Виды баз данных. Большой обзор типов СУБД
Часто, в обзорах видов баз данных упоминают реляционные и “другие”, “NoSQL” и т.д., либо приводят самые основные типы СУБД (базы данных), забывая о редких. В данной статье я постараюсь описать максимально полно виды баз данных и привести примеры конкретных реализаций. Разумеется, статья не претендует на всеохватность и классифицировать базы данных можно по разному, в том числе по типам оптимальной нагрузки и т.д., и все виды баз данных будут рассмотрены очень кратко. Но надеюсь, статья даст базовое представление о видах СУБД и принципах их работы.
В статье мы рассмотрим следующие типы баз данных:
Базы данных временных рядов
Графовые базы данных
Поисковые базы данных (Search Engines)
Объектно-ориентированные базы данных
RDF (Resource Description Framework)
Wide Column Stores
Native XML СУБД
GEO/GIS (пространственные) и специализированные СУБД
Event СУБД (баз данных переходов состояний)
Навигационные (Navigational) СУБД
Векторные базы данных
Начнем с самого распространенного типа — реляционных СУБД.
Реляционные базы данных
Наиболее известными реляционными базами данных являются Open Source проекты PostgreSQL, MySQL и SQLite, а также проприетарные решения Oracle, Microsoft SQL Server и IBM Db2Relational.
Суть реляционных баз в хранении данных в связанных таблицах.
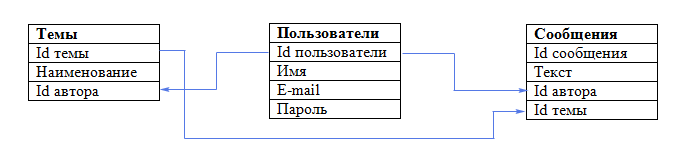
Стоит заметить, что реляционные базы бывают с хранением данных по строкам (PostgreSQL) и по столбцам/колонкам (ClickHouse, Vertica). Колоночные/столбцовые базы лучше подходят для аналитики, в то время как ориентация на строки лучше подходит для транзакционных нагрузок.

Реляционные СУБД — самый распространенный тип баз данных. В подкате таблица из более чем 150 вариантов. Источником данного списка является данный сайт-агрегатор информации по базам данных.
Список реляционных баз данных (и инструментов, содержащих функционал, присущий базам данных, таких как SQL-движки и т.д.) и поддерживаемый тип данных.
Полный список из 166 реляционных СУБД
Oracle — реляционная, мультимодальная
MySQL — реляционная, мультимодальная
Microsoft SQL Server -реляционная, мультимодальная
PostgreSQL — реляционная, мультимодальная
IBM Db2Relational — мультимодальная
Microsoft Access — реляционная
MariaDB — реляционная, мультимодальная
Microsoft Azure SQL Database — реляционная, мультимодальная
Teradata — реляционная, мультимодальная
Google BigQuery — реляционная
SAP HANA — реляционная, мультимодальная
SAP Adaptive Server — реляционная
Microsoft Azure Synapse Analytics — реляционная
Informix — реляционная, мультимодальная
Amazon Redshift — реляционная
Impala — реляционная, мультимодальная
Spark SQL — реляционная
ClickHouse — реляционная, мультимодальная
Apache Flink — реляционная
Greenplum — реляционная, мультимодальная
Amazon Aurora — реляционная, мультимодальная
H2 — реляционная, мультимодальная
Oracle Essbase — реляционная
Microsoft Azure Data Explorer — реляционная, мультимодальная
Microsoft Azure Data Explorer — реляционная, мультимодальная
Trino — реляционная, мультимодальная
SingleStore — реляционная, мультимодальная
SAP SQL Anywhere — реляционная
SAP IQ — реляционная
Oracle NoSQL — мультимодальная
Google Cloud Spanner — реляционная
YugabyteDB — реляционная, мультимодальная
TiDB — реляционная, мультимодальная
Apache Druid — мультимодальная
InterSystems Caché — мультимодальная
InterSystems IRIS — мультимодальная
SAP Advantage Database Server — реляционная
HEAVY.AI — реляционная, мультимодальная
Percona Server for MySQL — реляционная
EDB Postgres — реляционная
Apache Drill — мультимодальная
Apache Phoenix — реляционная
Citus — реляционная, мультимодальная
OceanBase — реляционная, мультимодальная
MonetDB — реляционная, мультимодальная
IBM Db2 warehouse — реляционная
Oracle Rdb — реляционная
PlanetScale — реляционная, мультимодальная
NonStop SQL — реляционная
Apache Kylin — реляционная
Apache HAWQ — реляционная
Dolt — реляционная, мультимодальная
openGauss — реляционная, мультимодальная
Actian Vector — реляционная
Vitess — реляционная, мультимодальная
TDSQL for MySQL — реляционная, мультимодальная
Kinetica — реляционная, мультимодальная
Splice Machine — реляционная
Postgres-XL — реляционная, мультимодальная
Alibaba Cloud MaxCompute — реляционная
Apache Pinot — реляционная
Alibaba Cloud AnalyticDB for MySQL — реляционная, мультимодальная
SQream DB — реляционная
Kingbase — реляционная, мультимодальная
Apache Doris — реляционная
Raima Database Manager — мультимодальная
Alibaba Cloud AnalyticDB for PostgreSQL — реляционная
Mimer SQL — реляционная
Kyligence Enterprise — реляционная
Actian PSQL — реляционная
Alibaba Cloud ApsaraDB for PolarDB — реляционная
Linter — реляционная, мультимодальная
GeoSpock — реляционная, мультимодальная
Faircom DB — мультимодальная
Tibco ComputeDB — реляционная
Valentina Server — реляционная
Edge Intelligence — реляционная
Fujitsu Enterprise Postgres — реляционная, мультимодальна
Transwarp KunDB — реляционная
Sadas Engine — реляционная
Из отечественных игроков можно выделить
Postgres Pro — доработанный под корпоративные задачи PostgreSQL.
Jatoba — как и вариант выше, основана на PostgreSQL.
Квант-Гибрид — еще один вариант PostgreSQL.
Ред — СУБД на базе Interbase/Firebird
ProximaBD — на основе PostgreSQL.
Arenadata DB — корпоративное решение на основе Greenplum
YDB — serverless решение от Яндекса. Это Open Source продукт, который доступен в том числе как для on-premise инсталляций, так и как управляемый сервис с dedicated/serverless моделью потребления.
Вы можете развернуть реляционные базы данных PostgreSQL и MySQL в облаке Amvera Cloud c помощью простого push в выделенный Git-репозиторий. Для этого нужно выполнить несколько простых шагов, описанных в инструкциях для PostgreSQL и MySQL соответственно. Стоимость хостинга баз данных начинается от 170 руб. в месяц.
Реляционные базы закрывают широкий спектр задач, начиная от транзакционных баз и заканчивая аналитическими, но не являются “серебряной пулей” для всех задач. Рассмотрим другие виды базы данных.
Key-value (ключ значение) базы данных
Тип баз данных Key-value предназначен для осуществления быстрых, почти мгновенных запросов для таких задач как кэш, отображение баланса и т.д.. Высокая скорость осуществляется за счет хранения данных по принципу ключ-значение, и в большинстве случаев благодаря работе в оперативной памяти.
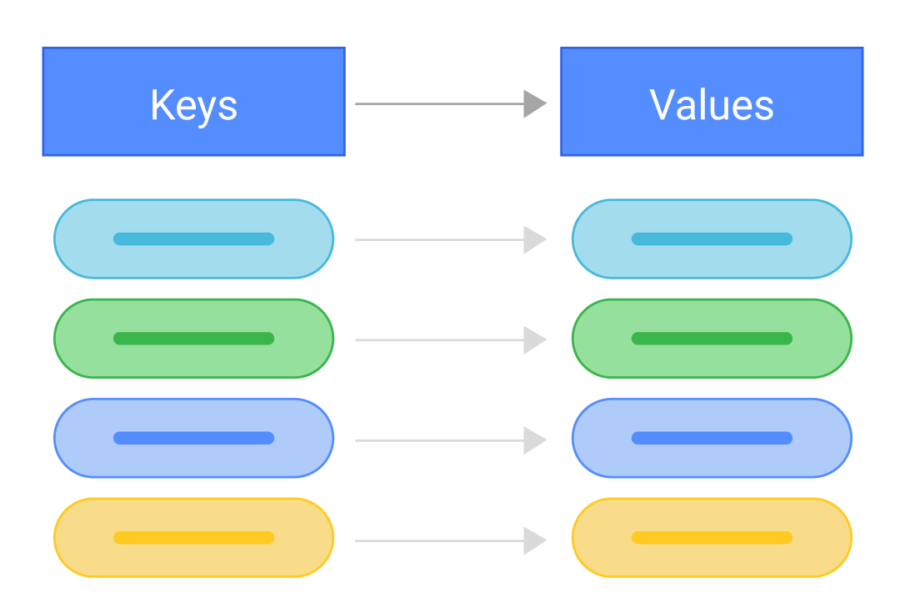
Словари содержат коллекцию объектов или записей, а объекты содержат множество различных полей, каждое из которых содержит данные. Записи хранятся и извлекаются с использованием ключа, который однозначно идентифицирует запись и используется для быстрого поиска данных.
Основным применением является ускорение отображения данных для конечных пользователей и снижение нагрузок, в том числе I/O на инфраструктуру организаций.
Наиболее известными и широко используемыми Key-Value решениями являются Redis и Memcached.
Полный список из 72 Key-Value СУБД под катом
Redis — Key-value, мультимодальная
Amazon DynamoDB — мультимодальная
Microsoft Azure Cosmos DB — мультимодальная
Hazelcast — Key-value, мультимодальная
Riak KV — Key-value
Google Cloud Bigtable — мультимодальная
GemFire — Key-value, мультимодальная
Oracle NoSQL — мультимодальная
Oracle Berkeley DB — мультимодальная
InterSystems Caché — мультимодальная
InterSystems IRIS — мультимодальная
Amazon SimpleDB — Key-value
Amazon SimpleDB — Key-value
Oracle Coherence — Key-value
Tarantool — Key-value, мультимодальная
WebSphere eXtreme Scale — Key-value
Graph Engine — мультимодальная
Project Voldemort — Key-value
Cloudflare Workers KV — Key-value
Tokyo — Tyrant — Key-value
Immudb — Key-value, мультимодальная
Faircom DB — мультимодальная
Kyoto Tycoon — Key-value
Badger — Key — value
Dragonfly — Key — value
ScaleOut StateServer — Key-value
Resin Cache — Key-value
Faircom EDGE — мультимодальная
Из отечественных СУБД здесь следует отдельно выделить Tarantool, распространяемый под лицензией Упрощенная BSD и имеющий отдельную версию для крупных корпоративных клиентов. В Tarantool реализована гибридная схема данных: key-value, документно-ориентированная, реляционная и пространственная.
Вы можете развернуть Key-value базу данных Redis в облаке Amvera Cloud c помощью простого push в выделенный Git-репозиторий. Для этого нужно выполнить несколько простых шагов, описанных в инструкции по развертыванию Redis. Стоимость хостинга Redis начинается от 170 руб. в месяц.
Документо-ориентированные базы данных
Если вам нужно хранить много файлов/документов и вы не хотите задумываться (до разумных пределов, разумеется) о структуре хранения, иерархии, связях, вам может подойти одна из документо-ориентированных баз данных. Дополнительным преимуществом являются широкие возможности для масштабирования.
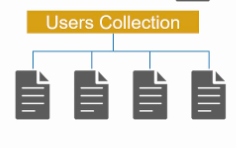
Документо-ориентированные базы данных созданы для хранения иерархических структур данных (документов). Основой документоориентированных СУБД являются документные хранилища, имеющие структуру дерева или леса. Деревья начинаются с корневого узла и может содержать несколько внутренних и листовых узлов. Листовые узлы содержат данные, которые при добавлении документа заносятся в индексы, это дает возможность даже при достаточно сложной структуре находить путь к искомых данных. В отличие от хранилищ типа ключ-значение, выборка по запросу к документному хранилищу может содержать части большого количества документов без полной загрузки этих документов в оперативную память.
