Какой буквой обозначается количество страниц?

Книга в которой150 страниц по 240 символов на каждой странице опредилить количество информации книги?
Книга в которой150 страниц по 240 символов на каждой странице опредилить количество информации книги.
Сообщение занимает 2 страницы, и содержит 1 \ 16 кбайта информации?
Сообщение занимает 2 страницы, и содержит 1 \ 16 кбайта информации.
На каждой странице записано 256 символов.
Какое количество информации несет одна буква использованного алфавита?

Rакой буквой обозначается разрядность в информатике?
Rакой буквой обозначается разрядность в информатике?
Известно количество символов в каждой строке, количество строк на странице?
Известно количество символов в каждой строке, количество строк на странице.
Написать программу, считывающую эти значения с клавиатуры и вычисляющую число символов на странице.

В книге 25 строке 1 странице?
В книге 25 строке 1 странице.
Всего 50 страниц.
В 1 строке 300 символов / букв / Сколько информации содержит в этой количество информации.

Какое количество страниц будет найдено по запросу шоколад?
Какое количество страниц будет найдено по запросу шоколад.

В учебнике, в котором 160 страниц, пронумерованы страницы с 4 по 159?
В учебнике, в котором 160 страниц, пронумерованы страницы с 4 по 159.
Какое общее количество цифр использовано в нумерации страниц учебника?
Определите количество информации в российском журнале, если в нем 56 страниц и на каждой странице 1568 букв?
Определите количество информации в российском журнале, если в нем 56 страниц и на каждой странице 1568 букв.
Мощность алфавита 33 буквы.
Ответ написать в байтах.

Задача №1 В таблице приведены запросы и количество найденных по ним страниц некоторого сегмента сети Интернет?
Задача №1 В таблице приведены запросы и количество найденных по ним страниц некоторого сегмента сети Интернет.
Запрос Найдено страниц Торты | Пироги 12000 Торты & ; Пироги 6500 Пироги 7700 Какое количество страниц будет найдено по запросу Торты?
Задача №2 В таблице приведены запросы и количество найденных по ним страниц некоторого сегмента сети Интернет.
Запрос Найдено страниц Пироженое & ; Выпечка 5100 Пироженое 9700 Пироженое | Выпечка 14200 Какое количество страниц будет найдено по запросу Выпечка?

Сообщение занимает 2 страницы и содержит 1 / 16 Кбайта информации?
Сообщение занимает 2 страницы и содержит 1 / 16 Кбайта информации.
На каждой станице записано 256 символов.
Какое количество информации несет одна буква ?
Вы зашли на страницу вопроса Какой буквой обозначается количество страниц?, который относится к категории Информатика. По уровню сложности вопрос соответствует учебной программе для учащихся 5 — 9 классов. В этой же категории вы найдете ответ и на другие, похожие вопросы по теме, найти который можно с помощью автоматической системы «умный поиск». Интересную информацию можно найти в комментариях-ответах пользователей, с которыми есть обратная связь для обсуждения темы. Если предложенные варианты ответов не удовлетворяют, создайте свой вариант запроса в верхней строке.
5. Количество информации. Измерение информации. Единицы измерения
За единицу количества информации принимается такое количество информации, которое содержит сообщение, уменьшающее неопределенность в два раза. Такая единица названа «бит».
Для информации существуют свои единицы измерения информации. Если рассматривать сообщения информации как последовательность знаков, то их можно представлять битами, а измерять в байтах, килобайтах, мегабайтах, гигабайтах, терабайтах и петабайтах.
Давайте разберемся с этим, ведь нам придется измерять объем памяти и быстродействие компьютера.
Единицей измерения количества информации является бит – это наименьшая (элементарная) единица.
1бит – это количество информации, содержащейся в сообщении, которое вдвое уменьшает неопределенность знаний о чем-либо.
Байт – основная единица измерения количества информации.
Байтом называется последовательность из 8 битов.
