§ 3.8. Деревья, лес
Определение 3.8.1. Неориентированным деревом (или просто деревом) называется связный граф без циклов. Дерево есть связный граф, содержащий n вершин и n – 1 ребер, дерево есть граф, любые две вершины которого можно соединить простой цепью.
Пример. Графы, изображенные на рис 21, являются деревьями.
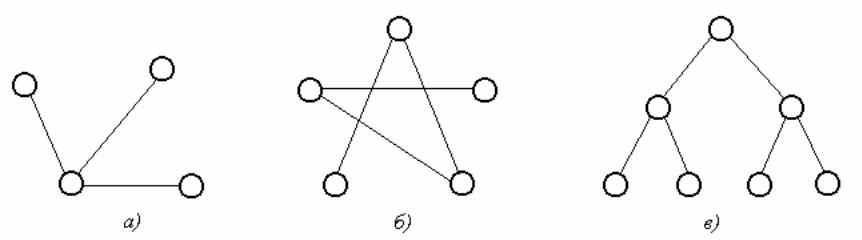 рис.21
рис.21
Если граф несвязный и не имеет циклов, то каждая его связная компонента будет деревом. Такой граф называется лесом. Можно интерпретировать рис.21 как лес, состоящий из трех деревьев.
Определение 3.8.2. Остовным деревом связного графа G называется любой его подграф, содержащий все вершины графа G и являющийся деревом.
Пример. Для графа, изображенного на рис. 22 а), графы на рис. б и в являются остовными деревьями.
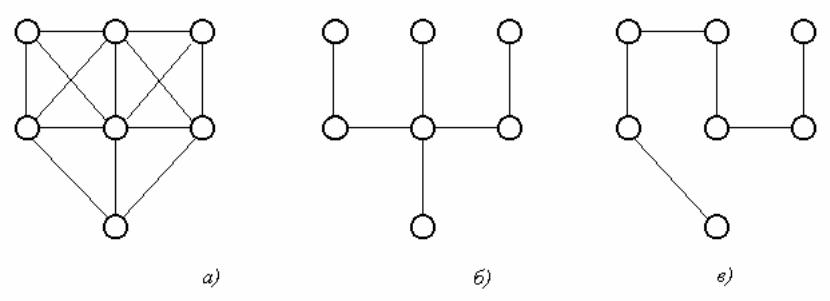 рис.22
рис.22
Определение 3.8.3. Ориентированным деревом называют граф, в котором в каждую вершину, кроме одной, называемой корнем дерева, заходит ровно одна дуга. В корень дерева ни одна дуга не заходит. Вершины, из которых не выходит ни одна дуга, называются листьями (рис.23).
 рис.23
рис.23
§ 3.9. Взвешенные графы
Определение 3.9.1. Взвешенный граф – это граф дугам, которого поставлены в соответствие веса, так что дуге (xi, xj) сопоставлено некоторое число c (xi, xj) = cij, называемое длиной (или весом, или стоимостью) дуги. Обычный (не взвешенный) граф можно интерпретировать как взвешенный, все ребра которого имеют одинаковый вес 1.
Определение 3.9.2. Длина пути во взвешенном графе — это сумма длин (весов) тех ребер, из которых состоит путь.
Определение 3.9.3. Расстояние между вершинами – это длина кратчайшего пути. Например, расстояние от вершины a до вершины d во взвешенном графе, изображенном на рис. 24, равно 6.
 рис.24
рис.24
Примеры взвешенных графов
Вес вершины
Вес ребра (дуги)
Наличие наземной границы
Стоимость получения визы
Наличие общей границы
§ 3.10. Эйлеровы и гамильтоновы графы
Определение 3.10.1. Если граф имеет цикл (не обязательно простой), содержащий все ребра графа по одному разу, то такой цикл называется эйлеровым циклом, а граф называется эйлеровым графом.
Определение 3.10.2. Если граф имеет цепь (не обязательно простую), содержащую все вершины по одному разу, то такая цепь называется эйлеровой цепью, а граф называется полуэйлеровым графом.
