Перевод игр для чайников (shedevr)
Если начали читать этот текст, то возможно вы решили перевести некую игру скажем с английского на русский. В принципе нет разницы английский язык или любой другой европейский. Данное руководство не совсем применимо если вас угораздило решиться на перевод с японского . В данном описании я рассмотрю подходы к переводу только однобайтовых кодировок. Что это за звери такие эти однобайтовые кодировки sbcs (Single Byte Character Set), надеюсь станет понятнее если у вас хватит терпения прочитать еще пару — тройку абзацев.
Для лабораторной работы нам понадобятся следующие инструменты:
- 1. шестнадцатиричный редактор (я буду приводить в пример GoldFinger)
- 2. Windows Commander для побайтного сравнения файлов и быстрого HEX просмотра
- 3. TileLayerPro утилита для поиска и редактирования битмэповых шрифтов в приставочных играх.(Лучшей утилтой на сегодня является Tile Molester)
- 4. SnesTool для генерации IPS файлов (спец формат который позволяет выделить только измененные байты и надевать изменения на оригинальный образ ROM)
- 5. PokePerevod — утилита, смысл которой я постараюсь объяснить в ниже.
Глава Первая — В начале были буквы. [ ]
Если вам известно, чем кодовая страница отличается от шрифта, а печатные символы от непечатных, вам лучше продолжить чтение со следующей главы.
Начнем с простого, наверное вы читаете этот текст на PC и соответственно объяснять, что такое IBM PC не надо (это было бы уж слишком для решивших ПЕРЕВОДИТЬ игры, а не просто мочить всех монстров до последнего патрона .
У персоналки (IBM PC) есть BIOS, в котором кроме всего прочего есть место где нарисованы шрифты, если посмотреть на экран пока машина грузится (русские Win9x нагляднее), то можно увидеть, что сначала выводимый на экран текст русскими буквами не читается, в смысле буквы мы видим, но они какие то не русские , потом весь русский тест видимый на экране внезапно становится понятным. Это значит, система загрузила MODE/DISPLAY/COUNTRY.sys которые в определенное место в памяти записывают новые ИЗОБРАЖЕНИЯ символов — шрифты . Ура с одним термином разобрались, идем дальше.
А когда мы располагаем, изображения символов в определенном порядке, например под номером 65 у нас нарисована заглавная английская буква «А», под номером 66 будет нарисована буква «B» и так далее. значит мы придумали кодовую страницу (code page или character set). Причем обратите внимание, что программе глубоко наплевать что мы увидим на мониторе. Она просто говорит подсистеме ввода/вывода покажи на экране символы с кодами (hex) 66,55,43,4B , а что увидит пользователь программу никак не волнует.
Далее, производители персоналок договорились о СТАНДАРТНОЙ кодовой странице, которая состоит из 255 (или 256 символов и английские буквы там всегда имеют одинаковые коды, а остальные как захочет производитель .
Поскольку вариантов нумерации изображений символов расплодилось много, то буржуины их пронумеровали и обозвали стандартными кодовыми страницами. Соответственно программа пишется с предположением, что на компьютере будет использована определенная кодовая страница и тогда он увидит на экране текст правильно.
Далее несколько констант (я буду пользоваться этими названиями ниже):
Для русских символов существует несколько СТАНДАРТНЫХ кодовых страниц (мы же блин не американы какие то, нас умом не понять
- MS DOS codepage — «cp866»
- MS Windows — «Windows-1251»
- Unix — «ISO8859-5»
- Mainframe — «cp1025»
Есть еще одна кодовая страница рожденная основоположниками FIDO в России под названием KOI8-R (ее использование, впрочем не лишено определенного смысла. )
Есть или вернее было еще несколько кодовых страниц на ПК типа Искра1030, Роботрон и т.д. о них читайте в учебниках истории развития компьютеров.
Как вы наверно догадываетесь текст написанный в одной кодировке не читается при использовании другой кодовой страницы (объяснять не буду, если не понятно почитайте спец. литературу для супер-чайников).
Однобайтовая кодировка (кодовая страница) — это когда одному байту соответствует один символ и получается, что всего символов закодированных таким образом может быть 255 (или 256 . Бывают еще двухбайтовые кодировки (double byte character set), когда одному изображению символа соответствует два байта и соответственно в кодировке может использоваться 65536 символов. Ярким представителем такой кодировки является Unicode. А есть еще смешанные кодировки (multi byte character set) типа UTF-8 когда английские буквы кодируются одним байтом, а все остальные символы двумя.
Далее речь пойдет об однобайтовых кодировках.
Глава 2 — Особенности перевода приставочных игр. [ ]
Рассмотрим вариант, когда программа работает не персоналке, а на приставке типа GameBoy. Дело в том, что у GB своего BIOS’a нет (в том понимании как это есть у IBM PC), поэтому вся программа (включая подсистему ввода-вывода) находится в так называемом ROM картридже. И соответственно, имея образ этого картриджа можно поправить как шрифты, так и текст игры. Вообще поправить можно все, что угодно, но мы с вами говорим о переводе а не о ломании игр. Разница между PC и GB лишь в том, что там нет понятия стандартная кодовая страница (кодировка). Каждый производитель игр может сочинить свой charset (кодировку) где, например коду 0x00 будет соответствовать изображение английской буквы «A» и собственно сложность при переводе приставочных игр заключается в том, чтобы догадаться какими кодами кодируются символы выводимые на экран.
Далее задача раскладывается на четыре:
- 1. найти шрифты (изображения символов)
- 2. написать таблицу соответствия символов (вычислить charset).
