Разбор тестирования 1С:Профессионал и PMP
Правильный ответ четвертый. Для расчета оптимальных агрегатов служит кнопка Получить оптимальные агрегаты обработки Управление итогами (на первом скриншоте). Полученная информация может быть сохранена в xml-файл и загружена в конфигуратор.
- Агрегаты используются только для регистра накопления с видом Остатки
- Агрегаты используются только для регистра накопления с видом Обороты
- Верны оба варианты
- Агрегаты рассчитываются в пользовательском режиме
- Агрегаты рассчитываются в режиме Конфигуратор
- Верны оба варианты
- В пределах дня
- В пределах месяца
- В пределах квартала
- Непериодический
- Любой из вышеуказанных вариантов
- Не может быть выбрана
- Автоматически в конфигураторе на основании структуры регистра накопления
- Автоматически в режиме 1С:Предприятие на основании данных регистра накопления
- Автоматически в режиме 1С:Предприятие на основании данных таблицы итогов
- В конфигураторе
- В режиме 1С:Предприятие
- В режиме 1С:Предприятие и Конфигураторе
- Автоматически при проведении документов
- Автоматически при изменении данных в таблице регистра накопления
- При обновлении агрегатов
- При пересчете итогов
6 комментариев:
Этот комментарий был удален автором.
не по всем комбинациям измерений, а только по выбранным !РАЗРАБОТЧИКОМ!;
Опечатка
В каком режиме производится расчет агрегатов (приведение в актуальное состояние)?
Агрегаты рассчитываются с использованием специализированных механизмов, запускаемых в режиме исполнения
Агрегаты рассчитываются платформой автоматически при проведении документов
Агрегаты рассчитываются в режиме "Конфигуратор" по выполнению специализированной команды
Варианты 1 или 2 в зависимости от настройки самого агрегата
Варианты 1 или 2 или 3 в зависимости от настройки самого агрегата
Варианты 1 или 3 вне зависимости от каких-либо условий
Ответ — 1. Проверено 1с тренажер.
С какой периодичностью можно получать итоговые данных для регистров бухгалтерии?
Произвольную
Только "Месяц", периодичность предопределена платформой
Можно определить из списка предлагаемых вариантов
Ответ 3.Проверено 1с тренажер.
В режиме конфигуратора может быть выбрана следующая периодичность таблицы итогов регистра накопления:
В пределах дня
В пределах месяца
В пределах квартала
Непериодический
Любой из вышеуказанных вариантов
Не может быть выбрана
Ответ 6.Проверено 1с тренажер.
Какую периодичность хранения итоговых данных можно задать для регистров бухгалтерии?
Произвольную
Только "Месяц", периодичность предопределена платформой
Можно определить из списка предлагаемых вариантов
Конструктор агрегатов 1С
Агрегаты — это специальный механизм, реализованный в оборотных регистрах накопления и позволяющий значительно сократить время формирования отчетов, что особенно важно для больших информационных баз, содержащих сотни тысяч и миллионы записей в регистрах.
Для любого регистра может быть создано несколько агрегатов. Каждый агрегат — это специализированное хранилище, содержащее агрегированные данные регистра в различных разрезах, удобных для формирования отчетов в данной информационной базе.
Система автоматически оценивает интенсивность работы пользователей с тем или иными разрезами информации и на основе накопленной статистики выбирает оптимальный состав поддерживаемых агрегатов.
Таким образом, агрегаты рассчитываются в пользовательском режиме.
Использование агрегатов позволяет аналитикам и менеджерам анализировать имеющуюся информацию, переключаясь между различными разрезами просмотра с небольшим временем отклика системы. При этом система использует накопленные агрегированные данные и всегда обеспечивает актуальность получаемых отчетов.
Платформа 1С:Предприятие позволяет формировать итоги по регистрам накопления и регистрам бухгалтерии, сворачивая данные по всем комбинациям измерений с периодичностью в месяц (управление итогами регулируется стандартной обработкой).
Для регистров накопления есть возможность использовать вместо итогов агрегаты. В этом случае данные будут также сворачиваться, но:
- только по комбинациям измерений, выбранным разработчиком;
- с периодичностью, выбранной разработчиком (в день, месяц, квартал, полугодие, год, непериодически).
Заполнение агрегатов при изменении данных осуществляется при обновлении агрегатов с помощью регламентного задания.
В режиме 1с Предприятие механизм управления агрегатами доступен в меню «Главное меню — Все функции. — Стандартные — Управление итогами».


Конструктор агрегатов 1С
Платформа содержит специальный конструктор агрегатов, позволяющий:
- создать и настроить агрегаты, которые будет использовать регистр накопления ;
- изменять состав агрегатов и настраивать их использование.
Вызов конструктора агрегатов 1С:
- из окна редактирования оборотного регистра накопления;
- из дерева конфигурации, из контекстного меню оборотного регистра накопления.
