Работа с файлом строк
 Работа с текстовым файлом. Вывод определенных строк и слов
Работа с текстовым файлом. Вывод определенных строк и слов
Ребят, привет! Помогите задачки решить, половину сама осилила, а над остальным уже второй день.
Работа с текстовым файлом (замена строк)
Доброго времени суток Мне нужно сделать некий файл настроек. Каждая настройка будет находиться на.
Работа с текстовым файлом и массивом строк
Доброго времени суток, уважаемые программисты! Возникла у меня задачка, никак не могу решить.
Работа с Excel файлом размером в 54к строк
Всем доброго времени суток! Столкнулся с такой проблемой: есть Excel’евский файл, в нем 54к строк.
Работа с файлом, счёт строк, ошибка конца файла
Доброго времени суток! При исполнении сборки ни cmd ни far32 воспроизвести желаемый результат не.
Решение задач ГИА
компьютерная программа по информатике и икт (11 класс)
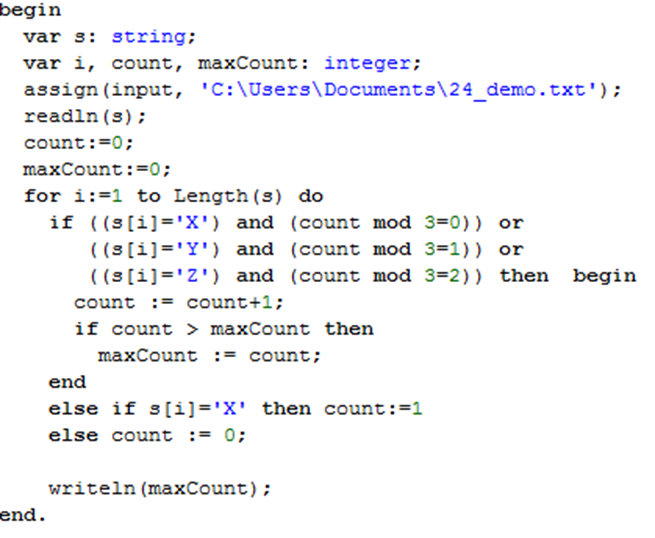
СТРОКИ Задание_1( демо_версия ) . Текстовый файл состоит не более чем из 10 6 символов X, Y и Z. Определите максимальное количество идущих подряд символов, среди которых каждые два соседних различны. Для выполнения этого задания следует написать программу . f= open (’24.txt ‘) # открыть файл для чтения s = f.readline () # читает одну целую строку из файла m_d =d = 1 # m_d — максимальная длина, d- длина текущей строки for i in range (1, len (s )): # len (s) возвращает длину строки if s[i] != s[i — 1 ]: # != не равно d += 1 if d > m_d : m_d = d else : d = 1 print ( m_d ) ОТВЕТ: 35
f=open(’24.txt’) m_d =d = 1 for line in f : # Ещё один способ сделать это — прочитать файл построчно for i in range( len (line)-1): if line[ i ] != line[ i — 1]: d += 1 if d > m_d : m_d = d else: d = 1 print( m_d )
СтатГрад от 22.10.2021 Текстовый файл содержит строки различной длины. Общий объём файла не превышает 1 Мбайт. Строки содержат только заглавные буквы латинского алфавита (ABC…Z). Определите количество строк, в которых буква E встречается чаще, чем буква A . ( файл состоит из отдельных строк) ОТВЕТ:467 f=open(’24.txt’) ka =0 ke =0 k=0 for line in f: ka =0 ke =0 for a in line: if a==’A’: ka +=1 elif a==’E’: ke +=1 if ke > ka : k+=1 print (k)
СтатГрад от 10.12.2021 Текстовый файл содержит только заглавные буквы латинского алфавита (ABC…Z). Определите символ, который чаще всего встречается в файле сразу после буквы A. Например, в тексте ABCAABADDD после буквы A два раза стоит B, по одному разу – A и D. Для этого текста ответом будет B . f=open (’24.txt ‘) # ord (‘A’)=65 возвращает код буквы , b =[0]* 26 # chr (65)=‘A’- возвращает символ по коду for line in f: for i in range( len (line)-1): if line[ i ]==’E’: b[ ord (line[i+1])-65]+=1 m=0 n=0 for i in range (0,26): if b[ i ]>m: m=b[ i ] n= i print ( chr (n+65))
Обработка символьных строк. Задание 24 ЕГЭ
Пример 1: Текстовый файл состоит из символов A, C, D, F и O.
