Скрытые символы в ворд
Чем дольше используется проверка оригинальности, тем больше появляется методов обхода антиплагиата. На что только не идут студенты — и меняют кодировки, и добавляют нечитаемые фрагменты текста, чтобы программа не распознала копирование материала. Некоторые даже добавляют белым шрифтом фрагменты, никак не относящиеся к теме. Сегодня мы хотим рассказать о скрытых символах в антиплагиате — как их можно использовать и чем они опасны.
Какие есть варианты использования скрытых символов?
Выделяют несколько основных видов применения скрытых символов в ворде для обхода антиплагиата :
1. Добавление белого текста в надпись. Отличительной особенность надписи является то, что ее не видно при выделении текста, но она копируется в проверку. Как результат — повышается оригинальность за счет фрагмента, который не видно визуально. Увидеть такие скрытые символы в ворде не получится без использования поиска по тексту, а антиплагиат их распознает. То есть, если не знать, что именно искать и где, то можно и не найти эту надпись.
2. Добавление невидимых символов в ворде , которые видит антиплагиат . Для этого могут использоваться знаки чужих алфавитов, которые в действующих кодировках текстового редактора не распознаются. Их видно как небольшие пробелы, которые меньше обычных. Такими знаками можно делить слова на части или вписывать между ними. При изменении цвета текста они остаются незамеченными, но все равно видно, что некоторые интервалы выглядят не так. Не подойдет в том случае, если текст будут вычитывать.
3. Использование еврейской точки. Это символ из иврита, который ставится над словами. Если такие точки расставить по тексту, изменив их цвет и размер, то антиплагиат увидит эти невидимые символы , а проверяющий — нет.
4. Греческий алфавит. Система проверки оригинальности научилась определять латинские буквы. Но греческие она пока не распознает. Поэтому некоторые студент заменяют часть букв в тексте на греческие, чтобы получить нужные показатели оригинальности. Такая замена символов в антиплагиате еще не значит , что работа будет оригинальной — алгоритмы постоянно дорабатываются и улучшаются.
Чем опасно применение скрытых символов
Антиплагиат может легко найти скрытые символы в ворде . И если их будет много, система просто поставит отметку “ Подозрительный документ ”. Такой документ не будет зачтен в качестве реферата, диплома или ВКР.
Убрать невидимые символы в ворде Антиплагиат не сможет. Если всё-таки придется чистить текст от таких ошибок, то надо будет либо прописывать замену символов, либо отображать их через поиск и потом удалять. Это в любом случае потребует времени.
С добавлением текста в надпись еще проще. Если руководитель откроет текст, он обнаружит большой фрагмент документа, который можно будет найти через поиск. Антиплагиат поможет ему увидеть скрытые символы в ворде и удалить их. Результат — работу придется переписывать, отношение преподавателя испортится.
Можно ли обойти антиплагиат без скрытых символов
Чтобы пройти проверку на оригинальность без использования таких методов, используйте Антиплагиат Экспресс. Он работает с документом на уровне кода и меняет его таким образом, чтобы текст оставался читаемым, но давал нужные показатели уникальности. Заказать повышение оригинальности очень просто — достаточно загрузить текст в личном кабинете и через несколько минут получить готовый к сдаче документ.
Если у вас имеются какие-то вопросы — позвоните нам, у нас круглосуточная поддержка клиентов!
Сегодня 9 студентов повысили уникальность своих работ. А всего — 534503 студента
Как избавиться от скрытых символов в тексте?
После «кодирования» так называемого (искусственного повышения оригинальности текста) студенты часто сталкиваются с проблемой скрытых символов (половинчатые пробелы, вставка слов, формул, иероглифов, замена букв и т.д.) в тексте работы. А причина тому — это макрос, который вставляет весь этот хлам в текст Вашей работы на программном уровне. И избавится от него крайне сложно.
