Основы T-SQL. DML
Для добавления данных применяется команда INSERT , которая имеет следующий формальный синтаксис:
Вначале идет выражение INSERT INTO , затем в скобках можно указать список столбцов через запятую, в которые надо добавлять данные, и в конце после слова VALUES скобках перечисляют добавляемые для столбцов значения.
Например, пусть ранее была создана следующая база данных:
Добавим в нее одну строку с помощью команды INSERT:
После удачного выполнения в SQL Server Management Studio в поле сообщений должно появиться сообщение «1 row(s) affected»:
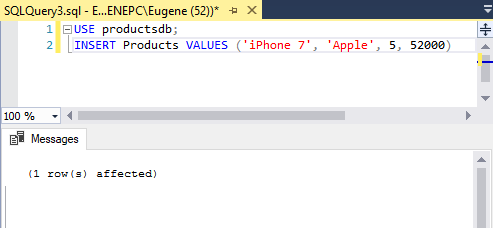
Стоит учитывать, что значения для столбцов в скобках после ключевого слова VALUES передаются по порядку их объявления. Например, в выражении CREATE TABLE выше можно увидеть, что первым столбцом идет Id. Но так как для него задан атрибут IDENTITY, то значение этого столбца автоматически генерируется, и его можно не указывать. Второй столбец представляет ProductName, поэтому первое значение — строка «iPhone 7» будет передано именно этому столбцу. Второе значение — строка «Apple» будет передана третьему столбцу Manufacturer и так далее. То есть значения передаются столбцам следующим образом:
ProductName: ‘iPhone 7’
Также при вводе значений можно указать непосредственные столбцы, в которые будут добавляться значения:
Здесь значение указывается только для трех столбцов. Причем теперь значения передаются в порядке следования столбцов:
ProductName: ‘iPhone 6S’
Для неуказанных столбцов (в данном случае ProductCount) будет добавляться значение по умолчанию, если задан атрибут DEFAULT, или значение NULL. При этом неуказанные столбцы должны допускать значение NULL или иметь атрибут DEFAULT.
Также мы можем добавить сразу несколько строк:
В данном случае в таблицу будут добавлены три строки.
Также при добавлении мы можем указать, чтобы для столбца использовалось значение по умолчанию с помощью ключевого слова DEFAULT или значение NULL:
В данном случае для столбца ProductCount будет использовано значение по умолчанию (если оно установлено, если его нет — то NULL).
Если все столбцы имеют атрибут DEFAULT, определяющий значение по умолчанию, или допускают значение NULL, то можно для всех столбцов вставить значения по умолчанию:
Но если брать таблицу Products, то подобная команда завершится с ошибкой, так как несколько полей не имеют атрибута DEFAULT и при этом не допускают значение NULL.
Добавление данных при помощи Management Studio
3. В результате откроется таблица. Сетка этой таблицы должна отображать строки данных, содержащиеся в таблице, но, поскольку данных еще нет, сетка пуста и готова к добавлению записей (строк). Обратите внимание на черную стрелку-треугольник слева. Это маркер текущей записи, который обозначает запись, на которую направлены действия пользователя. В данном случае, этот маркер не уместен, но он станет полезным, когда в таблице будет содержаться хотя бы несколько записей.
4. Эта операция сводится к тому, чтобы ввести информацию в необходимые столбцы. Однако, если вы осуществите ввод не во все столбцы и оставите пустым столбец, ввод данных в который обязателен, то получите сообщение об ошибке. Нажатие клавиши "стрелка вниз" приводит к тому, что позиция ввода (и указатель текущей записи) перемещается вниз. В этот момент SQL-сервер попытается обновить в таблице запись, которую вы покидаете.
5. Щелкнув на ОК, мы вернемся назад и сможем доввести недостающие данные. Завершив ввод, мы снова нажмем клавишу стрелка вниз, при этом база данных обновится. Обратите внимание на следующий факт: несмотря на то, что введена лишь первая запись в таблице, в столбце видим значение 2. Очередное значение идентификатора генерируется при каждой попытке вставить запись, вне зависимости от успеха этой попытки. Следствием этого факта могут стать пробелы в нумерации строк. Эта проблема легко решается при помощи Query Editor. При необходимости, можно сбросить текущее значение счетчика таким образом, что Query Editor начнет отсчет с более желательного для вас числа. Синтаксис этой команды несложен:
· имя таблицы, в которой вы хотите сбросить счетчик автоматических значений, необходимо заключить в апострофы (одинарные кавычки).
· параметр NORESEED можно использовать для того, чтобы получить от SQL-сервера предполагаемое значение счетчика, то есть иными словами, максимальное из имеющихся в столбце значений,
· счетчик для таблицы можно сбросить автоматически, просто указав параметр RESEED без значения. При этом будет просмотрена вся таблица и счетчик примет наибольшее из существующих уже значений. Альтернативная возможность заключается в том, чтобы явным образом указать желаемое значение счетчика, отделив его запятой от зарезервированного слова RESEED.
Удаление данных
Удаление данных из таблицы производится командой DELETE. Ее синтаксис:
Одной командой можно удалять записи только из одной таблицы.
Удалять записи из таблицы можно также при помощи Management Studio.
1. Откройте Management Studio, откройте базу данных и найдите нужную таблицу. Щелкните на ее значке правой кнопкой мыши, выберите в контекстном меню команду Edit Table 200 rows
1. В результате будут выбраны строки таблицы. Выделите произвольную строку щелчком на серой вертикальной панели слева. В примере выделена верхняя строка.
2. Теперь нажмите клавишу Delete. В ответ на экране появится окно сообщения, запрашивающее ваше подтверждение. Чтобы удалить запись, щелкните нa Yes (Да).