Определите максимальное количество идущих подряд пар символов вида согласная + гласная в прилагаемом файле. Для выполнения этого задания следует написать программу.(kege.ru 4710)
Для этого способа не нужно программирование, но нужно понимать, что он не универсальный и в некоторых задачах будет слишком трудоемким.
Решение: Открываем текстовый файл. Возможности блокнота очень ограничены, поэтому основные функции, которыми мы будем пользоваться это замена и поиск. Так как нам не важна конкретная буква, важно только чтобы она была согласной или гласной, заменим все гласные на «А», а согласные на «С», с помощью меню правка-> заменить
Таким образом задание преобразовывается в нахождение количества АС. Чтобы проще было считать, заменим «АС» на любой другой символ, например «#». Получим:

Далее путем подбора ищем максимальное количество «#», но если понимаем, что их слишком много, то заменяем, например, 10 «#» на другой символ – «$». Теперь видим, что максимальное количество «$», которое мы нашли, это 9, что будет означать 90 комбинаций «АС» + 5 «#» идущих следом дают ответ 95.
Пример 2. Текстовый файл состоит из заглавных букв латинского алфавита. Определите максимальное количество подряд идущих символов, среди которых нет сочетания DD, но есть сочетание FE. Для выполнения этого задания следует написать программу.(kege.ru 5223)
Решение: Данную задачу тоже можно решить, не прибегая к программированию.
Чтобы исключить сочетание DD, сделаем разбивку текста на слова, заменив «DD» на «D D». В блокноте не очень удобно искать, поэтому скопируем текст в Word. Выполняем поиск FE, ищем максимальную длину слова.

Программный способ решения. Python
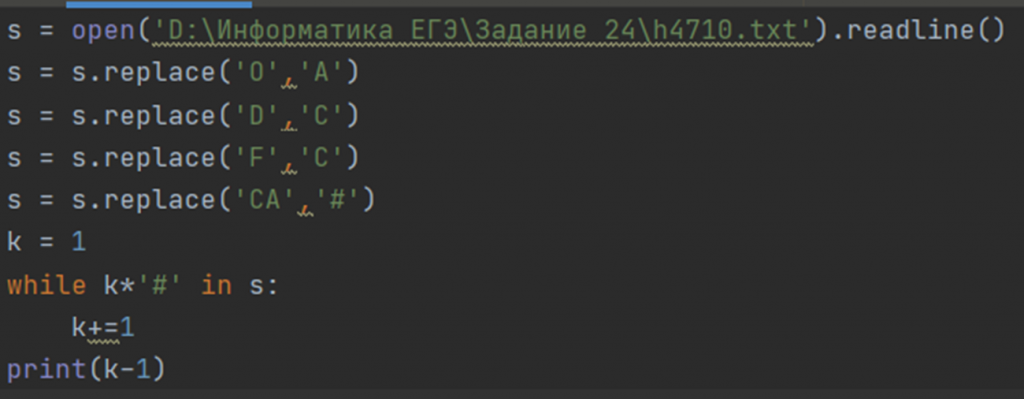
Пример: Текстовый файл состоит из символов A, C, D, F и O. Определите максимальное количество идущих подряд пар символов вида согласная + гласная в прилагаемом файле. Для выполнения этого задания следует написать программу.(kege.ru 4710)
Решение:
Первое, с чего начинаем любое задание, это открываем и читаем файл: S = open(‘Путь к файлу\имя файла’).readline()
Так как нам не важно какая именно гласная или согласная должна идти, то упростим задачу заменив все гласные и согласные на какую-то одну букву. Например, все гласные на ‘А’, а все согласные на ‘С’:
Таким образом согласная + гласная это сочетание ‘АС’. Чтобы проще было считать, заменим АС на любой другой символ, например ‘*’:
Чтобы посчитать количество в цикле while будем последовательно искать количество *, начиная с 1:
Но так как уже после нахождения максимального количества, цикл выполнится еще раз, то выводить будем к-1
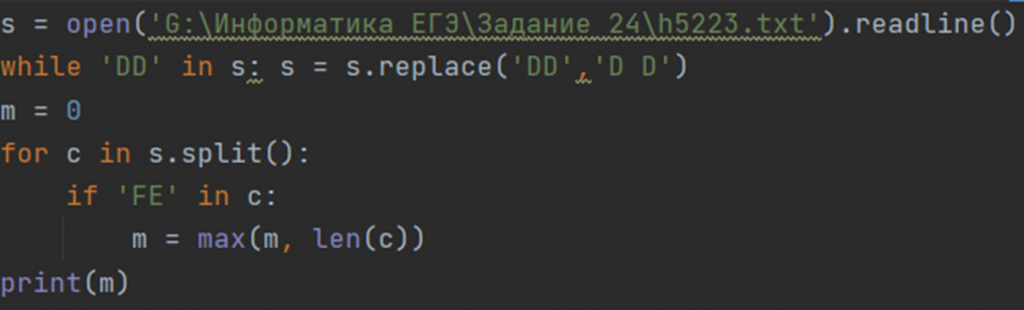