Наиболее популярной документо-ориентированной базой данных на текущий момент является MongoDB.

1. MongoDB — Документо-ориентированная, мультимодальная
2. Amazon DynamoDB — мультимодальная
3. Databricks — мультимодальная
4. Microsoft Azure Cosmos DB — мультимодальная
5. Couchbase — Документо-ориентированная, мультимодальная
6. Firebase Realtime Database — Документо-ориентированная
7. CouchDB — Документо-ориентированная, мультимодальная
8. Google Cloud Firestore — Документо-ориентированная
9. MarkLogic — мультимодальная
10. Realm — Документо-ориентированная
11. Aerospike — мультимодальная
12. Google Cloud Datastore — Документо-ориентированная
13. Virtuoso — мультимодальная
14. OrientDB — мультимодальная
15. ArangoDB — мультимодальная
16. RavenDB — Документо-ориентированная, мультимодальная
17. Oracle NoSQL — мультимодальная
18. IBM Cloudant — Документо-ориентированная
19. RethinkDB — Документо-ориентированная, мультимодальная
20. InterSystems IRIS — мультимодальная
21. PouchDB — Документо-ориентированная
22. CloudKit — Документо-ориентированная
23. Apache Drill — мультимодальная
24. Amazon DocumentDB — Документо-ориентированная
25. Mnesia — Документо-ориентированная
26. LiteDB — Документо-ориентированная
27. Fauna — мультимодальная
28. Datameer — Документо-ориентированная
29. GigaSpaces — мультимодальная
30. FoundationDB — мультимодальная
31. AllegroGraph — мультимодальная
32. HPE Ezmeral Data Fabric — мультимодальная
33. CrateDB — мультимодальная
34. LokiJS — Документо-ориентированная
35. BigchainDB — Документо-ориентированная
36. AlaSQL — мультимодальная
37. SurrealDB — мультимодальная
38. Sequoiadb — мультимодальная
39. Percona Server for MongoDB — Документо-ориентированная
40. HarperDB — Документо-ориентированная
41. EJDB — Документо-ориентированная
42. YDB — мультимодальная
43. ArcadeDB — мультимодальная
44. Bangdb — мультимодальная
45. XTDB — Документо-ориентированная
46. YTsaurus — мультимодальная
47. OrigoDB — мультимодальная
48. WhiteDB — Документо-ориентированная
49. ToroDB — Документо-ориентированная
50. SenseiDB — Документо-ориентированная
51. Acebase — Документо-ориентированная
52. iBoxDB — Документо-ориентированная
53. RaptorDB — Документо-ориентированная
54. NosDB — Документо-ориентированная
55. CortexDB — мультимодальная
56. JasDB — Документо-ориентированная
Из отечественных решений, к документо-ориентированным базам данных можно отнести СУБД Енисей.
И в рамках одной из модальностей к таким базам можно отнести YDB и YTsaurus.
Вы можете развернуть документо-ориентированную базу данных MongoDB в облаке Amvera Cloud c помощью простого push в выделенный Git-репозиторий. Для этого нужно выполнить несколько простых шагов, описанных в инструкции по развертыванию MongoDB. Стоимость хостинга MongoDB начинается от 170 руб. в месяц.
Базы данных временных рядов
Если у вас есть упорядоченные по времени данные с временными метками, такие как метрики от инфраструктуры или данные датчиков, может быть полезно использовать одну из баз данных временных рядов.

Общие характеристики баз данных временных рядов:
Данные временных рядов всегда собираются на протяжении определенного периода времени.
Данные из рабочих нагрузок являются новыми и записываются как вставки. Уже существующие данные не обновляются путем замены.
Когда данные записываются, они автоматически назначаются последнему интервалу времени.
Базы даных временных рядов часто используются для осуществления мониторинга различных метрик (будь то загрузка CPU, или показатели работы какого-либо датчика).
Наиболее популярными и базами временных рядов являются Prometheus, InflubDB, Graphite.
Полный список из 43 СУБД для хранения временных рядов
Time Series, мультимодальная
Time Series, мультимодальная
Time Series, мультимодальная
Time Series, мультимодальная
Time Series, мультимодальная
Time Series, мультимодальная
Time Series, мультимодальная
Raima Database Manager
Alibaba Cloud TSDB
IBM Db2 Event Store
Графовые базы данных
А если вам нужно анализировать отношения данных, их связи или просто упростить запросы с километровыми Join, имеет смысл использовать графовые базы данных.
Данные и их связи представляются как вершины и ребра графа соответственно.
Таким способом можно легко представить денежные переводы (для определения различных мошеннических схем), связи в социальной сети и граф общения между операторами сотовой сети.
Чаще всего графовые базы данных используются в финансовой сфере для выявление различных мошеннических схем, но они будут удобны и для любой другой задачи, где нужно работать со связями объектов.
Наиболее известное Open Source решение, это Neo4J, но есть и ряд других качественных альтернатив.
Полный список из 39 графовых баз данных
Microsoft Azure Cosmos DB
Но анализ графа можно выполнить и с использованием других типов баз данных, к примеру key-value, как описано с статье.
Поисковые базы данных (Search Engines)
Eсли вам необходимо осуществлять поиск большим объемам данных, особенно неструктурированным, как пример поиск по нескольким терабайтами логов, то вам может пригодиться использовать базу данных, совмещающую с функционалом хранения информации еще и функционал поиска по текстам.
Представим, что у вас есть N петабайт логов (или других текстовых данных). Обычный поиск по словам уже не подойдет, чтобы осуществить поиск и аналитику в разумное время.
На помощь приходит индексирование. Если очень утрировано его рассмотреть, можно его представить следующим способом. Каждому слову/лемме/n-грамме присвоим индекс и запишем эти индексы в специальную таблицу, где строки, это документ, а в столбики это индексы. Похожая система используется для построения систем поиска плагиата, правда там чаще применяют не слова, а шинглы (индексы с наслоением).
А искать по индексу существенно быстрее, чем по совпадению по словам в документах.
Строго говоря, для поиска по документам можно использовать и эмбеддинги нейронных сетей, в которых закодирован «смысл» высказываний. Но для данной задачи лучше подойдут векторные базы данных, которые замыкают наш список.
Разумеется, современные поисковые СУБД предлагают значительно более широкий функционал.
Наиболее популярны такие решения как Elasticsearch (и его версия — OpenSearch), проприетарный Splunk, о котором я писал одну из прошлых статей и Sphinx.
Полный список из 25 поисковых СУБД
Search engine, мультимодальная
Search engine, мультимодальная
Search engine, мультимодальная
Microsoft Azure Search
Alibaba Cloud Log Service
Search engine, мультимодальная
Search engine, мультимодальная
Объектно-ориентированные базы данных
Объектно-ориентированные базы данных представляют собой базы данных, в где информация представлена в виде объектов, как в объектно-ориентированных языках программирования.
Объектно-ориентированные базы данных появились как способ нативной коммуникации кода написанного с использованием объектно-ориентированных языков с базой данных.
Объектно-ориентированные базы данных обладают следующими преимуществами:
Нет проблемы несоответствия модели данных в бд и приложении, так как в БД они сохраняются в том же виде.
Не нужно отдельно поддерживать модель данных на стороне базы данных.
Все объекты на уровне источника строго типизированы.
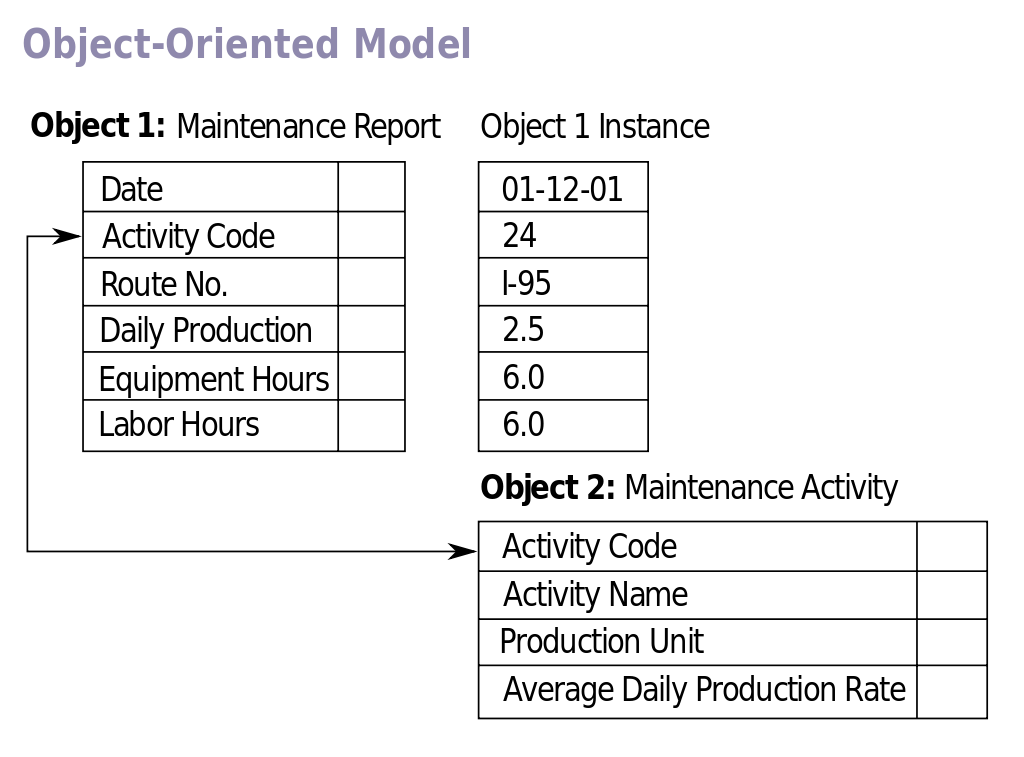
Наиболее известной объектно-ориентированной СУБД является Db4o, но есть и другие.
Полный список из 21 объектно-ориентированной СУБД
1. InterSystems Caché — мультимодальная
2. Db4o — объектно-ориентированная
3. Actian NoSQL Database — объектно-ориентированная
4. ObjectStore — объектно-ориентированная
5. Matisse — объектно-ориентированная
6. Perst — объектно-ориентированная
7. GigaSpaces — мультимодальная
8. ObjectBox — объектно-ориентированная, мультимодальная
9. ObjectDB — объектно-ориентированная
10. atoti — объектно-ориентированная
11. GemStone/S — объектно-ориентированная
12. Objectivity/DB — объектно-ориентированная
13. Starcounter — объектно-ориентированная
14. Jade — объектно-ориентированная
15. Actian Fast — объектно-ориентированная
16. Eloquera — объектно-ориентированная
17. Siaqodb — объектно-ориентированная
18. OrigoDB — мультимодальная
19. DataFS — объектно-ориентированная, мультимодальная
20. WakandaDB — объектно-ориентированная
21. VelocityDB — мультимодальная
RDF (Resource Description Framework)
RDF базы данных частично похожи на графовые базы. RDF СУБД функционируют на основе концепции формулировок утверждений, касающихся ресурсов, как выражений субъект-предикат-объект. Субъект обозначает ресурс, а предикат обозначает черты ресурса и определяет отношения между объектом и субъектом.
Вот что говорится про RDF в Википедии
Resource Description Framework (RDF, «среда описания ресурса») — это разработанная консорциумом Всемирной паутины модель для представления данных, в особенности — метаданных. RDF представляет утверждения о ресурсах в виде, пригодном для машинной обработки. RDF является частью концепции семантической паутины.
Ресурсом в RDF может быть любая сущность — как информационная (например, веб-сайт или изображение), так и неинформационная (например, человек, город или некое абстрактное понятие). Утверждение, высказываемое о ресурсе, имеет вид «субъект — предикат — объект» и называется триплетом. Утверждение «небо голубого цвета» в RDF-терминологии можно представить следующим образом: субъект — «небо», предикат — «имеет цвет», объект — «голубой». Для обозначения субъектов, отношений и объектов в RDF используются URI.
![]()
Множество RDF-утверждений образует ориентированный граф, в котором вершинами являются субъекты и объекты, а рёбра отображают отношения.