Из окна редактирования оборотного регистра накопления:

Из дерева конфигурации, из контекстного меню оборотного регистра накопления:

Если для регистра накопления недоступен конструктор агрегатов, то необходимо изменить настройку регистра накопления «Вид регистра» — «Обороты».

Для отображения в конструкторе списка оптимальных агрегатов необходимо:
- произвести расчет оптимальных агрегатов в 1С:Предприятие (кнопка «Получить оптимальные агрегаты» обработки «Управление итогами»);
- сохранить их в xml-файл;
- загрузить их в конструкторе.

Особенности использования агрегатов 1С:
- Конструктор агрегатов предназначен для формирования агрегатов только регистров накопления.
- Конструктор агрегатов может быть вызван:
- по кнопке «Агрегаты» в окне редактирования объекта конфигурации на закладке «Данные»;
- в пределах дня;
- в пределах месяца;
- в пределах квартала;
- непериодический.

Добавить комментарий Отменить ответ
Для отправки комментария вам необходимо авторизоваться.
Этот сайт использует Akismet для борьбы со спамом. Узнайте, как обрабатываются ваши данные комментариев.
Агрегаты
Я считаю, что именно агрегаты из Domain-Driven Design лежат в основе поддерживаемых информационных систем. Однако эта концепция малоизвестна за пределами DDD-сообщества и довольно сложна для понимания, поэтому я решил написать очередной пост посвящённый агрегатам. В основном для чтобы структурировать собственное понимание агрегатов и создать «методичку» для своих команд, но и широкой общественности, я надеюсь, этот пост тоже может быть полезен.
Что такое агрегат? (TLDR)
Агрегат — это кластер сущностей и объектов-значений, объединённых общими инвариантами. Любое взаимодействие с агрегатом осуществляется через одну и только одну из его сущностей, называемую корнем агрегата.
Для того чтобы обеспечить соблюдение инвариантов, агрегат должен удовлетворять следующим требованиям:
Выступать единицей персистанса (все сущности всегда загружаются и сохраняются вместе). «Точкой входа» персистанса (загружаемым и сохраняемым объектом) является корень агрегата.
Все модификации состояния агрегата должны осуществляться через корень.
Все сущности должны входить только в один агрегат.
В объектно-ориентированном коде агрегат всегда материализуется минимум в два класса — корень агрегата и репозиторий агрегата. Внутри агрегата связи реализуются ссылками непосредственно на объекты. Между агрегатами связи реализуются через идентификаторы корней агрегатов.
Например, отчёт с непересекающимися отчётными периодами и составителем моделируется двумя агрегатами, которые на Котлине будут выглядеть так:
Почему агрегата именно два, а не один или три? Ответ на этот вопрос лежит в принципах декомпозиции модели информации системы.
Принципы декомпозиции модели информации на агрегаты
При проектировании агрегатов (как и всех других элементов ПО) следует руководствоваться принципом высокой связанности/низкой сцепленности. В случае агрегатов этот принцип выражается в соблюдении следующих ограничений:
Агрегаты не должны иметь циклических связей.
Агрегаты должны определять область жизни всех сущностей, в них входящих. Эта область определяется областью жизни корня агрегата. Некорневые сущности не могут появляться раньше корня и продолжать существовать после его удаления.
Агрегаты должны обеспечивать соблюдение инвариантов. Агрегаты предоставляют такое API, которое не позволит клиенту перевести модель в невалидное состояние.
Агрегаты должны обеспечивать возможность реализовать все операции системы так, чтобы в одной транзакции менялся (или удалялся) один агрегат. Притом речь идёт именно об изменении (в том числе в виде удаления) существующих агрегатов — создавать и читать можно сколько угодно агрегатов.
Агрегаты должны быть минимального необходимого размера. Имеется в виду и количество типов сущностей в агрегате, и количество экземпляров сущностей и их размер в байтах.
Агрегаты должны храниться целиком в одной системе хранения данных на одном узле. Разные агрегаты одной системы могут храниться на разных узлах или в разных хранилищах.
Агрегаты могут ссылаться на другие агрегаты только через идентификаторы корней. Внутри агрегата сущности могут свободно ссылаться друг на друга.
Так вот, почему агрегатов всё-таки именно два? Потому что отчёты и составители ценны сами по себе и имеют независимые жизненные циклы. А периоды не имеют смысла без отчёта и инвариант отсутствия пересечения определяется на кластере объектов отчёта и его отчётных периодов.
Методика декомпозиции модели информации на агрегаты
Я предпочитаю идти от обратного и на первом этапе считать каждую сущность отдельным агрегатом, а потом искать причины для объединения сущностей в агрегаты. Поэтому первой версией разбиения информации на агрегаты является сама ER-диаграмма.
Затем я ищу инварианты системы. Самый простой и часто встречаемый инвариант — область жизни одной сущности (А) не должна выходить за пределы области жизни другой сущности (Б). В этом случае сущности А и Б нужно объединить в агрегат с Б в качестве корня.
