VLAN Configuration Guide, Cisco IOS XE Bengaluru 17.5.x (Catalyst 9300 Switches)
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
Book Title
VLAN Configuration Guide, Cisco IOS XE Bengaluru 17.5.x (Catalyst 9300 Switches)
Configuring Layer 3 Subinterfaces
View with Adobe Reader on a variety of devices
View in various apps on iPhone, iPad, Android, Sony Reader, or Windows Phone
View on Kindle device or Kindle app on multiple devices
Results
Chapter: Configuring Layer 3 Subinterfaces
Configuring Layer 3 Subinterfaces
This module describes how to configure the dot1q VLAN subinterfaces on a Layer 3 interface, which forwards IPv4 and IPv6 packets to another device using static or dynamic routing protocols. You can use Layer 3 interfaces for IP routing and inter-VLAN routing of Layer 2 traffic.
Restrictions for Configuring Layer 3 Subinterfaces
Subinterfaces are not supported on StackWise Virtual Link.
Subinterfaces with Software-Defined Access (SD-Access) is not supported.
Do not configure more than 4,000 Layer 3 interfaces, that includes routed physical interfaces, SVI interfaces and subinterfaces.
A maximum of 1000 SVI interfaces is supported.
Do not configure encapsulation on the native VLAN of an IEEE 802.1Q trunk without the native keyword. Always use the native keyword of the dot1q vlan command when the VLAN ID is the ID of the IEEE 802.1Q native VLAN.
If you configure normal-range VLANs on subinterfaces, you cannot change the VLAN Trunking Protocol (VTP) mode from Transparent.
If a Layer 3 port has a subinterface configured with dot1q as the native VLAN, Cisco recommends not to configure routing related configuration on the Layer 3 port as it will hinder the functionality of the native VLAN subinterface.
Information About Layer 3 Subinterfaces
A dot1q VLAN subinterface is a virtual Cisco IOS interface that is associated with a VLAN ID on a routed physical interface. A parent interface is a physical port. Subinterfaces can be created on Layer 3 physical interfaces and Layer 3 port channels. A subinterface can be associated with different functionalities such as IP addressing, forwarding policies, Quality of Service (QoS) policies, and security policies.
Subinterfaces divide the parent interface into two or more virtual interfaces on which you can assign unique Layer 3 parameters such as IP addresses and dynamic routing protocols. The IP address for each subinterface should be in a different subnet from any other subinterface on the parent interface.
You can create a subinterface with a name that consists of the parent interface name (for example, HundredGigabitEthernet 1/0/33) followed by a period and then by a number that is unique for that subinterface. For example, you can create a subinterface for HundredGigabitEthernet interface 1/0/33 named HundredGigabitEthernet 1/0/33.1, where .1 indicates the subinterface.
One of the uses of subinterfaces is to provide unique Layer 3 interfaces to each VLAN that is supported by the parent interface. In this scenario, the parent interface connects to a Layer 2 trunking port on another device. You can configure a subinterface and associate the subinterface to a VLAN ID using 802.1Q trunking.
You can configure subinterfaces with any normal range or extended range VLAN ID in VLAN Trunking Protocol (VTP) transparent mode. Because VLAN IDs 1 to 1005 are global in the VTP domain and can be defined on other network devices in the VTP domain, you can use only extended range VLANs with subinterfaces in VTP client or server mode. In VTP client or server mode, normal-range VLANs are excluded from subinterfaces.
Use bridge groups on VLAN interfaces (also called fall-back bridging) to bridge nonrouted protocols. Bridge groups on VLAN interfaces are supported on the route processor (RP) software.
You can configure the same VLAN ID on a Layer 2 VLAN or Layer 3 VLAN interface and on a Layer 3 subinterface.
The following features and protocols are supported on Layer 3 subinterfaces:
Addressing and routing: IPv4 and IPv6.
Unicast routing: Open Shortest Path First (OSPF), Enhanced Interior Gateway Routing Protocol (EIGRP), Routing Information Protocol (RIP), Border Gateway Protocol (BGP), and static routing.
Multicast routing: Internet Group Management Protocol (IGMP), Protocol-Independent Multicast Sparse Mode (PIM-SM), Source Specific Multicast (SSM), and Multiprotocol Label Switching (MPLS).
First-Hop Redundancy Protocol (FHRP) protocols: Hot Standby Router Protocol (HSRP), Virtual Router Redundancy Protocol (VRRP), and Gateway Load Balancing Protocol (GLBP).
Bidirectional Forwarding Detection (BFD), Unicast Reverse Path Forwarding (uRPF), and Equal-Cost Multipath (ECMP).
Maximum transmission unit (MTU) and IPv4 fragmentation.
Virtual routing and forwarding (VRF) lite.
Router access control list and policy-based routing (PBR).
Quality of Service (QoS): Marking and policing.
Services: Network Address Translation (NAT) IPv4, Security Group Access Control List (SGACL) enforcement, DHCP Server/Relay , SGT Exchange Protocol (SXP), and NetFlow.
Layer 3 EtherChannels.
How to Configure Layer 3 Subinterfaces
You can configure one or more subinterfaces on a routed interface. Configure the parent interface as a routed interface by using the no switchport command . The parent interface can have its own IP address, policies, and configurations attached to it. Untagged traffic and any tagged traffic or VLAN (not handled by the subinterface) that comes into the port are handled by the parent interface.
Layer 3 subinterface (Cisco)
Home  Knowledge Base Design & Configure Layer 3 subinterface (Cisco)
Knowledge Base Design & Configure Layer 3 subinterface (Cisco)
Design & Configure
Layer 3 subinterface (Cisco)
Technology: Network
Area: Configuration General
Vendor: Cisco
Software: 12.X, 15.X
Platform: ISR Routers, ASR Routers
Subinterfaces divide the parent interface into two or more virtual interfaces on which you can assign unique Layer 3 parameters such as IP addresses and dynamic routing protocols parameters. The IP address for each subinterface should be in a different subnet from any other subinterface on the parent interface (if you are not using VRF-Lite feature).
Switch# configure terminal
switch(config)# interface ethernet 2/1.1
switch(config-if)# ip address 192.0.2.1 255.0.0.0
switch(config-if)# encapsulation dot1Q 33
Because subinterfaces work always on trunk links, there is a necessity of encapsulation definition. The encapsulation command defines the VLAN tag (VLAN number) which will be using by this subinterface.
Интерфейсы и подчиненные интерфейсы в маршрутизаторе: что они и для чего они нужны?
Одним из важнейших компонентов любой сети является маршрутизатор. Несмотря на то, что многие люди воспринимают это как устройство, излучающее сигнал Wi-Fi, это гораздо больше. Одной из важных функций маршрутизатора является обеспечение связи между различными VLAN, то есть различными виртуальными локальными сетями, которые создаются для правильной сегментации трафика. Помните, что все VLAN создаются в коммутаторе и применяются для каждого порта к подключенному оборудованию. Это руководство объяснит все, что вам нужно знать о субинтерфейсах маршрутизатора и о том, что отличает его от интерфейсов.
Субинтерфейсы чрезвычайно важны при настройке связи между двумя или более VLAN. Особенно, если вы работаете с оборудованием от производителя Cisco. Однако важно усилить несколько важных концепций, прежде чем переходить к рассматриваемым субинтерфейсам. Эти подчиненные интерфейсы также существуют в любом Linuxна основе маршрутизатора, хотя они и называются не субинтерфейсами, а виртуальными интерфейсами, но на самом деле это одно и то же, и служит той же цели: для взаимодействия имеющихся у нас VLAN.
Маршрутизатор имеет несколько портов, каждый из которых, в свою очередь, является сетевым интерфейсом. Когда мы говорим о сетевом интерфейсе, мы имеем в виду аппаратный компонент, который позволяет устройству подключаться к любой сети. Следовательно, маршрутизатор имеет несколько сетевых интерфейсов, то есть несколько сетевых карт, упакованных в одно устройство.
В некоторой степени он похож на компьютер. Хотя все компьютеры имеют один проводной сетевой интерфейс, в соответствии с нашими потребностями вы можете добавить одну или несколько сетевых карт, чтобы у вашего компьютера было несколько интерфейсов. То же самое относится к беспроводным сетевым интерфейсам, то есть на одном компьютере может быть несколько беспроводных сетевых интерфейсов. Последнее особенно полезно, если вас интересуют действия, связанные со взломом сетей Wi-Fi.