RDF сам по себе является не форматом файла, а только лишь абстрактной моделью данных, то есть описывает предлагаемую структуру, способы обработки и интерпретации данных. Для хранения и передачи информации, уложенной в модель RDF, существует целый ряд форматов записи.
Для обработки RDF-данных предлагается реализовать языки запросов: SPARQL (стандарт W3C), RQL, RDQL.”
Что из нижеперечисленного реализовано в современных субд
Заметил, что когда спрашиваешь кого-нибудь, особенно на собеседовании, какие типы СУБД существуют, то первое что вспоминают многие – это реляционные базы данных, и NoSQL, а вот про разновидности часто забывают или не могут сформулировать их отличие. Поэтому начнем с простого перечисления наиболее используемых.
Тем, кому не хочется долго читать, может сразу перейти на итоговую таблицу .
Нужно обязательно сделать ремарку, что некоторые крупные производители, имеют в своем арсенале несколько типов СУБД, как в виде отдельных продуктов, так и в виде внутренней реализации. Например, у Oracle на самом деле чего только нет, начиная с классической реляционной СУБД, продолжая с отдельным продуктом Oracle NoSQL Database, который может использоваться и как документная, и как колоночная, и как ключ-значение. Отдельное решение от того же Oracle, Autonomous Data Warehouse – это уже специализированное решение для хранилищ данных. Еще один отдельный продукт от Oracle – Oracle Graph Server для работы с графами, и еще много другого. Этому можно посвятить отдельную серию статей.
Реляционные СУБД
Начнем по порядку, классические, реляционные СУБД чаще всего используются для построения решений OLTP (Online Transaction Processing). В таких решениях СУБД работает с небольшими по размерам транзакциями, но идущими большим потоком, и при этом от системы требуется минимальное время отклика, а так же возможность, при определенных условиях, отменить любые изменения выполняемых в рамках транзакции. Если вы строите систему, в рамках которой требуется хранить значительное количество сущностей (таблиц), с различными типами связей между ними (один-к-одному, один-к-многим, многие-ко-многим), то это скорее всего про реляционные СУБД.
Наиболее известные СУБД такого типа — Oracle, Microsoft SQL, PostgreSQL, MySQL.
Когда выбирать реляционную СУБД
Один из основных признаков, который говорит о том что нужно выбирать реляционную СУБД – это высокая нормализация данных. Дополнительными признаками будет необходимость обработки большого кол-ва коротких транзакций, с большей долей операций на вставку
Когда не выбирать реляционную СУБД
Если предполагается хранить не структурируемые данные, или наоборот очень простые структуры типа ключ-значение, то лучше посмотреть в сторону документных СУБД и специализированных СУБД типа ключ-значение соответственно.
Так же один из признаков, что имеет смысл подумать не о реляционных СУБД, это такой факт как необходимость часто обновлять значения в одних и тех же строках. Обычно это обходится «дорого» в реляционных СУБД, и нужно применять «продвинутую магию» что бы делать это корректно.
Конечно, тут есть много «но», или «а если очень хочется», и других ситуаций, когда данные рекомендации можно игнорировать. Это нормально, особенно когда за дело берется эксперт, который знает как это сделать.
СУБД типа ключ-значение
Наверное один из самых простых типов СУБД. В упрощенном виде, это некая таблица с уникальным ключом и собственно связанным с ним значением, в котором может быть что угодно. Чаще всего такие СУБД используют для кэширования, т.к. они очень быстро работают, а это и не сложно, когда есть уникальный ключ, и запрос возвращает только одно значение. У некоторых представителей данных СУБД есть возможность работать полностью в памяти, а так же есть возможность задавать срок жизни записи, после истечения которого, записи будут автоматически удаляться.
Наиболее известные СУБД такого типа — Redis и Memcached.
Когда выбирать СУБД ключ-значение
Если СУБД будет использоваться для кэширования данных или для брокеров сообщений, то это очень подходящий тип. Так же, такая СУБД хорошо подходит для баз где нужно хранить достаточно простые структуры, и иметь к ним очень быстрый доступ.
Когда не выбирать СУБД ключ-значение
Если вы предполагаете хранить в базе данных много сущностей (таблиц), а у сущностей будут сложные структуры с разными типами данных. Так же, если вы предполагаете делать из этой таблицы сложные запросы которые возвращают множества строк.
Документные СУБД
Документные или документно-ориентированные СУБД — это одна из наиболее популярных разновидностей NoSQL СУБД, где основной единицей логической модели данных является документ — структурированный текст, с определенным синтаксисом.
Иногда встречаются мнения что модель данных в документных БД похожа на модель данных в объектно-ориентированных базах данных. В этом есть доля правды, единственная реальная разница между ними заключается в том, что базы данных документов только сохраняют состояние, но не поведение.
Так же, само название «документо-ориентированная» подчас вводит в заблуждение, и мне встречались коллеги, которые считали, что это база для систем документооборота. Нет, это не так.
Интересно, что документные СУБД развиваются достаточно активно, и сейчас некоторые из них, в том числе, поддерживают проверку схемы.
Известными представителями таких СУБД являются CouchDB, MongoDB, Amazon DocumentDB.
Когда выбирать документную СУБД
Если нужно хранить объекты в одной сущности, но с разной структурой. Если нужно хранит структуры, включая объекты, списки и словари, особенно в формате близкому к JSON.
На самом деле область применения документных СУБД очень широкая. Их можно использовать как компактную базу данных для отдельно взятого микро-сервиса, так и для вполне масштабных решений, в качестве хранилища состояний чего-либо.
Когда не выбирать документную СУБД
Не самое лучшее решение для реализации транзакционная модели, и точно не лучший вариант для формирования отчетности.
Графовые СУБД
Графовые СУБД — специфичный тип, предназначены для работы с графами, с их узлами, свойствами, и произвольными отношениями между узлами.
Очень простой пример, это организация связей в различного типа социальных сетях, где нужно хранить связи между пользователями (узлами) по разным критериям (родственные связи, коллеги, общие интересы).
Известные представители этого типа субд — Neo4j, Amazon Neptune, InfiniteGraph, InfoGrid.
Когда выбирать графовые СУБД
Точно стоит обратить внимание на графовые СУБД, если строите какое-то подобие социальной сети, или реализуете систему оценок и рекомендаций. Ну и во всех случаях когда вы хорошо понимаете что такое графы, и для чего это нужно.
Когда не выбирать графовые СУБД
Практически во всех остальных случаях, кроме указанных выше, лучше воздержаться от использования графовых СУБД.
Колоночные СУБД
Колоночные СУБД очень похожи на реляционные. Они так же состоят из строк, которые имеют атрибуты, а строки группируются в таблицах. Различия в логических моделях несущественные, а вот на уровне физического хранения данных различия значительные.
В реляционных СУБД данные хранятся «построчно», это означает что для считывания значения определенной колонки, придется прочитать практически всю строку, как минимум от первой до нужной колонки. В колоночной СУБД данные хранятся «поколоночно», т.е. колонка — это как отдельная таблица. Соответственно чтение будет происходить из конкретного столбца сразу. На практике это реально работает очень быстро (проверено мной на нескольких реализованных хранилищах данных).
Основные преимущества колоночных СУБД – эффективное выполнения сложных аналитических запросов на больших объемах, и легкое, практически мгновенное, изменение структуры таблиц с данными, плюс существенная компрессия и сжатие, которое позволяет значительно экономить место.
Яркие представители колоночных СУБД — Sybase IQ (ныне SAP IQ), Vertica, ClickHouse, Google BigTable, InfoBright, Cassandra.
Когда выбирать колоночные СУБД
Один из весомых аргументов за использование именно колоночной СУБД — это если вы хотите построить хранилище данных, и планируете делать выборки со сложными аналитическими вычислениями. Косвенный признак, который так же может сигнализировать о том, что имеет смысл, хотя бы посмотреть в сторону колоночных СУБД — это если количество строк, из которых делаются выборки, превышает сотни миллионов.
Когда не выбирать колоночные СУБД
Учитывая специфику колоночных СУБД, будет не эффективно ее использовать, если выборки достаточно простые, параметры выборки статичны, и если преобладают выборки по ключевым значениям. Так же, если количество строк в таблице, из которой делается выборка, меньше сотен миллионов строк, то скорее всего не будет большого преимущества, по сравнению с реляционной СУБД.
Нужно так же иметь ввиду, что в колоночных СУБД могут быть и другие ограничения. Например, может отсутствовать поддержка транзакций, а язык запросов может отличаться от классического SQL, и прочее.
Итоги
Важное замечание – не пытайтесь сразу все задачи решить в рамках одной СУБД. Это более чем нормально иметь несколько разных типов СУБД. Так же, не пытайтесь сразу определиться с производителем СУБД, или связать свою жизнь с одним конкретным брендом.
При выборе типа СУБД следует, прежде всего, исходить из типа решаемых задач, типов обрабатываемых данных, перспектив роста и масштабирования.
Обращайте так же внимание на популярность и наличие широкого круга разработчиков и средств разработки – это даст вам возможность, при необходимости, найти ответ на возникший вопрос быстро.
В данной статье я намеренно не делаю акцент на выбор между облачными и on-premise решениями — эта тема одной из следующих статей.
Итак, в таблице представленной ниже, кратко собрано то, что описано выше в статье.
Тип СУБД
Когда выбирать
Примеры популярных СУБД
Нужна транзакционность; высокая нормализация; большая доля операций на вставку
Oracle, MySQL, Microsoft SQL Server, PostgreSQL
Задачи кэширования и брокеры сообщений
Для хранения объектов в одной сущности, но с разной структурой; хранение структур на основе JSON
CouchDB, MongoDB, Amazon DocumentDB
Задачи подобные социальным сетям; системы оценок и рекомендаций
Neo4j, Amazon Neptune, InfiniteGraph, InfoGrid
Хранилища данных; выборки со сложными аналитическими вычислениями; количество строк в таблице превышает сотни миллионов
Vertica, ClickHouse, Google BigTable, Sybase \ SAP IQ, InfoBright, Cassandra
Надеюсь данная статья оказалась полезной.
В следующих статьях посмотрим на выбор между облачными и on-premise СУБД, платными и бесплатными, и многое другое.
Что из нижеперечисленного реализовано в современных субд
СУБД — это система управления базами данных. Так называют сложное программное обеспечение, которое требуется, чтобы создавать базы данных, изменять их, получать из них данные и контролировать версии.
База данных — это хранилище, где находится информация. База может принадлежать сайту, приложению, любой программе: там будут находиться сведения, связанные с работой проекта. А СУБД — это программный комплекс, который позволяет администрировать базу, защищает ее целостность и конфиденциальность сведений.

Системы управления бывают разными: различаются типы баз данных, особенности представления информации внутри базы, методы управления и языки, на которых пишутся запросы. Существуют платные и бесплатные СУБД, системы для локального или распределенного использования, предназначенные для крупных, средних или мелких проектов.
Кто пользуется СУБД
- Бэкенд-разработчики, которые часто взаимодействуют с базой, чтобы получать данные для сайта или приложения.
- Разработчики локальных приложений, которые тоже могут хранить собственные данные.
- Администраторы баз данных — если продукт сложный, то для обслуживания базы, как правило, необходим собственный администратор. Такие сотрудники обычно специализируются на конкретной СУБД.
- Другие IT-специалисты — в разных ситуациях работать с БД могут аналитики, DevOps-инженеры или специалисты по Big Data.
Для чего нужны СУБД
- Создание и хранение базы данных нужного типа — он зависит от того, к какому виду относится система.
- Управление базой — сюда относится создание новых записей, модификация существующих или удаление данных, которые уже не нужны.
- Получение нужных сведений из базы в удобной форме с помощью запросов, обычно на специальном языке SQL. Запросы фильтруют данные и выдают только нужную информациЮ, так как в базе могут быть миллионы записей. СУБД обязана поддерживать хотя бы один язык запросов.
- Администрирование и контроль доступа к базе данных, выдача разным пользователям различных прав и поддержка конфиденциальности сведений.
- Обеспечение безопасности и целостности данных, чтобы какая-либо проблема не привела к потере информации из базы.
- Защита от возможных атак и сбоев.
- Отслеживание изменений, резервное копирование и восстановление базы в случае падения.
