Какие данные о пользователе браузер передаёт сайтам?

Читайте, как посмотреть данные о пользователе, которые сайты могут получить из вашего браузера. Как минимизировать предоставляемую сети информацию.Как только вы откроете свой интернет-браузер, то сразу начнете оставлять за собой «цифровые следы», по которым веб-сайты, посещённые вами, будут отслеживать все ваши действия онлайн. Это абсолютно законная практика. Разработчики веб-сайтов, досок объявлений, рекламы товаров и услуг контролируют любые действия пользователей, связанные с ними.
Собранные данные гарантировано включают ваше текущее местоположение и «IP-адрес», которые сообщает ваш браузер при переходе по любой ссылке, независимо от того, пользуетесь ли вы компьютером, мобильном устройством или даже телевизором. И это только самая малая часть ваших личных данных свободно предоставляемых вашим браузером всем желающим.
Посмотреть эту информацию в сети очень просто, существует множество веб-порталов, предоставляющих пользователям подобную информацию.
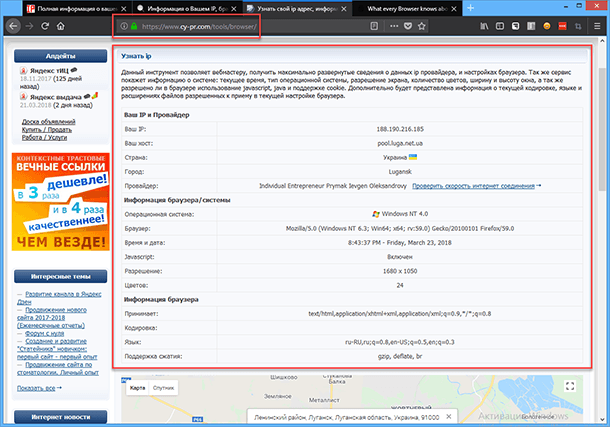
Доступность такой информации нельзя ограничить полностью, но можно сделать её минимальной. Также прочитайте статью о том, как бороться со слежкой и избежать неприятностей в сети.
Давайте разберёмся какие именно данные сообщает ваш браузер
Утечка информации начинается с вашего браузера, он передает сайтам «HTTP заголовки» и ещё множество дополнительных служебных данных. При этом большая часть информации крайне важна для корректной работы в сети и от этого никуда не деться.
Как только вы подключаетесь к Интернету, то сразу начинаете сообщать «IP-адрес», свою конкретную точку входа в сеть, зная которую можно с лёгкостью определить ваше местоположение. Ещё браузер передаёт свое название, версию, поддерживаемые технологии и данные о подключённых модулях. А также информацию об операционной системе, на которой он запущен, о её настройках, стационарная или мобильная версия ОС, модель процессора (CPU) и графического процессора (GPU), разрешение экрана, и даже текущий уровень заряда аккумулятора для ноутбуков, планшетов или телефонов.
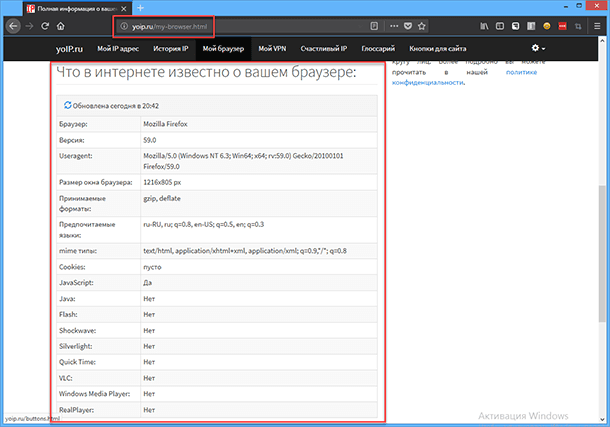
Что же, рассмотрим какую еще информацию может собирать и передавать о вас браузер.
Базовые данные работы интернет-браузера
Когда была проведена установка\удаление (если были), число сбоев, зарегистрированные ошибки, а также время беспрерывной работы в сети. Большинство браузеров отслеживают эти данные и составляют так называемые «logs» (отчёты о работе), без ведома пользователей.
Данные о поведении пользователя
Разработчики программного обеспечения часто интегрируют в него специальные системы, которые служат для сбора информации и составления отчётов о взаимодействии пользователя и программы. То есть, разработчики хотят знать на какие именно кнопки вы чаще всего нажимаете, какие функции вы чаще всего используете и сколько раз они вам понадобились. Опираясь на эти данные, они узнают о предпочтениях своих пользователей, о затруднениях, которые возникли при решении той или иной задачи, и самое главное эта информация даёт понять какие функции нуждаются в улучшении, а от каких нужно отказаться.
Сбор таких данных в большинстве случаев можно отключить в настройках программы, но далеко не все разработчики предоставляют такую возможность, так что перед использованием любой программы нужно тщательно читать «Уведомление о приватности».
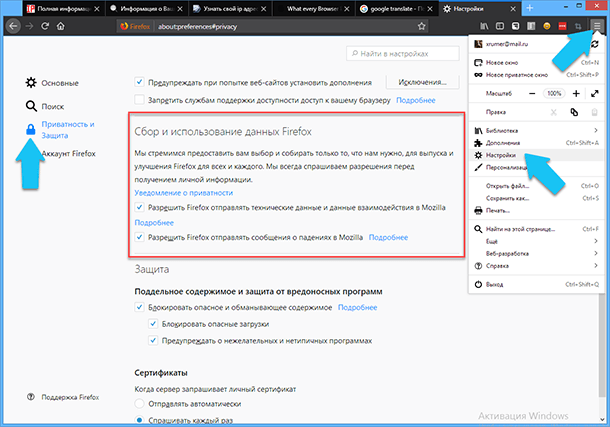
Например, при установке браузера «Opera» вас спросят, не хотите ли вы поучаствовать в «Программе по улучшению браузера». В «Firefox» функция отправки данных «Сбор и использование данных Firefox» включается по умолчанию, и найти её можно в «Параметрах». Чтобы отключить эту функцию нажмите на кнопку «Открыть меню» в правом верхнем углу окна программы, далее кликаем на «Настройка», или просто перейдите по ссылке «about:preferences». На открывшейся странице настроек, слева в меню кликаем на ссылку «Приватность и Защита» и пролистываем страницу до нужного заголовка и просто снимаем две галочки.
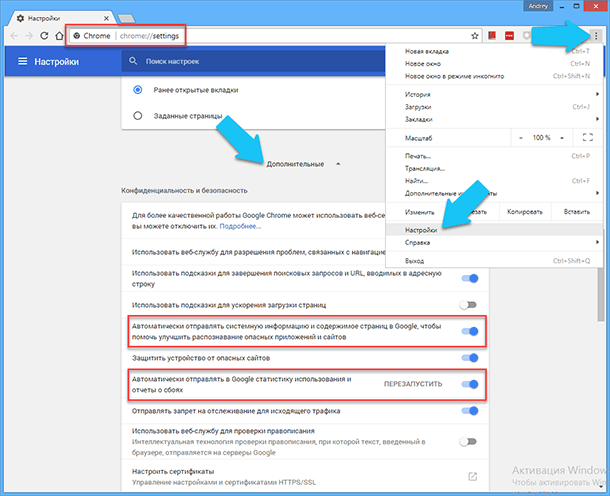
С браузером «Google Chrome» дело обстоит по-другому. По умолчанию функции телеметрии и отправки отчётов отключены, но при этом, программа все равно продолжает собирать информацию о ваших действиях и благополучно отправляет её куда нужно. Например, после того как вы авторизовались с помощью учётной записи «Google», браузер скрупулёзно собирает статистику всех введённых вами поисковых запросов и передаёт её. Чтобы проверить включены ли эти функции, нажмите на кнопке «Настройка и управление Google Chrome» (три точки) в правом верхнем углу программы, далее кликаем на ссылке «Настройки», или просто переходим по ссылке «chrome://settings/». Далее пролистываем вниз и кликаем на «Дополнительные», и в разделе “Конфиденциальность и Безопасность” выключаем два переключателя об автоматической отправке системной информации.
Данные авторизации в онлайн приложениях и веб-сервисах
Это самая важная информация, ваши личные данные авторизации, которые вы использовали для входа на разного рода сайты такие как поисковые системы, социальные сети, онлайн хранилища, веб-сайты электронных кошельков и так далее. Они включают: адреса электронной почты, пароли, ваши паспортные данные (данные форм), разного рода идентификаторы и другая информация, которая понадобиться для корректной работы с ними. Чем больше вы используете онлайн расширений и веб-сервисов, тем больше таких данных будет хранить браузер и постоянно передавать их приложениям.
Браузер «Firefox», использует простейшую синхронизацию, в неё входят закладки, открытые вкладки, история посещений, дополнения, используемые пароли и логины, а также настройки. Для синхронизации будет достаточно только адреса электронной почты. Чтобы настроить «Параметры синхронизации» нажмите на кнопку «Открыть меню», далее кликаем на «Настройка». На открывшейся странице настроек слева в меню кликаем на ссылку «Аккаунт Firefox» и доставляем или снимаем нужные галочки.
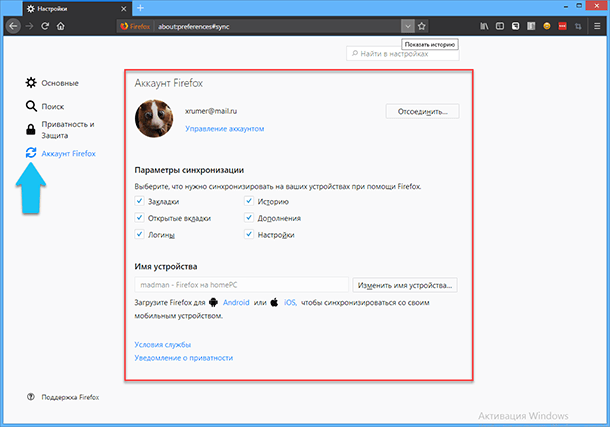
«Chrome» опять выделяется, синхронизация здесь также зависит только от адреса электронной почты, но если вы подключите к браузеру вашу учётную запись «Google», то на каком бы устройстве вы не авторизовались, всюду будет всплывать одинаковая реклама. К тому же, «Chrome» синхронизирует значительно больше параметров: сервисы, данные форм, закладки, расширения, история, пароли, настройки, темы, вкладки и данные о кредитных картах. Обязательно проверьте, чтобы была установлена галочка на шифровании синхронизированных паролей с помощью аккаунта «Google».