Please enable JavaScript

С другой стороны, какова именно роль маршрутизатора? Это устройство может подключаться к одной или нескольким сетям. В свою очередь, он может подключаться к другим маршрутизаторам для обмена информацией о маршрутизации. Сама маршрутизация стала возможной благодаря таблицам маршрутизации. У каждого маршрутизатора есть таблица маршрутизации, в которой указаны возможные места назначения, по которым следует перенаправить путь, по которому следует каждый пакет данных. Маршрутизатор имеет все необходимые функции, чтобы иметь возможность принимать решения о том, какой из них является наилучшим, чтобы ни один пакет данных не был отброшен или заблокирован в какой-то момент его прохождения по сети.
Маршрутизатор на палочке
Если в вашей сети более одной VLAN, коммутатор не может выполнять функцию, позволяющую компьютеру в VLAN 1 взаимодействовать с VLAN 2, за исключением случаев, когда это коммутатор L2 + или L3, который включает функциональность Inter. -VLAN маршрутизация, в этом случае можно.
Если у вас «нормальный» коммутатор L2, вам потребуются услуги маршрутизатора для взаимодействия сетей VLAN, декапсуляции и инкапсуляции сетей VLAN для правильной связи. Что означает Router-on-a-Stick? Давайте посмотрим на этот пример сети:
Представлены два компьютера, каждый из которых подключен к VLAN. Один к VLAN 10, а другой к VLAN 20. Эти компьютеры подключены к коммутатору через соответствующие интерфейсы. То есть у коммутатора два порта заняты обоими компьютерами. На другой стороне коммутатора есть соединение между ним и маршрутизатором. Если говорить строго на физическом уровне, если у вас две сети VLAN, вы можете выбрать один порт маршрутизатора для каждого порта, чтобы он подключался к коммутатору. Поэтому и в этом случае коммутатор должен иметь два магистральных порта.
Если мы масштабируем случай до четырех, пяти, шести или более VLAN, это будет практически невозможно. Очень легко и маршрутизатор, и порты коммутатора будут заняты, что вызывает различные трудности при управлении обоими устройствами. Вот почему концепция Router-on-a-Stick позволяет создавать суб-интерфейсы в маршрутизаторе, то есть в том же физическом интерфейсе маршрутизатора мы можем создавать виртуальные интерфейсы или суб-интерфейсы, и каждый из них Он будет связан с одной из VLAN, которые есть в нашей сети.
Что касается коммутатора, если мы применим Router-on-a-Stick, нам понадобится только магистральный порт.
Как настроить суб-интерфейсы
Вначале мы отметили, что субинтерфейсы в значительной степени применяются в устройствах производителя Cisco. По этой причине мы собираемся продемонстрировать его работу через конфигурацию через CLI (интерфейс командной строки) самого маршрутизатора Cisco. Первое, что мы должны гарантировать, это то, что коммутатор или коммутаторы в нашей сети правильно настроены для портов доступа и назначения VLAN.
Switch1#configure terminal
Switch1 (config)# interface gigabitEthernet 0/1
Switch1 (config-if)# switchport mode access
Switch1 (config-if)# switchport access vlan 100
Switch1 (config-if)# interface gigabitEthernet 0/2
Switch1 (config-if)# switchport mode access
Switch1 (config-if)# switchport access vlan 200
Мы также должны гарантировать правильную конфигурацию нашего магистрального порта, которая позволит трафику различных VLAN перемещаться к маршрутизатору и наоборот.
Switch1 (config)# interface gigabitEthernet 0/24
Switch1 (config-if)# switchport trunk encapsulation dot1q
Switch1 (config-if)# switchport mode trunk
Одна из введенных нами команд такова:
switchport trunk encapsulation dot1q
Это относится к IEEE 802.1Q communication стандарт . По сути, это протокол, который позволяет каждому кадру Ethernet, генерируемому хостами (компьютерами), иметь идентификатор VLAN, то есть идентификатор, который указывает, в какую VLAN этот кадр должен перейти. Этот протокол работает только между сетевыми устройствами: маршрутизаторами и коммутаторами. Он не применяется к хостам, поэтому, как только он достигает места назначения, этот идентификатор VLAN отправляется без тегов или без тегов, то есть он представляется как обычный кадр Ethernet.
Теперь мы настраиваем роутер. Всегда перед настройкой субинтерфейсов мы должны убедиться, что интерфейсы действительно работают. Поэтому мы всегда должны начинать с команды «без выключения», чтобы активировать их. Затем вы можете начать с подчиненных интерфейсов.
(config)# interface gigabitEthernet 0/0
(config-if)# no shutdown
(config-if)# exit
(config-if)# interface gigabitEthernet 0/0.100
(config-subif)# encapsulation dot1Q 100
(config-subif)# ip address 192.168.1.1 255.255.255.0
(config-subif)# exit
(config)# interface gigabitEthernet 0/0.200
(config-subif)# encapsulation dot1Q 200
(config-subif)# ip address 192.168.2.1 255.255.255.0
(config-subif)# exit
Совет, который используется, заключается в том, что каждый подчиненный интерфейс имеет ту же нумерацию, что и номер VLAN, с которой мы работаем. Как мы видим в примерах команд, один субинтерфейс — .100 (для VLAN 100), а другой — .200 (для VLAN 200). Это больше, чем что-либо для настройки и администрирования намного легче и избежать проблем.
С другой стороны, мы снова видим команду «encapsulation dot1Q», и на этот раз она сопровождается идентификатором соответствующей ей VLAN. Это позволит каждому подинтерфейсу интерпретировать все тегированные кадры 802.1Q, поступающие из магистрального порта коммутатора. Если это не настроено, маршрутизатор не будет интерпретировать кадры и не будет знать, куда направить каждый из них.
Наконец, мы видим назначение IP-адресов для каждого подчиненного интерфейса. Эти же IP-адреса будут настроены на каждом хосте и будут действовать как шлюз по умолчанию . То есть на каждом компьютере в VLAN 100 должен быть настроен адрес 192.168.1.1 как шлюз. То же самое и с VLAN 200, IP-адрес шлюза 192.168.2.1.
Router-on-a-Stick — одна из самых важных концепций, когда дело касается сетей. Он выделяется, главным образом, тем, что позволяет в полной мере использовать несколько портов наших сетевых устройств. Интерфейс маршрутизатора может иметь один или несколько подчиненных интерфейсов. Это обеспечивает масштабируемость и гибкость нашей сети без ненужных затрат. Важным аспектом является то, что настоятельно рекомендуется, чтобы эта магистраль работала на мультигигабитных скоростях и даже на скоростях 10 Гбит / с, чтобы не создавать узких мест в этом канале при передаче файлов между VLAN.
Сети для самых маленьких. Часть третья. Статическая маршрутизация
Мальчик сказал маме: “Я хочу кушать”. Мама отправила его к папе.
Мальчик сказал папе: “Я хочу кушать”. Папа отправил его к маме.
Мальчик сказал маме: “Я хочу кушать”. Мама отправила его к папе.
И бегал так мальчик, пока в один момент не упал.
Что случилось с мальчиком? TTL кончился.
Итак, поворотный момент в истории компании “Лифт ми Ап”. Руководство понимает, что компания, производящая лифты, едущие только вверх, не выдержит борьбы на высококонкурентном рынке. Необходимо расширять бизнес. Принято решение о покупке двух заводов: в Санкт-Петербурге и Кемерово.
Нужно срочно организовывать связь до новых офисов, а у вас ещё даже локалка не заработала.
Сегодня:
1. Настраиваем маршрутизацию между вланами в нашей сети (InterVlan routing)
2. Пытаемся разобраться с процессами, происходящими в сети, и что творится с данными.
3. Планируем расширение сети (IP-адреса, вланы, таблицы коммутации)
4. Настраиваем статическую маршрутизацию и разбираемся, как она работает.
5. Используем L3-коммутатор в качестве шлюза
InterVlan Routing
Чуточку практики для взбадривания.
В предыдущий раз мы настроили коммутаторы нашей локальной сети. На данный момент устройства разных вланов не видят друг друга. То есть фактически ФЭО и ПТО, например, находятся в совершенно разных сетях и не связаны друг с другом. Так же и серверная сеть существует сама по себе. Надо бы исправить эту досадную неприятность.
В нашей московской сети для маршрутизации между вланами мы будем использовать роутер cisco 2811. Иными словами он будет терминировать вланы. Кадры здесь заканчивают свою жизнь: из них извлекаются IP-пакеты, а заголовки канального уровня отбрасываются.

Процесс настройки маршрутизатора очень прост:
0) Сначала закончим с коммутатором msk-arbat-dsw1. На нём нам нужно настроить транковый порт в сторону маршрутизатора, чего мы не сделали в прошлый раз.
1) Назначаем имя маршрутизатора командой hostname, а для развития хорошего тона, надо упомянуть, что лучше сразу же настроить время на устройстве. Это поможет вам корректно идентифицировать записи в логах.
