Как построить дендрограмму в excel
Гистограмма в Excel – это способ построения наглядной диаграммы, отражающей изменение нескольких видов данных за какой-то период времени.
С помощью гистограммы удобно иллюстрировать различные параметры и сравнивать их. Рассмотрим самые популярные виды гистограмм и научимся их строить.
Как построить обновляемую гистограмму?
Имеем данные по продажам разных видов молочной продукции по каждому месяцу за 2015 год.
Построим обновляемую гистограмму, которая будет реагировать на вносимые в таблицу изменения. Выделим весь массив вместе с шапкой и кликнем на вкладку ВСТАВКА. Найдем так ДИАГРАММЫ – ГИСТОГРАММА и выберем самый первый тип. Он называется ГИСТОГРАММА С ГРУППИРОВКОЙ.
Получили гистограмму, размер поля которой можно менять. На такой диаграмме наглядно видно, например, что самые большие продажи были по молоку в ноябре, а самые маленькие – по сливкам в июне.
Если мы будем вносить в таблицу изменения, внешний вид гистограммы тоже будет меняться. Для примера вместо 1400 в январе по кефиру поставим 4000. Видим, как зеленый столбец полетел вверх.
Гистограмма с накоплением
Теперь рассмотрим, как построить гистограмму с накоплением в Excel. Еще один тип гистограмм, который позволяет отразить данные в процентном соотношении. Строится она точно так же, но выбирается другой тип.
Получаем диаграмму, на которой можно видеть, что, например, в январе больше продано молока, чем кефира или сливок. А в августе, по сравнению с другими молочными продуктами, молока было продано мало. И т.п.
Гистограммы в Excel можно изменять. Так, если мы кликнем правой кнопкой мыши в пустом месте диаграммы и выберем ИЗМЕНИТЬ ТИП, то сможем несколько ее видоизменить. Поменяем тип нашей гистограммы с накоплением на нормированную. Результатом будет та же самая диаграмма, но по оси Y будут отражены соотношения в процентном эквиваленте.
Аналогично можно производить и другие изменения гистограммы, что мы и сделали:
- поменяли шрифта на Arial и изменили его цвет на фиолетовый;
- сделали подчеркивание пунктирной линией;
- переместили легенду немного выше;
- добавили подписи к столбцам.
Как объединить гистограмму и график в Excel?
Некоторые массивы данных подразумевают построение более сложных диаграмм, которые совмещают несколько их видов. К примеру, гистограмма и график.
Рассмотрим пример. Для начала добавим к таблице с данными еще одну строку, где прописана выручка за каждый месяц. Она указана в рублях.
Теперь изменим существующую диаграмму. Кликнем в пустом месте правой кнопкой и выберем ВЫБРАТЬ ДАННЫЕ. Появится такое поле, на котором будет предложено выбрать другой интервал. Выделяем всю таблицу снова, но уже охватывая и строку с выручкой.
Excel автоматически расширил область значений по оси Y, поэтому данные по количеству продаж остались в самом низу в виде незаметных столбиков.
Но такая гистограмма неверна, потому что на одной диаграмме у нас значатся числа в рублевом и количественном эквиваленте (рублей и литров). Поэтому нужно произвести изменения. Перенесем данные по выручке на правую сторону. Кликнем по фиолетовым столбикам правой кнопкой, выберем ФОРМАТ РЯДА ДАННЫХ и отметим ПО ВСПОМОГАТЕЛЬНОЙ ОСИ.
Видим, что график сразу изменился. Теперь фиолетовый столбик с выручкой имеет свою область значения (справа).
Но это все равно не очень удобно, потому что столбики почти сливаются. Поэтому произведем еще одно дополнительное действие: кликнем правой кнопкой по фиолетовым столбцам и выберем ИЗМЕНИТЬ ТИП ДИАГРАММЫ ДЛЯ РЯДА. Появится окно, в котором выбираем график, самый первый тип.
Получаем вполне наглядную диаграмму, представляющую собой объединение гистограммы и графика. Видим, что максимальная выручка была в январе и ноябре, а минимальная – в августе.
окно, содержащее дендрограмму, построенную по результатам кластерного анализа.
Полученный график можно редактировать и распечатать непосредственно из Excel или
перенести, воспользовавшись буфером обмена, в какой-либо графический редактор,
например, в CorelDraw. Векторный формат изображения удобен для редактирования при
подготовке иллюстрационной графики. Основным преимуществом данного подхода является
возможность избежать утомительной процедуры экспорта данных из Excel в программу,
выполняющую статистические вычисления, что существенно экономит время.
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
Кластерный анализ
Назначение . С помощью онлайн-калькулятора можно проводить классификацию объектов алгоритмами «ближайшего соседа» и «дальнего соседа» с построением дендрограммы.
- Шаг №1
- Шаг №2
- Видеоинструкция
- Оформление Word
Выбор конкретного метода кластерного анализа зависит от цели классификации.