Байт – довольно мелкая единица измерения информации. Например, 1 символ – это 1 байт.
Производные единицы измерения количества информации
1 килобайт (Кб)=1024 байта =210 байтов
1 мегабайт (Мб)=1024 килобайта =210 килобайтов=220 байтов
1 гигабайт (Гб)=1024 мегабайта =210 мегабайтов=230 байтов
1 терабайт (Гб)=1024 гигабайта =210 гигабайтов=240 байтов
Запомните, приставка КИЛО в информатике – это не 1000, а 1024, то есть 210 .
Методы измерения количества информации
Итак, количество информации в 1 бит вдвое уменьшает неопределенность знаний. Связь же между количеством возможных событий N и количеством информации I определяется формулой Хартли:
Алфавитный подход к измерению количества информации
При этом подходе отвлекаются от содержания (смысла) информации и рассматривают ее как последовательность знаков определенной знаковой системы. Набор символов языка, т.е. его алфавит можно рассматривать как различные возможные события. Тогда, если считать, что появление символов в сообщении равновероятно, по формуле Хартли можно рассчитать, какое количество информации несет в себе каждый символ:
Вероятностный подход к измерению количества информации
Этот подход применяют, когда возможные события имеют различные вероятности реализации. В этом случае количество информации определяют по формуле Шеннона:
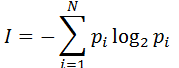 , где
, где
I – количество информации,
N – количество возможных событий,
Pi – вероятность i-го события.
6. Кодирование информации различных видов
1.6.1. КОДИРОВАНИЕ ЧИСЕЛ.
Используя n бит, можно записывать двоичные коды чисел от 0 до 2n-1, всего 2n чисел.
1) Кодирование положительных чисел: Для записи положительных чисел в байте заданное число слева дополняют нулями до восьми цифр. Эти нули называют незначимыми.
Например: записать в байте число 1310 = 11012
2) Кодирование отрицательных чисел:Наибольшее положительное число, которое можно записать в байт, — это 127, поэтому для записи отрицательных чисел используют числа с 128-го по 255-е. В этом случае, чтобы записать отрицательное число, к нему добавляют 256, и полученное число записывают в ячейку.
1.6.2. КОДИРОВАНИЕ ТЕКСТА.
Соответствие между набором букв и числами называется кодировкой символа. Как правило, код символа хранится в одном байте, поэтому коды символов могут принимать значение от 0 до 255. Такие кодировки называют однобайтными. Они позволяют использовать 256 символов. Таблица кодов символов называется ASCII (American StandardCodeforInformationInterchange- Американский стандартный код для обмена информацией). Таблица ASCII-кодов состоит из двух частей:
Коды от 0 до 127 одинаковы для всех IBM-PC совместимых компьютеров и содержат:
коды управляющих символов;
коды цифр, арифметических операций, знаков препинания;
некоторые специальные символы;
коды больших и маленьких латинских букв.
Вторая часть таблицы (коды от 128 до 255) бывает различной в различных компьютерах. Она содержит:
коды букв национального алфавита;
коды некоторых математическихсимволов;
коды символов псевдографики.
В настоящее время все большее распространение приобретает двухбайтная кодировка Unicode. В ней коды символов могут принимать значение от 0 до 65535.
1.6.3. КОДИРОВАНИЕ ЦВЕТОВОЙ ИНФОРМАЦИИ.
Одним байтом можно закодировать 256 различных цветов. Это достаточно для рисованных изображений типа мультфильмов, но не достаточно для полноцветных изображений живой природы. Если для кодирования цвета использовать 2 байта, можно закодировать уже 65536 цветов. А если 3 байта – 16,5 млн. различных цветов. Такой режим позволяет хранить, обрабатывать и передавать изображения, не уступающие по качеству наблюдаемым в живой природе.
Из курса физики известно, что любой цвет можно представить в виде комбинации трех основных цветов: красного, зеленого, синего (их называют цветовыми составляющими). Если кодировать цвет точки с помощью 3 байтов, то первый байт выделяется красной составляющей, второй – зеленой, третий – синей. Чем больше значение байта цветовой составляющей, тем ярче этот цвет.
