Биты, байты, построение с двоичным кодом
Если вы работаете с компьютерами (или даже не работаете!), Велика вероятность, что вы слышали, что люди говорят о компьютерах как о «кучке нулей и единиц». Это была одна из немногих вещей, которые я знал о компьютерах до того, как начал заниматься программным обеспечением: все это только единицы и нули. И только после того, как я научился программировать и начал профессионально программировать, я понял, что это на самом деле означает. Да, компьютеры работают с единицами и нулями. Это определенно немного сложнее, но не настолько, чтобы мы не могли этого понять!
Давайте начнем с названия нашей проблеме. Те единицы и нули, из которых состоит компьютер? Они основаны на типе системы счисления, называемой двоичной. Двоичная система счисления основана на простой идее: вместо того, чтобы считать с помощью 10 цифр — как мы научились делать в детском саду, — вы можете считать с помощью только двух цифр. Двоичная система счисления, которая используется сегодня в компьютерах, была создана Готфридом Вильгельмом Лейбницем в 1679 году, но этот способ счета имеет гораздо более долгую историю, восходящую к древним египтянам.
Итак, если двоичный код состоит только из двух цифр, как считать после… двух?
Бинарный счет
В нашей современной системе счета на каждое место приходится десять возможных цифр. Вот почему мы иногда слышим, как люди называют нашу систему подсчета основанием 10; другое название для этого — денар. В двоичной системе счисления у нас есть две возможные цифры на место, поэтому мы можем называть это счетом по основанию 2 (которое иногда сокращается как bin для двоичного файла). Количество возможных цифр на место — единственная реальная разница в способе подсчета по основанию 2 и основанию 10.

В примере слева мы видим, что мы начинаем считать так же, как и в базе 10. Сначала с 0, затем с 1. Но когда мы переходим к числу 2, как вы продолжаете считать ?!
Что ж, давайте подумаем о том, что мы делаем в базе 10. Когда мы дойдем до числа 9, что мы будем делать? Мы сбрасываем единицы измерения, чтобы снова начать с числа 0, и увеличиваем наши разряды десятков до числа 1. Когда мы прошли все возможности между 10–19, мы сбрасываем единицы измерения на 0 и увеличиваем разряды десятков до число 2. Мы делаем это до тех пор, пока не достигнем числа от 90 до 99, а затем добавляем еще один разряд: разряд сотен.
Та же логика применима к счету в двоичном формате. Начнем с 0 и 1. Чтобы представить число 2, мы сбрасываем первое место на 0 и добавляем еще одну цифру слева: 10. Затем мы снова увеличиваем первое место: 11. И если мы продолжим это делать, мы видите, что первые 10 чисел в двоичном формате выглядят следующим образом:
(Pssst — существует закономерность в количестве возможных перестановок / комбинаций на цифру! Но если вы еще не видите его, не волнуйтесь. Позже это станет немного более очевидным).
Запись в двоичном формате
Мы знаем, что компьютеры работают на двоичной системе. И все же никто из нас не набирает двоичный код на клавиатуре! Это заставило бы нас поверить в то, что то, что мы вводим в наши машины, каким-то образом преобразуется (компилируется) в двоичный код. Это происходит с помощью нескольких уровней абстракции, и мы не будем углубляться во все из них.
Хотя не обязательно знать все слои, я думаю, что есть смысл немного знать, как работает это преобразование. Мы сделаем это простым и сосредоточимся на преобразовании десятичных чисел (целых) в двоичные.
Помните, в начальной школе нам всем приходилось изучать наши таблицы умножения? А потом помните, в средней школе мы начали изучать экспоненты и поняли, насколько полезны эти таблицы умножения? Что ж, будьте готовы осознать это еще раз! За последнюю неделю я много практиковал преобразование в двоичный код и обратно и понял, что самое важное, что вы можете сделать, когда дело доходит до изучения двоичного кода, — это освежить свои силы двойки. (Но на случай, если вам понадобится небольшая помощь, я включил степень двойки в свои примеры ниже.)
Преобразование в двоичный
Давайте взглянем на пару примеров. Сначала давайте попробуем преобразовать число 27 (с основанием 10) в двоичное (с основанием 2).
Мы хотим разбить это число на две части. Итак, мы можем спросить себя: какой степени двойки я могу достичь, не переходя через число, которое я хочу преобразовать?
Найдя это число, мы хотим вычесть его из нашей общей суммы, а затем повторять этот процесс, пока не останется ноль. Важно помнить (о чем я, кажется, всегда забываю): 2 в степени 0 всегда равно единице!