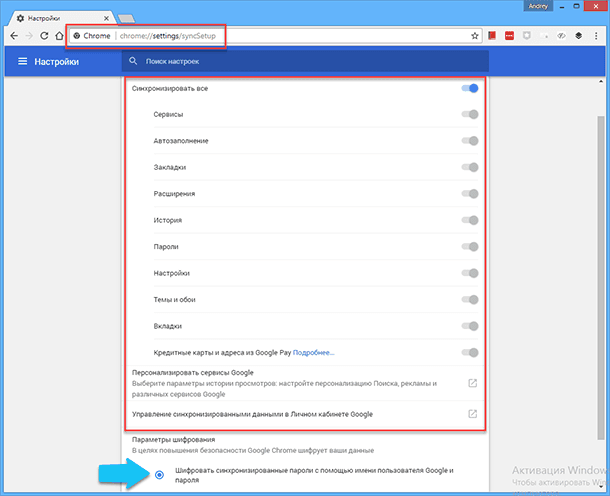
Чтобы дополнительно настроить параметры синхронизации в «Chrome», нажмите на кнопке «Настройка и управление Google Chrome», далее кликаем на ссылке «Настройки». После чего в разделе «Пользователи» кликаем на «Синхронизация» и выключаем или включаем нужные переключатели.
Сохранённые в браузере пароли
Как не странно, но абсолютно любой человек, которые сядет за ваш ПК и откроет браузер, сразу получит доступ к сохранённым данным авторизации, которые вы по небрежности сохранили. А также легко сможет посмотреть все данные в настройках браузера, без каких-либо препятствий. В браузере «Firefox» можно использовать функцию мастер-пароль, тогда перед открытием настроек его необходимо будет ввести.
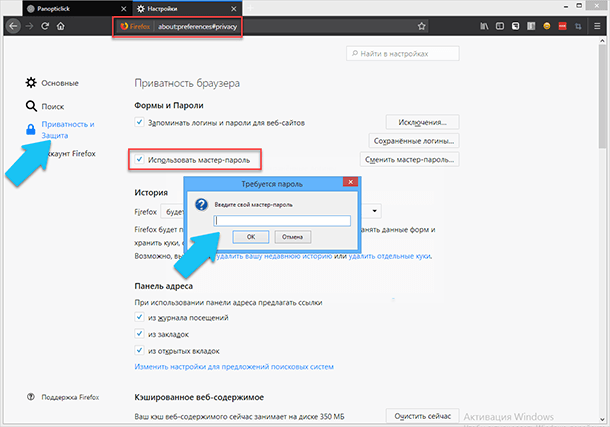
Чтобы избежать потери самых основных данных авторизации, таких как: электронная почта, пароли платежных систем и онлайн-банкинги, мы рекомендуем использовать для них сложносоставные слова-пароли понятные только вам, и никогда нигде их не сохранять и никому не рассказывать.
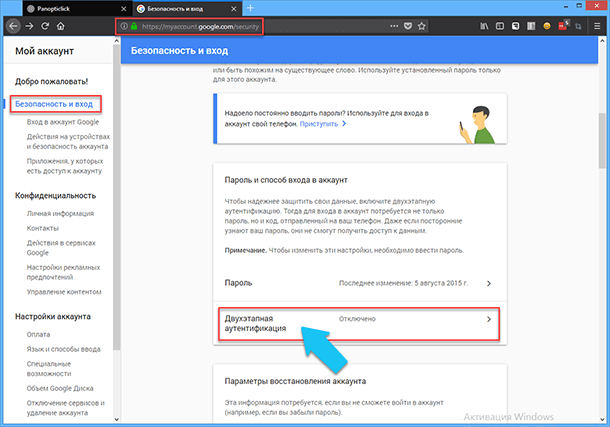
В настройках аккаунта «Google» можно использовать «Двухэтапную аутентификацию», то есть вместе с паролем система попросит ввести специальный код, который вам пришлют через смс, на электронную почту или в специализированном мобильном приложении. Чтобы включить «Двухэтапную аутентификацию» перейдите на страницу «Мой аккаунт» в настройках аккаунта «Google», или перейдите по ссылке «https://myaccount.google.com», далее кликаем на раздел «Безопасность и вход».
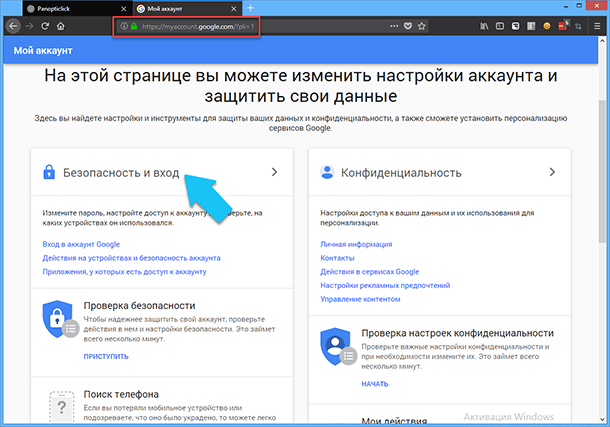
После чего, прокручиваем страницу вниз до раздела «Пароль и способ входа в аккаунт», находим ссылку «Двухэтапная аутентификация» и нажимаем на неё, далее кликаем на кнопку «Приступить» и выбираем нужный вам вариант.
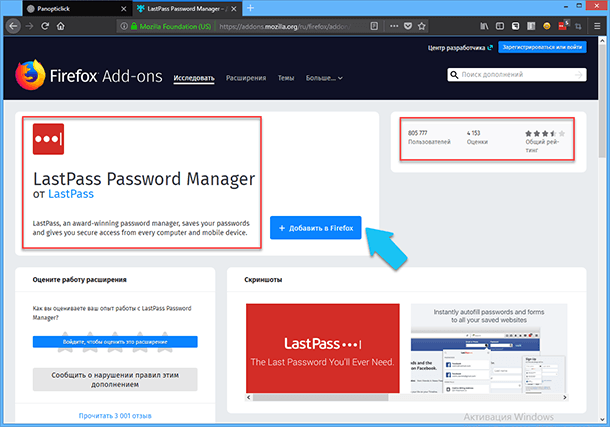
Для хранения всех других паролей используйте специальные программы или онлайн хранилища. Как вариант, могу порекомендовать веб-сервис «LastPass». То есть, запоминаем пароли для самых важных сервисов, плюс запоминаем и никогда не сохраняем ещё всего один для входа в «LastPass», вот и все методы предосторожности. В этом случае, даже если вы потеряете, или у вас украдут этот пароль, то вы всегда сможете сменить его с помощью электронной почты.
Сервис «Lastpass» разработал специальные расширения для большинства самых распространённых браузеров, для «Chome», «Opera», «Firefox», «Internet Explorer», «Safari» и «Microsoft Edge», и предоставляет его совершенно бесплатно. Обратите внимание, что приложение для мобильных устройств платное. Работать с ним очень просто, управление и настройка предельно понятны. Также «LastPass» позволяет открывать веб-сайты в один клик, а логин и пароль автоматически пропишутся в нужных полях. Ещё, как дополнение, присутствует встроенный настраиваемый генератор паролей, чтобы вы не мучились, придумывая новый безопасный пароль. Ещё приложение предоставляет защищённое хранилище для крайне важной для вас информации, чтобы посмотреть данные хранящиеся там, необходимо будет заново ввести мастер-пароль.
Более подробно о дополнении «LastPass» вы сможете узнать в статьях на нашем сайте: 17 самых полезных дополнений для браузера Google Chrome и ТОП 17 расширений для Firefox Quantum.
Информация о поведении на странице
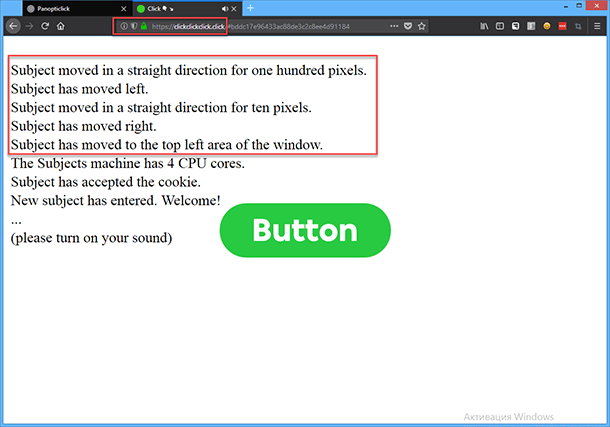
Множество самых современных веб-сайтов также могут более тщательно отслеживать ваши действия на странице. Чтобы убедиться в этом самому, перейдите на сайт «clickclickclick.click», который с лёгкостью будет собирать и выводить вам сообщения о движениях мыши, нажатиях на кнопки и ссылки на странице, а также многие другие действия в браузере.
Но это лишь вершина айсберга, это лишь малая часть той личной информации, которая собирается о вас в сети. Ваш браузер, показывающий, что вы используете, допустим «Google Chrome» где-то в Украине, толком не сообщает о вас ничего, но эти данные можно комбинировать с другими, чтобы выделить вас из толпы.
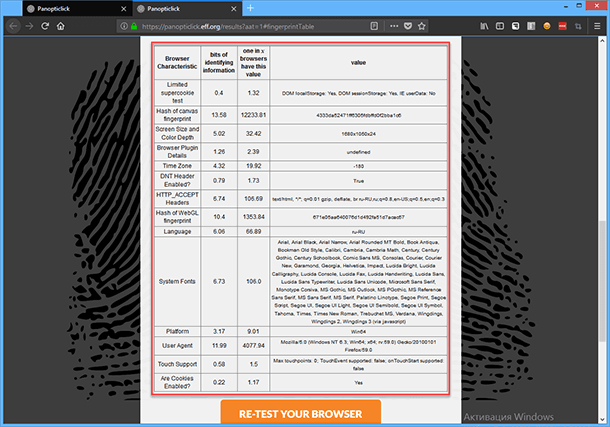
Проведите тест «Panopticlick» (https://panopticlick.eff.org/) созданный организацией «Electronic Frontier Foundation» – Фонда Электронных Рубежей. Это некоммерческая правозащитная организация, созданная для защиты конфиденциальности в связи с открытием новых видов коммуникаций. С помощью него вы сможете узнать гораздо больше о том, как ваш браузер может сформировать и транслировать в интернет ваш уникальный отпечаток.
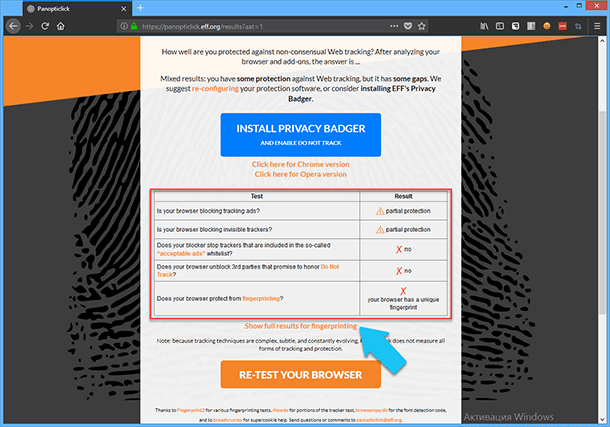
К уже известной информации добавляется, ваше собственное конкретное сочетание дополнений, плагинов и поддерживаемых технологий браузера, установленной конфигурации ПК, языка системы по умолчанию, даже шрифтов, которыми вы пользуетесь. Если скомбинировать все эти параметры, то можно с достаточно большой вероятностью идентифицировать именно ваш ПК, и собирая информацию о сайтах, которые вы посещаете, определить весь круг ваших интересов. А если в браузере сохранены пароли для социальных сетей, то и идентифицировать вас как личность.
