Как считать строку с пробелами c
Функция sscanf считывает данные из строки (массива символов) в переменные. Функция имеет следующий синтаксис
Первый параметр функции представляет строку, из которой считываются данные. Второй параметр представляет формат считывания. В качестве последующих параметров указываются переменные, в которые идет считывание.
Считаем данные из строки
В данном случае строка, из которой считываются данные:
Разделителем между значениями является пробел, либо последовательность пробелов, табуляция и перевод строки.
Эту строку передаем в функцию sscanf первым аргументом и считываем ее значения в переменные c , n , d :
А второй аргумент — формат считывания определяет, как данные из строки будут сопоставляться с переменными:
Поскольку значения в строке buff разделены пробелами, то и в строки форматирования спецификаторы разделены пробелами. Первый спецификатор %c позволяет считать первый символ в переменную типа char c .
Второй спецификатор — %d обеспечивает считывание целого числа в переменную n .
И третий спецификатор %lf считывает данные в переменную типа double — d
То есть в итоге консольный вывод был бы следующим:
Обратите внимание, что формат считывания соответствует строке, из которой считываются данные. Если бы в строке данные были бы разделены запятыми, то спецификаторы в формате считывания также были бы разделены запятыми:
Еще один пример. Пусть в строке содержатся данные пользователя, как имя, возраст, зарплата. Считаем эти данные в переменные:
Причем строка форматирования может быть более сложной. Например:
В данном случае исходная строка представляет текст «Name is Tom and age is 38» . И на эту строку накладывается строка форматирования «Name is %s and age is %d» . Соответственно здесь спецификатор %s будет представлять строку «Tom», а спецификатор %d — число 38.
Считывание с консоли
Комбинируя это функцию с fgets() , можно считывать данные с консоли:
Пример консольного ввода:
Данный способ имеет премущества по сравнению с чтением через scanf , поскольку при считывании функция scanf удаляет из входного буфера только значения, которые соответствуют спецификаторам. Поэтому, если ввод через scanf не соответствует чему-либо, оставшиеся в буфере символы будут считываться при следующем вызове scanf.
sprintf
Функция sprintf производит обратное действие — записывает данные в строку:
В качестве первого параметра функция принимает указатель на буфер, в который идет запись. Второй параметр представляет строку форматирования. Кроме того, в качестве дополнеительных аргументов в функцию можно передавать дополнительные значения для спецификаторов из строки форматирования. Результатом функции является длина количество записанный символов плюс нулевой символ.
В данном случае в переменную text записывается строка «Name: %s Age: %d\n» , в которую вместо спецификаторов подставляются значения переменных name и age .
Функция scanf
Функция scanf() представляет собой процедуру ввода общего назначения, которая читает поток stdin и сохраняет информацию в переменных, перечисленных в списке аргументов. Она может читать все встроенные типы данных и автоматически преобразовывать их в соответствующий внутренний формат.
В версии C99 к параметру format применен квалификатор restrict .
- спецификаторов формата;
- пробельных символов;
- символов, отличных от пробельных.
Спецификации формата начинаются знаком % и сообщают функции scanf() тип данного, которое будет прочитано. Спецификации формата приведены в таблице 13.3. Например, по спецификации %s будет прочитана строка, а по спецификации %d — целое значение. Строка форматирования читается слева направо, и спецификации формата сопоставляются аргументам в порядке их перечисления в списке аргументов.
По умолчанию спецификации a , f , e и g заставляют функцию scanf() присваивать данные переменным типа float . Если перед одной из этих спецификаций поставить модификатор l , функция scanf() присвоит прочитанные данные переменной типа double . Использование же модификатора L означает, что полученное значение присвоится переменной типа long double .