- 3. дорисовать недостающие изображения символов (русские буквы)
- 4. перевести текстовые строки в игре на другой язык.
Опыты над разными образами игр (для GB) показали, что в случае если игра выпущена для европейских языков (английский и т.д.) то там как правило есть место для 255 символов, но изображения как правило есть только для тех букв, которые выводятся на экран, а изображения других букв кодировки просто оставлены пустыми.
Во многих руководствах и мини туториалах по переводу приставочных игр говорится о ЗАМЕНЕ изображений английских символов русскими и последующем переводе. Однако такой подход приводит к тому, что тот текст который еще НЕ переведен не читаем (вспомните работу русского scandisk при загрузке Win9x) и соответственно у игрока нет никаких шансов догадаться о том, что там ему говорят. Это не дает возможности нормально играть в частично переведенную игру. Поэтому далее я постараюсь объяснить, как можно переводить и оставлять понятным, то, что еще не переведено.
Глава 3 — Перевод в лоб. [ ]
Вернемся к нашим баранам. Сначала попробуем разобраться с двоичными файлами (играми) на PC.
Далее если не указано специально речь идет о программах работающих под M$Windows и соответственно, кириллица в кодовой странице Windows-1251.
Рассмотрим какую ни будь программу в двоичном виде. Картина будет примерно следующая:
То, что мы видим в левой части экрана это коды символов в HEX виде, то, что в правой части — это изображения символов. Соответственно верить можно только левой части, а правая зависит от разных настроек системы. Причем обратите внимание, что мы разглядывая таким образом программу, видим и исполняемый код и текстовые константы. Если вы не знаете, что такое исполняемый(двоичный) код, читайте спец. литературу.
Соответственно, что мы делаем, если хотим перевести этот текст на другой язык. Мы своим зорким глазом отличаем печатные символы от непечатных, (тех что на экране обычно не встретишь). И далее вставляем в левую часть другие коды, которые соответствуют другим печатным символам, и соответственно с правой стороны, увидим скажем английские буквы.
Следует заметить, что если в результате наших изменений мы вдруг забьем несколько позиций «непечатных» символов, то программа может перестать работать (это запросто могут оказаться исполняемые инструкции). С другой стороны часть непечатных символов (с нашей точки зрения) может быть вполне печатными (например немецкие умляуты).
Если вы увидите картину типа такой:
. то вам не повезло, тут используется двухбайтовая кодировка, и перевод такой игры может сильно усложнится не потому, что тяжело работать с Unicod’ом, а просто мало утилит нормально с ним работают и это значит инструментарий переводчика придется писать самим .
Для того, чтобы уже, наконец закрыть вопрос «лобового перевода» следует заметить, что набить в HEX редакторе даже 20-30 килобайт текста под силу только самоотверженным людям а за набивание более 100Kb можно просто памятник ставить (посмертно, поскольку процесс перевода может длиться всю оставшуюся жизнь.
Глава 4 — Убиваем HEX редактор. [ ]
Идея достаточно проста — как бы вынуть весь текст из файла, перевести его, а потом засунуть обратно в те же места. но по возможности, не своими руками .
Если приглядеться к тому, как переводят в лоб, то можно заметить, что:
- 1. глазами находят текст и запоминают смещение, где это текст лежит в файле
- 2. вычисляют, где этот текст оканчивается (каким ни будь непечатным символом типа 0x00)
- 3. подбирают перевод фразы сходный по длине с оригинальной строкой
- 4. набивают его в те же места.
Данный процесс вполне поддается описанию, скажем на Visual Basic’e, главный вопрос в том, как программно отличить печатные символы от непечатных. Тут нам на помощь приходят все те же таблицы символов (codepages). Однако в СВОИХ таблицах мы опишем коды ТОЛЬКО печатных символов. Теперь программа может отличить коды печатных символов от непечатных и все, что остается это разобраться в том, как отличить текстовую строку в файле от двоичных инструкций. Для этого опять вернемся в лобовому переводу — там мы глазами читаем весь файл по байтику, пока не встретим последовательность печатных символов. Ура ключевое слово произнесено (кто не догадался я не виноват, в качестве эксперимента могу вам прочитать двоичный образ скажем Winword.exe и найти там текст, думаю к концу чтения все станет понятно
Далее все (или почти все) делает железяка — сканирует файл и вынимает ВСЕ последовательности печатных символов (тех, что есть в таблице, остальные считает непечатными) если встречает 2 или более печатных символа подряд, то такая последовательность записывается в файл отчета (например report.txt)
Структура выходного файла может быть проста до безобразия:
десятичное_смещение_в_двоичном_файле+пробел+последовательность_символов+crlf (признак конца строки) Следует заметить, что если мы говорим о том, что переводиться будет приставочная игра, со своей кодировкой, то нам такой выходной файл ничего не даст, на персоналке в нашей windows-1251 мы все равно ничего не поймем, значит строка вынутая из файла должна быть перекодирована из кодировки приставки в кодировку PC. Это тоже не проблема просто помимо кодов печатных символов нужно в нашей таблице указать какими кодами этот символ должен отображаться в кодировке PC. Поэтому в итоге таблица имеет структуру типа:
Причем ДО знака равенства пишется HEX код символа, а после знака равенства, каким ОДНИМ символом этот код выглядит на PC. Причем если вы вспомните Главу 1 (если конечно вы ее не пропустили), то скорее всего догадаетесь, что посмотрев на эту таблицу в шестнадцатиричном виде мы можем сделать и обратное преобразование.