Даже если вы не авторизовались на веб-сайте, то он все равно может догадаться, являетесь ли вы тем же «незнакомцем», который кликнул на какую-нибудь рекламу неделю назад, и благополучно завалить вас подобной или ещё что похуже. Опять же, данные передаваемые браузером – это только начало. Следующий шаг – это веб-сайты содержащие большое количество вашей личной информации, которую можно отследить.
Подразумеваемое слежение, файлы «cookie»
Большинство веб-порталов крайне заинтересованы в том, чтобы «узнать» как можно больше о вас, будь то для большей персонализации своих услуг, или для более качественного подбора рекламы (например: Google, Yandex, Facebook, Twitter, Vk и так далее).
Чтобы лучше регистрировать эти данные, они сохраняют «cookie-файлы» в вашей системе, когда вы в первый раз посещаете сайт. Файлы «cookie» действуют как специальные маркеры, служащие для вашей идентификации. При каждом повторном посещении веб-сайта, именно «cookie-файлы» сообщают о том, что вы были там раньше.
Ещё, они служат для сохранения ваших настроек для каждого отдельного сайта, таким образом экономя ваше время, не выбирая своё местоположение каждый раз на сайтах погоды, «cookie» также может хранить предметы в корзине покупок (для сайтов онлайн магазинов), чтобы они ждали, когда вы вернетесь.
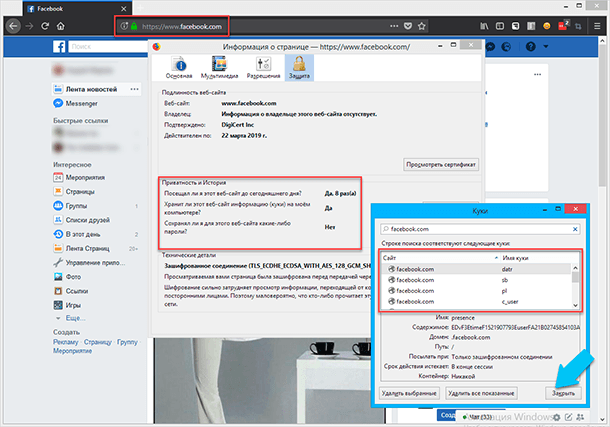
В принципе, это очень полезная штука для сайтов и пользователей. Но «cookie» могут пойти дальше и будут постоянно добавлять все больше и больше деталей в вашу личную историю, которая сначала будет комплектоваться всеми данными, сообщаемыми вашим браузером.
Протокол безопасности браузера следит за тем, чтобы веб-сайты смогли получить доступ только к своим собственным файлам «cookie». Но каким-то образом, на вашем ПК появляются сторонние файлы «cookie», которые не связаны с конкретным сайтом, но могут быть сохранены на ПК через многослойные страницы, рекламные сети или другие продвинутые технологии отслеживания.
Что такое межсайтовый мониторинг и сторонние файлы «cookie»?
При загрузке страницы, веб-порталы могут подгружать сторонние файлы и ресурсы (изображения, скрипты т.д.) хранящиеся на других доменах в сети. Это называется перекрестной или межсайтовой загрузкой, и это одна из самых мощных функций сети. Однако, эта функция также обеспечивает межсайтовое отслеживание действий пользователей в интернете.
Представьте себе, что вы сначала зашли на какой-либо сайт в поисках нового гаджета, а затем зашли на какой-то другой сайт с рецептами. Теперь представьте, что оба этих сайта подгружают информацию с третьего (стороннего) домена, естественно сторонний веб-сайт использует файлы «cookie», которые сохранятся в вашей системе. Напомню, что вы не посещали третий сайт на прямую, но теперь, благодаря «cookie», владелец этого сайта сможет узнать, что вы посетили оба первых веб-сайта, будет знать какие именно товары и рецепты просматривали, каким браузером пользовались и так далее. Это и называется межсайтовым отслеживанием, а такие «cookie-файлы» – называются сторонними. В сети уже сейчас полно веб-порталов, которые используют данную технологию, и все «МОЛЧА» собирают данные о пользователях.
Именно сторонние «cookie-файлы» ответственны за то, что вы целую неделю, наблюдаете рекламу телефонов только потому, что пару раз открывали интернет магазин гаджетов. В последней версии своего веб-браузера «Safari», компания «Apple» начала активно бороться с межсайтовым мониторингом и стала блокировать сторонние «cookie-файлы», к большому огорчению рекламодателей.
По сути, этот метод используется только для того, чтобы распознать, кто вы и подобрать для вас более подходящую рекламу. Данные о посещении веб-сайтов, поисковых запросах, файлах «cookie» и вашем браузере сочетаются с определёнными догадками рекламщиков, чтобы попытаться спрогнозировать, какие именно объявления вам больше всего интересны.
Более того, недавнее исследование, проведенное в Принстонском университете, показало, что межсайтовые трекеры, встроенные в 482 из 50 000 сайтов в Интернете. Они записывают практически всю активность пользователей в браузере и анализируют её. Эти записи якобы предназначены для улучшения управления сайтом и оптимизации интерфейса, но в то же время, пользователям приходится просто доверять свои личные данные сторонней компании, даже не подозревая об этом.
Есть еще одна группа компаний, которая может «сливать» рекламщикам подобные данные, это интернет-провайдеры, у которых теперь появилась возможность дополнительно зарабатывать деньги, продавая историю просмотров. Позволяя рекламодателям узнать, какие именно веб-сайты вы посещали, и какие товары вас интересуют в данный момент.
Все виды данных описанные выше, не могут работать по одиночке, именно собрав их воедино и правильно структурировав, маркетинговые компании смогут собрать ваш полный профиль. И каждый день он будет становится всё более подробным.
Добровольно предоставляемая информация, социальные сети
До сих пор, мы еще не говорили о данных, которые вы передаёте в сеть абсолютно добровольно: список поисковых запросов, которые вы вводите в «Google» с подключенной учётной записью, посещённые места, которые вы отмечаете в «Facebook», дата рождения, которую вы ввели в описании профиля «Twitter» и так далее.
Все эти мега-порталы придерживаются своей собственной политики конфиденциальности, которая оговаривает то, как эти данные могут быть использованы. Как правило, данные собираются для более эффективной таргетированной рекламы, и для улучшения продуктов и сервисов, которые вам предоставляются. Пользователям просто ничего не остаётся как мириться с этим сбором личной информации, если вы и дальше хотите использовать все «плюшки», о которых идет речь.

Например, если у вас есть учетная запись «Tumblr», то вы самостоятельно предоставляете «Tumblr» разрешению фактически контролировать все, что вы делаете в сети. Это отчасти также вопрос здравого смысла, именно поэтому социальные сети могут отслеживать поведение пользователей и якобы исправлять ошибки, но в тоже время они постоянно собирают и анализируют все больше данных о вас.
Объедините всю эту личную информацию вместе с данными, о которых мы уже говорили выше, и получается, что такие крупнейшие порталы, как «Google» и «Facebook», могут легко знать о вас больше, чем вы сами знаете.
В прошлом году, компания «Google» внесла изменения в свою политику конфиденциальности, чтобы данные из рекламной сети «DoubleClick» могли быть объединены с другими данными, такими как ваше имя и ваши любимые видео «YouTube», чтобы создать самую полную картину о вас и ваших вкусах. Не у каждой маркетинговой компании есть доступ к информации «Google» или «Facebook», но такие данные легко покупаются и продаются между компаниями, специализирующимися на их сборе.
В сети «Facebook» только вы можете указать, кто ваши близкие друзья, какие места вы посетили, и оставить отзыв о понравившемся, как часто вы заказываете еду, на какие группы вы подписаны, и соответственно, что именно вам больше всего интересно.
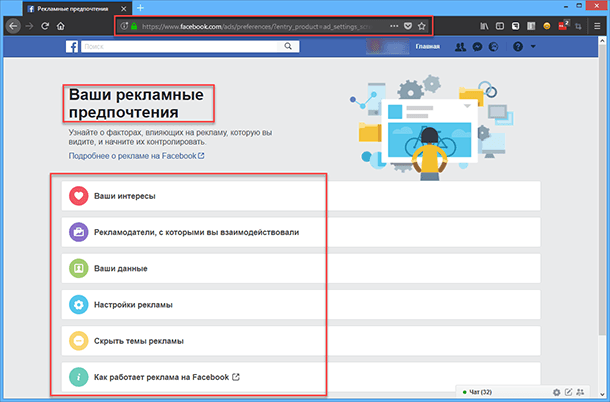
Благодаря этой информации, вашему браузеру и данным, которые «Facebook» собирает когда вы онлайн, компания знает, когда вы ожидаете рождения ребенка, какой вы придерживаетесь политики, время, которое вы просиживаете в Интернете. Зная всё это, «Facebook» самостоятельно подбирает вам рекламу и разного рода предложения (группы, приложения, события и т.д.), но также предоставляет вам возможность самому настроить эти параметры, для этого перейдите по ссылке: «https://www.facebook.com/ads/preferences/?entry_product=ad_settings_screen»
Возможно, самая большая социальная сеть в мире может нарушать общепринятую политику безопасности в плане того, какое количество персональных данных она может собирать и использовать. Но принципы остаются одинаковы для всех сайтов в мире, будь то те, которые вы используете для покупок, или поиска путешествий, или чтения новостей.
На самом деле, политика конфиденциальности каждого отдельного сайта сводится к тому, как все собранные данные регистрируются и используются владельцами сайтов. Они, как правило, оперируют очень широкими и расплывчатыми понятиями, которые дают им большую свободу действий, когда дело касается обработки информации в профилях. Вся проблема в том, что в мире не существует единых правовых норм, полностью описывающих процесс сбора, анализа, распространения и использования данных о пользователях. И это очень печально.
Как минимизировать предоставляемую информацию в сети
Сбор данных о поведении пользователей на сайте, по своей сути не является нарушение закона и не несёт прямого вреда. Веб-сайтам нужны эти данные, чтобы совершенствовать предлагаемые продукты и сервисы, а также предлагать релевантные рекламные объявления, благодаря которым они зарабатывают и держаться на плаву. Тем не менее, вы должны предельно точно осознавать, что они собирают все данные, в том числе и личную конфиденциальную информацию, что не есть хорошо. Статью о том, как бороться со слежкой и избежать неприятностей в сети, читайте на нашем сайте.
Подходы к извлечению данных из веб-ресурсов
В предыдущей статье мы рассмотрели основные понятия и термины в рамках технологии Data Mining. Сегодня более детально остановимся на Web Mining и подходах к извлечению данных из веб-ресурсов.
- Анализ DOM дерева, использование XPath.
- Парсинг строк.
- Использование регулярных выражений.
- XML парсинг.
- Визуальный подход.
