Коллизии HashCode
Представьте, вы пишите мессенжер или почтовый клинт. Вам придется работать с кучей повторяющихся строковых значений. Например в чате — какой-то влюбленный Вася может спамить десятки аналогичных признаний в любви своей даме сердца Насте. Но мы то знаем, что все Насти шлю** Наверняка мы захотим как-то кэшировать эти сообщения. Для этого подойдет HashMap или HashSet, например. Все знают, что эти структуры данных, ссылаются на хэш значение объекта, которое не бесконечно, а ограничено 32 битами. Но проблемы могут начаться уже с пары строк.
Пример такой коллизии:
Вообще если длина строк одинаковая и выполняется:
то, хэши всегда будут одинаковыми, не буду вдаваться в подробности почему так 😀
Окей, хэши могут быть одинаковыми на ровном месте, но по какому принципу они рассчитываются?
Стандартная реализация hashCode
Посмотри сгенерированный idea hashCode() для простого POJO класса.
У String, кстати свой алгоритм: h(s)=∑(s[index] * 31 ^(n-1-index)) Смысл тот же, только проходим по всем char
Как вы заметили везде используется это непонятное число 31. Вопрос: А че не 41 или 97, например?
А по каким критериям оно отбирается?
- Число должно быть простым и нечетным, чтобы уменьшить вероятность коллизий.
- Число должно занимать мало места в памяти
- Умножение должно выполняться быстро
Оказывается 31 идеальный кандидат ведь:
- Оно простое и нечетное
- Занимает всего 1 байт в памяти
- Уго умножение можно заменить на быстрый побитовой сдвиг. 31 * i == (i << 5) — i
PS: А че за (i << x) — i ?
Побитовой сдвиг влево на x позиций. Работает точно также как умножить какое-то число на 2 x раз.
Вернемся к сути.
Окей, выяснили, по какому принципу считается HashCode и что в любой момент может произойти коллизия и данные перетрутся. Так че делать?
Да ничего, HashMap и HashSet самоcтоятельно обрабытывают такие ситуации. Важно только правильно переопределить метод equals(o) у класса.
Логика работы такая:
Кладем в список объект по ключу “cat”
Кладем в него другой по этому же ключу
HashMap/Set проверяет равны ли эти объекты в методе equals
Если равны — заменяет, если нет, создает в этой ячейке связный список, а например в седьмой джаве бакет в HashMap, при появлении в нём более семи объектов, меняет начинку со связного списка на дерево.
Важно помнить, что получение элемента из связного списка работает за время O(n), и если колиизий наберется много, скорость hash таблицы станет уже далеко не константной.
Поэтому если все же решили использовать String в качестве ключа, можно за основу брать 2 простых числа, скажем 17 и 37. Ребята из Project Lombok придумали здесь
Минуточку
Переопределил я hashCode() , но как-же теперь JVM узнает, на какой адрес в памяти ссылается этот объект?
На самом деле у каждого объекта есть идентификационный хеш (identity hash code). Если класс переопределил hashCode() , всегда можно вызвать System.identityHashCode(o) .
Да и вообще, hashCode() не возвращает какой-либо адрес объекта в памяти, что бы это не значило. В версиях java 6 и 7 это случайно генерируемое число. В версиях 8 и 9 это число, полученное на основании состояния потока. Подробнее об этом можно почитать здесь
How is collision handled in HashMap?
![]()
This is a popular interview data structure question for software engineers. Most of you might already know what is hash collision, and probably know one or two popular methods that are used to handle it. Today I’m going to organize all the methods I found from various resources for collision handling, and write some python3 code for the two most popular methods.
Some background for beginners
What is HashMap?
Hashmap is a data structure that implements an associative array abstract data type, a structure that can map keys to values. A hashmap uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found.
What is a hash function?
A hash function is any function that can be used to map data of arbitrary size onto data of a fixed size. The values returned by a hash function are called hash values, hash codes, digests, or simply hashes. Then this value can be used to locate the value for the data input as a key.
What is hash collision?
The situation when distinct keys processed by the hash function return the same hash value, we call it hash collision. It happens for sure if the number of elements added is larger than the current size of the hashmap.