Обычной формой представления исходных данных в задачах кластерного анализа служит матрица:
Пример . Провести классификацию шести объектов, каждый из которых характеризуется двумя признаками (табл.9). В качестве расстояния между объектами принять , расстояние между кластерами исчислить по принципам: 1) “ближайшего соседа” и 2) “дальнего соседа”.
| № п/п | 1 | 2 | 3 | 4 | 5 | 6 |
| x1 | 2 | 4 | 5 | 12 | 14 | 15 |
| x2 | 8 | 10 | 7 | 6 | 6 | 4 |
2. Полученные данные помещаем в таблицу (матрицу расстояний).
| № п/п | 1 | 2 | 3 | 4 | 5 | 6 |
| 1 | 0 | 2.83 | 3.16 | 10.2 | 12.17 | 13.6 |
| 2 | 2.83 | 0 | 3.16 | 8.94 | 10.77 | 12.53 |
| 3 | 3.16 | 3.16 | 0 | 7.07 | 9.06 | 10.44 |
| 4 | 10.2 | 8.94 | 7.07 | 0 | 2 | 3.61 |
| 5 | 12.17 | 10.77 | 9.06 | 2 | 0 | 2.24 |
| 6 | 13.6 | 12.53 | 10.44 | 3.61 | 2.24 | 0 |
3. Поиск наименьшего расстояния.
Из матрицы расстояний следует, что объекты 4 и 5 наиболее близки P4;5 = 2 и поэтому объединяются в один кластер.
| № п/п | 1 | 2 | 3 | [4] | [5] | 6 |
| 1 | 0 | 2.83 | 3.16 | 10.2 | 12.17 | 13.6 |
| 2 | 2.83 | 0 | 3.16 | 8.94 | 10.77 | 12.53 |
| 3 | 3.16 | 3.16 | 0 | 7.07 | 9.06 | 10.44 |
| [4] | 10.2 | 8.94 | 7.07 | 0 | 2 | 3.61 |
| [5] | 12.17 | 10.77 | 9.06 | 2 | 0 | 2.24 |
| 6 | 13.6 | 12.53 | 10.44 | 3.61 | 2.24 | 0 |
При формировании новой матрицы расстояний, выбираем наименьшее значение из значений объектов №4 и №5.
В результате имеем 5 кластера: S(1), S(2), S(3), S(4,5), S(6)
Из матрицы расстояний следует, что объекты 4,5 и 6 наиболее близки P4,5;6 = 2.24 и поэтому объединяются в один кластер.
| № п/п | 1 | 2 | 3 | [4,5] | [6] |
| 1 | 0 | 2.83 | 3.16 | 10.2 | 13.6 |
| 2 | 2.83 | 0 | 3.16 | 8.94 | 12.53 |
| 3 | 3.16 | 3.16 | 0 | 7.07 | 10.44 |
| [4,5] | 10.2 | 8.94 | 7.07 | 0 | 2.24 |
| [6] | 13.6 | 12.53 | 10.44 | 2.24 | 0 |
При формировании новой матрицы расстояний, выбираем наименьшее значение из значений объектов №4,5 и №6.
В результате имеем 4 кластера: S(1), S(2), S(3), S(4,5,6)
Из матрицы расстояний следует, что объекты 1 и 2 наиболее близки P1;2 = 2.83 и поэтому объединяются в один кластер.
| № п/п | [1] | [2] | 3 | 4,5,6 |
| [1] | 0 | 2.83 | 3.16 | 10.2 |
| [2] | 2.83 | 0 | 3.16 | 8.94 |
| 3 | 3.16 | 3.16 | 0 | 7.07 |
| 4,5,6 | 10.2 | 8.94 | 7.07 | 0 |
При формировании новой матрицы расстояний, выбираем наименьшее значение из значений объектов №1 и №2.
В результате имеем 3 кластера: S(1,2), S(3), S(4,5,6)
Из матрицы расстояний следует, что объекты 1,2 и 3 наиболее близки P1,2;3 = 3.16 и поэтому объединяются в один кластер.
| № п/п | [1,2] | [3] | 4,5,6 |
| [1,2] | 0 | 3.16 | 8.94 |
| [3] | 3.16 | 0 | 7.07 |
| 4,5,6 | 8.94 | 7.07 | 0 |
При формировании новой матрицы расстояний, выбираем наименьшее значение из значений объектов №1,2 и №3.
В результате имеем 2 кластера: S(1,2,3), S(4,5,6)
| № п/п | 1,2,3 | 4,5,6 |
| 1,2,3 | 0 | 7.07 |
| 4,5,6 | 7.07 | 0 |
Таким образом, при проведении кластерного анализа по принципу “ближнего соседа” получили два кластера, расстояние между которыми равно P=7.07
Результаты иерархической классификации объектов представлены на рис. в виде дендрограммы.
Любую информацию легче воспринимать, если она представлена наглядно. Это особенно актуально, когда мы имеем дело с числовыми данными. Их необходимо сопоставить, сравнить. Оптимальный вариант представления – диаграммы. Будем работать в программе Excel.
