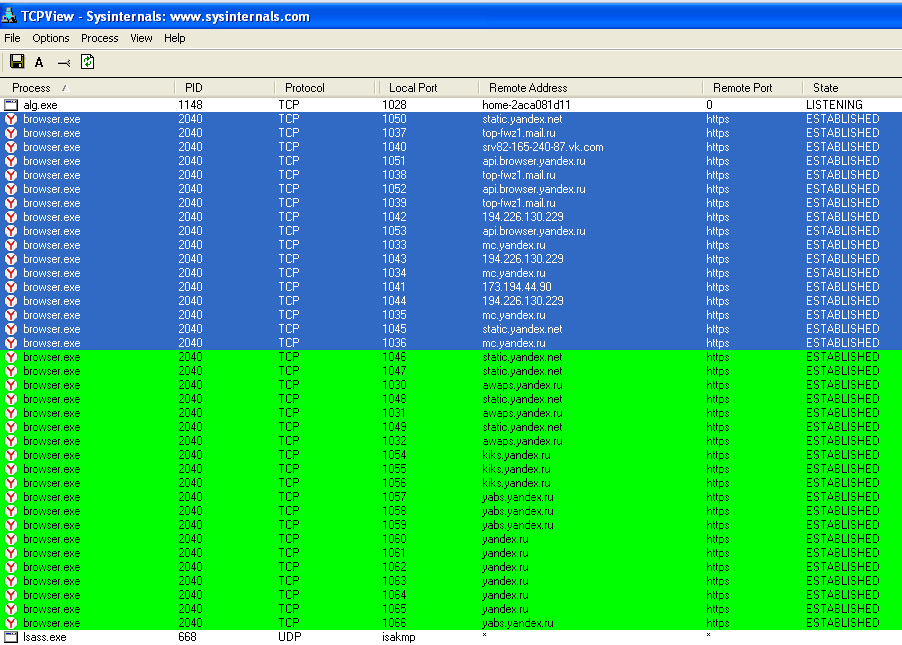
«Яндекс.Браузер» коннектится в десяток подсетей уже при старте
Обрати внимание, что часть трафика идет от имени системного процесса с нулевым PID. Адреса удаленных узлов, с которыми этот процесс устанавливает соединение, совпадают с теми, к которым одновременно подключается «Яндекс.Браузер».
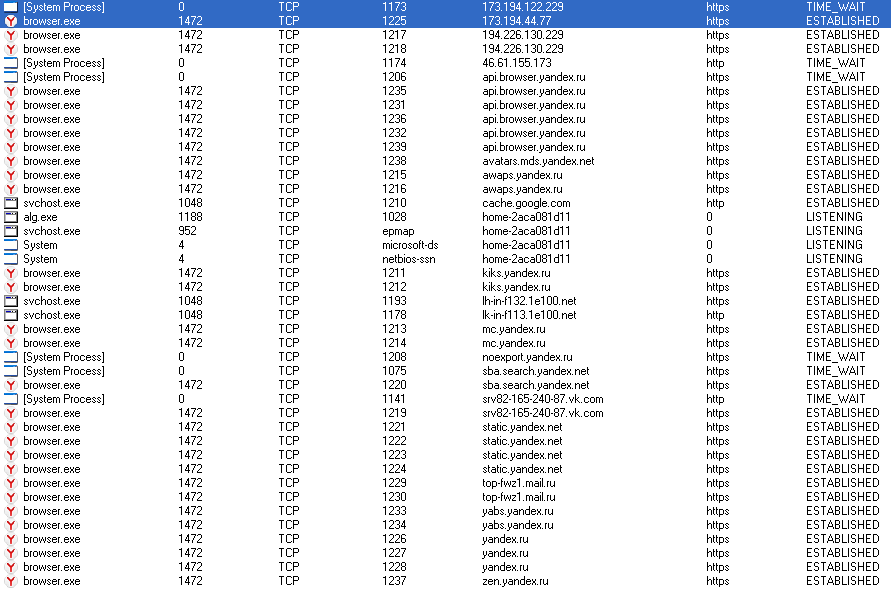
Подключения «Яндекс.Браузера» в TCPView
Самые подробные сведения «Яндекс.Браузер» отправляет на api.browser.yandex.ru . В них описана конфигурация компьютера, браузера и всех его компонентов, включая состояние менеджера паролей и количество сохраненных закладок. Отдельными строками указывался результат обнаружения других браузеров и их статус (какой запущен параллельно и какой выбран по умолчанию). Общий объем этих данных в нашем случае составил 86 Кбайт в простом текстовом формате. Это при том, что браузер был только что установлен и не содержал никаких следов пользовательской активности. Наша видеокарта в этом логе была указана как VirtualBox Graphics Adapter — теоретически это позволяет «Яндекс.Браузеру» легко определять, что он запущен в виртуальной среде.
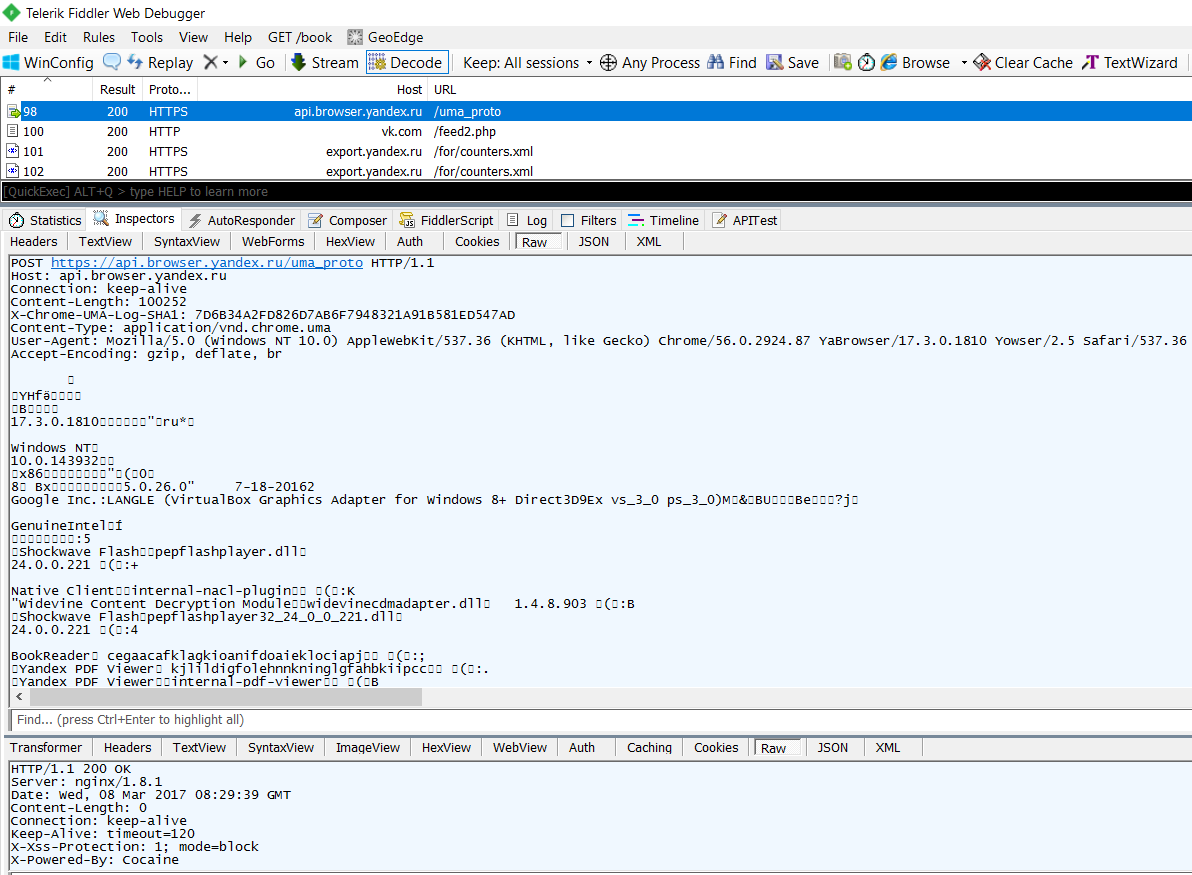
Подробная статистика «Яндекс.Браузера» (фрагмент списка)
В перехваченном трафике встречаются занятные строки вроде morda-logo или X-Powered by: Cocaine — разработчикам не откажешь в чувстве юмора. Помимо версии ОС и прочих технических сведений, «Яндекс.Браузер» определяет физическое местоположение устройства, на котором он запущен. Причем делает он это неявно — по HTTPS и через процесс explorer. Долгота и широта вычисляются с помощью сервиса геолокации Wi2Geo. Помимо самих координат, через сервер wi2geo.mobile.yandex.net всегда вычисляется и погрешность их определения. Естественно, мы подменили реальный адрес, но будет забавно, если кто-то попытается отыскать редакционную яхту в Аравийском море.