Современные компиляторы, поддерживающие добавленные в 1995 году средства работы с двухбайтовыми символами, позволяют к спецификации c применить модификатор l ; тогда будет считаться, что соответствующий указатель указывает на двухбайтовый символ (т.е. на данное типа whcar_t ). Модификатор l также можно использовать с кодом формата s ; тогда будет считаться, что соответствующий указатель указывает на строку двухбайтовых символов. Кроме того, модификатор l можно использовать для того, чтобы указать, что набор сканируемых символов состоит из двухбайтовых символов.
Если в строке форматирования встретится разделитель, то функция scanf() пропустит один или несколько разделителей во входном потоке. Под разделителем, или пробельным символом, подразумевается пробел, символ табуляции или разделитель строк (символ новой строки). По сути, наличие одного разделителя в управляющей строке приведет к тому, что функция scanf() будет читать, не сохраняя, любое количество (возможно, даже нулевое) разделителей до первого символа, отличного от разделителя.
Если в строке форматирования встретился символ, отличный от разделителя, то функция scanf() прочитает и отбросит его. Например, если в строке форматирования встретится %d , %d , то функция scanf() сначала прочитает целое значение, затем прочитает и отбросит запятую и, наконец, прочитает еще одно целое. Если заданный символ не найден, функция scanf() завершает работу.
Все переменные, получающие значения с помощью функции scanf() , должны передаваться посредством своих адресов. Это значит, что все аргументы должны быть указателями на переменные.
Элементы входного потока должны быть разделены пробелами, символами табуляции или разделителями строк. Такие символы, как запятая, точка с запятой и т.п., не распознаются в качестве разделителей. Это означает, что оператор примет значения, введенные как 10 20 , но откажется от последовательности символов 10, 20 .
Символ * , стоящий после знака % и перед кодом формата, прочитает данные заданного типа, но запретит их присваивание. Следовательно, оператор при вводе данных в виде 10/20 поместит значение 10 в переменную x , отбросит знак деления и присвоит значение 20 переменной у .
Команды форматирования могут содержать модификатор максимальной длины поля. Он представляет собой целое число, располагаемое между знаком % и кодом формата, которое ограничивает количество читаемых для всех полей символов. Например, если в переменную address нужно прочитать не более 20 символов, используется следующий оператор.
Если входной поток содержит более 20 символов, то при последующем обращении к операции ввода чтение начнется с того места, в котором «остановился» предыдущий вызов функции scanf() . Если разделитель встретится раньше, чем достигнута максимальная длина поля, ввод данных завершится. В этом случае функция scanf() переходит к чтению следующего поля.
Хотя пробелы, символы табуляции и разделители строк используются в качестве разделителей полей, при чтении одиночного символа они читаются подобно любому другому символу. Например, если входной поток состоит из символов x у , то оператор поместит символ x в переменную а , пробел — в переменную b , а символ у — в переменную с .
Помните, что любые символы управляющей строки (включая пробелы, символы табуляции и новой строки), не являющиеся спецификациями формата, используются для установки соответствия и отбрасывания символов из входного потока. Любой соответствующий им символ отбрасывается. Например, если поток ввода выглядит, как 10t20 , оператор присвоит переменной x значение 10, а переменной у — значение 20. Символ t отбрасывается, так как он присутствует в управляющей строке.
Функция scanf() поддерживает спецификатор формата общего назначения, называемый набором сканируемых символов (scanset). В этом случае определяется набор символов, которые могут быть прочитаны функцией scanf() и присвоены соответствующему массиву символов. Для определения такого набора символы, подлежащие сканированию, необходимо заключить в квадратные скобки. Открывающая квадратная скобка должна следовать сразу за знаком процента. Например, следующий набор сканируемых символов указывает на то, что необходимо читать только символы A , B и C .
При использовании набора сканируемых символов функция scanf() продолжает читать символы и помещать их в соответствующий массив символов до тех пор, пока не встретится символ, отсутствующий в заданном наборе. Соответствующая набору переменная должна быть указателем на массив символов. При возврате из функции scanf() этот массив будет содержать строку из прочитанных символов, завершающуюся символом конца строки.