Так же мы научимся создавать динамические диаграммы и графики, которые автоматически обновляют свои показатели в зависимости от изменения данных. По ссылке в конце статьи можно скачать шаблон-образец в качестве примера.
Как построить диаграмму по таблице в Excel?
- Создаем таблицу с данными.
- Выделяем область значений A1:B5, которые необходимо презентовать в виде диаграммы. На вкладке «Вставка» выбираем тип диаграммы.
- Нажимаем «Гистограмма» (для примера, может быть и другой тип). Выбираем из предложенных вариантов гистограмм.
- После выбора определенного вида гистограммы автоматически получаем результат.
- Такой вариант нас не совсем устраивает – внесем изменения. Дважды щелкаем по названию гистограммы – вводим «Итоговые суммы».
- Сделаем подпись для вертикальной оси. Вкладка «Макет» — «Подписи» — «Названия осей». Выбираем вертикальную ось и вид названия для нее.
- Вводим «Сумма».
- Конкретизируем суммы, подписав столбики показателей. На вкладке «Макет» выбираем «Подписи данных» и место их размещения.
- Уберем легенду (запись справа). Для нашего примера она не нужна, т.к. мало данных. Выделяем ее и жмем клавишу DELETE.
- Изменим цвет и стиль.
Выберем другой стиль диаграммы (вкладка «Конструктор» — «Стили диаграмм»).
Как добавить данные в диаграмму в Excel?
- Добавляем в таблицу новые значения — План.
- Выделяем диапазон новых данных вместе с названием. Копируем его в буфер обмена (одновременное нажатие Ctrl+C). Выделяем существующую диаграмму и вставляем скопированный фрагмент (одновременное нажатие Ctrl+V).
- Так как не совсем понятно происхождение цифр в нашей гистограмме, оформим легенду. Вкладка «Макет» — «Легенда» — «Добавить легенду справа» (внизу, слева и т.д.). Получаем:
Есть более сложный путь добавления новых данных в существующую диаграмму – с помощью меню «Выбор источника данных» (открывается правой кнопкой мыши – «Выбрать данные»).

Когда нажмете «Добавить» (элементы легенды), откроется строка для выбора диапазона данных.
Как поменять местами оси в диаграмме Excel?
- Щелкаем по диаграмме правой кнопкой мыши – «Выбрать данные».
- В открывшемся меню нажимаем кнопку «Строка/столбец».
- Значения для рядов и категорий поменяются местами автоматически.
Как закрепить элементы управления на диаграмме Excel?
Если очень часто приходится добавлять в гистограмму новые данные, каждый раз менять диапазон неудобно. Оптимальный вариант – сделать динамическую диаграмму, которая будет обновляться автоматически. А чтобы закрепить элементы управления, область данных преобразуем в «умную таблицу».
- Выделяем диапазон значений A1:C5 и на «Главной» нажимаем «Форматировать как таблицу».
- В открывшемся меню выбираем любой стиль. Программа предлагает выбрать диапазон для таблицы – соглашаемся с его вариантом. Получаем следующий вид значений для диаграммы:
- Как только мы начнем вводить новую информацию в таблицу, будет меняться и диаграмма. Она стала динамической:
Мы рассмотрели, как создать «умную таблицу» на основе имеющихся данных. Если перед нами чистый лист, то значения сразу заносим в таблицу: «Вставка» — «Таблица».
Как сделать диаграмму в процентах в Excel?
Представлять информацию в процентах лучше всего с помощью круговых диаграмм.
Исходные данные для примера:
- Выделяем данные A1:B8. «Вставка» — «Круговая» — «Объемная круговая».
- Вкладка «Конструктор» — «Макеты диаграммы». Среди предлагаемых вариантов есть стили с процентами.
- Выбираем подходящий.
- Очень плохо просматриваются сектора с маленькими процентами. Чтобы их выделить, создадим вторичную диаграмму. Выделяем диаграмму. На вкладке «Конструктор» — «Изменить тип диаграммы». Выбираем круговую с вторичной.
- Автоматически созданный вариант не решает нашу задачу. Щелкаем правой кнопкой мыши по любому сектору. Должны появиться точки-границы. Меню «Формат ряда данных».
- Задаем следующие параметры ряда:
- Получаем нужный вариант:
Диаграмма Ганта в Excel
Диаграмма Ганта – это способ представления информации в виде столбиков для иллюстрации многоэтапного мероприятия. Красивый и несложный прием.

- У нас есть таблица (учебная) со сроками сдачи отчетов.
- Для диаграммы вставляем столбец, где будет указано количество дней. Заполняем его с помощью формул Excel.
- Выделяем диапазон, где будет находиться диаграмма Ганта. То есть ячейки будут залиты определенным цветом между датами начала и конца установленных сроков.
- Открываем меню «Условное форматирование» (на «Главной»). Выбираем задачу «Создать правило» — «Использовать формулу для определения форматируемых ячеек».