Желательно время на сетевые устройства раздавать через NTP (любую циску можно сделать NTP-сервером, кстати)
2) Далее переходим в режим настройки интерфейса, обращённого в нашу локальную сеть и включаем его, так как по умолчанию он находится в состоянии Administratively down.
Логика тут простая. Сначала указываем обычным образом физический интерфейс, к которому подключена нужная сеть, а после точки ставим некий уникальный идентификатор этого виртуального интерфейса. Для удобства, обычно номер сабинтерфейса делают аналогичным влану, который он терминирует.
4) Теперь вспомним о стандарте 802.1q, который описывает тегирование кадра меткой влана. Следующей командой вы обозначаете, что кадры, исходящие из этого виртуального интерфейса будут помечены тегом 2-го влана. А кадры, входящие на физический интерфейс FastEthernet0/0 с тегом этого влана будут приняты виртуальным интерфейсом FastEthernet0/0.2.
5) Ну и как на обычном физическом L3-интерфейсе, определим IP-адрес. Этот адрес будет шлюзом по умолчанию (default gateway) для всех устройств в этом влане.
и теперь убедимся, что с компьютера из сети ПТО мы видим сеть управления:
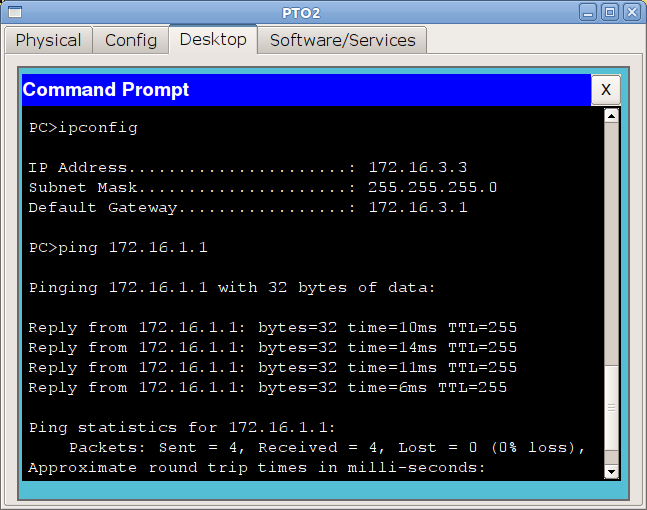
Работает и отлично, настройте пока все остальные интерфейсы. Проблем с этим возникнуть не должно.
Физика и логика процесса межвланной маршрутизации
Что происходит в это время с вашими данными?
Мы рассуждали в прошлый раз, что происходит, если вы пытаетесь связаться с устройством из той же самой подсети, в которой находитесь вы.
Под той же самой подсетью мы понимаем следующее.
Например, на вашем компьютере настроено следующее:
IP: 172.16.3.2
Mask: 255.255.255.0
GW: 172.16.3.1
Все устройства, адреса которых будут находиться в диапазоне 172.16.3.1-172.16.3.254 с такой же маской, как у вас будут являться членами вашей подсети. Что происходит с данными, если вы отправляет их на устройство с адресом из этого диапазона?
Повторим это с некоторыми дополнениями.
Для отправки данных они должны быть упакованы в Ethernet-кадр, в заголовок которого должен быть вставлен MAC-адрес удалённого устройства. Но откуда его взять?
Для этого ваш компьютер рассылает широковещательный ARP-запрос. В качестве IP-адреса узла назначения в IP-пакет с этим запросом будет помещён адрес искомого хоста. Сетевая карта при инкапсуляции указывает MAC-адрес FF:FF:FF:FF:FF:FF — это значит, что кадр предназначен всем устройствам. Далее он уходит на ближайший коммутатор и копии рассылаются на все порты нашего влана (ну, кроме, конечно, порта, из которого получен кадр). Получатели видят, что запрос широковещательный и они могут оказаться искомым хостом, поэтому извлекают данные из кадра. Все те устройства, которые не обладают указанным в ARP-запросе IP-адресом, просто игнорируют запрос, а вот устройство-настоящий получатель ответит на него и вышлет первоначальному отправителю свой MAC-адрес. Отправитель (в данном случае, наш компьютер) помещает полученный MAC в свою таблицу соответствия IP и MAC адресов ака ARP-кэш. Как выглядит ARP-кэш на вашем компьютере прямо сейчас, вы можете посмотреть с помощью команды arp -a 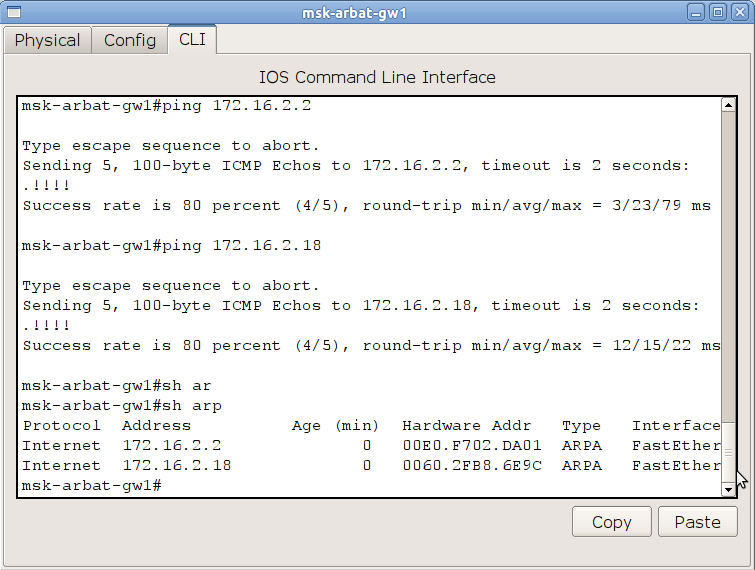
Потом ваши полезные данные упаковываются в IP-пакет, где в качестве получателя ставится тот адрес, который вы указали в команде/приложении, затем в Ethernet-кадр, в заголовок которого помещается полученный ARP-запросом MAC-адрес. Далее кадр отправляется на коммутатор, который согласно своей таблице MAC-адресов, решает, в какой порт его переправить дальше.
Но что происходит, если вы пытаетесь достучаться до устройства в другом влане? ARP-запрос ничего не вернёт, потому что широковещательные L2 сообщения кончаются на маршрутизаторе(т.е., в пределах широковещательного L2 домена), нужная сеть находится за ним, а коммутатор не пустит кадры из одного влана в порт другого. И вот для этого нужен шлюз по умолчанию (default gateway) на вашем компьютере.
То есть, если устройство-получатель в вашей же подсети, кадр просто отправляется в порт с мак-адресом конечного получателя. Если же сообщение адресовано в любую другую подсеть, то кадр отправляется на шлюз по умолчанию, поэтому в качестве MAC-адреса получателя подставится MAC-адрес маршрутизатора.
Проследим за ходом событий.