3. 4. В результате вы увидите, что запись из таблицы удалена.
4. Другой способ удалить запись состоит в том, чтобы щелкнуть на соответствующей строке правой кнопкой мыши и выбрать в контекстном меню команду Delete
Все операции удаления строк посредством оператора DELETE записываются в журнал транзакций. Каждый раз, когда удаляется запись, этот факт регистрируется в журнале транзакций. Если вы удаляете очень много записей из таблицы до того, как закрыть транзакцию, ваш журнал транзакций будет расти очень быстро. В этой ситуации, чтобы не расходовать ресурсы, используют команду TRUNCATE TABLE.
Оператор TRUNCATE TABLE удаляет все записи и таблице без обработки транзакций и без ведения журнала. Синтаксис команды усечения таблицы
TRUNCATE TABLE имя_таблицы
При использовании команды TRUNCATE TABLE после закрытиятранзакции никакого способа восстановитьудаленные таким образом данные не существует. Удаляются все записи, невозможно удалить записи выборочно.Одно из ограничений этой команды заключается в том, что ее нельзя применять к таблицам, содержащим внешние ключи.
Удаление таблицы
Другой способ быстро удалить данные из таблицы состоит в том, чтобы удалить саму таблицу, а затем заново ее создать. Чтобы удалить таблицу, используйте следующий код:
DROP TABLE имя_таблицы
Команда DROP TABLE не может удалить таблицу, содержащую внешние ключи. В такой ситуации необходимо удалить вначале ключи, а затем уже удалять таблицу.
Транзакции
Транзакция представляет собой единицу работы, которая должна быть подвергнута тесту ACID (Atomicity,Consistency, Isolation и Durability — Атомарность, Целостность, Изоляция и Окончательность), прежде чем быть классифицированной, как транзакция.
В своей простевшей форме атомарность означает: все изменения данных, входящие в транзакцию, должны быть успешно завершены, или же отменены все вместе, то есть изменения, которые к моменту сбоя уже успели произойти, должны быть отменены.
Вне зависимости от того, принята транзакция или отменена, целостность данных должна сохраниться.
Любые изменения данных, проводимые в рамках транзакции, должны быть изолированы от изменений, идущих в рамках любой другой транзакции. Каждая транзакция должна видеть данные в том состоянии, которое они либо имели до начала другой транзакции, либо пробрели после ее завершения. Невозможно увидеть промежуточное состояние данных, которое они имеют в процессе выполнения транзакции.
После того как транзакция завершена, все данные приобрели свое окончательное состояние. и изменить их можно только при помощи другой транзакции. Любой системный сбой (как программный, так и аппаратный) не должен повлиять на состояние данных после завершения транзакции.
В транзакцию можно заключить любые манипуляции с данными, будь то обновление, вставка или удаление. Речь может идти о манипуляциях с единственной записью или с набором записей. Транзакции нужны только в тех случаях, когда данные в результате манипуляций изменяются, и может возникнуть необходимость отменить внесенные изменения. При работе с транзакциями нужно помнить, что, начав транзакцию, вы блокируете часть таблицы или даже всю таблицу и, при определенных настройках базы данных, можете сделать невозможной работу других пользователей. Более того, в результате выполнении транзакции может возникнуть тупиковая ситуация.
По этой причине рекомендуется делать транзакции небольшими, короткими и ни при каких обстоятельствах не удерживать блокировку более чем на несколько секунд. Чтобы достигнуть этого, необходимо помещать в транзакцию минимальное число строк кода и принимать в последующем коде решение об отмене транзакции или ее принятии настолько быстро, насколько это вообще возможно.
Транзакция состоит из двух основных элементов. Это начало (старт) транзакции и окончание транзакции, когда мы решаем, принять транзакцию или отменить ее. Команда BEGIN TRAN объявляет начало транзакции. Собственно транзакция стартует с момента выполнения этой команды. Начиная с итого момента и оканчивая моментом выполнения одной из двух команд — COMMIT TRAN или ROLLBACK TRAN — любые операции, вносящие изменения в данные, относятся к данной транзакции.
Команду BEGIN TRAN можно дополнить именем транзакции длиной до 32 символов. Если вам потребуется вложенная транзакция, то есть транзакция, стартующая внутри другой транзакции, то именем можно снабдить только "внешнюю" транзакцию.
Команда COMMIT TRAN завершает транзакцию и записывает все изменения в базу данных. После выполнения этой команды отмена изменений становится невозможной. Это команда должна выполняться только тогда, когда все изменения уже готовы для того, чтобы стать окончательными.
Если нам потребуется отменить все изменения, которые успели внести операции, относящиеся к текущей транзакции (например, по причине возникших ошибок), то мы можем использовать команду ROLLBACK TRAN. Представьте себе следующую ситуацию: мы начали транзакцию командой BEGIN TRAN, затем успешно вставили строку в таблицу командой INSERT, а потом команда UPDATE завершилась с ошибкой. Мы можем "откатить" таблицу к предыдущему состоянию, то есть состоянию еще до выполнения команды INSERT при помощи команды ROLLBACK TRAN. Таким образом, команда INSERT также будет отменена, несмотря на то, что она была выполнена успешно и без ошибок.
Основное назначение блокировок состоит в том, чтобы начавшаяся транзакция, которая вносит изменения в данные и "знает", что их, возможно, придется затем отменить, могла быть твердо "уверенной" в том, что никакая другая транзакция к этому моменту не изменит данные еще раз. Однако с таким подходом связана одна проблема, заключающаяся в следующем: SQL-сервер не может просто блокировать данные, уже подвергшиеся изменению в транзакции. Блокируются данные, которые изменены не завершившейся транзакцией(блокировка на уровне строки или записи), но сервер может заблокировать и всю базу данных (блокировка на уровне базы данны х). Между этими двумя крайними случаями есть целый ряд промежуточных уровней, поэтому можно заблокировать большие или меньшие ресурсы, в зависимости от выполняемых операций.