Why hash collision must be handled?
When the hash function returns the same hash for two distinct data, we won’t know which value it should be if for the same hash we only store one value. Assume we have an array with a size of 10, has function is defined as return the mod(key, 10), for (key, value) pair (2, “Hello”), we store at array index 2, the value is “Hello”, now if we insert (12, “World”) to the hashmap, mod(12, 10) also return 2. If this collision is not handled properly, “Hello” is replaced with “World”, the hashmap will get “World” for key 2, which is not acceptable.
Внутренняя работа HashMap в Java
[примечание от автора перевода] Перевод был выполнен для собственных нужд, но если кому -то это окажется полезным, значит мир стал хоть немного, но лучше! Оригинальная статья — Internal Working of HashMap in Java
В этой статье мы увидим, как изнутри работают методы get и put в коллекции HashMap. Какие операции выполняются. Как происходит хеширование. Как значение извлекается по ключу. Как хранятся пары ключ-значение.
Как и в предыдущей статье, HashMap содержит массив Node и Node может представлять класс, содержащий следующие объекты:
- int — хэш
- K — ключ
- V — значение
- Node — следующий элемент
Теперь мы увидим, как все это работает. Для начала мы рассмотрим процесс хеширования.
Хэширование
Хэширование -это процесс преобразования объекта в целочисленную форму, выполняется с помощью метода hashCode(). Очень важно правильно реализовать метод hashCode() для обеспечения лучшей производительности класса HashMap.
Здесь я использую свой собственный класс Key и таким образом могу переопределить метод hashCode() для демонстрации различных сценариев. Мой класс Key:
Здесь переопределенный метод hashCode() возвращает ASCII код первого символа строки. Таким образом, если первые символы строки одинаковые, то и хэш коды будут одинаковыми. Не стоит использовать подобную логику в своих программах.
Этот код создан исключительно для демонстрации. Поскольку HashCode допускает ключ типа null, хэш код null всегда будет равен 0.
Метод hashCode()
Метод hashCode() используется для получения хэш кода объекта. Метод hashCode() класса Object возвращает ссылку памяти объекта в целочисленной форме (идентификационный хеш (identity hash code)). Сигнатура метода public native hashCode() . Это говорит о том, что метод реализован как нативный, поскольку в java нет какого -то метода позволяющего получить ссылку на объект. Допускается определять собственную реализацию метода hashCode(). В классе HashMap метод hashCode() используется для вычисления корзины (bucket) и следовательно вычисления индекса.
Метод equals()
Метод equals используется для проверки двух объектов на равенство. Метод реализованн в классе Object. Вы можете переопределить его в своем собственном классе. В классе HashMap метод equals() используется для проверки равенства ключей. В случае, если ключи равны, метод equals() возвращает true, иначе false.
Корзины (Buckets)
Bucket -это единственный элемент массива HashMap. Он используется для хранения узлов (Nodes). Два или более узла могут иметь один и тот -же bucket. В этом случае для связи узлов используется структура данных связанный список. Bucket -ы различаются по ёмкости (свойство capacity). Отношение между bucket и capacity выглядит следующим образом:
Один bucket может иметь более, чем один узел, это зависит от реализации метода hashCode(). Чем лучше реализованн ваш метод hashCode(), тем лучше будут использоваться ваши bucket -ы.
Вычисление индекса в HashMap
Хэш код ключа может быть достаточно большим для создания массива. Сгенерированный хэш код может быть в диапазоне целочисленного типа и если мы создадим массив такого размера, то легко получим исключение outOfMemoryException. Потому мы генерируем индекс для минимизации размера массива. По сути для вычисления индекса выполняется следующая операция:
где n равна числу bucket или значению длины массива. В нашем примере я рассматриваю n, как значение по умолчанию равное 16.
