Почему байт вмещает 256 символов?
1 Байт = 8 бит, т.е. это строка 1,2,3,4,5,6,7,8 почему тогда 2 возводят в 8-ю степень и получают 256 ? И что с этим делать? Т.е. каким образом и для чего записываются данные?
P.S. Извиняюсь за столь детский вопрос, но я никак не могу понять зачем это действие нужно?
Ваши рассуждения не совсем точны.
В байте действительно 8 бит, но нумеруются они от 0 до 7, причем нумерация ведется справа налево по возрастанию. Каждый такой номер является "весом" для бита равного 1, а вес этот измеряется соответствующей степенью числа 2 (биты это двоичная система счисления, где возможны только варианты 0 или 1).
Таким образом, максимально возможное число, которое можно отразить одним байтом в двоичной системе счисления, составляет 8 подряд идущих единичных битов, каждый со своим весом: 1*2^0 + 1*2^1 + 1*2^2 + 1*2^3 + 1*2^4 + 1*2^5 + 1*2^6 + 1*2^7
или 1+2+4+8+16+32+64+128 = 255. Но еще осталось значение 0, соответствующее случаю, когда все 8 бит байта нулевые. Следовательно, максимум кодов какие можно получить с помощью одного байта составляет 255+1 = 256 кодов (символов).
1 байт не может вместить 256 символов, одним байтом можно закодировать любой один из 256-ти символов, потому что именно столько уникальных комбинаций может принять последовательность из 8-ми двоичных бит. Один двоичный бит — это наименьшая единица количества информации, он может принять лишь два значения 0 и 1. Последовательность двух бит может принят уже 4 значения: 00, 01, 10 и 11, а из трех бит 8 значений, 000, 001 и так далее. Добавление каждого бита увеличивает количество возможных значений, которая может принять битовая последовательность в два раза, соответственно последовательность из 8 бит сможет принять 256 различных значений. Поэтому и используют степени двойки, так как 2 в степени N равно тому, сколько значений может принять последовательность из N двоичных бит.
Далее, существуют кодовые таблицы (ASCII, Win-1251 и т.п.), в которых каждым символам, таким как: большие и маленькие буквы английского и национального алфавитов, цифры, знаки препинания и спецсимволы, соответствует определенное значение байта, например для символа Q — это 81, соответственно 01010001. И всего в таблице и есть 256 символов, но при этом одним байтом можно "написать" один символ, а что-бы его потом прочитать, необходимо знать какая кодовая таблица, так называемая "кодировка", использовалась.
Ретроспектива решений прошлого, которое влияет на наше настоящее и будет влиять на будущее. Почему байт равен именно 8 битам?
Задумывались ли вы о том, как каждое наше решение определяет будущее? Иной раз не на один год, десятки, сотни, тысячи лет. Почему мы не можем делать двигатели ракет больше? Почему байт равен именно 8 битам, а не 7 или 16? А ведь он был равен этим числам раньше! Почему виртуальный терминал Linux до сих пор имеет скорость порта подключения? Давайте поговорим о том, как какое-то решение в прошлом определяет наше настоящее. И как мы можем повлиять на наше будущее.
Размер байта и ASCII коды
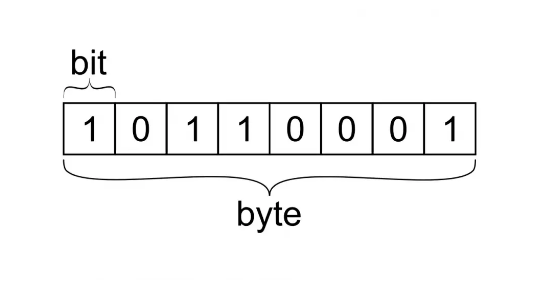
Сегодня многие ещё со школьной скамьи знают чему равен размер байта, и для нас это очевидно: 8 бит. Но думали ли вы, почему выбран такой размер? С чем это связанно?
Вы будете наверное сильно удивлены, но байт не всегда имел размер равный восьми битам! Раньше байт мог иметь размер от 4-х до 60-ти бит! Например, ЭВМ БЭСМ использовали 6-битные символы в 48-битных или 60-битных машинных словах.
Но почему именно 8 бит? Одна из причин — это двоичная система кодирования, так как наиболее удобными для обработки являются цифры, кратные степени двойки. Ну хорошо, скажите вы, почему тогда не 4, или 16, или 32? И будете правы.