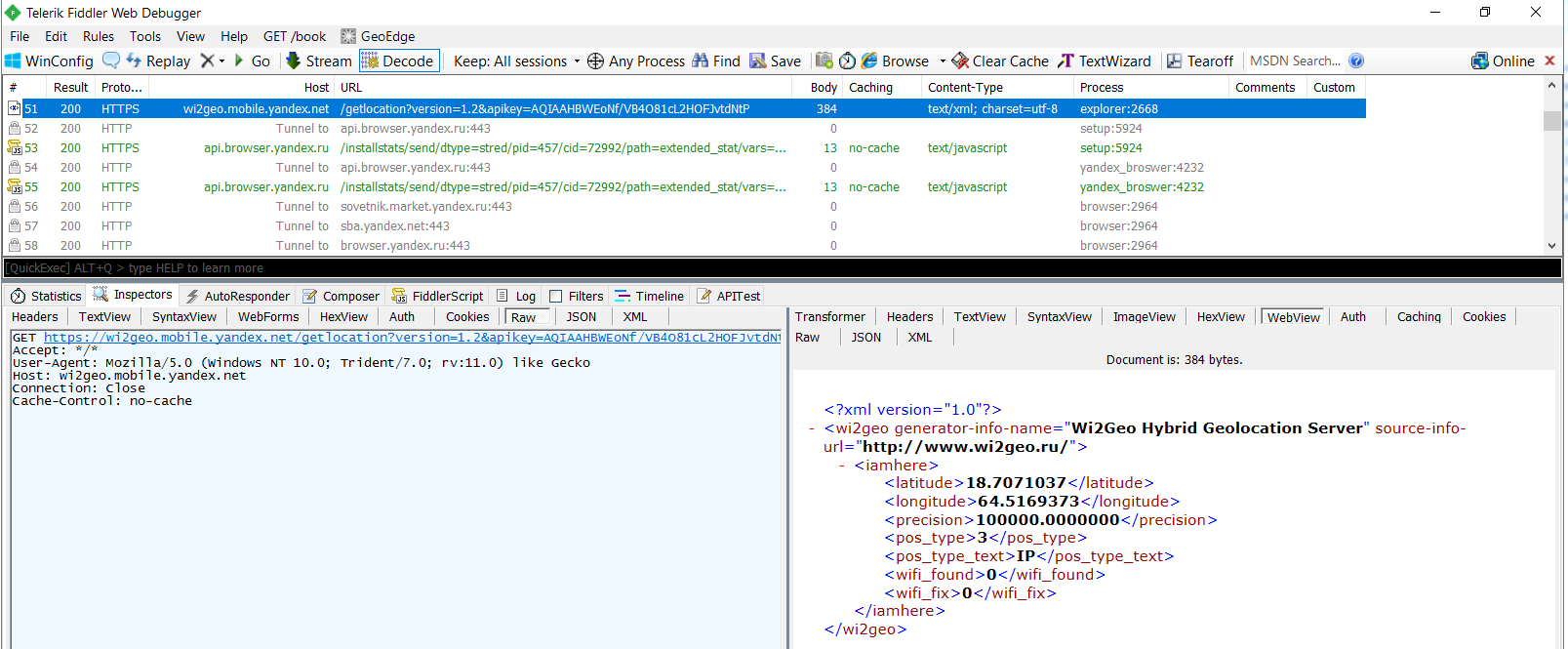
Геолокация по IP в «Яндекс.Браузере»
В тестах мы использовали Microsoft Edge 38.14, предустановленный в Windows 10 build 1607. Этот браузер интересен тем, что активен почти всегда. Даже если ты его не запускаешь, он появляется в памяти и устанавливает соединения с серверами Microsoft. В фоне преимущественно работает MSN-бот, а при запуске Edge на мгновение становятся видны соединения с семью основными сетями Microsoft.
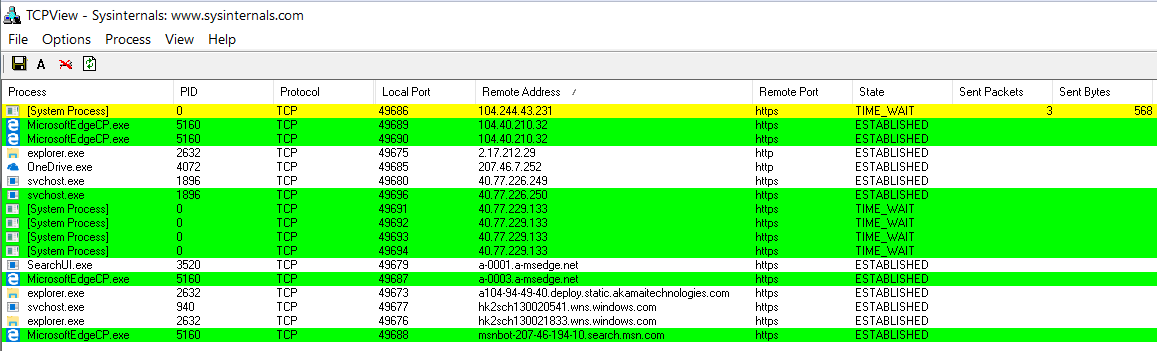
Подключения Edge при старте
Это сети 40.74.0.0–40.125.127.255, 68.232.32.0–68.232.47.255, 93.184.220.0–93.184.223.255, 104.40.0.0–104.47.255.255, 104.244.40.0–104.244.47.255, 111.221.29.0/24 и 207.46.0.0/16. Их номерная емкость просто огромна. Судя по балансу входящего и исходящего трафика, служат они не только для доставки контента, но и для масштабного сбора данных.

Соединение Edge с сетями Microsoft и партнеров
Как ни странно, при работе Edge не было замечено явной подозрительной активности браузера. Максимум, что косвенно идентифицировало пользователя, — это скупые строки телеметрии, User-Agent и куки.
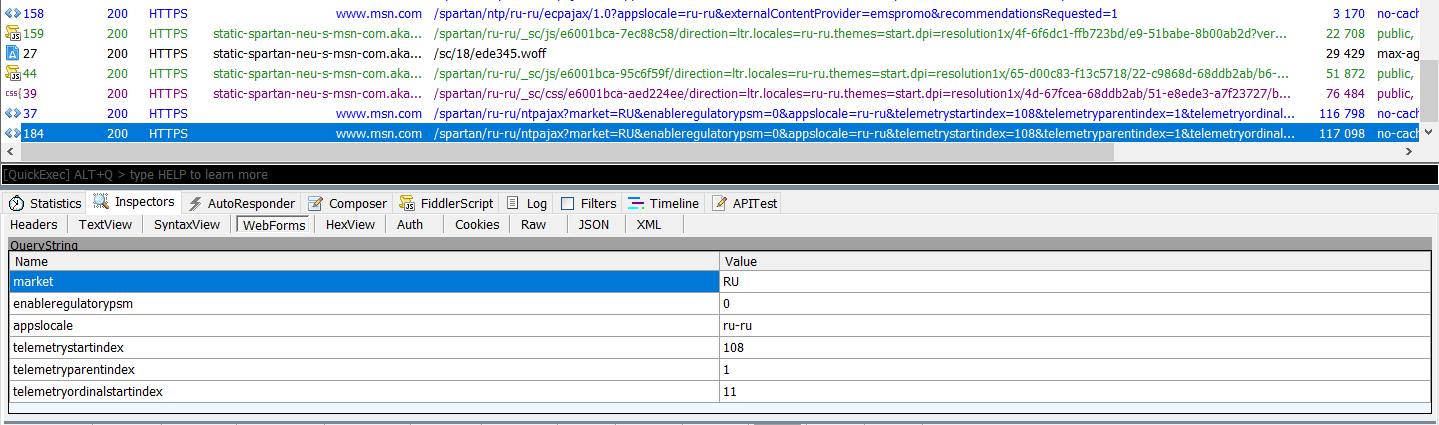
Простейшая телеметрия в Edge
При настройке запуска Edge с чистой страницы трафик вообще был минимальным. Единственное, что слегка насторожило, — строка, содержащая записи DefaultLocation= и MUID= . Значения, отправляемые в ней на сервер msn.com , закодированы.
По результатам прошлых исследований у нас сложилось стойкое ощущение, что скромное поведение Edge лишь иллюзия. Он часть Windows 10, а у Microsoft в этой ОС (а теперь и в других тоже) реализовано множество способов сбора детальной информации о пользователе и его сетевой активности. Как мы уже писали во второй части статьи о «шпионских» привычках Windows 10, отправлять эти сведения непосредственно через браузер вовсе не обязательно.
Opera
Уже во время установки браузера Opera 43.0 трафик идет не только между компьютером и сайтом opera.com.

Соединения во время установки Opera
Запросы отправляются также к серверам BitGravity и EdgeCast, но содержат они исключительно обезличенные идентификаторы, версию браузера и ОС.