Это может иметь больше смысла, чтобы увидеть на примере:
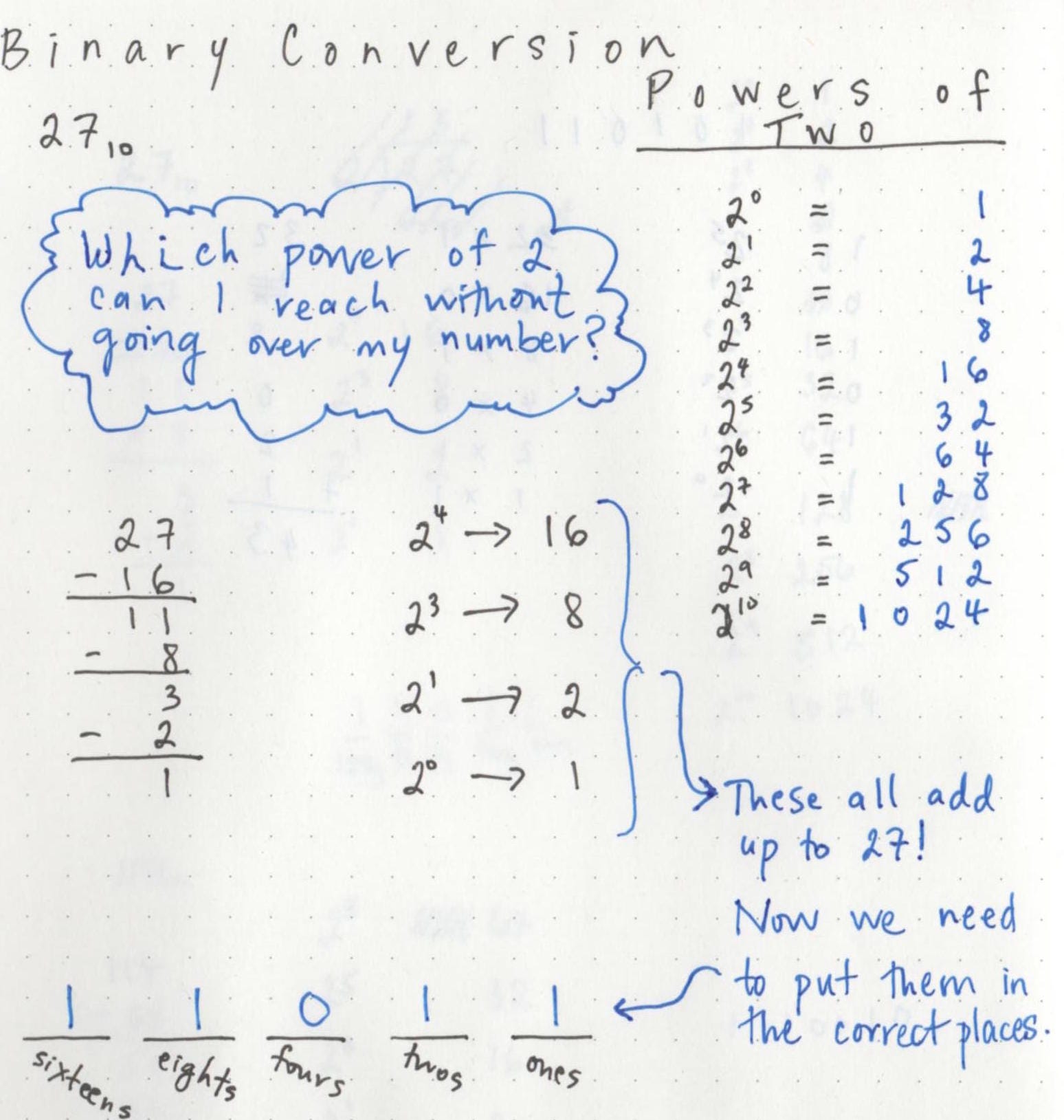
После того, как мы разбили наше число на степени двойки, нам нужно поставить их в нужное место. В базе 10 у нас есть единицы, десятки, сотни, тысячи и т. Д. В двоичной системе наши места происходят, как вы уже догадались, благодаря степени двойки. Наши места будут: единица, двойка, четверка, восьмерка, шестнадцать; другими словами, 2 в степени 0, 2 в степени 1, 2 в степени 2 и так далее.
Мы видим, что у нас есть значение 16, значение 8, значение 2 и значение 1. Именно так мы узнаем, к каким позициям относятся эти числа! Мы хотим поставить 1 в каждое из этих мест, и любое место / степень двойки, не имеющая значения в нашей разбивке чисел, получит ноль. Поскольку ничто в нашем числе 27 не может быть разбито в степень 2 (то есть, в нашем разбиении чисел не было четверок), мы поставим ноль в этом месте.
Вот и все! Число 27 можно преобразовать из основания 10 в двоичное как: 11011.
Хорошо, еще один пример. Давайте на этот раз по-крупному — число 114.
Наибольшая степень двойки, которую мы можем получить, не переходя за число 114, равна 64, или 2 в степени 6 (2 в степени 7 составляет 128, и это слишком велико, потому что оно идет по нашему номеру!). Мы сразу знаем, что у нас будет 1 вместо «64» или «2 в степени 6».
Давайте продолжим разбивать число 114 на две:

Итак, мы получили 64, 32, 16 и 2. После того, как мы поставили 1 в соответствующие настройки места, мы получим это число:
1110010
Вот и все! Двоичный эквивалент 114!
Если мы сделаем достаточно двоичных преобразований, мы начнем замечать, что четные числа с основанием десять всегда будут оканчиваться на 0, когда они преобразуются в двоичные. И наоборот, нечетные числа с основанием десять всегда будут заканчиваться на 1 при записи в двоичном формате. Помните то правило, о котором я упоминал ранее? 2 в степени 0 всегда равняется единице!
Вот это правило вступает в силу. Четные числа делятся на два, а это значит, что у вас никогда не будет лишнего остатка 1, когда вы разбиваете свое число на степени двойки.
Преобразование из двоичного
Интерпретировать числа из двоичного кода намного проще, если вы научитесь в нем писать. Когда мы преобразовывали десятичную систему в двоичную, мы разбивали вещи на степени двойки, верно? Но то, что мы на самом деле делали, было делением на двойку.
Исходя из этой логики, мы сделаем прямо противоположное противоположное действие, если захотим преобразовать двоичный в базовый 10. То есть мы умножим на двойку.