Эти понятия возникли в статье Эйлера в 1735 г., в которой он решал задачу о Кенигсбергских мостах и впервые ввел понятие графа. На рис.25, а приведен план расположения семи мостов в Кенигсберге (ныне Калининграде). Задача состоит в том, чтобы пройти каждый мост по одному разу и вернуться в исходную точку С. Поскольку в конце обхода нужно вернуться в исходную часть города, и на каждом мосту нужно побывать по одному разу, этот маршрут является простым циклом, содержащим все ребра графа. В дальнейшем такие циклы и стали называть эйлеровыми, а графы, имеющие эйлеров цикл – эйлеровыми графами.
Эйлеров цикл можно считать следом пера, вычерчивающего этот граф, не отрываясь от бумаги. Таким образом, эйлеровы графы – это графы, которые можно изобразить одним росчерком пера, причем процесс такого изображения начинается и заканчивается в одной и той же точке.
Обнаружив, что в данном графе не существует циклических обходов, проходящих по всем ребрам по одному разу, Эйлер обратился к общей задаче: при каких условиях в графе можно найти такой цикл? Ответ на этот вопрос дает следующая теорема.
Теорема Эйлера. Чтобы в связанном неориентированном графе G существовал эйлеров цикл, необходимо и достаточно, чтобы число вершин нечетной степени было четным.
Определение 3.10.3. Гамильтоновой цепью графа называется его простая цепь, которая проходит через каждую вершину графа точно один раз.
Определение 3.10.4. Цикл графа, проходящий через каждую его вершину, называется гамильтоновым циклом.
Определение 3.10.5. Граф называется гамильтоновым, если он обладает гамильтоновым циклом.
Гамильтоновы графы применяются для моделирования многих практических задач, например, служат моделью при составлении расписания движения поездов. Основой всех таких задач служит классическая задача коммивояжера: коммивояжер должен совершить поездку по городам и вернуться обратно, побывав в каждом городе ровно один раз, сведя при этом затраты на передвижения к минимуму.
Графическая модель задачи коммивояжера состоит из гамильтонова графа, вершины которого изображают города, а ребра — связывающие их дороги. Кроме того, каждое ребро оснащено весом, обозначающим транспортные затраты, необходимые для путешествия по соответствующей дороге, такие, как, например, расстояние между городами или время движения по дороге. Для решения задачи необходимо найти гамильтонов цикл минимального общего веса.
Теорема Кёнига. В полном конечном графе всегда существует гамильтонов путь.
Если в графе G(X) с n вершинами для любой пары вершин xi и xj справедливо неравенство
где m(хi), m(xj) – степени вершин хi и xj, то граф G(X) имеет гамильтонову цепь.
Несмотря на сходство в определении эйлерова и гамильтонового циклов, соответствующие теории для этих понятий имеют мало общего. Критерий существования для эйлеровых циклов был установлен просто, для гамильтоновых циклов никакого общего правила неизвестно. Более того, иногда даже для конкретных графов бывает трудно решить, можно ли найти такой цикл. В принципе, поскольку речь идет о конечном числе вершин, задачу можно решить перебором, однако эффективного алгоритма неизвестно.
Деревья — Теория графов
В этом уроке мы изучим еще один вид графов — древовидные. Именно этот вид графов активно используется в программировании — он связан с алгоритмами сортировки и поиска.
Деревья
Деревья — это связные графы без циклов. Их часто применяют в математике и информатике. Вот так они выглядят:
Как видно из примера, у деревьев определенная древовидная ветвистость, откуда они и получили свое название.
Благодаря связности и отсутствию циклов у деревьев есть ряд свойств:
В любом дереве есть ровно один путь из каждой вершины в каждую другую. Например, если есть два пути к вершине, то их можно объединить, чтобы получить цикл
У деревьев наименьшее количество ребер, которое только может быть у графа. При этом они остаются связными. Каждое ребро дерева — режущее, значит, не лежит в цикле
У деревьев наибольшее число ребер, которое может быть у графа без циклов. Добавление любого ребра к дереву создает ровно один цикл. Например, если добавить ребро между вершинами
Все что нужно знать о древовидных структурах данных
![]()
Когда вы впервые учитесь кодировать, общепринято изучать массивы в качестве «основной структуры данных».
В конце концов, вы также изучаете хэш-таблицы. Для получения степени по «Компьютерным наукам» (Computer Science) вам придется походить на занятия по структурам данных, на которых вы узнаете о связанных списках, очередях и стеках. Эти структуры данных называются «линейными», поскольку они имеют логические начало и завершение.