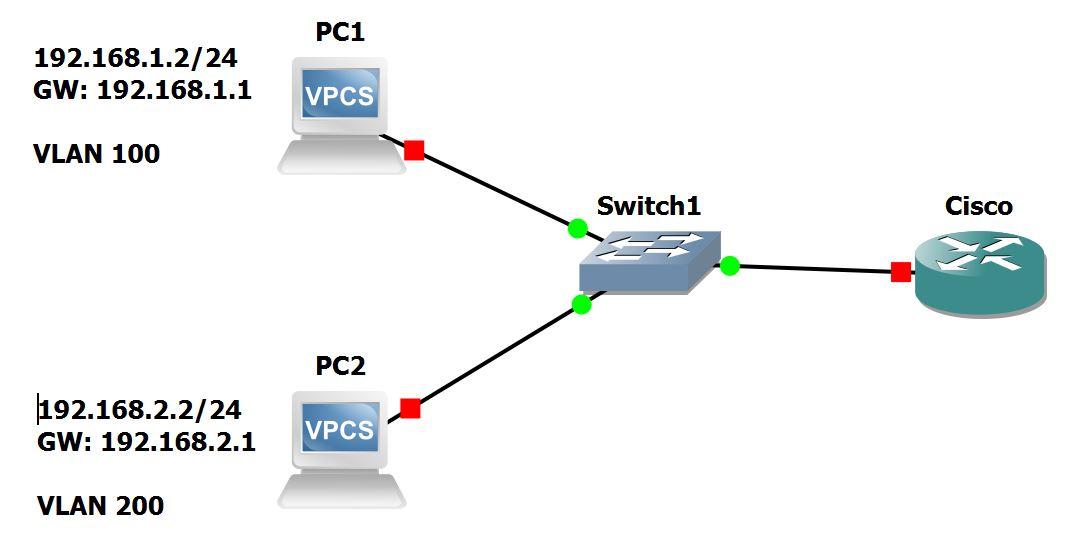
1) ПК с адресом 172.16.3.2/24 хочет отправить данные компьютеру с адресом 172.16.4.5. 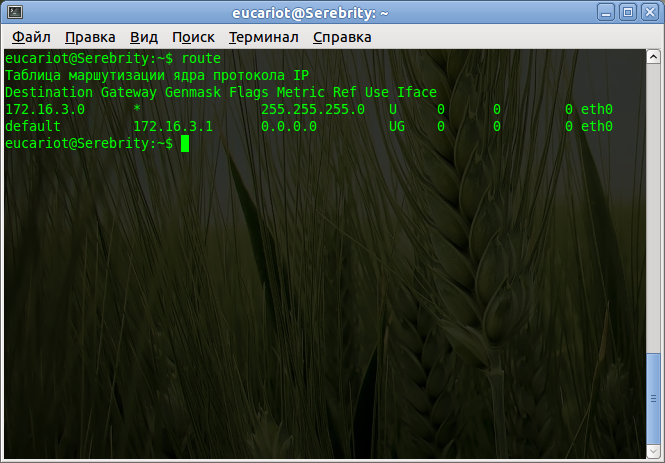
Он видит, что адрес из другой подсети, следовательно, данные должны уйти на шлюз по умолчанию. Но в таком случае, ПК нужен MAC-адрес шлюза. ПК проверяет свой ARP-кэш в поисках соответствия IP-адрес шлюза — MAC-адрес и не находит нужного 
2) ПК отправляет широковещательный ARP-запрос в локальную сеть. Структура ARP-запроса:
— на канальном уровне в качестве получателя — широковещательный адрес ( FF:FF:FF:FF:FF:FF), в качестве отправителя — MAC-адрес интерфейса устройства, пытающегося выяснить IP
— на сетевом — собственно ARP запрос, в нем содержится информация о том, какой IP и кем ищется. 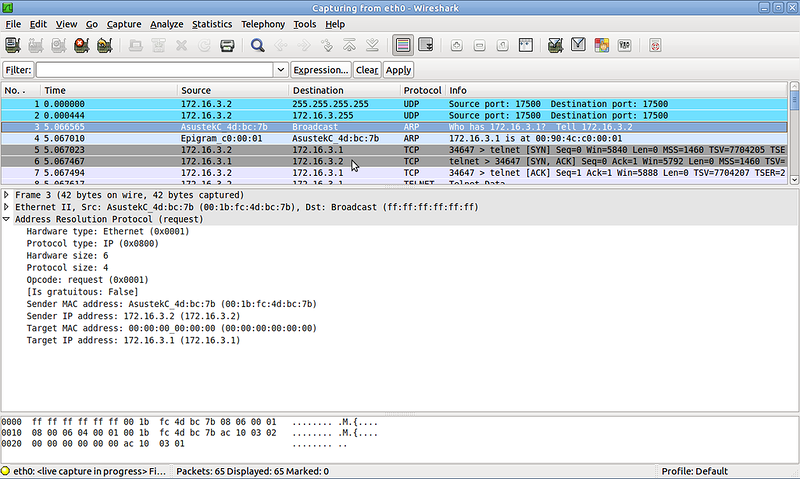
3) Коммутатор, на который попал кадр, рассылает его копии во все порты этого влана (того, которому принадлежит изначальный хост), кроме того, откуда он получен.
4) Все устройства, получив этот кадр и, видя, что он широковещательный, предполагают, что он адресован им.
5) Распаковав кадр, все хосты, кроме маршрутизатора, видят, что в ARP-запросе не их адрес. А маршрутизатор посылает unicast’овый ARP-ответ со своим MAC-адресом.
6) Изначальный хост получает ARP-ответ, теперь у него есть MAC-адрес шлюза. Он формирует пакет из тех данных, что ему нужно отправить на 172.16.4.5. В качестве MAC-адреса получателя ПК ставит адрес шлюза. При этом IP-адрес получателя в пакете остаётся 172.16.4.5
7) Кадр посылается в сеть, коммутаторы доставляют его на маршрутизатор.
8) На маршрутизаторе, в соответствии с меткой влана, кадр принимается конкретным сабинтерфейсом. Данные канального уровня откидываются.
9) Из заголовка IP-пакета, рутер узнаёт адрес получателя, а из своей таблицы маршрутизации видит, что тот находится в непосредственно подключенной к нему сети на определённом сабинтерфейсе (в нашем случае FE0/0.102).
10) Маршрутизатор отправляет ARP-запрос с этого сабинтерфейса — узнаёт MAC-адрес получателя.
11) Изначальный IP-пакет, не изменяясь инкапсулируется в новый кадр, при этом:
— в качестве MAC-адреса источника указывается адрес интерфейса шлюза
— IP-адрес источника — адрес изначального хоста (в нашем случае 172.16.3.2)
— в качестве MAC-адреса получателя указывается адрес конечного хоста
— IP-адрес получателя — адрес конечного хоста (в нашем случае 172.16.4.5)
и отправляется в сеть с сабинтерфейса FastEthernet0/0.102, получая при этом метку 102-го влана.
12) Кадр доставляется коммутаторами до хоста-получателя.
Планирование расширения
Теперь обратимся к планированию. В нулевой части мы уже затронули эту тему, но тогда речь была только о двух офисах в Москве, теперь же сеть растёт.
Будет она вот такой:
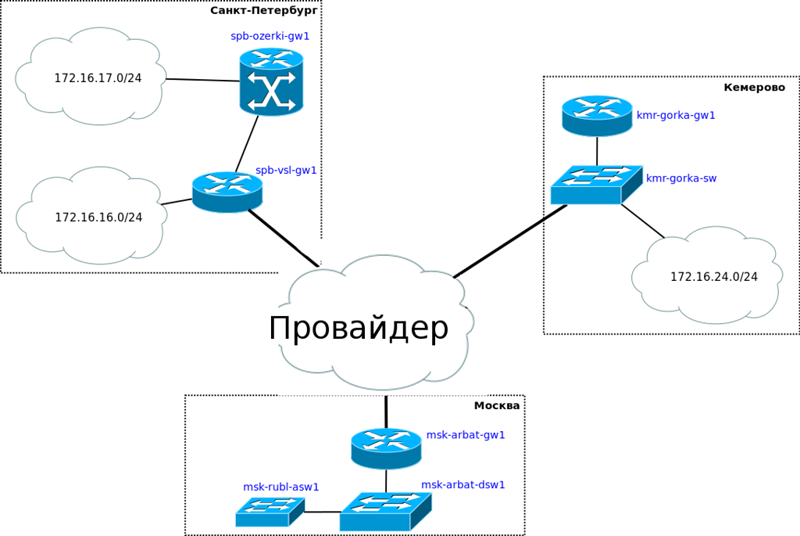
То есть прибавляются две точки в Санкт-Петербурге: небольшой офис на Васильевском острове и сам завод в Озерках — и одна в Кемерово в районе Красная горка.
Для простоты у нас будет один провайдер “Балаган Телеком”, который на выгодных условиях предоставит нам L2VPN до обеих точек.
В одном из следующих выпусков мы тему различных вариантов подключения раскроем в красках. А пока вкратце: L2VPN — это, очень грубо говоря, когда вам провайдер предоставляет влан от точки до точки (можно для простоты представить, что они включены в один коммутатор).
Следует сказать несколько слов об IP-адресации и делении на подсети.
В нулевой части мы уже затронули вопросы планирования, весьма вскользь надо сказать.
Вообще, в любой более или менее большой компании должен быть некий регламент — свод правил, следуя которому вы распределяете IP-адреса везде. Сеть у нас сейчас разрастается и разработать его очень важно.
Ну вот к примеру, скажем, что для офисов в других городах это будет так:
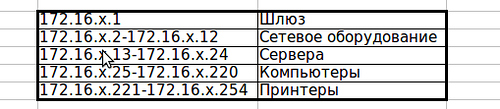
Это весьма упрощённый регламент, но теперь мы во всяком случае точно знаем, что у шлюза всегда будет 1-й адрес, до 12-го мы будем выдавать коммутаторам и всяким wi-fi-точкам, а все сервера будем искать в диапазоне 172.16.х.13-172.16.х.23. Разумеется, по своему вкусу вы можете уточнять регламент вплоть до адреса каждого сервера, добавлять в него правило формирования имён устройств, доменных имён, политику списков доступа и т.д.
Чем точнее вы сформулируете правила и строже будете следить за их выполнением, тем проще разбираться в структуре сети, решать проблемы, адаптироваться к ситуации и наказывать виновных.