Анализ DOM дерева
Этот подход основывается на анализе DOM дерева. Используя этот подход, данные можно получить напрямую по идентификатору, имени или других атрибутов элемента дерева (таким элементом может служить параграф, таблица, блок и т.д.). Кроме того, если элемент не обозначен каким-либо идентификатором, то к нему можно добраться по некоему уникальному пути, спускаясь вниз по DOM дереву, например:
body -> p[10] -> a[1] -> текст ссылки
или пройтись по коллекции однотипных элементов, например:
body -> links -> 5 элемент -> текст ссылки
- можно получить данные любого типа и любого уровня сложности
- зная расположение элемента, можно получить его значение, прописав путь к нему
- различные HTML / JavaScript движки по-разному генерируют DOM дерево, поэтому нужно привязываться к конкретному движку
- путь элемента может измениться, поэтому, как правило, такие парсеры рассчитаны на кратковременный период сбора данных
- DOM-путь может быть сложный и не всегда однозначный
Data Extracting SDK использует Microsoft.mshtml для анализа DOM дерева, но является «надстройкой» над библиотекой для удобства работы:
UriHtmlProcessor proc = new UriHtmlProcessor( new Uri ( «http://habrahabr.ru/new/page1/» ));
proc.Initialize();
var links = from l in proc.Links
where l.Class == «topic» && EndsWithInt(l.Href) == true
select new ResultItem <
Link = l.Href,
TopicName = l.Text.ToWindows1251()
>;
* This source code was highlighted with Source Code Highlighter .
Следующим эволюционным этапом анализа DOM дерева является использования XPath — т.е. путей, которые широко используются при парсинге XML данных. Суть данного подхода в том, чтобы с помощью некоторого простого синтаксиса описывать путь к элементу без необходимости постепенного движения вниз по DOM дереву. Данный подход использует всеми известная библиотека jQuery и библиотека HtmlAgilityPack:
HtmlDocument doc = new HtmlDocument();
doc.Load( «file.htm» );
foreach (HtmlNode link in doc.DocumentElement.SelectNodes( «//a[@href» ])
<
HtmlAttribute att = link[ «href» ];
att.Value = FixLink(att);
>
doc.Save( «file.htm» );
* This source code was highlighted with Source Code Highlighter .
Парсинг строк
Несмотря на то, что этот подход нельзя применять для написания серьезных парсеров, я о нем немного расскажу.
Иногда данные отображаются с помощью некоторого шаблона (например, таблица характеристик мобильного телефона), когда значения параметров стандартные, а меняются только их значения. В таком случае данные могут быть получены без анализа DOM дерева, а путем парсинга строк, например, как это сделано в Data Extracting SDK:
Компания: Microsoft
Штаб-квартира: Редмонд
string data = «<p>Компания: Microsoft</p><p>Штаб-квартира: Редмонд</p>» ;
string company = data.GetHtmlString( «Компания: » , «</p>» );
string location = data.GetHtmlString( «Штаб-квартира: » , «</p>» );
// output
// company = «Microsoft»
// location = «Редмонт»
* This source code was highlighted with Source Code Highlighter .
Использование набора методов для анализа строк иногда (чаще — простых шаблонных случаях) более эффективный чем анализ DOM дерева или XPath.
Регулярные выражения и парсинг XML
Очень часто видел, когда HTML полностью парсили с помощью регулярных выражений. Это в корне неверный подход, так как таким образом можно получить больше проблем, чем пользы.
Регулярные выражения необходимо использоваться только для извлечения данных, которые имеют строгий формат — электронные адреса, телефоны и т.д., в редких случаях — адреса, шаблонные данные.
Еще одним неэффективным подходом является рассматривать HTML как XML данные. Причина в том, что HTML редко бывает валидным, т.е. таким, что его можно рассматривать как XML данные. Библиотеки, реализовавшие такой подход, больше времени уделяли преобразованию HTML в XML и уже потом непосредственно парсингу данных. Поэтому лучше избегайте этот подход.
Визуальный подход
В данный момент визуальный подход находится на начальной стадии развития. Суть подхода в том, чтобы пользователь мог без использования программного языка или API «настроить» систему для получения нужных данных любой сложности и вложенности. О чем-то похожем (правда применимым в другой области) — методах анализа веб-страниц на уровне информационных блоков, я уже писал. Думаю, что парсеры будущего будут именно визуальными.
Проблемы и общие рекомендации
Проблемы при парсинге HTML данных — использование JavaScript / AJAX / асинхронных загрузок очень усложняют написание парсеров; различные движки для рендеринга HTML могут выдавать разные DOM дерева (кроме того, движки могут иметь баги, которые потом влияют на результаты работы парсеров); большие объемы данных требуют писать распределенные парсеры, что влечет за собой дополнительные затраты на синхронизацию.
Нельзя однозначно выделить подход, который будет 100% применим во всех случаях, поэтому современные библиотеки для парсинга HTML данных, как правило, комбинируют, разные подходы. Например, HtmlAgilityPack позволяет анализировать DOM дерево (использовать XPath), а также с недавних пор поддерживается технология Linq to XML. Data Extracting SDK использует анализ DOM дерева, содержит набор дополнительных методов для парсинга строк, а аткже позволяет использовать технологию Linq для запросов в DOM модели страницы.
На сегодня абсолютным лидером для парсинга HTML данных для дотнетчиков является библиотека HtmlAgilityPack, но ради интереса можно посмотреть и на другие библиотеки.
Веб-данные на службе вашего бизнеса
«Кто владеет информацией, тот владеет миром», — справедливо заметил Натан Ротшильд еще двести лет назад. Крупные технологические компании давно поняли, что Интернет — самая большая база данных, созданная за всю историю человечества, а сбор и анализ информации онлайн это ключ к пониманию своего потребителя, конкурентов, рынка, построению выверенных ценовых алгоритмов и управлению брендом. Сбор и структурирование общедоступных данных с сайтов называется веб-парсинг.
Но для компаний среднего и малого бизнеса, которые хотят воспользоваться публичными данными, существует невидимый технологический барьер — вместе с ростом спроса на веб-данные, развиваются и технологии, препятствующие свободному, прозрачному сбору информации. Сбор данных также осложняет динамичная природа Интернета: постоянно меняющаяся структура целевых сайтов, постоянно обновляющиеся в режиме реального времени данные, огромное количество страниц, которые необходимо парсить и очищать полученные массивы данных.
Data collector — технологическое решение, которое позволяет полностью автоматизировать парсинг данных из Интернета без необходимости писать код, инвестировать в инфрастуктуру и девелоперские ресурсы. Это продукт авторства израильской HighTech-компании Bright Data – ведущей мировой платформы для парсинга веб-данных. Метод ее работы являет собой абсолютно новый, прорывной подход к автоматизированному парсингу данных из Интернета для нужд бизнеса.
Принцип работы Data Collector основан на использовании десятков миллионов резидентных и серверных айпи в сочетании с запатентованными технологиями автоматического обхода блокировки публичных веб-сайтов и последующего за этим парсинга данных.
Главное преимущество перед традиционным парсингом сайтов в том, что Data Collector опирается на собственную прокси-инфрастуктуру, которая изначально создавалась для коммерческого сбора открытой информации из Интернета и является самой большой прокси-инфраструктурой в мире.
72 миллиона резидентных айпи, 900 тысяч серверных айпи и порядка 7 миллионов мобильных айпи, рассредоточеных по всему миру, супер-серверы балансирующие нагрузку и способные выдерживать пиковый трафик в десятки террабайт в час и посылать миллионы параллельных запросов с 100% безотказной работой сети.
Это позволяет клиентам Bright Data сэкономить тысячи долларов на покупке и поддержании собственных прокси.
Вторая черта, это встроенная запатентованная технология разблокировки доступа к публичным веб-сайтам на основе искусственного интеллекта. Алгоритмы ИИ постоянно анализируют целевые сайты, распознают изменения в разметке, решают капчу, вычисляют и генерируют цифровые отпечатки, которые будут оптимально работать именно с этим доменом. Разблокировка также включает в себя такие механизмы как fall back, retry, waterfall для того, чтобы обеспечить 100% успешности исполнения запроса.
Те, кто занимается парсингом сайтов давно, знают, насколько трудоемким может быть этот этап. Поэтому его автоматизации позволяет владельцам бизнеса облегченно вздохнуть — сбор критически важных веб-данных никогда неожиданно не остановится и для этого больше не нужно тратить девелоперские ресурсы.
Третья черта — богатейшая, постоянно обновляемая и бесплатная библиотека веб-парсеров* (коллекторов) для самых популярных целевых сайтов. Только в категории «Электронная коммерция» доступно более 100 постоянно поддерживаемых и обновляемых командой топ-инженеров Bright Data веб-парсеров. В категории «Социальные сети» есть веб-парсеры для 20 самых популярных платформ — Facebook, Instagram, LinkedIn, TikTok, Telegram и так далее. Те, кто занимается сбором деловой информации онлайн, будут рады узнать, что уже давно разработаны и поддерживаются веб-парсеры для owler, crunchbase, appollo и так далее.
Любой шаблонный веб-парсер можно легко приспособить под свои уникальные задачи с помощью бесплатного low-code интерфейса для создания и редактирования веб-парсеров.
Заключительный этап сбора данных это их доставка и интеграция в процессы компании. Доступные форматы: JSON, ndjson, CSV, XLSX, HTML. Способы доставки — прямая интеграция, email, API download, Webhook, Amazon S3, Google Cloud Storage, Microsoft Azure Storage, SFTP.
Таким образом, чтобы начать парсить веб-данные для бизнеса, не нужно ничего — ни прокси-инфраструктура, ни программы для разблокировки сайтов, ни умения писать код. Достаточно аккаунта в Bright Data.
Большинство компаний сегодня уже признают значение веб-данных для своего бизнеса. Парсинг и анализ публичных веб-данных стал неотъемлемой частью исследования рынка, двигателем совершенствования операционных процессов и поддержания конкурентного преимущества. Те, кто не пользуются веб-данными, остаются позади. Можно выделить 4 основных направления сбора веб-данных:
парсинг платформ электронной коммерции: цены, новинки, промо-акции, ассортимент, наличие на складе, описание, фото продуктов
парсинг данных поисковой выдачи: по ключевым словам, по регионам, по типу пользовательского устройства
парсинг деловых данных: LinkedIn, Owler, Crunchbase и другие источники деловой информации
Но хватит теории! Перейдем к конкретным примерам из практики.
Fornova является лидером рынка с самой полной глобальной базой данных в сфере туризма и работает с крупнейшими гостиничными сетями и онлайн-платформами, которые постоянно задают такие вопросы, как: «Насколько конкурентоспособна моя недвижимость?»; «Как моя собственность представлена в разных каналах сбыта?»; «Какова правильная ставка для этого предложения?» Чтобы ответить на эти вопросы компания ежедневно отслеживает более 100 000 отелей, десятки OTA, метапоисков и сайтов бронирования, а также отслеживает 1,25 миллиарда тарифов из более чем 75 разных стран каждый месяц.