Другими словами такая таблица может использоваться для перекодировки в обе стороны.
Вынув таким замысловатым образом текстовые последовательности из двоичного файла можно заняться их переводом в обычном текстовом редакторе. Подойдет даже WinWord,
Остается только одна проблема, поскольку в файле такого формата нет указания на длину оригинальной строки, то лучше воспользоваться спец. редактором, который не даст вам вылезти за размеры оригинальной строки и соответственно не позволит забить непечатные символы, следующие за текстовой строкой.
Следует заметить, что десятичное_смещение_в_двоичном_файле в файле вынутого текста, объяснит программе из какого места файла вынули эту строчку и даст возможность положить перевод в то же самое место. Возможно в следующих редакциях данного руководства я сподоблюсь и допишу как вставлять текст в другие места, а не по старым адресам.
Несколько общих замечаний: [ ]
- 1. Никто не мешает удлинить строку перевода, просто надо понимать, что вы рискуете забить своим текстом непечатные символы, и соответственно сделать игру неработоспособной.
- 2. Если перевод получается короче оригинала, нужно понимать, что если вы не нарастите свой укороченный перевод пробелами до оригинальной длины, то при выводе текста игра выведет еще и текст длиннее перевода. Игра ведь не знает, что строка стала короче и выведет то количество символов, которое было в оригинале. Если только в подсистеме вывода текста у игры нет зарезервированного специального кода, который говорит о том, что строка окончена.
- 3. Спец. символы, которые описаны в пункте 2 мы также можем описать как печатные и следовательно в своем текстовом редакторе сами расставлять концы строк.
- 4. При создании таблицы перекодировки нужно понимать, что одному коду всегда соответствует один символ (изображение) иначе программа перекодировки не сможет понять, как перекодировать переведенный текст. Иными словами таблица перекодировки должна быть обратимой.
- 5.
НЕОБРАТИМАЯ ТАБЛИЦА — это когда нельзя применив одну и ту же таблицу воссоздать первоначальный файл. Проверить обратимость очень просто, нужно ВЫНУТЬ текст из ROM’a затем НЕ изменяя полученный вынутый_текст.txt ВЕРНУТЬ его в ROM и потом сравнить (побайтно) полученные файлы, делать это например умеет WindowsCommander (выделить в одном окне входной файл, выделить в другом окне выходной файл а потом file -> compare by content) если входной и выходной файлы РАЗЛИЧАЮТСЯ то таблица НЕОБРАТИМА, то есть один тот же символ может перекодироваться в разные коды. такой таблицей пользоваться НЕСТОИТ поскольку она будет портить неоднозначные символы.
Собственно теоретическая часть на этом оканчивается, далее следуют суровые будни перевода
Все вышеописанные размышления, легли в основу программульки под названием PokePerevod. И далее я постараюсь показать как она облегчит жизнь переводчику интузазисту.
Глава 5 — Переводим Кристальных Покемонов. [ ]
Сперва наперво требуется раздобыть образ американской или европейской версии ROM’a, В другой стране я посоветовал бы купить нормальный картридж, и устройство типа GB Transferer, которое позволит сделать backup картриджа на PC.
Предположим вы так и поступили, далее обзаведитесь описанными выше утилитами (они бесплатны), а PokePerevod даже раздается с исходным текстом, дабы знающие VisualBasic могли усовершенствовать эту программульку вусмерть .
Далее запускаем TileLayerPro и начинаем разглядывать ROM, видим примерно следующее:
теперь переключимся в режим 1bpp View—>Format—>1BPP, что означает 1 Bit Per Point, в таком виде лежат шрифты в данном ROM’e. Как догадаться в каком формате лежат шрифты это отдельная песня и здесь не рассматривается. В худшем случае вам нужно пролистать/просмотреть весь ROM во всех вариантах .
Полистав некоторое время вы увидите экран типа этого:
произойдет это примерно по смещению hex(F8200). Теперь мы знаем правую часть таблицы, то есть что сначала заглавные английские буквы, потом несколько символов «();:[]» потом маленькие английские и т.д. Подсчитав количество квадратиков можно узнать, что шрифт состоит из 128 символов, однако мы не знаем с какого кода начинается отсчет — соответствует ли код hex(00) коду заглавной «A» или нет 🙁 Если учесть опыт персоналок, то скорее всего нет, проведя ряд экспериментов (это возможно будет описано в будущих версиях этого руководства) мы наконец понимаем, что заглавной «A» имеет код hex(80). Ура половина дела сделана. В результате получим таблицу следующего вида: (это печатные английские символы)
Таблица перекодировки готова, НО естественно это не все коды которые имеют соответствующие изображения, Полный вариант таблицы можно взять там же, где дистрибутив PokePerevod .
Далее нам надо всунуть изображения символов кириллицы в этот шрифт (разобраться как это сделать остается на факультатив . В итоге у меня получилось нечто вроде:
Обратите внимание я нарисовал русские буквы РЯДОМ, а не поверх английских символов, это значит, что игра будет по прежнему работать и показывать английский текст как прежде.
После урока рисования, начинается урок арифметики по вычислению кодов новоявленных русских букв с соответствующим изменением таблицы перекодировки (ведь печатных символов у нас прибавилось). Обратите внимание еще на один момент, поскольку «свободного» места не так уж много, я довольствовался только заглавными русскими буквами. НЕ забудьте что переводить в этом случае можно будет ТОЛЬКО заглавными русскими. впрочем этого вполне достаточно.