Это примерно, как схема запоминания паролей: когда у вас есть некое правило их формирования, вам не нужно держать в голове несколько десятков сложнозапоминаемых паролей, вы всегда можете их вычислить.
Вот так же и тут. Я некогда работал в средних размеров холдинге и знал, что если я приеду в офис где-нибудь в забытой коровами деревне, то там точно x.y.z.1 — это циска, x.y.z.2 — дистрибьюшн-свитч прокурва, а x.y.z.101 — компьютер главного бухгалтера, с которого надо дать доступ на какой-нибудь контур-экстерн. Другой вопрос, что надо это ещё проверить, потому что местные ИТшники такого порой наворотят, что слезами омываешься сквозь смех.
IP-план
Теперь нам было бы весьма кстати составить IP-план. Будем исходить из того, что на всех трёх точках мы будем использовать стандартную сеть с маской 24 бита (255.255.255.0) Это означает, что в них может быть 254 устройства.
Почему это так? И как вообще понять все эти маски подсетей? В рамках одной статьи мы не сможем этого рассказать, иначе она получится длинная, как палуба Титаника и запутанная, как одесские катакомбы. Крайне рекомендуем очень плотно познакомиться с такими понятиями, как IP-адрес, маска подсети, их представления в двоичном виде и CIDR (Classless InterDomain Routing) самостоятельно. Мы же далее будем только аргументировать выбор конкретного размера сети. Как бы то ни было, полное понимание придёт только с практикой.
Вообще, очень неплохо эта тема раскрыта в этой статье: http://habrahabr.ru/post/129664/
В данный момент (вспомним нулевой выпуск) у нас в Москве использованы адреса 172.16.0.0-172.16.6.255. Предположим, что сеть может ещё увеличиться здесь, допустим, появится офис на Воробьёвых горах и зарезервируем ещё подсети до 172.16.15.0/24 включительно.
Все эти адреса: 172.16.0.0-172.16.15.255 — можно описать так: 172.16.0.0/20. Эта сеть (с префиксом /20) будет так называемой суперсетью, а операция объединения подсетей в суперсети называется суммированием подсетей (суммированием маршрутов, если быть точным, route summarization)
Очень наглядный IP-калькулятор. Я и сейчас им периодически пользуюсь, хотя со временем приходит интуитивное и логическое понимание соответствия между длиной маски и границами сети.
Теперь обратимся к Питеру. В данный момент в этом прекрасном городе у нас 2 точки и на каждой из них подсети /24. Допустим это будут 172.16.16.0/24 и 172.16.17.0/24. Зарезервируем адреса 172.16.18.0-172.16.23.255 для возможного расширения сети.
172.16.16.0-172.16.23.255 можно объединить в 172.16.16.0/21 — в общем-то исходя именно из этого мы и оставляем в резерв именно такой диапазон.
В Кемерово нам нет смысла оставлять такие огромные запасы /21, как в Питере (2048 адресов или 8 подсетей /24), или тем более /20, как в Москве (4096 или 16 подсетей /24). А вот 1024 адреса и 4 подсети /24, которым соответствует маска /22 вполне рационально.
Таким образом сеть 172.16.24.0/22 (адреса 172.16.24.0-172.16.27.255) будет у нас для Кемерово.

Тут надо бы заметить: делать такой запас в общем-то необязательно и то, что мы зарезервировали вполне можно использовать в любом другом месте сети. Нет табу на этот счёт. Однако в крупных сетях именно так и рекомендуется делать и связано это с количеством информации в таблицах маршрутизации.
Понимаете ли дело вот в чём: если у вас несколько подряд идущих подсетей разбросаны по разным концам сети, то каждой из них соответствует одна запись в таблице маршрутизации каждого маршрутизатора. Если при этом вы вдруг используете только статическую маршрутизацию, то это ещё колоссальный труд по настройке и отслеживанию корректности настройки.
А если же они у вас все идут подряд, то несколько маленьких подсетей вы можете суммировать в одну большую.
Поясним на примере Санкт-Петербурга. При настройке статической маршрутизации мы могли бы делать так:
Это 8 команд и 8 записей в таблице. Но при этом пришедший на маршрутизатор пакет в любую из сетей 172.16.16.0/21 в любом случае будет отправлен на устройство с адресом 172.16.2.2.
Вместо этого мы поступим так:
И вместо восьми возможных сравнений будет только одно.
Для современных устройств ни в плане процессорного времени ни использования памяти это уже не является существенной нагрузкой, однако такое планирование считается правилами хорошего тона и в конечном итоге вам же самим проще разобраться.
Но, положа руку на сердце, такое планирование скорее исключение, нежели правило: так или иначе фрагментация маршрутов с ростом сети неизбежна.
Теперь ещё несколько слов о “линковых” сетях. В среде сетевых администраторов так называются сети точка-точка (Point-to-Point) между двумя маршрутизаторами.
Вот опять же в примере с Питером. Два маршрутизатора (в Москве и в Петербурге) соединены друг с другом прямым линком (неважно, что у провайдера это сотня коммутаторов и маршрутизаторов — для нас это просто влан). То есть кроме вот этих 2-х устройств здесь не будет никаких других. Мы знаем это наверняка. В любом случае на интерфейсах обоих устройств (смотрящих в сторону друг друга) нужно настраивать IP-адреса. И нам точно незачем назначать на этом участке сеть /24 с 254 доступными адресами, ведь 252 в таком случае пропадут почём зря. В этом случае есть прекрасный выход — бесклассовая IP-адресация.
Почему она бесклассовая? Если вы помните, то в нулевой части мы говорили о трёх классах подсетей: А, В и С. По идее только их вы и могли использовать при планировании сети. Бесклассовая междоменная маршрутизация (CIDR) позволяет очень гибко использовать пространство IP-адресов.
Мы просто берём сеть с самой маленькой возможной маской — 30 (255.255.255.252) — это сеть на 4 адреса. Почему мы не можем взять сеть с ещё более узкой маской? Ну 32 (255.255.255.255) по понятными причинам — это вообще один единственный адрес, сеть 31 (255.255.255.254) — это уже 2 адреса, но один из них (первый) — это адрес сети, а второй (последний) — широковещательный. В итоге на адреса хостов у нас и не осталось ничего. Поэтому и берём маску 30 с 4 адресами и тогда как раз 2 адреса остаются на наши два маршрутизатора.
Вообще говоря, самой узкой маской для подсетей в cisco таки является /31. При определённых условиях их можно использовать на P-t-P-линках.
Что же касается маски /32, то такие подсети, которые суть один единственный хост используются для назначения адресов Loopback-интерфейсам.
Именно так мы и поступим. Для этого, собственно, в нулевой части мы и оставили сеть 172.16.2.0/24 — её мы будем дробить на мелкие сетки /30. Всего их получится 64 штуки, соответственно можно назначить их на 64 линка.
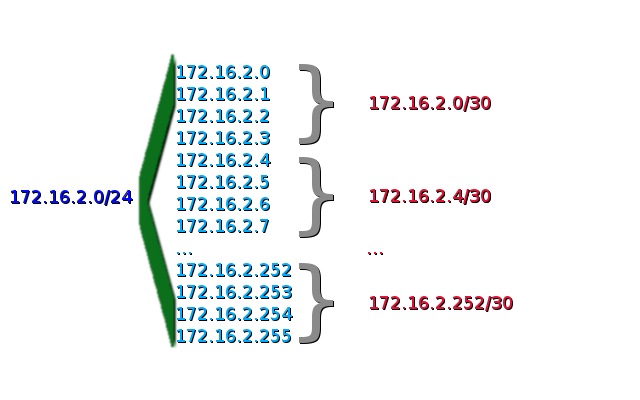
Здесь мы поступили так же, как и в предыдущем случае: сделали небольшой резерв для Питера, и резерв для Кемерово. Вообще резерв — это всегда очень хорошо о чём бы мы ни говорили. 😉
Принципы маршрутизации
Перед началом настройки стоит определиться с тем, для чего нужна маршрутизация вообще.
Рассмотрим такую сеть:

Вот к примеру с компьютера ПК1 — 172.16.3.2 я хочу подключиться по telnet к L3-коммутатору с адресом 172.16.17.1.
Как мой компьютер узнает что делать? Куда слать данные?
1) Как вы уже знаете, если адрес получателя из другой подсети, то данные нужно отправлять на шлюз по умолчанию.
2) По уже известной вам схеме компьютер с помощью ARP-запроса добывает MAC-адрес маршрутизатора.
3) Далее он формирует кадр с инкапсулированным в него пакетом и отсылает его в порт. После того, как кадр отправлен, компьютеру уже по барабану, что происходит с ним дальше.
4) А сам кадр при этом попадает сначала на коммутатор, где решается его судьба согласно таблице MAC-адресов. А потом достигает маршрутизатора RT1.