Есть много компаний, которые могут собирать публичные данные с сотен веб-страниц ежедневно, но когда у вас есть сотни тысяч или миллионы страниц с данными, вам нужна очень сложная технология, чтобы действительно выжать из этих данных максимальную отдачу. Именно здесь на помощь приходит компания Bright Data, которая помогает нам добиться успеха в том, что мы предлагаем нашим клиентам.
Superscanner отслеживает цены в розничных сетях, особенно в пищевой и фармацевтической промышленности. Компания собирает миллионы точек данных, сопоставляет идентичные или похожие продукты и делает их доступными через аналитическую панель, экспорт и API для розничных продавцов и брендов. Используя эту технологию, Superscanner обслуживает почти все розничные сети в Нидерландах, а также множество ритейлеров в Бельгии, некоторые во Франции, некоторые в Люксембурге и некоторые в Германии.
Bright Data экономит нам много времени и освобождает сотрудников для выполнения важной работы, которую в противном случае они не смогли бы делать. Самое большое преимущество использования технологий Bright Data заключается в том, что мы можем забыть об их существовании. [. ] По сути, мы можем просто положиться на Bright Data в сборе необходимых нам веб-данных. Мы планируем продолжать использовать их инструменты и в будущем.
Андрис Моой,
Технический директор Superscanner
Mathison предлагает первую в своем роде инновационную комплексную систему для управления набором персонала, измерением стратегии и отчетностью. Платформа централизует сотни инклюзивных сетей талантов и использует ИИ, чтобы помочь работодателям находить кандидатов на их самые важные должности. Чтобы сохранить разнообразие кадров, Mathison предоставляет работодателям единый интерфейс для управления разнообразной деятельностью по найму. Это включает в себя поиск различных кандидатов; снижение предвзятости в описании должностных обязанностей; отбор кандидатов и собеседования; и мобилизация членов команды для усилий по инклюзивному найму с инструментами для повышения осведомленности и изменения поведения. Среди клиентов Mathison такие компании, как Hello Fresh, TripAdvisor и Sonos.
Bright Data — чрезвычайно ценный партнер, который помогает нам удовлетворить наши растущие потребности в онлайн-данных, поскольку мы можем передать наши усилия по сбору и управлению данными на аутсорсинг.
Зарегистрируйте аккаунт на сайте Bright Data и следуйте инструкциям по активации. После активации аккаунта, для настройки вашего парсера выполните три простых шага:
— Определите целевые сайты и данными, которые вы хотите с них парсить.
— Затем определите периодичность, с которой вы хотите получать данные и формат доставки.
— И наконец, выберите, куда отправлять готовые результаты.
Для новых пользователей первый веб-парсер — бесплатный.
*Для клиентов Bright Data все шаблонные веб-парсеры доступны бесплатно, так же как и интерфейс для их редактирования. Оплата производится исключительно по количеству загруженных страниц (CPL).
Как очистить кэш браузера
Читайте статью, если хотите узнать, что такое кэш, зачем он нужен и как быстро очистить кэш интернет-браузера.
Что такое кэш
Чтобы понять, что такое кэш, нужно разобраться, как работают интернет-браузеры.
Дело в том, что любой сайт — это набор файлов. Файлы каждого сайта хранятся на одном из серверов в интернете. Чтобы попасть на сайт, сначала нужно найти его файлы в интернет-пространстве. Поэтому когда пользователь вводит запрос в поисковую строку, браузер сразу начинает искать сервер, на котором размещен сайт. Затем он обращается к этому серверу и запрашивает у него файлы сайта. Сервер дает ответ, и в браузере открывается искомая страница.
Этот процесс не виден пользователю, поскольку браузер выполняет его в автоматическом режиме. Со стороны пользователя процесс не выглядит сложным, однако на техническом уровне тратятся время и ресурсы системы.