Далее мы запускаем PokePerevod, загружаем ROM и таблицу и вынимаем текст в файл.
Файл будет большой и содержать будет много мусора типа:
Это не должно нас останавливать, теперь это текстовый файл и можно заниматься переводом, правда я посоветовал бы открыть этот документ в notepad и удалить строки с непонятным текстом, тогда работать будет легче и быстрее.
Вынутый и почищенный файл перевода можно открывать в редакторе переводов в PokePerevod.
Самое главное редактор перевода не даст удлинять строку перевода (без специального на то разрешения), чем значительно ускорит работу. В том числе есть возможность «Найти и заменить» по всему переводу. В общем, разберетесь.
Замечание — не пытайтесь сразу перевести весь текст, достаточно перевести пару слов, и вернув текст в ROM а потом запустив поправленный вариант ROM’a убедиться, что вы все сделали правильно. Возможно и даже наверняка выяснится, что можно добавить печатных символов в таблицу (например пробел ) для таких изысканий очень полезен GoldFinger, экран которого показан ниже:
Формат таблиц описанный в данном руководстве (и используемый в PokePerevod) совместим с форматом таблиц для GoldFinger,
, GoldFinger при показе изображений символов использует досовскую кодировку (cp866) и следовательно, для того, чтобы увидеть, что мы там напереводили нужно открыть нашу виндоусовую таблицу (Windows-1251) в WordPad и сказать Save as —> MS DOS Format и такую вот таблицу подсунуть GoldFinger’у.
Глава 6 — Делай раз, делай два. [ ]
Обычно процедура перевода следующая:
- 1. используя TileLayer или Tile Molester находишь ИЗОБРАЖЕНИЯ букв в роме просто нужно открыть в программе файл с ромом и листать. листать. листать пока не увидишь нечто похожее на буквы 🙂
вобщем-то иногда это может оказаться значительно сложнее, но это уже другая история
- 2. генеришь английскую таблицу и разглядывая изображения символов дописываешь недостающие символы (коды символов типа «:»,»-«,» английская» и «русская», первая для ВЫнимания текста, вторая для Вставления твоего перевода обратно.
Пояснения к пункту 4. Как высчитывать коды для вновь рисуемых русских букв?
Представим ты нашел, что коду x41 (в HEX) соответствует заглавная английская буква «A», то есть в таблице у тебя написано 41=A. (. и ты можешь с этой таблицей вынуть текст из рома и его прочитать, в смысле ты уверен, что английская часть таблицы у тебя правильная)
. далее разглядывая изображения шрифта в роме, немного выше ты увидел черное место (ну или белое ) или символ, который считаешь ненужным скажем немецкий умляут(U с двумя точками), причем не забудь включить показ сетки (Grid lines=ON).
. далее считаешь «клеточки»(тайлы) в обратном порядке начиная с «А», скажем насчитал 5, зовешь калькулятор(calc) переключаешь в режим HEX и пишешь 41 — 5 = получаешь 3C, значит если ты в этом тайле нарисуешь скажем букву «Ц» то в таблице нужно дописать строчку «3C=Ц». ну и так далее в том же духе
. не забудь этот занимательный рассказ относится к случаю, когда изображение одной буквы вписывается в один квадратик (он же тайл), если скажем изображение одной буквы нарисовано в ДВУХ тайлах (например, как в сапфировых покемонах), то тогда ты число отсчитанных тайлов должен сначала поделить на число тайлов в символе. поясню, скажем насчитал 10 тайлов (каждая буква занимает 2 тайла) значит в калькуляторе пишешь 41 — (10 / 2) =
Как переводятся игры?
Перевод видеоигры — это больше, чем просто перевод контента с одного языка на другой. Вам нужны программисты для работы над каждым переводом в вашу игру, дизайнеры, которые могут адаптировать ваш визуальный контент, и команда, которая может управлять вашим проектом от одного этапа к другому.
Сколько стоит перевод игры?
Перевод запустит вас из От 0,09 до 0,135 доллара за слово для агентств и 0,02–0,06 доллара для индивидуальных переводчиков, если исходный язык — английский. Редактирование стоит около 0,05 доллара за слово.
Как вы переводите в игровом чате?
Помимо карты, на этой панели браузера есть масса другой интересной информации. Оказавшись там, вы увидите текстовый чат в правом верхнем углу. Отсюда вы можете скопировать + вставить в выбранную вами службу перевода. Если вы используете Google Chrome, вы можете сразу Нажмите -> Перевести страницу. также.
Какой лучший код для игр?
- C ++
- Джава.
- HTML5.
- CSS3.
- JavaScript.
- SQL.
Как мне локализовать свои игры?
- Спланируйте свой проект. .
- Выберите вашу компанию по локализации. .
- Создайте комплект локализации. .
- Экспортируйте свои строки. .
- Импортируйте свои строки. .
- Переведите свой контент. .
- Локализация нетекстовых элементов. .
- Проведите проверки качества.
Следует ли мне локализовать свою игру?
Процесс локализации (l10n) включает перевод, интернационализацию, культуризацию и лингвистическое обеспечение качества. Большое количество игроков не загрузят игру, если она не на их родном языке. Локализация игр вызывает доверие во всем мире: более высокие рейтинги, больше загрузок и увеличение продаж — плюсы.
Сколько времени занимает перевод игры?
Даже при самом оптимистичном подходе оказывается, что локализация требует минимум четыре с половиной месяца. Надеюсь, это упростит процесс для тех, кто думает, что это так же просто, как переключение документа Word с переведенным текстом.