- Вводим формулу вида: =И(E$2>=$B3;E$2 Готовые примеры графиков и диаграмм в Excel скачать:

Как сделать еженедельный график в Excel вместе с ежедневным.
Пример создания динамического синхронного еженедельного графика вместе с ежедневным. Синхронное отображение двух таймфреймов на одном графике.
В программе Excel специально разрабатывались диаграммы и графики для реализации визуализации данных.

Одним из инструментов для решения экономических задач является кластерный анализ. С его помощью кластеры и другие объекты массива данных классифицируются по группам. Данную методику можно применять в программе Excel. Посмотрим, как это делается на практике.
Использование кластерного анализа
С помощью кластерного анализа можно проводить выборку по признаку, который исследуется. Его основная задача – разбиение многомерного массива на однородные группы. В качестве критерия группировки применяется парный коэффициент корреляции или эвклидово расстояние между объектами по заданному параметру. Наиболее близкие друг к другу значения группируются вместе.
Хотя чаще всего данный вид анализа применяют в экономике, его также можно использовать в биологии (для классификации животных), психологии, медицине и во многих других сферах деятельности человека. Кластерный анализ можно применять, используя для этих целей стандартный набор инструментов Эксель.
Пример использования
Имеем пять объектов, которые характеризуются по двум изучаемым параметрам – x и y.
-
Применяем к данным значениям формулу эвклидового расстояния, которое вычисляется по шаблону:


На этом завершается процедура разбиения совокупности на группы.
Как видим, хотя в целом кластерный анализ и может показаться сложной процедурой, но на самом деле разобраться в нюансах данного метода не так уж тяжело. Главное понять основную закономерность объединения в группы.

Мы рады, что смогли помочь Вам в решении проблемы.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Кластерный анализ Excel
Один из действенных инструментов решения экономических и статистических задач является кластерный анализ.
Один из действенных инструментов решения экономических и статистических задач является кластерный анализ. Он представляет собой разделение на группы разного рода объектов, на основании важных критериев. Полученные путем кластеризации группы поддаются анализу. Простым примером может стать прилавок в продуктовом. Здесь ассортимент продуктов проходит кластеризацию и разделяется на группы: «бакалея», «рыба», «молочные продукты» и т.д. При переносе кластеризации на потребителя получается выделить группы, которые так или иначе реагируют на рекламу, с определенной периодичностью покупают тот или иной товар или вовсе отказываются от его потребления и т.д. Проведение кластерного анализа можно осуществлять с использованием различного программного обеспечения, в том числе и стандартного Excel, с которым умеет работать большое количество пользователей.
Процесс кластеризации
На основании выбранного метода меняется сам процесс кластеризации. Практически всегда он является итеративным – многократно повторяющимся. Для объединения разных элементов в один кластер требуется постоянно добавлять в него, расширять близкие, схожие по типу какому-то критерию объекты. В процессе кластеризации можно проводить большое количество экспериментов, в которых один и тот же массив данных разделяется по разным критериям. Несмотря на то, что эксперименты сами по себе могут быть интересными, они – не самоцель. Кластеризация должна выполняться для получения содержательных сведений о структуре данных, которые исследуются. На основании полученных кластеров проводятся исследования свойств и характеристик объектов для формирования точного описания полученных групп.
Когда применяется кластерный анализ
Посредством кластерного анализа можно разделять массив на основании изучаемых характеристик. Разделение большого массива данных на обобщенные группы с близкими характеристиками. Критерием группировки выступает парный коэффициент корреляции или эвклидово расстояние между объектами. При этом близкие друг другу значения группируются вместе.
Область применения кластеризации – обширна. Среди наиболее простых примеров:
- Биология – разделение животных на виды, на основании их признаков.
- Медицина – применяется с целью классифицировать заболевания по симптоматике, способам лечения.
- Психология – для анализа поведения разных групп людей в определенных ситуациях.
- Экономика – изучение экономических изменений, составление прогнозов.
- Маркетинг – проведение исследований для продвижения продукции.
- Возможность анализировать данные практически любой природы;
- Обработка больших объемов информации путем ее сжатия, компоновки;
- Простая наглядная демонстрация данных;
- Может выполняться циклически и проводиться до тех пор, пока не будет получен необходимый результат. При этом каждый цикл может значительно изменять направление дальнейшего анализа.
- Состав и число кластеров напрямую связаны с выбранными критериями кластеризации;
- Преобразование первоначальных данных, сбор и их группировка может исказить отдельные объекты, лишить их своей индивидуальности;
- Часть данных, присущих конкретному кластеру, может просто игнорироваться в рамках анализируемой совокупности.
- Player ID – номер присваиваемый игрокам баскетбольной команды. В нашей выборке будет 20 игроков.
- Team – обозначение команд. Двадцать игроков разделены на 5 команд.
- Points – набранные игроками очки.
- Rebounds – количество подборов каждого игрока.
- Пол.