Однако в самом начале изучения деревьев и графов мы можем оказаться слегка сбитыми с толку. Нам привычно хранить данные линейным способом, а эти две структуры хранят данные совершенно иначе.
Данная статья поможет вам лучше понять древовидные структуры данных и устранить все недоразумения на их счет.
Из этой статьи вы узнаете:
- Что такое деревья?
- Разберете примеры деревьев.
- Узнаете терминологию и разберете алгоритмы работы с этими структурами.
- Узнаете как реализовать древовидные структуры в программном коде.
Давайте начнем наше учебное путешествие 🙂
Определения
Когда вы только начинаете изучать программирование, обычно бывает проще понять, как строятся линейные структуры данных, чем более сложные структуры, такие как деревья и графы.
Деревья являются широко известными нелинейными структурами. Они хранят данные не линейным способом, а упорядочивают их иерархически.
Давайте вплотную займемся реальными примерами
Что я имею в виду, когда я говорю иерархически?
Представьте себе генеалогическое древо отношений между поколениями: бабушки и дедушки, родители, дети, братья и сестры и т.д. Мы обычно организуем семейные деревья иерархически.
Мое фамильное дерево
Приведенный рисунок — это мое фамильное древо. Тосико, Акикадзу, Хитоми и Такеми — мои дедушки и бабушки.
Тошиаки и Джулиана — мои родители.
ТК, Юдзи, Бруно и Кайо — дети моих родителей (я и мои братья).
Структура организации — еще один пример иерархии.
Структура компании является примером иерархии
В HTML, объектная модель документа (DOM) представляется в виде дерева.
Объектная модель документа (DOM)
HTML-тег содержит другие теги. У нас есть тег заголовка и тег тела. Эти теги содержат определенные элементы. Заголовок имеет мета теги и теги заголовка. Тег тела имеет элементы, которые отображаются в пользовательском интерфейсе, например, h1 , a , li и т.д.
Техническое определение
Дерево представляет собой набор объектов, называемых узлами. Узлы соединены ребрами. Каждый узел содержит значение или данные, и он может иметь или не иметь дочерний узел.
Первый узел дерева называется корнем. Если этот корневой узел соединен с другим узлом, тогда корень является родительским узлом, а связанный с ним узел — дочерним.
Все узлы дерева соединены линиями, называемыми ребрами. Это важная часть деревьев, потому что она управляет связью между узлами.
Листья — это последние узлы на дереве. Это узлы без потомков. Как и в реальных деревьях, здесь имеется корень, ветви и, наконец, листья.
Другими важными понятиями являются высота и глубина.
Высота дерева — это длина самого длинного пути к листу.
Глубина узла — это длина пути к его корню.
Справочник терминов
- Корень — самый верхний узел дерева.
- Ребро — связь между двумя узлами.
- Потомок — узел, имеющий родительский узел.
- Родитель — узел, имеющий ребро, соединяющее его с узлом-потомком.
- Лист — узел, не имеющий узлов-потомков на дереве.
- Высота — это длина самого дальнего пути к листу.
- Глубина — длина пути к корню.
Бинарные деревья
Теперь рассмотрим особый тип деревьев, называемых бинарными или двоичными деревьями.
“В информатике бинарным (двоичным) деревом называется иерархическая структура данных, в которой каждый узел имеет не более двух потомков (детей). Как правило, первый называется родительским узлом, а дети называются левым и правым наследниками.” — Wikipedia
Рассмотрим пример бинарного дерева.
Давайте закодируем бинарное дерево
Первое, что нам нужно иметь в виду, когда мы реализуем двоичное дерево, состоит в том, что это набор узлов. Каждый узел имеет три атрибута: value , left_child , и right_child.
Как мы реализуем простое двоичное дерево, которое инициализирует эти три свойства?
Вот наш двоичный класс дерева.
Когда мы создаем экземпляр объекта, мы передаем значение (данные узла) в качестве параметра. Посмотрите на left_child , и right_child . Оба имеют значение None .
Когда мы создаем наш узел, он не имеет потомков. Просто есть данные узла.
Давайте это проверим:
Это выглядит так.