Сколько времени нужно на перевод игры?
Обычно у них есть один перевод на каждый язык, и все они будут выполнены с первого прохода одновременно. в течение месяца или двух, в зависимости от того, сколько у вас текста и сколько нюансов они должны извлечь из него.
Как пользоваться универсальным переводчиком игр?
С универсальным переводчиком игр и запущенной текстовой игрой на японском все, что нужно сделать пользователю, — это нажать кнопку в чтобы отправить снимок экрана игры на серверы Google. Google сканирует изображение в поисках текста и переводит его, а универсальный переводчик игр накладывает переведенный текст поверх исходного текста.
Как мне стать переводчиком игр?
Наиболее важные требования к переводу игр — это языки (с упором на перевод). Геймдизайн или продвижение от тестировщика локализации также отличный способ стать переводчиком игр. Поскольку локализация игр — это новая область, здесь нет жестких правил.
Сколько стоит локализация?
Выберите подходящего поставщика локализации
Средняя плата этих агентств составляет около 0,20 доллара за слово. На нижнем уровне находятся небольшие агентства. В них работают носители языка, которые могут не иметь большого опыта, но все же имеют опыт работы с конкретными языковыми парами. Средняя плата таких фирм составляет около 0,08 доллара за слово.
Как переводят и дублируют видеоигры, или Почему в русских локализациях почти не матерятся?

В наше время нельзя уже представить крупный блокбастер без перевода на родной язык. В начале нулевых это было что-то непередаваемое и невероятное. Каждый (даже откровенно промптовый) перевод был манной небесной для отечественного геймера. Поломанные скрипты, криво озвученные в подвальном помещении диалоги, невнятные квесты, обрезанные наполовину слова и фирменная фраза: «Она — со мной, углепластик. Так охладите своё тр..хание» — стали фирменными чертами пиратских переводов. Сейчас на рынке такого уже не встретишь.



Позже зарубежный рынок таки обратил внимание на отечественную аудиторию и вполне легально позволяет крупным издательским конторам переводить и продавать их продукцию на территории «большой и необъятной». Привет качественный дубляж, адаптированные шрифты, полностью рабочая игра и грамотный перевод. И, казалось бы, уже не к чему придраться, но современные игроки все равно находят причины для недовольств. Почему тут ускоренная озвучка, почему тут нет сарказма, почему тут молодой актер озвучивает старого персонажа, и, конечно же, самый любимый вопрос: ГДЕ черт возьми мат?!
Мы связались с представителем компании Бука и узнали, почему переводы видеоигр получаются такими, какими мы их видим в повседневности. Эта статья развеет ваши представления о создании российских переводов, и вы сможете в дальнейшем взглянуть на дубляж игровых проектов с другой стороны.
Как происходит подготовка к переводу
Cделать качественную локализацию — труд непостижимых масштабов. Из-за особенностей языка (не только русского) нельзя просто взять и перевести игру дословно. Из уроков английского (а на нем базируются практически все игры) мы знаем, что словосочетания, идиомы и тот же самый мат можно интерпретировать по-разному. Так как отечественные издатели занимаются именно локализацией, а не обычным переводом, то им приходится время от времени тратить довольно значительное количество времени и сил, дабы донести игроку смысл происходящего.
Первым делом издатель игрового тайтла договаривается с российским локализатором, ставит сроки, объем задач и бюджет. Если проект ААА-класса, скорее всего, издатель закажет дубляж, перевод текстур, оригинальные шрифты. Если игра рангом ниже, то обычно всё заканчивается текстовым переводом и адаптацией. Инди-проекты если и получают локализации, то чаще всего после релиза, когда разработчик способен оплатить услуги переводчика. Бывает и такое, что крупные проекты, такие как ремейк Final Fantasy VII, проходят мимо российского рынка, и за перевод берутся фанаты.
 Final Fantasy VII Remake не получила русского перевода
Final Fantasy VII Remake не получила русского перевода
Когда договор заключен, разработчики скидывают необходимый пакет файлов для перевода, иначе называемый локитом. В идеале он состоит из документа с пронумерованными диалогами, выдержки из дизайн-документа, содержащей биографию персонажей и сюжет, звуковых дорожек, словаря, текстур в формате PSD, инструкций по переводу и, конечно, билда самой игры. На деле — это текстовый документ с диалогами и текстами UI без комментариев, а бывает, и без явной нумерации.
Звуковые дорожки… забудьте. Часто на момент записи звуковых дорожек не хватает, потому что оригинальные еще не записаны — есть только текст и очень жесткий срок сдачи записей. Поэтому бывает и так, что локализация вообще идет вслепую. Из-за этого наши игроки часто жалуются: интонации героя в русской версии игры не подходят под ситуацию. А локализатор не виноват, что к портянке с диалогами не догадались банальный комментарий оставить.
Как вы уже поняли, словари, дополнительная документация и другие полезные файлы, необходимые для качественного перевода и адаптации, чаще всего отсутствуют. Ругаться и винить издателей с разработчиками тоже не совсем правильно. Например, Valve предоставляет локализаторам полный пакет необходимых программ и документов. Когда в России переводили Half-Life 2, студия-разработчик лично следила за отбором актеров и подыскивала максимально близкие голоса к оригиналу. Но даже такой пристальный контроль не спас локализацию от ошибок, ускоренных диалогов, перепутанных фраз и других недостатков.