Как информация хранится в БД
Связанные таблицы. Данные могут быть организованы по-разному в зависимости от типа базы. Чаще всего речь идет о реляционных БД — базах данных, где информация представлена в виде связанных друг с другом таблиц. Такие СУБД управляются с помощью языка запросов SQL и обычно хранят структурированные данные, между которыми есть жесткие связи.
Объекты. Объектные и объектно-реляционные БД представляют блоки информации как объект — сложную сущность с рядом свойств и методов. Объектная модель дает больше возможностей при работе с данными: у объектов есть наследование и другие свойства, которых нет у реляционных таблиц. Подробнее об этом можно прочесть в статье про объектно-ориентированный подход.
Древовидные структуры. Еще один вариант системы хранения информации — иерархический. В нем данные хранятся в виде древовидной структуры. Его расширение — сетевой тип: он отличается от иерархического тем, что данные могут иметь больше одного «предка».
Иногда частным подвидом иеархического типа называют документно-ориентированную модель, при которой данные представлены в виде JSON-подобных документов. Она более гибкая и хорошо подходит для информации, не связанной между собой. Но для жестко связанных данных такой способ не подойдет.
Из чего состоят системы управления базами данных
Если база — это хранилище, то СУБД — комплекс средств для обслуживания хранилища. СУБД имеет сложное устройство.
Ядро СУБД отвечает за главные операции: хранение базы, ее обслуживание, документирование изменений. Это основная часть системы.
Процессор языка или компилятор обрабатывает запросы. Обычно СУБД реляционного, объектно-ориентированного и объектно-реляционного типа поддерживают язык SQL и внутренние языки запросов.
Набор утилит предназначен для различных сервисных функций: их может быть очень много, а некоторые СУБД могут расширяться с помощью пользовательских модулей.

Виды СУБД по способу доступа
База данных хранится на так называемом сервере — это не обязательно отдельный компьютер, некоторые системы позволяют «поднять» сервер на конечном устройстве. Если база и все части системы находятся на одном компьютере, и ими пользуются с того же устройства, СУБД называется локальной. Если части системы находятся на разных устройствах — это распределенная СУБД.
Системы по-разному обеспечивают хранение и доступ к данным. Существуют три вида архитектуры.
Клиент-серверная. База данных находится на сервере, СУБД располагается там же. К базе могут обращаться различные клиенты — конечные устройства. Например, пользователи запрашивают информацию на конкретном сайте.
Клиент-серверная архитектура подразумевает, что прямой доступ к базе есть только у сервера — он обрабатывает обращения клиентов. Сами клиенты не обязаны иметь специальное ПО для взаимодействия с базами данных. Так для доступа к сайту не нужно устанавливать программы, которые будут обрабатывать запросы, — все сделает сервер, жестко отделенный от клиентской части.
Такие базы надежны и обычно имеют высокую доступность. Ими пользуются чаще всего.
Файл-серверная. Тут все иначе: база хранится на файл-сервере, вот СУБД — на каждом клиентском компьютере. Доступ к базе данных могут получить только устройства, на которых установлена и настроена система.
Сейчас такие системы используются очень редко, в основном во внутренних приложениях, которые работают в локальных сетях. В крупных проектах файл-серверные СУБД не применяют.
Встраиваемая. Это маленькая локальная СУБД, которая используется для хранения данных отдельной программы. Такие системы не функционируют как самостоятельные единицы, а встраиваются в программный продукт как модуль. Они нужны при разработке локальных приложений, целиком размещаются на одном устройстве и обычно очень мало весят.
Что такое NoSQL-системы
Большинство баз данных управляется специальным языком запросов SQL. Но из этого правила есть исключения — системы, которые не подразумевают использования SQL. Их называют NoSQL.
К СУБД NoSQL относят любые нереляционные системы — те, где не поддерживается реляционная модель представления информации. Некоторые нужны для хранения больших данных, другие — для ведения логов, третьи — для хранения данных с огромным количеством связей. Например, документно-ориентированные СУБД тоже относятся к NoSQL.
Вместо SQL применяются внутренние языки запросов, часто основанные на тех или иных языках программирования. Иногда они схожи с SQL, а иногда вместо внутреннего языка система использует JavaScript или иной ЯП.
Примеры современных СУБД
-
— объектно-реляционная клиент-серверная СУБД, одна из первых и самых популярных в мире. Платная, сложная, подходит для больших проектов. — объектно-реляционная СУБД клиент-серверного типа, которую иногда называют бесплатным аналогом Oracle. Масштабная, рассчитана на высоконагруженные проекты, содержит огромное количество функций и распространяется бесплатно. — реляционная клиент-серверная СУБД. Популярный выбор для проектов небольшого и среднего размера. Легкая, гибкая и довольно простая в использовании. Она бесплатная, хорошо подходит для обучения и веб-проектов. — документно-ориентированная NoSQL-СУБД, где данные хранятся в JSON-подобных файлах. Тоже бесплатная, а внутренний язык запросов основан на JavaScript. — маленькая и легкая встраиваемая СУБД, которая активно применяется в локальных проектах.
Особенности построения баз данных, тонкости работы с запросами, поддержку целостности и другие важные темы можно изучить самостоятельно с помощью учебников и мануалов, а также на курсах SkillFactory.
Системы управления базами данных
В этом подразделе приводится классификация СУБД, и рассматриваются основные их функции. В качестве основных классификационных признаков можно использовать следующие: вид программы, характер использования, модель данных. Названные признаки существенно влияют на целевой выбор СУБД и эффективность использования разрабатываемой информационной системы.
Система управления базами данных (СУБД) – это важнейший компонент АИС, основанной на базе данных. СУБД необходима для создания и поддержки базы данных информационной системы в той же степени, как для разработки программы на алгоритмическом языке – транслятор. Программные составляющие СУБД включают в себя ядро и сервисные средства (утилиты).
Ядро СУБД – это набор программных модулей, необходимый и достаточный для создания и поддержания БД, то есть универсальная часть, решающая стандартные задачи по информационному обслуживанию пользователей. Сервисные программы предоставляют пользователям ряд дополнительных возможностей и услуг, зависящих от описываемой предметной области и потребностей конкретного пользователя.
Классификация СУБД.
В общем случае под СУБД можно понимать любой программный продукт, поддерживающий процессы создания, ведения и использования БД. Рассмотрим какие из имеющихся на рынке программ имеют отношение к БД и в какой мере они связаны с базами данных.
К СУБД относятся следующие основные виды программ:
— средства разработки программ работы с БД.
Полнофункциональные СУБД (ПФСУБД) представляют собой традиционные СУБД, которые сначала появились для больших машин, затем для мини-машин и для ПЭВМ. Из числа всех СУБД современные ПФСУБД являются наиболее многочисленными и мощными по своим возможностям. К ПФСУБД относятся, например, такие пакеты как: Clarion Database Developer, DataBase, Dataplex, dBase IV, Microsoft Access, Microsoft FoxPro и Paradox R: BASE.
Обычно ПФСУБД имеют развитый интерфейс, позволяющий с помощью команд меню выполнять основные действия с БД: создавать и модифицировать структуры таблиц, вводить данные, формировать запросы, разрабатывать отчеты, выводить их на печать и т. п. Для создания запросов и отчетов не обязательно программирование, а удобно пользоваться языком QBE (Query By Example — формулировки запросов по образцу, см. подраздел 3.8). Многие ПФСУБД включают средства программирования для профессиональных разработчиков.
Некоторые системы имеют в качестве вспомогательных и дополнительные средства проектирования схем БД или CASE-подсистемы. Для обеспечения доступа к другим БД или к данным SQL-серверов полнофункциональные СУБД имеют факультативные модули.
Серверы БД предназначены для организации центров обработки данных в сетях ЭВМ. Эта группа БД в настоящее время менее многочисленна, но их количество постепенно растет. Серверы БД реализуют функции управления базами данных, запрашиваемые другими (клиентскими) программами обычно с помощью операторов SQL.
Примерами серверов БД являются следующие программы: NetWare SQL (Novell), MS SQL Server (Microsoft), InterBase (Borland), SQLBase Server (Gupta), Intelligent Database (Ingress).
В роли клиентских программ для серверов БД в общем случае могут использоваться различные программы: ПФСУБД, электронные таблицы, текстовые процессоры, программы электронной почты и т. д. При этом элементы пары «клиент — сервер» могут принадлежать одному или разным производителям программного обеспечения.
В случае, когда клиентская и серверная части выполнены одной фирмой, естественно ожидать, что распределение функций между ними выполнено рационально. В остальных случаях обычно преследуется цель обеспечения доступа к данным «любой ценой». Примером такого соединения является случай, когда одна из полнофункциональных СУБД играет роль сервера, а вторая СУБД (другого производителя) — роль клиента. Так, для сервера БД SQL Server (Microsoft) в роли клиентских (фронтальных) программ могут выступать многие СУБД, такие как: dBASE IV, Biyth Software, Paradox, DataEase, Focus, 1-2-3, MDBS III, Revelation и другие.
Средства разработки программ работы с БД могут использоваться для создания разновидностей следующих программ:
— серверов БД и их отдельных компонентов;
Программы первого и второго вида довольно малочисленны, так как предназначены, главным образом, для системных программистов. Пакетов третьего вида гораздо больше, но меньше, чем полнофункциональных СУБД.
К средствам разработки пользовательских приложений относятся системы программирования, например Clipper, разнообразные библиотеки программ для различных языков программирования, а также пакеты автоматизации разработок (в том числе систем типа клиент-сервер). В числе наиболее распространенных можно назвать следующие инструментальные системы: Delphi и Power Builder (Borland), Visual Basic (Microsoft), SILVERRUN (Computer Advisers Inc.), S-Designor (SDP и Powersoft) и ERwin (LogicWorks).
Кроме перечисленных средств, для управления данными и организации обслуживания БД используются различные дополнительные средства, к примеру, мониторы транзакций
По характеру использования СУБД делят на персональные и многопользовательские.
Персональные СУ БД обычно обеспечивают возможность создания персональных БД и недорогих приложений, работающих с ними. Персональные СУБД или разработанные с их помощью приложения зачастую могут выступать в роли клиентской части многопользовательской СУБД. К персональным СУБД, например, относятся Visual FoxPro, Paradox, Clipper, dBase, Access и др
Многопользовательские СУБД включают в себя сервер БД и клиентскую часть и, как правило, могут работать в неоднородной вычислительной среде (с разными типами ЭВМ и операционными системами). К многопользовательским СУБД относятся, например, СУБД Oracle и Informix.
По используемой модели данных СУБД (как и БД), разделяют на иерархические, сетевые, реляционные, объектно-ориентированные и другие типы. Некоторые СУБД могут одновременно поддерживать несколько моделей данных.
С точки зрения пользователя, СУБД реализует функции хранения, изменения (пополнения, редактирования и удаления) и обработки информации, а также разработки и получения различных выходных документов.
Для работы с хранящейся в базе данных информацией СУБД предоставляет программам и пользователям следующие два типа языков :
— язык описания данных — высокоуровневый непроцедурный язык декларативного типа, предназначенный для описания логической структуры данных;
— язык манипулирования данными — совокупность конструкций, обеспечивающих выполнение основных операций по работе с данными: ввод, модификацию и выборку данных по запросам.
Названные языки в различных СУБД могут иметь отличия. Наибольшее распространение получили два стандартизованных языка: QBE (Query By Example) — язык запросов по образцу и SQL (Structured Query Language) — структурированный язык запросов. QBE в основном обладает свойствами языка манипулирования данными, SQL сочетает в себе свойства языков обоих типов — описания и манипулирования данными.
Перечисленные выше функции СУБД, в свою очередь, используют следующие основные функции более низкого уровня, которые назовем низкоуровневыми:
— управление данными во внешней памяти;
— управление буферами оперативной памяти;
— ведение журнала изменений в БД;
— обеспечение целостности и безопасности БД. Дадим краткую характеристику необходимости и особенностям реализации перечисленных функций в современных СУБД.