Мы можем передать строку ‘ a ’ в качестве значения нашему узлу бинарного дерева. Если мы напечатаем значение, left_child и right_child , мы увидим значения.
Перейдем к части вставки. Что нам нужно здесь сделать?
Мы реализуем метод вставки нового узла справа и слева.
- Если у текущего узла нет левого дочернего элемента, мы просто создаем новый узел и устанавливаем его в left_child текущего узла.
- Если у него есть левый дочерний потомок, мы создаем новый узел и помещаем его вместо текущего левого потомка. Назначьте этот левый дочерний узел новым левым дочерним новым узлом.
Давайте это нарисуем 🙂
Вот программный код:
Еще раз, если текущий узел не имеет левого дочернего элемента, мы просто создаем новый узел и устанавливаем его в качестве left_child текущего узла. Или мы создаем новый узел и помещаем его вместо текущего левого потомка. Назначим этот левый дочерний узел в качестве левого дочернего элемента нового узла.
И мы делаем то же самое, чтобы вставить правый дочерний узел.
Но не полностью. Осталось протестировать.
Давайте построим следующее дерево:
Подытоживая изображенное дерево, заметим:
- узел a будет корнем нашего бинарного дерева
- левым потомком a является узел b
- правым потомком a является узел c
- правым потомком b является узел d (узел b не имеет левого потомка)
- левым потомком c является узел e
- правым потомком c является узел f
- оба узла e и f не имеют потомков
Таким образом, вот код для нашего дерева следующий:
Теперь нам нужно подумать об обходе дерева.
У нас есть два варианта: поиск в глубину (DFS) и поиск по ширине (BFS).
• Поиск в глубину (Depth-first search, DFS) — один из методов обхода дерева. Стратегия поиска в глубину, как и следует из названия, состоит в том, чтобы идти «вглубь» дерева, насколько это возможно. Алгоритм поиска описывается рекурсивно: перебираем все исходящие из рассматриваемой вершины рёбра. Если ребро ведёт в вершину, которая не была рассмотрена ранее, то запускаем алгоритм от этой нерассмотренной вершины, а после возвращаемся и продолжаем перебирать рёбра. Возврат происходит в том случае, если в рассматриваемой вершине не осталось рёбер, которые ведут в не рассмотренную вершину. Если после завершения алгоритма не все вершины были рассмотрены, то необходимо запустить алгоритм от одной из не рассмотренных вершин.
• Поиск в ширину (breadth-first search, BFS) — метод обхода дерева и поиска пути. Поиск в ширину является одним из неинформированных алгоритмов поиска. Поиск в ширину работает путём последовательного просмотра отдельных уровней дерева, начиная с узла-источника. Рассмотрим все рёбра, выходящие из узла. Если очередной узел является целевым узлом, то поиск завершается; в противном случае узел добавляется в очередь. После того, как будут проверены все рёбра, выходящие из узла, из очереди извлекается следующий узел, и процесс повторяется.
Давайте подробно рассмотрим каждый из алгоритмов обхода.
Поиск в глубину (DFS)
DFS исследует все возможные пути вплоть до некоторого листа дерева, возвращается и исследует другой путь (осуществляя, таким образом, поиск с возвратом). Давайте посмотрим на пример с этим типом обхода.
Результатом этого алгоритма будет: 1–2–3–4–5–6–7.
Давайте разъясним это подробно.
- Начать с корня (1). Записать.
- Перейти к левому потомку (2). Записать.
- Затем перейти к левому потомку (3). Записать. (Этот узел не имеет потомков)
- Возврат и переход к правому потомку (4). Записать. (Этот узел не имеет потомков)
- Возврат к корневому узлу и переход к правому потомку (5). Записать.
- Переход к левому потомку (6). Записать. (Этот узел не имеет никаких потоков)
- Возврат и переход к правому потомку (7). Записать. (Этот узел не имеет никаких потомков)
- Выполнено.
Проход в глубь дерева, а затем возврат к исходной точке называется алгоритмом DFS.
После знакомства с этим алгоритмом обхода, рассмотрим различные типы DFS-алгоритма: предварительный обход (pre-order), симметричный обход (in-order) и обход в обратном порядке (post-order).
Предварительный обход
Именно это мы и делали в вышеприведенном примере.
1. Записать значение узла.