- изначально пустой hashMap: здесь размер hashmap равен 16:
HashMap: 
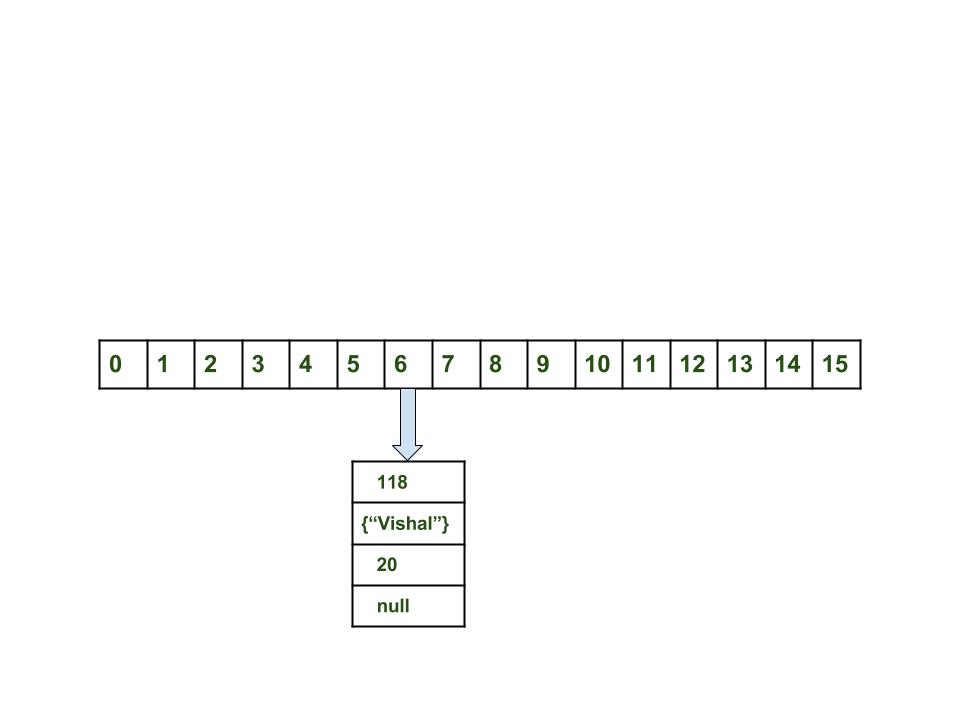
- вставка пар Ключ — Значение: добавить одну пару ключ — значение в конец HashMap
Вычислить значение ключа <"vishal">. Оно будет сгенерированно, как 118.
Вычислить индекс с помощью метода index , который будет равен 6.
Создать объект node.
Поместить объект в позицию с индексом 6, если место свободно.
Теперь HashMap выглядит примерно так:
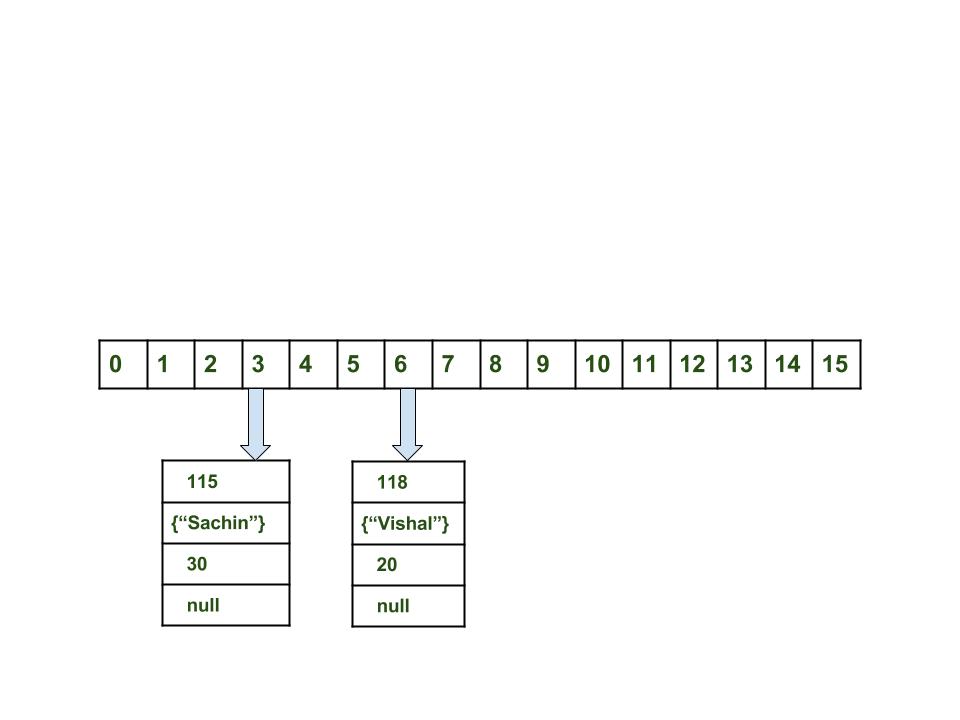
- добавление другой пары ключ — значение: теперь добавим другую пару
Вычислить значение ключа <"sachin">. Оно будет сгенерированно, как 115.