Реализация функции управления данными во внешней памяти в разных системах может различаться и на уровне управления ресурсами (используя файловые системы ОС или непосредственное управление устройствами ПЭВМ), и по логике самих алгоритмов управления данными. В основном методы и алгоритмы управления данными являются «внутренним делом» СУБД и прямого отношения к пользователю не имеют. Качество реализации этой функции наиболее сильно влияет на эффективность работы специфических ИС, например, с огромными БД, со сложными запросами, большим объемом обработки данных.
Необходимость буферизации данных и как следствие реализации функции управления буферами оперативной памяти обусловлено тем, что объем оперативной памяти меньше объема внешней памяти.
Буферы представляют собой области оперативной памяти, предназначенные для ускорения обмена между внешней и оперативной памятью. В буферах временно хранятся фрагменты БД, данные из которых предполагается использовать при обращении к СУБД или планируется записать в базу после обработки. Механизм транзакций используется в СУБД для поддержания целостности данных в базе.
Транзакцией называется некоторая неделимая последовательность операций над данными БД, которая отслеживается СУБД от начала и до завершения. Если по каким-либо причинам (сбои и отказы оборудования, ошибки в программном обеспечении, включая приложение) транзакция остается незавершенной, то она отменяется.
Говорят, что транзакции присущи три основных свойства:
— атомарность (выполняются все входящие в транзакцию операции или ни одна);
— сериализуемость (отсутствует взаимное влияние выполняемых в одно и то же время транзакций);
— долговечность (даже крах системы не приводит к утрате результатов зафиксированной транзакции).
Примером транзакции является операция перевода денег с одного счета на другой в банковской системе. Здесь необходим, по крайней мере, двухшаговый процесс. Сначала снимают деньги с одного счета, затем добавляют их к другому счету. Если хотя бы одно из действий не выполнится успешно, результат операции окажется неверным и будет нарушен баланс между счетами.
Контроль транзакций важен в однопользовательских и в многопользовательских СУБД, где транзакции могут быть запущены параллельно. В последнем случае говорят о сериализуемости транзакций. Под сериализацией параллельно выполняемых транзакций понимается составление такого плана их выполнения (сериального плана), при котором суммарный эффект реализации транзакций эквивалентен эффекту их последовательного выполнения.
При параллельном выполнении смеси транзакций возможно возникновение конфликтов (блокировок), разрешение которых является функцией СУБД. При обнаружении таких случаев обычно производится «откат» путем отмены изменений, произведенных одной или несколькими транзакциями.
Ведение журнала изменений в БД (журнализация изменений) выполняется СУБД для обеспечения надежности хранения данных в базе при наличии аппаратных сбоев и отказов, а также ошибок в программном обеспечении.
Журнал СУБД — это особая БД или часть основной БД, непосредственно недоступная пользователю к используемая для записи информации обо всех изменениях базы данных. В различных СУБД в журнал могут заноситься записи, соответствующие изменениям в СУБД на разных уровнях: от минимальной внутренней операции модификации страницы внешней памяти до логической операции модификации БД (например, вставки записи, удаления столбца, изменения значения в поле) и даже транзакции.
Для эффективной реализации функции ведения журнала изменений в БД необходимо обеспечить повышенную надежность хранения и поддержания в рабочем состоянии самого журнала. Иногда для этого в системе хранят несколько копий журнала.
Обеспечение целостности БД составляет необходимое условие успешного функционирования БД, особенно для случая использования БД в сетях. Целостность БД, есть свойство базы данных, означающее, что в ней содержится полная, непротиворечивая и адекватно отражающая предметную область информация.
Поддержание целостности БД включает проверку целостности и ее восстановление в случае обнаружения противоречий в базе данных. Целостное состояние БД описывается с помощью ограничений целостности в виде условий, которым должны удовлетворять хранимые в базе данные. Примером таких условий может служить ограничение диапазонов возможных значений атрибутов объектов, сведения о которых хранятся в БД, или отсутствие повторяющихся записей в таблицах реляционных БД.
Обеспечение безопасности достигается в СУБД шифрованием прикладных программ, данных, защиты паролем, поддержкой уровней доступа к базе данных и к отдельным ее элементам (таблицам, формам, отчетам и т. д.).
Что из нижеперечисленного реализовано в современных субд
Понятия база данных (БД) и система управления базами данных (СУБД). Модели данных. Структура базы данных, поля и записи. Свойства полей БД. Типы данных. Режимы работы для реляционных БД. Объекты БД и их назначение. Работа с СУБД Мicrosoft Ассеss.
4.1. Основные понятия баз данных и систем управления базами данных
База данных— это организованная структура, предназначенная для хранения информации. Поскольку данные и информация — понятия взаимосвязанные, но не тождественные, следует отметить некоторое несоответствие в этом определении. Его причины чисто исторические. В те годы, когда формировалось понятие баз данных, в них действительно хранились только данные. Однако сегодня большинство систем управления базами данных позволяют размещать в своих структурах не только данные, но и методы (то есть программный код), с помощью которых происходит взаимодействие с потребителем или с другими программно-аппаратными комплексами. Таким образом, мы можем говорить, что в современных базах данных хранятся отнюдь не только данные, но и информация.
С понятием базы данных тесно связано понятие системы управления базой данных (СУБД). Это комплекс программных средств, предназначенных для создания структуры новой базы, наполнения ее содержимым, редактирования содержимого и визуализации информации. Под визуализацией информации базы понимается:
отбор отображаемых данных в соответствии с заданным критерием;
оформление и последующая выдача на устройство вывода или передача по каналам связи.
В мире существует множество СУБД. Несмотря на то, что они могут по-разному работать с разными объектами и предоставляют пользователю различные функции и средства, большинство СУБД опираются на единый устоявшийся комплекс основных понятий. Это дает нам возможность рассмотреть одну систему и обобщить ее понятия, приемы и методы на весь класс СУБД. В качестве такого учебного объекта мы выберем СУБД Мicrosoft Ассеss, входящую в пакет Мicrosoft Оffice. В тех случаях, когда конкретные приемы операций зависят от используемой версии программы, мы будем опираться на наиболее распространенную версию Мicrosoft Ассеss 2000, хотя в основном речь будет идти о таких обобщенных понятиях и методах, для которых различия между конкретными версиями программ второстепенны.
Модели данных. По способу установления связей между данными различают следующие модели данных:
Реляционная модельявляется простейшей и наиболее привычной формой представления данных в виде таблицы.
В теории множеств таблице соответствует термин отношение (relation), который и дал название модели. Для нее имеется развитый математический аппарат — реляционное исчисление и реляционная алгебра, где для баз данных (отношений) определены такие хорошо известные теоретико-множественные операции, как объединение, вычитание, пересечение, соединение и др.
Достоинством реляционной модели является сравнительная простота инструментальных средств ее поддержки, недостатком — жесткость структуры данных (например — невозможность задания строк таблицы произвольной длины) и зависимость скорости ее работы от размера БД. Для многих операций, определенных в такой модели, может оказаться необходимым просмотр всей базы.
Иерархическая и сетевая модели предполагают наличие связей между данными, имеющими какой-либо общий признак.
В иерархической моделитакие связи могут быть отражены в виде дерева-графа, где возможны только односторонние связи от старших вершин к младшим. Это облегчает доступ к необходимой информации, но только если все возможные запросы отражены в структуре дерева. Никакие иные запросы удовлетворены быть не могут.
Указанный недостаток снят в сетевой модели, где теоретически, возможны связи «всех со всеми». Поскольку на практике это, естественно, невозможно, приходится прибегать к некоторым ограничениям.
Использование иерархической и сетевой моделей ускоряет доступ к информации в БД, но поскольку каждый элемент данных должен содержать ссылки на некоторые другие элементы, требуются значительные ресурсы как дисковой, так и основной памяти ЭВМ. Недостаток основной памяти, конечно, снижает скорость обработки данных. Кроме того, для таких моделей характерна сложность реализации СУБД.
Структура простейшей базы данных
Сразу поясним, что если в базе нет никаких данных (пустая база), то это все равно полноценная база данных. Хотя данных в базе и нет, но информация в ней все-таки есть — это структура базы. Она определяет методы занесения данных и хранения их в базе. Простейший «некомпьютерный» вариант базы данных — деловой ежедневник, в котором каждому календарному дню выделено по странице. Даже если в нем не записано ни строки, он не перестает быть ежедневником, поскольку имеет структуру, четко отличающую его от записных книжек, рабочих тетрадей и прочей писчебумажной продукции.
БД могут содержать различные объекты, но, забегая вперед, скажем, что основными объектами любой базы данных являются ее таблицы. Простейшая БД имеет хотя бы одну таблицу. Соответственно, структура простейшей БД тождественно равна структуре ее таблицы.
Мы знаем, что структуру двумерной таблицы образуют столбцы и строки. Их аналогами в структуре простейшей БД являются поля и записи. Если записей в таблице пока нет, значит, ее структура образована только набором полей. Изменив состав полей базовой таблицы (или их свойства), мы изменяем структуру БД и, соответственно, получаем новую БД.
Свойства полей базы данных
Поля БД не просто определяют структуру базы — они еще определяют групповые свойства данных, записываемых в ячейки, принадлежащие каждому из полей. Ниже перечислены основные свойства полей таблиц БД на примере СУБД Мicrosoft Ассеss:
Имя поля— определяет, как следует обращаться к данным этого поля при автоматических операциях с базой (по умолчанию имена полей используются в качестве заголовков столбцов таблиц).
Тип поля— определяет тип данных, которые могут содержаться в данном поле.
Размер поля— определяет предельную длину (в символах) данных, которые могут размещаться в данном поле.
Формат поля— определяет способ форматирования данных в ячейках, принадлежащих полю.
Маска ввода— определяет форму, в которой вводятся данные в поле (средство автоматизации ввода данных).
Подпись— определяет заголовок столбца таблицы для данного поля (если подпись не указана, то в качестве заголовка столбца используется свойство Имя поля).
Значение по умолчанию— то значение, которое вводится в ячейки поля автоматически (средство автоматизации ввода данных).
Условие на значение— ограничение, используемое для проверки правильности ввода данных (средство автоматизации ввода, которое используется, как правило, для данных, имеющих числовой тип, денежный тип или тип даты).
Сообщение об ошибке— текстовое сообщение, которое выдается автоматически при попытке ввода в поле ошибочных данных (проверка ошибочности выполняется автоматически, если задано свойство Условие на значение).
Обязательное поле— свойство, определяющее обязательность заполнения данного поля при наполнении базы;
Пустые строки— свойство, разрешающее ввод пустых строковых данных (от свойства Обязательное поле отличается тем, что относится не ко всем типам данных, а лишь к некоторым, например к текстовым).
Индексированное поле— если поле обладает этим свойством, все операции, связанные с поиском или сортировкой записей по значению, хранящемуся в данном поле, существенно ускоряются. Кроме того, для индексированных полей можно сделать так, что значения в записях будут проверяться по тому полю на наличие повторов, что позволяет автоматически исключить дублирование данных.
Следует обратить внимание на то, что поскольку в разных полях могут содержаться данные разного типа, то и свойства у полей могут различаться в зависимости от типа данных. Так, например, список вышеуказанных свойств полей относится в основном к полям текстового типа. Поля других типов могут иметь или не иметь эти свойства, но могут добавлять к ним и свои. Например, для данных, представляющих действительные числа, важным свойством является количество знаков после десятичной запятой. С другой стороны, для полей, используемых для хранения рисунков, звукозаписей, видеоклипов и других объектов ОLЕ, большинство вышеуказанных свойств не имеют смысла.
Типы данных
С основными типами данныхмы уже знакомы. Так, например, при изучении электронных таблиц Мicrosoft Ехсеl мы видели, что они работают с тремя типами данных: текстами, числами и формулами. Таблицы БД, как правило, допускают работу с гораздо большим количеством разных типов данных. БД Мicrosoft Ассеss работают с типами данных, которые представлены в таблице 4.1.
Таблица 4.1. Типы данных СУБД Мicrosoft Ассеss
Название типа
Тип данных, используемый для хранения обычного неформатированного текста ограниченного размера (до 255 символов).
Специальный тип данных для хранения больших объемов текста (до 65 535 символов). Физически текст не хранится в поле. Он хранится в другом месте базы данных, а в поле хранится указатель на него.