Давайте посмотрим, как это может выглядеть; преобразуем 101011 в основание 10:
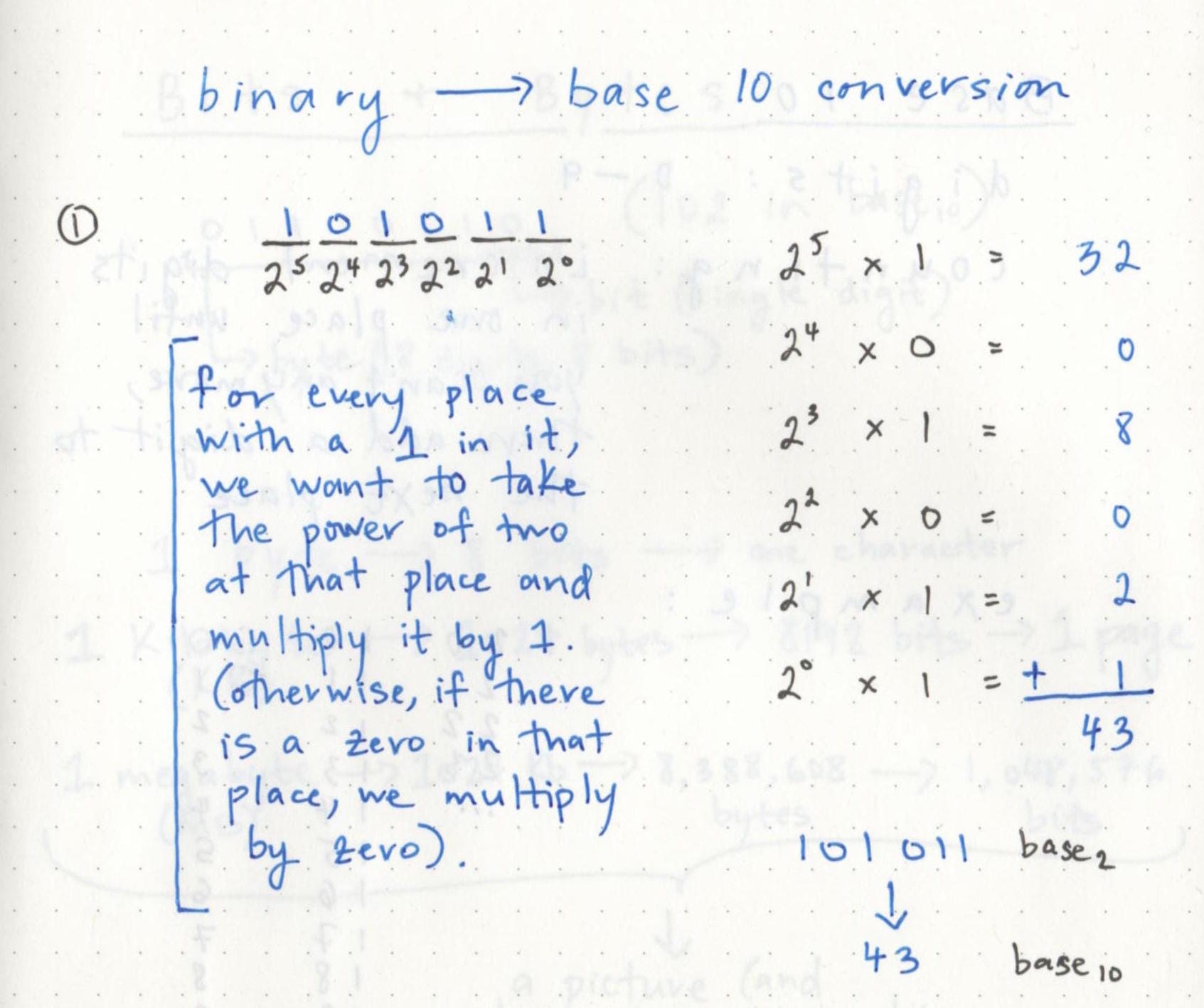
Сначала мы посмотрим, что находится в каждом месте, и вспомним, с какой степенью двойки связано это место. Мы можем начать слева направо: мы видим, что у нас есть 1 вместо 32 (2 в степени 5), что означает, что мы знаем, что версия этого числа с основанием 10 может быть разбита (читай: разделена) на 32.
Запишем это сбоку и продолжим. В разряде 2 в разряде 4 (который мы также могли бы назвать разрядом 16) стоит ноль, поэтому вместо умножения на 1 мы умножим его на 0.
Хорошее практическое правило при преобразовании из двоичного кода заключается в следующем: если на месте есть единица, умножьте степень двойки для этого места на 1 (и затем продолжайте делать это, пока не пройдете все места! ).
В конце концов, мы переходим к последней цифре и получаем следующие числа: 32, 8, 2 и 1 (что то же самое, что 2 в степени 5, 2 в степени 3, 2 в степени 1, 2 в степени 0). Все эти числа вместе дают нам преобразование 101011 по основанию 10: число 43.
Еще один быстрый пример — на этот раз давайте попробуем меньшее число. Вот как мы преобразовали 10100 в основание 10:

Надеюсь, это немного проще для понимания! Возможно, мы даже сможем сделать это в уме (в зависимости от того, насколько хорошо мы знаем свою степень двойки). Мы знаем, что нам нужно суммировать значение 2 в степени 4 и 2 в степени 2.
Что ж, к настоящему моменту мы, вероятно, сможем сделать это довольно быстро: 2 в степени 4 равно 16, а 2 в степени 2 равно 4. Что такое 16 + 4? 20.
И вот оно! 10100 совпадает с 20 в базе 10. Легко и просто!
Как компьютеры читают двоичные файлы?
Хорошо, хватит математики. При чем здесь компьютеры?
По сути, компьютеры состоят из переключателей. Мы уже знаем, что компьютеры интерпретируют двоичные файлы. Но мы можем не осознавать, что переключатели и схемы, которые сегодня являются строительными блоками компьютеров, фактически представляют собой двоичные представления.
В компьютере есть миллиарды (крошечных) цифровых схем, которые невероятно просты. Они состоят из переключателей. У переключателя может быть только два состояния: включено или выключено. Другой способ подумать об этом — верно или неверно. И мы можем представить этот двоичный файл включения / выключения еще одним способом: 1 и 0.
Двоичная — это система нумерации, которую компьютеры используют для включения и выключения. Включено — 1, а выключено — 0.
Что еще круче, так это то, что все в компьютерах (и в информатике, кстати,!) На самом элементарном уровне основано на этой парадигме включения / выключения. Небольшие разряды электричества либо проходят, либо не проходят, в зависимости от того, включено или выключено что-то.
Итак, как компьютер интерпретирует и разбивает сложные вещи (например, этот пост в блоге) на единицы и нули? В нем используются разные единицы измерения, которые можно преобразовать в двоичные.
Одна цифра в двоичном формате называется двузначной цифрой t. Но вы можете знать это как бит . Поскольку мы знаем, что двоичный код имеет основание 2, а одна цифра может быть только 0 или 1, мы также можем сделать вывод, что бит может быть только когда-либо либо 0, либо 1.