5) Поскольку маршрутизатор ограничивает широковещательный домен — здесь жизнь этого кадра и заканчивается. Циска просто откидывает заголовок канального уровня — он уже не пригодится — извлекает из него IP-пакет.
6) Теперь маршрутизатор должен принять решение, что с ним делать дальше. Разумеется, отправить его на какой-то свой интерфейс. Но на какой?
Для этого существует таблица маршрутизации, которая есть на любом рутере. Выяснить, что у нас в данный момент находится в таблице маршрутизации, можно с помощью команды show ip route:
Каждая строка в ней — это способ добраться до той или иной сети.
Вот к примеру, если пакет адресован в сеть 172.16.17.0/24, то данные нужно отправить на устройство с адресом 172.16.2.2.
Таблица маршрутизации формируется из:
— непосредственно подключенных сетей (directly connected) — это сети, которые начинаются непосредственно на нём. В примере 172.16.3.0/24 и 172.16.2.0/30. В таблице они обозначаются буквой C
— статический маршруты — это те, которые вы прописали вручную командой ip route. Обозначаются буквой S
— маршруты, полученные с помощью протоколов динамической маршрутизации (OSPF, EIGRP, RIP и других).
7) Итак, данные в сеть 172.16.17.0 (а мы хотим подключиться к устройству 172.16.17.1) должны быть отправлены на следующий хоп — следующий прыжок, которым является маршрутизатор 172.16.2.2. Причём из таблицы маршрутизации видно, что находится следующий хоп за интерфейсом FE0/1.4 (подсеть 172.16.2.0/30).
8)Если в ARP-кэше циски нет MAC-адреса, то надо снова выполнить ARP-запрос, чтобы узнать MAC-адрес устройства с IP-адресом 172.16.2.2. RT1 посылает широковещательный кадр с порта FE0/1.4. В этом широковещательном домене у нас два устройства, и соответственно только один получатель. RT2 получает ARP-запрос, отбрасывает заголовок Ethernet и, понимая из данных протокола ARP, что искомый адрес принадлежит ему отправляет ARP-ответ со своим MAC-адресом.
9) Изначальный IP-пакет, пришедший на RT1 не меняется, он инкапсулируется в совершенно новый кадр и отправляется в порт FE0/1.4, получая при этом метку 4-го влана.
10) Полностью аналогичные действия происходят на следующем маршрутизаторе. И на следующем и следующем (если бы они были), пока пакет не дойдёт до последнего, к которому и подключена нужная сеть.
11) Последний маршрутизатор видит, что искомый адрес принадлежит ему самому, а извлекая данные транспортного уровня, понимает, что это телнет и передаёт все данные верхним уровням.
Так вот и путешествуют данные с одного хопа на другой и ни один маршрутизатор представления не имеет о дальнейшей судьбе пакета. Более того, он даже не знает есть ли там действительно эта сеть — он просто доверяет своей таблице маршрутизации.
Настройка
Каким образом мы организуем каналы связи? Как мы уже сказали выше, в нашем офисе на Арбате есть некий провайдер Балаган-Телеком. Он обещает нам предоставить всё, что мы только захотим почти задарма. И мы заказываем у него две услуги L2VPN, то есть он отдаст нам два влана на Арбате в Москве, и по одному в Питере и Кемерово.
Вообще говоря, номера вланов вам придётся согласовывать с вашим провайдером по той простой причине, что у него они могут быть просто заняты. Поэтому вполне возможно, что у вас будет влан, например, 2912 или 754. Но предположим, что нам повезло, и мы вольны сами выбирать номер.
Москва. Арбат
msk-arbat-gw1(config)#interface FastEthernet 0/1.4
msk-arbat-gw1(config-subif)#description Saint-Petersburg
msk-arbat-gw1(config-subif)#encapsulation dot1Q 4
msk-arbat-gw1(config-subif)#ip address 172.16.2.1 255.255.255.252
msk-arbat-gw1(config)#interface FastEthernet 0/1.5
msk-arbat-gw1(config-subif)#description Kemerovo
msk-arbat-gw1(config-subif)#encapsulation dot1Q 5
msk-arbat-gw1(config-subif)#ip address 172.16.2.17 255.255.255.252
Провайдер
Разумеется, мы не будем строить всю сеть провайдера. Вместо этого просто поставим коммутатор, ведь по сути сеть провайдера с нашей точки зрения будет одним огромным абстрактным коммутатором.
Тут всё просто: принимаем транком линк с Арбата в один порт и с двух других портов отдаём их на удалённые узлы. Ещё раз хотим подчеркнуть, что все эти 3 порта не принадлежат одному коммутатору — они разнесены на сотни километров, между ними сложная MPLS-сеть с кучей коммутаторов.
Настраиваем “эмулятор провайдера”:
Санкт-Петербург. Васильевский остров
Теперь обратимся к нашему spb-vsl-gw1. Тут у нас тоже 2 порта, но решим вопрос нехватки портов иначе: добавим сюда плату. Плата с двумя FastEthernet-портам и двумя слотами для WIC вполне подойдёт.
Пусть встроенные порты будут для локальной сети, а порты на дополнительной плате мы используем для аплинка и связи с Озерками.
Здесь вы можете увидеть отличие в нумерации портов и понять их смысл.
FastEthernet — это тип порта (Ethernet, Fastethernet, GigabitEthernet, POS, Serial или другие)
x/y/z.w=Slot/Sub-slot/Interface.Sub-interface.
Каким образом здесь вам провайдер будет отдавать канал — транком или аксесом, вы решаете сообща. Как правило, для него не составит проблем ни один из вариантов.
Но мы уже настроили транк, поэтому соответствующим образом настраиваем порт на циске:
Вернёмся в Москву. С msk-arbat-gw1 мы можем увидеть адрес 172.16.2.2:
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds:
.
Success rate is 100 percent (5/5), round-trip min/avg/max = 2/7/13 ms
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.16.1, timeout is 2 seconds:
…
Success rate is 0 percent (0/5)
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 8 subnets, 2 masks
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
msk-arbat-gw1(config)#ip route 172.16.16.0 255.255.255.0 172.16.2.2
msk-arbat-gw1#sh ip route
Codes: C — connected, S — static, I — IGRP, R — RIP, M — mobile, B — BGP
D — EIGRP, EX — EIGRP external, O — OSPF, IA — OSPF inter area
N1 — OSPF NSSA external type 1, N2 — OSPF NSSA external type 2
E1 — OSPF external type 1, E2 — OSPF external type 2, E — EGP
i — IS-IS, L1 — IS-IS level-1, L2 — IS-IS level-2, ia — IS-IS inter area
* — candidate default, U — per-user static route, o — ODR
P — periodic downloaded static route
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 9 subnets, 2 masks
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
S 172.16.16.0/24 [1/0] via 172.16.2.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.16.1, timeout is 2 seconds:
.
Success rate is 100 percent (5/5), round-trip min/avg/max = 4/10/24 ms
Вот, казалось бы оно — счастье, но проверим связь с компьютера:
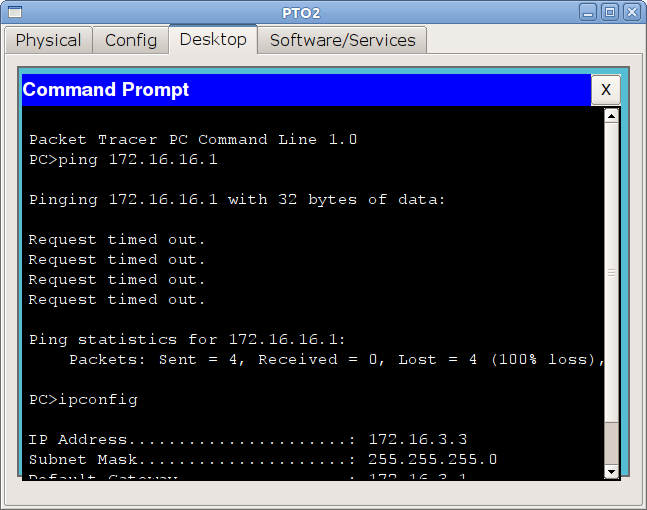
В чём дело?!
Компьютер знает, куда отправлять пакет — на свой шлюз 172.16.3.1, маршрутизатор тоже знает — на хост 172.16.2.2. Пакет уходит туда, принимается spb-vsl-gw1, который знает, что пингуемый адрес 172.16.16.1 принадлежит ему. А обратно нужно отправить пакет на адрес 172.16.3.3, но в сеть 172.16.3.0 у него нет маршрута. А пакеты, сеть назначения которых неизвестна, просто дропятся — отбрасываются.