Чтобы тратить меньше ресурсов, придумали систему кэширования. Кэш — это буферная зона на системном диске, в которой хранятся временные файлы браузера. Кэш позволяет хранить данные (скрипты, картинки, видео и другое) интернет-ресурсов и страниц сайтов, которые недавно посещал пользователь.
Если пользователь захочет зайти на один из ресурсов повторно, браузер возьмет файлы сайта из кэша — папки на системном диске компьютера. Это позволит значимо сократить время повторной загрузки страницы и сэкономить резервы интернет-системы.
Кэш легко перепутать с cookie-файлами и историей посещений браузера. Однако эти элементы слабо связаны друг с другом, поскольку имеют принципиальные различия. История браузера — это перечень всех интернет-ресурсов, на которые в определенный временной период заходил пользователь. Cookie — это небольшие отрывки данных, которые браузер запоминает, а затем использует при аутентификации (например, логин и пароль), воспроизведении настроек и подсчете статистики. В кэш попадает вся техническая информация (html-код, стили CSS, медиафайлы) страниц сайтов, на которые недавно заходил пользователь.
Для чего нужно чистить кэш
Можно сказать, что кэш — это кратковременная память браузера. Следовательно, в ней может хранится ограниченное количество данных и информации. Если в кэше набирается слишком много информации, система начинает функционировать хуже. В этом случае кэш затрудняет работу — страницы грузятся медленнее, браузер и вся система подвисает, что создает проблемы для пользователя.
Также «залежавшийся» кэш нередко играет злую шутку с пользователем. Самый яркий пример — страницы с ошибками. Если при первом переходе на сайт вы столкнулись с ошибкой, браузер запомнит его именно в таком виде. Даже если работа ресурса позднее будет восстановлена, при повторном переходе вы увидите всё ту же ошибку из кэша. Всё это наводит на мысль о том, что кэш необходимо регулярно чистить.
Система кэширования встроена во все современные интернет-браузеры. В инструкциях ниже мы покажем универсальные способы, с помощью которых можно очистить кэш в таких популярных браузерах, как Google Chrome, Mozilla Firefox, Opera, Яндекс.Браузер, Internet Explorer (Edge) и Safari.
С помощью наших инструкций вы сможете как очистить кэш браузера на ноутбуке, так и на стационарном компьютере и других устройствах. Чтобы удалить кэш с мобильного устройства на Android , используйте статью Как очистить кэш браузера на телефоне.
Очистка кэша в Google Chrome
Мы описали наиболее универсальный способ очистить кэш браузера Google. Если вы хотите узнать другие способы очистки, читайте статью Как очистить кэш в браузере Google Chrome.
В браузере нажмите на кнопку с тремя точками. Затем кликните Настройки:
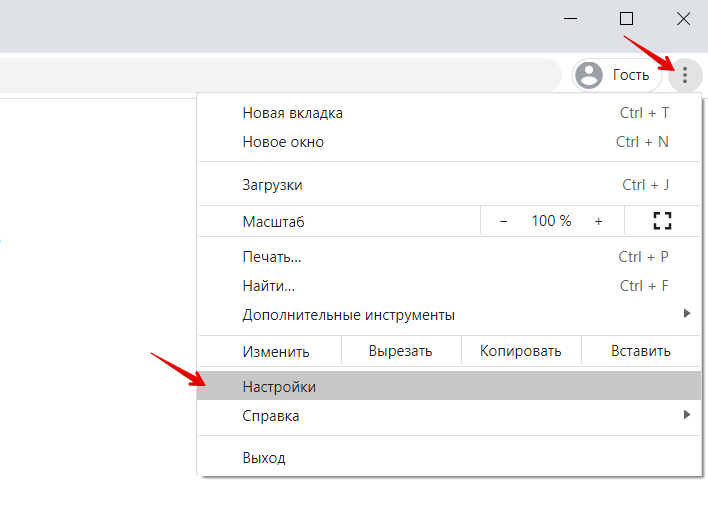
Пролистайте страницу до раздела «Конфиденциальность и безопасность» и нажмите Очистить историю:
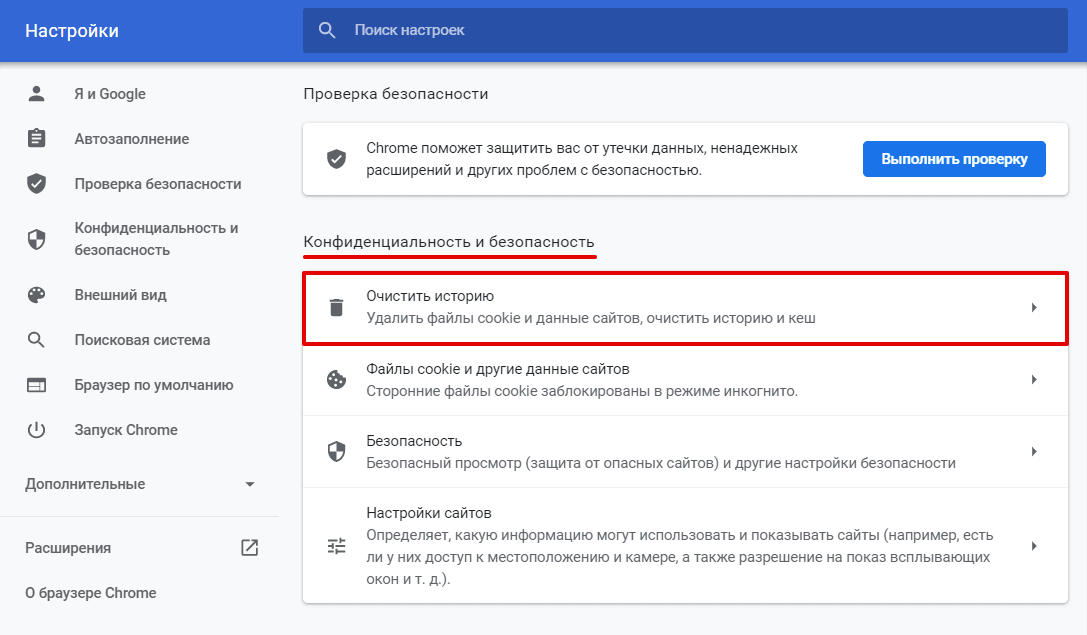
Отметьте чекбокс «Изображения и другие файлы, сохраненные в кеше». Затем выберите нужный временной диапазон в выпадающем списке:
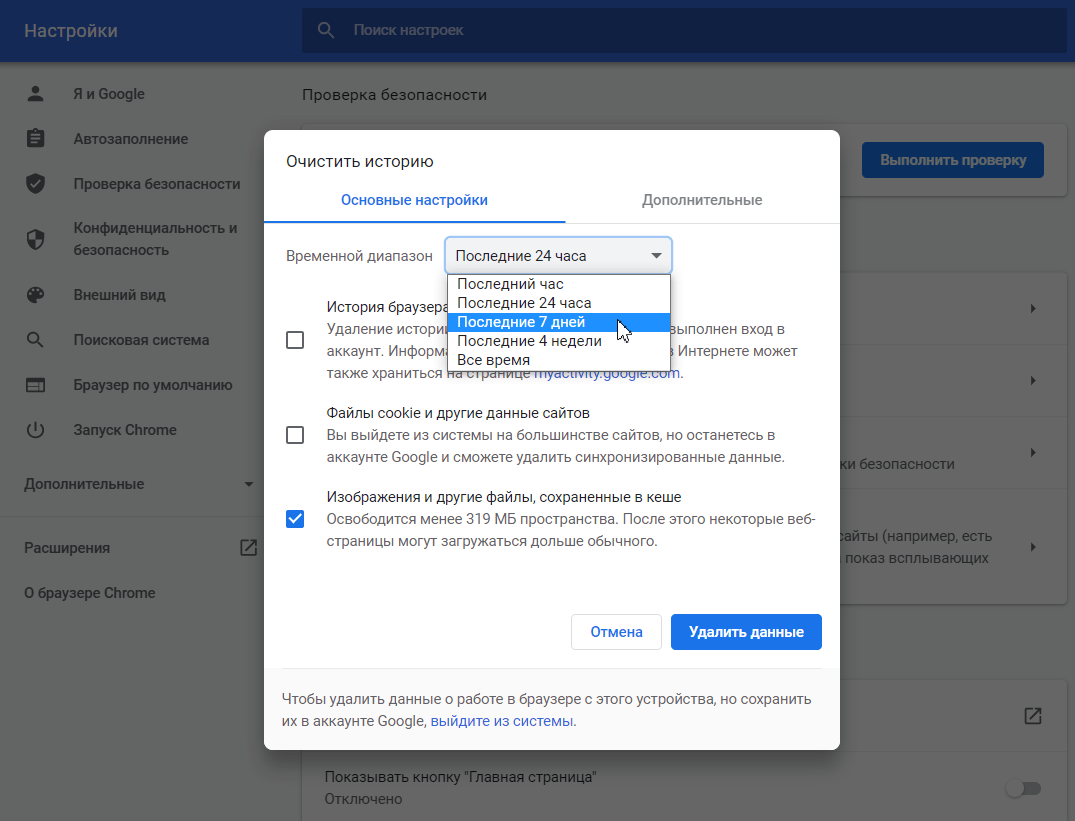
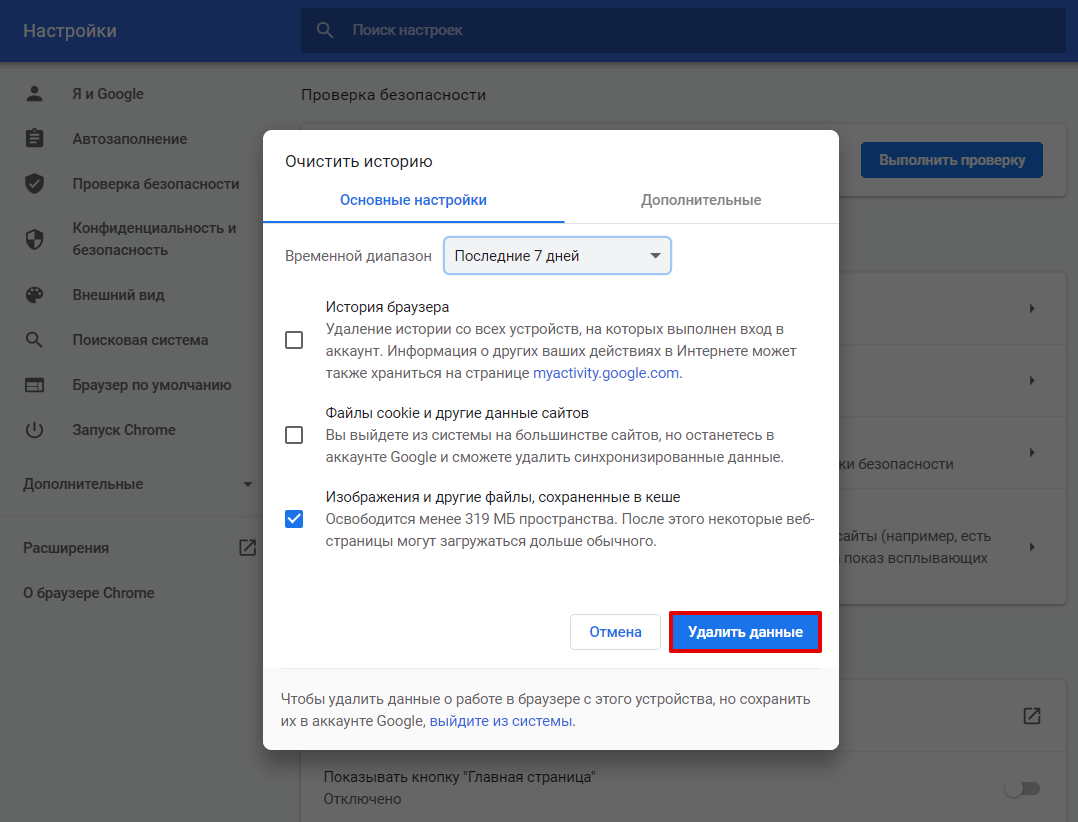
Кликните Удалить данные:
Очистка кэша в Яндекс.Браузер
Мы описали наиболее универсальный способ очистить кэш в браузере Яндекс. Если вы хотите узнать другие способы очистки, читайте статью Как очистить кэш в Яндекс.Браузере.
Нажмите Настройки:
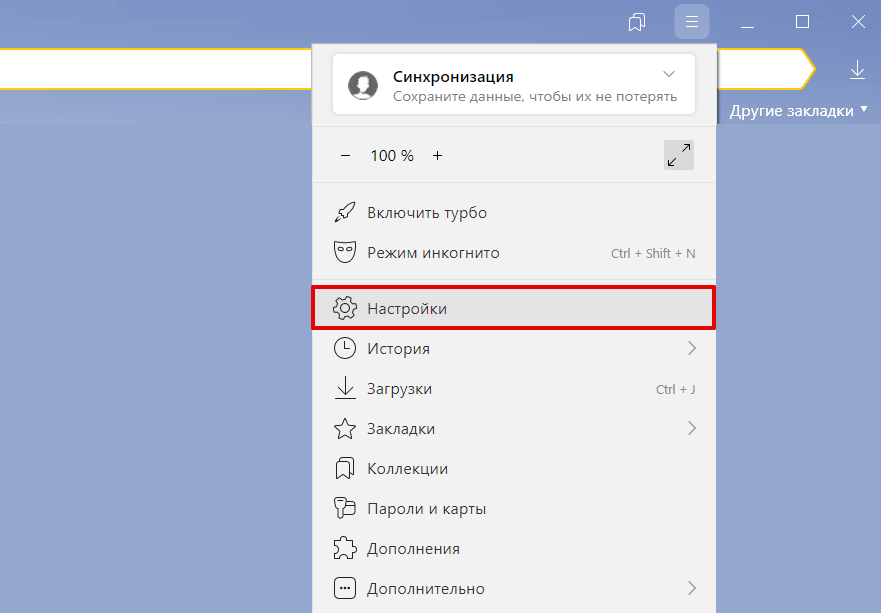
В левом меню выберите блок «Системные» и прокрутите страницу до конца. Нажмите Очистить историю:
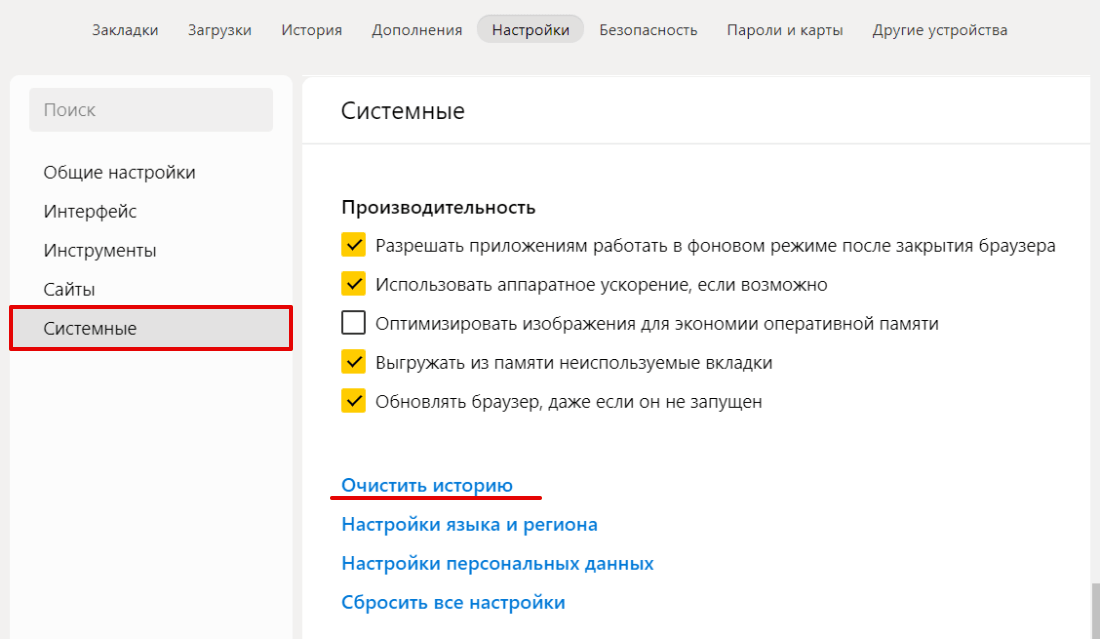
Обратите внимание! Для вызова настроек куки и кэша можно использовать горячие клавиши. Введите сочетание клавиш Ctrl + Shift + Del и перед вами откроется окно настроек.
Очистка кэша в Mozilla Firefox
Мы описали наиболее универсальный способ очистить кэш в браузере Mozilla. Если вы хотите узнать другие способы очистки, читайте статью Как очистить кэш браузера Mozilla Firefox.
