Как отличить текст в файле с обычной кодировкой от Unicode?
Нужно прочесть текстовый файл. Как узнать, закодирован таблицей символов (однобайтовых), или в файле содержится текст в формате Unicode (16-ти битные символы)?
Файл всегда содержит байты. Иногда содержимое файла можно декодировать в текст, используя выбранную кодировку такую как cp1251, cp866, utf-8, или utf-16le.
На Windows, файлы, закодированные в utf-16, к сожалению иногда называют Unicode (что вводит в заблуждение: Unicode—это не кодировка). utf-16 это всего лишь одна из многих кодировок, которую можно использовать, чтобы закодировать текст (Unicode) в байты:
Файлы, содержащие текст, закодированный в utf-8, utf-16, utf-32 и других кодировках, могут содержать в начале специальную последовательность байт (U+FEFF символ BOM, закодированный в соответствующей кодировке), которая идентифицирует эти кодировки.
Если файл следует этому соглашению, то достаточно несколько первых байт из файла (в двоичном режиме открытого) сравнить с вариантами BOM, чтобы определить соответствующую кодировку. В общем случае нет гарантированного на 100% способа определить кодировку файла (хотя некоторые кодировки могут быть более вероятны чем другие и может быть API, которое пытается угадать кодировку, такое как: IsTextUnicode() с IS_TEXT_UNICODE_STATISTICS ). Пример: «Bush hid the facts» текст, закодированный в ascii кодировке, мог некоторыми приложениями интерпретироваться как текст в utf-16le кодировке, приводя к кракозябрам.
FAQ: Как проверить кодировку в текстовом файле?
Программный комплекс SocialKit корректно работает с кириллицей в текстовых файлах, кодировка которых соответствует стандарту Windows-1251 (кратко может быть записано как CP1251 или ANSI). В этой связи в задачах, поддерживающих указание внешнего файла с перечнем комментариев, сообщений, описаний и прочей информации, которая может содержать кириллицу, нужно указывать текстовые файлы, где русский текст задан в кодировке по стандарту Windows-1251 или же просто ANSI, или CP1251 — всё это, по сути, одно и то же.
Учитывая, что многие инструменты по работе с текстом не отображают, в какой именно кодировке задан текст в текстовом файле и/или не поддерживают преобразование кодировок, то у новичков часто возникает вопрос о том, как именно привести кодировку текстового файла с русским текстом к понятному для SocialKit формату CP1251.
Следует сразу отметить, что большинство текстовых редакторов для ОС Windows (например, встроенный Блокнот и Wordpad) по умолчанию создают текстовые файлы именно с кодировкой по стандарту Windows-1251. Однако, эта кодировка по умолчанию может быть изменена в следствие тех или иных действий.
Если вы не уверены в том, в какой именно кодировке задан текст, то проще всего этот текст пересохранить через стандартный Блокнот Windows. При пересохранении Блокнот также покажет, в каком формате текст сейчас.
Опишем эту простую процедуру по шагам.
1. Открыть искомый текстовый файл в Блокноте Windows и выбрать пункт меню «Файл» -> «Сохранить как. «.
Пример текстового файла, в котором русский текст задан в формате UTF, но это не очевидно при открытии.
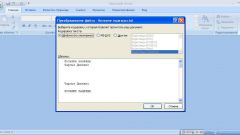
2. В открывшемся диалоговом окне вы сразу видите, в какой кодировке был сохранён текст в текстовом файле.
Диалоговое окно пересохранения текстового файла, в котором можно сразу изменить кодировку.
Как видно, в примере текст в текстовом файле был ранее сохранён в кодировке UTF-8. Для изменения кодировке достаточно выбрать в выпадающем списке кодировку ANSI и нажать кнопку «Сохранить«.
При этом зрительно для вас ничего не изменится, но многое изменится для программы и алгоритмов, занимающихся обработкой текста в процессе отправки. Корректно Instagram’у будет отправлен только ANSI-текст.
Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или —mime, которые включают вывод строки с типом MIME. Пример:

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
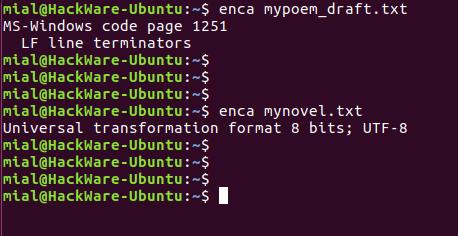
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
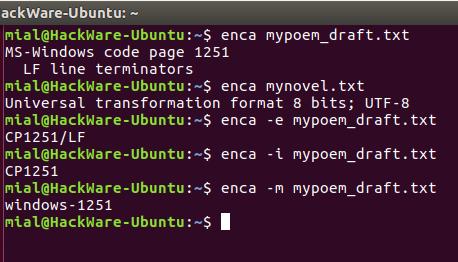
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.
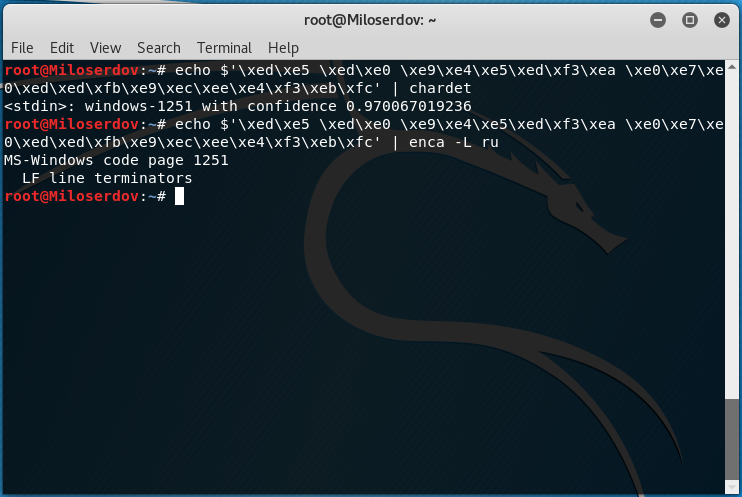
Если возникло сообщение об ошибке:
то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
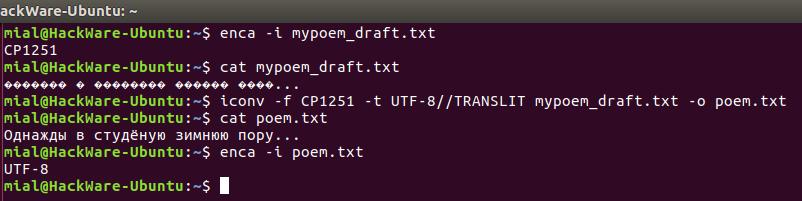
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном.
Внимание! Следующая команда изменяет исходный файл, при этом иногда его просто обнуляет. Поэтому обязательно начните с создания резервной копии:
Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:
Как определить кодировку текстового файла

Примените специализированные утилиты для определения кодировок текстовых файлов. В UNIX-подобных системах можно использовать enca. При необходимости установите эту программу при помощи доступных менеджеров пакетов. Выведите список доступных языков, выполнив команду:
enca —list languages
Определите кодировку текстового файла, указав его имя при помощи опции -g и язык документа при помощи опции -L. Например:
enca -L russian -g /home/vic/tmp/aaa.txt.
- Кодировка текста ASCII
- Как узнать кодировку текста
- Как узнать кодировку файла
- Как определить кодировку
- Как проверить кодировку

- Как подобрать кодировку

- Как узнать кодировку

- Как расшифровать txt

- Как восстановить кодировку

- Как раскодировать закодированные данные

- Как расшифровать письмо

- Как изменить кодировку в ворд
- Почему вместо букв показываются иероглифы
- Как выбрать кодировку, которая позволит прочитать документ

- Как распознать файл

- Как изменить кодировку текстового файла

- Как перевести абракадабру