Half-Life 2 получила две версии локализации. Одну от Софтклаба, за которой пристально следила Valve, другую от Буки, где у локализатора было больше творческой свободы. Услышать оба перевода можно на видео
Собственно, получив (или не получив) необходимые файлы, локализаторы приступают к работе.
Dick — это имя или детектив? Как адаптируют и переводят видеоигры на русский язык
Первым делом в работу вступают переводчики. Исходя из того, дал ли разработчик словарь терминов, зависит скорость и качество самого перевода. В него обычно входят имена всех ключевых персонажей, заклинания, описания и названия локаций. Если сценаристы напару с издателем об этом не позаботились, то нашим переводчикам приходится по несколько раз перечитывать тысячи строк текста и выискивать все необходимые термины. Нельзя просто взять и перевести название какого-нибудь фэнтезийного оружия, не обратив внимание на весь контекст вокруг него. Было время, когда переводчики забивали болт на словарь, из-за чего в играх два или три заклинания имели одинаковое название, при этом в самой игре были совершенно разные.
 В русской локализации, вертиберд (VertiBird) из Fallout 2 получил новое название — винтокрыл (Gyrodyne)
В русской локализации, вертиберд (VertiBird) из Fallout 2 получил новое название — винтокрыл (Gyrodyne)
Собранный словарь перечитывают и подбирают подходящий перевод для каждого термина. Переводчику приходится учитывать, в каком контексте будет использоваться то или иное слово, а, следовательно, заранее определять его как часть речи с определенным падежом.
Бывает и так, что переводчик не знает, как правильно перевести или адаптировать термин под наш язык, объявляя его непереводимым. Из-за чего Шепард у нас коммандер, дворфы не имеют точной трактовки, а еще дебафы, юниты, дропы, абузы и так далее. Переводчикам приходиться разбираться в пасхалках и намеках, не теряя при этом основной замысел разработчиков. Переводчики составляют свои словари в ходе работы. Затем редакторам приходится собирать один общий словарь, чтобы можно было привести термины к единому виду.
 Стараниями наших переводчиков, Шепард получил звание капитана, а в действительности имел звание коммандера-лейтенанта, что сопоставимо с майором. А вот Андерсон как раз таки имел звание капитана, поэтому Шепард выполнял его приказы
Стараниями наших переводчиков, Шепард получил звание капитана, а в действительности имел звание коммандера-лейтенанта, что сопоставимо с майором. А вот Андерсон как раз таки имел звание капитана, поэтому Шепард выполнял его приказы
Покончив со словарем и комментариями к тексту, начинается процесс литературного перевода. Стоит сразу обратить внимание, что современные игры чаще всего имеют при себе тонны текста (игры серии Dark Souls не в счет). Работа над таким мастодонтом сравнима с переводом толстенной книги. Вот только времени на сам процесс дается куда меньше, а планку качества нужно держать.
Собственно, о качестве. Опечатки, непереводимые слова, идиомы — не самые крупные из бед, которые поджидают переводчиков. Основная проблема кроется в самих переводчиках. Мало владеть иностранной речью, нужно хорошо знать родной язык. Благодаря этому литературный перевод становится профессиональным. К сожалению, найти умельца владеющим большим багажом знаний, умений и высоким игровым стажем — задача не из легких. Корочка переводчика или филолога не дает гарантии, что у специалиста получится влиться в необходимую среду для локализации.
Переводчик-новичок в первые недели работы начинает осознавать, что перевод видеоигр куда сложнее и непонятнее, чем перевод того же кино. Текст игры подается не сплошным текстом, как в сценарии или субтитрах, а вразброс. И благо, если разработчик заранее позаботился и пронумеровал строки текста и поставил комментарии для упрощения перевода. Случается, что переводчик переводит реплику из одного диалога в огромной РПГ, а варианты ответа затерялись где-то на середине общего документа. Работнику приходится искать нужный кусок текста или надеяться, что переведенные реплики согласуются с начальным диалогом.
 Disco Elysium состоит на 80% из текста. Стоит переводчику слегка изменить текст или не разглядеть полную картину диалога, то потеряется вся прелесть этой RPG
Disco Elysium состоит на 80% из текста. Стоит переводчику слегка изменить текст или не разглядеть полную картину диалога, то потеряется вся прелесть этой RPG
Ролевой жанр сам по себе доставляет немало проблем отечественным локализаторам. И не только из-за уникальной терминологии, но и из-за банального выбора пола героя. Переводчику приходится выкручиваться и перефразировать диалоги так, чтобы они подходили под любой пол. Благо в современных играх всё чаще встречается строгое распределение диалогов по принадлежности пола. Вдобавок англоговорящим сценаристам неведомо понятие склонения, и когда на стадии тестирования редактор замечает: Волшебник нужно пить зелье, чтобы восстанавливать ману; то переводчик получает текст обратно на доработку, посылая всех трехэтажным матом.
Исходя из этого, переводчики берутся за перевод тех игр, которые им больше подходят по жанру. Специалист, через которого прошел не один десяток шутеров, определенно возьмется именно за шутер. А профессионал в переводе крупных РПГ возьмется за нового « Ведьмака» и будет готов ко всем подводным камням, имеющимся в этом жанре.
Основной же трудностью перевода было и остаётся время. Никогда не знаешь, чего ожидать от издателя. К примеру, на перевод Kingdom Come: Deliverance выделили больше года, когда игра находилась еще в разработке. Времени предостаточно на качественную локализацию, но стадия «в разработке» портит всё веселье. За этот период текст игры может существенно измениться, а разработчики еще и не удосужатся своевременно сообщить о корректировках локализатору. Из-за этого переводчикам приходится постоянно возвращаться к тексту и молиться… дабы изменения не зацепили уже переведенный и адаптированный текст.