Тип данных для хранения действительных чисел.
Тип данных для хранения календарных дат и текущего времени.
Тип данных для хранения денежных сумм.
Специальный тип данных для уникальных (не повторяющихся в поле) натуральных чисел с автоматическим наращиванием. Естественное использование — для порядковой нумерации записей.
Величины, способные принимать только два значения, да/нет или 1/0.
OLE Object (Поле объекта OLE)
Поля, позволяющие вставлять рисунки, звуки и данные других полей.
Ссылки, дающие возможность открывать объект Мicrosoft Access (таблицу, запрос…), файл другого приложения или Web-страницу.
1.3. Системы управления базами данных
В этом подразделе приводится классификация СУБД и рассматриваются основные их функции. В качестве основных классификационных признаков можно использовать следующие: вид программы, характер использования, модель данных. Названные признаки существенно влияют на целевой выбор СУБД и эффективность использования разрабатываемой информационной системы.
Классификация СУБД. В общем случае под СУБД можно понимать любой программный продукт, поддерживающий процессы создания, ведения и использования БД. Рассмотрим, какие из имеющихся на рынке программ имеют отношение к БД и в какой мере они связаны с базами данных.
К СУБД относятся следующие основные виды программ:
средства разработки программ работы с БД.
Полнофункциональные СУБД (ПФСУБД) представляют собой традиционные СУБД, которые сначала появились для больших машин, затем для мини-машин и для ПЭВМ. Из числа всех СУБД современные ПФСУБД являются наиболее многочисленными и мощными по своим возможностям. К ПФСУБД относятся, например, такие пакеты, как Clarion Database Developer, DataEase, DataFlex, dBase IV, Microsoft Access, Microsoft FoxPro и Paradox R:BASE.
Обычно ПФСУБД имеют развитый интерфейс, позволяющий с помощью команд меню выполнять основные действия с БД: создавать и модифицировать структуры таблиц, вводить данные, формировать запросы, разрабатывать отчеты, выводить их на печать и т. п. Для создания запросов и отчетов не обязательно программирование, а удобно пользоваться языком QBE (Query By Example — формулировки запросов по образцу, см. подраздел 3.8). Многие ПФСУБД включают средства программирования для профессиональных разработчиков.
Некоторые системы имеют в качестве вспомогательных и дополнительные средства проектирования схем БД или CASE-подсистемы. Для обеспечения доступа к другим БД или к данным SQL-серверов полнофункциональные СУБД имеют факультативные модули.
Серверы БД предназначены для организации центров обработки данных в сетях ЭВМ. Эта группа БД в настоящее время менее многочисленна, но их количество постепенно растет. Серверы БД реализуют функции управления базами данных, запрашиваемые другими (клиентскими) программами обычно с помощью операторов SQL.
Примерами серверов БД являются следующие программы: NetWare SQL (Novell), MS SQL Server (Microsoft), InterBase (Borland), SQLBase Server (Gupta), Intelligent Database (Ingress).
В роли клиентских программ для серверов БД в общем случае могут использоваться различные программы: ПФСУБД, электронные таблицы, текстовые процессоры, программы электронной почты и т. д. При этом элементы пары «клиент — сервер» могут принадлежать одному или разным производителям программного обеспечения.
В случае, когда клиентская и серверная части выполнены одной фирмой, естественно ожидать, что распределение функций между ними выполнено рационально. В остальных случаях обычно преследуется цель обеспечения доступа к данным «любой ценой». Примером такого соединения является случай, когда одна из полнофункциональных СУБД играет роль сервера, а вторая СУБД (другого производителя) — роль клиента. Так, для сервера БД SQL Server (Microsoft) в роли клиентских (фронтальных) программ могут выступать многие СУБД, такие как dBASE IV, Blyth Software, Paradox, DataEase, Focus, 1-2-3, MDBS III, Revelation и другие.
Средства разработки программ работы с БД могут использоваться для создания разновидностей следующих программ:
серверов БД и их отдельных компонентов;
Программы первого и второго вида довольно малочисленны, так как предназначены, главным образом, для системных программистов. Пакетов третьего вида гораздо больше, но меньше, чем полнофункциональных СУБД.
К средствам разработки пользовательских приложений относятся системы программирования, например Clipper, разнообразные библиотеки программ для различных языков программирования, а также пакеты автоматизации разработок (в том числе систем типа клиент-сервер). В числе наиболее распространенных можно назвать следующие инструментальные системы: Delphi и Power Builder (Borland), Visual Studio (Microsoft), SILVERRUN (Computer Advisers Inc.), S-Designor (SDP и Powersoft) и ERwin (LogicWorks).
Если говорить о конкретных системах программирования (для языков C++, С#, Visual Basic, Java и др.), то все они содержат некоторые средства доступа к наиболее широко используемым БД.
Кроме перечисленных средств, для управления данными и организации обслуживания БД используются различные дополнительные средства, к примеру мониторы транзакций (см. подраздел 4.2).
По характеру использования СУБД делят на персональные и многопользовательские.
Персональные СУБД обычно обеспечивают возможность создания персональных БД и недорогих приложений, работающих с ними. Персональные СУБД или разработанные с их помощью приложения зачастую могут выступать в роли клиентской части многопользовательской СУБД. К персональным СУБД, например, относятся Visual FoxPro, Paradox, Clipper, dBase, Access и др.
Многопользовательские СУБД включают в себя сервер БД и клиентскую часть и, как правило, могут работать в неоднородной вычислительной среде (с разными типами ЭВМ и операционными системами). К многопользовательским СУБД относятся, например, СУБД Oracle и Informix.
В зависимости от способа хранения и обработки БД (централизованного или децентрализованного) СУБД можно разделить на два класса: централизованные (или обычные) СУБД и децентрализованные (или распределенные) СУБД. В обычных СУБД данные хранятся в том же месте, где и программы их управления. В распределенных СУБД как программное обеспечение, так и данные распределены по узлам сети. Распределенные СУБД могут быть однородными или неоднородными. Неоднородность СУБД может проявляться в отличии поддерживаемых модели данных, типов данных, языков запросов, фирм-разработчиков и т. д.
Одной из разновидностей распределенных СУБД являются мультибазовые системы, в которых управление каждым из узлов осуществляется автономно. В мультибазовых СУБД производится такая интеграция локальных систем, при которой не требуется изменение существующих СУБД и в то же время конечным пользователям предоставляется доступ к совместно используемым данным. Пользователи локальных СУБД получают возможность управлять данными собственных узлов без централизованного контроля, который присутствует в обычных распределенных СУБД. Примером мультибазовой СУБД является система UniSQL компании Cincom Corporation.
В зависимости от возможности распараллеливания процесса обработки данных выделяют СУБД с последовательной и параллельной обработкой (параллельные СУБД). Параллельные СУБД функционируют в многопроцессорной вычислительной системе (как правило, со множеством устройств хранения данных) или в сети компьютеров.
По используемой модели данных СУБД (как и БД), разделяют на иерархические, сетевые, реляционные, объектно-ориентированные и другие типы. Некоторые СУБД могут одновременно поддерживать несколько моделей данных.
С точки зрения пользователя, СУБД реализует функции хранения, изменения (пополнения, редактирования и удаления) и обработки информации, а также разработки и получения различных выходных документов.
Для работы с хранящейся в базе данных информацией СУБД предоставляет программам и пользователям следующие два типа языков:
язык описания данных — высокоуровневый непроцедурный язык декларативного типа, предназначенный для описания логической структуры данных;
язык манипулирования данными — совокупность конструкций, обеспечивающих выполнение основных операций по работе с данными: ввод, модификацию и выборку данных по запросам.
Названные языки в различных СУБД могут иметь отличия. Наибольшее распространение получили два стандартизованных языка: QBE (Query By Example) — язык запросов по образцу и SQL (Structured Query Language) — структурированный язык запросов. QBE в основном обладает свойствами языка манипулирования данными, SQL сочетает в себе свойства языков обоих типов — описания и манипулирования данными.
Перечисленные выше функции СУБД, в свою очередь, используют следующие основные функции более низкого уровня, которые назовем низкоуровневыми:
управление данными во внешней памяти;
управление буферами оперативной памяти;
ведение журнала изменений в БД;
обеспечение целостности и безопасности БД.
Дадим краткую характеристику необходимости и особенностям реализации перечисленных функций в современных СУБД.
Реализация функции управления данными во внешней памяти в разных системах может различаться и на уровне управления ресурсами (используя файловые системы ОС или непосредственное управление устройствами ПЭВМ), и по логике самих алгоритмов управления данными. В основном методы и алгоритмы управления данными являются «внутренним делом» СУБД и прямого отношения к пользователю не имеют. Качество реализации этой функции наиболее сильно влияет на эффективность работы специфических ИС, например, с огромными БД, со сложными запросами, большим объемом обработки данных.
Необходимость буферизации данных и как следствие реализации функции управления буферами оперативной памяти обусловлено тем, что объем оперативной памяти меньше объема внешней памяти.
Буферы представляют собой области оперативной памяти, предназначенные для ускорения обмена между внешней и оперативной памятью. В буферах временно хранятся фрагменты БД, данные из которых предполагается использовать при обращении к СУБД или планируется записать в базу после обработки.
Механизм транзакций используется в СУБД для поддержания целостности данных в базе. Транзакцией называется некоторая неделимая последовательность операций над данными БД, которая отслеживается СУБД от начала и до завершения. Если по каким-либо причинам (сбои и отказы оборудования, ошибки в программном обеспечении, включая приложение) транзакция остается незавершенной, то она отменяется.
В зависимости от времени, требуемого для выполнения, выделяют обычные и продолжительные транзакции. Продолжительные транзакции могут охватывать часы, дни и даже месяцы. Такие транзакции могут возникать в процессе проектирования и разработки сложных систем крупным коллективом людей. Кроме того, помимо обычных плоских транзакций, используется модель вложенных транзакций. В последнем случае транзакция рассматривается как набор взаимосвязанных подзадач (субтранзакций), каждая из которых также может состоять из произвольного количества субтранзакций.
Говорят, что транзакции присущи три основных свойства:
атомарность (выполняются все входящие в транзакцию операции или ни одна);
серализуемость (отсутствует взаимное влияние выполняемых в одно и то же время транзакций);
долговечность (даже крах системы не приводит к утрате результатов зафиксированной транзакции).
Примером транзакции является операция перевода денег с одного счета на другой в банковской системе. Здесь необходим, по крайней мере, двухшаговый процесс. Сначала снимают деньги с одного счета, затем добавляют их к другому счету. Если хотя бы одно из действий не выполнится успешно, результат операции окажется неверным и будет нарушен баланс между счетами.
Контроль транзакций важен в однопользовательских и в многопользовательских СУБД, где транзакции могут быть запущены параллельно. В последнем случае говорят о сериализуемости транзакций. Под сершлизацией параллельно выполняемых транзакций понимается составление такого плана их выполнения (сериального плана), при котором суммарный эффект реализации транзакций эквивалентен эффекту их последовательного выполнения.
При параллельном выполнении смеси транзакций возможно возникновение конфликтов (блокировок), разрешение которых является функцией СУБД. При обнаружении таких случаев обычно производится «откат» путем отмены изменений, произведенных одной или несколькими транзакциями.
Ведение журнала изменений в БД (журнализация изменений) выполняется СУБД для обеспечения надежности хранения данных в базе при наличии аппаратных сбоев и отказов, а также ошибок в программном обеспечении.
Журнал СУБД — это особая БД или часть основной БД, непосредственно недоступная пользователю и используемая для записи информации обо всех изменениях базы данных. В различных СУБД в журнал могут заноситься записи, соответствующие изменениям в СУБД на разных уровнях: от минимальной внутренней операции модификации страницы внешней памяти до логической операции модификации БД (например, вставки записи, удаления столбца, изменения значения в поле) и даже транзакции.
Для эффективной реализации функции ведения журнала изменений в БД необходимо обеспечить повышенную надежность хранения и поддержания в рабочем состоянии самого журнала. Иногда для этого в системе хранят несколько копий журнала.