Рассмотрим еще один пример: Текстовый файл состоит из заглавных букв латинского алфавита. Определите максимальное количество подряд идущих символов, среди которых нет сочетания DD, но есть сочетание FE. Для выполнения этого задания следует написать программу.(kege.ru 5223)
Решение: Так как строка не может содержать DD, но может содержать D, то можно разбить нашу строку на подстроки при нахождении DD:
while ‘DD’ in s:
s= s.replace(‘DD’, ‘D D’)
s = s.split()
Программный способ решения. Pascal
1. Для решения любой задачи, начала нужно прочитать строку из файла •в языке PascalABC.NET можно выполнить перенаправление потока ввода:
assign( input, ‘k7.txt‘ );
readln(s); •программа будет «думать», что читает данные, введённые с клавиатуры (с консоли), а на самом деле эти данные будут прочитаны из файла k7.txt •2. Далее рассмотрим несколько вариантов заданий
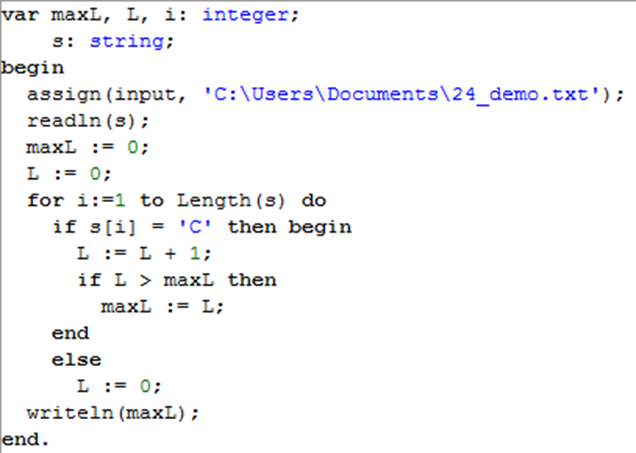
Вариант 1. Самая длинная цепочка символов «С»
L – длина текущей цепочки букв C
maxL – максимальная длина цепочки букв C на данный момент
Рассмотрим очередной символ строки; если это буква C, увеличиваем L на 1 и, если нужно запоминаем новую максимальную длину; если это не буква C, просто записываем с L ноль:
maxL := 0;
L := 0;
for i:=1 to Length(s) do
if s[i] = ‘C’ then begin
L:= L+ 1; # ещё одна буква C
if L > maxL then # возможно, новая максимальная длина
maxL:= L; end
else
L := 0; # цепочка букв C кончилась
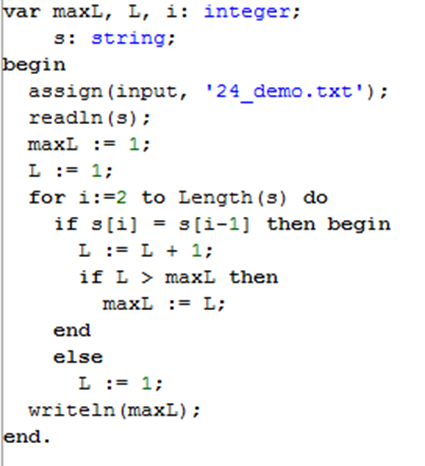
Вариант 2. Самая длинная цепочка любых символов
•Cложность состоит в том, что мы (в отличие от предыдущей задачи) не знаем, из каких именно символов состоит самая длинная цепочка
Введем переменные: L – длина текущей цепочки одинаковых символов ; maxL – максимальная длина цепочки одинаковых символов на данный момент;
В начальный момент рассмотрим один первый символ (цепочка длины 1 есть всегда!):
maxL:= 1;
L := 1;
Будем перебирать в цикле все символы, начиная с s[1] (второго по счёту) до конца строки, постоянно «оглядываясь назад», на предыдущий символ
for i := 2 to Length(s) do
обработать пару символов s[i-1] и s[i]
Eсли очередной символ s[i] такой же, как и предыдущий, цепочка одинаковых символов продолжается, и
нужно увеличить значение переменной L; если значение L стало больше maxL, обновляем maxL:
if s[i] = s[i-1] then # цепочка продолжается
L :=L+ 1; # увеличиваем длину
if L > maxL then begin # если цепочка побила рекорд
maxL := L ; # запоминаем её длину…
else
L:= 1 # началась новая цепочка
Eсли очередной символ не совпал с предыдущим, началась новая цепочка, и её длина пока равна 1 (это значение записывается в переменную L)
Вариант 3. Самая длинная цепочка вида XYZXYZXYZ…
Проверка того, что символ принадлежит цепочке, производится следующим образом. Заметим, что в искомой цепочке чередуется группа из трёх символов (XYZ). Пронумеруем символы искомой цепочки, начиная с нуля.