Это означает, что наш компьютер должен делать все, создавая двоичные числа, то есть использовать только 0 и 1 и связывать их вместе. Что кажется безумием! Но он может строить биты поверх других битов. И это именно то, что он делает. Он объединяет 8 бит (8 цифр) в байт . Мы, возможно, уже слышали термин «байт», или, возможно, видели это на переполнении стека. Байт настолько распространен в способе интерпретации двоичного кода компьютерами, что считается единицей компьютерной памяти.
Я думаю, что байты особенно интересны, потому что один байт может представлять 256 различных комбинаций. (Помните, степень 2? 2 в степени 8 равна 256.) А что насчет того, если у вас есть два байта? Два байта означают 16 бит (двоичные цифры), что означает, что вы можете представить 65 536 различных комбинаций (2 в степени 16)! Это множество различных перестановок, которые можно представить всего двумя байтами! Если вы думаете об одной схеме (часто называемой транзисторами), управляющей переключателем включения / выключения на цифру, всего 16 транзисторов могут обрабатывать и интерпретировать тонны информации!
Биты, строительные блоки байтов, чрезвычайно важны и заслуживают понимания. Они важны, потому что разные компьютеры могут обрабатывать разное количество бит за раз. Например, 8-битная машина разбивает и обрабатывает 8 бит за раз. 16-битная машина распадается и обрабатывает 16 бит за раз. Количество битов, которые обрабатываются за раз, известно как компьютерное слово, поэтому мы можем думать о битах как о «буквах», составляющих компьютерное слово. Большинство компьютеров теперь имеют длину слова 32 или 64 бита. И теперь вы знаете, что это означает: ваша машина обрабатывает 32 или 64 бита за раз. Другими словами, ваш компьютер обрабатывает двоичные строки длиной от 32 до 64 цифр!
Эти единицы компьютерной памяти — это то, что обычно имеют в виду люди, когда говорят, что «все — единицы и нули». Потому что это действительно так.
Возьмем один символ слова. Этот символ требует 8 бит (или 1 байт) для его представления. Итак, что насчет чего-то большего? А как насчет страницы текста длиной около 1000 слов? Для этого потребуется намного больше байтов!

Возможно, я смотрел на слишком много единиц и нулей, но похоже, что как только вы начинаете думать о шкале битов и способах их соединения, построения и использования . ну, все начинает выглядеть как двоичное!
Сила двух
Двоичный формат — это то, о чем в наши дни думают немногие программисты. В глубине души мы знаем, что это важно и заслуживает изучения, но может показаться таким сложным и ненужным для размышлений.
Но если вы вспомните, когда компьютеры занимали целые комнаты (представьте, насколько велики были тогда схемы и транзисторы!), Насколько далеко они продвинулись и как сильно изменились с тех пор, это будет просто потрясающе.
По сути, это двоичный язык — язык, на котором говорит и понимает каждый компьютер. Так что, если вы интересуетесь компьютерами или работаете с ними, стоит немного узнать об основах двоичного кода. В конце концов, даже несмотря на то, что это всего лишь два числа, в конечном итоге это то, чем написан окружающий нас мир.

Заранее извиняюсь, если вы начнете мечтать в 0 и 1 сейчас!
Ресурсы
Если вы нашли этот пост интересным, ознакомьтесь с этими ресурсами ниже. Я нашел их очень полезными в изучении двоичного кода, так что, возможно, вы тоже это сделаете! Удачного обучения.
Двоичная система счисления. Бит и байт. Сегментация памяти.
Вообще, как компьютер может хранить, например, слово «диск»? Главный принцип — намагничивание и размагничивание одной дорожки (назовем ее так). Одна микросхема памяти — это, грубо говоря, огромное количество дорожек. Сейчас попробуем разобраться. Например:
нуль будет обозначаться как 0000 (четыре нуля),
(т.е. правую единицу заменяем на 0 и вторую устанавливаем в 1).
Уловили принцип? «0» и «1» — это т.н. биты. Один бит, как вы уже заметили, может быть нулем или единицей, т.е. размагничена или намагничена та или иная дорожка («0» и «1» это условное обозначение). Если еще присмотреться, то можно заметить, что каждый следующий установленный бит (начиная справа) увеличивает число в два раза: 0001 в нашем примере = 1; 0010 два; 0100 четыре; 1000 восемь и т.д. Это и есть т.н. двоичная форма представления данных.
Т.о. чтобы обозначить числа от 0 до 9 нам нужно четыре бита (хоть они и не до конца использованы. Можно было бы продолжить: десять 1010, одиннадцать 1011 , пятнадцать 1111).
Компьютер хранит данные в памяти именно так. Для обозначения какого-нибудь символа (цифры, буквы, запятой, точки. ) в компьютере используется определенное количество бит. Компьютер «распознает» 256 (от 0 до 255) различных символов по их коду. Этого достаточно, чтобы вместить все цифры (0 — 9), буквы латинского алфавита (a — z, A — Z), русского (а — я, А — Я), а также другие символы. Для представления символа с максимально возможным кодом (255) нужно 8 бит. Эти 8 бит называются байтом. Т.о. один любой символ — это всегда 1 байт (см. рис. 1).
| 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 |
| р | н | р | н | н | р | н | р |
Рис. 1. Один байт с кодом буквы Z
(буквы н и р обозначают: намагничено или размагничено соответственно)
Можно элементарно проверить. Создайте в текстовом редакторе файл с любым именем и запишите в нем один символ, например, «М» (но не нажимайте Enter!). Если вы посмотрите его размер, то файл будет равен 1 байту. Если ваш редактор позволяет смотреть файлы в шестнадцатеричном формате, то вы сможете узнать и код сохраненного вами символа. В данном случае буква «М» имеет код 4Dh в шестнадцатеричной системе, которую мы уже знаем или 1001101 в двоичной.
Т.о. слово «диск» будет занимать 4 байта или 4*8 = 32 бита. Как вы уже поняли, компьютер хранит в памяти не сами буквы этого слова, а последовательность «единичек» и «ноликов». «Почему же тогда на экране мы видим текст, а не «единички-нолики»? — спросите вы. Чтобы удовлетворить ваше любопытство, я забегу немного вперед и скажу, что всю работу по выводу самого символа на экран (а не битов) выполняет видеокарта (видеоадаптер), которая находится в вашем компьютере. И если бы ее не было, то мы, естественно, ничего бы не видели, что у нас творится на экране.