- Возраст.
- Уровень образования.
- Доходы.
- Ручная проверка;
- Определение контрольных точек и проверка полученных кластеров через них;
- Определение стабильности выполненной кластеризации с помощью добавления в модель дополнительных переменных;
- Кластеризация с помощью разных методов: K средних, иерархическая агломеративная DBSCAN. Разные методы могут привести к получению разных кластеров. В целом, это нормально, но если кластеры, полученные разными методами, схожи, то это указывает, в первую очередь, на правильность кластеризации.
- В биологии – для определения видов животных на Земле.
- В медицине – для классификации заболеваний по группам симптомов и способам терапии.
- В психологии – для определения типов поведения личности в определенных ситуациях.
- В экономическом анализе – при изучении и прогнозировании экономической депрессии, исследовании конъюнктуры.
- В разнообразных маркетинговых исследованиях.
- позволяет разбивать многомерный ряд сразу по целому набору параметров;
- можно рассматривать данные практически любой природы (нет ограничений на вид исследуемых объектов);
- можно обрабатывать значительные объемы информации, резко сжимать их, делать компактными и наглядными;
- может применяться циклически (проводится до тех пор, пока не будет достигнут нужный результат; а после каждого цикла возможно значительное изменение направленности дальнейшего исследования).
- состав и количество кластеров зависит от заданного критерия разбиения;
- при преобразовании исходного набора данных в компактные группы исходная информация может искажаться, отдельные объекты могут терять свою индивидуальность;
- часто игнорируется отсутствие в анализируемой совокупности некоторых значений кластеров.
- Шаг №1
- Шаг №2
- Видеоинструкция
- Оформление Word
Когда требуется обработать большое количество данных, преобразовать информацию в простые группы, которые проще изучать – применяется кластерный анализ.
Преимущества и недостатки кластерного анализа
Использование такого типа анализа дает возможность разбить многомерный ряд на основании различных параметров. Среди главных преимуществ этого инструмента выделяются:
Недостатки представленного метода:
Пример выполнения кластерного анализа в Excel
Чтобы наглядно показать, как выполняется анализ, возьмем 6 объектов исследования. У каждого из них имеется 2 параметра, которые характеризуют их – X и Y.
Их мы будем использовать в примере, основанном на определения евклидова расстояния: =КОРЕНЬ((x2-x1)^2+(y2-y1)^2)
Результаты, которые были получены, занесем в матрицу расстояний.
Из полученных данных видно, что самыми близкими являются 4 и 5 объекты. Поэтому их можно сгруппировать, а при формировании новой матрицы расстояний остается значение, которое было меньшим из двух.
Новая матрица позволяет увидеть, что теперь ближайшими объектами являются кластер и объект 6. Повторяем предыдущий шаг – объединяем, оставляем меньшее значение и формируем новую матрицу.
Здесь ближайшими объектами стали 1 и 2. Повторяем формирование кластера.
Осталось исследовать последние 3 объекта. Минимальное расстояние получилось между кластером и объектом 3. Выполним еще раз их объединение.
В результате группировки с использованием метода «ближайшего соседа» удалось сгруппировать 6 объектов и разделить их на 2 кластера, расстояние между которыми – 7,07.
Применение инструмента кластерного анализа имеет большое значение в рамках анализа в экономике. С его помощью удается вычленять периоды, в которых параметры были максимально приближены, и динамика отличалась своей схожестью. Метод кластеризации в экономике позволяет исследовать товарную и общехозяйственную конъюнктуру.
Как сделать кластерную выборку в Excel: пошаговая инструкция
Выборка часто используется в статистике для анализа нескольких групп данных, которые являются частью массива. Выборка представляет собой разбивание всего объема данных на кластеры и использование определенной группы кластеров в выборке. В примере, описанном ниже, вы можете узнать, как сделать кластеризацию в Excel и превратить ее в кластерную выборку.
Шаг 1: Ввод данных
Для начала, необходимо ввести исходные данные в программу. Например, используем такие:
Выполнить кластеризацию всего массива представленных данных можно по разным критериям: разделить игроков по количеству очков, подборов или просто создать кластеры на основе их принадлежности к определенной команде.
Для создания случайно кластерной выборки самым простым способом станет случайный выбор двух команд и определение, какие игроки должны входить в окончательную выборку.
Шаг 2: поиск уникальных значений
Создание дополнительного массива, который будет содержать уникальные значения. За основу выбора уникальных значений берем столбец Team и создаем новый Unique, в который вводим следующую формулу Excel =UNIQUE(B2:B21).
Следующий столбец создается на основе ввода целого числа (начиная с 1) для каждого уникального названия команды, полученного путем ввода формулы:
Шаг 3: выбор случайных кластеров
Чтобы создать своего рода рандомайзер, используем такую формулу: =СЛУЧМЕЖДУ(G2, G6). Это позволит случайным образом выбирать одно из полученных целых чисел, которыми мы обозначили команды.