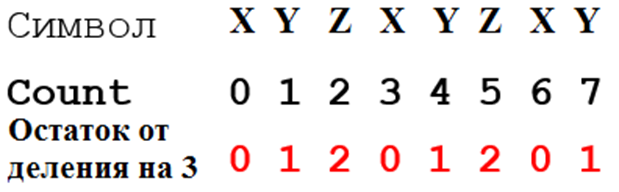 Видно, что позиция каждого символа имеет одинаковый остаток от деления на 3. Позиция есть значения переменной счётчика в момент проверки символа. Поэтому если совпадает символ и соответствующий ему остаток от деления, то он принадлежит цепочке. Для приведённого примера условие проверки выглядит так
Видно, что позиция каждого символа имеет одинаковый остаток от деления на 3. Позиция есть значения переменной счётчика в момент проверки символа. Поэтому если совпадает символ и соответствующий ему остаток от деления, то он принадлежит цепочке. Для приведённого примера условие проверки выглядит так
if ((s[i]=’X’) and (count mod 3=0)) or
((s[i]=’Y’) and (count mod 3=1)) or
((s[i]=’Z’) and (count mod 3=2))
Если символ не является частью этой цепочки, но может являться её началом (X), длина цепочки принимается равной единице, в противном случае длина обнуляется
else if s[i]=’X’ then count:=1
else count := 0;
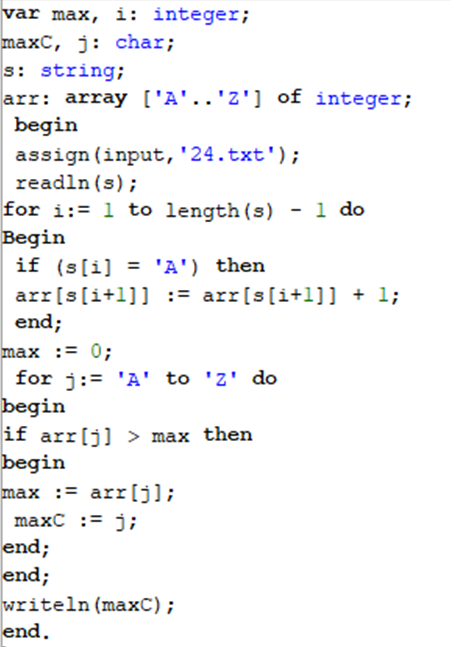
Вариант 4. Текстовый файл содержит только заглавные буквы латинского алфавита (ABC…Z). Определите символ, который чаще всего встречается в файле сразу после буквы A.
Например, в тексте ABCAABADDD после буквы A два раза стоит B, по одному разу — A и D. Для этого текста ответом будет B. Для выполнения этого задания следует написать программу. Ниже приведён файл, который необходимо обработать с помощью данного алгоритма.
Для обозначения каждого символа введем переменную массив [‘A’..’Z’]. Таким образов, нумерация элементов массива будет равна символам латинского алфавита. Теперь когда мы встретим символ “А”, мы на место его последующего символа, будем записывать сколько он раз встречался после буквы “А”.
Изначально, наш массив будет выглядеть следующим образом:

Но как только мы встретим символ “А”, мы на место следующего символа прибавим 1.
Например, если у нас дана последовательность NADK… массив примет вид:
 В программе это будет реализовано следующим образом:
В программе это будет реализовано следующим образом:
После того, как массив будет заполнен, останется только найти среди его элементов максимальный и вывести его индекс, так как он будет указывать на соответствующую букву.
Вариант 5. Текстовый файл состоит не более чем из 10 6 десятичных цифр. Найдите максимальную длину последовательности, которая состоит из цифр одинаковой четности.
Например, в последовательности 1533244622185452354, 5 последовательностей с нечетными цифрами – 1533, 1, 5, 5, 35 – и 5 с четными – 244622, 8, 4, 2, 4. Следовательно, искомая последовательность – 244622.
В качестве ответа укажите максимальную длину найденной последовательности.
Для выполнения этого задания следует написать программу.
Особенность задания состоит в том, что нужно будет преобразовать символы строки в числа. Для этого можно воспользоваться функцией strtoint или ord.