Белый цвет – у точки есть все цветовые составляющие, и они имеют полную яркость. Поэтому белый цвет кодируется так: 255 255 255. (11111111 11111111 11111111)
Черный цвет – отсутствие всех прочих цветов: 0 0 0. (00000000 00000000 00000000)
Серый цвет – промежуточный между черным и белым. В нем есть все цветовые составляющие, но они одинаковы и нейтрализуют друг друга.
Например: 100 100 100 или 150 150 150. (2-й вариант — ярче).
Красный цвет – все составляющие, кроме красной, равны 0. Темно-красный: 128 0 0. Ярко-красный: 255 0 0.
Зеленый цвет – 0 255 0.
Синий цвет – 0 0 255.
1.6.4. КОДИРОВАНИЕ ГРАФИЧЕСКОЙ ИНФОРМАЦИИ.
Рисунок разбивают на точки. Чем больше будет точек, и чем мельче они будут, тем точнее будет передача рисунка. Затем, двигаясь по строкам слева направо начиная с верхнего левого угла, последовательно кодируют цвет каждой точки. Для черно-белой картинки достаточно 1 байта для точки, для цветной – до 3-х байт для одной точки.
Двоичная система счисления
В двоичной системе счисления используются всего две цифры 0 и 1. Другими словами, двойка является основанием двоичной системы счисления. (Аналогично у десятичной системы основание 10.)
Чтобы научиться понимать числа в двоичной системе счисления, сначала рассмотрим, как формируются числа в привычной для нас десятичной системе счисления.
В десятичной системе счисления мы располагаем десятью знаками-цифрами (от 0 до 9). Когда счет достигает 9, то вводится новый разряд (десятки), а единицы обнуляются и счет начинается снова. После 19 разряд десятков увеличивается на 1, а единицы снова обнуляются. И так далее. Когда десятки доходят до 9, то потом появляется третий разряд – сотни.
Двоичная система счисления аналогична десятичной за исключением того, что в формировании числа участвуют всего лишь две знака-цифры: 0 и 1. Как только разряд достигает своего предела (т.е. единицы), появляется новый разряд, а старый обнуляется.
Попробуем считать в двоичной системе:
1 – это один (и это предел разряда)
11 – это три (и это снова предел)
100 – это четыре
Перевод чисел из двоичной системы счисления в десятичную
Не трудно заметить, что в двоичной системе счисления длины чисел с увеличением значения растут быстрыми темпами. Как определить, что значит вот это: 10001001? Непривычный к такой форме записи чисел человеческий мозг обычно не может понять сколько это. Неплохо бы уметь переводить двоичные числа в десятичные.
В десятичной системе счисления любое число можно представить в форме суммы единиц, десяток, сотен и т.д. Например:
1476 = 1000 + 400 + 70 + 6
Можно пойти еще дальше и разложить так:
1476 = 1 * 103 + 4 * 102 + 7 * 101 + 6 * 100
Посмотрите на эту запись внимательно. Здесь цифры 1, 4, 7 и 6 — это набор цифр из которых состоит число 1476. Все эти цифры поочередно умножаются на десять возведенную в ту или иную степень. Десять – это основание десятичной системы счисления. Степень, в которую возводится десятка – это разряд цифры за минусом единицы.
Аналогично можно разложить и любое двоичное число. Только основание здесь будет 2:
10001001 = 1*27 + 0*26 + 0*25 + 0*24 + 1*23 + 0*22 + 0*21 + 1*20
Если посчитать сумму составляющих, то в итоге мы получим десятичное число, соответствующее 10001001:
1*27 + 0*26 + 0*25 + 0*24 + 1*23 + 0*22 + 0*21 + 1*20 = 128 + 0 + 0 + 0 + 8 + 0 + 0 + 1 = 137
Т.е. число 10001001 по основанию 2 равно числу 137 по основанию 10. Записать это можно так:
Почему двоичная система счисления так распространена?