При нажатии на клавиши ENTER сгенерируется случайное значение. У нас высветилось 5. Команда, которая взаимосвязана с этим значением – Е. Она будет выполнять роль первой команды, участвующей в окончательной выборке.
Для того чтобы получить второе значение, необходимо снова нажать на ячейку I2 и ENTER. Новое число опять будет выбрано из записанной нами функции =СЛУЧМЕЖДУ(G2, G6) .
Во второй раз рандомайзер выбрал значение 3. Команда, которая соответствует этому значению – С. Она станет второй командой, представленной в окончательной выборке.
Шаг 4: Фильтрование окончательного образца
В состав окончательной выборки будут входить все игроки, которые принадлежат к команде С или команде Е. Для фильтрации только этих команд необходимо выделить все изначальные данные в столбцах A, B, C, D. После этого необходимо нажать на вкладку «Данные» в верхнем меню Excel, а далее – «Фильтр», которая располагается в группе «Сортировка и фильтр».
После того как Excel сформирует фильтр над каждым столбцом, останется нажать на стрелку, расположенную в столбце «Team». После этого оставить галочки только для команд C и E.
После нажатия на подтверждение («ОК») данные будут отфильтрованы и в таблице будут отображаться только игроки, принадлежащие к команде С или к команде Е.
Этот образец – окончательная случайная выборка из всего массива данных. В него включены все игроки по критерию «Команда».
На основании полученных данных можно выбрать, например, самого результативного игрока из двух этих команд или рассчитать среднее количество очков, заработанных каждым из них. Конечно, в представленном массиве в целом и в кластере в частности указано совсем немного информации, но и ее уже можно использовать.
Как кластерный анализ применяется в маркетинговых исследованиях
Маркетологи часто используют этот инструмент в качестве способа изучения различных данных о товарах, потребителях, нишах и т.д. Оно требуется как для проведения теоретических изысканий, так и маркетологам, занимающимся практической работой. Чаще всего они решают вопросы, связанные с объединением в группы различных объектов: клиентов, товаров, услуг и т.д.
Так, одна из важнейших задач, которая решается при помощи кластерного анализа, является изучение потребительского поведения. Метод позволяет выполнить группировку всех потребителей в однородные массы. Она позволяет не только получить максимально подробное представление о том, как клиент из каждой группы себя ведет, но и определить факторы, которые влияют на то или иное поведение. Кластеризация в маркетинговых исследованиях может выполняться по разным критериям.
Одной из важнейших задач, которая решается путем применения в качестве рабочего инструмента кластерного анализа, – позиционирование. С его помощью выявляется ниша, в которой лучше всего позиционировать новую продукцию.
Применение такого анализа позволяет построить карту, на основании которой определяется уровень конкуренции в разных сегментах рынка, оценить параметры товара, позволяющие попадать в определенный сегмент. Проведение анализа полученной карты поможет определить новые, незанятые ниши на рынке, в которых разрешено предлагать уже созданные товары или разрабатывать инновационные продукты.
Кроме того, инструмент может пригодиться в случаях, когда необходимо изучить клиентов компании. В этой ситуации клиенты разделяются на группы, и для каждого образовавшегося кластера разрабатывается индивидуальная политика взаимодействия. Разделение на кластеры позволяет не только сократить количество объектов, которые нужно анализировать, но и одновременно подобрать подход для каждой клиентской базы.
Как оценить качество кластеризации
Чтобы проверить качество выполненной кластеризации, можно воспользоваться такими процедурами, как:
Не стоит пренебрегать проверками, в противном случае все исследование на фоне неправильной кластеризации может стать ошибочным.
Заключение
Алгоритм применения инструмента кластерного анализа упрощается с использованием возможностей Excel. Конечно, требуется проработать различные варианты взаимодействия с массивом данных на основании использования программных возможностей. Программное обеспечение позволяет не только фильтровать данные, но и сортировать объекты, выполнять различные расчеты. Кроме того, с помощью ее средств можно выполнить упрощение восприятия информации путем составления диаграмм, полученных, например, в результате создания конкретной выборки. Этот инструмент незаменим в маркетинге, он позволяет оптимизировать продвижение продукции, оптимально расходовать ресурсы для отдельных групп потребителей.



Нажимая кнопку «Войти», Вы принимаете условия
Политики конфиденциальности
Как сделать кластерный анализ в Excel: сфера применения и инструкция
Кластерный анализ объединяет кластеры и переменные (объекты), похожие друг на друга. То есть классифицирует объекты. Часто при решении экономических задач, имеющих достаточно большое число данных, нужна многомерность описания. Один из простых методов многомерного анализа – кластерный анализ.
Кластерный анализ является количественным инструментом исследования социально-экономических процессов, для описания которых необходимо много характеристик. Он позволяет разбить выборку на несколько групп по исследуемому признаку, проанализировать группы (как группируются переменные), группировку объектов (как группируются объекты). С помощью метода решаются задачи сегментирования рынка, анализируются сельские хозяйства для сравнения производительности, например, прогнозируется конъюнктура рынка отдельных продуктов и т.д.