Функция StrToInt конвертирует строку с целым значением, такую как ‘123’, в целое Integer.
Функция ORD
Буквы от ‘A’ до ‘Z’ следуют в возрастающем порядке, иными словами, каждая буква имеет порядковое значение, соответствующее ее месту в алфавите. Это порядковое значение может быть получено посредством функции ord.
ord(выражение) – возвращает порядковый номер литеры или значения другого дискретного типа.
ord(‘I’), ord(‘J’). Результат: 73, 74 (код ASCII)
Порядковый номер литеры зависит от используемого кода. Но, независимо от используемого кода, порядковые значения букв следуют по возрастанию:
ord(‘A’) < ord(‘B’) < ord(‘C’) … < ord(‘Z’)
Порядковые значения цифр также расположены по возрастанию:
ord(‘0’) < ord(‘1’) < ord(‘2’) … < ord(‘9’)
и, более того, порядковые значения соседних цифр отличаются на 1; так, ord(‘9’) – ord(‘0’) = 9. Отсюда следует, что численное значение цифры d (типа char) может быть получено так
value := ord(d) – ord(‘0’).
Таким образом, получаем программу

Задания для самостоятельного решения
- Текстовый файл состоит не более чем из 10 6 символов X, Y и Z. Определите длину самой длинной последовательности, состоящей из символов Y. Хотя бы один символ Y находится в последовательности.
Для выполнения этого задания следует написать программу. Ниже приведён файл, который необходимо обработать с помощью данного алгоритма.
2. Текстовый файл 24-5.txt содержит последовательность из символов «(»и «)», всего не более 10 6 символов. Определите максимальное количество подряд идущих открывающих скобок «(» в этом файле.
3. Текстовый файл 24-j5.txt состоит не более чем из 10 6 символов S, T, O, C, K. Определите максимальное количество подряд идущих комбинаций «KOT»
4. В текстовом файле k8.txt находится цепочка из не более чем 10 6 символов, в которую могут входить заглавные буквы латинского алфавита A…Z и десятичные цифры. Найдите длину самой длинной подцепочки, состоящей из одинаковых символов. Выведите сначала символ, из которого строится цепочка, а затем через пробел – длину этой цепочки. Если таких цепочек (максимальной длины) несколько, выведите информацию о первой встретившейся цепочке.
5. Текстовый файл содержит только заглавные буквы латинского алфавита (ABC…Z). Определите символ, который чаще всего встречается в файле сразу после буквы E.
Например, в тексте EBCEEBEDDD после буквы E два раза стоит B, по одному разу — E и D. Для этого текста ответом будет B.
Для выполнения этого задания следует написать программу. Ниже приведён файл, который необходимо обработать с помощью данного алгоритма.
6. Текстовый файл содержит только заглавные буквы латинского алфавита (ABC…Z). Определите символ, который чаще всего встречается в файле между двумя одинаковыми символами.
Например, в тексте CBCABABACCC есть комбинации CBC, ABA (два раза), BAB и CCC. Чаще всего — 3 раза — между двумя одинаковыми символами стоит B, в ответе для этого случая надо написать B.
Для выполнения этого задания следует написать программу. Ниже приведён файл, который необходимо обработать с помощью данного алгоритма.
7. Текстовый файл состоит не более чем из 10 6 десятичных цифр. Найдите максимальную длину последовательности, каждые две соседние цифры в которой в сумме дают значение не меньшее 10.
Например, в последовательности 1567543853 есть две такие последовательности 5675 и 385.
В качестве ответа укажите максимальную длину найденной последовательности.
Для выполнения этого задания следует написать программу.
Файлы к заданию: 24.txt
8. Текстовый файл состоит не более чем из 10 6 десятичных цифр. Восходящей последовательностью называется последовательность цифр, в которой каждая цифра меньше следующей за ней. Например, в последовательности 7238903278 три таких последовательности – 2389, 03 и 278. Длиной последовательности называется количество входящих в нее цифр.
Определите сколько в файле восходящих последовательностей длиной 5, не входящих в восходящие последовательности большей длины.
Для выполнения этого задания следует написать программу.
Файлы к заданию: 24.txt
9. Текстовый файл состоит из заглавных букв латинского алфавита. Определите максимальное количество подряд идущих символов, среди которых нет сочетания TT, но есть сочетание AB.
Для выполнения этого задания следует написать программу.
10. В текстовом файле находится цепочка из символов латинского алфавита A, B, C, D, E, F. Найдите максимальную длину цепочки вида DEDEDE…. (состоящей из фрагментов DE, последний фрагмент может быть неполным).
11. Текстовый файл состоит из символов A, B, C, D, E, F.