В Ассемблере после двоичного числа всегда должна стоять буква «b». Это нужно для того, чтобы при ассемблировании нашей программы Ассемблер смог отличать десятичные, шестнадцатеричные и двоичные числа. Например: 10 — это «десять», 10h — это «шестнадцать» а 10b — это «два» в десятичной системе.
Т.о. в регистры можно загружать двоичные, десятичные и шестнадцатеричные числа.
В результате в регистрах AX, BH и CL будет находится одно и тоже число, только загружаем мы его в разных системах. Компьютер же будет хранить его в двоичном формате (как в регистре BH).
Итак, подведем итог. В компьютере вся информация хранится в двоичном формате (двоичной системе) примерно в таком виде: 10101110 10010010 01111010 11100101 (естественно, без пробелов. Для удобства я разделили биты по группам). Восемь бит — это один байт. Один символ занимает один байт, т.е. восемь бит. По-моему, ничего сложного. Очень важно уяснить данную тему, так как мы будем постоянно пользоваться двоичной системой, и вам необходимо знать ее на «отлично».
Как перевести двоичное число в десятичное:
Надо сложить двойки в степенях, соответствующих позициям, где в двоичном стоят единицы. Например:
Возьмем число 20. В двоичной системе оно имеет следующий вид: 10100b
Итак (начнем слева направо, считая от 4 до 0; число в нулевой степени всегда равно единице (вспоминаем школьную программу по математике)):
Как перевести десятичное число в двоичное:
Можно делить его на два, записывая остаток справа налево:
В результате получаем: 10100b = 20
Как перевести шестнадцатеричное число в десятичное:
В шестнадцатеричной системе номер позиции цифры в числе соответствует степени, в которую надо возвести число 16:
В настоящий момент есть множество калькуляторов, которые могут считать и переводить числа в разных системах счисления. Например, калькулятор Windows, который должен быть в инженерном виде. Очень удобен калькулятор и в DOS Navigator’е. Если у вас есть он, то отпадает необходимость в ручном переводе одной системы в другую, что, естественно, упростит вам работу. Однако, знать этот принцип крайне важно!
Сегментация памяти в DOS.
Возьмем следующее предложение: «Изучаем сегменты памяти». Теперь давайте посчитаем, на каком месте стоит буква «ы» в слове «сегменты» от начала предложения включая пробелы. На шестнадцатом. Подчеркну, что мы считали слово от начала предложения.
Теперь немного усложним задачу и разобьем предложение следующим образом (символом «_» обозначен пробел):
В слове «Изучаем» символ «И» стоит на нулевом месте; символ «з» на первом, «у» на втором и т.д. В данном случае мы считаем буквы начиная с нулевой позиции, используя два числа. Назовем их сегмент и смещение. Тогда, символ «ч» будет иметь следующий адрес: 0000:0003, т.е. сегмент 0000, смещение 0003. Проверьте.
В слове «сегменты» будем считать буквы начиная с десятой позиции, но с нулевого смещения. Тогда символ «н» будет иметь следующий адрес: 0010:0005, т.е. пятый символ начиная с десятой позиции. 0010 — сегмент, 0005 смещение. Тоже проверьте.
В слове «память» считаем буквы начиная с 0020 сегмента и также с нулевой позиции. Т.о. символ «а» будет иметь аодрес 0020:0001, т.е. сегмент 0020, смещение 0001. Опять проверим.
Итак, мы выяснили, что для того, чтобы найти адрес нужного символа необходимо два числа: сегмент и смещение внутри этого сегмента. В Ассемблере сегменты хранятся в сегментных регистрах: CS, DS, ES, SS (см. предыдущий выпуск ), а смещения могут храниться в других (но не во всех).
Регистр CS служит для хранения сегмента кода программы (Code Segment — сегмент кода);
Регистр DS для хранения сегмента данных (Data Segment — сегмент данных);
Регистр SS для хранения сегмента стека (Stack Segment — сегмент стека);
Регистр ES дополнительный сегментный регистр, который может хранить любой другой сегмент (например, сегмент видеобуфера).
Пример N 2:
Давайте попробуем загрузить в пару регистров ES:DI сегмент и смещение буквы «м» в слове «памяти» из примера N 1 (см. выше). Вот как это запишется на Ассемблере:
Теперь в регистре ES находится сегмент с номером 20, а регистре DI смещение к букве «м» в слове «памяти». Проверьте, пожалуйста.
Здесь стоит отметить, что загрузка числа (т.е. какого-нибудь сегмента) напрямую в сегментый регистр запрещена. Поэтому мы в строке (1) загрузили сегмент в AX, а в строке (2) загрузили в регистр ES число 20, которое находилось в регистре AX:
Когда мы загружаем программу в память, она автоматически располагается в первом свободном сегменте. В файлах типа *.com все сегментные регистры автоматически инициализируются для этого сегмента (устанавливаются значения равные тому сегменту, в который загружена программа). Это можно проверить при помощи отладчика. Если, например, мы загружаем программу типа *.com в память, и компьютер находит первый свободный сегмент с номером 5674h, то сегментные регистры будут иметь следующие значения:
Код программы типа *.com должны начинаться со смещения 100h. Для этого мы, собственно, и ставили в наших прошлых примерах программ оператор org 100h, указывая Ассемблеру при ассемблировании использовать смещение 100h от начала сегмента, в который загружена наша программа (позже мы рассмотрим для чего это нужно). Сегментные же регистры, как я уже говорил, автоматически принимают значение того сегмента, в который загрузилась наша программа.
Пара регистров CS:IP задает текущий адрес кода. Теперь рассмотрим, как все это происходит на конкретном примере:
Пример N 3.
Итак, строки (1) и (8) описывают сегмент: CSEG (даем имя сегменту) segment (оператор Ассемблера, указывающий, что имя CSEG — это название сегмента); CSEG ends (end segment — конец сегмента) указывает Ассемблеру на конец сегмента.
Строка (2) сообщает, что код программы (как и смещения внутри сегмента CSEG) необходимо отсчитывать с 100h. По этому адресу в память всегда загружаются программы типа *.com.