Если первый символ в наборе является знаком ^ , то получаем обратный эффект: входное поле читается до тех пор, пока не встретится символ из заданного набора сканируемых символов, т.е. знак ^ заставляет функцию scanf() читать только те символы, которые отсутствуют в наборе сканируемых символов.
Во многих реализациях допускается задавать диапазон с помощью дефиса. Например, функция scanf (), встречая набор сканируемых символов в виде %[A-z] , будет читать символы, попадающие в диапазон от А до Z.
Важно помнить, что в наборе сканируемых символов различаются прописные и строчные буквы. Следовательно, чтобы сканировать как прописные, так и строчные буквы, в наборе сканируемых символов придется задать их отдельно.
Функция scanf() возвращает число, равное количеству полей, для которых успешно присвоены значения. К этим полям не относятся поля, которые были прочитаны, но присвоение не состоялось в связи с использованием модификатора * , подавляющего присваивание. При обнаружении ошибки до присвоения значения первого поля функция scanf() возвращает значение EOF .
Модификаторы формата, добавленные к функции scanf() Стандартом C99
В версии C99 для использования в функции scanf() добавлены модификаторы формата hh , ll , j , z и t . Модификатор hh можно применять к спецификациям d , i , о , u , x и n . Он означает, что соответствующий аргумент является указателем на значение типа signed char или unsigned char . Модификатор ll также можно применять к спецификациям d , i , о , u , x и n . Он означает, что соответствующий аргумент является указателем на значение типа signed long long int или unsigned long long int .
Считывание строки с пробелами
Считывание строки с пробелами
Подскажите,пожалуйста,как считать из эдита строку с пробелами,я знаю,что через команду strcpy но у.
 Считывание строки с пробелами
Считывание строки с пробелами
Ситуация такая, необходимо с консоли прочитать строку вводимую пользователем вместе с пробелами. .
Считывание файла с пробелами.
Подскажите, пожалуйста, как при считывание текстового файла сохранить пробелы между словами. Темы.
Считывание вместе с пробелами
Столкнулся с одной проблемой при считывании из файла программа считает пробелы символами.
fflush(stdin) — пробовал и без очистки то же самое.
Добавлено через 4 минуты
Пробовал
Считывание из файла с пробелами
Здравствуйте. Нужно считать из файла сообщение, в котором заранее известны что будут пробелы.
Считывание нескольких строк с пробелами
итак, есть код ввода списка учеников и вывода имени по номеру. #include <iostream> using.
Считывание нескольких строк с пробелами
Я знаю, что есть функция getline. Но если мне в коде надо считать несколько разных строк с.
Считывание из файла вместе с пробелами
Здравствуйте, у меня есть проблема. Я работаю над проектом и мне нужно считать информацию из файла.
Как получить от пользователя строку с пробелами
Ввод строки в консольном приложении для пользователя не представляет особых сложностей — он просто печатает необходимое количество знаков и нажимает ENTER.
А вот для начинающего программиста на С++ всё может оказаться не так просто и привести к потере времени и сил на решение простой задачи. Зачем эта заморочка существует в С++, лично мне вообще непонятно. Но она существует. И заключается она в следующем.
Строка с пробелами не читается
Точнее, не читается она привычным для С++ способом. Например, если у вас есть переменная str , то вы можете попытаться прочитать в эту переменную строку, введённую пользователем:
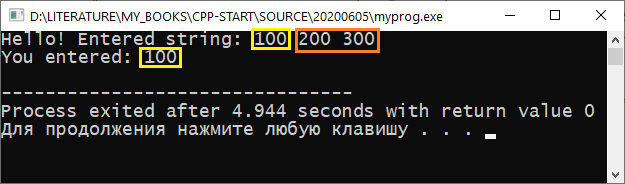
И всё будет прекрасно работать, если пользователь введёт строку БЕЗ пробелов. Однако вас ждёт неприятность, если во вводимой строке будут пробелы. Например, если пользователь введёт:
100 200 300
то в переменной str после выполнения инструкции cin >> str; будет только 100 . То есть строка будет прочитана ТОЛЬКО до первого пробела.