Но самые важные инварианты определяются конкретными людьми в конкретном контексте и для их выявления не существует универсального алгоритма на базе технических вводных. Чтобы выявить самые важные инварианты я обращаюсь к экспертам — заказчикам, пользователям, владельцам продукта, руководителям проектов,
аналитикам и т.д. Зачастую эксперты самостоятельно не могут сформулировать инварианты, и им необходимо помочь, предлагая свои версии и задавая наводящие вопросы (например, «могут ли пересекаться отчётные периоды?»). Конкретные техники и способы помощи экспертам подробно расписаны в книгах по DDD.
Действительно важные инварианты бизнес так или иначе озвучит — важно их услышать. Если не услышите в процессе разработки, то точно услышите, когда инвариант будет нарушен в промышленной эксплуатации с последствиями для бизнеса:)
Получив список инвариантов, я выбираю те, что затрагивают несколько типов или экземпляров сущностей. Сущности, которые участвуют в обеспечении одного инварианта, объединяю в агрегаты. Если речь идёт о разных типах, то в агрегат я объеднияю сами эти сущности. Если речь идёт о разных экземплярах одной сущности, то я присоединяю их списком к одной из существующих или специально созданной для этого сущности.
Затем я проверяю получившиеся агрегаты на соответствие принципам.
Принцип акцикличных агрегатов я сейчас нарушаю крайне редко, а нарушения сразу же видны на ER-диаграмме. При разбиении циклов я пользуюсь принципом стабильных зависимостей и удаляю ссылку из более «стабильного» агрегата. Стабильность определяется по значимости для бизнеса, вероятности изменений в будущем и количеству входящих связей. Значимость для бизнеса и вероятность изменений определяются посредством гадания на кофейной гуще.
Что такое диаграмма эффектов?
Диаграмма эффектов — это моё изобретение, предназначенное для помощи в декомпозиции модели информации на агрегаты и в декомпозиции системы на модули. Сейчас диаграмма эффектов толком не описана — есть микропост с ранним описанием подхода к декомпозиции в котором есть пара ссылок на открытые статьи с описанием похожих диаграмм и черновик поста о диаграмме эффектов.
Чтобы проверить принцип изменения одного агрегата в одной транзакции, я строю диаграмму эффектов для того чтобы увидеть операции, которые меняют несколько агрегатов. С такими агрегатами можно поступить по-разному:
Если агрегаты всегда меняются вместе и размер позволяет — объединить их в один.
Если в одной операции смешались разные ответственности и есть возможность — разбить операцию на две.
Если в одной операции смешались разные ответственности, но разбиение операции невозможно или ухудшает дизайн — разбить изменения агрегатов на разные транзакции.
В первую очередь стоит посмотреть на вариант с использованием шины событий. В этом случае в первой транзакции остаётся изменение первого агрегата и генерация события, а в изменения остальных агрегатов уходят в транзакции обработчиков события.
Если разбиение через события приводит к появлению каскада событий, то можно просто разбить операцию на несколько транзакций.
Если я уверен, что операция имеет высокую связанность, а конкуренция за агрегат низкая (он меняется редко или только одним пользователем) — оставить всё как есть.
Если выполнять декомпозицию по описанной выше методике, то агрегаты с большим количеством видов сущностей у меня ни разу не появлялись. Поэтому для проверки принципа малых агрегатов остаётся удостоверится в отсутствии «больших» атрибутов и связей «один к действительно многому».
«Большие» тексты и массивы байт (картинки) я всегда выношу в отдельные агрегаты, даже когда это приводит к нарушениям принципов общей области жизни и изменения одного агрегата в одной транзакции. «Большой» — понятие относительное, и я выделяю атрибуты, если математическое ожидание их размера превышает
«Действительно многие» связи я также всегда выношу в отдельные агрегаты вопреки
остальным принципам. «Действительно многие» — тоже понятие относительное, и я выношу связи, когда математическое ожидание количества связанных объектов превышает
Для проверки всех остальных принципов у меня нет устоявшихся инструментария и эвристик и их нарушение я ищу «методом вдумчивого взгляда».
Процесс «проверить-подрихтовать-обновить диаграммы» я повторяю до тех пор, пока не получу результат, проходящий проверку.
Частые ошибки проектирования агрегатов
Моделирование лишних связей
Самой распространённой ошибкой является добавление лишних ссылок между объектами. Предельный случай этой ошибки — модель связного графа объектов.
Но и в контексте проектирования агрегатов можно внести в модель лишние связи. Чаще всего причинами внесения лишних связей являются:
удобство навигации — связь добавляется, чтобы была возможность добраться до объекта А, имея на руках объект Б.
отражение реальности — связь добавляется потому, что «в реальности» сущности связаны.
отражение модели данных — связь добавляется потому, что в логической схеме реляционной БД есть соответствующий атрибут и внешний ключ.