Запускаем программу из Примера N 3 в отладчике. Допустим, она загрузилась в свободный сегмент 1234h. Первая команда в строке (4) будет располагаться по такому адресу:
1234h:0100h (т.е. CS = 1234h, а IP = 0100h) (посмотрите в отладчике на регистры CS и IP).
Перейдем к следующей команде (в отладчике CodeView нажмите клавишу F8, в другом посмотрите какая клавиша нужна; будет написано что-то вроде «F8-Step»). Теперь вы видите, что изменились следующие регистры:
AX = 0900h (точнее, AH = 09h, а AL = 0, т.к. мы загрузили командой mov ah,9 число 9 в регистр AH, при этом не трогая AL. Если бы AL был равен, скажем, 15h, то после выполнения данной команды AX бы равнялся 0915h)
IP = 102h (т.е. указывает на адрес следующей команды. Из этого можно сделать вывод, что команда mov ah,9 занимает 2 байта: 102h — 100h = 2).
Следующая команда (нажимаем клавишу F8) изменяет регистры DX и IP. Теперь DX указывает на смещение нашей строки («Oleg$») относительно начала сегмента, т.е. 109h, а IP равняется 105h, т.е. адрес следующей команды. Нетрудно посчитать, что команда mov dx,offset My_name занимает 3 байта (105h — 102h = 3).
Обратите внимание, что в Ассемблере мы пишем:
а в отладчике видим следующее:
mov dx,109 (109 — шестнадцатеричное число, но CodeView символ ‘h’ не ставит. Это надо иметь в виду).
Почему так происходит? Дело в том, что при ассемблировании программы, Ассемблер подставляет вместо offset My_name реальный адрес строки с именем My_name в памяти. Можно, конечно, записать сразу
Программа будет работать нормально. Но для этого нам нужно высчитать самим этот адрес. Попробуйте вставить следующие команды, начиная со строки (7) в примере N 3:
Просто продублируем команду int 20h (хотя, как вы уже знаете, до строки (8) программа не дойдет).
Теперь ассемблируйте программу заново. Запускайте ее под отладчиком. Вы увидите, что в DX загружается не 109h, а другое число. Подумайте, почему так происходит. Это просто!
В окне «Memory» («Память») вы должны увидеть примерно такое:
Позиция N1 (1234) — сегмент, в который загрузилась наша программа (может быть любым).
Позиция N2 (0000) — смещение в данном сегменте (сегмент и смещение отделяются двоеточием (:)).
Позиция N3 (CD 20 00 . F0 FE) — код в шестнадцатеричной системе, который располагается с адреса 1234:0000.
Позиция N4 (= .a.) — код в ASCII (ниже рассмотрим), соответствующий шестнадцатеричным числам с правой стороны.
В Позиции N2 (смещение) введите значение, которое находится в регистре DX после выполнения строки (5). После этого в Позиции N4 вы увидите строку «Oleg$», а в Позиции N3 — код символов «Oleg$» в шестнадцатеричной системе. Вот что загружается в DX! Это не что иное, как АДРЕС (смещенеие) нашей строки в сегменте!
Но вернемся. Итак, мы загрузили в DX адрес строки в сегменте, который мы назвали CSEG (строки (1) и (9) в Прмере N 3). Теперь переходим к следующей команде: int 21h. Вызываем прерывание DOS с функцией 9 (mov ah,9) и адресом строки в DX (mov dx,offset My_name).
Как я уже говорил раньше, для использования прерываний в программах, в AH заносится номер функции. Номера функций нужно запоминать.
Наше первое прерывание.
Функция 09h прерывания 21h выводит строку на экран, адрес которой указан в регистре DX.
Вообще, любая строка, состоящая из ASCII символов, называется ASCII-строка. ASCII символы — это символы от 0 до 255 в DOS, куда входят буквы русского и латинского алфавитов, цифры, знаки препинания и пр.
Изобразим это в таблице (так всегда теперь будем делать):
Функция 09h прерывания 21h — вывод строки символов на экран в текущую позицию курсора:
Вход: AH = 09h, DX = адрес ASCII-строки символов, заканчивающийся ‘$’
Выход: ничего
В поле «Вход» мы указываем, в какие регистры что загружать, а в поле «Выход» — что возвращает функция. Сравните эту таблицу с Примером N 3.
Вот мы и рассмотрели сегментацию памяти. Если я что-то упустил, то это рассмотрим в последующих выпусках. Очень надеюсь на то, что вы разобрались в данной теме.
Теперь интересная программка для практики, которая выводит в верхний левый угол экрана веселую рожицу на синем фоне:
Многие операторы вы уже знаете. Поэтому я буду объяснять только новые.
В данном примере мы используем вывод символа прямым отображением в видеобуфер.
В строках (4) и (5) загружаем в сегментный регистр ES число 0B800h, которое соответствует сегменту дисплея в текстовом режиме (запомните его!). В строке (6) загружаем в регистр DI нуль. Это будет смещение относительно сегмента 0B800h. В строках (8) и (9) в регистр AH заносится атрибут символа (31 — ярко-белый символ на синем фоне) и в AL — ASCII-код символа (01 — это рожица) соответственно.
В строке (10) заносим по адресу 0B800:0000h (т.е. первый символ в первой строке дисплея — верхний левый угол) атрибут и ASCII-код символа (31 и 01 соответственно) (сможете разобраться?).
Обратите внимание на запись регистров в строке (10). Скобки ( [ ] ) указывают на то, что надо загрузить число не в регистр, а по адресу, который содержится в регистре (в данном случае, как уже отмечалось, — это 0B800:0000h).
Можете поэксперементировать с данным примером. Только не меняйте строки (4) и (5). Сегментный регистр должен быть ES (можно, конечно, и DS, но тогда надо быть осторожным). Более подробно данный метод рассмотрим позже. Сейчас нам из него нужно понять принцип сегментации на практике.