Кликните в правом углу экрана на три горизонтальные линии и нажмите Настройки:
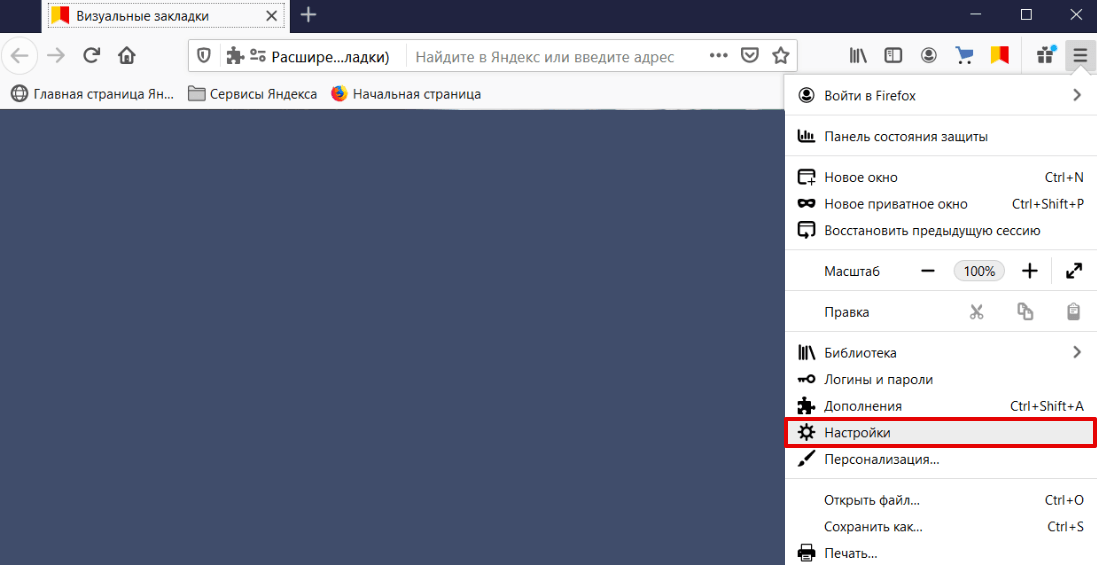
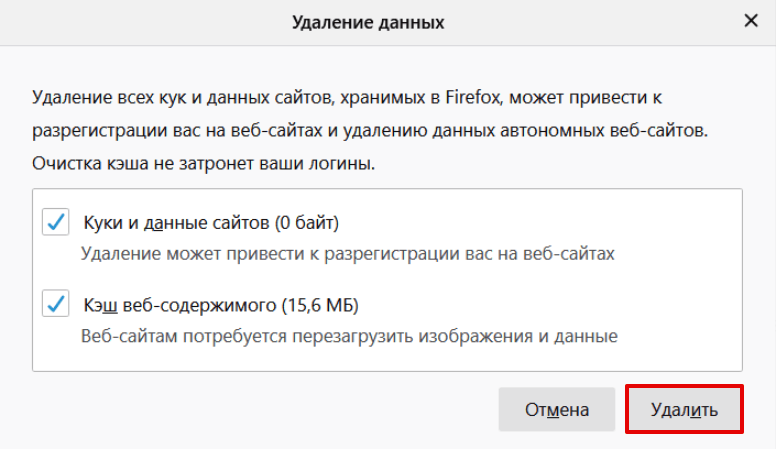
В левом меню выберите «Приватность и Защита». Прокрутите страницу до блока «Куки и данные сайтов» и нажмите Удалить данные:
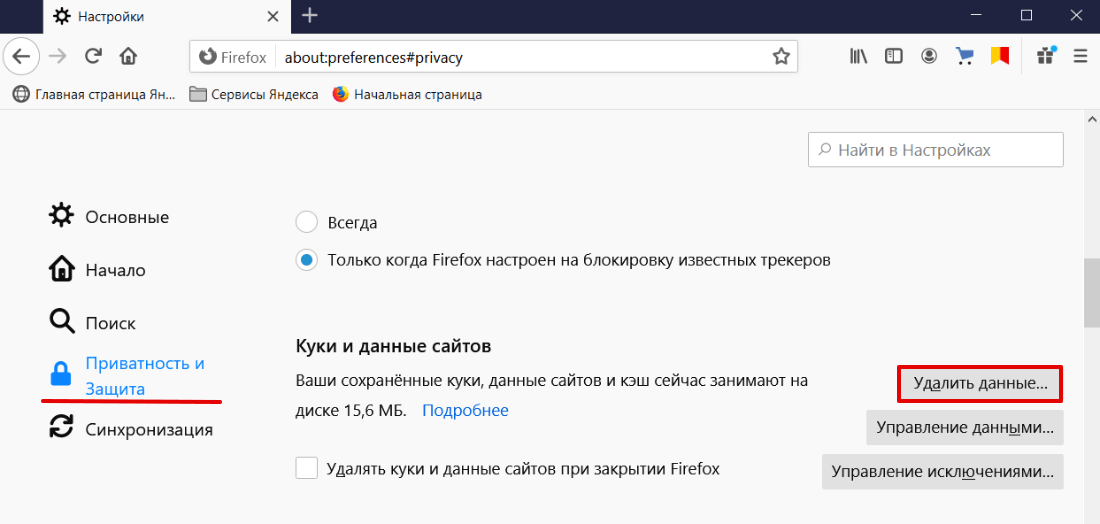
Установите галочки в чекбоксах Кэш веб-содержимого и Куки и данные сайтов (если нужно). Нажмите Удалить:
Очистка кэша в Opera
Мы описали наиболее универсальный способ очистки кэша браузера Opera. Если у вас Windows и вы хотите узнать другие способы, читайте статью Как очистить кэш в браузере Оpеrа на Windows.
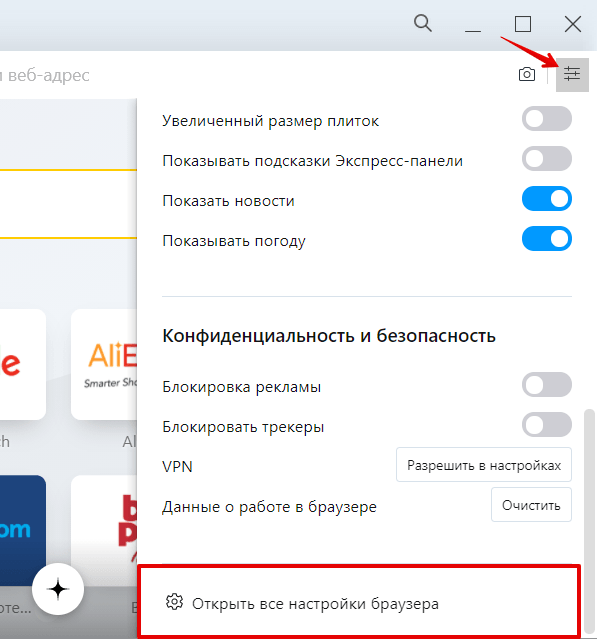
В браузере нажмите на кнопку с тремя перечеркнутыми полосками. Затем кликните Открыть все настройки браузера:
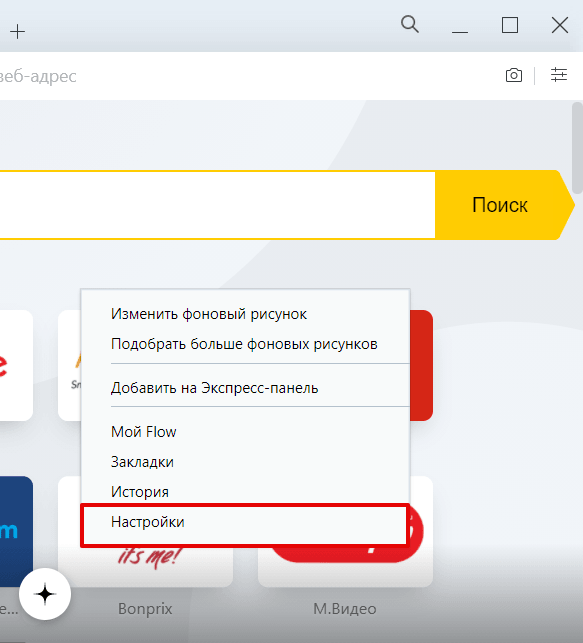
Также на этом шаге вы можете кликнуть правой кнопкой мыши на стартовой странице и нажать Настройки:
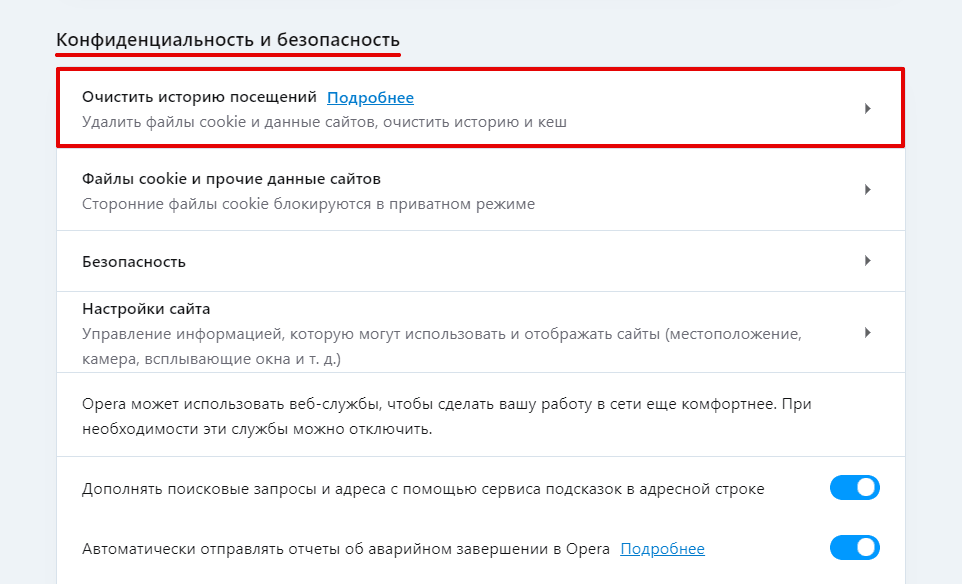
Пролистайте страницу до раздела «Конфиденциальность и безопасность» и нажмите Очистить историю посещений:
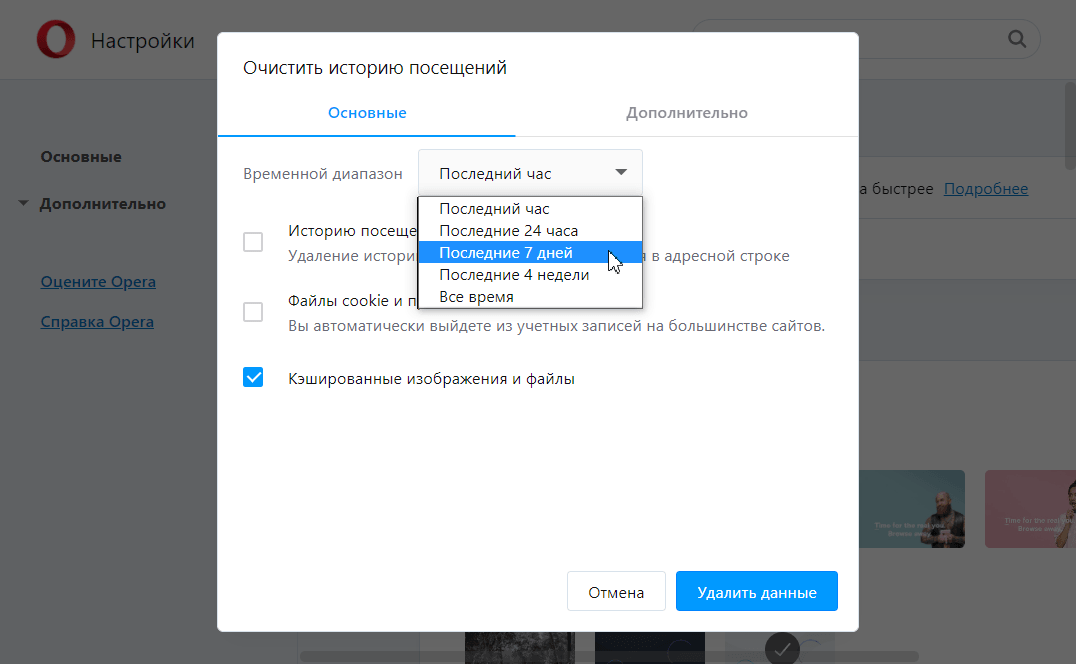
Отметьте чекбокс «Изображения и другие файлы, сохраненные в кеше». Затем в выпадающем списке выберите нужный временной диапазон:
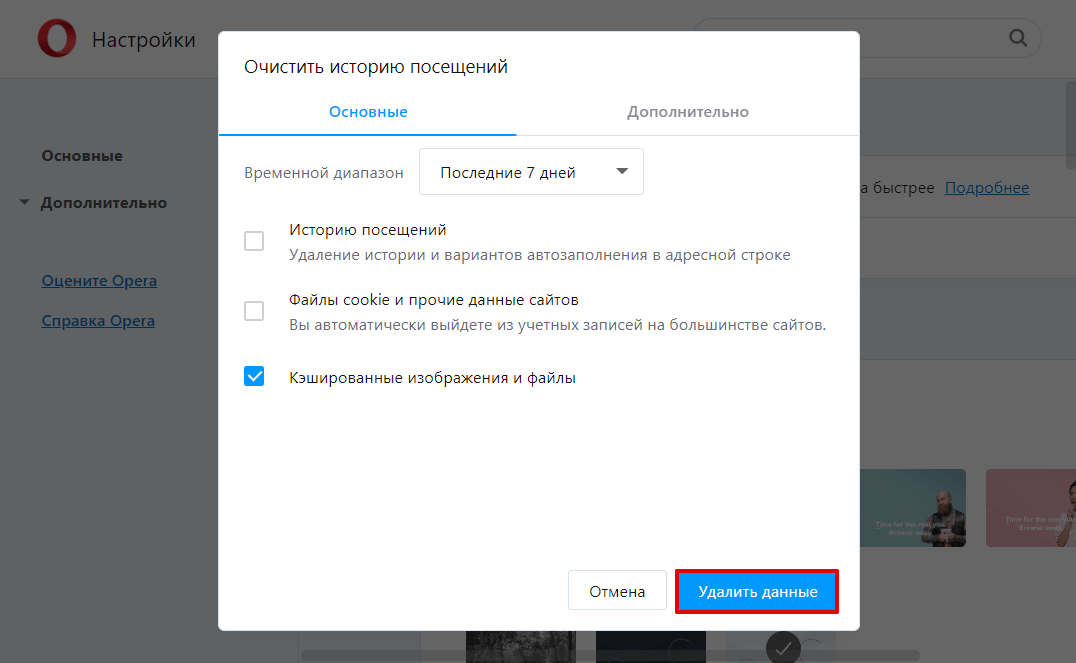
Кликните Удалить данные:
Очистка кэша в Microsoft Edge
Мы описали наиболее универсальный способ очистки кэша в браузера Edge. Если вы хотите узнать другие способы очистки, читайте статью Как очистить кэш в браузере Microsoft Edge.