Вычислить индекс с помощью метода index , который будет равен 3.
Создать объект node.
Поместить объект в позицию с индексом 3, если место свободно.
Теперь HashMap выглядит примерно так:
- в случае возникновения коллизий: теперь добавим другую пару
Вычислить значение ключа <"vaibhav">. Оно будет сгенерированно, как 118.
Вычислить индекс с помощью метода index , который будет равен 6.
Создать объект node.
Поместить объект в позицию с индексом 6, если место свободно.
В данном случае в позиции с индексом 6 уже существует другой объект, этот случай называется коллизией.
В таком случае проверям с помощью методов hashCode() и equals(), что оба ключа одинаковы.
Если ключи одинаковы, заменить текущее значение новым.
Иначе связать новый и старый объекты с помощью структуры данных «связанный список», указав ссылку на следующий объект в текущем и сохранить оба под индексом 6.
Теперь HashMap выглядит примерно так:
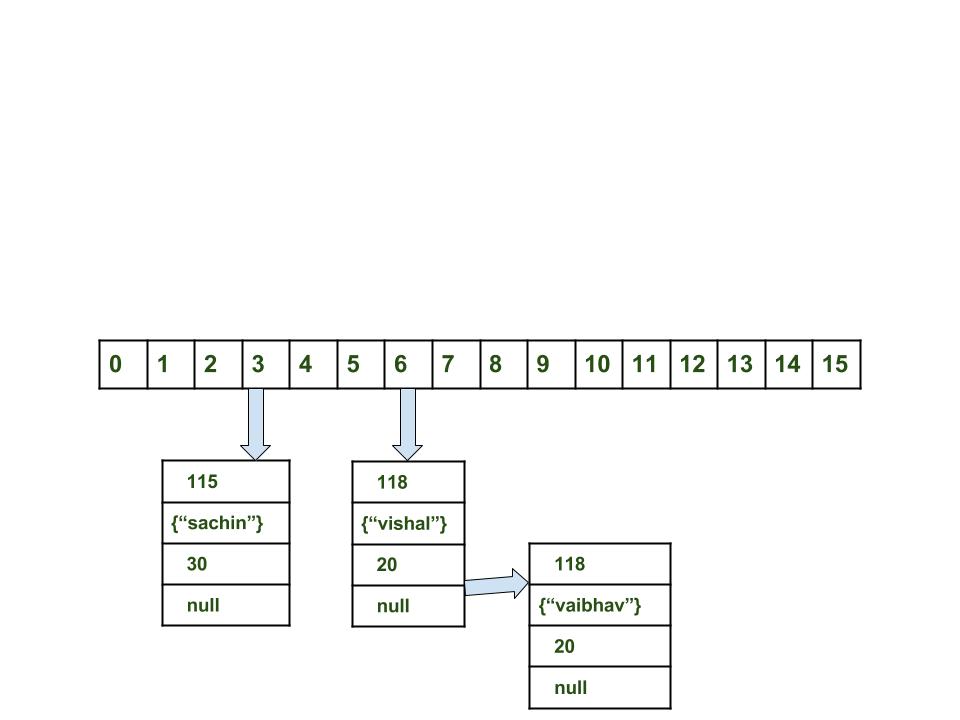
[примечание от автора перевода] Изображение взято из оригинальной статьи и изначально содержит ошибку. Ссылка на следующий объект в объекте vishal с индексом 6 не равна null, в ней содержится указатель на объект vaibhav.
- получаем значение по ключу sachin:
Вычислить хэш код объекта <“sachin”>. Он был сгенерирован, как 115.