Следует отметить, что вывод символа прямым отображением в видеобуфер является самым быстрым. Выполнение команды в строке (10) занимает 3 — 5 тактов. Т.о. на Pentium-100Mhz можно за секунду вывести 20 миллионов(!) символов или чуть меньше точек на экран! Если бы все программисты (а особенно Microsoft) выводили бы символы или точки на экран методом прямого отображения в видеобуфер на Ассемблере, то программы бы работали чрезвычайно быстро. Я думаю, вы представляете.
Как перевести двоичный код в биты
На аппаратном уровне вся информация в компьютере представляет последовательность электрических сигналов. Например, в какой-то определенной ячейке памяти может быть иметься сильное напряжение, или оно может быть очень слабым. Для описания состояния сигнала информатике используется термина бит . По сути бит является наименьшей единицей информации в компьютере. Бит может иметь значение 1 (есть сигнал, что обычно соответствует напряжению от 2 до 5 V) или 0 (сигнал отсутствует или слабый — обычно от 0 до 2 V).
8 битов составляют байт . Фактически байт — это наименьшая единица информации, которую можно прочитать или записать в память большинством современных процессоров.
Один бит может принимать два значения: 0 и 1. Два бита вместе могут принимать четыре значения: 00, 01, 10 и 11. Три бита могут принимать восемь значений: 000, 001, 010, 011, 100, 101, 110 и 111. Обобщая, группа из n битов может принимать 2 n значений. Таким образом, группа из 8 бит или 1 байт может представлять 2 8 , то есть 256 уникальных значений. Таким образом, вся информация в компьютере фактически представляет последовательность бит.
Двоичная система
Поскольку бит может иметь только два значения — 1 и 0, то для записи битов применяют двоичную систему исчисления. Вообще система исчисления представляет способ записи чисел. Например, в поседневной жизни мы пользуемся десятичной системой исчисления . Это значит, что основанием этой системы является число 10, а каждый символ числа может иметь 10 вариантов значений — от 0 до 9. В десятичной системе каждое число можно представить как сумму цифер чисел, умноженных на 10 в степени, соответствующей порядковому номеру цифры в этом числе (нумерация начинается с нуля). Например, стандартное число 123 можно представить следующим образом:
Или возьмем другое десятичное число — 123,45
В двоичной системе каждый символ числа может иметь только два значения — 1 и 0, например, число 1101. Чтобы перевести число из двоичной системы в десятичную умножаем значение каждого бита (1 или 0) на число 2 в степени, равной номеру бита (нумерация битов идет от нуля):
Перевод десятичного числа в двоичную систему выглядит несколько сложнее. Стандартный алгоритм преобразования подразумевает деление числа и результатов последующих делений на 2 и помещение остатков от деления в результат. Например, переведем десятичное число 13 в двоичную систему:
Общий алгоритм состоит в последовательном делении числа и результатов деления на 2 и получение остатков, пока не дойдем до 0. Затем выстраиваем остатки в линию в обратном порядке и таким образом формируем двоичное представление числа. Конкретно в данном случае по шагам:
Делим число 13 на 2. Результат деления — 6, остаток от деления — 1 (так как 13 — 6 *2 = 1)
Далее делим результат предыдущей операции деления — число 6 на 2. Результат деления — 3, остаток от деления — 0
Делим результат предыдущей операции деления — число 3 на 2. Результат деления — 1, остаток от деления — 1
Делим результат предыдущей операции деления — число 1 на 2. Результат деления — 0, остаток от деления — 1
Последний результат деления равен 0, поэтому завершаем процесс и выстраиваем остатки от операций делений, начиная с последнего — 1101
Шестнадцатиричная система
Если число большое, то запись двоичных чисел может быть довольно длинной и поэтому не очень удобной. Например, число 23410 в двоичной системе равно 111010102 . И для упрощения работы с двоичными числами применяется шестнадцатеричная система.
В шестнадцатеричной системе счисления двоичные числа разделены на группы по 4 бита. При 4 битах в группе количество возможных значений равно 24 или 16. Первым 10 из этих 16 чисел присваиваются цифры 0–9, а последним 6 — буквы A-F:
Двоичное число 11101010 можно представить более компактно, разбив его на две 4-битные группы (1110 и 1010) и записав их в виде шестнадцатеричных цифр EA .
Алгоритм перевода из шестнадцатеричной системы в десятичную и обратно тот же, что и для двоичной, только вместо 2 используется число 16. Например, шестнадцатеричное число E6 можно представить следующим образом:
А чтобы получить из 10-тичного числа 16-ричное, делим число на 16 и получаем остатки:
Чтобы указать, что число шестнадцатеричное, перед ним указываются символы 0X или 0x , например, 0xE6
Стоит отметить, что 4 бита, которые соответствуют одной шестнадцатеричной цифре, называется nibble или полубайт(слог, тертрада)
При работе с разными системами счисления легко запутаться. Например, какую систему в реальности представляет число 1010 ? Оно может равным образом представлять и десятичную, и двоичную, и шестнадцатеричную. И чтобы указать, что число относится к определенной системе счисления, используют различные обозначения. Так, для указания, что число является двоичным, перед число обычно ставится префикс 0b :
Чтобы указать, что число является шестнадцатеричным, перед число обычно ставится префикс 0x :
Представление отрицательных чисел
Для представления отрицательных чисел обычно применяется two’s complement ( дополнение до 2 ). С точки зрения математики чтобы получить отрицательный аналог числа надо от 0 (нуля) вычесть это число. Например, для получения -1 надо произвести операцию 0 — 1 = -1 . С точки зрения архитектуры компьютера в качестве 0 выступает число 2 N . В данном случае степень N представляет количество битов в числе.
Например, наше число состоит из 8 бит (1 байт), наподобие 0000 0001 (1 в десятичной системе). И мы хотим получить число -1. Для этого выполняем следующую операцию:
Но 255 — это в десятичной системе. А как это будет выглядеть в двоичной системе:
Таким образом, для 8 битное отрицательное число -1 в двоичной системе будет представлять 1111 1111
Аналогичная операция в шестнадцатеричной системе:
Если же мы выполним обратную операцию — к 1111 1111 прибавим изначальное число 0000 0001 , то мы получим степень двойки. Поэтому подобное представление отрицательных чисел и называется дополнение до 2-х.