Обеспечение целостности БД составляет необходимое условие успешного функционирования БД, особенно для случая использования БД в сетях. Целостность БД есть свойство базы данных, означающее, что в ней содержится полная, непротиворечивая и адекватно отражающая предметную область информация. Поддержание целостности БД включает проверку целостности и ее восстановление в случае обнаружения противоречий в базе данных. Целостное состояние БД описывается с помощью ограничений целостности в виде условий, которым должны удовлетворять хранимые в базе данные. Примером таких условий может служить ограничение диапазонов возможных значений атрибутов объектов, сведения о которых хранятся в БД, или отсутствие повторяющихся записей в таблицах реляционных БД.
Обеспечение безопасности достигается в СУБД шифрованием прикладных программ, данных, защиты паролем, поддержкой уровней доступа к базе данных и к отдельным ее элементам (таблицам, формам, отчетам и т. д.).
Что из нижеперечисленного реализовано в современных субд
Систе́ма управле́ния ба́зами да́нных (СУБД) — специализированная программа (чаще комплекс программ), предназначенная для организации и ведения базы данных. Для создания и управления информационной системой СУБД необходима в той же степени, как для разработки программы на алгоритмическом языке необходим транслятор.
Содержание
Основные функции СУБД
- управление данными во внешней памяти (на дисках);
- управление данными в оперативной памяти с использованием дискового кэша; , резервное копирование и восстановление базы данных после сбоев;
- поддержка языков БД (язык определения данных, язык манипулирования данными).
Обычно современная СУБД содержит следующие компоненты:
- ядро, которое отвечает за управление данными во внешней и оперативной памяти и журнализацию,
- процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода,
- подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД
- а также сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
Классификация СУБД
По модели данных
По типу управляемой базы данных СУБД разделяются на:
По архитектуре организации хранения данных
- локальные СУБД (все части локальной СУБД размещаются на одном компьютере)
- распределенные СУБД (части СУБД могут размещаться на двух и более компьютерах)
По способу доступа к БД
- Файл-серверные
В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. Ядро СУБД располагается на каждом клиентском компьютере. Доступ к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на ЦП сервера, а недостатком — высокая загрузка локальной сети.
На данный момент файл-серверные СУБД считаются устаревшими.
Примеры: Microsoft Access, Borland Paradox.
Такие СУБД состоят из клиентской части (которая входит в состав прикладной программы) и сервера (см. Клиент-сервер). Клиент-серверные СУБД, в отличие от файл-серверных, обеспечивают разграничение доступа между пользователями и мало загружают сеть и клиентские машины. Сервер является внешней по отношению к клиенту программой, и по надобности его можно заменить другим. Недостаток клиент-серверных СУБД в самом факте существования сервера (что плохо для локальных программ — в них удобнее встраиваемые СУБД) и больших вычислительных ресурсах, потребляемых сервером.
Примеры: Interbase, IBM DB2, MS SQL Server, Oracle, MySQL, ЛИНТЕР.
- Встраиваемые
Встраиваемая СУБД — библиотека, которая позволяет унифицированным образом хранить большие объёмы данных на локальной машине. Доступ к данным может происходить через геоинформационные системы).
Ссылки
Русскоязычные сайты
Зарубежные сайты
Литература
- К. Дж. Дейт Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: «Вильямс», 2006. — С. 1328. — ISBN 0-321-19784-4
См. также
DDL, SELECT | INSERT | UPDATE | MERGE | DELETE | JOIN | UNION | CREATE | ALTER | DROP
Сравнение синтаксиса
Типы реализаций
Flat file | Deductive | Dimensional | Иерархическая | Объектно-ориентированная | Temporal
Свободные системы
Ingres | PostgreSQL | Sav Zigzag |
Wikimedia Foundation . 2010 .
Полезное
Смотреть что такое «СУБД» в других словарях:
СУБД — система управления базой данных система управления базами данных Словари: Словарь сокращений и аббревиатур армии и спецслужб. Сост. А. А. Щелоков. М.: ООО «Издательство АСТ», ЗАО «Издательский дом Гелеос», 2003. 318 с., С. Фадеев. Словарь… … Словарь сокращений и аббревиатур
субд — сущ., кол во синонимов: 1 • система (86) Словарь синонимов ASIS. В.Н. Тришин. 2013 … Словарь синонимов
СУБД — абревіатура система управління базами даних незмінювана словникова одиниця … Орфографічний словник української мови
СУБД с непосредственной записью — СУБД с непосредственной записью это система управления базами данных (СУБД), в которых все измененные блоки данных незамедлительно записываются во внешнюю память при поступлении сигнала подтверждения любой транзакции. Такая стратегия… … Википедия
СУБД-приложение — Программа, обеспечивающая пользователю доступ к данным БД. [http://www.morepc.ru/dict/] Тематики информационные технологии в целом EN database application … Справочник технического переводчика
СУБД с отложенной записью — Эту статью следует викифицировать. Пожалуйста, оформите её согласно правилам оформления статей. СУБД с отложенной записью это система управления базами данных (СУБД), в которых изменения аккумулируются в … Википедия
СУБД Progress — Progress промышленная база данных, разрабатываемая компанией Progress Software. Поддерживаемые платформы Version 9.0A (доступна с декабря 1998): AIX (32 разрядная), IBM AS/400, Sun Solaris на Windows NT на Windows 32 Intel (client), Citrix… … Википедия
СУБД — компьют. система управления базами данных database management system (DBMS) … Универсальный дополнительный практический толковый словарь И. Мостицкого
СУБД — система управления базами данных … Словарь сокращений русского языка
субдіафрагмальний — а, е. Такий, що розміщений під діафрагмою; піддіафрагмальний … Український тлумачний словник
Реляционные и нереляционные базы данных: какие выбрать?
Сегодня хотим обсудить «вечную» тему нынешнего века – эффективное и надёжное хранение данных. По исследованиям некоторых учёных, в год человечество генерирует данных больше, чем вся цивилизация с древнейших времён и до начала нашего столетия.
Куда нам столько и что делать с этой информацией? Кроме того, при таких объёмах встаёт вопрос не только хранения, но и извлечения данных. Поэтому мы решили вспомнить, какие способы для этого существуют и какой из них выбрать. Итак, начнём.

Эпоха электричества ознаменовала появление нового класса машин – компьютеров, которые позволили обрабатывать и хранить большое количество информации, ранее недоступное человеку.
Существенной вехой в истории развития вычислительных машин является появление категории «файлов».

Источник фото: http://risovach.ru/upload/2013/11/mem/my-ustanovili-tebe_36186411_orig_.jpeg
Если рассмотреть понятие файла, оно заключается в том, что это некоторая область на устройстве хранения информации, имеющая своё название, из которой можно считывать данные и в которую их можно записывать.
Шестидесятые годы XX века являются рубежом, с которого начинается использование компьютеров не только в качестве исполнителей счётных задач, но и для обработки документов.
Для реализации вышеозначенной задачи требуется ввести новое понятие, так называемую «базу данных», суть которой сводится к некоторой совокупности организованно хранящейся информации.
Структура базы данных предполагает также взаимодействие между составляющими её различными элементами. Именно потребность в необходимости оперирования файлами привела к появлению надстройки над операционной системой – системы управления базами данных.
В этой статье мы рассмотрим системы управления базами данных, а также узнаем, что же представляют собой реляционные и нереляционные базы и в чём заключаются их особенности.
Ниже мы собрали список
основных пунктов, чтобы вам было проще ориентироваться по статье:
Программное обеспечение для работы с современными базами данных
В специализированной программе, которая использует для своего функционирования файл или файлы, за полноту и достоверность содержащихся данных обычно отвечал один человек. С появлением же потребности в использовании базы данных многими пользователями и многими специализированными программами появилась необходимость в отделении собственно хранения данных от самих прикладных программ, одновременно с необходимостью ведения их c требующимися полнотой, внесением нужных изменений и безопасностью.
Именно с этого момента начинает работу специализированный посредник, который берёт на себя функцию взаимодействия между конкретной прикладной программой и базой данных. Этот посредник получил название «система управления базами данных», или сокращенно ― СУБД.
СУБД представляет собой специальную программу, имеющую основной своей функцией создание, изменение и ведение базы данных некоторой совокупностью пользователей через прикладные программы.
Основные функции программного обеспечения баз данных
Создание изначальной структуры базы данных;
СУБД создаёт структуру базы данных в виде диалога, то есть последовательно получает от пользователя требующиеся ей данные. После чего производится начальное создание базы данных;
Возможность модифицирования данных пользователем. Дальнейшая работа с базой данных через СУБД позволяет пользователям вносить новые данные, стирать их, производить различные выборки. Такие возможности даёт специальный язык программирования, графический интерфейс пользователя;
Независимость прикладных программ от базы данных. Это позволяет изменять в некоторых пределах логическое представление базы данных, не меняя сам способ хранения; в то же время это позволяет производить некоторые изменения в базе данных, не вызывая необходимости поменять представление данных;
Логическое единство базы данных. СУБД не позволит ввести цифру вместо буквы, неправильную дату и т. д.;
Защита от повреждений в случае неправильного функционирования или повреждения ЭВМ – современные СУБД имеют средства резервного восстановления базы;
Разграничение доступа пользователей в зависимости от категории. Современные СУБД имеют средства контроля доступа, которые позволяют пользователям иметь доступ только к тем данным, к которым они имеют право;
Обеспечение одновременной работы нескольких пользователей. СУБД предоставляет средства одновременной работы, которые защищают целостность базы с помощью различных блокировок;
Управление хранением. Так как база данных располагается в памяти компьютера, при работе с ней происходит освобождение определённых блоков и заполнение других. СУБД производит рациональное управление местом хранения;
Поддержка деятельности администратора. Так как в процессе работы СУБД может потребоваться ввод новых данных технического типа: новое разграничение доступа, изменение структуры и т. д. СУБД предоставляет удобные средства, которые позволяют администратору производить все эти действия.
Преимущества и недостатки СУБД
отслеживание отсутствия избыточности и согласованности данных;
использование данных многими пользователями;
сохранение структуры данных, то есть их целостности;
увеличение эффекта от использования системы управления данными с ростом масштаба (т. е. ярко выраженный эффект масштаба);
доступ к большим данным и их постоянная готовность к работе;
повышение производительности работы;
облегчение обслуживания системы, так как нет критической зависимости от какого-либо конкретного типа данных.
Но, несмотря на все ярко выраженные преимущества пользования системами управления базами данных, этот процесс также содержит определённый ряд сложностей, которые встают на пути.

Источник фото: https://www.meme-arsenal.com/memes/49744a3f286732121b18344f96748312.jpg
Среди них можно перечислить:
общее большое усложнение всей системы;
материальное обеспечение (аппаратное);
большие материальные затраты при сбое системы.
Реляционные базы данных
В последнее время большое распространение получила «реляционная модель», суть которой заключается в том, что основанная на математической теории множеств она рассматривает таблицы как отдельные множества, объединённые по определённому признаку, как показано на рисунке 1.
Рисунок 1 – Операция над таблицами (реляционная модель)
Для удобства представления и хранения система хранения данных в рамках реляционной модели обычно представляет собой совокупность таблиц, взаимосвязанных между собой определённым образом.
Таблица представляет собой плоскую двумерную сетку, которая содержит определённый тип или типы структурированных данных, например фильмы, группы крови, маршруты движения и т. д.
Если разбирать дальнейшее устройство любой таблицы, то она состоит из столбцов и строк.
Столбец таблицы представляет собой вертикальную область, выделенное свойство всех типологий, которые содержатся обычно в строках таблицы.
Строка таблицы представляет собой горизонтальную область, которая уникализирует типологию. Например, в строках таблицы могут содержаться фамилии, марки автомобилей, названия улиц и т. д.
Структурные элементы таблицы, из которых она состоит, взаимодействуют между собой, а также с другими структурными элементами других таблиц.
С ростом количества информации появилась необходимость в специальном языке, который бы оперировал данными и мог функционировать в абсолютно различающихся компьютерных системах таким образом, чтобы пользователи могли оперировать данными, составляя определённые запросы.
Отвечая на запросы времени, появился определённый язык, который получил название SQL – Structured Query Language (язык структурированных запросов), он был выпущен в 1986 году и к нынешнему времени фактически стал стандартом.