Тут следует вспомнить ещё о том, что в 1963 году был принят Американский Стандартный Код для обмена информации (American Standard Code for Information Interchange) или сокращённо ASCII. Этот стандарт был разработан на основе телеграфного кода и его первое коммерческое использование было в качестве семибитного кода телетайпа, для отправки телеграфных сообщений. Первоначально основанный на английском алфавите, ASCII кодирует 128 заданных символов в семибитовые целые числа. Девяносто пять закодированных символов могут быть напечатаны: они включают цифры от 0 до 9, строчные буквы от a до z, прописные буквы от A до Z и символы пунктуации. Кроме того, исходная спецификация ASCII включала 33 непечатных управляющих кода, которые были созданы для телетайпов; большинство из них уже устарели, хотя некоторые из них до сих пор широко используется, например, возврат каретки, перевод строки и код табуляции.
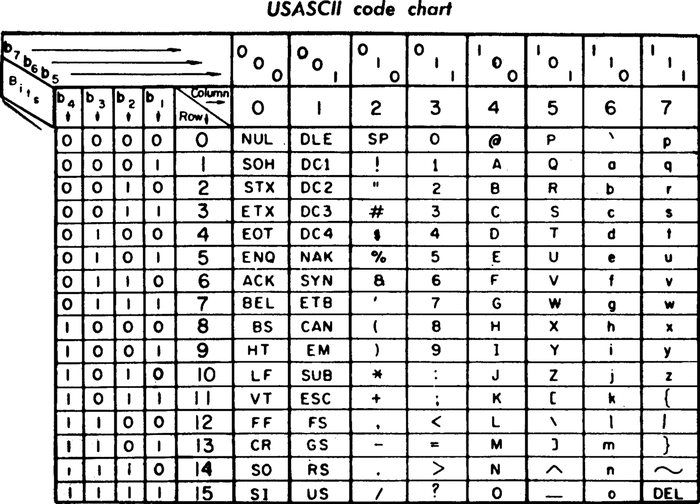
Семибитная таблица ASCII из руководства к принтеру до 1972 г.
Тут пересекаются сразу две ветки, история телеграфа, которая повлияла на развитие компьютерной индустрии. Мы об этом поговорим в следующей главе и собственно говоря самое представление байта.
В 1960-х компания IBM, которая так же участвовала в стандартизации ASCII представила для своей линейки вычислительных машин System/360 восьмибитовый Extended Binary Coded Decimal Interchange Code (EBCDIC). Следует понимать что EBCDIC и ASCII отличаются. Распространнёность ЭВМ IBM System/360 привела к повсеместному внедрению восьмиразрядного байта.
Разработка восьмиразрядных микропроцессоров в 1970-х годах популяризировала этот размер памяти. Микропроцессоры, такие как Intel 8008, прямой предшественник 8080 и 8086, использовавшиеся в ранних персональных компьютерах, также могли выполнять небольшое количество операций с четырехбитными парами в байтах.
Вернёмся к стандарту ASCII, которым в той или иной мере мы пользуемся теперь каждый день, даже этот текст так или иначе включает в себя данный стандарт.
Американский стандартный код для обмена информацией (ASCII) был разработан под эгидой комитета Американской ассоциации стандартов (ASA), называемого комитетом X3, его подкомитетом X3.2 (позже X3L2), а позже — X3 этого подкомитета. 2.4 рабочая группа (сейчас INCITS ). ASA стал Институтом стандартов Соединенных Штатов Америки (USASI) и, в конечном итоге, Американским национальным институтом стандартов (ANSI).
Подкомитет X3.2 разработал ASCII на основе более ранних систем кодирования телетайпов. До того, как был разработан ASCII, используемые кодировки включали 26 символов букв, 10 цифр и от 11 до 25 специальных графических символов. Для того, чтобы кодировать все эти данные, а также управляющие символы, совместимые со Стандартами международного телеграфного алфавита (ITA2) от 1924 года, требовалось более 64 кодов для ASCII. ITA2, в свою очередь, основывались на 5-битном телеграфном коде, который Эмиль Бодо изобрел в 1870 году и запатентовал в 1874 году.