Блокировками SQL-сервер управляет автоматически, но понимание происходящих при этом процессов позволит вам эффективно использовать блокировки в ваших транзакциях.
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
SQL Server. Создание базы данных, таблиц и связей между ними
В этой статье мы научимся работать с основными объектами базы данных — таблицами, в которых хранится вся информация баз данных.
База данных представляет собой хранилище объектов. Основные из них:
- Таблицы: хранят данные
- Представления (Views): выражения языка SQL, которые возвращают набор данных в виде таблицы
- Хранимые процедуры: выполняют код на языке SQL по отношению к данным к БД (например, получает данные или изменяет их)
- Функции: также код SQL, который выполняет определенную задачу
Используется два типа баз данных: системные и пользовательские. Системные базы данных необходимы серверу SQL для корректной работы. А пользовательские базы данных создаются пользователями сервера и могут хранить любую произвольную информацию. Их можно изменять и удалять, создавать заново. Собственно это те базы данных, которые мы будем создавать и с которыми мы будем работать.
Системные базы данных
В MS SQL Server по умолчанию создается четыре системных баз данных:
- master: эта главная база данных сервера, в случае ее отсутствия или повреждения сервер не сможет работать. Она хранит все используемые логины пользователей сервера, их роли, различные конфигурационные настройки, имена и информацию о базах данных, которые хранятся на сервере, а также ряд другой информации.
- model: эта база данных представляет шаблон, на основе которого создаются другие базы данных. То есть когда мы создаем через SSMS свою бд, она создается как копия базы model.
- msdb: хранит информацию о работе, выполняемой таким компонентом как планировщик SQL. Также она хранит информацию о бекапах баз данных.
- tempdb: эта база данных используется как хранилище для временных объектов. Она заново пересоздается при каждом запуске сервера.
Все эти базы можно увидеть через SQL Server Management Studio в узле Databases -> System Databases:

Эти базы данных не следует изменять, за исключением бд model.
Если на этапе установки сервера был выбран и установлен компонент PolyBase, то также на сервере по умолчанию будут расположены еще три базы данных, которые используется этим компонентом: DWConfiguration, DWDiagnostics, DWQueue.
Создание базы данных в SQL Management Studio
Теперь создадим свою базу данных. Для этого мы можем использовать скрипт на языке SQL, либо все сделать с помощью графических средств в SQL Management Studio.
В данном случае мы выберем второй способ. Для этого откроем SQL Server Management Studio и нажмем правой кнопкой мыши на узел Базы данных. Затем в появившемся контекстном меню выберем пункт Создать базу данных:

После этого нам открывается окно для создания базы данных:

В поле Имя базы данных необходимо ввести название новой бд. Следующее поле Владелец задает владельца базы данных. По умолчанию оно имеет значение <по умолчанию>, то есть владельцем будет тот, кто создает эту базу данных. Оставим все как есть.
Далее идет таблица для установки общих настроек базы данных. Она содержит две строки — первая для установки настроек для главного файла, где будут храниться данные, и вторая строка для конфигурации файла логирования. В частности, мы можем установить следующие настройки:
- Логическое имя: логическое имя, которое присваивается файлу базы данных.
- Тип файла: есть несколько типов файлов, но, как правило, основная работа ведется с файлами данных (ROWS Data) и файлом лога (LOG)
- Файловая группа: означает группу файлов. Группа файлов может хранить множество файлов и может использоваться для разбиения базы данных на части для размещения в разных местах.
- Начальный размер (MБ): устанавливает начальный размер файлов при создании (фактический размер может отличаться от этого значения).
- Автоувеличение/Максимальный размер: при достижении базой данных начального размера SQL Server использует это значение для увеличения файла.
- Путь: каталог, где будут храниться базы данных.
- Имя файла: непосредственное имя физического файла. Если оно не указано, то применяется логическое имя.
После ввода названия базы данных нажмем на кнопку ОК, и бд будет создана.
После этого она появится среди баз данных сервера. Если эта бд впоследствии не потребуется, то ее можно удалить, нажав на нее правой кнопкой мыши и выбрав в контекстном меню пункт Удалить.
Создание таблиц, отношения таблиц, внешние ключи
Ключевым объектом в базе данных являются таблицы. Таблицы состоят из строк и столбцов. Столбцы определяют тип информации, которая хранится, а строки содержат значения для этих столбцов.
Типы данных SQL SERVER
- для строк лучше всего использовать nvarchar (ни в коем случае не используйте nchar, при этом длина строки строго зафиксирована и не зависит от содержимого — т.е. сложно потом будет сравнивать строки, т.к. они будут дополняться ненужными нам пробелами). Если поле очень большое, то лучше использовать nvarchar(MAX) или text, но при этом размер должен быть адекватным, чтобы не замедлять работу в дальнейшем
- для чисел используйте int, float . Важный момент — не нужно всех поражать своим знанием типов и использовать long там, где можно использовать int. Это в дальнейшем немного усложнит обработку таких значений в C# (т.е. по возможности не удивляйте своих коллег такими моментами, лучше удивите их быстрыми запросами SQL)
- булевский тип — bit
- деньги храните либо в типе money, либо в decimal (18,2) , либо в банке
- дата и время – тип datetime . Важный момент – изучите различные функции работы с датами (getdate, datediff, dateadd и др) – это будет часто встречаться
- очень важный тип – это uniqueidentifier . Это GUID – уникальный 32-битный код. Его особенность в том, что каждое новое значение — уникально (вероятность дубля критически мала). Идентификаторы GUID в первую очередь используются для назначения идентификаторов, которые должны быть уникальными в рамках сети, содержащей много компьютеров в различных расположениях. Значение идентификатора GUID для столбца uniqueidentifier формируется с помощью функции newid() .