Определите максимальное количество подряд пар символов вида гласная + согласная в прилагаемом файле.
Определите символ который чаще всего встречается в файле сразу после буквы a
k=0 a=[] for x in range(2*10**10, 4*10**10+1, 100000):
print(a[0], k) #20000400000
- Тип 3. Хотя бы два нуля.
a=[int(x) for x in range(1,100+1)]
for i in range(len(a)): s=str(a[i]) if s.count(«0»)==2: k+=1 print(k)
- Пример решения (основа)
- На компьютере на файл навести и в самом низу Свойства файла (Вохможно это на английском) и там путь нажо копировать. Не забыть r.
В файле содержится последовательность целых чисел. Элементы последовательности могут принимать целые значения от −10 000 до 10 000 включительно. Определите и запишите в ответе сначала количество пар элементов последовательности, в которых хотя бы одно число делится на 3, затем максимальную из сумм элементов таких пар. В данной задаче под парой подразумевается два идущих подряд элемента последовательности. Например, для последовательности из пяти элементов: 6; 2; 9; –3; 6 — ответ: 4 11.
- r»C:\Users\mike\py101book\data\test.txt»
f=open(r»/storage/emulated/0/Compiler/py_3/17-1.txt») a=[int(x) for x in f] sumMax=-100 count=0 for i in range(len(a)-1):
- Тип 3 Файл содержит последовательность неотрицательных целых чисел, не превышающих 10 000. Назовём парой два идущих подряд элемента последовательности. Определите количество пар, в которых хотя бы один из двух элементов делится на 3, а их сумма делится на 5. В ответе запишите два числа: сначала количество найденных пар, а затем – максимальную сумму элементов таких пар.
f=open(r»/storage/emulated/0/Download/17.txt») a=[int(x) for x in f] count=0 sumMax=-100000 for i in range(len(a)-1):
print(count, sumMax, ‘Ответ на пример 3’)
Тип 4. В файле содержится последовательность из 10 000 целых положительных чисел. Каждое число не превышает 10 000. Определите и запишите в ответе сначала количество пар элементов последовательности, у которых сумма элементов кратна 117, затем максимальную из сумм элементов таких пар. В данной задаче под парой подразумевается два различных элемента последовательности. Порядок элементов в паре не важен. f=open(r»/storage/emulated/0/Download/17-2.Два различных элемента.txt») a=[int(x) for x in f] f.close() k=0 mx=0 for i in range(len(a)-1):
print(k,mx) #Ответ 427120 19890
- Задание 22
- Укажите наименьшее из таких чисел x, при вводе которого алгоритм печатает сначала 3, а потом 2.
for x in range(1,1000):
- Написан алгоритм. Найдите при каком наибольшем х алгоримт напечатает сначала 6, а потом 13.
for x in range(10000001,1000000000,100): #единица в конце первого числа и шаг в 100 сделаны чисто чтоьы ускорить ппоцесс. Алгоритм работает и без них
- Получив на вход число x, этот алгоритм печатает два числа L и M. Укажите наибольшее из таких чисел x, при вводе которых алгоритм печатает сначала 25, а потом 3.
for i in range(400,1000):
- Получив на вход число x, этот алгоритм печатает два числа a и b. Укажите наибольшее из таких чисел x, при вводе которых алгоритм печатает сначала 2, а потом 12.
for i in range(1000,10000):
- Задание 22
- Укажите наименьшее возможное значение x, при вводе которого программа выведет сначала 3, а потом 2.
for i in range(1,100): x=i a=b=0 while x>0: if x%2==0: a+=1 else: b+=1 x//=2 if a==3 and b==2: print(i) #Ответ: 17.
- Получив на вход натуральное число x, этот алгоритм печатает число S. Укажите такое наименьшее число x, при вводе которого алгоритм печатает пятизначное число.
for i in range(1,10000):
- Тип количество цифр. #Получив на вход натуральное число x, этот алгоритм печатает число S. Укажите такое наименьшее число x, при вводе которого алгоритм печатает пятизначное число. #Аккауратно! строка x//=2 может быть написана в задании криво, но она должна быть под while
for i in range(15,20):
- Задание 23
- Больше типов в Галерее
- Тип 1. Количество программ
Исполнитель Осень16 преобразует число на экране. У исполнителя есть три команды, которым присвоены номера: 1) Прибавить 1; 2) Прибавить 2; 3) Прибавить 3. Первая команда увеличивает число на экране на 1, вторая увеличивает его на 2, третья — увеличивает на 3. Программа для исполнителя Осень16 — это последовательность команд. Сколько существует программ, для которых при исходном числе 1 результатом является число 15 и при этом траектория вычислений содержит число 8?
print(f(1,8)*f(8,15)) #Ответ 1936
- Тип 2. Количество программ с избегаемым этапом
Исполнитель НечетМ преобразует число на экране. У исполнителя НечетМ две команды, которым присвоены номера: 1. прибавь 1 2. сделай нечётное Первая из этих команд увеличивает число x на экране на 1, вторая переводит число x в число 2x+1. Сколько существует таких программ, которые число 1 преобразуют в число 25, причём траектория вычислений не содержит число 24?
print(f(1,25)) #Ответ 10
- Тип 3. Количество программ с обязательным и избегаемым этапами.