Комитет обсудил возможность использования функции сдвига (как в ITA2 ), которая позволила бы представить более 64 кодов шестибитным кодом. В сдвинутом коде некоторые коды символов определяют выбор между вариантами следующих кодов символов. Это позволяет компактное кодирование, но менее надежно для передачи данных, поскольку ошибка при передаче кода сдвига обычно делает нечитаемую длинную часть передачи. Комитет по стандартам отказался от перехода, и поэтому для ASCII требовался как минимум семибитный код.
Комитет рассмотрел восьмибитный код, поскольку восемь битов ( октетов ) позволят двум четырехбитным шаблонам эффективно кодировать две цифры с помощью двоичного десятичного числа. Однако при передаче всех данных потребуется восемь битов, когда достаточно семи. Комитет проголосовал за использование семибитного кода для минимизации затрат, связанных с передачей данных. Поскольку, в то время перфолента лента могла записывать восемь бит в одной позиции, при желании можно было использовать бит четности для проверки ошибок.

Современная 8-битная таблица ASCII.
Таким образом, сразу несколько факторов сошлось в пользу того, чтобы байт стал иметь размер именно 8 бит. Но, на мой взгляд, основная — это возможность кодировать и хранить текстовую информацию в минимальном одном байте и возможность хранить десятичные цифры в каждом полубайте.
Устройство терминала Linux
На своей домашней системе, вы открываете виртуальный терминал линукс, который вообще работает в окне, и имеет абсолютно виртуальное представление. Но он до сих пор совместим со старинными терминалами.
Можно открыть терминал и ввести stty, то можно обнаружить что данная программа имеет скорость подключения, как и СОМ-порт. И вообще имеет кучу настроек termios для СОM-порта.
Я уже достаточно подробно останавливался в своих статьях о работе СОМ-порта в статье «UART и с чем его едят» и там было сказанно следующее:

Телетайп, который подключается по UART и может служить для ввода и вывода информации.
В результате ввод-вывод в линуксе — это фактические управление телетайпом. Даже самые современные стандарты терминала обратно совместимы с такого типа телетайпом. Более того, я вам уверенно скажу, что если этот телетайп подключить к современному компу и настроить вывод терминала на физический СОМ-порт, он без программных переделок будет работать (аппаратные понадобятся, так как там немного другие стандарты напряжений работы, но незначительные).
У меня было желание привести намного большее количество примеров, отсылок в прошлое. Например о раскладках клавиатуры, что это ещё с лохматых времён печатных машинок, либо отсылки о форме современных мобильных телефонов. Однако статья и так превратилась в безумную простыню, а мысль мне всё же удалось изложить.

Раскладка QWERTY, изобретённая в 1888 году для печатных машинок используется до сих пор.
Мысль моей статьи достаточно простая: даже самые незначительные вещи, которые вы внедряете сегодня, могут оказать самое громадное влияние на наше будущее.
Почему в байте именно 8 бит?

Я опубликовала в интернет-журнале статью на тему двоичного представления информации компьютерами и, среди прочих, неоднократно получала вопрос: «Почему в архитектуре x86 используются байты, состоящие именно из 8 бит, а не иного их количества?»
Я считаю, что на любой подобный вопрос можно дать два основных ответа и некую их комбинацию:
- Так сложилось исторически, и другой размер (например, 4, 6 или 16 бит) тоже вполне сработает.
- Восемь бит по какой-то причине является лучшим вариантом, и даже если бы история сложилась иначе, мы бы всё равно использовали именно 8-битные байты.
- Некая комбинация этих двух версий.
Приведу пример исторической случайности: в DNS есть поле class , которое может содержать одно из пяти значений – internet , chaos , hesiod , none и any ). Для меня это явный пример исторической случайности – не могу представить себе, чтобы мы, воссоздавая это поле сегодня, определили его таким же образом, не беспокоясь об обратной совместимости. Не уверена, что мы бы вообще стали использовать поле класса.
В этой статье не приводятся однозначные объяснения, но я задала вопрос на Mastodon, и собрала из полученных ответов несколько возможных причин 8-битного размера байта. Думаю, что ответ представляет некое сочетание этих причин.
▍ В чём отличие между байтом и словом?
Начну с того, что в этой статье будут активно обсуждаться байты и слова. В чём же отличие между ними? Вот моё понимание этого вопроса:
- Размер байта представляет минимальную единицу данных, которую можно адресовать. Например, в программе на моей машине 0x20aa87c68 может быть адресом одного байта, а значит 0x20aa87c69 будет адресом следующего байта.