2. Перейти к левому потомку и записать его. Это выполняется тогда и только тогда, когда имеется левый потомок.
3. Перейти к правому потомку и записать его. Это выполняется тогда и только тогда, когда имеется правый потомок.
Симметричный обход
Результатом алгоритма симметричного обхода для этого дерева tree в примере является 3–2–4–1–6–5–7.
Первый левый, средний второй и правый последний.
Теперь давайте напишем код.
- Перейти к левому потомку и записать. Это выполняется тогда и только тогда, когда имеется левый потомок.
- Записать значение узла.
- Перейти к правому потомку и записать. Это выполняется тогда и только тогда, когда имеется правый потомок.
Обход в обратном порядке
Результатом алгоритма прохода в обратном порядке для этого примера дерева является 3–4–2–6–7–5–1.
Первое левое, правое второе и последнее посередине.
Давайте напишем для него код.
- Перейти к левому потомку и записать. Это выполняется тогда и только тогда, когда имеется левый потомок.
- Перейти к правому потомку и записать. Это выполняется тогда и только тогда, когда имеется правый потомок.
- Записать значение узла.
Поиск в ширину (BFS)
BFS алгоритм обходит дерево tree уровень за уровнем вглубь дерева.
Вот пример, помогающий лучше объяснить этот алгоритм:
Таким образом мы обходим дерево уровень за уровнем. В этом примере результатом является 1–2–5–3–4–6–7.
- Уровень/Глубина 0: только узел со значением 1.
- Уровень/Глубина 1: узлы со значениями 2 и 5.
- Уровень/Глубина 2: узлы со значениями 3, 4, 6, и 7.
Теперь давайте напишем код.
Для реализации BFS-алгоритма мы используем данные структуры “очередь”.
Как это работает?
Вот пошаговое объяснение.
- Сначала добавить root узел внутрь очереди с помощью метода put .
- Повторять до тех пор пока очередь не пуста.
- Получить первый узел в очереди, а затем записать ее значение.
- Добавить и левый и правый потомок в очередь (если текущий узел имеет потомка).
- Выполнено. Мы будет записывать значение каждого узла, уровень за уровнем с помощью нашей очереди.
Бинарное дерево поиска
“Бинарное (двоичное) дерево поиска иногда называют упорядоченными бинарными деревьями, оно хранит значения упорядоченно, таким образом поиск и другие операции могут строится на принципах бинарного поиска ” — Wikipedia
Важным свойством поиска на двоичном дереве является то, что величина узла Binary Search Tree больше, чем количество его потомков левого элемента-потомка, но меньшее, чем количество его потомков правого элемента-потомка.
Вот детальный разбор приведенной выше иллюстрации.
- A инвертировано. Поддерево subtree 7–5–8–6 должно быть с правой стороны, а поддерево subtree 2–1–3 должно быть слева.
- B является единственной корректной опцией. Оно удовлетворяет свойству Binary Search Tree .
- C имеет одну проблему: узел со значением 4. Он должен быть слева от root потому что меньше 5.
Давайте напишем код для поиска на бинарном дереве!
Наступило время писать код!
Что вы увидите? Мы вставим новые узлы, поищем значения, удалим узлы и сбалансируем дерево.
Вставка: добавление новых узлов на наше дерево
Представьте, что у нас есть пустое дерево, и мы хотим добавить новые узлы со следующими значениями в следующем порядке: 50, 76, 21, 4, 32, 100, 64, 52.
Первое, что нам нужно знать, это то, что 50 является корнем нашего дерева.
Теперь мы можем начать вставлять узел за узлом.
- 76 больше чем 50, поэтому вставим 76 справа.
- 21 меньше чем 50, поэтому вставим 21 слева.
- 4 меньше чем 50. Узел со значением 50 имеет левого потомка 21. Поскольку 4 меньше чем 21, вставим его слева от этого узла.
- 32 меньше чем 50. Узел со значением 50 имеет левого потомка 21. Поскольку 32 больше чем 21, вставим 32 справа от этого узла.
- 100 больше чем 50. Узел со значением 50 имеет правого потомка 76. Поскольку 100 больше чем 76, вставим 100 справа от этого узла node.
- 64 больше чем 50. Узел со значением 50 имеет правого потомка 76. Поскольку 64 меньше чем 76, вставим 64 слева от этого узла.