Подключение Opera к разным сетям при запуске
При каждом старте Opera 43.0 показывала страницу с рекламой разных брендов — от айтишных (Google, Yandex, Rambler) до совсем попсовых. Что поделать! Такова современная схема монетизации. Когда мы смотрели перехваченный трафик в Wireshark, то увидели вот такую строчку комментария от партнера Opera — сервиса бронирования отелей Booking.com: «x-content-Type-options: nosniff. Вы знаете, что вам могут платить за ковыряние нашего кода? Мы нанимаем дизайнеров и разработчиков для работы в Амстердаме». Предложение заманчивое, но, пожалуй, в Амстердаме лучше отдыхать, чем работать. Иначе будет получаться слишком веселый код.
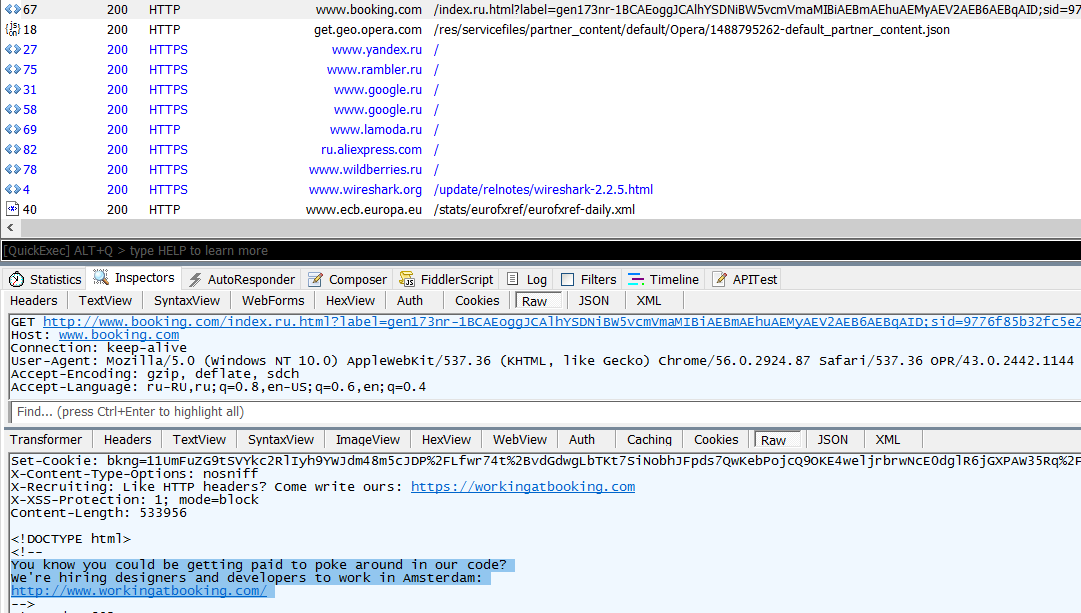
Не ковыряйте код бесплатно!
Помимо серверов в домене opera.com, одноименный браузер часто соединяется с узлами нидерландской сети WIKIMEDIA-EU-NET (91.198.174.0/24). Перехваченный трафик к этим серверам содержал только пакеты проверки сертификата безопасности (SSL), а все «личные данные» ограничивались скупой строчкой User-Agent: … OPR/36.0.2130.80 . Странно, поскольку версия «Оперы» была 43.0.
Сжатие данных сервисом Opera Turbo выполняется через системный процесс с нулевым PID, а трафик идет на серверы opera-mini.net .

Работа функции Opera Turbo
Во время нашего испытания браузер Opera вел себя скромно. В настройках по умолчанию он загружал много рекламной фигни уже при старте, но вскоре эти левые подключения закрывались. Никаких интимных подробностей Opera не разглашала.
Firefox
Разработчик Firefox — Mozilla Foundation активно использует облачные веб-сервисы Amazon. Это видно по множеству соединений с серверами compute.amazonaws.com , которые появляются сразу при старте браузера.
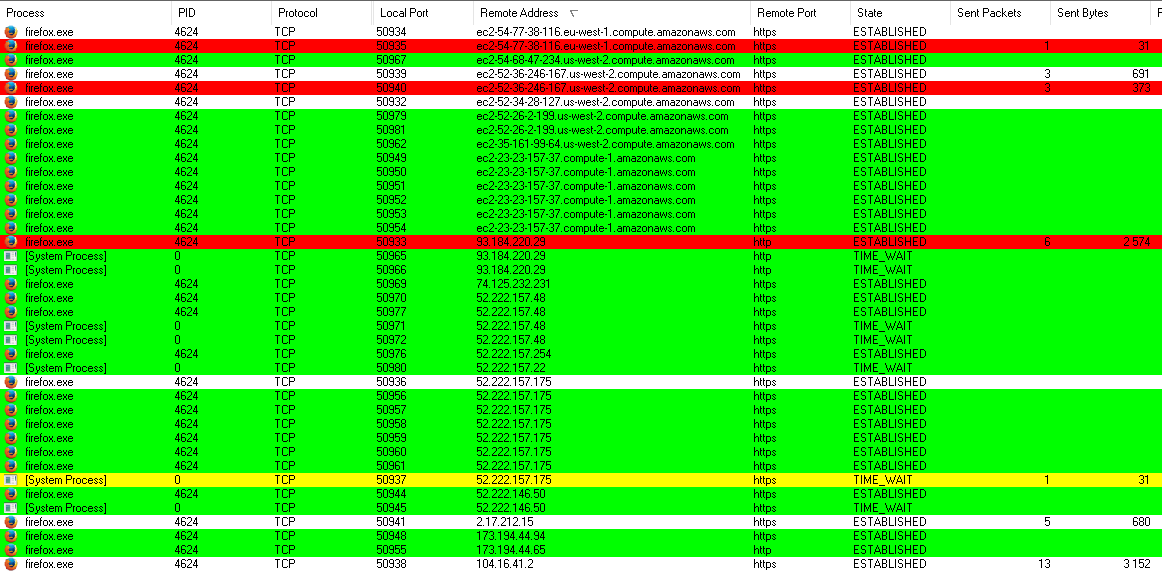
Автоматические соединения браузера Firefox
Они возникают всякий раз при запуске Firefox 51.0, даже если он только что установлен. Помимо Amazon, трафик идет в подсети Akamai, Cloudflare, EdgeCast и Google. Это нужно, чтобы сбалансировать нагрузку при скачивании обновлений самого браузера и его дополнений, а также обеспечить возможность быстро отправлять поисковые запросы. Кроме того, по умолчанию на новой вкладке браузера демонстрируются ссылки на другие проекты сообщества Mozilla, картинки для которых также загружаются из Сети.
Основная статистика о работе Firefox отправляется по адресу telemetry.mozilla.org . Выглядит она скудно и довольно безобидно.
Физическое местоположение устройства с запущенным браузером Firefox определяется через открытую систему Mozilla Location Service, но только если пользователь разрешил это в настройках: «Меню → Инструменты → Информация о странице → Разрешения → Знать ваше местоположение».
Как мы ни старались найти хоть какую-то подозрительную активность Firefox, ее не обнаружилось. Весь трафик полностью укладывался в рамки пользовательского соглашения.
Шифрование ≠ кодирование
Процедура шифрования принципиально отличается от кодирования. Если шифрование преобразует данные и делает их нечитаемыми без знания ключа и алгоритма расшифровки, то кодирование служит для сокращения записей и их стандартизации. Достигается это при помощи использования как кодовых страниц, так и какого-то условленного способа записи. Кодировок и форматов не так много. Подобрать нужные — дело техники. Однако без знания условных обозначений закодированная запись становится сложной для понимания в любом формате.

Закодированная информация о браузере
В случае с браузерами расшифрованный трафик часто оказывается дополнительно закодирован. Часть используемых в нем переменных имеет очевидный смысл. Например, запись s:1440x900x24 сообщает об установленном разрешении экрана и глубине цветовой палитры (8 бит на каждый канал RGB). Другие переменные более-менее легко угадываются из контекста. Например, можно предположить, что _ym_uid=1488623579201112390 — это идентификатор пользователя в системе «Яндекс.Метрика». Однако есть и множество других значений, смысл которых не так очевиден. К примеру, запись fpr:335919976901 или rqnl:1:st1488642088 — это тоже какие-то данные. В сыром виде их смысл может быть непонятен даже специалистам компании-разработчика. Просто потому, что обычно их анализирует автоматическая система, которая превращает подобную абракадабру в какие-то наглядные сведения.
Задергиваем шторы
Предотвратить отправку большей части статистики браузерами Chrome, Firefox и Opera довольно просто. Достаточно снять флажок «Отправлять сведения об использовании» или аналогичный ему. Обычно соответствующий пункт есть в мастере установки и в настройках браузера в разделе «Приватность».