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 2 subnets, 2 masks
C 172.16.2.0/30 is directly connected, FastEthernet1/0.4
C 172.16.16.0/24 is directly connected, FastEthernet0/0
Но, почему же, спросите вы, с msk-arbat-gw1 до 172.16.16.1 пинг был? Какая разница 172.16.3.1 или 172.16.3.2? Всё просто.
Из таблицы маршрутизации всем видно, что следующий хоп — 172.16.2.2, при этом адрес из 172.16.2.1 принадлежит интерфейсу этого маршрутизатора, поэтому он и ставится в заголовок в качестве IP-адреса отправителя, а не 172.16.3.1. Пакет отправляется на spb-vsl-gw1, тот его принимает, передаёт данные приложению пинг, которое формирует echo-reply. Ответ инкапсулируется в IP-пакет, где в качестве адреса получателя фигурирует 172.16.2.1, а 172.16.2.0/30 — непосредственно подключенная к spb-vsl-gw1 сеть, поэтому без проблем пакет доставляется по назначению. То етсь в сеть 172.16.2.0/30 маршрут известен, а в 172.16.3.0/24 нет.
Для решения этой проблемы мы можем прописать на spb-vsl-gw1 маршрут в сеть 172.16.3.0, но тогда придётся прописывать и для всех других сетей. Для всех сетей в Москве, потом в Кемерово, потом в других городах — очень большой объём настройки.
И тут стоить заметить, что по сути у нас только один выход в мир — через Москву. Узел в Озерках — тупиковый, а других нет. То есть в основном все данные будут уходить в Москву, где большая часть подсетей и будет выход в интернет.
Чем нам это может помочь? Есть такое понятие — маршрут по умолчанию, ещё он носит романтическое название шлюз — последней надежды. И второму есть объяснение. Когда маршрутизатор решает, куда отправить пакет, он просматривает всё таблицу маршрутизации и, если не находит нужного маршрута, пакет отбрасывается — это если у вас не настроен шлюз последней надежды, если же настроен, то сиротливые пакеты отправляются именно туда — просто не глядя, предоставляя право уже следующему хопу решать их дальнейшую судьбу. То есть если некуда отправить, то последняя надежда — маршрут по умолчанию.
Настраивается он так:
И теперь тадааам:
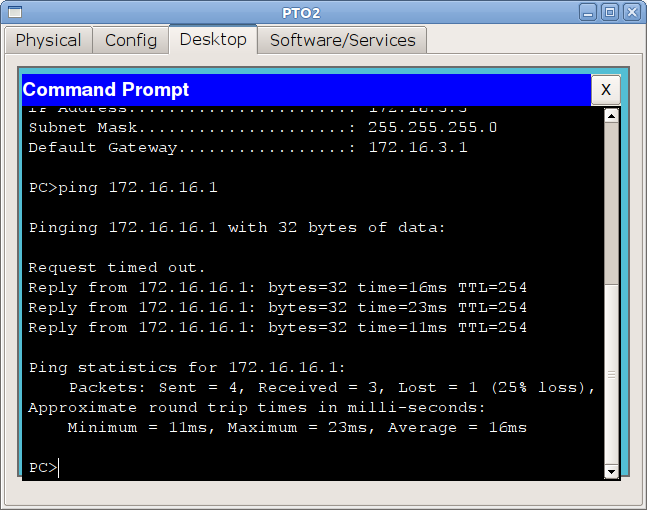
В случае таких тупиковых областей довольно часто применяется именно шлюз последней надежды, чтобы уменьшить количество маршрутов в таблице и сложность настройки.
Санкт-Петербург. Озерки
Теперь озаботимся Озерками. Здесь мы поставим L3-коммутатор. Допустим, связаны они у нас будут арендованным у провайдера волокном (конечно, это идеализированная ситуация для маленькой компании, но можно же помечтать).
Использование коммутаторов третьего уровня весьма удобно в некоторых случаях. Во-первых, интервлан роутинг в этом случае делается аппаратно и не нагружает процессор, в отличие от маршрутизатора. Кроме того, один L3-коммутатор обойдётся вам значительно дешевле, чем L2-коммутатор и маршрутизатор по отдельности. Правда, при этом вы лишаетесь ряда функций, естественно. Поэтому при выборе решения будьте аккуратны.
Настроим маршрутизатор на Васильевском острове, согласно плану:
В качестве некст хопа ставим адрес, который мы выделили для линковой сети на Озерках — 172.16.2.6
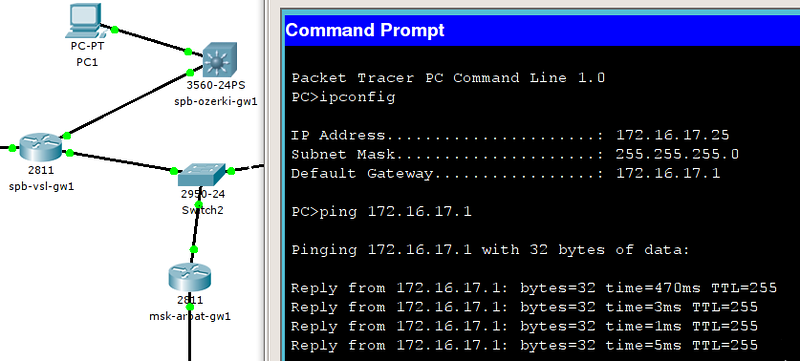
Теперь перенесёмся в сами Озерки:
Подключим кабель в уже настроенный порт fa1/1 на стороне Васильевского острова и в 24-й порт 3560 в Озерках.
По умолчанию все порты L3-коммутатора работают в режиме L2, то есть это обычные “свитчёвые” порты, на которых мы можем настроить вланы. Но любой из них мы можем перевести в L3-режим, сделав портом маршрутизатора. Тогда на нём мы сможем настроить IP-адрес:
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.2.5, timeout is 2 seconds:
.
Success rate is 80 percent (4/5), round-trip min/avg/max = 1/18/61 ms
После этого все устройства во втором влане будут иметь шлюзом 172.16.17.1
Чтобы коммутатор превратился в почти полноценный маршрутизатор, надо дать ещё одну команду:
Таким образом мы включим возможность маршрутизации.
Никаких других маршрутов, кроме как по умолчанию нам тут не надо:
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.16.1, timeout is 2 seconds:
.
Success rate is 100 percent (5/5), round-trip min/avg/max = 3/50/234 ms
А до Москвы нет:
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.3.1, timeout is 2 seconds:
…
Success rate is 0 percent (0/5)
spb-ozerki-gw1#traceroute 172.16.3.1
Type escape sequence to abort.
Tracing the route to 172.16.3.1
1 172.16.2.5 4 msec 2 msec 5 msec
2 * * *
3 * * *
4 *
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 9 subnets, 2 masks
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
S 172.16.16.0/24 [1/0] via 172.16.2.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.17.1, timeout is 2 seconds:
.
Success rate is 100 percent (5/5), round-trip min/avg/max = 4/10/18 ms
Но странной неожиданностью для вас может стать то, что с spb-ozerki-gw1 вы не увидите Москву по-прежнему:
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.3.1, timeout is 2 seconds:
…
Success rate is 0 percent (0/5)
И даже с компьютера 172.16.17.26 связь есть:
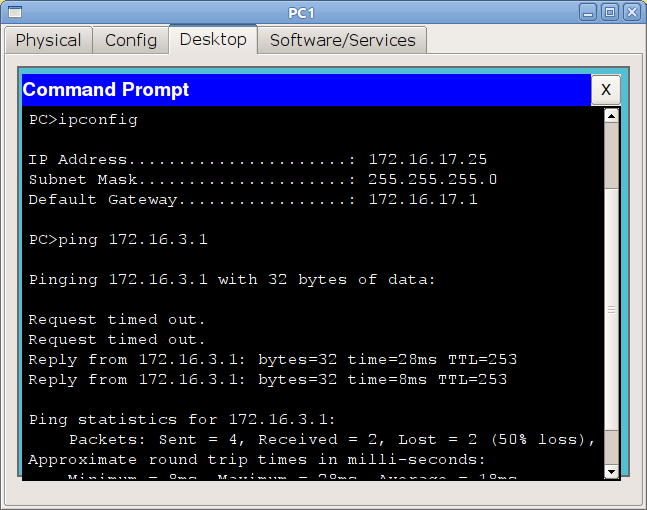
Как же так? Ответ, вы не поверите, так же прост — проблемы с маршрутизацией.