отражение пользовательского интерфейса — связь добавляется потому, что в UI в форме ввода или вывода данных, участвуют данные разных сущностей.
Но напомню, что единственной причиной добавления ссылки на объект является вхождение объекта в агрегат, а единственной причиной включения объекта в агрегат является его участие в обеспечении инварианта. Поэтому если связь не требуется для обеспечения инварианта, то её включение необходимо дважды обдумать. Потому что лишние связи ведут к повышению сцепленности дизайна и как следствие усложнению системы и деградации производительности.
Анемичная доменная модель
Ещё одной распространённой ошибкой является анемичная доменная модель. Анемичная доменная модель характеризуется в первую очередь сущностями, у которых все свойства доступны для чтения и записи через геттеры и сеттеры. При этом всё поведение сущности ограничивается геттерами и сеттерами. Эта ошибка ведёт к утери возможности обеспечить соблюдение инвариантов.
Кроме того, последствием анемичной модели становится погребение существенных для агрегата трансформаций в методах сервисов приложения. Что влечёт за собой жёсткую сцепку трансформаций и ввода-вывода. Из-за чего:
Усложняется задача тестирования трансформаций.
Снижается переиспользуемость трансформаций.
Усложняется задача понимания кода из-за смешения разных уровней абстракции в сервисе приложения.
Давайте сравним решения одной и той же задачи с помощью анемичной и «полнокровной» доменных моделей.
В качестве задачи возьмём систему хранения информации о торговле на бирже крипто-валют. В центре этой системы находятся «торги по символу» — торги между парой крипто-валют.
Требования к системе следующие:
Каждый пользователь по каждой паре может вести торги с использованием «грида» — по сути, набора значений параметров алгоритма торговли.
В каждый момент времени для каждого символа пользователя может быть активен только один из гридов символа.
Гриды уникально идентифицируются своим именем.
Для каждого грида хранится статистика по торгам с его участием (в примере — только доход).
Статистика может меняться только у активного грида.
Каждый пользователь может вести торги одновременно по нулю и более символов.
Так же есть ограничение на API системы: обновление информации осуществляется посредством отправки клиентом списка активных в данный момент пар и их гридов.
Реализация этой задачи с анемичной доменной моделью будет выглядеть примерно так:
Такую реализацию будет относительно сложно протестировать — надо будет либо сетапить и проверять состояние БД, либо использовать моки и делать тесты хрупким и зависящим от деталей реализации.
Также здесь в одном методе смешаны и работа с БД (1) и бизнес-правила (2).
Эти две проблемы можно решить посредством вынесения бизнес-правил в утилитарный метод. Однако это не решит основную проблему — с таким подходом невозможно защитить инварианты. Ничего не остановит клиентский код от удаления активного грида из trading.grids . Как и от изменения статистики по неактивному гриду.
Для того чтобы защитить инварианты, необходимо большую часть логики перенести в доменную модель. Также необходимо исключить возможность неконтролируемых операций записи.
Если оставаться в парадигме изменяемой модели данных, то это можно сделать путём сокращения области видимости сеттеров до внутренней ( internal ) в случае Котлина. Но тогда придётся выделять агрегаты в разные модули, что очень не удобно.
В том числе (но не только) по этому, я рекомендую пойти простым путём: сделать сущности неизменяемыми, с закрытым конструктором и опубликованным фабричным методом вместо него, который будет гарантировать соблюдение инвариантов.
Такая реализация гарантирует, что любые модификации в данных должны будут пройти через CustomerSymbols . А так как CustomerSymbols является единицей работы с БД, это гарантирует, что в БД не попадут никакие данные в обход кода контроля инвариантов в модели.
«Полнокровная» модель явно очерчивает список доступных операций и повышает их
видимость — все операции над агрегатом находится рядом с агрегатом, а не разбросаны по сервисам и утилитарным методам.
Наконец, вся бизнес логика, которую надо покрыть полноценным набором тестов, ушла в чистую доменную модель которую очень легко тестировать. А код с эффектами — updateCustomerSymbols — стал тривиальным и его достаточно протестировать одним интеграционным, е2е или сценарным тестом.
Всё вместе — гарантия соблюдения инвариантов, упрощение анализа операций записи и упрощение тестирования — позволяет существенно уменьшить количество ошибок и регрессий и, как следствие, сократить стоимость разработки в длительной перспективе.
Как программировать связи?
Связи внутри агрегата программируются свойствами со ссылками на объекты (a), а между агрегатами — свойствами с идентификаторами корней агрегатов (b):
Как защитить инварианты?
Для того чтобы гарантировать сохранность своих инвариантов, агрегат должен не позволять внешним клиентам менять состояние напрямую. Для достижения этого необходимо следовать принципу «Tell Don’t Ask». В случае агрегатов это означает предоставление корнем агрегата API внесения изменений вместо API получения изменяемых объектов внутренних сущностей.