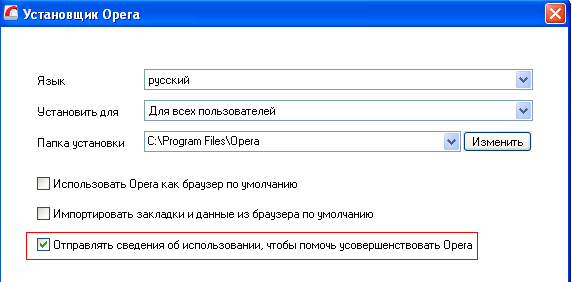
Слегка повысить приватность можно уже на этапе установки браузера
Там же можно отметить пункты «Отправлять сайтам запрет отслеживания», «Спрашивать разрешение на отправку моих геоданных» и снять флажок «Автоматически отправлять информацию о возможных проблемах».
Формулировка этих пунктов немного различается у разных браузеров, но суть их одинакова. «Запрет отслеживания» означает, что в исходящий трафик браузер будет добавлять заголовок do_not_track . Как его обрабатывать — целиком на совести владельца конкретного сайта.

Просьба сайтам не следить
Отправка геоданных по запросу означает, что сайты не смогут автоматически определять твое текущее местоположение. Как всегда, это немного повышает безопасность ценой снижения удобства.
Под «информацией о проблемах» в браузере подразумевается внезапное завершение его работы или невозможность соединиться с собственным узлом (например, для проверки обновлений). В таком случае разработчику могут быть отправлены расширенные сведения о возникшей проблеме. Если у тебя нет каких-то «хакерских» расширений и настроек, можно и помочь разработчикам сделать браузер лучше и стабильнее.
Выводы
В ходе исследования мы протестировали популярные браузеры, перехватили и проанализировали автоматически генерируемый ими трафик. Выводы здесь можно сделать очень осторожно. Часть отправляемых данных шифруется и дополнительно кодируется, поэтому их назначение остается неизвестным. Ситуация к тому же может измениться в любой момент: выйдет новая версия браузера, одна компания поглотит другую, и сменится политика конфиденциальности, читать которую большинству пользователей лень.
Проверенные нами браузеры действительно отправляют своим разработчикам и партнерам данные, собранные во время работы на любом устройстве — будь то компьютер или смартфон. Однако среди этих данных нет таких, которые можно было бы назвать личными и чувствительными к разглашению. В большинстве случаев это просто набор технических сведений, причем довольно лаконичный.
Например, в исходящих пакетах указывается разрешение экрана, но не определяется тип монитора. Идентифицируется общая архитектура процессора, но не записывается ни конкретная модель, ни его серийный номер. Вычисляется количество открытых вкладок, но не передаются их адреса. Аналогично и с паролями: в отправляемых браузером сведениях телеметрии нет самих сохраненных паролей — только их общее количество в рамках синхронизации настроек менеджера паролей.
До авторизации в каком-либо сетевом сервисе пользователя можно удаленно идентифицировать во время веб-серфинга только косвенно. Однако следует понимать, что даже общие технические сведения образуют уникальные сочетания. Вряд ли удастся найти много людей с такой же версией ОС, браузера, датой и временем его установки, набором установленных плагинов и расширений, количеством закладок, разрешением монитора, типом процессора, объемом оперативной памяти и полусотней других малых признаков. Этот цифровой отпечаток не раскрывает тайну личности, но позволяет отличить одного пользователя от других достаточно надежно.
Изначально браузеры и сайты присваивают пользователям безличные идентификаторы. Выглядят они как буквенно-цифровые строки. Они нужны, чтобы собрать воедино всю статистику работы и не смешивать данные от разных пользователей. Как их зовут и что они любят — разработчикам браузеров все равно. Это интересует отделы маркетинга крупных компаний, активно продвигающих разные социальные фишки. Поисковые системы, социальные сети, онлайновые игры, сайты знакомств и поиска работы — вот основные охотники за личными данными, но это уже совсем другая история.
Api browser ya ru что это
Итак, как известно, Яндекс выпустил свой новый браузер. Как многие и ожидали, этот браузер собирает статистическую информацию об использовании пользователем Интернета.
Как я выяснил, теперь эта статистическая информация не такая уж и «анонимная», как было заявлено. Но об этом чуть позже. Начнем с того, что же по факту Яндекс.Браузер отсылает себе.
Сам я пользуюсь Убунтой, но по такому случаю установил себе Windows 7 на VirtualBox, туда впихнул Яндекс.Браузер, а также программу CharlesProxy для просмотра трафика.
Итак, заходим с браузера на http://vk.com/ и видим, что происходит.
Посылаются запросы на следующие хосты:
Прошу обратить внимание: отправляются не только урлы, но заголовки Title страниц.
Спустя буквально минуту простоя (т.е. я ничего нигде не нажимал) — начинают делаться запросы, каждую секунду новый.
Запросы идут в больших количествах на адреса, в которых присутствует ydx-malware-shavar, видимо что-то с антивирусной проверкой, но ведь я только что включил компутер и никуда кроме родного вконтактика не заходил! Что-то тут неладное.
Ну а теперь собсно перейдем к названию топика. Как вы уже могли догадаться, теперь и приватные данные уходят к Яндексу. Яркий пример. Я залогинился в контакте, и вот что ушло в Яндекс:
Ушли имя и фамилия моей страницы! Иными словами, т.к. заголовки посещаемых страниц отправляются в Яндекс, они теперь знают, как меня зовут. (аккаунт на скрине «левый», если что).
Да, имя и фамилию из «ВКонтакте» можно было узнать и просто по URL часто посещаемой страницы, так что и всякие там счетчки типа LiveInternet’a тоже знают всех поимённо. НО! Ведь даже если ваши имя и фамилия указаны не настоящие, все равно отправка Title — это откровенно говоря наглость со стороны Яндекса. В тайтле может содержаться часть текста ваших электронных писем, да и вообще любая приватная информация.
Я не помню, простые счетчики на сайтах отправляют Title посещаемых страниц или нет?
В связи с этим, есть сильные основания полагать, что в огромном количестве зашифрованных переменных, отправляемых в Яндекс (видно на скринах), есть еще куча приватной информации.
Введение в web APIs
Начнём с рассмотрения того что представляют собой API на высоком уровне и выясним, как они работают, как их использовать в своих программах и как они структурированы. Также рассмотрим основные виды API и их применение.
| Необходимые знания: | Базовая компьютерная грамотность, понимание основ HTML и CSS, основы JavaScript (см. первые шаги, building blocks, объекты JavaScript). |
|---|---|
| Цель: | Познакомиться с API, выяснить что они могут делать и как их использовать. |
Что такое API?
Интерфейс прикладного программирования (Application Programming Interfaces, APIs) — это готовые конструкции языка программирования, позволяющие разработчику строить сложную функциональность с меньшими усилиями. Они «скрывают» более сложный код от программиста, обеспечивая простоту использования.
Для лучшего понимания рассмотрим аналогию с домашними электросетями. Когда вы хотите использовать какой-то электроприбор, вы просто подключаете его к розетке, и всё работает. Вы не пытаетесь подключить провода напрямую к источнику тока — делать это бесполезно и, если вы не электрик, сложно и опасно.

Точно также, если мы хотим, например, программировать 3D графику, гораздо легче сделать это с использованием API, написанных на языках высокого уровня, таких как JavaScript или Python.
Note: Смотрите также API в словаре.
API клиентской части JavaScript
Для JavaScript на стороне клиента, в частности, существует множество API. Они не являются частью языка, а построены с помощью встроенных функций JavaScript для того, чтобы увеличить ваши возможности при написании кода. Их можно разделить на две категории:
- API браузера встроены в веб-браузер и способны использовать данные браузера и компьютерной среды для осуществления более сложных действий с этими данными. К примеру, API Геолокации (Geolocation API) предоставляет простые в использовании конструкции JavaScript для работы с данными местоположения, так что вы сможете, допустим, отметить своё расположение на карте Google Map. На самом деле, в браузере выполняется сложный низкоуровневый код (например, на C++) для подключения к устройству GPS (или любому другому устройству геолокации), получения данных и передачи их браузеру для обработки вашей программой, но, как было сказано выше, эти детали скрыты благодаря API.
- Сторонние API не встроены в браузер по умолчанию. Такие API и информацию о них обычно необходимо искать в интернете. Например, Twitter API позволяет размещать последние твиты (tweets) на вашем веб-сайте. В данном API определён набор конструкций, осуществляющих запросы к сервисам Twitter и возвращающих определённые данные.

Взаимодействие JavaScript, API и других средств JavaScript
Итак, выше мы поговорили о том, что такое JavaScript API клиентской части и как они связаны с языком JavaScript. Давайте теперь тезисно запишем основные понятия и определим назначение других инструментов JavaScript:
- JavaScript — Язык программирования сценариев высокого уровня, встроенный в браузер, позволяющий создавать функциональность веб-страниц/приложений. Отметим, что JavaScript также доступен на других программных платформах, таких как Node. Но пока не будем останавливаться на этом.
- API браузера (Browser APIs) — конструкции, встроенные в браузер, построенные на основе языка JavaScript, предназначенные для облегчения разработки функциональности.