В прошлой теме была создана база данных university. Теперь определим в ней первую таблицу. Опять же для создания таблицы в SQL Server Management Studio можно применить скрипт на языке SQL, либо воспользоваться графическим дизайнером. В данном случае выберем второе.
Для этого раскроем узел базы данных university в SQL Server Management Studio, нажмем на его подузел Таблицы правой кнопкой мыши и далее в контекстном меню выберем Создать -> Таблица.

После этого нам откроется дизайнер таблицы. В центральной части в таблице необходимо ввести данные о столбцах таблицы. Дизайнер содержит три поля:
- Имя столбца: имя столбца
- Тип данных: тип данных столбца. Тип данных определяет, какие данные могут храниться в этом столбце. Например, если столбец представляет числовой тип, то он может хранить только числа.
- Разрешить значения Null: может ли отсутствовать значение у столбца, то есть может ли он быть пустым
Допустим, нам надо создать таблицу с данными учащихся в учебном заведении. Для этого в дизайнере таблицы четыре столбца: Id, FirstName, LastName и Year, которые будут представлять соответственно уникальный идентификатор пользователя, его имя, фамилию и год рождения. У первого и четвертого столбца надо указать тип int (то есть целочисленный), а у столбцов FirstName и LastName — тип nvarchar(50) (строковый).
Затем в окне Properties, которая содержит свойства таблицы, в поле Name надо ввести имя таблицы — Students, а в поле Identity ввести Id, то есть тем самым указывая, что столбец Id будет идентификатором.
Имя таблицы должно быть уникальным в рамках базы данных. Как правило, название таблицы отражает название сущности, которая в ней хранится. Например, мы хотим сохранить студентов, поэтому таблица называется Students (слово студент во множественном числе на английском языке). Существуют разные мнения по поводу того, стоит использовать название сущности в единственном или множественном числе (Student или Students). В данном случае вопрос наименования таблицы всецело ложится на разработчика базы данных.
И в конце нам надо отметить, что столбец Id будет выполнять роль первичного ключа (primary key). Первичный ключ уникально идентифицирует каждую строку. В роли первичного ключа может выступать один столбец, а может и несколько.
Для установки первичного ключа нажмем на столбец Id правой кнопкой мыши и в появившемся меню выберем пункт Задать первичный ключ.
После этого напротив поля Id должен появиться золотой ключик. Этот ключик будет указывать, что столбец Id будет выполнять роль первичного ключа.
И после сохранения в базе данных university появится таблица Students:
Мы можем заметить, что название таблицы на самом деле начинается с префикса dbo. Этот префикс представляет схему. Схема определяет контейнер, который хранит объекты. То есть схема логически разграничивает базы данных. Если схема явным образом не указывается при создании объекта, то объект принадлежит схеме по умолчанию — схеме dbo.
Нажмем правой кнопкой мыши на название таблицы, и нам отобразится контекстное меню с опциями:

С помощью этих опций можно управлять таблицей. Так, опция Delete позволяет удалить таблицу. Опция Design откроет окно дизайнера таблицы, где мы можем при необходимости внести изменения в ее структуру.
Для добавления начальных данных можно выбрать опцию Изменить первые 200 строк. Она открывает в виде таблицы 200 первых строк и позволяет их изменить. Но в нашей таблице пока пусто, т.к. только что ее создали..
Создание таблиц и связей между ними с помощью диаграмм
В SSMS есть удобный графический инструмент для создания таблиц, а также для установки связей между ними — это диаграммы. Правой клавишей кликаем на пункт “диаграммы баз данных”, далее выбираем “создать диаграмму базы данных”
Далее может появиться вот такое сообщение (т.к. таблиц пока нет) :

Нажимаем “да” и видим следующее окно:

После этого кликаем правой кнопкой мышки по экрану и выбираем пункт “создать таблицу”:

Задаем название таблицы:

После создания таблицы добавляем колонки таблицы, указав их тип:

Добавляем первичный ключ (primary key). Для этого кликаем правой кнопкой мышки на поле рядом с названием “id” и выбираем “задать первичный ключ”:, рядом с “id” появится золотой ключик.

После перемещаемся на правую панель:

Здесь мы меняем значение на “да” (если нужно чтоб у id был автоинкремент, выбираем начальное значение “id”, а также шаг автоинкремента).
Таким образом создаем нужные таблицы. Таблицы можно менять местами, увеличивать или отдалять.
Несколько слов о связях между таблицами.
Выделяют следующие типы связей:
- один к одному
- один ко многим
- многие ко многим
Связь один к одному : встречается не часто, объекту одной сущности соответствует один объект другой сущности (пример: один пользователь один блог). Иными словами первичный ключ зависимой таблицы в то же время является внешним ключом, который ссылается на первичный ключ из главной таблицы.
Связь один ко многим : самый часто встречающийся тип связей. Несколько строк из зависимой (дочерней) таблицы зависят от одной строки главной (родительской) таблицы. Пример: в одной группе много студентов.
Связь многие ко многим : одна строка из одной таблицы (А) может быть связана с множеством строк из другой таблицы (Б). В свою очередь одна строка из таблицы Б может быть связана со множеством строк из таблицы А. Однако в SQL server нельзя установить связь многие ко многим между двумя таблицами. Это можно сделать с помощью вспомогательной промежуточной таблицы (иногда данные из этой таблицы представляют как отдельную сущность).
Теперь задаем связи между таблицами. Для этого в таблице, где есть внешний ключ (foreign key) нажимаем левой кнопкой мышки на поле рядом с названием внешнего ключа и не отпуская тянем на вторую таблицу к полю “id”
Создание таблиц в Microsoft SQL Server (CREATE TABLE) – подробная инструкция
Привет, сегодня я Вам расскажу о том, как создаются таблицы в Microsoft SQL Server, при этом мы рассмотрим примеры создания таблиц как с помощью графического интерфейса, специально для начинающих, так и с помощью инструкции CREATE TABLE языка T-SQL.
В прошлой статье «Создание базы данных в Microsoft SQL Server» я рассказывал, как создаются пустые базы данных, в которых еще нет таблиц, поэтому сегодня, в продолжение того материала я покажу, как создаются таблицы, в которые и будут добавляться и храниться все данные.
Как было уже отмечено, создать таблицу в Microsoft SQL Server можно двумя способами: первый — с помощью графического конструктора SQL Server Management Studio (SSMS), и второй — с помощью инструкции на языке T-SQL.
Заметка! Для комплексного изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL, в которых используется последовательная методика обучения и рассматриваются все конструкции языка SQL и T-SQL.
Исходные данные для примера
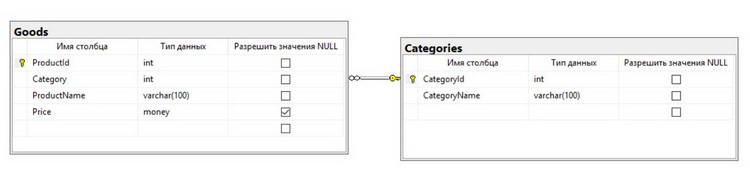
Давайте представим, что нам нужно реализовать базу данных со следующую структурой (пример структуры тестовый). В ней у нас будет две таблицы, и они будут содержать следующие столбцы:
- Goods – таблица будет содержать информацию о товарах:
- ProductId – идентификатор товара, столбец не может содержать значения NULL, первичный ключ;
- Category – ссылка на категорию товара, столбец не может содержать значения NULL, но имеет значение по умолчанию, например, для случаев, когда товар еще не распределили в необходимую категорию, в этом случае товару будет присвоена категория по умолчанию («Не определена» или «Не указана»);
- ProductName – наименование товара, столбец не может содержать значения NULL;
- Price – цена товара, столбец может содержать значения NULL, например, с ценой еще не определились.
- CategoryId – идентификатор категории, столбец не может содержать значения NULL, первичный ключ;
- CategoryName – наименование категории, столбец не может содержать значения NULL.
При этом внести товар с несуществующей категорией нельзя, поэтому мы добавим еще и ограничение внешнего ключа.
Примечание! В качестве сервера у меня выступает версия Microsoft SQL Server 2017 Express, как ее установить, можете посмотреть в моей видео-инструкции.
Итак, давайте приступим.
Создание таблицы в Microsoft SQL Server с помощью Management Studio
Запускаем среду SQL Server Management Studio.
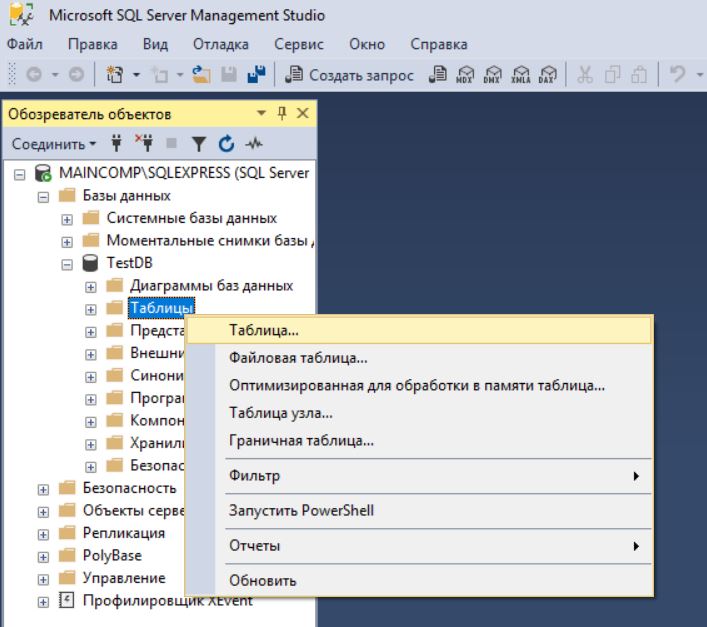
В обозревателе объектов открываем контейнер «Базы данных», затем открываем нужную базу данных и щелкаем правой кнопкой мыши по пункту «Таблицы», и выбираем «Таблица».
У Вас откроется конструктор таблиц. В нем будет всего три колонки:
- Имя столбца – сюда пишем название столбца;
- Тип данных – выбираем тип данных для этого столбца, подробней о типах данных можете почитать в статье «Типы данных в Microsoft SQL Server»;
- Разрешить значения NULL – если поставить галочку, то столбец сможет принимать значение NULL.
Заполняем эти колонки, сначала в соответствии с нашей тестовой структурой таблицы Categories.
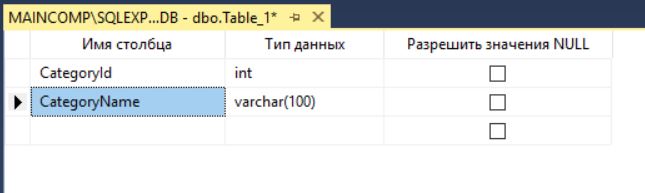
После этого нам нужно определить первичный ключ, для этого щелкаем правой кнопкой мыши по нужному столбцу (в нашем случае это CategoryId) и выбираем пункт «Задать первичный ключ».
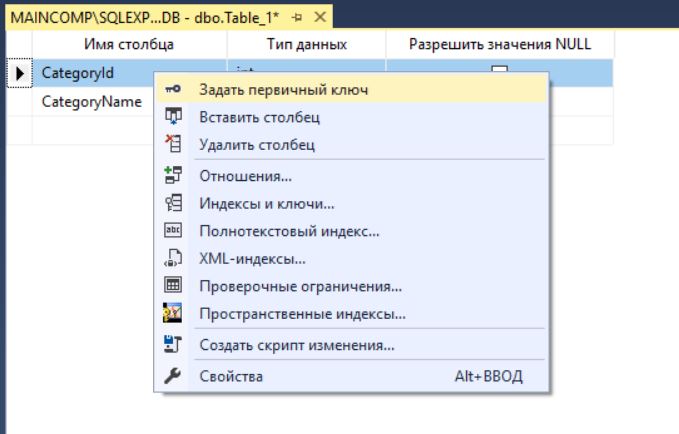
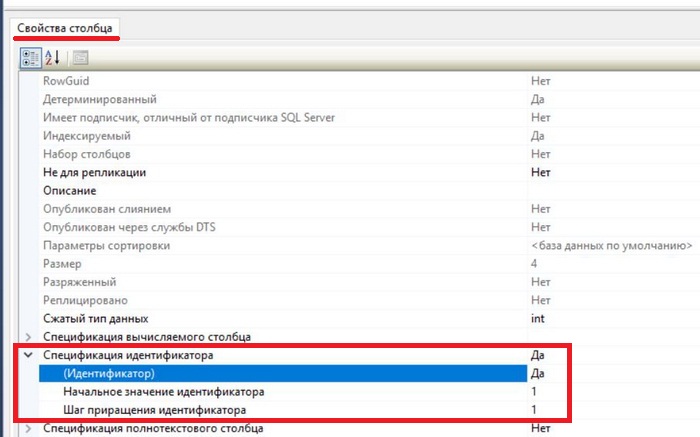
Также для этого столбца давайте определим спецификацию идентификатора, т.е. зададим свойство IDENTITY, для того чтобы данный столбец автоматически генерировал уникальный идентификатор записи.
Чтобы это сделать, в свойствах столбца в нижней части конструктора ищем раздел «Спецификация идентификатора» и включаем его, т.е. ставим «Да». В случае необходимости Вы можете задать начальное значение идентификатора, например, для того чтобы начать идентификацию с определённого значения, а также можете изменить шаг приращения, т.е. на какое значение будет увеличиваться Ваш идентификатор.
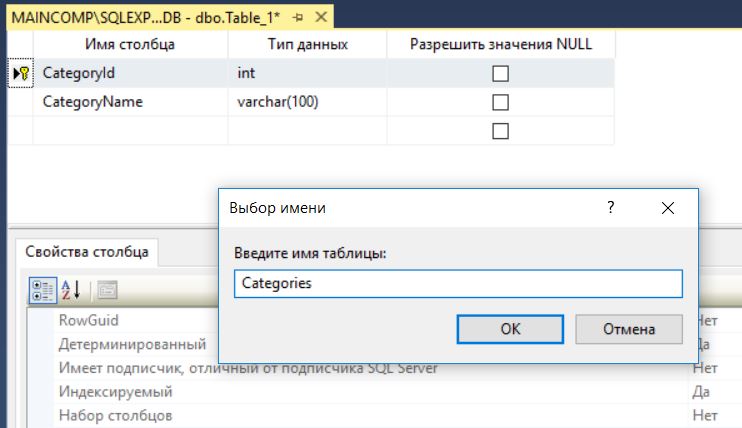
Определение нашей таблицы готово, теперь нам ее необходимо сохранить. Для этого щелкаем по вкладке правой кнопкой мыши и нажимаем «Сохранить» или просто нажимаем сочетание клавиш «Ctrl+S», также кнопка «Сохранить» доступна и в меню «Файл».
Далее вводим название таблицы, в нашем случае это Categories, и нажимаем «OK».
Все, конструктор можно закрыть, можете обновить обозреватель объектов, чтобы таблица у Вас отобразилась.
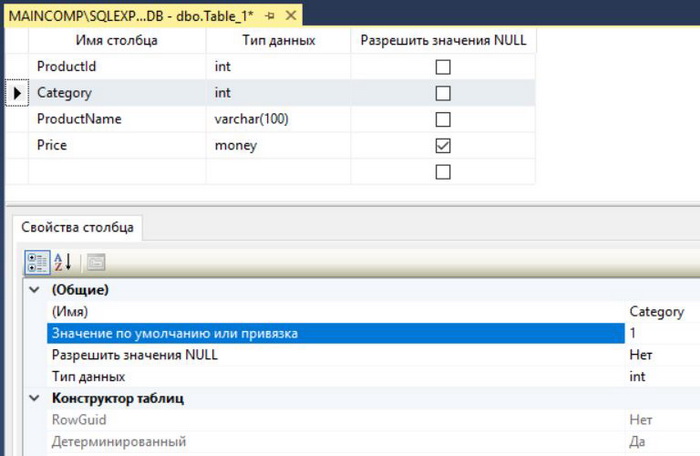
Теперь переходим к таблице Goods. В этом случае делаем все то же самое, т.е. определяем столбцы, задаем первичный ключ и задаем спецификацию идентификатора. Только в данном случае нам нужно дополнительно задать значение по умолчанию для столбца Category и создать ограничение внешнего ключа (FOREIGN KEY).
Для того чтобы задать значение по умолчанию, необходимо выбрать столбец, и в свойствах этого столбца в параметре «Значение по умолчанию или привязка» указать желаемое значение по умолчанию, в нашем случае давайте напишем 1.
Чтобы создать внешний ключ, щелкаем в любом месте конструктора правой кнопкой мыши и выбираем пункт «Отношения…».
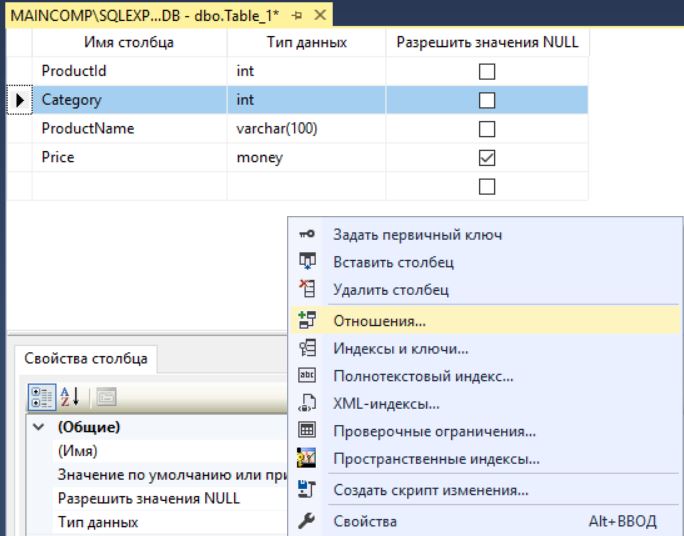
Затем нажимаем добавить.
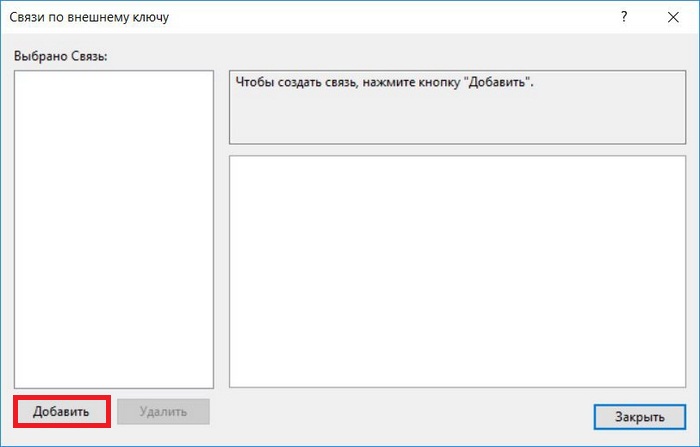
Далее задаем спецификацию таблиц и столбцов, для этого щелкаем на три точки напротив соответствующего свойства.
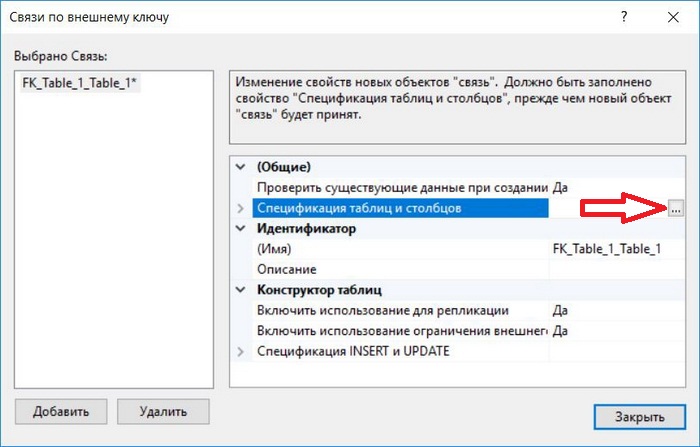
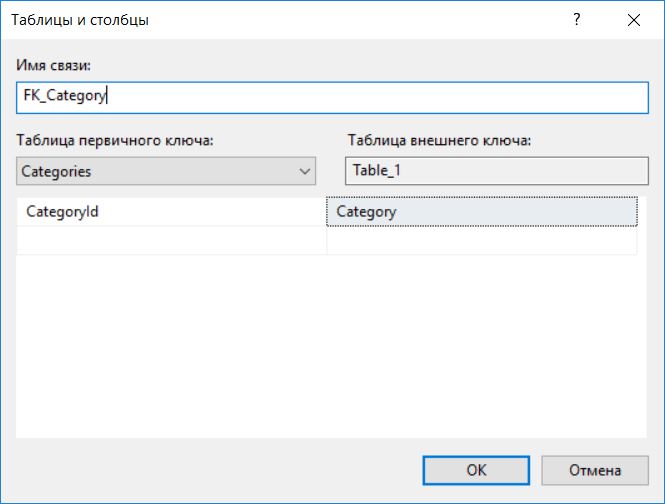
Потом откроется окно, в котором мы указываем следующее:
- Таблица первичного ключа – выбираем из списка таблицу Categories, а также ее первичный ключ, по которому будет осуществляться связь;
- Таблица внешнего ключа – это как раз наша текущая таблица, пока она еще не создана, поэтому она отображается как Table_1, в этом случае выбираем столбец Category этой таблицы, который будет выполнять роль внешнего ключа, т.е. это и будет ссылка на внешнюю таблицу (т.е. сопоставление таблиц будет осуществляться как CategoryId = Category);
- Имя связи — название ограничения, допустим, у нас это будет FK_Category.