При этом для получения информации об агрегате есть несколько подходов:
Использовать неизменяемые классы для моделирования сущностей агрегатов. Объекты таких классов можно безопасно передавать клиентам, поэтому агрегат может предоставить прямой доступ к своим частям.
Плюсы: минимум дополнительного кода, хорошо масштабируется по количеству методов запроса информации.
Минусы: повышает сцепленность между клиентами и агрегатом.
Предоставлять API в том числе для получения информации только на уровне корня агрегата. В этом случае внутренние сущности вообще не попадают в публичное API агрегата.
Плюсы: полностью скрывает устройство агрегата и минимизирует связанность между клиентами и агрегатом.
Минусы: плохо масштабируется по количеству методов запроса информации.
Использовать копии изменяемых объектов. Этот подход похож на первый, тем что даёт клиентам доступ к частям агрегата, но клиентам выдаются не сами объекты частей, а их копии.
Плюсы: может быть использован в случае, когда нет возможности сделать объекты неизменяемыми.
Минусы: те же, что и у первого подхода, и необходимость в дополнительном коде копирования объектов в каждом геттере и, как следствие, большей нагрузки на сборщика мусора.
Использовать «read-only» представления. Похож на третий подход, но вместо копий предполагается возвращать «read-only» представления изменяемых сущностей.
Плюсы: нет необходимости в коде копирования объектов и снижение нагрузки на сборщика мусора.
Минусы: требует описания дополнительных интерфейсов для представлений и не очень надёжен — никто не запретит клиенту привести объект к изменяемому типу или поменять его через механизм рефлексии.
Я сам использую преимущественно первый подход, подключая второй в случаях, когда вижу необходимость в сокрытии структуры агрегата.
Как реализовать выборку данных для UI?
Существует несколько походов, и у каждого из них свои плюсы и минусы.
Сборка DTO из агрегатов. Заключается в том, чтобы вытащить нужные агрегаты из репозиториев и собрать из них DTO.
Плюсы — минимальная сцепленность модулей, минимум дополнительного кода
Минусы — потенциальные проблемы с производительностью из-за нескольких запросов в БД и больше ручной работы по добавлению зависимостей на репозитории и чтению данных из них.
Сборка DPO из агрегатов. По сути то же, что и первый вариант, только клиенту выдаётся Data Payload Object (DPO), вместо DTO. DPO — это набор агрегатов, из которого клиент сам строит нужные ему структуры.
Плюсы — минимальная сцепленность модулей, не нужен код для маппинга агрегатов в клиентские структуры.
Минусы — клиенту будут возвращаться лишние данные, что может плохо сказаться на эффективности и безопасности системы.
Отдельные модели для записи и чтения. В дополнение к модели для записи (агрегаты), создаётся дополнительная денормализованная модель для чтения.
Плюсы — эффективная работа с БД и создание DTO средствами ORM.
Минусы — неявная сцепленность модуля генерации DTO с деталями реализации всех модулей агрегатов, в два раза больше кода для описания модели данных.
Сборка DTO в СУБД. Современные СУБД (PostgreSQL, в частности) имеют встроенные средства для формирования JSON и позволяют собрать финальную DTO непосредственно SQL-запросом.
Плюсы — самая эффективная работа с БД.
Минусы — завязка на диалект определённой СУБД, менее удобный инструментарий для работы с SQL-запросами (чем с кодом на Kotlin, например), примитивные средства переиспользования кода и создания абстракций в самом SQL.
Варианты 1-3 подробно рассмотрены в книгах по DDD, вариант 4 хорошо описан в посте Лукаса Едера Stop Mapping Stuff in Your Middleware. Use SQL’s XML or JSON Operators Instead
Я сейчас в качестве варианта по умолчанию использую первый, а третий или четвёртый задействую в «горячем» коде. Второй вариант я пока что ни разу не использовал.
Зачем объединять сущности в агрегаты?
Для того чтобы обеспечить выполнение инварианта, затрагивающего несколько
сущностей. Частым примером такого инварианта являются слабые сущности — сущности
область жизни которых ограничена областью жизни другой сущности.
Почему агрегаты должны быть маленькими?
Из соображений производительности. Так как агрегаты являются единицей персистанса, большие агрегаты приведут к передаче больших объёмов данных по сети. И так как агрегаты являются единицей согласованности, большие агрегаты приведут к «большим» транзакциям (по количеству затронутых объектов и длительности), что повлечёт за собой большое количество конфликтующих транзакций. Это, в свою очередь, станет причиной либо ошибкам согласованности, либо большим накладным расходам на синхронизацию транзакций.
Когда не стоит объединять сущности в агрегаты?
Тогда, когда это приведёт к большим агрегатам. Например, пользователя, его фото и его комментарии лучше разделить по разным агрегатам, не смотря на то, что фото и комментарии являются слабыми сущностями. Фото — просто в силу большого размера. Комментарии — в силу их неограниченного роста.
Когда можно включать в агрегат много видов сущностей?