Дело в том, что двоичная система счисления – это язык вычислительной техники. Каждая цифра должна быть как-то представлена на физическом носителе. Если это десятичная система, то придется создать такое устройство, которое может быть в десяти состояниях. Это сложно. Проще изготовить физический элемент, который может быть лишь в двух состояниях (например, есть ток или нет тока). Это одна из основных причин, почему двоичной системе счисления уделяется столько внимания.
Перевод десятичного числа в двоичное
Может потребоваться перевести десятичное число в двоичное. Один из способов – это деление на два и формирование двоичного числа из остатков. Например, нужно получить из числа 77 его двоичную запись:
77 / 2 = 38 (1 остаток)
38 / 2 = 19 (0 остаток)
19 / 2 = 9 (1 остаток)
9 / 2 = 4 (1 остаток)
4 / 2 = 2 (0 остаток)
2 / 2 = 1 (0 остаток)
1 / 2 = 0 (1 остаток)
Собираем остатки вместе, начиная с конца: 1001101. Это и есть число 77 в двоичном представлении. Проверим:
1001101 = 1*26 + 0*25 + 0*24 + 1*23 + 1*22 + 0*21 + 1*20 = 64 + 0 + 0 + 8 + 4 + 0 + 1 = 77
ASCII(англ. American Standard Code for Information Interchange) — американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов. В американском варианте английского языка произносится [э́ски], тогда как в Великобритании чаще произносится [а́ски]; по-русски произносится также [а́ски] или [аски́].
ASCII представляет собой кодировку для представления десятичных цифр, латинского и национального алфавитов, знаков препинания и управляющих символов. Изначально разработанная как 7-битная, с широким распространением 8-битного байта ASCII стала восприниматься как половина 8-битной. В компьютерах обычно используют расширения ASCII с задействованным 8-м битом и второй половиной кодовой таблицы (например КОИ-8).
Поскольку ASCII изначально предназначался для обмена информацией (по телетайпу), в нём, кроме информационных символов, используются символы-команды для управления связью. Это обычный набор спецсигналов, применявшийся и в других докомпьютерных средствах обмена сообщениями (азбука Морзе, семафорная азбука), дополненный с учётом специфики устройства.
(После названия каждого символа указан его 16-ричный код)
NUL, 00 — Null, пустой. Всегда игнорировался. На перфолентах 1 представлялась отверстием, 0 — отсутствием отверстия. Поэтому пустые части перфоленты до начала и после конца сообщения состояли из таких символов. Сейчас используется во многих языках программирования как конец строки. (Строка понимается как последовательность символов.) В некоторых операционных системах NUL — последний символ любого текстового файла.
SOH, 01 — Start Of Heading, начало заголовка.
STX, 02 — Start of Text, начало текста. Текстом называлась часть сообщения, предназначенная для печати. Адрес, контрольная сумма и т. д. входили или в заголовок, или в часть сообщения после текста.
ETX, 03 — End of Text, конец текста. Здесь телетайп прекращал печатать. Использование символа Ctrl-C, имеющего код 03, для прекращения работы чего-то (обычно программы), восходит ещё к тем временам.
EOT, 04 — End of Transmission, конец передачи. В системе UNIX Ctrl-D, имеющий тот же код, означает конец файла при вводе с клавиатуры.
ENQ, 05 — Enquire. Прошу подтверждения.
ACK, 06 — Acknowledgement. Подтверждаю.
BEL, 07 — Bell, звонок, звуковой сигнал. Сейчас тоже используется. В языках программирования C и C++ обозначается \a.
BS, 08 — Backspace, возврат на один символ. Сейчас стирает предыдущий символ.
TAB, 09 — Tabulation. Обозначался также HT — Horizontal Tabulation, горизонтальная табуляция. Во многих языках программирования обозначается \t .