Исполнитель РазДваТри преобразует число на экране. У исполнителя есть три команды, которым присвоены номера: 1. Прибавить 1 2. Прибавить 2 3. Умножить на 3 Сколько существует программ, которые преобразуют исходное число 1 в число 15, и при этом траектория вычислений содержит число 10 и не содержит числа 13? def f(curr,end):
print(f(1,10)*f(10,15)) #Ответ 168
Тип 4. Исполнитель Увеличитель345 преобразует число, записанное на экране. У исполнителя три команды, которым присвоены номера: 1. Прибавь 3 2. Прибавь 4 3. Прибавь 5 Первая из них увеличивает число на экране на 3, вторая увеличивает это число на 4, а третья – на 5. Программа для исполнителя Увеличитель345 – это последовательность команд. Сколько есть программ, которые число 22 преобразуют в число 42? def f(curr,end):
print(f(22,42)) #Ответ 73
Тип 5. Исполнитель преобразует число на экране. У исполнителя есть две команды, которым присвоены номера: 1. Удвоить 2. Удвоить и прибавить Первая команда умножает число на экране на 2, вторая — умножает его на 2, а затем прибавляет 1. Сколько различных результатов можно получить из исходного числа 1 после выполнения программы, содержащей ровно 10 команд?
d=set() def f(curr,step):
f(1,0) print(len(d)) #Ответ 1024
Тип 6. Предпоследняя команда. Две операции: 1)Прибавить 1 2)Прибавить 2 Сколько существует программ, которые преобразт число 3 в 18 и предпоследняя команда 2)? Предпоследняя команда это команда прибавления 2. Мы должны получить 18, т е это надо вычитать, получаем 15 и 14. Так как предпоследняя команда 2 переводит 15 в 17, а 14 в 16 и из них уже последней командой можно получить 18. def f(curr,end):
print(f(1,14)+f(1,15)) #Ответ 987
Тип 7. Самая короткая программа. Три команды: Прибавить 1 Прибавить 5 Умножить на 3 Найдитe длину самой короткой программы, которая преобразует 1 в 227.
from functools import * @lru_cache(None) #Именно так, без None не работает! def f(curr,end,step):
print(f(1,227,0)) #Ответ 7
- Задание 24
Текстовый файл содержит строки различной длины. Общий объём файла не превышает 1 Мбайт. Строки содержат только заглавные буквы латинского алфавита (ABC…Z). В строках, содержащих менее 25 букв A, нужно определить и вывести максимальное расстояние между одинаковыми буквами в одной строке. Пример. Исходный файл: GIGA GABLAB NOTEBOOK AGAAA В этом примере во всех строках меньше 25 букв A. Самое большое расстояние между одинаковыми буквами – в третьей строке между буквами O, расположенными в строке на 2-й и 7-й позициях. В ответе для данного примера нужно вывести число 5.
print(m, j) #Ответ 1004 N
Текстовый файл содержит строки различной длины. Общий объём файла не превышает 1 Мбайт. Строки содержат только заглавные буквы латинского алфавита (ABC…Z).
Необходимо найти строку, содержащую наименьшее количество букв N (если таких строк несколько, надо взять ту, которая находится в файле раньше), и определить, какая буква встречается в этой строке чаще всего. Если таких букв несколько, надо взять ту, которая позже стоит в алфавите. Пример. Исходный файл: NINA NABLAB ANAAA В этом примере в первой строке две буквы N, во второй и третьей — по одной. Берём вторую строку, т. к. она находится в файле раньше. В этой строке чаще других встречаются буквы A и B (по два раза), выбираем букву B, т. к. она позже стоит в алфавите. В ответе для этого примера надо записать B.
f=open(r»/storage/emulated/0/Download/24-2-пример 2 задание 24.txt») s=f.readline() mn=1000 m=0 for s in f:
print(mn,ch) #Ответ 23 Y
from collections import Counter
word = ‘приоритет’ c = Counter(word) print(c.most_common(1)[0][0])
Т.к. метод most_common возвращает список самых частых значений (даже если мы запросили одно самое частое значение), то нужно взять первый элемент (для этого нужен первый [0]). Каждый элемент в этом списке — пара (элемент, количество), поэтому нужно взять первый элемент еще раз.