Агрегат может включать много видов сущностей, при соблюдении двух условий:
Агрегат преимущественно изменяется одним пользователем — исключает проблемы с синхронизацией.
Агрегат остаётся ограниченным по размеру в байтах — исключает проблемы с производительностью.
Почему в транзакции можно менять только один агрегат?
Во-первых — по определению. Агрегат определяет границы согласованности.
Во-вторых, потому что много маленьких агрегатов — это де-факто один большой агрегат со всеми вытекающими проблемами с синхронизацией и производительностью.
В-третьих, агрегаты могут храниться на разных машинах. А по определению агрегата это значит, что придётся иметь дело с распределёнными транзакциями. С которыми я бы предпочёл иметь дело в последнюю очередь.
Как обеспечить выполнение принципа «модификация одного агрегата в одной транзакции»?
В первую очередь, необходимо понять действительно ли эти модификации
должны быть строго согласованы, или можно обойтись согласованностью в
конечном итоге. Для этого автор Implementing Domain-Driven Design предлагает следующий алгоритм:
если обеспечение согласованности изменений является ответственностью пользователя, инициировавшего выполнение операции — то модификации должны быть строго согласованы.
иначе — можно обойтись согласованностью в конечном итоге.
Если получилось что, модификации должны быть строго согласованы, то это значит, что вы «открыли» новый инвариант, и новый агрегат для его обеспечения. Если при этом агрегат становится большим — надо взвешивать плюсы и минусы и либо оставлять большой агрегат, либо возвращаться на этап проектирования агрегатов и операций системы и искать новое решение. Возможно несколько потенциальных решений:
«Закрыть» этот неудобный инвариант и перейти к согласованности в конечном итоге.
Убрать из агрегата «лишние» сущности, которые были включены в него по причинам отличным от обеспечения инварианта.
Разбить большой агрегат, новым способом, который обеспечит соблюдение всех инвариантов. Возможно для этого придётся отказаться от некоторых инвариантов.
Если же модификации могут быть согласованными в конечном итоге, то операцию необходимо разбить на две. Для этого надо разбить код на два транзакционных метода в слое сервисов приложения. Затем либо оба этих метода публикуются для клиентов, либо они связываются через публикацию доменного события первым методом и его обработку вторым.
Заключение
Агрегаты — действительно сложная тема:
Clustering Entities (5) and Value Objects (6) into an Aggregate with a carefully crafted consistency boundary may at first seem like quick work, but among all DDD tactical guidance, this pattern is one of the least well understood.
— Vaughn Vernon, Implementing Domain-Driven Design
и её невозможно полностью понять, прочитав один пост.
Но я постарался собрать в этом посте необходимый минимум информации для того, чтобы спроектировать первый агрегат.
Управление итогами и агрегатами
Система позволяет администрировать итоги регистров накопления и бухгалтерии, агрегаты оборотных регистров накопления.
Регистры системы предназначены для хранения и обработки информации, отражающей деятельность предприятия. В регистрах хранится информация об изменении состояний объектов предметной области (документов, справочников) или другая, не отражающаяся непосредственно в этих объектах, например, информация о курсах валют.
Агрегаты — это специальный механизм, реализованный в оборотных регистрах накопления. Для любого регистра может быть создано несколько агрегатов. Каждый агрегат — это специализированное хранилище, содержащее агрегированные данные регистра в различных разрезах, удобных для формирования отчетов в конкретной информационной базе. Использование агрегатов позволяет значительно сократить время формирования отчетов, что важно для больших информационных баз.
С более подробной информацией о регистрах и агрегатах можно ознакомиться в книге «1С: Предприятие 8.3. Руководство разработчика».
Администрирование итогов и агрегатов осуществляется в форме «Управление итогами и агрегатами», которая вызывается из пункта «Администрирование», расположенного на панели действий подсистемы «Администрирование», раздел «Управление итогам и агрегатами».
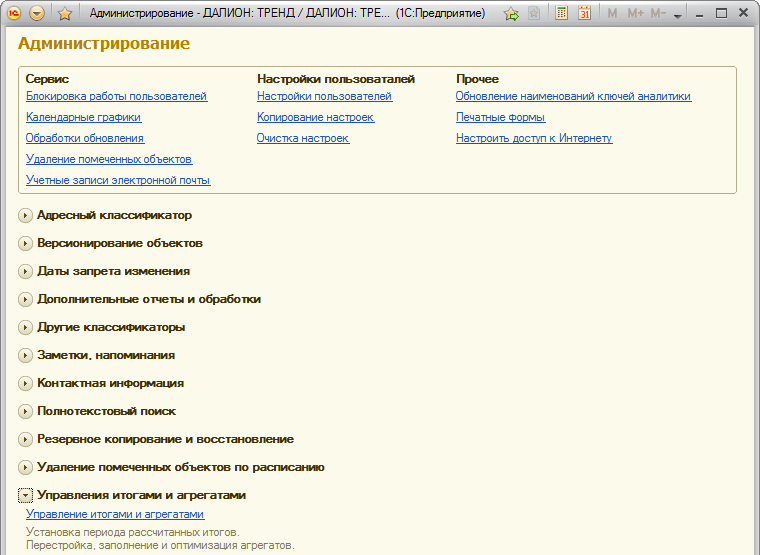
Форма поддерживает два режима работы:
Часто используемые возможности — режим предоставляет простые средства для выполнения наиболее часто используемых действий с итогами регистров. Режим позволяет «одним нажатием» выполнить действия, возникающие при обслуживании системы.