LF, 0A — Line Feed, перевод строки. Сейчас в конце каждой строчки текстового файла ставится либо этот символ, либо CR, либо и тот и другой (CR, затем LF), в зависимости от операционной системы. Во многих языках программирования обозначается \n и при выводе текста приводит к переводу строки.
VT, 0B — Vertical Tab, вертикальная табуляция.
FF, 0C — Form Feed, прогон страницы, новая страница.
CR, 0D — Carriage Return, возврат каретки. Во многих языках программирования этот символ, обозначаемый \r, можно использовать для возврата в начало строчки без перевода строки. В некоторых операционных системах этот же символ, обозначаемый Ctrl-M, ставится в конце каждой строчки текстового файла перед LF.
SO, 0E — Shift Out, измени цвет ленты (использовался для двуцветных лент; цвет менялся обычно на красный). В дальнейшем обозначал начало использования национальной кодировки.
SI, 0F — Shift In, обратно к Shift Out.
DLE, 10 — Data Link Escape, освобождение канала данных — следующие символы представляют собой данные, а не управляющие символы.
DC1, 11 — Device Control 1, 1-й символ управления устройством — включить устройство чтения перфоленты.
DC2, 12 — Device Control 2, 2-й символ управления устройством — включить перфоратор.
DC3, 13 — Device Control 3, 3-й символ управления устройством — выключить устройство чтения перфоленты.
DC4, 14 — Device Control 4, 4-й символ управления устройством — выключить перфоратор.
NAK, 15 — Negative Acknowledgment, не подтверждаю. Обратно Acknowledgment.
SYN, 16 — Synchronization. Этот символ передавался, когда для синхронизации было необходимо что-нибудь передать.
ETB, 17 — End of Text Block, конец текстового блока. Иногда текст по техническим причинам разбивался на блоки.
CAN, 18 — Cancel, отмена (того, что было передано ранее).
EM, 19 — End of Medium, конец носителя (кончилась перфолента и т. д.)
SUB, 1A — Substitute, подставить. Ставится на месте символа, значение которого было потеряно или испорчено при передаче. Сейчас Ctrl-Z используется как конец файла при вводе с клавиатуры в системах DOS и Windows. У этой функции нет никакой очевидной связи с символом SUB.
ESC, 1B — Escape. Следующие за ним символы имеют какое-то другое значение, отличное от того, которое определено в ASCII. Обычно начинал управляющие последовательности.
FS, 1C — File Separator, разделитель файлов.
GS, 1D — Group Separator, разделитель групп.
RS, 1E — Record Separator, разделитель записей.
US, 1F — Unit Separator, разделитель юнитов. То есть поддерживалось 4 уровня структуризации данных: сообщение могло состоять из файлов, файлы из групп, группы из записей, записи из юнитов.
DEL, 7F — Delete, стереть последний символ. Символом DEL, состоящим в двоичном коде из всех единиц, можно было забить любой символ. Устройства и программы игнорировали DEL так же, как NUL. Код этого символа происходит из первых текстовых процессоров с памятью на перфоленте: в них удаление символа происходило забиванием его кода дырочками (обозначавшими логические единицы).
Растровая и векторная графика
Способы представления изображений в памяти ЭВМ
Формальное определение компьютерная (машинная) графика – это создание, хранение и обработка моделей объектов и их изображений с помощью ЭВМ. Под интерактивной компьютерной графикой понимают раздел компьютерной графики, изучающий вопросы динамического управления со стороны пользователя содержанием изображения, его формой, размерами и цветом на экране с помощью интерактивных устройств взаимодействия.
Под компьютерной геометрией понимают математический аппарат, применяемый в компьютерной графике.
Необходимо отметить следующую отличительную черту компьютерных изображений. Изображения, которые мы встречаем в нашей повседневной жизни, реальные картины природы, можно бесконечно детализировать, выявлять все новые цвета и оттенки. Изображения, хранящиеся в памяти компьютера, независимо от способа их получения и представления, всегда являются усеченной моделью картины реального мира. Их детализация возможна лишь с той степенью, которая была заложена при их создании или получении, и их цветовая гамма будет не шире заранее оговоренной.