- 52 больше чем 50. Узел со значением 50 имеет правого потомка 76. Поскольку 52 меньше чем 76, узел со значением 76 имеет левого потомка 64. 52 меньше чем 64, поэтому вставим 54 слева от этого узла.
Вы заметили, что здесь присутствует некоторая структура (патттерн)?
Давайте рассмотрим еще раз более подробно.
- В новом узле значение больше или меньше чем значение текущего узла?
- Если значение нового узла больше чем значение текущего узла, следует перейти на правое поддерево. Если текущий узел не имеет потомка справа, вставить его справа, или в ином случае вернуться к шагу 1.
- Если значение нового узла меньше текущего узла — перейти на левое поддерево. Если текущий узел не имеет левого потомка, вставить его слева, или в ином случае вернуться к шагу 1.
- Мы не рассматривали здесь обработку особых ситуаций. Когда значение нового узла равно значению текущего узла, используется правило 3. Рассмотрим вставку равных значений слева в поддерево.
Давайте напишем код.
Вроде бы все просто.
Большой частью этого алгоритма выступает рекурсия, которая находится в строке 9 и строке 13. Обе строки кода вызывают метод insert_node и используют его для своих левых и правых потомков соответственно.
Строки 11 и 15 осуществляют делают вставку для каждого потомка.
Давайте найдем значение узла … Или не найдем …
Теперь алгоритм, который мы будем строить — алгоритм поиска. Для данного значения (целое число), мы скажем, имеет ли наше дерево двоичного поиска или нет это значение.
Важно отметить, что мы определили алгоритм вставки. Сначала у нас есть наш корневой узел. Все левые узлы поддеревьев будут иметь меньшие значения, чем корневой узел. И все правильные узлы поддерева будут иметь значения, превышающие корневой узел.
Давайте рассмотрим пример.
Представьте, что у нас имеется это дерево.
Теперь мы хотим узнать есть ли у нас узел со значением 52.
Давайте рассмотрим подробнее.
- Начинаем с корневого узла в качестве текущего. Является ли данная величина меньше текущей величины узла? Если да, будем искать ее на поддереве слева.
- Данное значение больше текущего значения для узла? Если да, будем искать ее справа на поддереве.
- Если правила №1 и №2 оба неверны, можем сравнить значение текущего узла и заданного узла на равенство. Если результат сравнения выдает значение true , можем сказать, «Да!» Наше дерево имеет заданное значение, иначе сказать – нет, оно не имеет.
Давайте напишем код.
Разберем код подробнее:
- Строки 8 и 9 попадают под правило №1.
- Строки 10 и 11 попадают под правило №2.
- Строки 13 попадают под правило №3.
Как нам это проверить?
Давайте создадим наше Binary Search Tree путем инициализации корневого узла значением 15.
А теперь мы вставим много новых узлов.
Для каждого вставленного узла мы проверим работает ли наш метод find_node .
Да, он работает для этих заданных значений! Давайте проверим для значения, отсутствующего в нашем бинарном дереве поиска.
Стирание: удаление и организация
Удаление — более сложный алгоритм, потому что нам нужно обрабатывать разные случаи. Для заданного значения нам нужно удалить узел с этим значением. Представьте себе следующие сценарии для данного узла: у него нет потомков, есть один потомок или есть два потомка.
- Сценарий №1: узел без потомков (листовой узел).
Если узел, который мы хотим удалить, не имеет дочерних элементов, мы просто удалим его. Алгоритм не требует реорганизации дерева.
- Сценарий №2: узел с одним потомком (левый или правый потомок).
В этом случае наш алгоритм должен заставить родительский узел указывать на узел-потомок. Если узел является левым дочерним элементом, мы делаем родительский элемент левого дочернего элемента дочерним. Если узел является правым дочерним по отношению к его родительскому, мы делаем родительский элемент правого дочернего дочерним.
- Сценарий №3: узел с двумя потомками.
Когда узел имеет 2 потомка, нужно найти узел с минимальным значением, начиная с дочернего узла. Мы поставим этот узел с минимальным значением на место узла, который мы хотим удалить.
Пришло время записать код.