Простой способ получить из положительного числа отрицательного и наборот (то есть фактически умножение на -1) заключается в том, чтобы инвертировать биты — биты 0 поменять на 1, а 1 на 0, и затем прибавить 1. Например, получим число -3. Для этого сначала возьмем двоичное представление числа 3:
Таким образом, число 1111 1101 является двоичным представлением числа -3, что в шестнадцатеричной системе аналогично 0xFD
Другой пример, число 1 в двоичной системе равно 0b0000001 . Чтобы получить число -1, сначала инвертируем биты:
Далее прибавляем 1:
То есть число -1 в двоичной системе равно 1111 1111 или 0xFF (в шестнадцатеричной системе)
Подобным образом можно получить обратно число 1:
Соответственно, в зависимости от того, какое именно это число — положительное или отрицательно, интерпретировать это число можно по разному. Например, если число 1111 1111 рассматривается как положительное, то в десятичной системе оно равно 255. Если же оно рассматривается как отрицательное, то в десятичной системе оно равно -1.
Таким образом, 8-битные числа со знаком охватывают диапазон от -128 до 127, а 8-битные числа без знака — от 0 до 255.
Инструкции
Основу программы на ассемблере составляют инструкции — некоторые действия, например, сложение двух значений, помещение в регистр значения и т.д. При выполнении программы процессор выбирает и интерпретирует каждую инструкцию. Как и все данные, каждая инструкция, каждое действие в программе представляет последовательность битов. Каждой инструкции сопоставляется определенный машинный двоичный код, который также называется кодом инструкции или кодом операции (опкод, opcode).
Код операции — это один байт, определяющий основную операцию инструкции. Например, инструкция, которая копирует в регистр RAX число 1, имеет опкод C7 в шестнадцатеричной форме или 11000111 в двоичной форме. В зависимости от инструкции, ее операндов опкод меняется. Например, инструкция, которая копирует в регистр EAX число 1, имеет опкод B8 в шестнадцатеричной форме или 10111000 в двоичной форме. К опкодам инструкций следует добавить коды/значения операндов — регистра и чисел.
Написание машинного кода вручную возможно, но излишне громоздко. На практике вместо опкодов применяются так называемые мнемоники — человекочитаемые названия инструкций. Например, инструкция, которая копирует в регистр некоторое значение, имеет мнемонику mov (от слова «move» — помещать, поместить). А чтобы скопировать в регистр RAX число 1, нам достаточно написано команду
А чтобы скопировать в регистр EAX число 1, нам достаточно написано команду
Это довольно удобнее, чем в бинарной форме вводить команды.
Программа состоит из набора подобных инструкций. Процессор запускает программы через цикл выборки-выполнения (fetch-execute cycle). Компьютер считывает по одной инструкции за раз. Для этого процессор обращается к специальному регистру — указателю команд (или регистр IP), который также называется программным счетчиком (или PC) и который хранит адрес инструкции для выполнения. По сути, компьютер выполняет бесконечный цикл следующих операций:
Считывает инструкцию с адреса памяти, указанного указателем инструкции — регистром IP/PC
Двоичный код в текст и обратно
Добро пожаловать на наш инструмент онлайн-конвертации двоичного кода. Этот инструмент предназначен для быстрой и точной переводной конвертации между обычным текстом и двоичным кодом. Он будет полезен для студентов, разработчиков программного обеспечения, криптографов, и любого, кто работает с данными на самом низком уровне.
На нашей платформе вы можете преобразовать обычный текст в двоичный код и наоборот. Мы поддерживаем кодировку UTF-8, UTF-16 и ASCII чтобы обеспечить наибольшую совместимость и точность перевода. Также предоставляем возможность отображения двоичного кода с пробелами или без них, в зависимости от ваших потребностей. Используйте наш инструмент для быстрого перевода текста в двоичный код и обратно, сохраняя целостность исходных данных и обеспечивая точный результат. Мы надеемся, что наш инструмент будет полезен для ваших проектов, образования и исследований. Начните прямо сейчас, просто введите ваш текст или двоичный код в соответствующее поле ввода и позвольте нашему инструменту сделать все остальное!
Как это считается
Перевод текста в двоичный код — это процесс преобразования символов текста в их двоичное представление. Это можно сделать вручную, следуя нижеуказанным шагам:
- Определите кодировку: Сначала вам нужно определить, какая кодировка используется для текста, который вы хотите перевести в двоичный код. Самой распространенной кодировкой является ASCII, но также часто используются UTF-8 и UTF-16. ASCII кодирует только символы английского алфавита, тогда как UTF-8 и UTF-16 поддерживают большинство мировых языков.
- Найдите код символа: Следующим шагом будет определение числового значения каждого символа в вашем тексте согласно выбранной кодировке. Для ASCII, например, буква «A» имеет код 65.
- Преобразуйте код в двоичный формат: Затем вы преобразуете этот числовой код в двоичный формат. Для этого вам понадобится знание процедуры перевода десятичного числа в двоичное. Например, число 65 в двоичном формате становится 01000001.
- Повторите процесс для каждого символа: Продолжайте этот процесс для каждого символа в вашем тексте. Каждый символ будет переведен в двоичный код, и в конце вы получите полное двоичное представление вашего текста.
Важно отметить, что хотя этот процесс можно выполнить вручную, он может быть трудоемким и подвержен ошибкам, особенно для больших текстов. Для этих целей лучше использовать автоматизированные инструменты, такие как онлайн-конвертеры двоичного кода.
Примеры
Задание: Переведите в двоичный код слово Hello
Решение: Пользуемся онлайн декодером на этой странице, получаем, что слово hello в двоичном коде выглядит так: 01101000 01100101 01101100 01101100 01101111
Задание: Вам дан двоичный код 0000000001110111 0000000001101111 0000000001110010 0000000001101100 0000000001100100. Расшифруйте его в кодировке UTF-16
Решение: Вводим двоичный код в нижнее окно, получаем, что это слово «world»
Задание: Переведите слово «true» в двоичный код, используя кодировку ASCII и предоставив его без пробелов
Решение: С помощью конвертора можно получить результат — 01110100011100100111010101100101