Одно и то же изображение может быть представлено в памяти ЭВМ двумя принципиально различными способами и получено два различных типа изображения: растровое и векторное. Рассмотрим подробнее эти способы представления изображений, выделим их основные параметры и определим их достоинства и недостатки.
Что такое растровое изображение?
Возьмём фотографию (например, см. рис. 1.1). Конечно, она тоже состоит из маленьких элементов, но будем считать, что отдельные элементы мы рассмотреть не можем. Она представляется для нас, как реальная картина природы.
Теперь разобьём это изображение на маленькие квадратики (маленькие, но всё-таки чётко различимые), и каждый квадратик закрасим цветом, преобладающим в нём (на самом деле программы при оцифровке генерируют некий «средний» цвет, т. е. если у нас была одна чёрная точка и одна белая, то квадратик будет иметь серый цвет).
Как мы видим, изображение стало состоять из конечного числа квадратиков определённого цвета. Эти квадратики называют pixel (от PICture ELement) – пиксел или пиксель.

Рис. 1.1. Исходное изображение
Теперь каким-либо методом занумеруем цвета. Конкретная реализация этих методов нас пока не интересует. Для нас сейчас важно то, что каждый пиксель на рисунке стал иметь определённый цвет, обозначенный цифрой (рис. 1.2).

Рис. 1.2. Фрагмент оцифрованного изображения и номера цветов
Теперь пойдём по порядку (слева направо и сверху вниз) и будем в строчку выписывать номера цветов встречающихся пикселей. Получится строка примерно следующего вида:
1 2 8 3 212 45 67 45 127 4 78 225 34 .
Вот эта строка и есть наши оцифрованные данные. Теперь мы можем сжать их (так как несжатые графические данные обычно имеют достаточно большой размер) и сохранить в файл.
Итак, под растровым (bitmap, raster) понимают способ представления изображения в виде совокупности отдельных точек (пикселей) различных цветов или оттенков. Это наиболее простой способ представления изображения, ибо таким образом видит наш глаз.
Достоинством такого способа является возможность получения фотореалистичного изображения высокого качества в различном цветовом диапазоне. Недостатком – высокая точность и широкий цветовой диапазон требуют увеличения объема файла для хранения изображения и оперативной памяти для его обработки.
Для векторной графики характерно разбиение изображения на ряд графических примитивов – точки, прямые, ломаные, дуги, полигоны. Таким образом, появляется возможность хранить не все точки изображения, а координаты узлов примитивов и их свойства (цвет, связь с другими узлами и т. д.).
Вернемся к изображению на рис. 1.1. Взглянем на него по-другому. На изображении легко можно выделить множество простых объектов — отрезки прямых, ломанные, эллипс, замкнутые кривые. Представим себе, что пространство рисунка существует в некоторой координатной системе. Тогда можно описать это изображение, как совокупность простых объектов, вышеперечисленных типов, координаты узлов которых заданы вектором относительно точки начала координат (рис. 1.3).

Рис. 1.3. Векторное изображение и узлы его примитивов
Проще говоря, чтобы компьютер нарисовал прямую, нужны координаты двух точек, которые связываются по кратчайшей прямой. Для дуги задается радиус и т. д. Таким образом, векторная иллюстрация – это набор геометрических примитивов.
Важной деталью является то, что объекты задаются независимо друг от друга и, следовательно, могут перекрываться между собой.
При использовании векторного представления изображение хранится в памяти как база данных описаний примитивов. Основные графические примитивы, используемые в векторных графических редакторах: точка, прямая, кривая Безье, эллипс (окружность), полигон (прямоугольник). Примитив строится вокруг его узлов (nodes). Координаты узлов задаются относительно координатной системы макета.
А изображение будет представлять из себя массив описаний – нечто типа:
Каждому узлу приписывается группа параметров, в зависимости от типа примитива, которые задают его геометрию относительно узла. Например, окружность задается одним узлом и одним параметром – радиусом. Такой набор параметров, которые играют роль коэффициентов и других величин в уравнениях и аналитических соотношениях объекта данного типа, называют аналитической моделью примитива. Отрисовать примитив – значит построить его геометрическую форму по его параметрам согласно его аналитической модели.
Векторное изображение может быть легко масштабировано без потери деталей, так как это требует пересчета сравнительно небольшого числа координат узлов. Другой термин – «object-oriented graphics».
Самой простой аналогией векторного изображения может служить аппликация. Все изображение состоит из отдельных кусочков различной формы и цвета (даже части растра), «склеенных» между собой. Понятно, что таким образом трудно получить фотореалистичное изображение, так как на нем сложно выделить конечное число примитивов, однако существенными достоинствами векторного способа представления изображения, по сравнению с растровым, являются:
· векторное изображение может быть легко масштабировано без потери качества, так как это требует пересчета сравнительно небольшого числа координат узлов;
· графические файлы, в которых хранятся векторные изображения, имеют существенно меньший, по сравнению с растровыми, объем (порядка нескольких килобайт).
Сферы применения векторной графики очень широки. В полиграфике – от создания красочных иллюстраций до работы со шрифтами. Все, что мы называем машинной графикой, 3D-графикой, графическими средствами компьютерного моделирования и САПР – все это сферы приоритета векторной графики, ибо эти ветви дерева компьютерных наук рассматривают изображение исключительно с позиции его математического представления.
Как видно, векторным можно назвать только способ описания изображения, а само изображение для нашего глаза всегда растровое. Таким образом, задачами векторного графического редактора являются растровая прорисовка графических примитивов и предоставление пользователю сервиса по изменению параметров этих примитивов. Все изображение представляет собой базу данных примитивов и параметров макета (размеры холста, единицы измерения и т. д.). Отрисовать изображение – значит выполнить последовательно процедуры прорисовки всех его деталей.
Для уяснения разницы между растровой и векторной графикой приведем простой пример. Вы решили отсканировать Вашу фотографию размером 10´15 см чтобы затем обработать и распечатать на цветном принтере. Для получения приемлемого качества печати необходимо разрешение не менее 300 dpi. Считаем:
10 см = 3,9 дюйма; 15 см = 5,9 дюймов.
По вертикали: 3,9 * 300 = 1170 точек.
По горизонтали: 5,9 * 300 = 1770 точек.
Итак, число пикселей растровой матрицы 1170 * 1770 = 2 070 900.
Теперь решим, сколько цветов мы хотим использовать. Для черно-белого изображения используют обычно 256 градаций серого цвета для каждого пикселя, или 1 байт. Получаем, что для хранения нашего изображения надо 2 070 900 байт или 1,97 Мб.
Для получения качественного цветного изображения надо не менее 256 оттенков для каждого базового цвета. В модели RGB соответственно их 3: красный, зеленый и синий. Получаем общее количество байт – 3 на каждый пиксел. Соответственно, размер хранимого изображения возрастает в три раза и составляет 5,92 Мб.
Для создания макета для полиграфии фотографии сканируют с разрешением 600 dpi, следовательно, размер файла вырастает еще вчетверо.
С другой стороны, если изображение состоит из простых объектов, то для его хранения в векторном виде необходимо не более нескольких килобайт.
Определение количества информации в сообщении

Все мы привыкли к тому, что все вокруг можно измерить. Мы можем определить массу посылки, длину стола, скорость движения автомобиля. Но как определить количество информации, содержащееся в сообщении? Ответ на вопрос в статье.
Итак, давайте для начала выберем сообщение. Пусть это будет «Принтер — устройство вывода информации.«. Наша задача — определить, сколько информации содержится в данном сообщении. Иными словами — сколько памяти потребуется для его хранения.
Определение количества информации в сообщении
Для решения задачи нам нужно определить, сколько информации несет один символ сообщения, а потом умножить это значение на количество символов. И если количество символов мы можем посчитать, то вес символа нужно вычислить. Для этого посчитаем количество различных символов в сообщении. Напомню, что знаки препинания, пробел — это тоже символы. Кроме того, если в сообщении встречается одна и та же строчная и прописная буква — мы считаем их как два различных символа. Приступим.
В слове Принтер 6 различных символов (р встречается дважды и считается один раз), далее 7-й символ пробел и девятый — тире. Так как пробел уже был, то после тире мы его не считаем. В слове устройство 10 символов, но различных — 7, так как буквы с, т и о повторяются. Кроме того буквы т и р уже была в слове Принтер. Так что получается, что в слове устройство 5 различных символов. Считая таким образом дальше мы получим, что в сообщении 20 различных символов.
Далее вспомним формулу, которую называют главной формулой информатики:
Подставив в нее вместо N количество различных символов, мы узнаем, сколько информации несет один символ в битах. В нашем случае формула будет выглядеть так:
Вспомним степени двойки и поймем, что i находится в диапазоне от 4 до 5 (так как 2 4 =16, а 2 5 =32). А так как бит — минимальная единица измерения информации и дробным быть не может, то мы округляем i в большую сторону до 5. Иначе, если принять, что i=4, мы смогли бы закодировать только 2 4 =16 символов, а у нас их 20. Поэтому получаем, что i=5, то есть каждый символ в нашем сообщении несет 5 бит информации.
Осталось посчитать сколько символов в нашем сообщении. Но теперь мы будем считать все символы, не важно повторяются они или нет. Получим, что сообщение состоит из 39 символов. А так как каждый символ — это 5 бит информации, то, умножив 5 на 39 мы получим:
5 бит x 39 символов = 195 бит
Это и есть ответ на вопрос задачи — в сообщении 195 бит информации. И, подводя итог, можно написать алгоритм нахождения объема информации в сообщении:
Какой буквой в информатике обозначается кол-во страниц?
В современном мире информатика играет все более важную роль. Ее применение находит в различных областях жизни, таких как образование, наука, коммуникации и даже в повседневных делах. Одним из важных аспектов информатики является работа с документами и электронными страницами. В процессе работы с ними иногда встает вопрос об обозначении количества страниц в документе. И здесь на помощь приходит специальный символ.
В информатике символ, обозначающий количество страниц, называется "N". Это сокращение используется для указания, сколькими страницами состоит документ или электронный файл. Когда встречается буква "N", это указывает на число страниц, но не конкретное число, а общее количество.
Примеры использования символа "N":
- Регистрационная форма для конференции: "Укажите количество страниц вашей научной статьи: N".
- Рекламный буклет: "В данном буклете содержится N страниц с информацией о нашей компании и продуктах".
- Инструкция по сборке мебели: "Инструкция разделена на N страниц для удобства пользования".
Использование символа "N" позволяет гибко указывать количество страниц в документе без необходимости точного числа. Это особенно полезно в случаях, когда количество страниц может меняться в зависимости от различных факторов, таких как добавление или удаление информации, изменение размера шрифта и т.д.
Кроме буквы "N", в информатике также широко используется другой символ — "M". Обычно он используется для обозначения общего объема информации или размера файла. Однако буква "M" относится к объему информации, а не количеству страниц. Например, "Размер документа составляет M мегабайт".
Выводя на широкое применение символ "N" в информатике помогает упростить обозначение количества страниц в документах и электронных файлах, делая их более удобными и читаемыми для пользователей.
Таким образом, буква "N" является специальным символом в информатике, используемым для обозначения количества страниц. Он придает документам и электронным файлам ясность и удобство в указании количества страниц, особенно в случаях, когда точное число может меняться или неизвестно.
Примечание: разметка с помощью Markdown используется для создания форматированного текста, поэтому данную статью можно было разметить с использованием нескольких конструкций этого языка разметки.