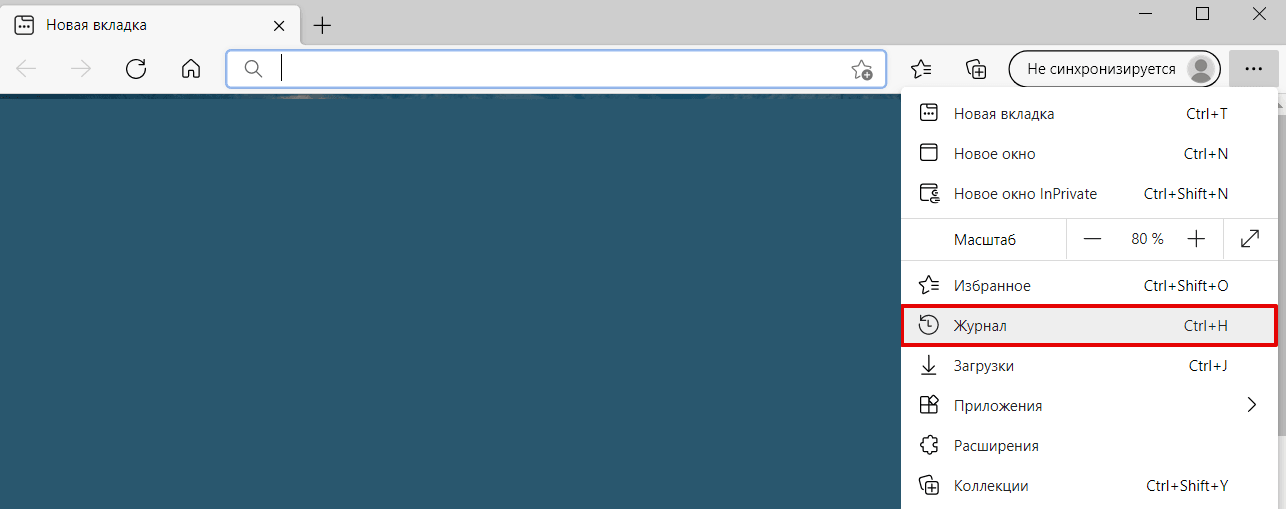
В правом верхнем углу браузера нажмите на три точки. Выберите Журнал:
Также можно использовать горячие клавиши Ctrl+Shift+Delete. В этом случае сразу переходите к шагу 3.
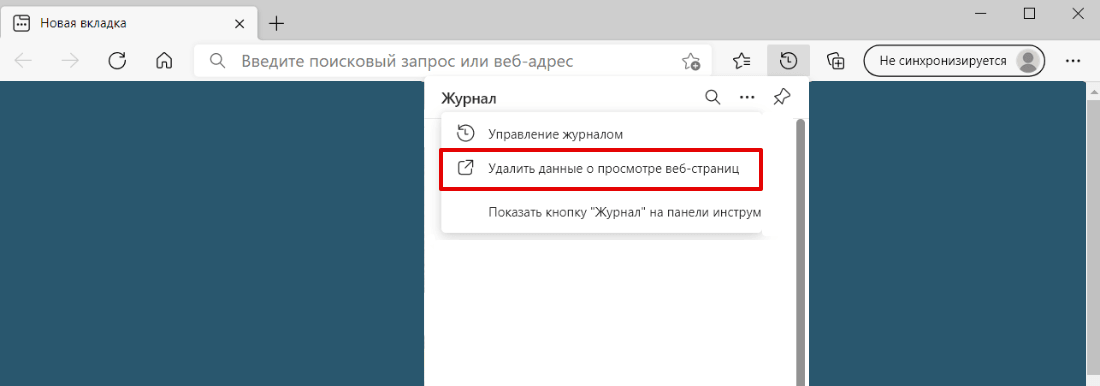
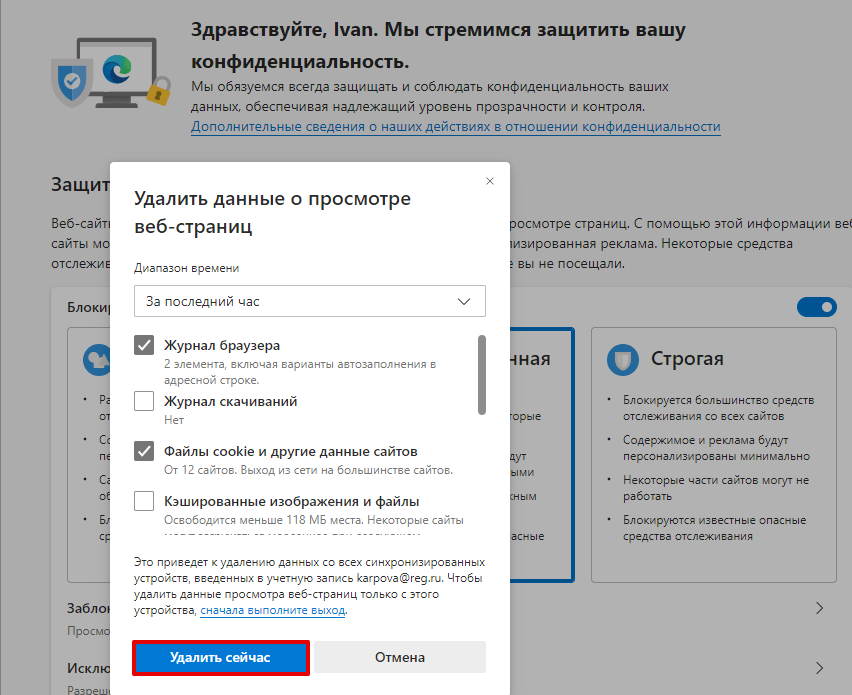
Нажмите на Удалить данные о просмотре веб-страниц:
 Как почистить кэш на хостинге
Как почистить кэш на хостинге
Нажмите Удалить сейчас:
Очистка кэша в Internet Explorer
Мы описали наиболее универсальный способ очистки кэша в браузера Internet Explorer 11. Если вы хотите узнать другие способы очистки, читайте статью Как очистить кэш в браузере Internet Explorer.
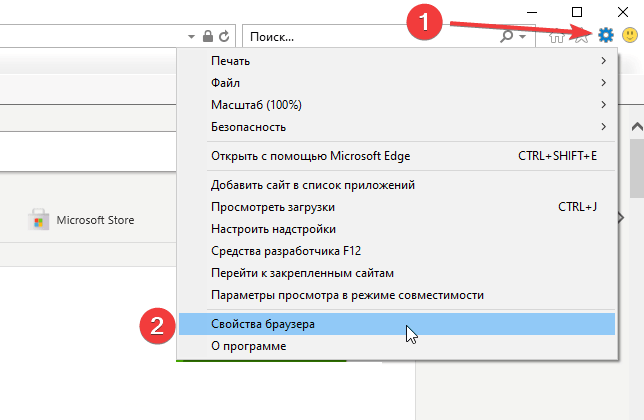
Откройте браузер, нажмите значок настроек в верхнем правом углу и выберите в открывшемся списке Свойства браузера:
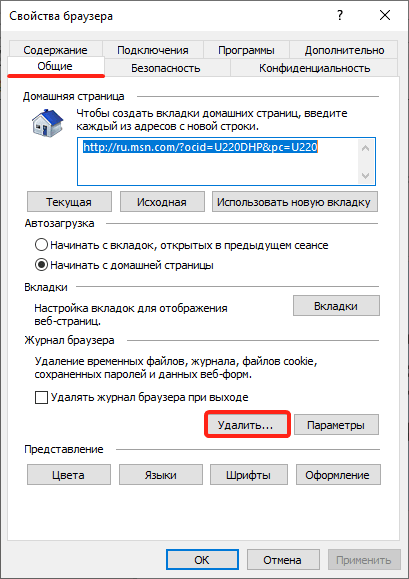
Во вкладке «Общие» нажмите Удалить:
Поставьте чекбоксы напротив пунктов «Временные файлы Интернета и веб-сайтов» и «Файлы cookie и данные веб-сайтов», затем нажмите Удалить: