мотивация
Задача поиска ближайших соседей очень распространена. Вы можете думать о приложениях, таких как поиск дубликатов или аналогичных документов, поиск аудио / видео. Хотя использование грубой силы для проверки всех возможных комбинаций даст вам точного ближайшего соседа, но это не масштабируется вообще. Приближенные алгоритмы для решения этой задачи были областью активных исследований. Хотя эти алгоритмы не гарантируют точного ответа, чаще всего они дают хорошее приближение. Эти алгоритмы быстрее и масштабируемы.
Локальное хеширование (LSH) является одним из таких алгоритмов. У LSH есть много применений, включая:
- Обнаружение почти дубликатов: LSH обычно используется для дедупликации большого количества документов, веб-страниц и других файлов.
- Общегеномное исследование ассоциации: биологи часто используют LSH для идентификации сходных экспрессий генов в базах данных генома.
- Масштабный поиск изображений: Google использовал LSH вместе с PageRank для создания своей технологии поиска изображений VisualRank,
- Аудио / видео снятие отпечатков пальцев: в мультимедийных технологиях LSH широко используется в качестве метода снятия отпечатков пальцев аудио / видео данных.
В этом блоге мы попытаемся понять работу этого алгоритма.
Главная идея

LSHотносится к семейству функций (известных как семейства LSH) для хеширования точек данных в сегменты, чтобы точки данныхрядом друг с другом расположены в одинаковых ведрах с большой вероятностью, в то время как данные указываютдалеко друг от друга, скорее всего, будут в разных ведрах, Это облегчает идентификацию наблюдений с различной степенью сходства.
Поиск похожих документов
Давайте попробуем понять, как мы можем использовать LSH в решении актуальной проблемы. Проблема, которую мы пытаемся решить:
Цель:Вам были предоставлены большие коллекции документов. Вы хотите найти «почти одинаковые» пары.
В контексте этой проблемы мы можем разбить алгоритм LSH на 3 широких этапа:
- Shingling
- Минимальное перемешивание
- Локальное хеширование
Не читайте много на рисунке сейчас. Это просто, чтобы дать вам представление о ходе процесса. Мы обсудим каждый шаг подробно.
Shingling
На этом этапе мы конвертируем каждый документ внабор символов длиной k (также известный как k-черепица или k-грамм).Основная идея состоит в том, чтобы представлять каждый документ в нашей коллекции как набор k-черепиц.

Например: один из ваших документов (D): «Надаль». Теперь, если нас интересует 2-черепица, тогда наш набор:
- Подобные документы имеют больше шансов
- Изменение порядка абзацев в документе с изменением слов не сильно влияет на опоясывающий лишай
- значение k 8–10обычно используется на практике. Небольшое значение приведет к множеству черепицы, которые присутствуют в большинстве документов (плохо для дифференциации документов)
Жакард Индекс
У нас есть представление каждого документа в виде черепицы. Теперь нам нужен показатель для измерения сходства между документами. Jaccard Index — хороший выбор для этого. Индекс Жакара между документами A и B можно определить как:

Это также известно какпересечение над объединением (IOU),
Предположим, что A: «Надаль» и B: «Надя», тогда представление с двумя черепицами будет:

Индекс Жакара = 2/6
Большее количество общих черепиц приведет к увеличению индекса Жакара и, следовательно, более вероятно, что документы похожи.
Давайте обсудим 2 больших вопроса, которые нам нужно решить:
Сложность времени
Теперь вы можете думать, что мы можем остановиться здесь. Но если вы думаете о масштабируемости, выполнение только этого не сработает. Для сбора n документов необходимо сделатьп * (п-1) / 2сравнение, в основномO (N²), Представьте, что у вас есть 1 миллион документов, тогда число сравнений будет 5 * 10¹¹ (не масштабируется вообще!).
Пространство сложности
Матрица документа является разреженной матрицей, и ее хранение в том виде, в каком оно есть, потребует больших затрат памяти. Одним из способов решения этой проблемы является хеширование.
Идея хеширования состоит в том, чтобы преобразовать каждый документ в небольшую подпись, используя функцию хеширования.ЧАС,Предположим, что документ в нашем корпусе обозначается какд.Затем:
- H (d) — подпись, и она достаточно мала, чтобы уместиться в памяти
- ЕслиСходство (d1, d2)высокая тогдаВероятность (Н (d1) == Н (d2))в приоритете
- ЕслиСходство (d1, d2)то низкоВероятность (Н (d1) == Н (d2))низок
Выбор функции хеширования тесно связан с метрикой подобия, которую мы используем. Для подобия Жакара подходящая хеш-функциямин-хеширование,
Минимальное перемешивание
Это критический и самый магический аспект этого алгоритма, поэтому обратите внимание:
Шаг 1:Случайная перестановка(Π)изиндекс строкиматрицы гальки документа

Шаг 2:Хеш-функция являетсяиндекс первой (в перестановочном порядке) строки, в которой столбец C имеет значение 1.Сделайте это несколько раз (используйте разные перестановки), чтобы создать подпись столбца.



Свойство Min-hash
Сходство сигнатур — это доля мин-хеш-функций (строк), в которых они согласуются. Таким образом, сходство подписи для C1 и C3 составляет 2/3, поскольку 1-я и 3-я строки одинаковы.


Ожидаемое сходство двух подписей равно схожести столбцов Жакара. Чем длиннее подписи, тем ниже ошибка
В приведенном ниже примере вы можете увидеть это в некоторой степени. Есть разница, так как у нас есть подписи только длины 3. Но если увеличить длину, 2 сходства будут ближе.

Таким образом, используя минимальное хеширование, мы решили проблемусложность пространстваустраняя скудность и в то же времясохраняя сходство, В реальной реализации это трюк для создания перестановок индексов, о которых я не буду рассказывать, но вы можете проверить это видео около 15:52. Минимальная реализация
Локальное хеширование
Цель: найти документы со сходством Жакара, по крайней мере, t
Общая идея LSH состоит в том, чтобы найти алгоритм, который, если мы введем подписи двух документов, говорит нам, что эти два документа образуют пару кандидатов или нет, то есть их сходство превышает пороговое значениеT, Помните, что мы берем сходство подписей как прокси для сходства Jaccard между оригинальными документами.
Специально для минимальной хэш-матрицы подписи:
- Хеш столбцы матрицы подписиMиспользуя несколько хеш-функций
- Если 2 документа хэшируются в одно и то же ведро дляхотя бы одиниз хеш-функции мы можем взять 2 документа в качестве пары кандидатов
Теперь вопрос в том, как создавать разные хеш-функции. Для этого мы делаем групповой раздел.
Ленточная перегородка

- Разделите матрицу подписи наб полосыкаждая группа имеетг строк
- Для каждой полосы, хэшируйте свою часть каждого столбца в хеш-таблицу сk ведер
- Пары столбцов-кандидатов — это те, которые хэшируют в одно и то же ведро длякак минимум 1 полоса
- Настройте b и r, чтобы поймать большинство похожих пар, но несколько не похожих пар
Здесь есть несколько соображений. В идеале для каждой полосы мы хотим принять k равным всем возможным комбинациям значений, которые столбец может принимать в пределах полосы. Это будет эквивалентно сопоставлению идентичности. Но в этом случае k будет огромным числом, которое вычислительно невозможно. Например: если для группы у нас есть 5 строк. Теперь, если элементы в сигнатуре являются 32-битными целыми числами, тогда k в этом случае будет (2³²) ⁵
1.4615016e + 48. Вы можете увидеть, в чем проблема здесь. Обычно k берется около 1 миллиона.
Идея состоит в том, что если 2 документа похожи, то они появятся как пара кандидатов, по крайней мере, в одной из полос.
Выбор B & R

Если мы возьмем b большое, то есть большее число хеш-функций, мы уменьшим r, так как b * r является константой (количество строк в матрице сигнатур). Интуитивно это означает, что мыувеличение вероятности нахождения пары кандидатов.Этот случай равносилент (порог сходства)
Допустим, ваша матрица подписи имеет 100 строк. Рассмотрим 2 случая:
Во 2-м случае выше вероятность того, что 2 документа появятся в одной корзине хотя бы один раз, поскольку они имеютбольше возможностей (20 против 10)а такжесравнивается меньше элементов подписи (5 против 10).
Чем выше б, тем нижеПорог сходства (выше ложных срабатываний), а более низкий b означает более высокий порог сходства (выше ложных срабатываний)
Давайте попробуем понять это на примере.
Настроить:
- 100к документов хранятся в виде подписи длиной 100
- Матрица подписи: 100 * 100000
- Сравнение подписей методом грубой силы приведет к сравнению 100C2 = 5 миллиардов (довольно много!)
- Давайте возьмем b = 20 → r = 5
порог сходства (т): 80%
Мы хотим, чтобы 2 документа (D1 и D2) со схожестью 80% хэшировались в одном и том же сегменте как минимум для одной из 20 полос.
P (D1 и D2 идентичны в определенной полосе) = (0,8) ⁵ = 0,328
P (D1 и D2 не одинаковы во всех 20 полосах) = (1–0,328) ^ 20 = 0,00035
Это означает, что в этом сценарии у нас есть
0,035% вероятности ложного отрицания на 80% похожих документов.
Также мы хотим, чтобы 2 документа (D3 и D4) с 30% сходством не хэшировались в одном и том же сегменте ни для одной из 20 полос (порог = 80%).
P (D3 и D4 идентичны в определенной полосе) = (0,3) ⁵ = 0,00243
P (D3 и D4 похожи, по крайней мере, в одной из 20 полос) = 1 — (1–0,00243) ^ 20 = 0,0474
Это означает, что в этом сценарии у нас есть
4,74% вероятности ложного срабатывания при 30% аналогичных документов.
Таким образом, мы можем видеть, что у нас есть несколько ложных срабатываний и несколько ложных отрицательных. Эти пропорции будут варьироваться в зависимости от выбора b и r.
То, что мы хотим здесь, это что-то вроде ниже Если у нас есть 2 документа, сходство которых превышает пороговое значение, то вероятность их совместного использования в одном и том же сегменте хотя бы в одной из полос должна составлять 1, иначе 0.

Наихудший случай будет, если у насb = количество строк в матрице подписикак показано ниже.

Обобщенный случай для любых b и r приведен ниже.

Выберите b и r, чтобы получить лучшую S-кривую, т.е. минимальный уровень ложных отрицательных и ложных положительных результатов.

Резюме по LSH
- мелодияМ, б, гполучить почти все пары документов с одинаковыми подписями, но исключить большинство пар, которые не имеют схожих подписей
- Проверьте в основной памяти, чтопары-кандидатыдействительно естьпохожие подписи
Вывод
Я надеюсь, что вы хорошо понимаете этот мощный алгоритм и как он сокращает время поиска. Вы можете себе представить, как LSH может быть применен буквально к любому виду данных и насколько он актуален в современном мире больших данных.
Locality sensitive hashing — LSH explained
T he problem of finding duplicate documents in a list may look like a simple task — use a hash table, and the job is done quickly and the algorithm is fast. However, if we need to find not only exact duplicates, but also documents with differences such as typos or different words, the problem becomes much more complex. In my case, I’ve had to find duplicates in a very long list of given questions.
Jaccard index
First, we need to define a method of determining whether a question is a duplicate of another. After experimenting with string distance metrics (Levenshtein, Jaro-Winkler, Jaccard index) I’ve come to the conclusion that the Jaccard index performs sufficiently for this use case. The Jaccard index is an intersection over a union. We count the amount of common elements from two sets, and divide by the number of elements that belong to either the first set, the second set, or both. Let’s have a look at the example:
Assuming that we have two following questions:
“Who was the first ruler of Poland”
“Who was the first king of Poland”
We can visualize it in the following sets:
The size of the intersection is 6, while the size of the union is 6 + 1 + 1 = 8, thus the Jaccard index is equal to 6 / 8 = 0.75
We can conclude — the more common words, the bigger the Jaccard index, the more probable it is that two questions are a duplicate. So where we can set a threshold above which pairs would be marked as a duplicate? For now, let’s assume 0.5 as a threshold, but in a real life, we need to get this value by experiment. We could stop here, but current solution makes a number of comparisons growing quadratically (It’s 0.5*(n²-n) where n is the number of questions).
Min part of MinHash
It’s been shown earlier that the Jaccard can be a good string metric, however, we need to split each question into the words, then, compare the two sets, and repeat for every pair. The amount of pairs will grow rapidly. What if we somehow created a simple fixed-size numeric fingerprint for each sentence and then just compare the fingerprints?
In this section I will use following questions:
“Who was the first king of Poland”
“Who was the first ruler of Poland”
“Who was the last pharaoh of Egypt”
And their Jaccard indexes:
J(“Who was the first king of Poland”, “Who was the first ruler of Poland”) = 0.75
J(“Who was the first king of Poland”,“Who was the last pharaoh of Egypt”) = 0.4
J(“Who was the first ruler of Poland”, “Who was the last pharaoh of Egypt”)=0.4
To calculate MinHash we need to create the dictionary (a set of all words) from all our questions. Then, create a random permutation:
(“last”, “Who”, “Egypt”, “king”, “ruler”, “was”, “of”, “Poland”, “pharaoh”, “the”, “first”)
We have to iterate over the rows, writing the index in the respective cell, if the word being checked is present in the sentence.
Now the second row:
Only the first word occurrence is relevant (giving a minimal index — hence the name MinHash). We have a minimum value for all our questions and the first part of the fingerprint. To get the second one we need to create another random permutation and retrace our steps:
Then, we repeat permuting and searching as many times as big we want our fingerprint. For the purpose of example my consists of 6 items. We’ve already had 2, so let’s create 4 more permutations:
(“first”, “king”, “Egypt”, “was”, “Who”, “of”, “pharaoh”, “last”, “Poland”, “ruler”, “the”)
(“ruler”, “king”, “Poland”, “Who”, “the”, “pharaoh”, “of”, “first”, “Egypt”, “last”, “was”)
(“king”, “Poland”, “ruler”, “last”, “pharaoh”, “the”, “Who”, “Egypt”, “first”, “of”, “was”)
(“the”, “pharaoh”, “Who”, “ruler”, “Poland”, “Egypt”, “king”, “last”, “was”, “first”, “of”)
Our complete MinHashes are:
MinHash(“Who was the first king of Poland”) = [2, 1, 1, 2, 1, 1]
MinHash(“Who was the first ruler of Poland”) = [2, 1, 1, 1, 1, 1]
MinHash(“Who was the last pharaoh of Egypt”) = [1, 1, 3, 4, 4, 1]
Now we can check how similar are two MinHashes by calculating their Jaccard indexes:
MinHashSimilarity(“Who was the first king of Poland”, “Who was the first ruler of Poland”) = 5/6 ≈ 0.83
MinHashSimilarity(“Who was the first king of Poland”, “Who was the last pharaoh of Egypt”) = 2/6 ≈ 0.33
MinHashSimilarity(“Who was the first ruler of Poland”, “Who was the last pharaoh of Egypt”) = 2/6 ≈ 0.33
Well, that’s really close to their Jaccard indexes, and the more permutations we do, the closer the approximations get. How’s that possible?
Let’s analyze how we calculate the Jaccard index. We need to look at our table. Considering only two questions, we can create a table like the following:
A — where the word is present in both questions
B —it’s present in one of them
C — it’s in the dictionary, but in neither of the questions
We can write the formula for the Jaccard index as a/(a+b) where a is a number of rows of type A and b of type B
Now since we have random permutations, let’s count a probability that two questions will have an equal fingerprint component. We can skip type C rows since they do not interfere in any way with a component value calculation (If we consider only two questions). So what is the probability that we will take type A row, from the set of A and B rows? P = a/(a + b) which is exactly the same as Jaccard index! That explains why our approximations were close and why more permutations mean better approximations.
Hash part of MinHash
We now have an algorithm which could potentially perform better, but the more documents the bigger the dictionary, and thus the higher the cost of creating permutations, both in time and hardware. Instead of creating n permutations we can take a hash function (like md5, sha256 etc.) use it on every word in the question and find a minimal hash value. It will be the first element of the fingerprint, then we will take another hash function, and so on until we have our n elements in the fingerprint. Wait, but why does it work?
Let’s wonder what permutation does — it basically maps each word from dictionary to a different number. The fact that mapped numbers are integers increased by one is not important to us.
What are hash functions doing? Simplifying — they map string to a number, so basically the same as the permutation! How is that better? We don’t need the whole dictionary before — if the new question appears we can easily calculate its MinHash. Also, we don’t need to scan the whole dictionary for each question and create a permutation of the whole dictionary. Both of these operations are pretty costly. We just saved a lot of our and our’s computer time.
So now we can compute a fingerprint and compare it easily, but still we need to compare every fingerprint with all others. This is bad. Exponentially bad.
Let’s look back at our MinHashes:
MinHash(“Who was the first king of Poland”) = [2, 1, 1, 2, 1, 1]
MinHash(“Who was the first ruler of Poland”) = [2, 1, 1, 1, 1, 1]
MinHash(“Who was the last pharaoh of Egypt”) = [1, 1, 3, 4, 4, 1]
Now group them by three elements:
MinHash(“Who was the first king of Poland”) =[2, 1, 1, 2, 1, 1] => [211, 211]
MinHash(“Who was the first ruler of Poland”) =[2, 1, 1, 1, 1, 1] => [211, 111]
MinHash(“Who was the last pharaoh of Egypt”)=[1, 1, 3, 4, 4, 1]=>[113,441]
What can we see? Our duplicates have one common group (first) where unique has no common groups. Since still, we’re talking about probability influenced issue let’s calculate what is the probability of at least one common group for duplicates:
- Probability of one specific element common in fingerprint = Jaccard index = P1 = 0.75
- Probability that all elements in one group are identical = Jaccard index to number of elements in group power = P2 = 0.75³ = 0.421875
- Probability that group will be different = P3 = 1-P2 = 0.578125
- Probability that all groups will be different = P4 to number of groups power = P3² = 0.334228516
- And finally — Probability that at least one group will be common = P5 = 1 — P4 = 0.665771484
So general equation will look like this: P5 = 1 — (1 — J^n)^b
Where:
J — Jaccard index
n — number of elements in group
b — number of groups
And probability for our unique question is 1 — (1–0.4³)² = 0.123904 — much lower. We could also make 3 groups 2 elements each. Here is plot:
Let’s analyze it: For the pair with J = 0.5 and b = 3, there is only 0.25 probability that we would find it as a duplicate. However, with b = 3 there is about 0.6 probability that we would mark it as a duplicate. What does it mean in practice? — More false positives for b = 3 and more false negatives for b = 2. We need to choose carefully our parameters, but more on that later.
Now we do not need to count anything — if there is a common group we can mark it as duplicates. We can just create lists with single groups:
[211, 211]
[211, 111]
[113, 441]
↓
[
211 => “Who was the first king of Poland”,
211 => “Who was the first ruler of Poland”,
113 => “Who was the last pharaoh of Egypt”
]
And
[
211 => “Who was the first king of Poland”,
111 => “Who was the first ruler of Poland”,
441 => “Who was the last pharaoh of Egypt”
]
It looks familiar to Hashtable! We can put columns of groups in the hash table and check for collision. Collision means that we hit a duplicate. And operations on the hash table have worst case scenario complexity of O(n), so our algorithm (of course depends on implementation) have potential to be also O(n) complex. Way better than O(n²) we had at the beginning.
Tweaking
After what we’ve learned so far we know that LSH takes, 3 arguments:
k — number of elements in MinHash
n — number of elements in groups (or buckets)
b — number of buckets and b*n must equal k
Our goal is to mark as duplicate every pair, or more, that have Jaccard index >= 0.17, so our probability chart should look like this:
Achieving step function is impossible in our case, so by manipulating our 3 parameters we need to approximate this as close as possible having in mind that bigger the k, more computing power we need (more hashes to calculate). After experiments, I’ve found that 200 for k is good starting value and it also has many divisors. Although 240 has more, so it would be my next shot.
As we can see b = 100 n = 2 or b = 50 n = 4 are the ones closest to reference. We should use both and then compare results.
One thing left — where to get 200 hash functions? Two example solutions:
- use MurmurHash with 200 different seeds
- create our own hash function by taking the output of md5 or another hash function and making XOR with some random number. Example python code:
def myFirstHash(string):
return md5(hash) ^ 636192
def mySecondHash(string):
return md5(hash) ^ 8217622
# And so on.
# But do it in a loop!
Warning — LSH can, and sometimes will produce accidental collisions, so at the end, we still need to compare all questions in given collision but it will be much much fewer operations than comparing all to each other.
And that would be all for now. In next article, I will show example implementation and some benchmarks.
Locality Sensitive Hashing (LSH): The Illustrated Guide
Locality sensitive hashing (LSH) is a widely popular technique used in approximate nearest neighbor (ANN) search. The solution to efficient similarity search is a profitable one — it is at the core of several billion (and even trillion) dollar companies.
Big names like Google, Netflix, Amazon, Spotify, Uber, and countless more rely on similarity search for many of their core functions.
Amazon uses similarity search to compare customers, finding new product recommendations based on the purchasing history of their highest-similarity customers.
Every time you use Google, you perform a similarity search between your query/search term — and Google’s indexed internet.
If Spotify manages to recommend good music, it’s because their similarity search algorithms are successfully matching you to other customers with a similarly good (or not so good) taste in music.
LSH is one of the original techniques for producing high quality search, while maintaining lightning fast search speeds. In this article we will work through the theory behind the algorithm, alongside an easy-to-understand implementation in Python!
You can find a video walkthrough of this article here:
Search Complexity
Imagine a dataset containing millions or even billions of samples — how can we efficiently compare all of those samples?
Even on the best hardware, comparing all pairs is out of the question. This produces an at best complexity of O(n²). Even if comparing a single query against the billions of samples, we still return an at best complexity of O(n).
We also need to consider the complexity behind a single similarity calculation — every sample is stored as a vector, often very highly-dimensional vectors — this increases our complexity even further.
How can we avoid this? Is it even possible to perform a search with sub-linear complexity? Yes, it is!
The solution is approximate search. Rather than comparing every vector (exhaustive search) — we can approximate and limit our search scope to only the most relevant vectors.
LSH is one algorithm that provides us with those sub-linear search times. In this article, we will introduce LSH and work through the logic behind the magic.
Locality Sensitive Hashing
When we consider the complexity of finding similar pairs of vectors, we find that the number of calculations required to compare everything is unmanageably enormous even with reasonably small datasets.
Let’s consider a vector index. If we were to introduce just one new vector and attempt to find the closest match — we must compare that vector to every other vector in our database. This gives us a linear time complexity — which cannot scale to fast search in larger datasets.
The problem is even worse if we wanted to compare all of those vectors against each other — the optimal approach sorting method to achieve this is at best log-linear time complexity.
So we need a way to reduce the number of comparisons. Ideally, we want only to compare vectors that we believe to be potential matches — or candidate pairs.
Locality sensitive hashing (LSH) allows us to do this.
LSH consists of a variety of different methods. In this article, we’ll be covering the traditional approach — which consists of multiple steps — shingling, MinHashing, and the final banded LSH function.
At its core, the final LSH function allows us to segment and hash the same sample several times. And when we find that a pair of vectors has been hashed to the same value at least once , we tag them as candidate pairs — that is, potential matches.
It is a very similar process to that used in Python dictionaries. We have a key-value pair which we feed into the dictionary. The key is processed through the dictionary hash function and mapped to a specific bucket. We then connect the respective value to this bucket.
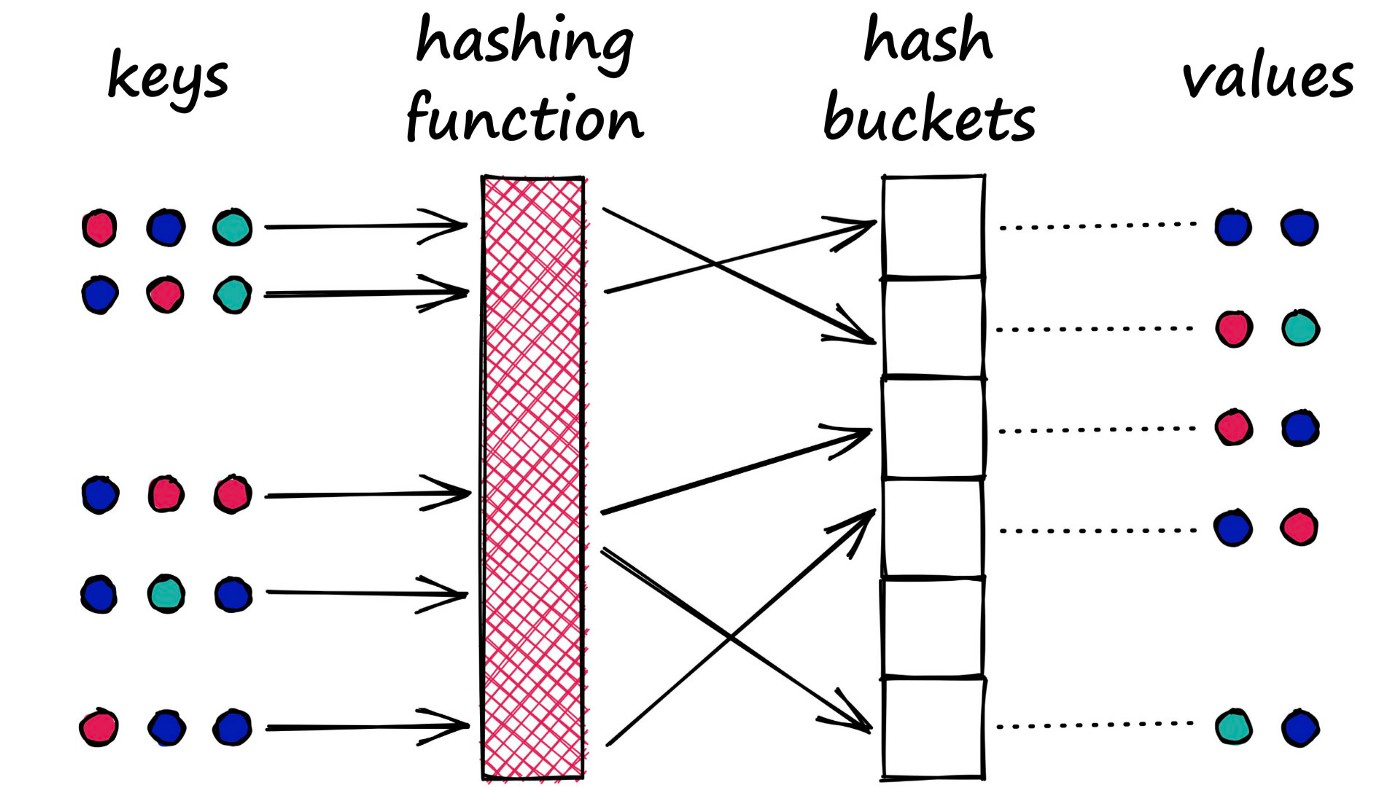
However, there is a key difference between this type of hash function and that used in LSH. With dictionaries, our goal is to minimize the chances of multiple key-values being mapped to the same bucket — we minimize collisions.
LSH is almost the opposite. In LSH, we want to maximize collisions — although ideally only for similar inputs.
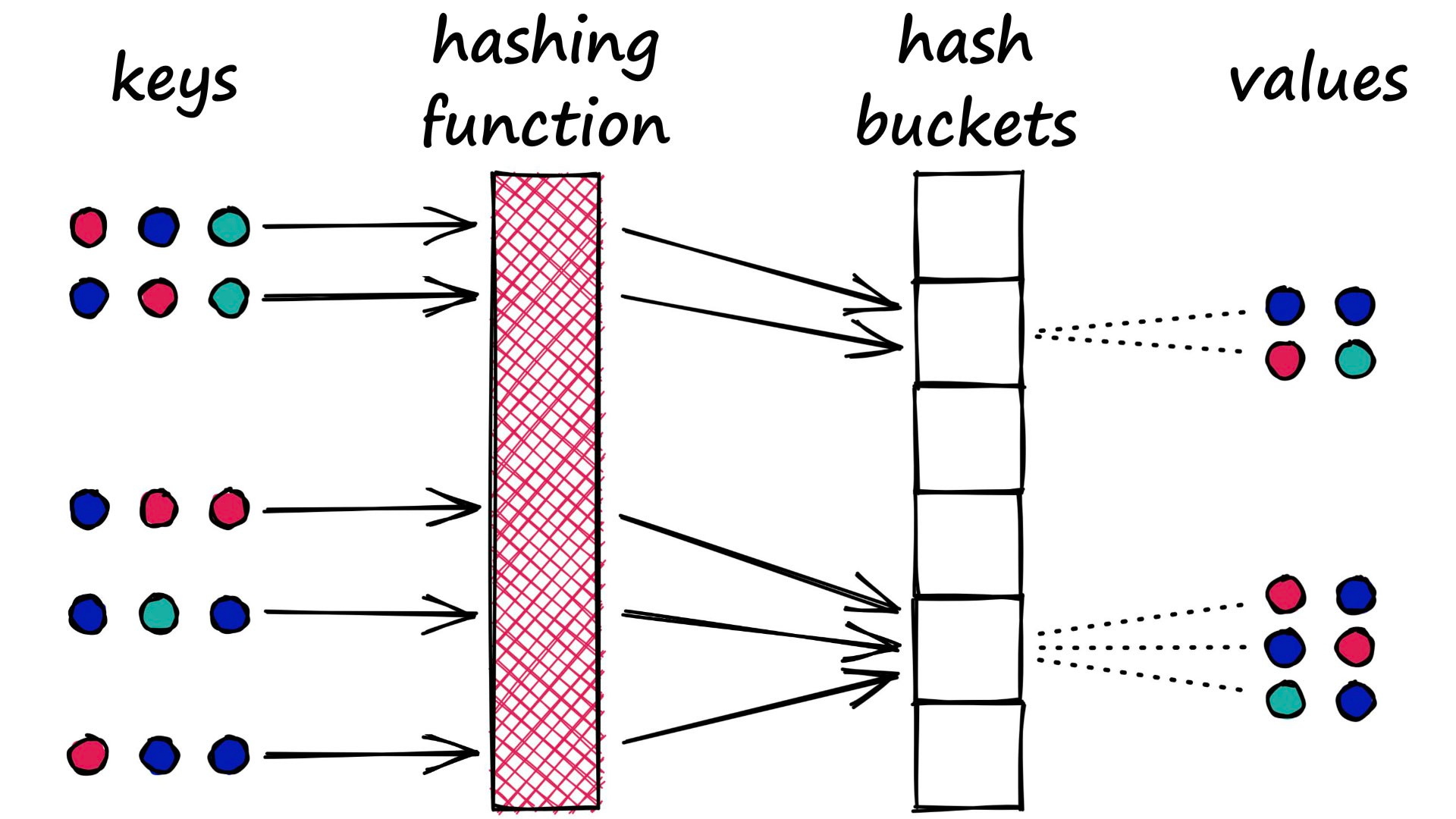
There is no single approach to hashing in LSH. Indeed, they all share the same ‘bucket similar samples through a hash function’ logic , but they can vary a lot beyond this.
The method we have briefly described and will be covering throughout the remainder of this article could be described as the traditional approach, using shingling, MinHashing, and banding.
There are several other techniques, such as Random Projection which we cover in another article.
Shingling, MinHashing, and LSH
The LSH approach we’re exploring consists of a three-step process. First, we convert text to sparse vectors using k-shingling (and one-hot encoding), then use minhashing to create ‘signatures’ — which are passed onto our LSH process to weed out candidate pairs.
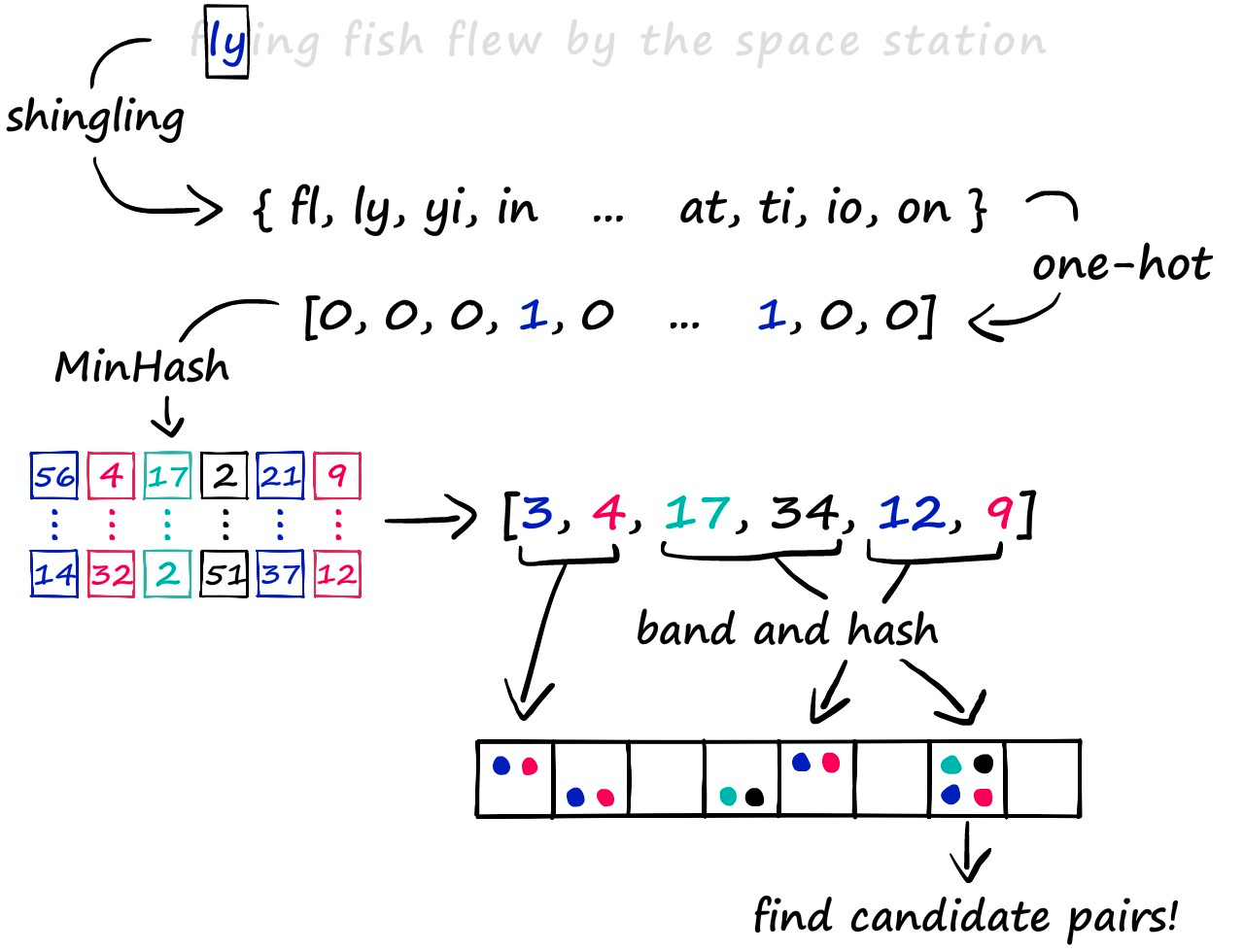
We will discuss some of the other LSH methods in future articles. But for now, let’s work through the traditional process in more depth.
k-Shingling
k-Shingling, or simply shingling — is the process of converting a string of text into a set of ‘shingles’. The process is similar to moving a window of length k down our string of text and taking a picture at each step. We collate all of those pictures to create our set of shingles.
Shingling also removes duplicate items (hence the word ‘set’). We can create a simple k-shingling function in Python like so:
Обзор алгоритмов локальночувствительного хеширования Серебряков В А 1

Постановка задачи Вместо попарного сравнения записей желательн 0: 1. Сравнивать не записи, а их короткие «заменители» 2. Каким-то образом заранее разбить все множество записей на группы кандидатов, предположительно имеющих сходство. 3

Меры близости • • • Расстояние d должно удовлетворять следующим аксиомам: 1. d(x, y) ≥ 0 (неотрицательно). 2. d(x, y) = 0 титтк x = y (0 только для совпадающих точек). 3. d(x, y) = d(y, x) (симметрия). 4. d(x, y) ≤ d(x, z) + d(z, y) (свойство треугольника). Мера Jaccard схожести множеств S и T — это |S∩T|/|S T |, т. е. отношение числа элементов в пересечении к числу элементов в объединении. • Косинусная мера: скалярное произведение векторов. • Угловая мера: угол между векторами/180. • Расстояние Хэмминга между битовыми векторами: |S XOR T|. • Евклидово расстояние d([x 1, x 2, . . . , xn], [y 1, y 2, . . . , yn]) =(∑i(xi − yi)2)1/2 Меру схожести между S и T будем обозначать SIM(S, T). 4
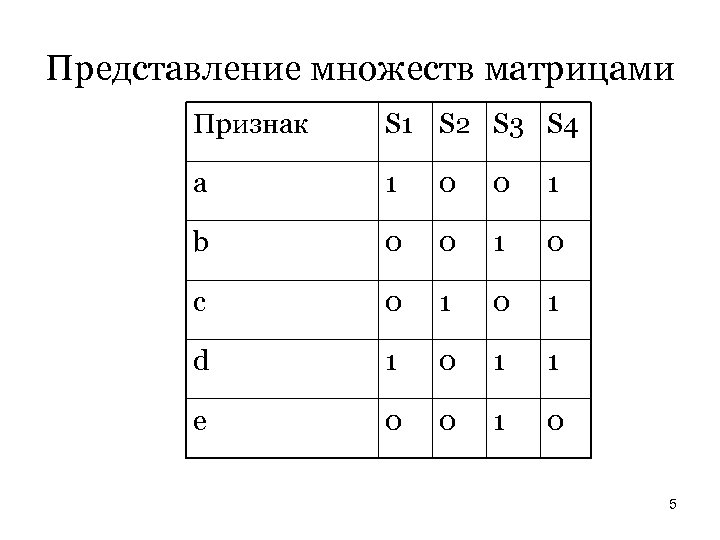
Представление множеств матрицами Признак S 1 S 2 S 3 S 4 a 1 0 0 1 b 0 0 1 0 c 0 1 d 1 0 1 1 e 0 0 1 0 5

Minhashing Broder, Andrei Z. ; Charikar, Moses; Frieze, Alan M. ; Mitzenmacher, Michael (1998), "Minwise independent permutations", Proc. 30 th ACM Symposium on Theory of Computing (STOC '98), New York, NY, USA: Association for Computing Machinery, pp. 327– 336 Нам надо заменить большие множества значительно меньшими представлениями, называемыми «Следами» (“fingerprints”, “signatures”, “sketches”). Основное свойство следов – возможность сравнения следов двух множеств для оценки меры схожести Jaccard исходных множеств. Ясно, что они не могут дать точного значения меры схожести. Далее предполагается, что след – результат вычисления hash-функции. Для вычисления minhash представим множество колонкой характеристической матрицы и выберем перестановку строк. Значение minhash колонки – это номер первой строки перестановки, в которой колонка имеет 1. Каждая перестановка определяет свою hash-функцию. На предыдущем слайде h(S 1)=1, h(S 2)=3, h(S 3)=2, h(S 4)=1. Для перестановки (3, 1, 5, 4, 2) получаем матрицу 6
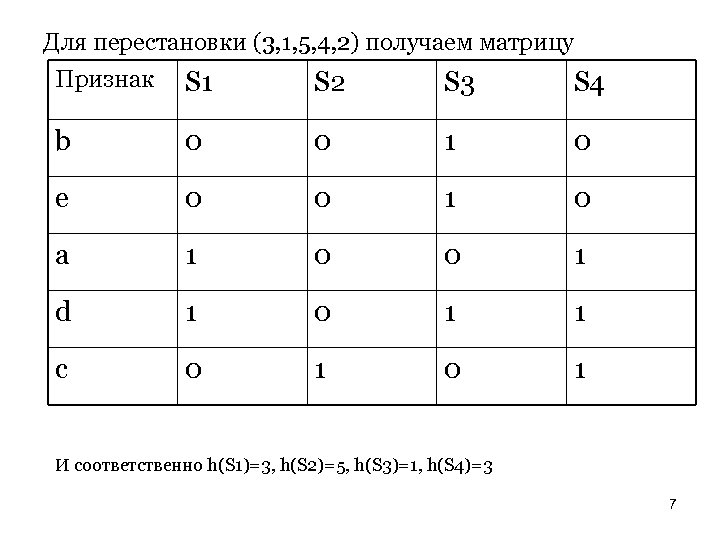
Для перестановки (3, 1, 5, 4, 2) получаем матрицу Признак S 1 S 2 S 3 S 4 b 0 0 1 0 e 0 0 1 0 a 1 0 0 1 d 1 0 1 1 c 0 1 И соответственно h(S 1)=3, h(S 2)=5, h(S 3)=1, h(S 4)=3 7

Minhashing и мера Jaccard Имеет место замечательная связь между Minhashing и мерой Jaccard: Вероятность того, что функция Minhash для случайной перестановки строк дает одно и то же значение для двух множеств, равна мере Jaccard этих множеств. Рассмотрим матрицу для двух множеств. Строки можно разделить на три категории: X. 1 в обеих колонках Y. 1 в одной колонке и 0 в другой Z. 0 в обеих колонках. Поскольку строки типа Z нас не интересуют, вероятность того, что при движении сверху-вниз будет встречена строка вида X, равна |X|/(|X|+|Y|), а это и есть мера Jaccard. 8

Minhash множества Пусть теперь мы сделали n перестановок h 1, h 2, . . . , hn. Этот набор перестановок будем называть minhash. Для каждой колонки S назовем minhash следом S вектор [h 1(S), h 2(S), . . . , hn(S)]. Т. о. из характеристической матрицы мы формируем матрицу следов, в которой iя колонка – это minhash след i-й колонки характеристической матрицы. Попарная близость колонок hi(Sj) = hi(Sk) совпадает с мерой Jaccard множеств Sj и Sk. 9
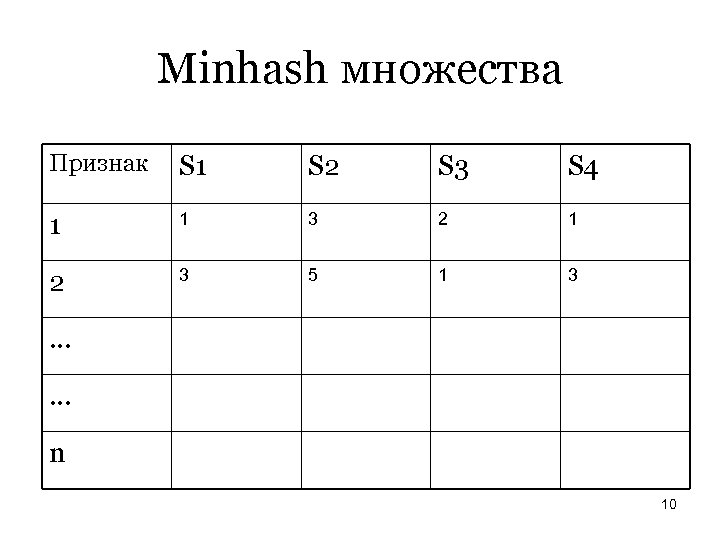
Minhash множества Признак S 1 S 2 S 3 S 4 1 1 3 2 1 2 3 5 1 3 … … n 10
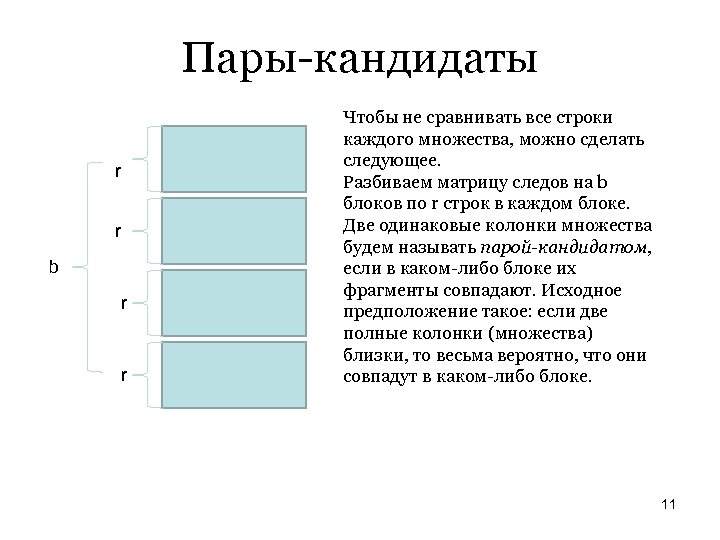
Пары-кандидаты r r b r r Чтобы не сравнивать все строки каждого множества, можно сделать следующее. Разбиваем матрицу следов на b блоков по r строк в каждом блоке. Две одинаковые колонки множества будем называть парой-кандидатом, если в каком-либо блоке их фрагменты совпадают. Исходное предположение такое: если две полные колонки (множества) близки, то весьма вероятно, что они совпадут в каком-либо блоке. 11

Вычисление вероятностей Предположим, что документы имеют схожесть s. Тогда вероятность, что следы этих документов совпадают в отдельно взятой строке, равна s. Вероятность того, что эти документы (точнее их следы) образуют парукандидат, вычисляется следующим образом: 1. Вероятность того, что следы равны во всех строках одного блока sr. 2. Вероятность того, что следы НЕ равны по крайней мере в одной строке блока 1 -sr. 3. Вероятность того, что следы НЕ равны по крайней мере в одной строке каждого блока (1 -sr)b. 4. Вероятность того, что следы равны во всех строках по крайней мере одного блока и поэтому становятся кандидатами на близость 1 -(1 -sr)b. Это вероятность того, что два документа, имеющие схожесть s, при данных значениях b и r будут отобраны как пары кандидаты. 12
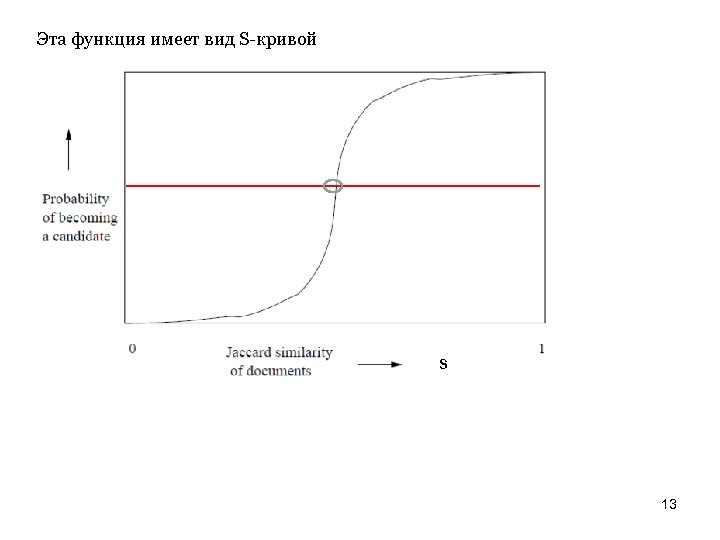
Эта функция имеет вид S-кривой s 13

Алгоритм слияния 1. Выбрать n для следов. 2. Выбрать значение s, которое определяет документы как близкие. Выбрать b число блоков и r число строк такие, что br = n и значение 1(1 -sr)b было максимальным. 3. Отобрать пары-кандидаты. 4. Проверить каждую пару кандидатов и определить действительно ли доля компонент, в которой они равны, не меньше t. 5. Опционально: сравнить сами документы. 14

Локально чувствительное хеширование Indyk, Piotr. ; Motwani, Rajeev. (1998). "Approximate Nearest Neighbors: Towards Removing the Curse of Dimensionality. ". Proceedings of 30 th Symposium on Theory of Computing. Gionis, A. ; Indyk, P. ; Motwani, R. (1999). "Similarity Search in High Dimensions via Hashing". Proceedings of the 25 th Very Large Database (VLDB) Conference. При поиске дубликатов даже попарное сравнение следов может оказаться нереализуемым. Но часто нас интересует не точное совпадение, а совпадение с некоторой точностью. 15
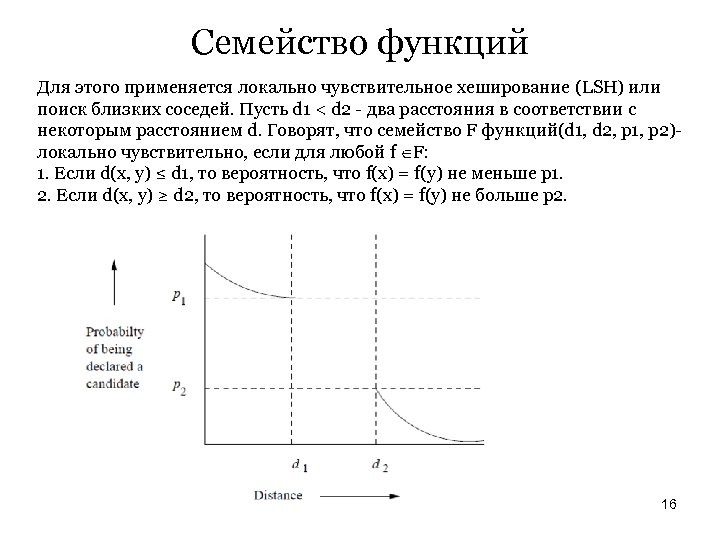
Семейство функций Для этого применяется локально чувствительное хеширование (LSH) или поиск близких соседей. Пусть d 1 < d 2 — два расстояния в соответствии с некоторым расстоянием d. Говорят, что семейство F функций(d 1, d 2, p 1, p 2)локально чувствительно, если для любой f F: 1. Если d(x, y) ≤ d 1, то вероятность, что f(x) = f(y) не меньше p 1. 2. Если d(x, y) ≥ d 2, то вероятность, что f(x) = f(y) не больше p 2. 16

Эквивалентное определение M. S. Charikar, “Similarity estimation techniques from rounding algorithms" Proc. ACM STOC, pp. 380 -388, 2002. Схема локально-чувствительного хэширования – это семейство F хэш функций над множеством объектов такое, что для двух объектов x, y, Prf F[f(x) = f(y)] = sim(x, y) 17

OR расширение локально чувствительного семейства функций Если определить f(x) = f(y) тттк fi(x) = fi(y) для одного или более значений i, получим OR-конструкцию – по (d 1, d 2, p 1, p 2)-чувствительному семейству F строится (d 1, d 2, 1 − (1 − p 1)b, 1 − (1 − p 2)b)-чувствительное семейство F′. Если f F′– это множество

AND расширение локально чувствительного семейства функций Пусть нам дано (d 1, d 2, p 1, p 2)-чувствительно семейство F. Мы можем сконструировать новое семейство F′ с помощью конструкции AND над F следующим образом. Каждый член F′ состоит из r членов F для некоторого фиксированного r. Если f принадлежит F′, и f строится по множеству

LSH для расстояния Hamming Пусть h(x, y) расстояние Хэмминга между векторами x и y. Можно определить функцию fi(x) как i-й бит вектора x. Тогда fi(x) = fi(y) титтк векторы x и y совпадают в i-й позиции. Тогда вероятность того, что fi(x) = fi(y) для случайно выбранного i равна 1 − h(x, y)/d (d – число бит), т. е. доле совпадающих позиций. Это в точности совпадает с ситуацией с minhashing. Т. о. семейство F, состоящее из функций

Случайные гиперплоскости и угловое расстояние Similarity Estimation Techniques from Rounding Algorithms Moses S. Charikar Dept. of Computer Science Princeton University Построим семейство функций следующим образом: Каждая функция f строится по случайно выбранному вектору v. Если даны два вектора x и y, будем говорить, что f(x) = f(y) титтк когда скалярные произведения (v, x) и (v, y) имеют один и тот же знак. Тогда F – локальночувствительное семейство с угловым (косинус) расстоянием. Его параметры те же, что и для семейства с расстоянием Jaccard, за исключением того, что расстояние меняется 0– 180, а не 0– 1. Т. е. , F (d 1, d 2, (180 − d 1)/180, (180 − d 2)/180)-локально чувствительное семейство хэш-функций. 21
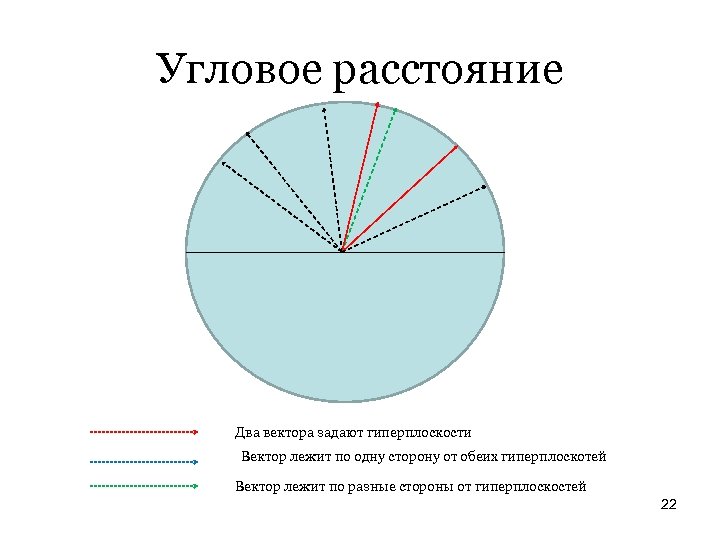
Угловое расстояние Два вектора задают гиперплоскости Вектор лежит по одну сторону от обеих гиперплоскотей Вектор лежит по разные стороны от гиперплоскостей 22

Вычисление Sim. Hash Для каждого документа – это скалярное произведение Sim. Hash = (вектор характеристик, случайный вектор). Хэш-функция f – это случайный вектор. Плоскость задается вектором характеристик документа. Знак скалярного произведения (т. е. элемента Sim. Hash) определяется положением случайного вектора относительно плоскости. Sim. Hash –это AND локальночувствительное семейство хэш функций для набора случайных векторов. Разные знаки скалярного произведения означают, что случайные векторы расположены по разные стороны от плоскости. Если в векторах Sim. Hash двух разных документов стоят разные знаки, значит соответствующий случайный вектор расположен по разные стороны относительно гиперплоскостей двух документов. Ищем между расстояние Хэмминга между векторами Sim. Hash двух разных документов. 23

Для случая библиографических записей Имеем N биграмм. Для каждой биграммы b имеем вектор h(b) и вес w(b). h(b) – это случайный вектор. Получаем матрицу M: Биграмма х h(b). Заменяем в матрице 0 на -1, получаем столбцы – векторы из 1 и -1 – это нормальные векторы для гиперплоскостей. Берем случайный вектор из значений биграмм данного множества (документа), скалярно умножаем на каждый из векторов матрицы, получаем либо >=0, либо <0. Это определяет, лежит ли вектор из значений биграмм данного множества (документа) по одну или другую сторону от гиперплоскости, определяемой ее вектором. Заменяем значение >=0 на 1, значение <0 на 0, получаем вектор следов. Строго говоря, получаем косинус угла, а не сам угол, что требуется по Теореме, но они не сильно расходятся. 24
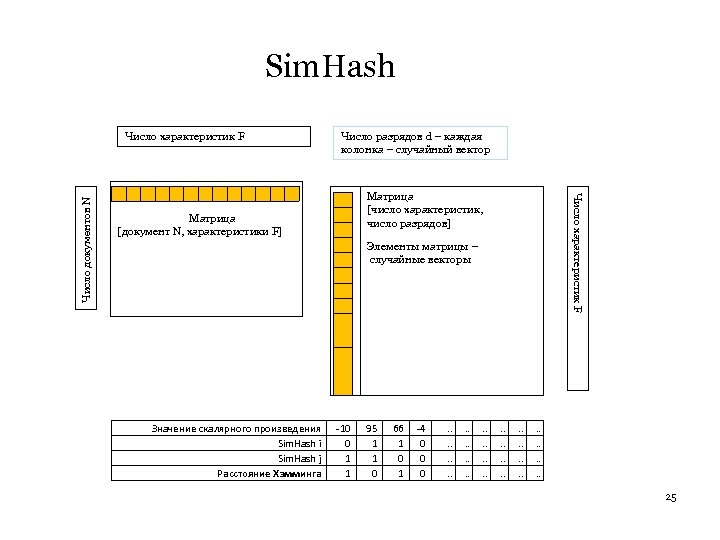
Sim. Hash Число разрядов d – каждая колонка – случайный вектор Матрица [число характеристик, число разрядов] Матрица [документ N, характеристики F] Число характеристик F Число документов N Число характеристик F Элементы матрицы – случайные векторы Значение скалярного произведения Sim. Hash i Sim. Hash j Расстояние Хэмминга -10 0 1 1 95 1 1 0 66 1 0 1 -4 0 0 0 . . . 25

Алгоритм получения случайных векторов 26

Проблема расстояния Хэмминга G. S. Manku, A. Jain, and A. Das Sarma, Detecting near-duplicates for web crawling, " Proc. ACM WWW, pp. 141 -150, 2007. Пусть d – длина simhash, в нашем случае 64. Пусть S – общее число записей, т. е. «задействованных» simhash, в нашем случае примерно 225. Обозначим S=2 f, т. е. в нашем случае f=25. Пусть k – критерий поиска, т. е. по скольким битам мы ищем различия, т. е при заданном simhash q мы ищем во множестве S такие, которые отличаются от q не более, чем в k битах. Идея заключается в том, чтобы разбить d на группы. Выделенные биты образуют входы в таблицу. Остальные биты сравниваем на расстояние k. Необходимо и достаточно, чтобы таких групп было k+1. k берем исходя из меры Jaccard. Если это 0. 75, то k=16. На самом деле это вопрос. Отношение «расстояние Jaccard» не транзитивно, так что не есть отношение эквивалентности. Мы не можем, отталкиваясь от записи, набрать все, отстоящие на J. Если взять слишком большое k, то такие группы будут очень большими, если маленькое – можем не поймать нужные. С другой стороны, поскольку мы ищем эквивалентные записи, то содержательно должны быть группы эквивалентности. Формально это определить нельзя. 27
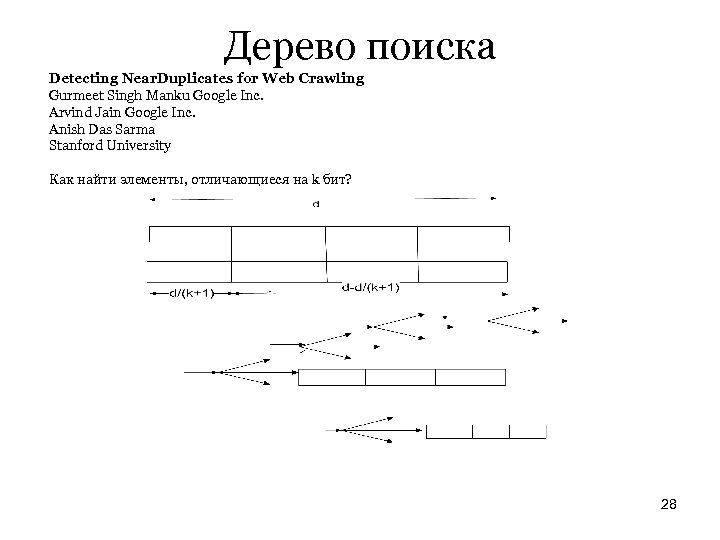
Дерево поиска Detecting Near. Duplicates for Web Crawling Gurmeet Singh Manku Google Inc. Arvind Jain Google Inc. Anish Das Sarma Stanford University Как найти элементы, отличающиеся на k бит? 28

Попарное сравнение На предыдущем шаге для каждой записи выбираются записи-кандидаты на попарное сравнение. Затем пары сравниваются. Сравнение заключается в построении биграмм и сопоставлении множеств этих биграмм. 29

Сложность Для данного q сложность поиска равна (число таблиц)*(lg длины таблицы, т. е. число бит, по которым строится таблица) * (сложность поиска во множестве). При n это все равно n 2 , но реально при n<=264 30

Результаты Сервер: 2. Процессор – Intel(R) Xeon(R) CPU E 5645 @ 2. 40 GHz x 2, два процессора. 24 виртуальных ядра, 12 реальных ядер. 3. Оперативная память – 98238 MBytes DDR 3. 1066 Mhz 4. Жесткие диски – RAID 0 Intel Multi-Flex SCSI Disk Device. Cредняя скорость чтения данных – 150 MB/s Windows Server 2012 Standard. 31

Результаты Алгоритм выявления дублетных библиографических записей обработал 21 313 009 записей. Для обработки такого объема данных на указанном сервере потребовалось 90 часов. В результате работы алгоритма было выявлено, что 1 239 293 библиографические записи являются дублетами какой-нибудь другой записи. Уникальных записей, т. е. записей, для которых не существует ни одного дублета, оказалось 19 066 057. Статистика по количеству дублетных записей 0 — 19 066 057 1 — 699 687 2 — 101 490 3 — 29 247 4 — 11 655 5 — 6 777 … 71 — 500 32