В качестве основных форм языка SQL можно назвать следующие:
Суть интерактивного SQL заключается в том, что пользователь базы данных может в интерактивном режиме использовать SQL-операторы.
Встроенный SQL позволяет интегрировать его операторы в код программы; в свою очередь, динамическая форма позволяет на лету генерировать операторы в процессе выполнения программ.
В отличие от перечисленных выше, статический представляет собой заранее определённые операторы в момент компиляции программы.
Если же говорить о достоинствах языка SQL, то среди них можно перечислить следующие:
переносимость между различными платформами;
поддержка компанией IBM;
поддержка компанией Microsoft;
основан на реляционных принципах;
может исполнять запросы интерактивно;
может давать доступ к базам данных через программы;
предоставляет все средства языка для удобного доступа к базам данных;
поддержка различных архитектур;
наличие доступа к данным через сеть Интернет;
интегрированность с языком Java.
Системы управления базами данных могут работать как в качестве серверной части, то есть реализовывать архитектуру «клиент-сервер», так и в виде настольной версии, то есть СУБД, работающей локально.
Серверная система управления базами данных занимается хранением и поддержкой, а также отвечает на поступающие от клиентов запросы.
Под клиентами подразумеваются любые компьютеры или приложения, которые обращаются к базе данных, используя специальный язык обращений.
Причём если мы говорим об архитектуре «клиент-сервер», то клиент может даже находиться в одной стране, а сервер – в другой. Здесь под клиентом понимается обычный компьютер, а под сервером – специализированная машина, достаточно мощная, чтобы хранить базы и обрабатывать множество запросов.
В качестве главного отличия любой настольной СУБД от серверной можно назвать то, что она работает локально и не может обрабатывать запросы, поступающие от других клиентов.
Если перечислить основные виды известных SQL-серверов, то среди них можно назвать: Microsoft SQL Server, Oracle, MySQL, Postgresql.
В свою очередь, системой, поддерживающей SQL и являющейся настольной, можно назвать Microsoft Access.
Нереляционные базы данных
Кроме традиционных баз (SQL), существует ещё другой способ хранения данных, получивший широкое распространение со второй половины двухтысячных годов, – нереляционные базы данных. Они отличаются от реляционных тем, что в них для хранения используется не система из строк и столбцов, а применяется модель, которая оптимизирована для хранения определённого типа содержимого. Например, данные могут храниться в виде документов JSON, графов, а также ключей-значений.
Кроме того, можно сказать, что нереляционные базы данных не используют язык запросов SQL, и вместо него запросы осуществляются с помощью иных языков и конструкций. Ниже рассмотрим, какие типы NoSQL баз данных бывают.
Такой тип оперирует набором данных объекта, которые называются документом. Они хранятся в полях, которые могут быть представлены различными форматами, среди которых можно назвать такие, как XML, JSON и т. д. Набор данных и их полнота зависят от целей конкретного применения.
Причём здесь важным моментом является то, что в отличие от реляционной модели хранения, где данные одного объекта могут быть распределены по разным таблицам, здесь они хранятся в одном документе, и этот тип хранения не требует, чтобы все документы имели одинаковую структуру, благодаря чему и достигается достаточно большая гибкость.
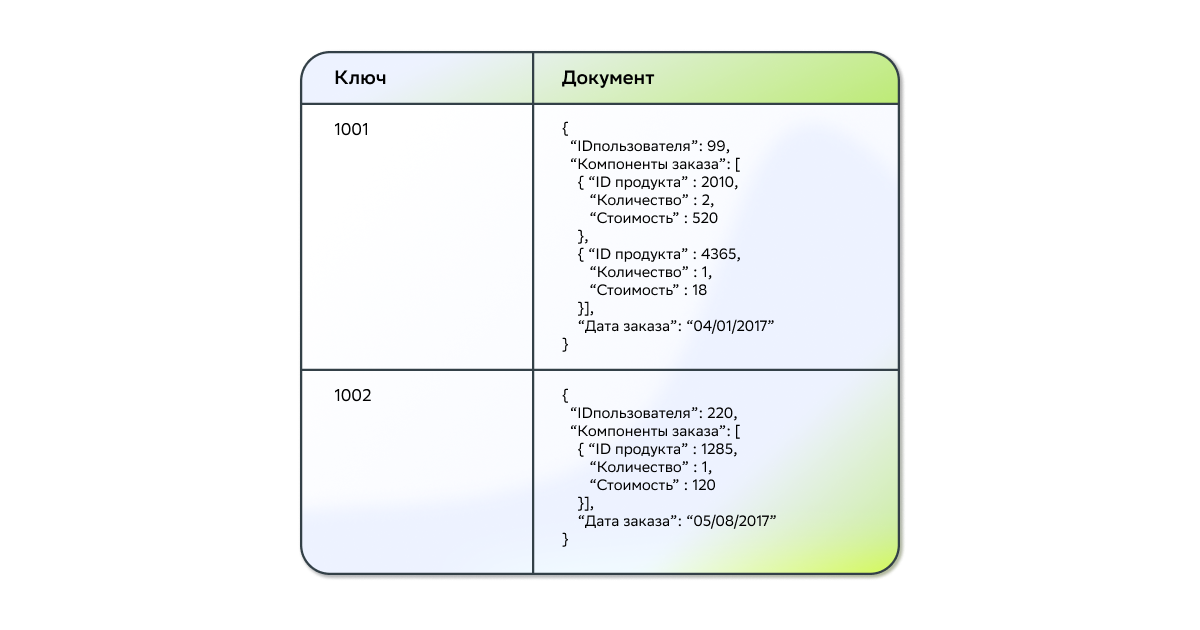
Для получения документов используется ключ документа, который представляет собой уникальную идентифицирующую сущность, благодаря которой можно получить доступ к конкретному документу.
Хранение данных в столбцах
Подобный тип хранения по своему виду очень сильно похож на реляционную базу данных – данные хранятся в столбцах, которые связаны и управляются как единое целое. В отличие от других типов хранения данных, при этой методике упорядочение данных происходит с помощью ключей, а не хэшей.
Хранение в виде «ключи-значения»
При таком способе хранения данные находятся в большой таблице, каждый набор данных обладает уникальным ключом. Подобный тип хранения можно использовать для применений, где используется поиск по ключам или диапазону ключей, но в то же время подобный тип хранения неудобен, если требуется осуществлять поиск и фильтрацию по значениям.
Хранилища содержимого графов
Данный тип хранилища представляет собой хранение данных, содержащихся в узлах, а также определяет связь между узлами. Подобные хранилища позволяют достаточно оперативно выполнять запросы, которые проходят через ряд узлов и рёбер, и производить анализ взаимосвязей между узлами.

Такие структуры позволяют производить поиск, например, «всех сотрудников, работающих в определённом отделе» либо «находящихся в подчинении определённого руководителя» и т. д.
Хранилища данных временных рядов
Этот тип хранилища используется для наборов значений, которые обладают небольшим весом и привязаны к определённым моментам времени. Обычно это данные телеметрии, например датчика или датчиков интернета вещей.
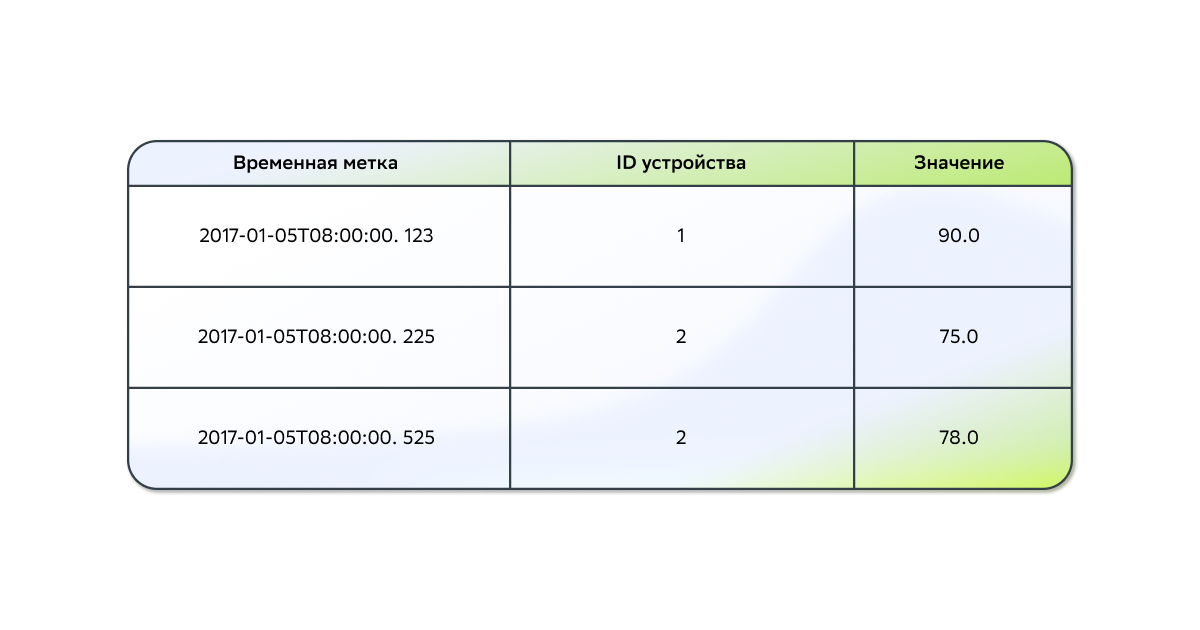
Подобного типа хранилища используются для сохранения и извлечения данных большого веса, в качестве которых могут выступать видеофайлы, изображения, файлы приложений и т. д. Само хранилище обладает, как правило, также достаточно большим объёмом, что позволяет ему хранить подобное содержимое.

Хранилище внешних индексов
Используется для индексированных данных других хранилищ, то есть подобный тип хранилища выступает в роли посредника, который ускоряет доступ к другим базам.
Как выбрать тип базы?
Как правило, реляционные базы выбирают для работы со сложными запросами и обработки рутинных задач. И здесь следует учесть вот что: SQL-базы масштабируются по вертикали, то есть с помощью увеличения нагрузки на отдельный конкретный сервер. В свою очередь, NoSQL-базы хорошо масштабируются по горизонтали за счёт увеличения количества серверов, что является весьма удобным при работе с большими объёмами данных, так называемыми Big Data.
Ещё одним интересным плюсом NoSQL является возможность хранения коллекций с различными атрибутами и полями, что позволяет за счёт отсутствия жёстких ограничений реализовывать поэтапную разработку. Также нереляционные базы хорошо справляются с задачами хранения недостаточно структурированных или же абсолютно неструктурированных данных.
Так как нереляционные базы, как правило, предназначены для доступа к ним с помощью конкретных шаблонов, они позволяют добиться более высоких показателей производительности, если сравнивать их с SQL-базами.
Среди некоторых из популярных нереляционных баз можно перечислить: MongoDB, Apache Cassandra, Couchbase.
Заключение
Компьютерная сфера вообще и технологии хранения данных в частности – это одна из тех сфер, которые претерпевают постоянные и очень быстрые изменения.
Сейчас, кроме реляционного способа хранения данных, появляются и развиваются и нереляционные способы, так называемые NoSQL. Потенциально данный способ при соответствующем подходе может дать большую производительность ввиду существенных отличий от реляционного подхода.
Нельзя дать однозначный ответ на вопрос, какой из типов баз является лучшим. Скорее следует руководствоваться комплексом нужных вам параметров: скорость доступа, тип данных, способ будущего масштабирования, наличие персонала, способного работать с этим типом баз и т. д.
В целом, для обеспечения эффективности могут быть выделены три основные составляющие:
хранение данных должно происходить распределённо, то есть внутри сети, которая состоит из нескольких ЭВМ, несмотря на то, что сами файлы могут быть достаточно большими;
необходимо создать такую схему хранения данных, которая обеспечит существенные преимущества по сравнению с традиционными реляционными базами данных, несмотря на то, что сами данные являются разреженными;
схема обработки данных должна строиться так, чтобы они обрабатывались непосредственно на той машине, где и находятся. Это позволит избежать передачи огромного массива по сети и в конечном счёте поднимет производительность.