- Размер слова является кратным размеру байта. Для меня это оставалось непонятным долгие годы, причём в Wikipedia этому даётся весьма туманное определение («слово – это естественная единица данных, используемая в конкретной архитектуре процессора»). Изначально я думала, что размер слова равен размеру регистра (64 бита на x86-64). Но, согласно разделу 4.1 («Fundamental Data Types») мануала по архитектурам Intel, в системах x86 слово имеет размер 16 бит при том, что размер регистров 64 бита. Это сбивает с толку. Какой всё-таки размер слова в системах x86 – 16 или 64 бита? Может ли это зависеть от контекста?
▍ Причина 1: чтобы любой символ английского алфавита вписывался в 1 байт
Статья на Wikipedia гласит, что 8-битный байт впервые начал использоваться в IBM System/360 в 1964 году.
Вот видео интервью с Фредом Бруксом (руководителем проекта), в котором обсуждается причина этого. Вот часть его содержания:
Идея о том, что 8-битный байт больше подходит для обработки текста, вполне логична: 2^6 равно 64, значит 6 бит оказалось бы недостаточно для букв нижнего/верхнего регистра и символов.
Для перехода на использование 8-битного байта в System/360 также была реализована кодировка 8-битных символов EBCDIC.
Похоже, что следующим значительным шагом в истории 8-битного байта стал процессор Intel 8008, который создавался для использования в терминале Datapoint 2200. Терминалам необходима возможность представлять буквы, а также управляющие коды, поэтому в них есть смысл использовать 8-битные байты. В руководстве к Datapoint 2200 из музея компьютерной истории на странице 7 сказано, что эта модель поддерживала кодировки ASCII (7 бит) и EBCDIC (8 бит).
▍ Почему 6-битный байт лучше подходит для научных вычислений?
Меня заинтересовал комментарий о том, что 6-битный байт оказался бы более подходящим для научных вычислений. Вот цитата из интервью с Джином Амдалем:
Мне это рассуждение совсем непонятно – почему при использовании 32-битного слова возведение числа в степень должно быть 8-битным? Почему нельзя использовать 9 или 10 бит? Но это всё, что мне удалось найти в результате недолгого поиска.
▍ Почему в мейнфреймах использовалось 36 бит?
Это также связано с 6-битным байтом: во многих мейнфреймах использовались 36-битные слова. Почему? Кто-то указал на прекрасное объяснение в статье Wikipedia, посвящённой 36-битному вычислению:
До появления компьютеров эталоном в точных научных и инженерных вычислениях был 10-циферный электромеханический калькулятор… В этих калькуляторах для каждой цифры присутствовал ряд клавиш, и операторы обучались использовать для ввода чисел все десять пальцев, поэтому, хоть в некоторых специализированных калькуляторах и было больше рядов, десять являлось практичным ограничением.
В связи с этим в первых двоичных компьютерах, нацеленных на тот же рынок, использовались 36-битные слова. Этой длины было достаточно для представления положительных и отрицательных целых чисел с точностью до десяти десятичных цифр (35 бит оказалось бы минимумом).
Получается, что поводом для использования 36 бит стал тот факт, что log_2(20000000000) равен 34.2.
Я предполагаю, что причина тому лежит где-то в 50-х годах – тогда компьютеры были невероятной роскошью. Поэтому, если вам требовалось, чтобы устройство поддерживало десять цифр, его нужно было спроектировать с поддержкой ровно достаточного для этого числа бит и не более.
Сегодня компьютеры стали быстрее и дешевле, поэтому, если вам по какой-то причине нужно представить десять цифр, то вы можете просто использовать 64 бита – потеря некоторого пространства памяти вряд ли станет проблемой.
Кто-то другой писал, что некоторые из этих машин с 36-битными словами позволяли выбирать размер байта – в зависимости от контекста можно было использовать 5, 6, 7 или 8-битные байты.
▍ Причина 2: для эффективной работы с десятичными значениями в двоичной кодировке
В 60-е годы существовала популярная кодировка целых чисел под названием BCD (binary-coded decimal), которая кодировала каждую цифру в 4 бита. Например, если бы вам понадобилось закодировать 1234, то в BCD это бы выглядело так:
Поэтому в целях удобства работы с закодированным в двоичную форму десятичным значением размер байта должен был быть кратным 4 битам – например, 8 бит.