Дело в том, что msk-arbat-gw1 о подсети 172.16.17.0/24 знает, а о 172.16.2.4/30 нет. А именно адрес 172.16.2.6 — адрес ближайшего к адресату интерфейса (или интерфейса, с которого отправляется IP-пакет) подставляет по умолчанию в качестве источника. Об этом забывать не нужно.
msk-arbat-gw1(config)#ip route 172.16.2.4 255.255.255.252 172.16.2.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.3.1, timeout is 2 seconds:
.
Success rate is 100 percent (5/5), round-trip min/avg/max = 7/62/269 ms
В РТ вы этого не увидите, почему-то, но в реальной жизни получится кольцо маршрутизации. Сети 172.16.3.0/24 и 172.16.16.0/21 не будут видеть друг друга:
пакет идущий с spb-ozerki-gw1 в сеть 172.16.3.0 попадает в первую очередь на spb-vsl-gw1, где сказано: “172.16.3.0/24 ищите за 172.16.2.6”, а это снова spb-ozerki-gw1, где сказано: “172.16.3.0/24 ищите за 172.16.2.5” и так далее. Пакет будет шастать туда-обратно, пока не истечёт значение в поле TTL.
Дело в том, что при прохождении каждого маршрутизатора поле TTL в IP-заголовке, изначально имеющее значение 255, уменьшается на 1. И если вдруг окажется, что это значение равно 0, то пакет погибает, точнее маршрутизатор, увидевший это, задропит его.
Таким образом обеспечивается стабильность сети — в случае возникновения петли пакеты не будут жить бесконечно, нагружая канал до его полной утилизации.
Кстати, в Ethernet такого механизма нет и если получается петля, то коммутатор только и будет делать, что плодить широковещательные запросы, полностью забивая канал — это называется широковещательный шторм (эта проблема решается с помощью специальной технологии\протокола STP- об этом в следующем выпуске).
В общем, если вы пускаете пинг из сети 172.16.17.0 на адрес 172.16.3.1, то ваш IP-пакет будет путешествовать между двумя маршрутизаторами, пока не истечёт срок его жизни, пройдя при этом по линку между Озерками и Васильевским островом 254 раза.
Кстати, следствием из работы этого механизма является то, что не может существовать связная сеть, где между узлами больше 255 маршрутизаторов. Впрочем это и не очень актуальная потребность. Сейчас даже самый долгий трейс занимает пару-тройку десятков хопов.
Кемерово. Красная горка
Рассмотрим последний небольшой пример — маршрутизатор на палочке (router on a stick).
Название навеяно схемой подключения:
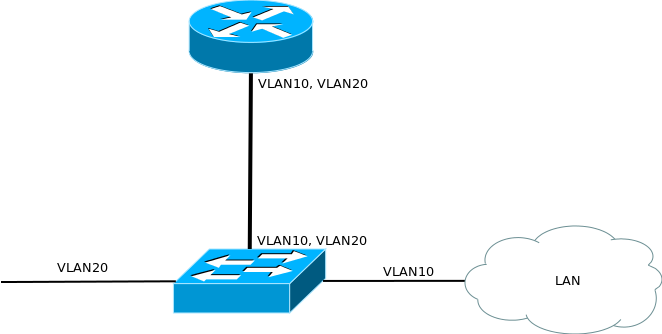
Маршрутизатор связан с коммутатором лишь одним кабелем и по разным вланам внутри него передаётся трафик и локальной сети, и внешний. Делается это, как правило, для экономии средств (на маршрутизаторе только один порт и не хочется покупать дополнительную плату).
Подключим следующим образом:
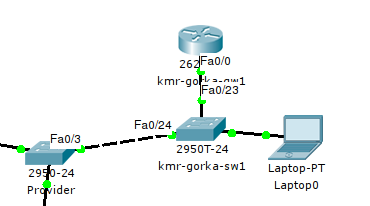
Настройка коммутатора уже не должна для вас представлять проблем. На UpLink-интерфейсе настраиваем оговоренный с провайдером 5-й влан транком:
Switch(config)#hostname kmr-gorka-sw1
kmr-gorka-sw1(config)#vlan 5
kmr-gorka-sw1(config-vlan)#name Moscow
kmr-gorka-sw1(config)#int fa0/24
kmr-gorka-sw1(config-if)#description Moscow
kmr-gorka-sw1(config-if)#switchport mode trunk
kmr-gorka-sw1(config-if)#switchport trunk allowed vlan 5
Транк в сторону маршрутизатора, где 5-ым вланом будут тегироваться кадры внешнего трафика, а 2-м — локального.
Router(config)#hostname kmr-gorka-gw1
kmr-gorka-gw1(config)#int fa0/0.5
kmr-gorka-gw1(config-subif)#description Moscow
kmr-gorka-gw1(config-subif)#encapsulation dot1Q 5
kmr-gorka-gw1(config-subif)#ip address 172.16.2.18 255.255.255.252
kmr-gorka-gw1(config)#int fa0/0
kmr-gorka-gw1(config-if)#no sh
kmr-gorka-gw1(config)#int fa0/0.2
kmr-gorka-gw1(config-subif)#description LAN
kmr-gorka-gw1(config-subif)#encapsulation dot1Q 2
kmr-gorka-gw1(config-subif)#ip address 172.16.24.1 255.255.255.0
Полагаем, что маршрутизацию здесь между Москвой и Кемерово вы теперь сможете настроить самостоятельно.
Дополнительно
Несмотря на то, что в таблице маршрутизации нет отдельной записи для подсети 172.16.17.0, маршрутизатор покажет вам, какой следующий хоп.
И ещё хотелось бы повторить самые важные вещи:
— Когда блок данных попадает на маршрутизатор, заголовок Ethernet полностью отбрасывается и при отправке формируется совершенно новый кадр. Но IP-пакет остаётся неизменным.
— Каждый маршрутизатор в случае статической маршрутизации принимает решение о судьбе пакета исключительно самостоятельно и не знает ничего о чужих таблицах.
— Поиск в таблице идёт НЕ до первой попавшейся подходящей записи, а до тех пор, пока не будет найдено самое точное соответствие (самая узкая маска). Например, если у вас таблица маршрутизации выглядит так:
И вы передаёте данные на 172.16.10.5, то он не пойдёт ни по маршруту через 172.16.2.22 ни через 172.16.2.26, а выберет самую узкую маску (самую длинную) /30 через 172.16.2.30.
— Если IP-адресу получателя не будет соответствовать ни одна запись в таблице маршрутизации и не настроен маршрут по умолчанию (шлюз последней надежды), пакет будет просто отброшен.
На этом первое знакомство с маршрутизацией можно закончить. Нам кажется, что читатель сам видит, сколько сложностей поджидает его здесь, может предположить, какой объём работы предстоит ему, если сеть разрастётся до нескольких десятков маршрутизаторов. Но надо сказать, что в современном мире статическая маршрутизация, не то чтобы не используется, конечно, ей есть место, но в подавляющем большинстве сетей, крупнее районного пионер-нета внедрены протоколы динамической маршрутизации. Среди них OSPF, EIGRP, IS-IS, RIP, которым мы посвятим отдельный выпуск и, скорее всего, не один. Но настройка статической маршрутизации в значительной степени поможет вашему общему пониманию маршрутизации.
В качестве самостоятельного задания попробуйте настроить маршрутизацию между Москвой и Кемерово и ответить на вопрос, почему не пингуются устройства из сети управления.
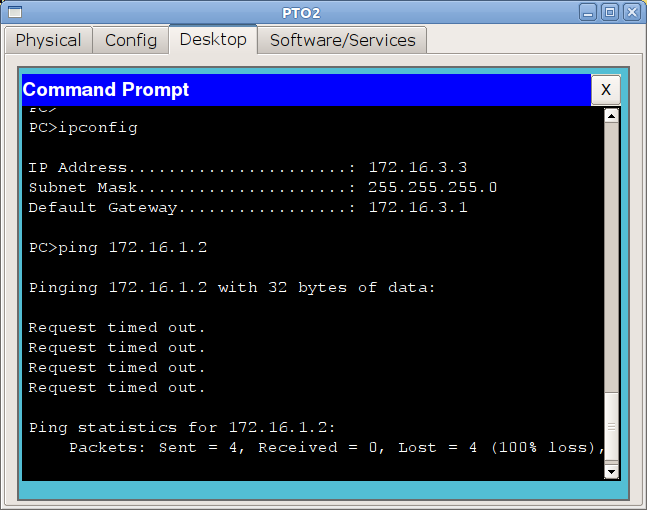
Материалы выпуска
Приносим извинения за гигантские простыни, видео тоже с каждым разом становится всё длиннее и невыносимее. Постараемся в следующий раз быть более компактными.
Все заинтересованные, но незарегистрированные приглашаются на беседу в ЖЖ.
За подготовку статьи большое спасибо моему соавтору thegluck и моей жене за львиное терпение.