- Сторонние API (Third party APIs) — конструкции, встроенные в сторонние платформы (такие как Twitter, Facebook) позволяющие вам использовать часть функциональности этих платформ в своих собственных веб-страницах/приложениях (например, показывать последние Твиты на вашей странице).
- Библиотеки JavaScript — Обычно один или несколько файлов, содержащих пользовательские (custom) функции. Такие файлы можно прикрепить к веб-странице, чтобы ускорить или предоставить инструменты для написания общего функциональности. Примеры: jQuery, Mootools и React.
- JavaScript фреймворки (frameworks) — Следующий шаг в развитии разработки после библиотек. Фреймворки JavaScript (такие как Angular и Ember) стремятся к тому, чтобы быть набором HTML, CSS, JavaScript и других технологий, после установки которого можно «писать» веб-приложение с нуля. Главное различие между фреймворками и библиотеками — «Обратное направление управления» ( “Inversion of Control” ). Вызов метода из библиотеки происходит по требованию разработчика. При использовании фреймворка — наоборот, фреймворк производит вызов кода разработчика.
На что способны API?
Широкое разнообразие API в современных браузерах позволяет наделить ваше приложение большими возможностями. Достаточно посмотреть список на странице MDN APIs index page.
Распространённые API браузера
В частности, к наиболее часто используемым категориям API (и которые мы рассмотрим далее в этом модуле) относятся :
- API для работы с документами, загруженными в браузер. Явный пример — DOM (Document Object Model) API, позволяющий работать с HTML и CSS — создавать, удалять и изменять HTML, динамически изменять вид страницы и т.д. Любое всплывающее окно на странице или появляющееся «на ходу» содержимое — всё это благодаря DOM. Узнайте больше об этой категории API на странице Работа с документами.
- API, принимающие данные от сервера, часто используются, чтобы обновить небольшие части веб-страницы. Эта, казалось бы, малая деталь оказывает огромное влияние на производительность и поведение сайтов, так как нет необходимости перезагружать всю страницу целиком, если вам нужно просто обновить список товаров или новых доступных историй. Это также сделает приложение или сайт более отзывчивым и «живым». Список API, благодаря которым это возможно, включает: XMLHttpRequest и Fetch API. Вы также могли встретить термин Ajax, описывающий эту технологию. Узнать больше об этой категории API на странице Получение данных от сервера.
- API для работы с графикой широко поддерживаются браузерами, самые популярные: Canvas и WebGL, позволяющие программно изменять данные о пикселях, содержащиеся в элементе HTML <canvas> для создания 2D и 3D изображений. Например, вы можете нарисовать фигуры, скажем, прямоугольники или круги, импортировать изображение в canvas и применить к нему фильтры, такие как сепия или оттенки серого с помощью Canvas API, или создать сложное 3D-изображение с освещением и текстурами, используя WebGL. Такие API часто используют в сочетании с API создания анимационных циклов (таких как window.requestAnimationFrame() ) и другими для создания постоянно меняющегося изображения на экране, как в мультфильмах или играх .
- Аудио и Видео API как HTMLMediaElement , Web Audio API, и WebRTC позволяют делать действительно интересные вещи с мультимедиа. Например, создать собственный пользовательский интерфейс (User Interface, UI) для проигрывания аудио/видео, вывод на экран субтитров, записывать видео с веб-камеры для обработки в canvas (см. выше) или для передачи на другой компьютер в видео-конференции, применять звуковые эффекты к аудио-файлам (такие как gain, distortion, panning и т.д.).
- API устройств — в основном, API для обработки и считывания данных с современных устройств удобным для работы веб-приложений образом. Мы уже говорили об API Геолокации, позволяющем считать данные о местоположении устройства. Другие примеры включают уведомление пользователя о появившемся обновлении для веб-приложения с помощью системных уведомлений (см. Notifications API) или вибрации (см. Vibration API).
- API хранения данных на стороне пользователя приобретают всё большее распространение в веб-браузерах — возможность хранить информацию на стороне клиента очень полезна, когда необходимо создать приложение, которое будет сохранять своё состояние между перезагрузками страницы, или даже работать, когда устройство не в сети. В данный момент доступно немало таких API. Например, простое хранилище данных в формате имя/значение (name/value) Web Storage API или хранилище данных в формате таблиц IndexedDB API.
Распространённые сторонние API
Существует множество сторонних API; некоторые из наиболее популярных, которые вы рано или поздно будете использовать, включают:
-
для добавления такой функциональности, как показ последних твитов на сайте. для работы с картами на веб-странице (интересно, что Google Maps также использует этот API). Теперь это целый набор API, который может справляться с широким спектром задач, как свидетельствует Google Maps API Picker. позволяет использовать различные части платформы Facebook в вашем приложении, предоставляя, например, возможность входа в систему с логином Facebook, оплаты покупок в приложении, демонстрация целевой рекламы и т.д. , предоставляющий возможность встраивать видео с YouTube на вашем сайте, производить поиск, создавать плейлисты и т.д. — фреймворк для встраивания функциональности голосовой и видео связи в вашем приложении, отправки SMS/MMS из приложения и т.д.
Note: вы можете найти информацию о гораздо большем количестве сторонних API в Каталоге Web API.
Как работает API?
Работа разных JavaScript API немного отличается, но, в основном, у них похожие функции и принцип работы.
Они основаны на объектах
Взаимодействие с API в коде происходит через один или больше объектов JavaScript, которые служат контейнерами для информации, с которой работает API (содержится в свойствах объекта), и реализуют функциональность, которую предоставляет API (содержится в методах объекта).
Note: Если вам ещё не известно как работают объекты, советуем вернуться назад и изучить модуль Основы объектов JavaScript прежде чем продолжать.
Вернёмся к примеру с API Геолокации — очень простой API, состоящий из нескольких простых объектов:
-
, содержит три метода для контроля и получения геоданных. , предоставляет данные о местоположении устройства в заданный момент времени — содержит Coordinates — объект, хранящий координаты и отметку о текущем времени. , содержит много полезной информации о расположении устройства, включая широту и долготу, высоту, скорость и направление движения и т.д.
Так как же эти объекты взаимодействуют? Если вы посмотрите на наш пример maps-example.html (see it live also), вы увидите следующий код:
Note: Когда вы впервые загрузите приведённый выше пример, появится диалоговое окно, запрашивающее разрешение на передачу данных о местонахождении этому приложению (см. раздел У них есть дополнительные средства безопасности там, где это необходимо далее в этой статье). Вам нужно разрешить передачу данных, чтобы иметь возможность отметить своё местоположение на карте. Если вы всё ещё не видите карту, возможно, требуется установить разрешения вручную; это делается разными способами в зависимости от вашего браузера; например, в Firefox перейдите > Tools > Page Info > Permissions, затем измените настройки Share Location; в Chrome перейдите Settings > Privacy > Show advanced settings > Content settings и измените настройки Location.
Во-первых, мы хотим использовать метод Geolocation.getCurrentPosition() , чтобы получить текущее положение нашего устройства. Доступ к объекту браузера Geolocation производится с помощью свойства Navigator.geolocation , так что мы начнём с
Это эквивалентно следующему коду
Но мы можем использовать точки, чтобы связать доступ к свойствам/методам объекта в одно выражение, уменьшая количество строк в программе.
Метод Geolocation.getCurrentPosition() имеет один обязательный параметр — анонимную функцию, которая запустится, когда текущее положение устройства будет успешно считано. Сама эта функция принимает параметр, являющийся объектом Position (en-US), представляющим данные о текущем местоположении.
Note: Функция, которая передаётся другой функции в качестве параметра, называется колбэк-функцией (callback function).
Такой подход, при котором функция вызывается только тогда, когда операция была завершена, очень распространён в JavaScript API — убедиться, что операция была завершена прежде, чем пытаться использовать данные, которые она возвращает, в другой операции. Такие операции также называют асинхронными операциями (asynchronous operations). Учитывая, что получение данных геолокации производится из внешнего устройства (GPS-устройства или другого устройства геолокации), мы не можем быть уверены, что операция считывания будет завершена вовремя и мы сможем незамедлительно использовать возвращаемые ею данные. Поэтому такой код не будет работать:
Если первая строка ещё не вернула результат, вторая вызовет ошибку из-за того, что данные геолокации ещё не стали доступны. По этой причине, API, использующие асинхронные операции, разрабатываются с использованием callback function, или более современной системы промисов, которая появилась в ECMAScript 6 и широко используются в новых API.
Мы совмещаем API Геолокации со сторонним API — Google Maps API, который используем для того, чтобы отметить расположение, возвращаемое getCurrentPosition() , на Google Map. Чтобы Google Maps API стал доступен на нашей странице, мы включаем его в HTML документ:
Чтобы использовать этот API, во-первых создадим объект LatLng с помощью конструктора google.maps.LatLng() , принимающим данные геолокации Coordinates.latitude (en-US) и Coordinates.longitude (en-US) :
Этот объект сам является значением свойства center объекта настроек (options), который мы назвали myOptions . Затем мы создаём экземпляр объекта, представляющего нашу карту, вызывая конструктор google.maps.Map() и передавая ему два параметра — ссылку на элемент <div> , на котором мы хотим отрисовывать карту (с ID map_canvas ), и объект настроек (options), который мы определили выше.