▍ Почему BCD была популярна?
Такое представление целых чисел мне показалось реально странным – почему бы не использовать двоичную форму, которая позволяет намного более эффективно хранить целые числа? Ведь эффективность в первых компьютерах была крайне важна.
Лично я склоняюсь к тому, что причина заключалась в специфике дисплеев первых компьютеров, на которых содержимое байта отображалось непосредственно в состояние лампочек – вкл/выкл.

Поэтому, если мы хотим, чтобы человеку было относительно удобно прочитывать десятичное число из его двоичного представления, то такой вариант будет намного более разумным. Я думаю, что сегодня кодировка BCD уже неактуальна, потому что у нас есть мониторы, и наши компьютеры умеют автоматически конвертировать числа из двоичной формы в десятичную, отображая итоговый результат.
Мне также было интересно, не из BCD ли родился термин «nibble» (полубайт), означающий 4 бита – в контексте BCD вы много обращаетесь к полубайтам (поскольку каждая цифра занимает 4 бита), поэтому есть смысл использовать слово для «4 бит», которые люди и прозвали «nibble». Сегодня для меня этот термин уже выглядит архаичным – если я его когда-то и использовала, то только смеха ради (оно такое забавное). Причём эта теория подтверждается статьёй в Wikipedia:
В качестве ещё одной причины использования BCD кто-то назвал финансовые вычисления. Сегодня, если вам нужно сохранить какое-то количество долларов, то вы обычно просто используете целочисленное значение в центах и делите это значение на 100, если хотите получить его долларовую часть. Это несложно, деление выполняется быстро. Но в 70-х деление на 100 целого числа, представленного в двоичном формате, явно выполнялось очень медленно, поэтому был смысл перестроить систему представления целых чисел во избежание деления на 100.
Ладно, хватит о BCD.
▍ Причина 3: 8 – это степень 2
Многие люди указали на важность того, чтобы размер байта был равен степени 2. Я не могу выяснить, правда это или нет, и меня не удовлетворило объяснение, что «компьютеры используют двоичную систему счисления, поэтому степень двойки подойдёт лучше всего». Это утверждение выглядит весьма правдоподобным, но мне хотелось разобраться глубже. За всю историю определённо было множество машин, в которых использовались байты с размером, не являющимся степенью 2. Вот несколько примеров, взятых из темы о ретрокомпьютерах со Stack Exchange:
- в мейнфреймах Cyber 180 использовались 6-битные байты;
- в серии Univac 1100 / 2200 использовались 36-битные слова;
- PDP-8 был 12-битным компьютером.
- каждому биту в слове требуется линия шины, а количество линий должно быть кратно 2 (почему?);
- значительная часть логики электросхем предрасположена к техникам «разделяй и властвуй» (мне нужен пример для понимания этого утверждения).
- Это упрощает проектирование делителей частоты, способных измерять «отправку 8 бит по такому-то каналу» и работающих на основе деления пополам – можно установить 3 таких делителя последовательно. Грэхем Сазерленд рассказал мне об этом и создал классный симулятор делителей частоты, демонстрирующий их устройство. На том же сайте (Falstad) есть и много других примеров схем, и он отлично подходит для создания различных симуляторов.
- Если у вас есть инструкция, обнуляющая конкретный бит в байте, то при размере байта 8 (2^3) вы можете использовать всего три бита этой инструкции для указания, какой это бит. В системах x86 такой возможности нет, зато она есть у инструкций тестирования битов в Z80.
- Кто-то также сказал, что в некоторых процессорах используются сумматоры с опережением переноса, которые работают с группами по 4 бита. Недолгий поиск в Google показал, что существует большое разнообразие схем сумматоров.
- Битовые карты: память вашего компьютера организована по страницам (обычно размером 2^n). При этом компьютеру необходимо отслеживать каждую страницу на предмет того, свободна она или нет. Для этого в операционных системах используются битовые карты, в которых каждый бит соответствует странице и равен 0 или 1 в зависимости от того, свободна ли она. Если бы в компьютере использовался 9-битный байт, то для нахождения нужной страницы в битовой карте пришлось бы делить на 9. Деление на 9 медленнее деления на 8, потому что деление на степени 2 всегда является самым быстрым.