Почему важно бороться с этой проблемой? Некоторые ВУЗы уже не допускают к защите и аттестации студентов в связи с этой проблемой. Так как скрытый текст расценивается не иначе, как попытка обмана «антиплагиата» и учебного заведения, в частности. Наказание за это становится все более суровое. Если не очистить текст своей работы с первого раза, и проверка снова их обнаружит – серьезные санкции не заставят себя ждать. Некоторые деканаты уже пугают нерадивых студентов уголовной ответственностью!
Существует два способа очистки текста от скрытых символов:
- Переписать весь текст работы.
- Обратится к знающим специалистам.
Если говорить о первом способе, то он поможет, но переписать объемную работу до 75 страниц дело не простое и плюс таблицы придется рисовать с нуля. Также заново придется сделать форматирование и оформление работы под требования вуза или колледжа. Для этого способа потребуется много времени и сил.
Второй способ по времени занимает до 1 часа, но за него придется заплатить, так как это уникальная услуга и делают её далеко не все, тем более с гарантией. Какой из представленных способов подходит, решать Вам!
На картинке ниже показан наглядный пример нашей работы, однако очень часто не все так очевидно и разницу может заметить только Ваш руководитель и система проверки, инспектор документов и пр.

Удалим скрытые символы из текста с гарантией
Уже более 5 лет мы помогаем очищать текст от скрытых символов. И за это время много чего видели. На какие только ухищрения не идут, чтобы повысить оригинальность текста. Что только не вставляют в текст работы, чтобы она казалась оригинальной.
Но это обман и с такими методами можно попасть в неприятную ситуацию. При проверке в системе антиплагиат проверяющий обнаруживают, что к тексту применили искусственное повышение и в лучшем случае просить студента удалить весь хлам из работы. В противном случае работу не примут и не допустят до защиты.
Многие пытаются самостоятельно все почистить, но, если бы всё было так просто. К сожалению, у студента не так много вариантов.
Обратитесь к нашим специалистам и не теряйте время!
Цена услуги очищения текста рассчитывается индивидуально в зависимости от «масштаба ущерба» тексту. Специалист всё бесплатно посчитает и напишем. Если Вы будете согласны – мы поможем.
От Вас потребуется сама работа, обязательно в формате Ворд (Microsoft Word), оплата и подождать до 1 часа.
Так Систему не обойти
Последний учебный год, апрель месяц. Студента все чаще и чаще начинают посещать мысли о том, что надо бы заняться дипломной работой. Заняться — в смысле придумать, как быстро состряпать нечто, что будет хотя бы созвучно той теме, которую, вроде как, утверждали с научным руководителем. А, да, надо хотя бы на 80 страниц, еще и соблюсти ГОСТы там всякие… Понятное дело, самому столько связного текста уже не успеть набрать (да еще и могут начать в суть работы вникать, ну его!). Очевидно — надо брать готовую работу, которую уже защитили, работу качественную, проверенную и одобренную. Знакомая всем нам ситуация. Открытым остается единственный вопрос — как сделать так, чтобы работа прошла проверку на заимствования… Поиск в интернете и общение с коллегами по несчастью приводят студента к следующим вариантам решения проблемы:
Написать работу самому;- Перефразировать текст (дорого и сложно);
- Обхитрить систему с помощью «технических обходов».
Давайте посмотрим, какими бывают технические обходы, как мы их отлавливаем и почему их применение — не самая хорошая идея…
Перефразирование может помочь выдать чужой текст за собственный, если оно выполнено качественно. Однако, качественное перефразирование само по себе является очень трудозатратным процессом, на который у студента, скорее всего, нет времени и средств. Простые же способы перефразирования (например, синонимизация) дадут результат, который не только обнаружится системой «Антиплагиат», но и, вполне вероятно, развеселит научного руководителя и аттестационную комиссию.
Таким образом, мы подходим к самому творческому и самому популярному среди студентов средству — техническим обходам — преобразованиям документа, которые, не меняя отображения исходного документа, изменяют текст, извлекаемый проверяющей системой.