Вычислить индекс с помощью метода index , который будет равен 3.
Перейти по индексу 3 и сравнить ключ первого элемента с имеющемся значением. Если они равны -вернуть значение, иначе выполнить проверку для следующего элемента, если он существует.
В нашем случае элемент найден и возвращаемое значение равно 30.
- получаем значение по ключу vaibahv:
Вычислить хэш код объекта <"vaibhav">. Он был сгенерирован, как 118.
Вычислить индекс с помощью метода index , который будет равен 6.
Перейти по индексу 6 и сравнить ключ первого элемента с имеющемся значением. Если они равны -вернуть значение, иначе выполнить проверку для следующего элемента, если он существует.
В данном случае он не найден и следующий объект node не равен null.
Если следующий объект node равен null, возвращаем null.
Если следующий объект node не равен null, переходим к нему и повторяем первые три шага до тех пор, пока элемент не будет найден или следующий объект node не будет равен null.
Изменения в Java 8
Как мы уже знаем в случае возникновения коллизий объект node сохраняется в структуре данных «связанный список» и метод equals() используется для сравнения ключей. Это сравнения для поиска верного ключа в связанном списке -линейная операция и в худшем случае сложность равнa O(n).
Для исправления этой проблемы в Java 8 после достижения определенного порога вместо связанных списков используются сбалансированные деревья. Это означает, что HashMap в начале сохраняет объекты в связанном списке, но после того, как колличество элементов в хэше достигает определенного порога происходит переход к сбалансированным деревьям. Что улучшает производительность в худшем случае с O(n) до O(log n).
Java HashMap под капотом
В этой статье мы рассмотрим наиболее популярную реализацию интерфейса Map из Java Collections Framework.
Прежде чем приступить к реализации, важно отметить, что первичные интерфейсы коллекции List и Set расширяют Collection , а Map — нет.
Проще говоря, HashMap хранит значения по ключам и предоставляет API для добавления, извлечения и манипулирования сохраненными данными различными способами. Реализация основана на принципах хеш-таблицы , которая на первый взгляд звучит немного сложно, но на самом деле ее очень легко понять.
Пары ключ-значение хранятся в так называемых сегментах, которые вместе составляют таблицу, которая на самом деле является внутренним массивом.
Как только мы узнаем ключ, под которым хранится или должен быть сохранен объект, операции хранения и поиска выполняются в постоянное время , O (1) в хэш-карте с большими размерами.
Чтобы понять, как хэш-карты работают под капотом, нужно понять механизм хранения и извлечения, используемый __HashMap. Мы сосредоточимся на них.
Наконец, HashMap часто встречающиеся вопросы в интервью , так что это хороший способ подготовить интервью или подготовиться к нему.
2. API put ()
Чтобы сохранить значение в хэш-карте, мы вызываем API put , который принимает два параметра; ключ и соответствующее значение:
Когда значение добавляется на карту под ключом, вызывается API hashCode () объекта ключа для получения так называемого начального значения хеш-функции.
Чтобы увидеть это в действии, давайте создадим объект, который будет действовать как ключ.
Мы создадим только один атрибут для использования в качестве хеш-кода для имитации первой фазы хеширования:
Теперь мы можем использовать этот объект для сопоставления значения в хэш-карте:
В приведенном выше коде ничего особенного не происходит, но обратите внимание на вывод консоли. Действительно, метод hashCode вызывается:
Затем, API-интерфейс hash () карты хеш-функции вызывается внутренне для вычисления окончательного значения хеш-функции с использованием начального значения хеш-функции.
Это окончательное хеш-значение в конечном итоге сводится к индексу во внутреннем массиве или к тому, что мы называем расположением сегмента.
Функция hash для HashMap выглядит следующим образом:
Здесь следует отметить только использование хеш-кода из ключевого объекта для вычисления окончательного хеш-значения
Находясь внутри функции put , окончательное значение хеша используется следующим образом:
Обратите внимание, что вызывается внутренняя функция putVal , и в качестве первого параметра указывается окончательное значение хеш-функции.
Можно задаться вопросом, почему ключ снова используется внутри этой функции, поскольку мы уже использовали его для вычисления значения хеш-функции.