Многомерный кластерный анализ
По сути, кластерный анализ – это совокупность инструментов для классификации многомерных объектов. Метод подразумевает определение расстояния между переменными (дельты) и последующее выделение групп наблюдений (кластеров).
Техника кластеризации применяется в самых разнообразных областях. Главное задача – разбить многомерный ряд исследуемых значений (объектов, переменных, признаков) на однородные группы, кластеры. То есть данные классифицируются и структурируются.
Вопрос, который задает исследователь при использовании кластерного анализа, – как организовать многомерную выборку в наглядные структуры.
Примеры использования кластерного анализа:
Когда нужно преобразовать «горы» информации в пригодные для дальнейшего изучения группы, используют кластерный анализ.
Дельта-кластерный анализ имеет и свои недостатки:
Как сделать кластерный анализ в Excel
Для примера возьмем шесть объектов наблюдения. Каждый имеет два характеризующих его параметра.
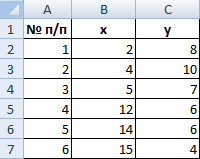
В качестве расстояния между объектами возьмем евклидовое расстояние. Формула расчета:
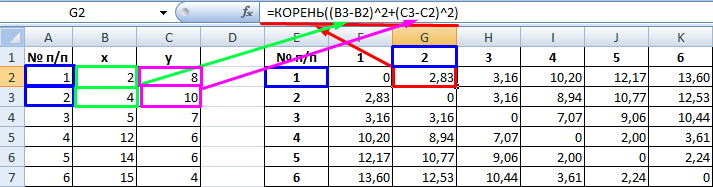
Рассчитанные данные размещаем в матрице расстояний.
Самыми близкими друг к другу объектами являются объекты 4 и 5. Следовательно, их можно объединить в одну группу – при формировании новой матрицы оставляем наименьшее значение.
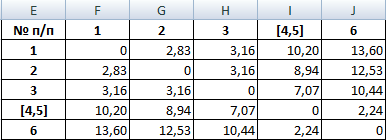
Из новой матрицы видно, что можно объединить в один кластер объекты [4, 5] и 6 (как наиболее близкие друг к другу по значениям). Оставляем наименьшее значение и формируем новую матрицу:
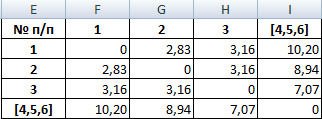
Объекты 1 и 2 можно объединить в один кластер (как наиболее близкие из имеющихся). Выбираем наименьшее значение и формируем новую матрицу расстояний. В результате получаем три кластера:
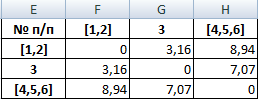
Самые близкие объекты – 1, 2 и 3. Объединим их.
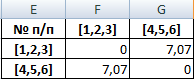
Мы провели кластерный анализ по методу «ближайшего соседа». В результате получено два кластера, расстояние между которыми – 7,07.
Огромное значение имеет кластерный анализ в экономическом анализе. Инструмент позволяет вычленять из громадной совокупности периоды, где значения соответствующих параметров максимально близки и где динамика наиболее схожа. Для исследования, к примеру, товарной и общехозяйственной конъюнктуры этот метод отлично подходит.
Как построить дендрограмму в excel пошаговая инструкция
окно, содержащее дендрограмму, построенную по результатам кластерного анализа.
Полученный график можно редактировать и распечатать непосредственно из Excel или
перенести, воспользовавшись буфером обмена, в какой-либо графический редактор,
например, в CorelDraw. Векторный формат изображения удобен для редактирования при
подготовке иллюстрационной графики. Основным преимуществом данного подхода является
возможность избежать утомительной процедуры экспорта данных из Excel в программу,
выполняющую статистические вычисления, что существенно экономит время.
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
Кластерный анализ
Назначение . С помощью онлайн-калькулятора можно проводить классификацию объектов алгоритмами «ближайшего соседа» и «дальнего соседа» с построением дендрограммы.
Выбор конкретного метода кластерного анализа зависит от цели классификации.
Обычной формой представления исходных данных в задачах кластерного анализа служит матрица:
каждая строка которой, представляет результат измерений k , рассматриваемых признаков на одном из обследованных объектов.
Наиболее трудным считается определение однородности объектов, которые задаются введением расстояния между объектами хi и хj (p(xi, xj)).
Объекты будут однородными в случае p(xi, xj)£ pпор,
где pпор— заданное пороговое значение.
Выбор расстояния (р) является основным моментом исследования, от которого зависят окончательные варианты разбиения. Наиболее распространенными считаются принципы “ближайшего соседа” или “дальнего соседа”. В первом случае за расстояние между кластерами принимают расстояние между ближайшими элементами этих кластеров, а во втором — между наиболее удаленными друг от друга.
В задачах кластерного анализа часто используют Евклидово и Хемингово расстояния.