▍ Причина 4: небольшой размер байта – это хорошо
Вы можете поинтересоваться: «Если 8-битные байты оказались лучше 4-битных, почему бы не продолжить увеличивать их размер? Можно же использовать 16-битные!»
Вот пара причин для сохранения небольшого размера байта:
- Это приведёт к пустой трате пространства – байт является минимальной адресуемой единицей, и если компьютер хранит много текста в кодировке ASCII (которой требуется всего 7 бит), то выделение для каждого символа не 8, а 12 или 16 бит приведёт к значительным потерям памяти.
- Если размер байта увеличивается, то и система процессора должна усложняться. К примеру, вам требуется по одной линии шины на бит. Так что, думаю, чем проще, тем лучше.
▍ Причина 5: совместимость
Процессор Intel 8008 (1972 год) был предшественником модели 8080 (1974 год), которая предшествовала 8086 (1976 год) – первому процессору семейства x86. Похоже, что 8080 и 8086 были очень популярны, и именно с них пошли все современные компьютеры x86.
Думаю, здесь уместен принцип «не чини того, что не сломано» – мне кажется, что 8-битные байты отлично работали, поэтому в Intel не увидели необходимости менять их размер. Сохранение 8-битного байта позволяет повторно использовать более обширную часть набора инструкций.
К тому же, в 80-х начали появляться сетевые протоколы вроде TCP, в которых использовались 8-битные байты (обычно называемые «октеты»), и если вы соберётесь реализовать сетевые протоколы, то наверняка решите использовать в них 8-битный байт.
На мой взгляд, основные причины, по которым байт состоит из 8 бит, следующие:
Почему в байте 8 битов
В реальном мире длина указывается в метрах, вес — в килограммах, а объем — в кубических метрах. Однако в виртуальном мире мы считаем биты, байты, мегабайты и гигабайты. Объем памяти компьютера, размер жестких дисков и размер пакета данных от операторов мобильной связи измеряются в битах, байтах и кратных им единицам.
Наименьшая единица информации в информатике это — 1 бит
Бит принимает одно из двух значений — 0 или . Последовательность таких битов со значениями нуль-единица позволяет передавать любую информацию в цифровом виде.
Единица большего размера, содержащая 8 битов, называется 1 байтом .
По определению, байт — это наименьшая адресуемая единица информации в памяти компьютера. Один байт состоит из восьми битов, которые могут быть 0 или 1 в двоичном формате.
Единицы памяти большего размера обозначаются добавлением префиксов кило , мега , гига и тера . В системе СИ десятичные префиксы — это степени числа 10 . Однако в информатике принято использовать степень двойки.
Таким образом, 1 КБ (килобайт) равен 2 в 10-й степени или 1024 байта . Следующие префиксы представляют собой число два в степени 20, 30, 40 и т. д.
- 1 КБ = 2 в 10-й степени или 1024 байта.
- 1 МБ (мегабайт) равен 2 в 20-й степени или 1024 килобайта.
- 1 ГБ (гигабайт) равно 2 в 30-й степени или 1024 мегабайта.
- 1 ТБ (терабайт) равен 2 в 40-й степени или 1024 гигабайта.
Что такое байт. Сколько бит в байте
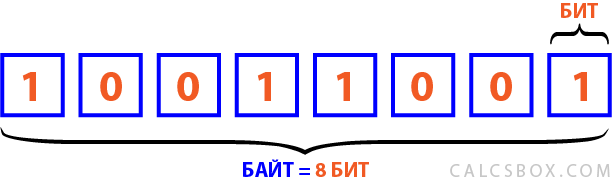
Вы, наверное, слыхали про азбуку Морзе, где комбинации длинных и коротких сигналов (точек и тире) расшифровывались в слова. А если взять комбинацию из 8 цифр, каждая из которых может быть единицей или нулем, то получим 256 комбинаций, чего хватит для отображения и цифр и букв, причем и не одного алфавита. И вот эти 8 бит называются байтом . Таким образом в байте 8 бит.
Бит — это минимальная единица. Она обозначается маленькой буквой «б». Следом за ней идет байт. Он уже обозначается большой буквой «Б».
Единицы информации

Таблица байтов:
- 1 байт = 8 бит
- 1 Кб (1 Килобайт) = 2 10 байт = 2*2*2*2*2*2*2*2*2*2 байт =
- 1024 байт (примерно 1 тысяча байт — 10 3 байт)
- 1 Мб (1 Мегабайт) = 2 20 байт = 1024 килобайт (примерно 1 миллион байт — 10 6 байт)
- 1 Гб (1 Гигабайт) = 2 30 байт = 1024 мегабайт (примерно 1 миллиард байт — 10 9 байт)
- 1 Тб (1 Терабайт) = 2 40 байт = 1024 гигабайт (примерно 10 12 байт)
- 1 Пб (1 Петабайт) = 2 50 байт = 1024 терабайт (примерно 10 15 байт)
- 1 Эксабайт = 2 60 байт = 1024 петабайт (примерно 10 18 байт)
- 1 Зеттабайт = 2 70 байт = 1024 эксабайт (примерно 10 21 байт)
- 1 Йоттабайт = 2 80 байт = 1024 зеттабайт (примерно 10 24 байт)
Почему на диске, карте памяти или флешке всегда меньше памяти, чем написано на упаковке?
Наверняка вам интересно, откуда берутся отличия заявленной и реальной емкости винчестеров? Меньший объем дискового пространства, доступного пользователю, не является ошибкой. Причина — разница в расчетах.
Емкость проданных твердотельных накопителей, жестких дисков, флеш-накопителей и карт памяти указывается в гигабайтах (ГБ) или терабайтах (ТБ). Например, покупая SSD-накопитель заявленной емкостью 512 ГБ, мы должны получить ровно столько же места для наших данных. Однако после установки накопителя в компьютер оказывается, что у нас около 476 ГБ. Почему в реальности такое значение?
Основная причина в том, как рассчитывается емкость диска. Люди используют десятичную систему счисления, основание которой равно 10. Компьютеры, однако, работают в двоичной системе, в которой основанием является число 2. Наименьшей единицей памяти, используемой в информатике, является байт. Обычно используемые десятичные префиксы (из системы СИ): кило (k) для тысячи, мега (M) для миллиона, гига (G) для миллиарда и тера (T) для триллиона. Таким образом, мы получаем один килобайт (тысяча байтов), мегабайт (миллион байтов), гигабайт (миллиард байтов) и терабайт (один триллион байтов) соответственно.
Следовательно, по заявлению производителей, емкость SSD на 512 ГБ составляет ровно 512 000 000 000 байт (512 байт x 1000 x 1000 x 1000).
Однако для компьютеров и бинарных файлов, которые они используют, вычисление этих значений немного отличается. 1 килобайт равен 102 байтам. 1 мегабайт равен 1 048 576 байтам (1024 x 1024), а 1 гигабайт равен 1 073 731 824 байтам (1024 x 1024 x 1024). Таким образом, диск с заявленным производителем объемом 512 ГБ фактически имеет емкость 476,84 ГБ. Рассчитываем это так: 512000000000 / 1024/1024/1024 = 476,84 ГБ.
Различная система расчета размера массовой памяти — не единственная причина различий между заявленной и реальной емкостью дисков. Производители ноутбуков используют скрытые разделы для восстановления, чтобы восстановить компьютер до исходного состояния, например, после аварии. Такой раздел занимает около 1 ГБ дискового пространства и обычно содержит образ операционной системы, драйверы и базовое программное обеспечение. Дисковое пространство также можно зарезервировать для так называемых буферов, которые отвечают за ускорение чтения и записи данных на TLC-накопителях. Размер такого буфера может составлять от нескольких мегабайт до нескольких гигабайт.
Подводя итог. Производители дисков считают 1 ГБ = 1 000 000 000 (миллиардом) байтов, а в двоичных файлах 1 ГБ = 1 073 731 824 байта. Этим объясняется разница в заявленной и реальной емкости SSD, дисковых накопителей и других носителей данных. Стоит отметить, что в 1998 году была предпринята попытка преодолеть эту двусмысленность. Международная электротехническая комиссия (IEC) предложила обозначить кратность 1024, добавив букву «i» после знака множителя (KiB вместо KB, MiB вместо MB) и изменив префикс, заканчивающийся на «bi» (kibibyte вместо килобайт, мебабайт вместо мегабайта). Новые имена, однако, не получили широкого распространения, и по сей день используются префиксы SI, которые проще использовать.