Причина в том, что хеш-карты хранят и ключ, и значение в расположении корзины как объект Map.Entry .
Как обсуждалось ранее, все интерфейсы инфраструктуры коллекций Java расширяют интерфейс Collection , а Map — нет. Сравните объявление интерфейса Map, которое мы видели ранее, с интерфейсом Set :
Причина в том, что ** карты точно не хранят отдельные элементы, как в других коллекциях, а представляют собой набор пар ключ-значение.
Таким образом, универсальные методы интерфейса Collection , такие как add , toArray , не имеют смысла, когда дело доходит до Map .
Концепция, которую мы рассмотрели в последних трех абзацах, является одним из самых популярных вопросов для собеседования в Java Collections Framework .
Так что это стоит понять.
Один специальный атрибут хеш-карты заключается в том, что он принимает значения null и нулевые ключи:
Когда во время операции put встречается пустой ключ, ему автоматически присваивается окончательное значение хеш-функции 0 ** , что означает, что он становится первым элементом базового массива.
Это также означает, что когда ключ имеет значение NULL, операция хеширования не выполняется, и, следовательно, API-ключ ключа hashCode не вызывается, что в конечном итоге исключает исключение нулевого указателя.
Во время операции put , когда мы используем ключ, который уже использовался ранее для хранения значения, он возвращает предыдущее значение, связанное с ключом:
в противном случае возвращается null:
Когда put возвращает значение NULL, это также может означать, что предыдущее значение, связанное с ключом, является NULL, не обязательно, что это новое отображение значения ключа:
API containsKey можно использовать для различения таких сценариев, как мы увидим в следующем подразделе.
3. Get API
Чтобы получить объект, уже сохраненный в хэш-карте, мы должны знать ключ, под которым он был сохранен. Мы вызываем API get и передаем ему ключевой объект:
Внутри используется тот же принцип хеширования. The hashCode () API ключевого объекта вызывается для получения начального значения хеша:
На этот раз hashCode API MyKey вызывается дважды; один раз для put и один раз для get :
Затем это значение повторно обрабатывается путем вызова внутреннего API hash () для получения окончательного значения хеш-функции.
Как мы видели в предыдущем разделе, это окончательное значение хеша в конечном итоге сводится к расположению сегмента или индексу внутреннего массива.
Объект значения, хранящийся в этом месте, затем извлекается и возвращается в вызывающую функцию.
Если возвращаемое значение равно нулю, это может означать, что ключевой объект не связан ни с одним значением в хэш-карте:
Или это может просто означать, что ключ был явно сопоставлен с нулевым экземпляром:
Чтобы провести различие между двумя сценариями, мы можем использовать API containsKey , которому мы передаем ключ, и он возвращает true, если и только если сопоставление было создано для указанного ключа в хэш-карте:
Для обоих случаев в приведенном выше тесте возвращаемое значение вызова API get равно нулю, но мы можем различить, какой из них есть какой.
4. Представления коллекции в HashMap
HashMap предлагает три представления, которые позволяют нам рассматривать его ключи и значения как другую коллекцию. Мы можем получить набор всех ключей карты :
Набор поддерживается самой картой. Так что любое изменение, внесенное в набор, отражается на карте :
Мы также можем получить коллекцию значений :
Как и набор ключей, любые изменения, внесенные в эту коллекцию, будут отражены в базовой карте .
Наконец, мы можем получить set view всех записей на карте:
Помните, что хеш-карта специально содержит неупорядоченные элементы, поэтому мы принимаем любой порядок при тестировании ключей и значений записей в цикле for each .
Много раз вы будете использовать представления коллекции в цикле, как в последнем примере, а точнее, с помощью их итераторов.
Просто помните, что итераторы для всех представленных выше представлений — fail-fast .
Если на карте произведено какое-либо структурное изменение, то после создания итератора будет сгенерировано исключение одновременного изменения:
Единственная разрешенная структурная модификация — это операция remove , выполняемая самим итератором:
Последнее, что нужно помнить об этих видах коллекций, — это производительность итераций. Здесь хэш-карта работает довольно плохо по сравнению со своими аналогами, связанными хэш-картой и древовидной картой.