ЛИРИЧЕСКОЕ ОТСТУПЛЕНИЕ
Вот за это я и не люблю С++. Ну зачем, спрашивается, так было делать?
Но отбросим лирику в сторону, и разберёмся, что же нам в этом случае делать?
А надо просто использовать другой способ. Например, такой:
В этом случае всё будет работать как надо:
Однако если вы думаете, что на этом ваши неприятности закончились, то зря. Это же С++. А не какой-нибудь Паскаль для лохов. У меня вообще иногда возникает подозрение, что создатель С++ преследовал цель не придумать мощный язык, а сделать так, чтобы программировать на нём могли только избранные. Иначе нафига в этом языке столько заморочек?
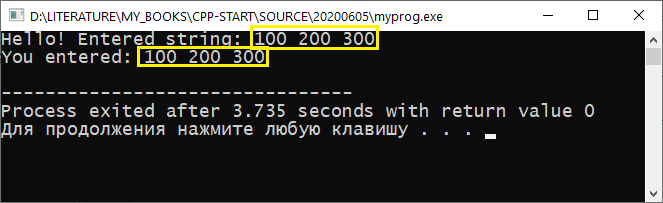
Итак, вот вам следующий нежданчик:
Здесь мы используем getline() , которая может читать целую строку (в том числе и с пробелами). Но, как вы думаете, сможем ли мы прочитать эту строку в этой программе?
Наверняка вы уже почувствовали подвох. И заключается он в том, что в этой программе вы не сможете прочитать строку str .
Но что же произойдёт? А то, что в переменную str запишется недочитанный буфер ввода, то есть строка » 200 300″ , и мы не сможем ввести новую строку.
Почему так? Потому что первый раз строка была прочитана не полностью, а только до первого пробела. Оставшиеся же символы остались в буфере, и новая строка не может быть введена, пока буфер полностью не прочитан.
Поэтому перед тем, как вводить новую строку, нам надо либо прочитать буфер до конца, либо очистить его.
Пробежаться до конца буфера можно, например, так:
Очистить буфер ввода cin можно, например, так:
то есть программа может быть примерно такой:
Ну что же, теперь, надеюсь, вы представляете, как пользователю ввести строку с пробелами в С++, и эта задачка не поставит вас в тупик.
Как ввести строку с пробелами через cin
Строку с пробелами можно ввести и привычным способом через cin , но для этого потребуется несколько переменных:
В этом случае вывод будет таким:
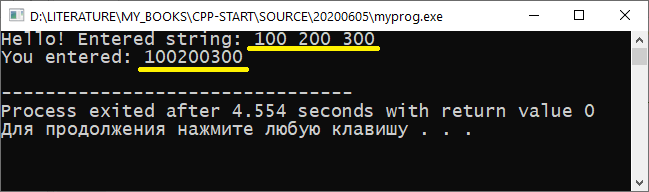
Как видите, так тоже можно. Правда пробелы при этом способе из введённой пользователем строки исключаются. Кроме того, не всегда удобно использовать несколько переменных для ввода. К тому же пользователю надо как-то знать, сколько пробелов допускается в строке. Ну или сильно усложнять код для обработки ввода.
На этом пока всё. Изучайте С++. Конечно, это далеко не самый простой язык. Но, с другой стороны, его изучение доставит вам много радости от неожиданных открытий, которых вы никогда не найдёте в более простых языках.
Так что я, например, использую Паскаль для работы (когда требуется сделать быстро и без лишних заморочек), а С++ для удовольствия, когда хочется немного помучиться, а результат и сроки не висят над тобой как Дамоклов меч…