Когда это сделано, наша карта отрисовывается.
Последний блок кода демонстрирует два распространённых подхода, которые вы увидите во многих API:
- Во-первых, объекты API обычно содержат конструкторы, которые вызываются для создания экземпляров объектов, используемых при написании программы.
- Во-вторых, объекты API зачастую имеют несколько вариантов (options), которые можно настроить и получить именно ту среду для разработки, которую вы хотите. API конструкторы обычно принимают объекты вариантов (options) в качестве параметров, с помощью которых и происходит настройка.
Note: Не отчаивайтесь, если вы что-то не поняли из этого примера сразу. Мы рассмотрим использование сторонних API более подробно в следующих статьях.
У них узнаваемые точки входа
При использовании API убедитесь, что вы знаете где точка входа для API. В API Геолокации это довольно просто — это свойство Navigator.geolocation , возвращающее объект браузера Geolocation , внутри которого доступны все полезные методы геолокации.
Найти точку входа Document Object Model (DOM) API ещё проще — при применении этого API используется объект Document , или экземпляр элемента HTML, с которым вы хотите каким-либо образом взаимодействовать, к примеру:
Точки входа других API немного сложнее, часто подразумевается создание особого контекста, в котором будет написан код API. Например, объект контекста Canvas API создаётся получением ссылки на элемент <canvas> , на котором вы хотите рисовать, а затем необходимо вызвать метод HTMLCanvasElement.getContext() :
Всё, что мы хотим сделать с canvas после этого, достигается вызовом свойств и методов объекта содержимого (content) (который является экземпляром CanvasRenderingContext2D ), например:
Note: вы можете увидеть этот код в действии в нашем bouncing balls demo (see it running live also).
Они используют события для управления состоянием
Мы уже обсуждали события ранее в этом курсе, в нашей статье Introduction to events — в этой статье детально описываются события на стороне клиента и их применение. Если вы ещё не знакомы с тем, как работают события клиентской части, рекомендуем прочитать эту статью прежде, чем продолжить.
В некоторых API содержится ряд различных событий, в некоторых — событий нет. Свойства обработчика, позволяющие запускать функции при совершении какого-либо события по большей части перечислены в нашем материале отдельного раздела «Обработчики событий (Event handlers)». Как простой пример, экземпляры объекта XMLHttpRequest (каждый представляет собой HTTP-запрос к серверу на получение каких-либо ресурсов (resource)) имеют несколько доступных событий, например, событие load происходит, когда ответ с запрашиваемым ресурсом был успешно возвращён и доступен в данный момент.
Следующий код содержит простой пример использования событий:
Note: вы можете увидеть этот код в действии в примере ajax.html (see it live also).
В первых пяти строках мы задаём расположение ресурса, который хотим получить, создаём экземпляр объекта запроса с помощью конструктора XMLHttpRequest() , открываем HTTP-запрос GET , чтобы получить запрашиваемый ресурс, определяем, что мы хотим получить этот ресурс в формате json, после чего отсылаем запрос.
Затем функция-обработчик onload определяет наши действия по обработке ответа сервера. Нам известно, что ответ успешно возвращён и доступен после наступления события load (и если не произойдёт ошибка), так что мы сохраняем ответ, содержащий возвращённый сервером объект JSON в переменной superHeroes , которую затем передаём двум различным функциям для дальнейшей обработки.
У них есть дополнительные средства безопасности там, где это необходимо
Функциональность WebAPI подвержена тем же соображениям безопасности, что и JavaScript или другие веб-технологии (например, same-origin policy), но иногда они содержат дополнительные механизмы защиты. К примеру, некоторые из наиболее современных WebAPI работают только со страницами, обслуживаемыми через HTTPS в связи с передачей конфиденциальных данных (примеры: Service Workers и Push).
К тому же, некоторые WebAPI запрашивают разрешение от пользователя, как только к ним происходит вызов в коде. В качестве примера, вы, возможно, встречали такое диалоговое окно при загрузке нашего примера Geolocation ранее:

Notifications API запрашивает разрешение подобным образом:

Запросы разрешений необходимы для обеспечения безопасности пользователей — не будь их, сайты могли бы скрытно отследить ваше местоположение, не создавая множество надоедливых уведомлений.
Итоги
На данном этапе, у вас должно сформироваться представление о том, что такое API, как они работают и как вы можете применить их в своём JavaScript-коде. Вам наверняка не терпится начать делать по-настоящему интересные вещи с конкретными API, так вперёд! В следующий раз мы рассмотрим работу с документом с помощью Document Object Model (DOM).
Вышло кошмарное приложение Яндекс Старт. Как вернуть старый Яндекс?
В этом году российский IT-гигант Яндекс переживает серьезную трансформацию. Весной стало известно, что компания планирует продать VK (ранее — Mail.ru Group) свои сервисы Дзен и Новости. 22 августа было подписано обязывающее соглашение, а 12 сентября сделка приобрела свой финальный вид. Вместе с улаживанием всех формальностей Яндекс выпустила обновление своего флагманского приложения до версии 22.91, превращающее его из «Яндекса — с Алисой» в «Яндекс Старт».

Так выглядел старый логотип приложения
Забегая вперед, можно сказать, что обновление получилось очень сырым. Пока оно вызывает исключительно противоречивые чувства. Если вы еще не устанавливали версию 22.91, настоятельно рекомендую не делать это. Сначала дочитайте материал до конца и узнайте обо всех изменениях. Если вы все-таки обновились и теперь хотите вернуть старое приложение Яндекса, то этот текст тоже будет полезен. В конце я обязательно расскажу, как откатить версию.
⚡ Подпишись на Androidinsider в Дзене, где мы публикуем эксклюзивные материалы
Куда пропал Яндекс
Прежде чем начать разговор о новом приложении Яндекса, нужно немного уточнить детали сделки между Yandex и VK. Вы наверняка знаете, что главная страница российского поисковика располагалась по адресу yandex.ru. Теперь, если вы попытаетесь на нее перейти, то автоматически будете перенаправлены на dzen.ru.
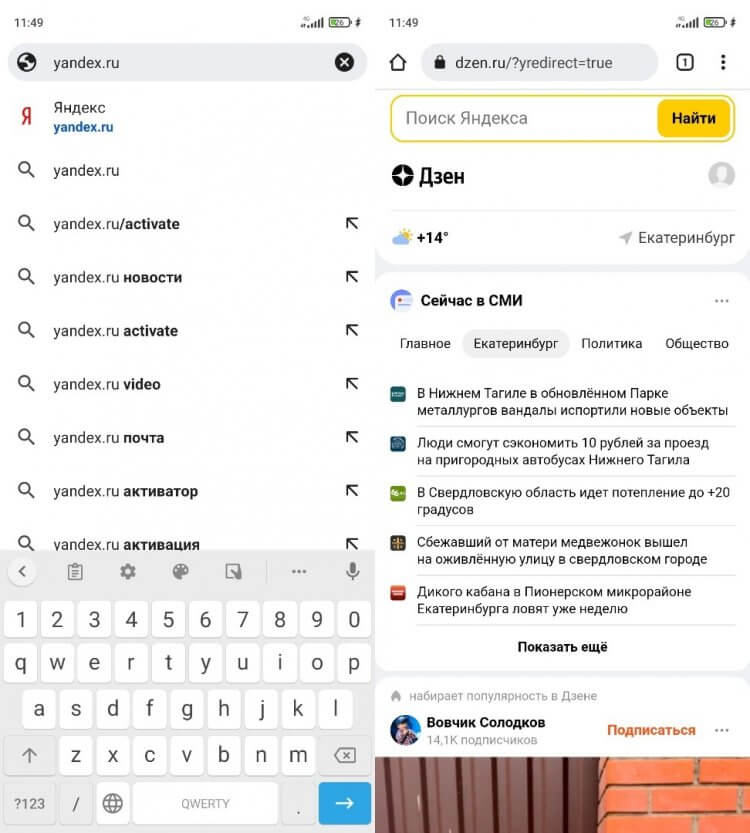
Попытавшись перейти на старую страницу Яндекса, вы попадете в Дзен
Несмотря на то, что название страницы говорит о принадлежности адреса к Дзену, визуально она практически не отличается от yandex.ru. Вверху здесь по-прежнему отображается поисковая строка Яндекс, новости сервиса Yandex News и лента Дзена. В будущем визуальная составляющая определенно изменится (хотя бы из-за того, что у VK есть собственный поисковик). А пока dzen.ru кажется переходным вариантом, так как при нажатии на строку поиска в контекстном меню вылезает предложение воспользоваться одним из сервисов Яндекса.
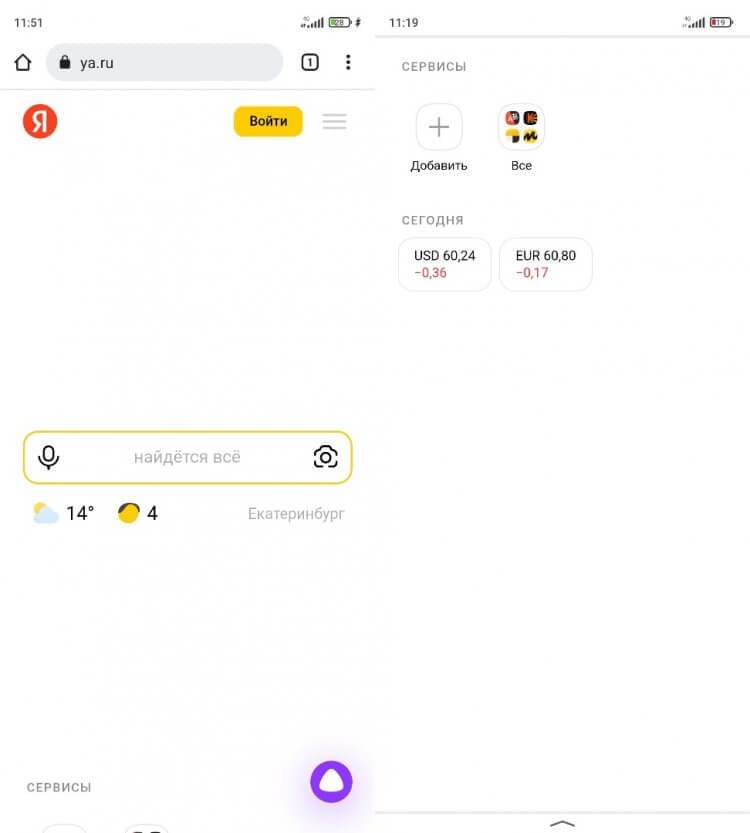
Новая страница Яндекса выглядит так
Теперь о том, куда исчез Яндекс. Главная страница Яндекс переехала на ya.ru и выглядит еще более спорно, чем основной экран обновленного Дзена. Между элементами интерфейса существует очень большой зазор. Если значок «Войти», позволяющий авторизоваться в Яндексе, находится в самом верху, то поисковая строка — посередине. А под ней — вкладка с сервисами Yandex и две плитки с курсами валют.
�� Загляни в телеграм-канал Сундук Али-Бабы, где мы собрали лучшие товары с АлиЭкспресс
Яндекс Старт — новое приложение
До обновления 22.91 приложение Яндекса объединяло в себе все сервисы компании, а Дзен и Новости были едва ли не главными продуктами, обеспечивающими самый большой трафик. Поскольку сейчас компании Аркадия Воложа нет смысла продвигать сервисы, проданные конкуренту, изменилось само позиционирование программы. Если раньше она называлась «Яндекс — с Алисой», то сейчас ее переименовали в «Яндекс Старт».
«Приложение Яндекс превращается в Яндекс Старт: теперь вы сами выбираете стартовую страницу», — сказано в пресс-релизе на странице программы в Google Play.
После установки обновления в глаза сразу же бросается иконка приложения. Теперь буква «Я» (логотип Яндекса) помещена в белый круг.

У приложения теперь новая иконка
Еще больше разница становится видна после первого запуска приложения Яндекс Старт. Посмотрите, как отличается стартовая страница в версии 22.90 (слева) и 22.91 (справа).
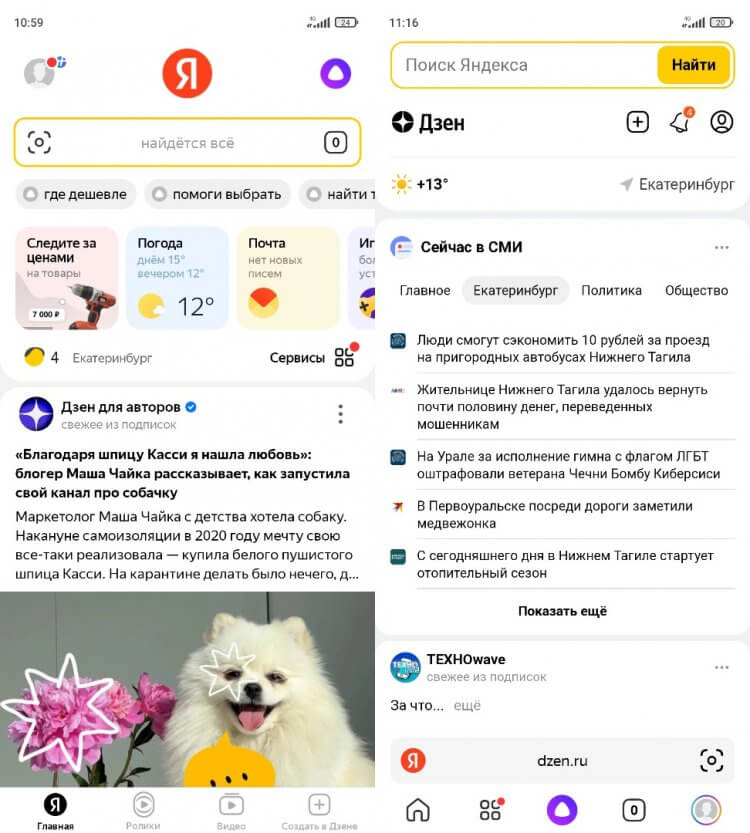
Стартовый экран приложения исчез, а вместо него открывается страница dzen.ru
Приложение Яндекс версии 22.90 представляло собой программу, объединяющую сервисы компании. На главной странице была доступна поисковая строка, большие вкладки с фирменными продуктами (теперь для их отображения нужно нажать на адресную строку), лента Дзена и новости. После обновления до 22.91 Яндекс превратился в обычный поисковик, который практически не отличается от другого приложения IT-гиганта — Yandex Browser, а вместо главного экрана перед нами красуется страница dzen.ru.
❗ Поделись своим мнением или задай вопрос в нашем телеграм-чате
Свою прописку поменяла иконка учетной записи. Если раньше она располагалась в левом верхнем углу, то теперь лого находится внизу справа и отображается на каждой странице в интернете, так как соседствует с адресной строкой. Само меню профиля осталось прежним, а вот раздел настроек изменился.
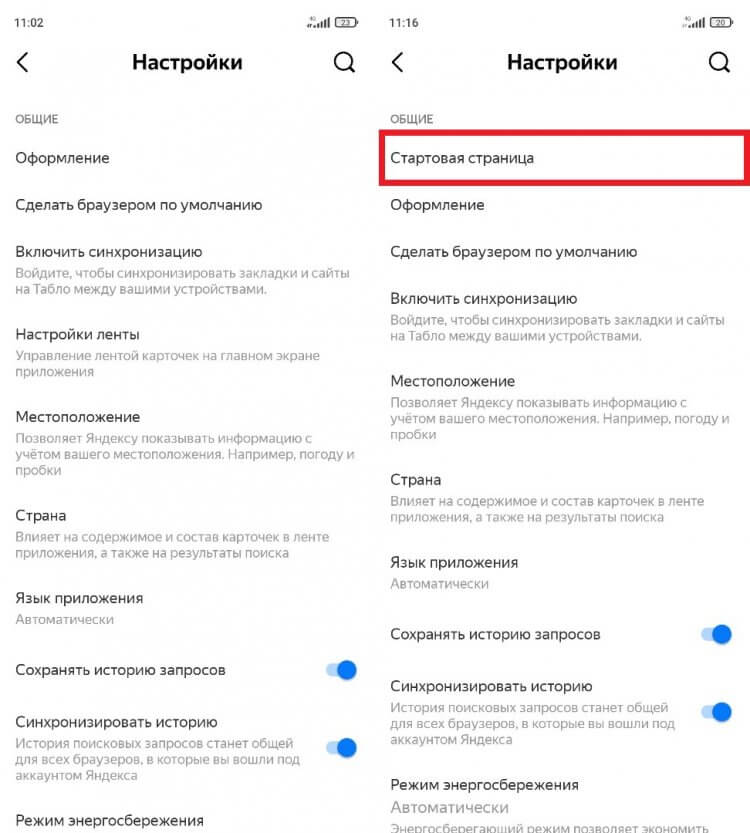
В настройках появился раздел «Стартовая страница»
Главным изменением стало появление раздела «Стартовая страница», как и в любом веб-браузере. По умолчанию выбрана страница dzen.ru, но при желании ее можно сменить на ya.ru или на адрес другого сайта. О том, чем отличается Дзен от Яндекса, я уже рассказал в начале материала.