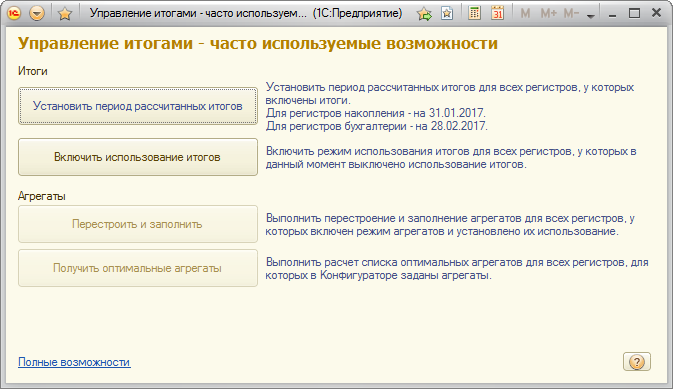
В этом режиме администратору доступны команды:
Для администрирования регистров:
- Установитьпериодрассчитанныхитогов — команда выполняет установку периода рассчитанных итогов для всех регистров накопления и бухгалтерии с включенными итогами. Для регистров накопления — на конец предыдущего месяца, для регистров бухгалтерии — на конец текущего месяца. Команду можно использовать в начале каждого месяца для повышения производительности регистров.
- Включитьиспользованиеитогов — команда включает использование итогов для всех регистров, у которых этот режим выключен (например, в результате аварийного завершения какой-либо процедуры, отключающей использование итогов).
Для администрирования агрегатов (настраивается дополнительно):
- Перестроитьизаполнить — команда выполняет операцию перестроения использования агрегатов и выполняет заполнение агрегатов. Операция выполняется для всех оборотных регистров накопления, для которых включен режим агрегатов и установлено их использование. Операция может выполняться продолжительное время. Операцию, как правило, нужно выполнять периодически, для этого можно воспользоваться регламентным заданием.
- Получитьоптимальныеагрегаты — команда позволяет получить список оптимальных агрегатов для всех оборотных регистров накопления, для которых в Конфигураторе заданы агрегаты. В процессе выполнения команды будет запрошен каталог, куда будут сохранены xml-файлы со списками оптимальных агрегатов. Каждый файл будет назван именем соответствующего регистра. Файлы используются для загрузки и создания оптимальных агрегатов в Конфигураторе. При загрузке оптимальных агрегатов может возникнуть ситуация, когда необходимо будет изменить список оптимальных агрегатов, а для этого потребуется снять с поддержки конфигурацию. Операция не является регулярной. Операция является наиболее ресурсоемкой и продолжительной, поэтому рекомендуется выполнять ее в случаях, когда с ИБ не работают другие пользователи.
Выполнение расчета оптимальных агрегатов может потребоваться в следующих случаях:
- существенное падение скорости формирования отчетов на текущем списке агрегатов;
- существенное изменение характера хранимых данных в ИБ;
- существенное изменение характера отчетов, которыми пользуются пользователи.
Полные возможности — предоставляет полный доступ к возможностям управления итогами и агрегатами системы. Режим позволяет выполнять все операции как с одним регистром, так и со списком регистров.
Режим «Полные возможности» позволяет получить доступ ко всем инструментам администрирования итогов регистров (закладка «Итоги») и агрегатов (закладка «Агрегаты»). В режиме полных возможностей доступен режим множественного выделения. Любая команда применяется к выделенным объектам, либо к тому, на котором установлен курсор.
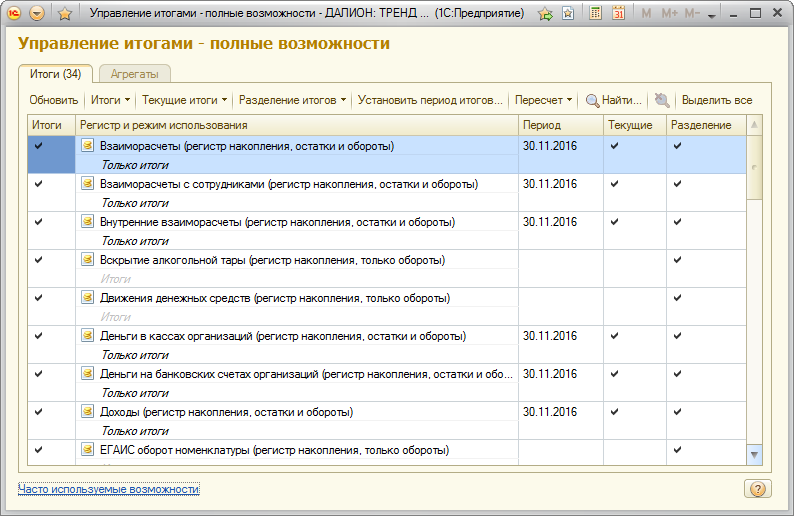
На закладке «Итоги» представлен список регистров накопления и бухгалтерии. В список попадают те регистры, у которых для текущего пользователя установлено право «Управление итогами».