Евклидово расстояние определяется по формуле:
;
сравнивается близость двух объектов по большому числу признаков.
Хемингово расстояние:
;
используется как мера различия объектов, задаваемых атрибутивными признаками.
Пример . Провести классификацию шести объектов, каждый из которых характеризуется двумя признаками (табл.9). В качестве расстояния между объектами принять , расстояние между кластерами исчислить по принципам: 1) “ближайшего соседа” и 2) “дальнего соседа”.
| № п/п | 1 | 2 | 3 | 4 | 5 | 6 |
| x1 | 2 | 4 | 5 | 12 | 14 | 15 |
| x2 | 8 | 10 | 7 | 6 | 6 | 4 |
2. Полученные данные помещаем в таблицу (матрицу расстояний).
| № п/п | 1 | 2 | 3 | 4 | 5 | 6 |
| 1 | 0 | 2.83 | 3.16 | 10.2 | 12.17 | 13.6 |
| 2 | 2.83 | 0 | 3.16 | 8.94 | 10.77 | 12.53 |
| 3 | 3.16 | 3.16 | 0 | 7.07 | 9.06 | 10.44 |
| 4 | 10.2 | 8.94 | 7.07 | 0 | 2 | 3.61 |
| 5 | 12.17 | 10.77 | 9.06 | 2 | 0 | 2.24 |
| 6 | 13.6 | 12.53 | 10.44 | 3.61 | 2.24 | 0 |
3. Поиск наименьшего расстояния.
Из матрицы расстояний следует, что объекты 4 и 5 наиболее близки P4;5 = 2 и поэтому объединяются в один кластер.
| № п/п | 1 | 2 | 3 | [4] | [5] | 6 |
| 1 | 0 | 2.83 | 3.16 | 10.2 | 12.17 | 13.6 |
| 2 | 2.83 | 0 | 3.16 | 8.94 | 10.77 | 12.53 |
| 3 | 3.16 | 3.16 | 0 | 7.07 | 9.06 | 10.44 |
| [4] | 10.2 | 8.94 | 7.07 | 0 | 2 | 3.61 |
| [5] | 12.17 | 10.77 | 9.06 | 2 | 0 | 2.24 |
| 6 | 13.6 | 12.53 | 10.44 | 3.61 | 2.24 | 0 |
При формировании новой матрицы расстояний, выбираем наименьшее значение из значений объектов №4 и №5.
В результате имеем 5 кластера: S(1), S(2), S(3), S(4,5), S(6)
Из матрицы расстояний следует, что объекты 4,5 и 6 наиболее близки P4,5;6 = 2.24 и поэтому объединяются в один кластер.
| № п/п | 1 | 2 | 3 | [4,5] | [6] |
| 1 | 0 | 2.83 | 3.16 | 10.2 | 13.6 |
| 2 | 2.83 | 0 | 3.16 | 8.94 | 12.53 |
| 3 | 3.16 | 3.16 | 0 | 7.07 | 10.44 |
| [4,5] | 10.2 | 8.94 | 7.07 | 0 | 2.24 |
| [6] | 13.6 | 12.53 | 10.44 | 2.24 | 0 |
При формировании новой матрицы расстояний, выбираем наименьшее значение из значений объектов №4,5 и №6.
В результате имеем 4 кластера: S(1), S(2), S(3), S(4,5,6)
Из матрицы расстояний следует, что объекты 1 и 2 наиболее близки P1;2 = 2.83 и поэтому объединяются в один кластер.
| № п/п | [1] | [2] | 3 | 4,5,6 |
| [1] | 0 | 2.83 | 3.16 | 10.2 |
| [2] | 2.83 | 0 | 3.16 | 8.94 |
| 3 | 3.16 | 3.16 | 0 | 7.07 |
| 4,5,6 | 10.2 | 8.94 | 7.07 | 0 |
При формировании новой матрицы расстояний, выбираем наименьшее значение из значений объектов №1 и №2.
В результате имеем 3 кластера: S(1,2), S(3), S(4,5,6)
Из матрицы расстояний следует, что объекты 1,2 и 3 наиболее близки P1,2;3 = 3.16 и поэтому объединяются в один кластер.
| № п/п | [1,2] | [3] | 4,5,6 |
| [1,2] | 0 | 3.16 | 8.94 |
| [3] | 3.16 | 0 | 7.07 |
| 4,5,6 | 8.94 | 7.07 | 0 |
При формировании новой матрицы расстояний, выбираем наименьшее значение из значений объектов №1,2 и №3.
В результате имеем 2 кластера: S(1,2,3), S(4,5,6)
| № п/п | 1,2,3 | 4,5,6 |
| 1,2,3 | 0 | 7.07 |
| 4,5,6 | 7.07 | 0 |
Таким образом, при проведении кластерного анализа по принципу “ближнего соседа” получили два кластера, расстояние между которыми равно P=7.07
Результаты иерархической классификации объектов представлены на рис. в виде дендрограммы.