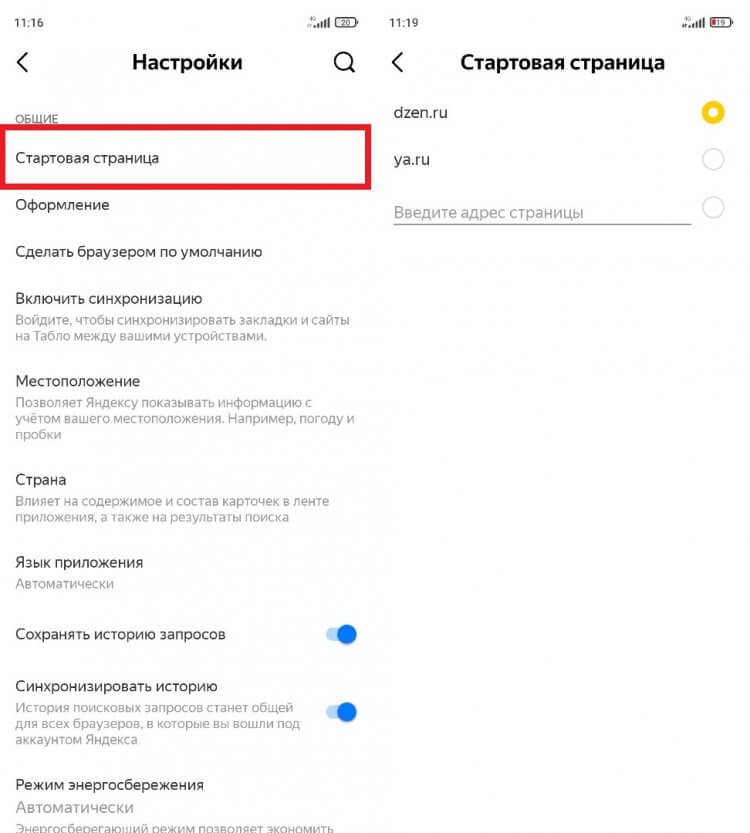
Можно выбрать стартовую страницу на свой вкус
Как вернуть приложение Яндекс
Свое мнение относительно приложения Яндекс Старт я высказал в самом начале, назвав его очень сырым (по крайней мере в нынешнем виде). С точки зрения удобства доступа к сервисам Yandex страница dzen.ru не может заменить главный экран, который был представлен в сборке 22.90, да и со временем она наверняка будет переформатирована под проекты VK. Если вы придерживаетесь того же мнения, то предлагаю разобраться, как вернуть старую версию приложения Яндекс. У вас есть 2 варианта. Первый заключается в откате на предыдущую версию:
- Удалите Яндекс Старт.
- Скачайте APK-файл приложения Яндекс — с Алисой версии 22.90.
- Запустите файл и подтвердите установку.
- По завершении инсталляции откройте страницу приложения Яндекс Старт в Google Play.
- Через «три точки» снимите галочку с пункта «Автообновление».
- После первого запуска Яндекс Старт отклоните предложение об обновлении.
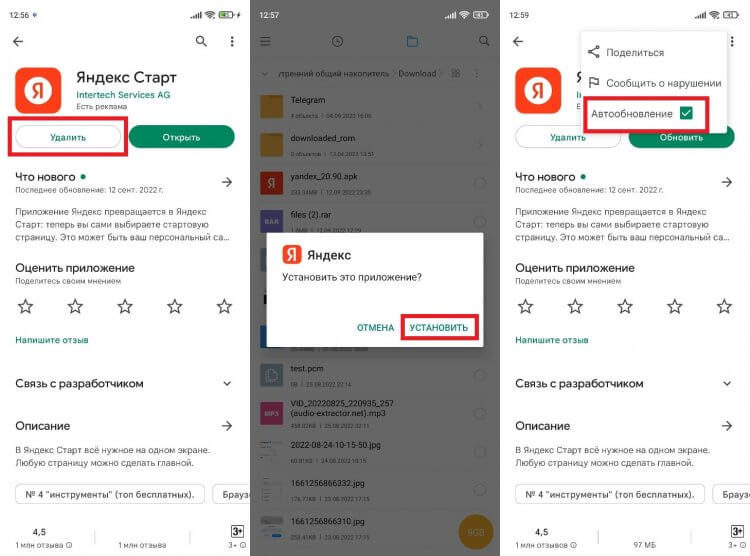
Не соглашайтесь на обновление приложения
Но есть еще один, более рациональный вариант. Одновременно с запуском Яндекс Старт компания перевыпустила приложение Яндекс — с Алисой, которое все так же можно установить через Google Play и другие цифровые площадки.
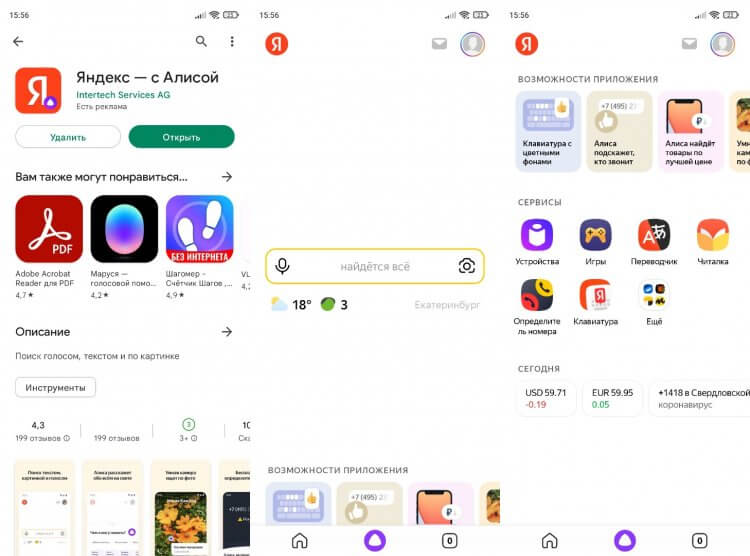
Так выглядит новая версия «Яндекс – с Алисой», которая устанавливается отдельно
Визуально это нечто среднее между старым приложением Яндекса и Яндекс Стартом. Интерфейс продолжает выглядеть слишком минималистично, а среди доступных сервисов предсказуемо отсутствуют Дзен и Новости. Но все-таки это оптимальная замена старому Яндексу, так как приложение будет обновляться, а разработчики наверняка учтут все пожелания пользователей.
Как настроить Яндекс, чтобы он опять стал удобным
С некогда удобной и многофункциональной страницы yandex.ru теперь вас переадресуют на dzen.ru. Где искать все прежние сервисы Яндекса?
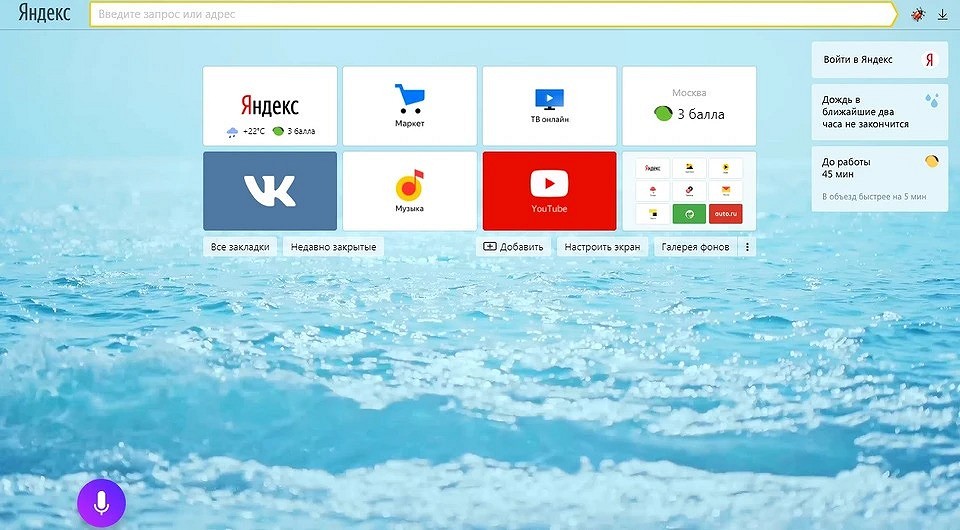
Не так давно «Яндекс» продал VK свои сервисы «Дзен» и «Новости». Это могло бы пройти для пользователей поисковика незамеченным, но теперь страница yandex.ru, которую раньше можно было настроить по своему усмотрению, не существует: с нее переадресуют на dzen.ru. А вот эта страница, несмотря на наличие на ней поисковой строки «Яндекса», принадлежит VK.
Поисковик переехал на ya.ru. Это фактически девственно чистая страница без удобных блоков и сервисов. Как теперь пользоваться «Картами», искать файлы на «Диске» или быстро открывать «Переводчик»? Есть несколько способов.
Как найти сервисы «Яндекса» на dzen.ru?
Тут все просто: надо кликнуть по пустой поисковой строке. Тогда под ней «»вылетят» ваши последние запросы и привычные сервисы. Если нужного нет в строке, нажмите «Еще».