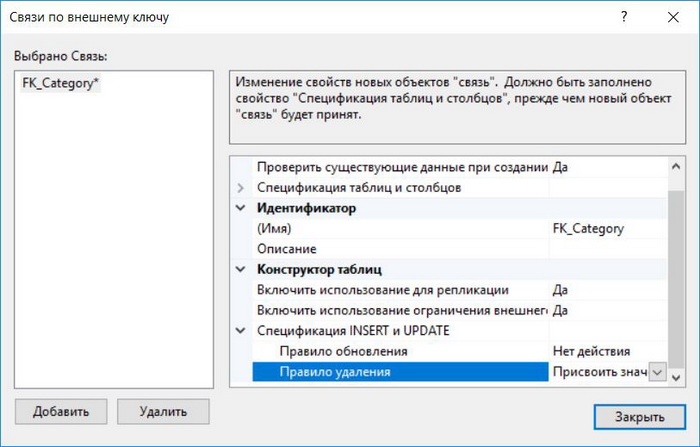
Нам осталось задать правила обновления и удаления, т.е. что будет происходить с записями таблицы Goods (они же ссылаются на таблицу Categories) если категория (запись таблицы Categories) будет изменена или удалена.
Изменять идентификатор категории вряд ли придётся, а если и придётся, то пусть в этих случаях появится ошибка, иными словами, правило обновление просто не задаем. А вот в случае с удалением категории, пусть всем товарам присвоится значение по умолчанию, т.е. неопределенная категория. Для этого определяем правило удаления как «Присвоить значение по умолчанию».
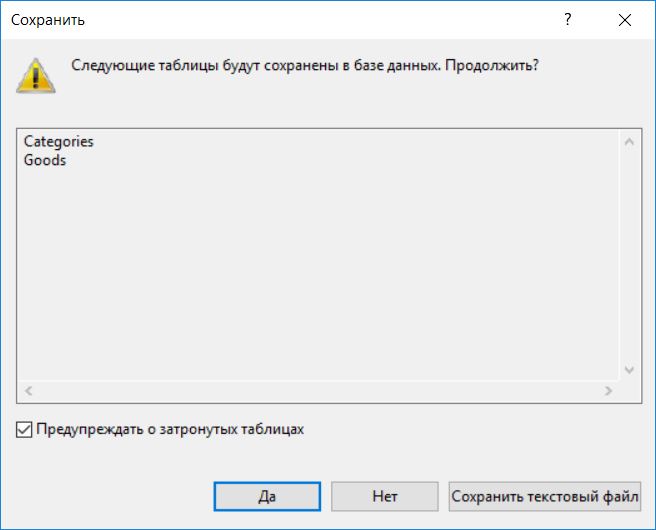
Затем можем сохранить таблицу тем же способом, что и раньше. Называем ее Goods. В случае если появится предупреждающее сообщение о том, что будут затронуты следующие таблицы, отвечаем «Да», т.е. продолжаем.
После обновления объектов в обозревателе, созданная таблица отобразится.
Теперь Вы можете добавлять данные в эти таблицы, например, с помощью инструкции INSERT.
Создание таблицы с помощью инструкции CREATE TABLE языка T-SQL
Теперь давайте я покажу процесс создания тех же самых таблиц, но только на языке T-SQL с использованием инструкции CREATE TABLE.
Упрощённый синтаксис создания таблиц следующий:
В реальности синтаксис инструкции CREATE TABLE очень большой и с первого взгляда сложный, поэтому начинающим лучше сначала понять принцип создания таблицы, а потом углубляться в детали.
Чтобы написать и выполнить инструкцию T-SQL, открываем редактор SQL запросов, для этого нажимаем кнопку «Создать запрос» и пишем необходимую инструкцию, она представлена чуть ниже. Эта инструкция эквивалентна всем действиям, которые мы делали в графическом интерфейсе.
Примечание! Если Вы создали таблицы с помощью графического интерфейса и хотите протестировать следующую инструкцию T-SQL по созданию таблиц, то Вам предварительно нужно удалить эти таблицы, так как они уже существуют и сервер выдаст ошибку. Для этого я специально включил в инструкцию команду DROP TABLE IF EXISTS, которая удаляет таблицы, в случае если они существуют. Параметр IF EXISTS доступен, начиная с 2016 версии SQL Server, подробней об этом параметре мы говорили в статье – «Инструкция DROP IF EXISTS».
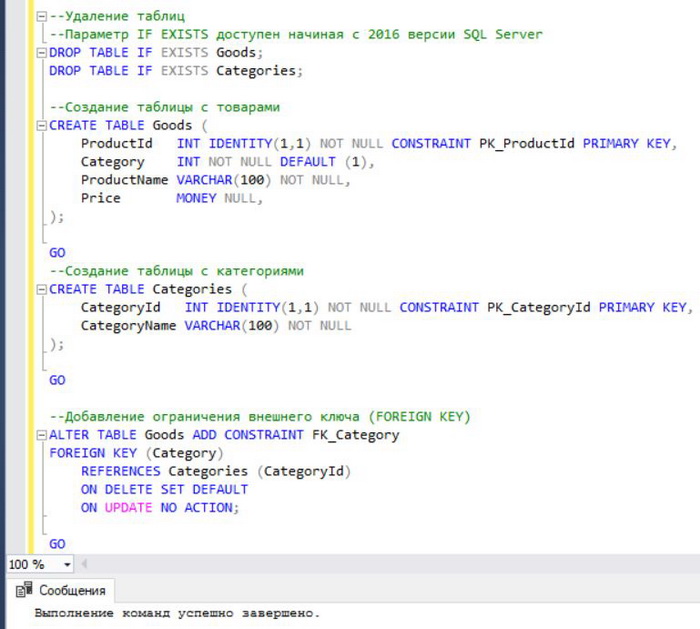
Выполняем инструкцию (кнопка «Выполнить»), в итоге также будут созданы две таблицы и соответствующие ограничения.