Итерация по хеш-карте происходит в худшем случае O (n) , где n — сумма его емкости и количества записей.
5. Производительность HashMap
На производительность хэш-карты влияют два параметра: Initial Capacity и Load Factor . Емкость — это количество сегментов или длина базового массива, а начальная емкость — просто емкость во время создания.
Короче говоря, коэффициент загрузки или LF — это мера того, насколько полной должна быть карта хеша после добавления некоторых значений до ее изменения.
Начальная емкость по умолчанию — 16 , а коэффициент загрузки по умолчанию — 0.75 .
Мы можем создать хэш-карту с пользовательскими значениями для начальной емкости и LF:
Значения по умолчанию, установленные командой Java, хорошо оптимизированы для большинства случаев. Тем не менее, если вам нужно использовать свои собственные значения, что очень хорошо, вам нужно понимать влияние на производительность, чтобы вы знали, что делаете.
Когда количество записей в хэш-карте превышает произведение LF и емкости, происходит перефразировка , т. Е. Создается другой внутренний массив с удвоенным размером исходного и все записи перемещаются в новые области памяти в новом массиве ,
Низкая начальная емкость снижает стоимость помещения, но увеличивает частоту перефразирования ** . Перефразировка, очевидно, очень дорогой процесс. Поэтому, как правило, если вы ожидаете много записей, вы должны установить достаточно высокую начальную емкость.
С другой стороны, если вы установите слишком высокую начальную емкость, вы заплатите стоимость за время итерации. Как мы видели в предыдущем разделе.
Таким образом, высокая начальная емкость хороша для большого количества записей в сочетании с минимальной итерацией .
Низкая начальная емкость хороша для нескольких записей с большим количеством итераций ** .
6. Столкновения в HashMap
Коллизия, или, более конкретно, коллизия хеш-кода в HashMap , — это ситуация, когда два или более ключевых объекта выдают одно и то же окончательное хеш-значение и, следовательно, указывают на одно и то же местоположение сегмента или индекс массива.
Этот сценарий может возникнуть из-за того, что согласно контракту equals и hashCode два неравных объекта в Java могут иметь одинаковый хэш-код .
Это также может произойти из-за конечного размера базового массива, то есть до изменения размера. Чем меньше этот массив, тем выше вероятность столкновения.
Тем не менее, стоит упомянуть, что в Java реализована технология разрешения коллизий хеш-кода, которую мы увидим на примере.
Имейте в виду, что именно хеш-значение ключа определяет корзину, в которой будет храниться объект. И поэтому, если хеш-коды любых двух ключей сталкиваются, их записи все равно будут храниться в той же корзине.
И по умолчанию реализация использует связанный список в качестве реализации сегмента.
Первоначально операции с постоянным временем O (1) put и get будут выполняться за линейное время O (n) в случае столкновения. Это связано с тем, что после нахождения местоположения блока с окончательным значением хеш-функции каждый из ключей в этом местоположении будет сравниваться с предоставленным объектом ключа с использованием API equals
Чтобы смоделировать эту технику разрешения коллизий, давайте немного изменим наш ранее ключевой объект:
Обратите внимание, что мы просто возвращаем атрибут id в качестве хеш-кода и, таким образом, вызываем конфликт.
Также обратите внимание, что мы добавили операторы log в наши реализации equals и hashCode — так что мы точно знаем, когда вызывается логика.
Давайте теперь продолжим, чтобы сохранить и извлечь некоторые объекты, которые сталкиваются в какой-то момент
В приведенном выше тесте мы создаем три разных ключа — один имеет уникальный id , а два других имеют одинаковый id . Поскольку мы используем id в качестве начального значения хеша, определенно произойдет столкновение как при хранении, так и при извлечении данных с этими ключами.
В дополнение к этому, благодаря технике разрешения конфликтов, которую мы видели ранее, мы ожидаем, что каждое из наших сохраненных значений будет восстановлено правильно, отсюда и утверждения в последних трех строках.
Когда мы запустим тест, он должен пройти, показывая, что конфликты были разрешены, и мы будем использовать созданный журнал, чтобы подтвердить, что конфликты действительно произошли: