Дисперсия
Дисперсия в статистике — это мера, которая показывает разброс между результатами. Если все они близки к среднему, дисперсия низкая. А если результаты сильно различаются — высокая.
Это один из основных показателей в статистическом анализе. Точка, вокруг которой считают разброс, — это обычно среднее арифметическое из выборки, математическое ожидание или какое-то целевое значение. А если смотрят, например, разброс между ответами на какой-то тестовый вопрос, в качестве центральной точки можно взять правильный ответ.
Термин «дисперсия» также встречается в физике, химии и биологии. Например, так называют явление, когда разные вещества не смешиваются друг с другом. А еще — разложение света на отдельные цвета, когда он проходит через призму. Но это другие понятия. Они не имеют отношения к статистике.

Освойте профессию «Data Scientist»
Дата-сайентисты решают поистине амбициозные задачи. Научитесь создавать искусственный интеллект, обучать нейронные сети, менять мир и при этом хорошо зарабатывать. Программа рассчитана на новичков и плавно введет вас в Data Science.

Решайте амбициозные задачи с помощью нейросетей

Что показывает дисперсия
Если говорить о всей выборке, дисперсия показывает, насколько разнородны результаты. Например, в одной группе почти все — шатены. В другой половина — шатены, а остальные — блондины, рыжие и брюнеты. Вторая группа более разнородная, в ней выше дисперсия.
Более близкие к реальному миру примеры:
- бизнесу дисперсия поможет рассчитать разброс между доходами за разные месяцы;
- ученый с помощью дисперсии поймет, насколько совпадают между собой результаты серии экспериментов.
Еще дисперсия показывает вероятность того, что конкретный результат будет далек от среднего. Например, средний рост россиянина мужского пола — 175 см. Но если остановить на улице случайного мужчину, вряд ли он окажется ровно 175 см ростом — скорее всего, выше или ниже. Дисперсия высокая — вероятность встретить «не среднее» значение выше.
В реальном мире это можно использовать так:
- проверять, насколько предсказуемы бизнес-показатели;
- оценивать риски — для компании, продвижения или даже обычной жизни.
Логика тут такая: чем меньше предсказуемости — тем больше хаоса и, соответственно, больше рисков.
Кто работает с дисперсией
- Ученые, которые могут пользоваться метриками из математической статистики, например для оценки результатов эксперимента.
- Статистики — они могут собирать данные по разным параметрам и потом оценивать их.
- Аналитики — статистика и в частности дисперсия используются в большинстве направлений Data Science, анализа данных, бизнес-аналитики и так далее. -инженеры — дисперсию учитывают, когда оценивают работу модели машинного обучения. Тут это будет разброс между ответами.
Формула дисперсии
Сначала дадим формальное определение, а потом объясним простыми словами. Дисперсия рассчитывается по формуле как среднее квадратичное отклонение от среднего значения:
- n — количество элементов,
- xi – i-й элемент в выборке,
- x — среднее арифметическое.
Звучит и выглядит сложно, но фактически все не так страшно. Вот как выглядит расчет пошагово:
- Найти среднее арифметическое x. Для этого нужно сложить все элементы и разделить полученную сумму на их количество.
- Потом от каждого элемента по очереди нужно отнять среднее арифметическое, а получившееся число возвести в квадрат. Это называется квадратами отклонения от среднего.
- Найденные квадраты отклонения от среднего нужно сложить.
- Сумму разделить на количество элементов в выборке.
Формула дисперсии случайной величины рассчитывается так:
Найти дисперсию случайной величины также можно по формуле, записанной в более удобном для расчетов виде:
Все перечисленное посчитать несложно — достаточно школьных знаний математики. А вот чтобы понять, почему формула именно такая, уже нужно разбираться в статистике.

Станьте дата-сайентистом и решайте амбициозные задачи с помощью нейросетей
Пример расчета дисперсии
Давайте посмотрим на практике, как рассчитать дисперсию. Для этого возьмем простую выборку из шести элементов. Будем считать, что это оценки группы с дополнительных занятий: [5, 2, 3, 5, 4, 5].
- Сначала найдем среднее арифметическое: (5 + 2 + 3 + 5 + 4 + 5) / 6 = 24 / 6 = 4.
- Теперь найдем квадраты отклонения от среднего:
- Сложим получившиеся квадраты: 1 + 4 + 1 + 1 + 0 + 1 = 8.
- Разделим сумму на количество элементов: 8 / 6 = 1,33.
Число 1,33 — это и есть дисперсия. Не слишком большая — большинство значений близко к среднему арифметическому, равному 4.
Как интерпретировать результат
Единицы измерения дисперсии — квадраты от единиц, в которых указаны значения в выборке. Например, в нашем расчете вышел разброс в 1,33 — это не баллы оценок, а их квадраты. Чтобы узнать, каким разброс будет в баллах, нужно будет взять квадратный корень из 1,33.
Какую дисперсию считать большой или маленькой — зависит от значений и выборки в целом. Например, для нашей небольшой выборки из чисел от 0 до 5 условная дисперсия в 4 считалась бы довольно большой. Но можно представить много выборок, где 4 — маленькое значение. Например, крупная выборка, где собраны числа от 100 до 1000.
Еще это зависит от сферы. Например, в условной медицине или точной инженерии даже небольшое число может быть значимой дисперсией.
Связь с другими показателями
Дисперсия тесно связана с несколькими другими показателями из статистики. Мы уже сказали про среднее арифметическое, но оно не единственное. Вот еще три важных показателя.
Стандартное отклонение. Это квадратный корень из дисперсии — выше мы говорили, что дисперсия представляет собой значение «в квадрате». А стандартное отклонение дает результат в тех же единицах измерения, что и числа в выборке. Если взять квадратный корень из нашей дисперсии в 1,33, получится 1,15 — значит, числа в выборке отклоняются от среднего на 1,15 балла. Отклоняются они опять же в среднем — для конкретного числа отклонение может быть и больше, и меньше.
Смещение. Смещение — это ошибка выборки. Например, когда исследователь собирал выборку, отобранные значения оказались похожими по какому-то фактору, а остальные он случайно проигнорировал. Например, отобрал для выборки фото с котами только белых котиков. В случае с машинным обучением это еще и «перекос» результатов, которые выдает модель: например, называет всех белых животных котами.
При чем тут дисперсия — она растет при маленьком смещении и падает при большом. Идеальная выборка — это маленькая дисперсия при большом смещении, но в реальности это практически невозможно. Поэтому приходится балансировать.
Ошибка прогнозирования. Статистику используют для прогнозирования. Но из-за дисперсии и смещения нельзя спрогнозировать все точно. Ошибка прогнозирования — это мера неточности. Чем она выше, тем сильнее прогноз может расходиться с реальным результатом. Существуют разные способы расчета этой ошибки, обычно для них используют реальные значения, если они известны.
Когда нужно применять дисперсию
Стандартное отклонение проще для понимания, так что может возникнуть вопрос: зачем пользоваться именно дисперсией. На практике пользуются и тем, и другим — зависит от задачи. Где-то считать показатели и анализировать удобнее через дисперсию, где-то — через стандартное отклонение. Благо, одно легко высчитывается через другое.
Например, дисперсия удобнее стандартного отклонения, если исследователь пользуется статистическим анализом или регрессией либо пишет теоретическую работу вроде лабораторной. Дисперсию бывает проще представить в процентах, она используется во множестве формул — так что смотреть нужно на саму задачу. Хотя и стандартное отклонение используют не реже.
Если вы хотите узнать больше про статистику, анализ данных и машинное обучение — приглашаем на курсы! Дадим много практических заданий и поможем получить первый реальный опыт.
Распишите, пожалуйста, по пунктам, что нужно сделать для того, чтобы найти дисперсию любого ряда чисел. 7 класс.
Дисперсией числового ряда называется среднее арифметическое квадратов отклонений от среднего арифметического.
Пусть есть некий ряд (значения некоторой случайной величины — скажем, рост учеников в классе): 145, 155, 130, 126, 134.
1) находим среднее арифметическое: (145 + 155 + 130 + 126 + 134) / 5 = 138
2) находим среднее арифметическое квадратов отклонений:
Дисперсия характеризует разброс — чем больше дисперсия, тем сильнее «разбросан» (варьируется) признак относительно центрального значения.
Как найти среднеквадратическое отклонение
В данной статье я расскажу о том, как найти среднеквадратическое отклонение. Этот материал крайне важен для полноценного понимания математики, поэтому репетитор по математике должен посвятить его изучению отдельный урок или даже несколько. В этой статье вы найдёте ссылку на подробный и понятный видеоурок, в котором рассказано о том, что такое среднеквадратическое отклонение и как его найти.
Среднеквадратическое отклонение дает возможность оценить разброс значений, полученных в результате измерения какого-то параметра. Обозначается символом 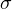 (греческая буква «сигма»).
(греческая буква «сигма»).
Формула для расчета довольно проста. Чтобы найти среднеквадратическое отклонение, нужно взять квадратный корень из дисперсии. Так что теперь вы должны спросить: “А что же такое дисперсия?”
Что такое дисперсия
Определение дисперсии звучит так. Дисперсия — это среднее арифметическое от квадратов отклонений значений от среднего.
Чтобы найти дисперсию последовательно проведите следующие вычисления:
- Определите среднее (простое среднее арифметическое ряда значений).
- Затем от каждого из значений отнимите среднее и возведите полученную разность в квадрат (получили квадрат разности).
- Следующим шагом будет вычисление среднего арифметического полученных квадратов разностей (Почему именно квадратов вы сможете узнать ниже).
Рассмотрим на примере. Допустим, вы с друзьями решили измерить рост ваших собак (в миллиметрах). В результате измерений вы получили следующие данные измерений роста (в холке): 600 мм, 470 мм, 170 мм, 430 мм и 300 мм.
| Порода собаки | Рост в миллиметрах |
| Ротвейлер | 600 |
| Бульдог | 470 |
| Такса | 170 |
| Пудель | 430 |
| Мопс | 300 |
Вычислим среднее значение, дисперсию и среднеквадратическое отклонение.
Сперва найдём среднее значение. Как вы уже знаете, для этого нужно сложить все измеренные значения и поделить на количество измерений. Ход вычислений:
Среднее 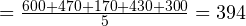 мм.
мм.
Итак, среднее (среднеарифметическое) составляет 394 мм.
Теперь нужно определить отклонение роста каждой из собак от среднего:
![\[ \begin{array}{l} 1: 600-394 = 206 \\ 2: 470-394 = 76 \\ 3: 170-394 = -224\\ 4: 430-394 = 36\\ 5: 300-394 = -94 \end{array} \]](https://yourtutor.info/wp-content/ql-cache/quicklatex.com-3916a3ccd97d909589dfe1dabb970af0_l3.png)
Наконец, чтобы вычислить дисперсию, каждую из полученных разностей возводим в квадрат, а затем находим среднее арифметическое от полученных результатов:
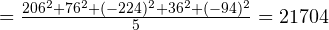
Дисперсия мм 2 .
Таким образом, дисперсия составляет 21704 мм 2 .
Как найти среднеквадратическое отклонение
Так как же теперь вычислить среднеквадратическое отклонение, зная дисперсию? Как мы помним, взять из нее квадратный корень. То есть среднеквадратическое отклонение равно:
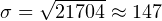 мм (округлено до ближайшего целого значения в мм).
мм (округлено до ближайшего целого значения в мм).
Применив данный метод, мы выяснили, что некоторые собаки (например, ротвейлеры) – очень большие собаки. Но есть и очень маленькие собаки (например, таксы, только говорить им этого не стоит).
Самое интересное, что среднеквадратическое отклонение несет в себе полезную информацию. Теперь мы можем показать, какие из полученных результатов измерения роста находятся в пределах интервала, который мы получим, если отложим от среднего (в обе стороны от него) среднеквадратическое отклонение.
То есть с помощью среднеквадратического отклонения мы получаем “стандартный” метод, который позволяет узнать, какое из значений является нормальным (среднестатистическим), а какое экстраординарно большим или, наоборот, малым.
Что такое стандартное отклонение
Но… все будет немного иначе, если мы будем анализировать выборку данных. В нашем примере мы рассматривали генеральную совокупность. То есть наши 5 собак были единственными в мире собаками, которые нас интересовали.
Но если данные являются выборкой (значениями, которые выбрали из большой генеральной совокупности), тогда вычисления нужно вести иначе.
Если есть 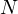 значений, то:
значений, то:
- Когда мы имеем дело с генеральной совокупностью при вычислении дисперсии, мы делим на (как и было сделано в рассмотренном нами примере).
- Когда мы имеем дело с выборкой, при вычислении дисперсии делим на
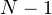 .
.
Все остальные расчеты производятся аналогично, в том числе и определение среднего.
Например, если наших пять собак – только выборка из генеральной совокупности собак (всех собак на планете), мы должны делить на 4, а не на 5, а именно:
Дисперсия выборки = 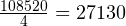 мм 2 .
мм 2 .
При этом стандартное отклонение по выборке равно 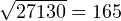 мм (округлено до ближайшего целого значения).
мм (округлено до ближайшего целого значения).
Можно сказать, что мы произвели некоторую “коррекцию” в случае, когда наши значения являются всего лишь небольшой выборкой.
Примечание. Почему именно квадраты разностей?
Но почему при вычислении дисперсии мы берём именно квадраты разностей? Допустим при измерении какого-то параметра, вы получили следующий набор значений: 4; 4; -4; -4. Если мы просто сложим абсолютные отклонения от среднего (разности) между собой … отрицательные значения взаимно уничтожатся с положительными:
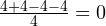 .
.
Получается, этот вариант бесполезен. Тогда, может, стоит попробовать абсолютные значения отклонений (то есть модули этих значений)?
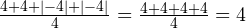 .
.
На первый взгляд получается неплохо (полученная величина, кстати, называется средним абсолютным отклонением), но не во всех случаях. Попробуем другой пример. Пусть в результате измерения получился следующий набор значений: 7; 1; -6; -2. Тогда среднее абсолютное отклонение равно:
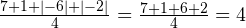 .
.
Вот это да! Снова получили результат 4, хотя разности имеют гораздо больший разброс.
А теперь посмотрим, что получится, если возвести разности в квадрат (и взять потом квадратный корень из их суммы).
Для первого примера получится:
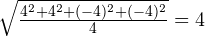 .
.
Для второго примера получится:
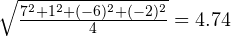 .
.
Теперь – совсем другое дело! Среднеквадратическое отклонение получается тем большим, чем больший разброс имеют разности … к чему мы и стремились.
Фактически в данном методе использована та же идея, что и при вычислении расстояния между точками, только примененная иным способом.
И с математической точки зрения использование квадратов и квадратных корней дает больше пользы, чем мы могли бы получить на основании абсолютных значений отклонений, благодаря чему среднеквадратическое отклонение применимо и для других математических задач.
О том, как найти среднеквадратическое отклонение, вам рассказал репетитор по математике в Москве, Сергей Валерьевич
Урок по теории вероятностей и статистике в 7 классе
план-конспект урока по математике (7 класс)

На предыдущих уроках мы рассмотрели так называемые средние характеристики числового ряда, позволяющие оценить его поведение “в среднем”. Повторим их определения и способы нахождения.
Слайд 2 – задание на повторение (комментарии учителя, проверка ответов учеников с помощью слайда).
Задание . Дан числовой набор.
Найти среднее арифметическое и медиану, определить, какая из характеристик лучше характеризует числовой набор и почему?
III. Изучение нового материала, формирование знаний, умений и навыков
Слайд 3 — характеристики числового ряда (комментарии учителя).
Средние характеристики числового ряда (среднее арифметическое, медиана), позволяют оценить поведение ряда “в среднем”. Но это не всегда наиболее полно характеризуют выборку. Чтобы получить полное представление о поведении числового ряда, помимо средних характеристик надо знать характеристики разброса , показывающие, насколько сильно значения ряда отличаются друг от друга, как сильно они разбросаны вокруг средних.
Рассмотрим следующий пример ( раздать карточки с таблицами, которых нужно заполнять по ходу урока)
Слайд 4-5 – задание 1 (комментарий учителя).
Международные спортивные игры "Дети Азии" получили свое начало в 1996 г. по инициативе первого Президента Республики Саха (Якутия) М.Е.Николаева и были посвящены 100-летию олимпийского движения. С тех пор они проводятся совместно с Олимпийским комитетом России, Росспортом, Министерством иностранных дел Министерством образования и науки Российской Федерации. Летом 2012 года будет V международная спортивная игра «Дети Азии».
Для участия в V международных спортивных играх «Дети Азии» нужно выбрать лучших футболистов республики. На одно место футболиста претендуют двое. Для каждого из них установили испытательный срок, в течение которого они должны были участвовать в отборных играх. Результаты спортсменов представлены в таблице