Вообще, в слове «приоритет» есть 3 буквы, которые встречаются по два раза (р, и, т), выведет только одну из них (у меня вывело «р»).
from collections import Counter f=open(r»/storage/emulated/0/Download/24-2-пример 2 задание 24.txt») s=f.readline()+»*» h=[] m=10000 for s in f:
print(m, c.most_common(24)[0][0]) #реже всего print(m, c.most_common(24)[-1][0])
- Ответ 23, Y
- Вообще. Можно сделать и так:
from collections import Counter f=open(r»/storage/emulated/0/Download/24-2-пример 2 задание 24.txt»)
s=[«N»]*10000 lines=f.readlines() for line in lines:
Текстовый файл содержит строки различной длины. Общий объём файла не превышает 1 Мбайт. Строки содержат только заглавные буквы латинского алфавита (ABC…Z). Определите количество строк, в которых буква E встречается чаще, чем буква A. Для выполнения этого задания следует написать программу. Ниже приведён файл, который необходимо обработать с помощью данного алгоритма.
f=open(r»/storage/emulated/0/Download/inf_22_10_20_24.txt») k=0 for s in f:
print(k) #Ответ 467
Текстовый файл содержит только заглавные буквы латинского алфавита (ABC…Z). Определите символ, который чаще всего встречается в файле сразу после буквы A.
Например, в тексте ABCAABADDD после буквы A два раза стоит B, по одному разу — A и D. Для этого текста ответом будет B.
Для выполнения этого задания следует написать программу. Ниже приведён файл, который необходимо обработать с помощью данного алгоритма.
Напишите программу на питоне. Текстовый файл содержит только заглавные буквы латинского алфавита (ABC…Z). Определите символ, который чаще всего встречается в файле сразу после буквы A.
Например, в тексте ABCAABADDD после буквы A два раза стоит B, по одному разу — A и D. Для этого текста ответом будет B.
Для выполнения этого задания следует написать программу. Ниже приведён файл, который необходимо обработать с данного алгоритма.
Ответы

writeln(‘сумма цифр числа ‘,a,’ равна’, a div 100+(a mod 100) div 10 +a mod 10);
writeln((a mod 10)*100+((a mod 100) div 10)*10 +a div 100);
фактографическая бд содержит краткие сведения об описываемых объектах, представленные в строго определенном формате.
документальная бд содержит обширную информацию самого разного типа: текстовую, графическую, звуковую, мультимедийную.
Сколько раз буква встречается в строке
Программа принимает на вход строку и букву. Надо определить (с использованием рекурсии), сколько раз данная буква встречается в строке.
Решение задачи
- Принимаем на вход строку и букву, записываем их в разные переменные.
- Передаем эти переменные в качестве аргументов в рекурсивную функцию.
- В качестве базы рекурсии примем условие, что строка является непустой.
- Если строка является непустой, то работа функции продолжается и мы смотрим, совпадает ли первый символ строки с проверяемой буквой, или нет. Если совпадает, то мы увеличиваем счетчик на единицу.
- Далее мы передаем строку без первой буквы снова в функцию, и все повторяется заново.
- Когда строка станет пустой, функция вернет нам количество вхождений буквы в строке. Выведем этот результат на экран.
- Конец.
Исходный код
Ниже дан исходный код программы для рекурсивного определения количества вхождений буквы в строку. Результаты работы программы также даны ниже.
Объяснение работы программы
- Пользователь вводит строку и букву, которые записываются в отдельные переменные string и ch .
- Далее эти переменные передаются в качестве аргументов в рекурсивную функцию check() .
- Для того чтобы функция продолжала свою работу, необходимо, чтобы строка была непустой. Если строка является пустой, функция завершает свою работу и возвращает 0 .
- На следующем шаге рекурсивная функция проверяет, совпадает ли буква в переменной ch с первой буквой в строке. Если совпадает, то в выходное значение добавляется 1 , к которой прибавляется функция check() , в которой в качестве аргумента передается наша строка, но уже без первой буквы. Если нет, то просто вызывается функция check() , где в качестве аргумента также строка без первой буквы.
- Так повторяется до тех пор, пока строка не станет пустой.
- После этого результат выводится на экран.
Результаты работы программы

Английский для программистов
Наш телеграм канал с тестами по английскому языку для программистов. Английский это часть карьеры программиста. Поэтому полезно заняться им уже сейчас