Но куда сложнее работать в сжатые сроки. Из-за этого появляются несогласованности по тексту, неадаптированные или убитые напрочь оригинальные шутки, и другие распространенные жалобы игроков на отечественные локализации.
Когда с основным переводом заканчивают, текст полностью переходит под власть редактора. У последнего очень важная роль — помечать плохо переведенные строки, находить нестыковки или даже отправлять текст на повторный перевод. Впрочем, последнее обычно никогда не происходит. При этом редактор должен понимать о чем речь и без помощи переводчика доводить локализацию до ума. Но и на этом работа с текстом не заканчивается. После редактора за уже готовый текст садится корректор. Его задача — отполировать и довести до ума перевод, исправив все грамматические и синтаксические ошибки.
Трудности дубляжа. Как дублируются видеоигры
Если издатель запросил еще и озвучку, то переведенный текст отправляется на стол режиссера дубляжа (нередко озвучка идет в процессе перевода). Здесь стоит сразу отметить, что у каждой студии дубляжа разный подход к самой озвучке, но об этом чуть позже.
Косяки локализации чаще встречаются именно на стадии озвучивания и сведении звука. Причин для этого достаточно. Бывает так, что у режиссера дубляжа кроме образцов голосов на роль может ничего и не быть в нужный момент времени. Ему приходится полагаться на свой опыт, удачу и профессионализм актеров. Самих актеров подбирают режиссеры, реже — разработчики.
Стандартная практика в создании локализации — использовать одного актера для нескольких персонажей. Нанимать на каждую мелкую роль отдельного актера нецелесообразно. Это заметно раздувает бюджет, в который входит: почасовая оплата актера и аренда студии.
 Portal 2 как пример хорошей локализации. Отлично подобранные голоса актеров и прекрасно адаптированные для отечественной аудитории диалоги
Portal 2 как пример хорошей локализации. Отлично подобранные голоса актеров и прекрасно адаптированные для отечественной аудитории диалоги
Обычно актеру дают список реплик, которые идут вразброс. О разыгрывании диалогов между двумя голосами не может идти и речи. И повезет, если актеру сообщают о ситуации, в которой идет диалог, или в тексте есть ответная реплика. Не повезет, если всё озвучивается наугад. Двойную проблему составляют тайминги. Это отрезок времени, в который актер должен уложиться во время дубляжа. Есть ошибочное мнение, что переведенная фраза всегда будет длиннее оригинала. Так может получиться, если над текстом работал переводчик-неумеха. Тогда либо актер ускоряется до уровня рэпера, либо потом, на монтаже его фразу ускоряют в несколько раз.
Именно из-за отсутствия коммуникации между разработчиками и локализаторами в озвучке появляются неправильные интонации, бесхарактерные персонажи, нелепые выкрики и потерянные в монотонной читке главные герои.
Случаются проблемы и из-за желания актера вставить свои пять копеек в озвучку персонажа. Или режиссер дубляжа добавляет хихиканья, вздохи и другую отсебятину, просто потому, что ему так кажется лучше. И не важно, что это идет вразрез с исходным сценарием игры. Например, последние дублированные игры Bethesda невозможно слушать. The Wolfenstein 2: The New Colossus прекрасный пример отвратительного подбора актеров, наплевательского отношения к оригиналу и желания впихнуть в локализацию как можно больше придуманных деталей.

Помимо реплик, актерам дубляжа приходится переозвучивать все стоны, вздохи и любой другой шум, что довольно сильно режет слух. Актерам сложно передать необходимые эмоции и звуки находясь в студии в статичном положении перед микрофоном. При неизмененных оригинальных звуках, локализаторам приходится искать актера с максимально похожим тембром голоса, дабы не портить впечатление игрокам.
Нередко игроки жалуются на отсутствие попыток актера изобразить требуемый акцент. Будем честны, из-за этого и правда теряется колорит и характер персонажей. Вот только русскоязычному человеку это практически нереально озвучить. Для примера, можете посмотреть, как американцы озвучивают русских персонажей. Клюква клюквой.
Проблема отсутствия мата в российском дубляже, несмотря на рейтинг 18+, исходит не от самих локализаторов, а из-за прямых просьб разработчиков и издателей. Наши студии сами не прочь поматериться для колорита персонажей, но требования есть требования. Приходится обходиться банальными: мля, черт, блин, мать вашу и так далее.
Английский и русский мат имеют совершенно разную окраску и степень эмоциональности. Поэтому у нас в обиходе такое разнообразие матерных слов. Если локализатор будет пихать мат в таком же количестве, как и в оригинальном сценарии, то велика вероятность превратить дубляж в жалкое подобие Kingpin: Life of Crime. С другой стороны, полное отсутствие матерных слов в игре, тем более уж в Metro 2033, портит общую картину от происходящего. Как минимум от персонажа по имени Бурбон будешь ждать более грязный лексикон, нежели тот, что он выдает в официальной локализации.

Сведение звука и монтаж
Текст переведен, звук записан, наступает третий и последний этап: впихнуть все это в игру. Но и здесь подводных камней не избежать. Первым под раздачу попадает звукорежиссер и монтажер. Им нужно свести звук и фразы таким образом, чтобы игрок не заметил подмены языка. Для этого существуют правила тайминга и липсинга. Первое отвечает за время длительности фразы, второе — за синхронизацию звука и движения губ.
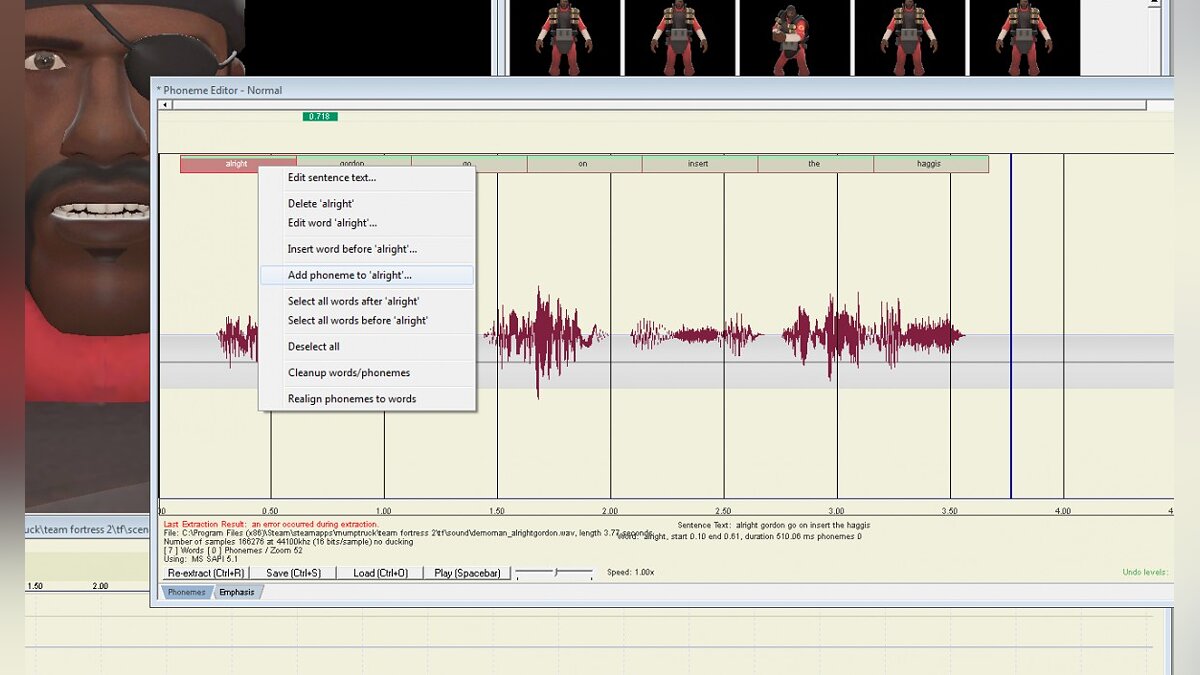 Создание липсинга при локализации на движке Source
Создание липсинга при локализации на движке Source
Проблемы возникают в основном из-за отсутствия необходимых локкитов, которые помогли бы монтажеру свести звук, подстроить губы под русскую речь, или растянуть длительность диалога на несколько секунд. Например, в Metro 2033 локализатор мог вставить полное предложение без ускорения. Это легко заметить, если сравнить продолжительность катсцен в английской и русской версиях игры. Valve дает локализаторам утилиту Faceposer, которая автоматически создает анимацию движения губ, ориентируясь на звуковой файл. Примеров заботливых разработчиков уйма, но есть и такие, которым не до трудностей локализаций. Из-за этого игроки наблюдают оборванные на полуслове диалоги, ускоренные в пять раз фразы, расхождение губ и звуков, издаваемых персонажем.
Человеческий фактор также влияет на финальный монтаж звука в игре. Звукорежиссер может попросту забить на уровень громкости, и диалоги будут звучать в три раза громче фонового звука. Кто-то не захочет обрабатывать звук и подстраивать его под окружение, вдобавок наплевательски отнесется к озвучке толпы, и каждый второй прохожий будет говорить одним и тем же голосом. Получают ли по рукам такие звукорежиссеры, нам доподлинно неизвестно.
Помимо криво смонтированной озвучки, возникают проблемы с простым текстом. При встраивании его в игру, локализаторы начинают замечать вылезшие за рамки слова, не помещающиеся буквы на иконке, перепутанные местами диалоги. Какие-то вещи исправить можно, а какие-то невозможно из-за ограничений движка.

Не всегда нашим локализаторам удается протестировать плод своих трудов, из-за строгих ограничений по времени или жанровой принадлежности игры. Пробежаться по линейному шутеру с включенными читами разработчика и просмотреть все диалоги, намного проще, чем пройти несколько раз крупную ролевую игру, где переводчикам придётся вглядываться в каждый диалог, реплику или энциклопедию. Поэтому в переводе Dragon Age: Origins так много опечаток, ошибок озвучки, запоротых дублей, непереведенных персонажей. Протестировать локализацию «быстро», невозможно в принципе, если на нее отведено несколько месяцев.
Объясните простыми словами что такое исходный код игры, пожалуйста.
Проще говоря тут есть своя иерархия:
1. Машинный код(нули и единицы)
2. Объектный код(приближенный к машинному, этакий посредник между высокими языками программирования и машинным.
3. Язык программирования высокого уровня, который понятен человеку, но не понятен компьютеру, пока не будет сконвертирован в объектный код(еще не машинный, но уже не исходный), а тот в свою очередь — уже в машинный код.
Получается три вида кода с некоторой иерархией:
1. Машинный код
2. Объектный код
3. Исходный код
То, что уже существует.