- Во-первых: Обратите внимание на значение параметров и родительский. Мы хотим найти узел, который имеет это значение, а родительский узел имеет важное значение для удаления узла.
- Во-вторых: Обратите внимание на возвращаемое значение. Наш алгоритм вернет логическое значение. Он возвращает True, если находит узел и удаляет его. В противном случае он вернет False
- От строки 2 до строки 9: Мы начинаем искать узел, который имеет искомое значение. Если значение меньше текущего значения узла, мы переходим к левому поддереву, рекурсивно (если и только если текущий узел имеет левый дочерний элемент). Если значение больше ‑ перейти в правое поддерево, повторить.
- Строка 10: Начинаем продумывать алгоритм удаления.
- От строки 11 до строки 13: Мы покрываем узел без потомков, и это левый потомок его родителя. Мы удаляем узел, устанавливая левый дочерний элемент родителя в None .
- Строки 14 и 15: Мы покрываем узел без потомков, и это правый потомок его родителя. Мы удаляем узел, установив правый дочерний элемент родителя в None .
- Очистить метод узла: я покажу код clear_node ниже. Он устанавливает дочерние элементы слева, правый дочерний элемент и его значение в None .
- От строки 16 до строки 18: мы покрываем узел только одним потомком (левым дочерним), и это левый потомок его родителя. Мы заменяем левый дочерний элемент родителя на левый дочерний элемент узла (единственный его дочерний элемент).
- От строки 19 до строки 21: мы покрываем узел только одним потомком (левым дочерним), и это правый потомок его родителя. Мы устанавливаем правый дочерний элемент родителя в левый дочерний элемент узла (единственный его дочерний элемент).
- От строки 22 до строки 24: мы покрываем узел только одним потомком (правый ребенок), и это левый дочерний элемент его родителя. Мы устанавливаем левый дочерний элемент родителя правым дочерним элементом узла (единственный его дочерний элемент).
- От строки 25 до строки 27: Мы покрываем узел только одним дочерним элементом (правый дочерний элемент), и это правый потомок его родителя. Устанавливаем правый дочерний элемент родителя правым дочерним элементом узла (единственный его дочерний элемент).
- От строки 28 до строки 30: Мы покрываем узел как левыми, так и правыми потомками. Получаем узел с наименьшим значением (код показан ниже) и устанавливаем его на значение текущего узла. Завершите действия, удалив наименьший узел.
- Строка 32: если мы найдем узел, который ищем, ему нужно снова присвоить True . Код между строками 11 и 31 мы используем именно для этого случая. Так что просто верните значение True , этого будет достаточно.
- Чтобы использовать метод clear_node : установите значение None для всех трех атрибутов — (значения left_child и right_child )
- Чтобы использовать метод find_minimum_value : перейдите влево. Если мы больше не найдем узлов, мы найдем самый маленький.
Теперь давайте проверим.
Будем использовать это дерево для проверки нашего алгоритма remove_node .
Удалим узел со значением 8. Это узел без дочернего элемента.
Теперь давайте удалим узел со значением 17. Это узел с одним потомком.
Наконец, мы удалим узел с двумя потомками. Это корень нашего дерева.
Проверки успешно выполнены 🙂
Пока это все!
Мы с вами уже очень многое изучили.
Поздравляем с завершением чтения и разбора нашей насыщенной информацией и практикой статьи. Всегда довольно сложно понять новую, неизвестную еще концепцию. Но вы читатель, преодолели все трудности 🙂
Это еще один шаг в моем обзоре алгоритмов и моделировании и структур данных. Вы можете найти более полные сведения о моем обзоре в издании Renaissance Developer.
Дерево (структура данных)
Дерево — одна из наиболее широко распространённых структур данных в информатике, эмулирующая древовидную структуру в виде набора связанных узлов. Является связанным графом, не содержащим циклы. Большинство источников также добавляют условие на то, что рёбра графа не должны быть ориентированными. В дополнение к этим трём ограничениям, в некоторых источниках указываются, что рёбра графа не должны быть взвешенными.
Содержание
Определения
- Корневой узел — самый верхний узел дерева.
- Корень — одна из вершин, по желанию наблюдателя.
- лист, листовой или терминальныйузел — узел, не имеющий дочерних элементов.
- Внутренний узел — любой узел дерева, имеющий потомков, и таким образом, не являющийся листовым узлом.