Список показывает текущее состояние регистров системы.
Флажками отмечены те режимы, которые в данный момент включены для каждого регистра:
- Итоги — состояние использования итогов. Если флажок установлен, то для регистра ведутся итоги, отсутствие флажка означает, что итоги по регистру не рассчитываются;
- Периодитогов — текущая дата актуальности итогов;
- Текущиеитоги — состояние использования текущих итогов. Наличие флажка означает, что для регистра рассчитываются не только общие итоги на указанную дату, но еще и оперативные итоги на дату последнего движения, отсутствие флажка — что оперативные итоги по регистру не рассчитываются. Этот режим имеет смысл применять для регистров, движения которых анализируются в оперативном учете перед проведением документов;
- Разделениеитогов — состояние режима разделения итогов. наличие флажка означает, что для регистра задействован механизм разделителя итогов, который обеспечивает более высокую параллельность работы при записи в регистр.
Серым цветом отмечены те режимы, которые невозможно изменить при текущем состоянии системы. Например, для регистра накопления «Закупки» нельзя включить разделение итогов, так как этот режим не включен для регистра в Конфигураторе.
На закладке «Итоги» доступны следующие команды:
- Итоги — включает и выключает использование итогов;
- Текущиеитоги — включает и выключает использование текущих итогов;
- Разделениеитогов — включает и выключает разделение итогов;
- Установитьпериодитогов — устанавливает выбранный период рассчитанных итогов;
- Пересчет — выполняет пересчет итогов, текущих итогов либо выполняет пересчет итогов за выбранный период.
На закладке «Агрегаты» в верхнем списке содержится перечень оборотных регистров накопления, для которых в Конфигураторе заданы агрегаты, а в нижнем списке — перечень этих агрегатов. В списке агрегатов содержится признак использования агрегата и статистическая информация о нем. В список попадают те оборотные регистры накопления, у которых для текущего пользователя установлено право Управление итогами.
На закладке «Агрегаты» доступны следующие команды:
- Режим — устанавливает режима использования регистра: итоги или агрегаты;
- Использование — включает и выключает использование агрегатов;
- Перестроить — выполняет перестроение использования агрегатов;
- Обновить — выполняет заполнение агрегатов;
- Очистить — выполняет очистку агрегатов;
- Оптимальные. — создает список оптимальных агрегатов. В процессе выполнения команды будет запрошен каталог, куда будут сохранены xml-файлы со списками оптимальных агрегатов. Каждый файл будет назван именем соответствующего регистра. После выполнения команды, в списке регистров жирным шрифтом будут выделены те регистры, для которых необходимо создать оптимальные агрегаты в Конфигураторе.
Для переключения режимов служит команда в правом нижнем углу формы. Форма запоминает режим открытия.
Некоторые операции с регистрами и агрегатами можно выполнять по заданному расписанию с помощью регламентных заданий.
Ряд операций с регистрами и агрегатами система позволяет выполнять в автоматическом режиме по определенному расписанию. Для этого администратор с помощью обработки «Регламентные и фоновые задания» может настроить следующие регламентные задания:
- «Обновление агрегатов» — регламентное задание переносит данные из таблиц движений регистров в соответствующие таблицы агрегатов. Переносятся те движения, которые были созданы в таблице движений после предыдущего обновления агрегатов. Чем больше данных вводится в ИБ в течение дня, тем чаще в течение дня должно происходить обновление агрегатов;
- «Перестроение агрегатов» — регламентное задание включает или выключает использование того или иного агрегата. В зависимости от характера вносимых данных в ИБ, а также от динамики изменения данных, которые выводятся в отчетах, рекомендуется выполнять операцию с периодичностью раз в день, неделю, месяц. Необходимо перестраивать агрегаты чаще, если, например, в ИБ постоянно вносится много новых данных или если резко меняется характер отчетов, которыми пользуются пользователи;
- «Установка периода рассчитанных итогов» — переносит период рассчитанных итогов на начало текущего месяца. Операция позволяет повысить скорость формирования отчетов. Рекомендуется задавать период запуска раз в месяц.
С более подробной информацией по работе с регламентными заданиями можно ознакомиться в разделе «Регламентные и фоновые задания».
Для работы с формой у администратора должна быть установлена роль «Полные права».