Дерево считается ориентированным, если в корень не заходит ни одно ребро.
- Полный сцепленный ключ — идентификатор записи, который образуется путём конкатенации всех ключей экземпляров родительских записей (групп).
Узел является экземпляром одного из двух типов элементов графа, соответствующим объекту некоторой фиксированной природы. Узел может содержать значение, состояние или представление отдельной информационной структуры или самого дерева. Каждый узел дерева имеет ноль или более узлов-потомков, которые располагаются ниже по дереву (по соглашению, деревья ‘растут’ вниз, а не вверх, как это происходит с настоящими деревьями). Узел, имеющий потомка, называется узлом-родителем относительно своего потомка (или узлом-предшественником, или старшим). Каждый узел имеет не больше одного предка. Высота узла — это максимальная длина нисходящего пути от этого узла к самому нижнему узлу (краевому узлу), называемому листом. Высота корневого узла равна высоте всего дерева. Глубина вложенности узла равна длине пути до корневого узла.
Корневые узлы
Самый верхний узел дерева называется корневым узлом. Быть самым верхним узлом подразумевает отсутствие у корневого узла предков. Это узел, на котором начинается выполнение большинства операций над деревом (хотя некоторые алгоритмы начинают выполнение с «листов» и выполняются, пока не достигнут корня). Все прочие узлы могут быть достигнуты путём перехода от корневого узла по рёбрам (или ссылкам). (Согласно формальному определению, каждый подобный путь должен быть уникальным). В диаграммах он обычно изображается на самой вершине. В некоторых деревьях, например, кучах, корневой узел обладает особыми свойствами. Каждый узел дерева можно рассматривать как корневой узел поддерева, «растущего» из этого узла.
Поддеревья
Поддерево — часть древообразной структуры данных, которая может быть представлена в виде отдельного дерева. Любой узел дерева T вместе со всеми его узлами-потомками является поддеревом дерева T. Для любого узла поддерева либо должен быть путь в корневой узел этого поддерева, либо сам узел должен являться корневым. То есть поддерево связано с корневым узлом целым деревом, а отношения поддерева со всеми прочими узлами определяются через понятие соответствующее поддерево (по аналогии с термином «соответствующее подмножество»).
Упорядочивание деревьев
Существует два основных типа деревьев. В рекурсивном дереве или неупорядоченном дереве имеет значение лишь структура самого дерева без учёта порядка потомков для каждого узла. Дерево, в котором задан порядок (например, каждому ребру, ведущему к потомку, присвоены различные натуральные числа) называется деревом с именованными рёбрами или упорядоченным деревом со структурой данных, заданной перед именованием и называемой структурой данных упорядоченного дерева.
Упорядоченные деревья являются наиболее распространёнными среди древовидных структур. Двоичное дерево поиска — одно из разновидностей упорядоченного дерева.
Представление деревьев
Существует множество различных способов представления деревьев. Наиболее общий способ представления изображает узлы как записи, расположенные в динамически выделяемой памяти с указателями на своих потомков, предков (или и тех и других), или как элементы массива, связанные между собой отношениями, определёнными их позициями в массиве (например, двоичная куча).
Деревья как графы
В теории графов дерево — связанный ациклический граф. Корневое дерево — это граф с вершиной, выделенной в качестве корневой. В этом случае любые две вершины, связанные ребром, наследуют отношения «родитель-потомок». Ациклический граф со множеством связанных компонентов или набор корневых деревьев иногда называется лесом.
Методы обхода
Пошаговый перебор элементов дерева по связям между узлами-предками и узлами-потомками называется обходом дерева. Зачастую, операция может быть выполнена переходом указателя по отдельным узлам. Обход, при котором каждый узел-предок просматривается прежде его потомков называется предупорядоченным обходом или обходом в прямом порядке (pre-order walk), а когда просматриваются сначала потомки, а потом предки, то обход называется поступорядоченным обходом или обходом в обратном порядке (post-order walk). Существует также симметричный обход, при котором посещается сначала левое поддерево, затем узел, затем — правое поддерево, и обход в ширину, при котором узлы посещаются уровень за уровнем (N-й уровень дерева — множество узлов с высотой N). Каждый уровень обходится слева направо.