C точки зрения работы с техническими обходами (далее будем называть их просто «обходами») перед системой «Антиплагиат» стоят две задачи:
- Обнаружение потенциальных обходов и уведомление пользователя о них;
- Очистка проверяемого текста от обходов.
Общую схему обработки обходов можно описать следующим образом:
- Обнаружение обходов, сохранение информации о них;
- Очистка извлеченного текста от обходов;
- Определение «подозрительности» документа на основании найденных обходов;
- Отображение информации о подозрительности пользователю, отображение найденных обходов.
Вот как это выглядит на практике.
Документ в формате docx:
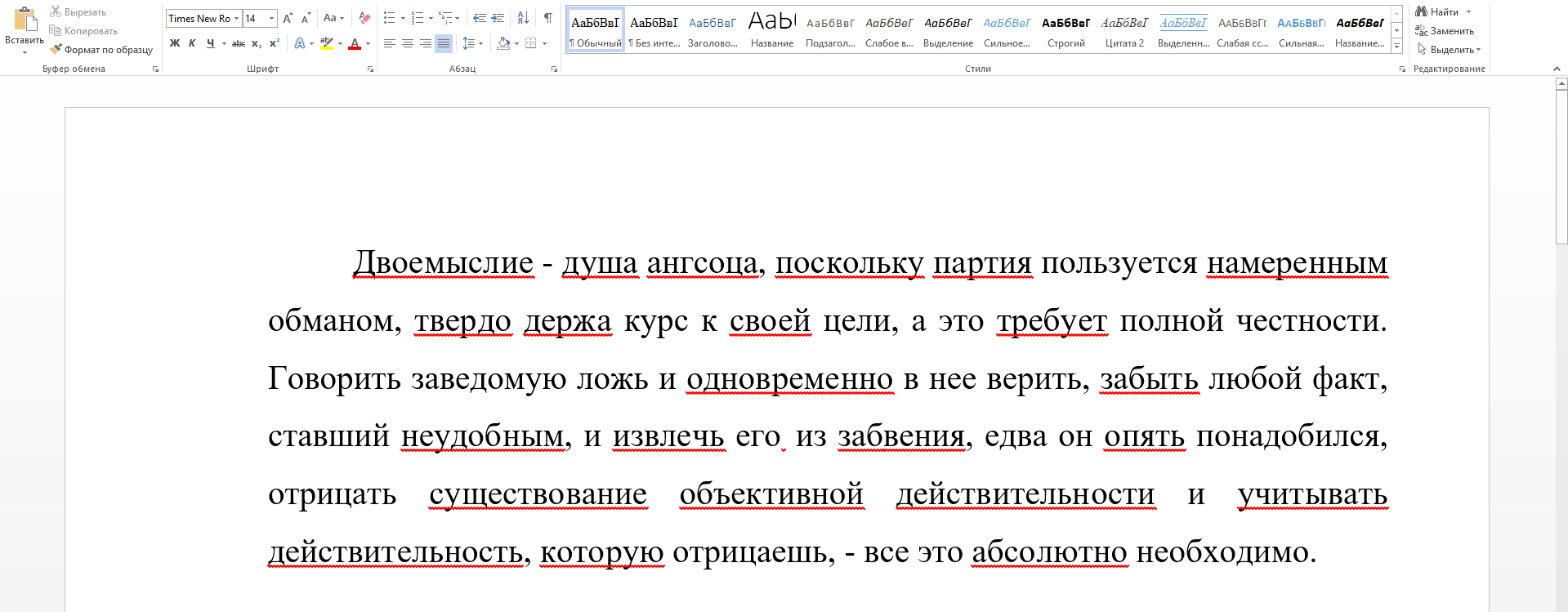
Проверяем документ без функционала обнаружения обходов:
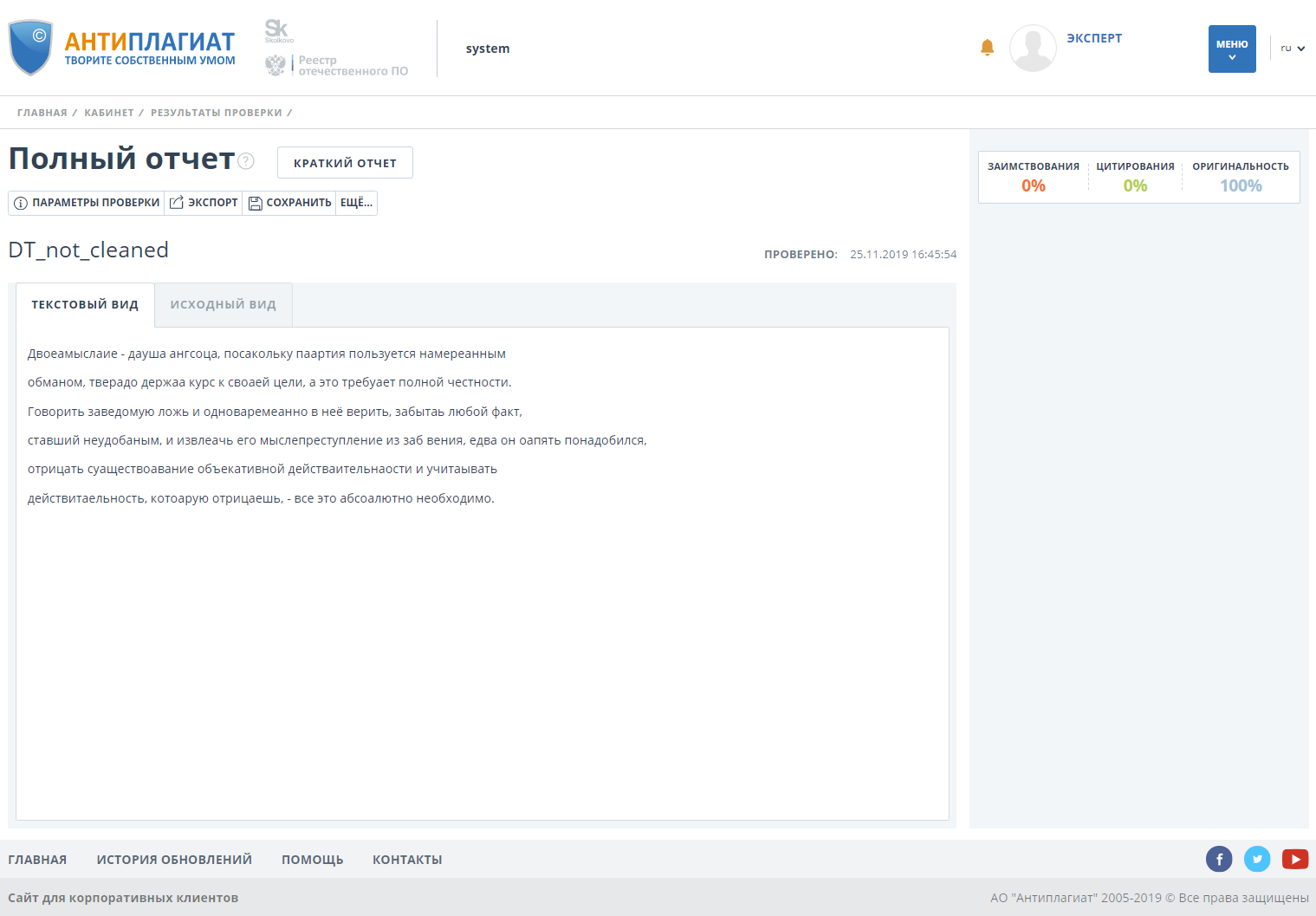
Документ имеет стопроцентную оригинальность.
Проверяем документ с включенным функционалом обнаружения обходов и видим, что оригинальность падает до 0.

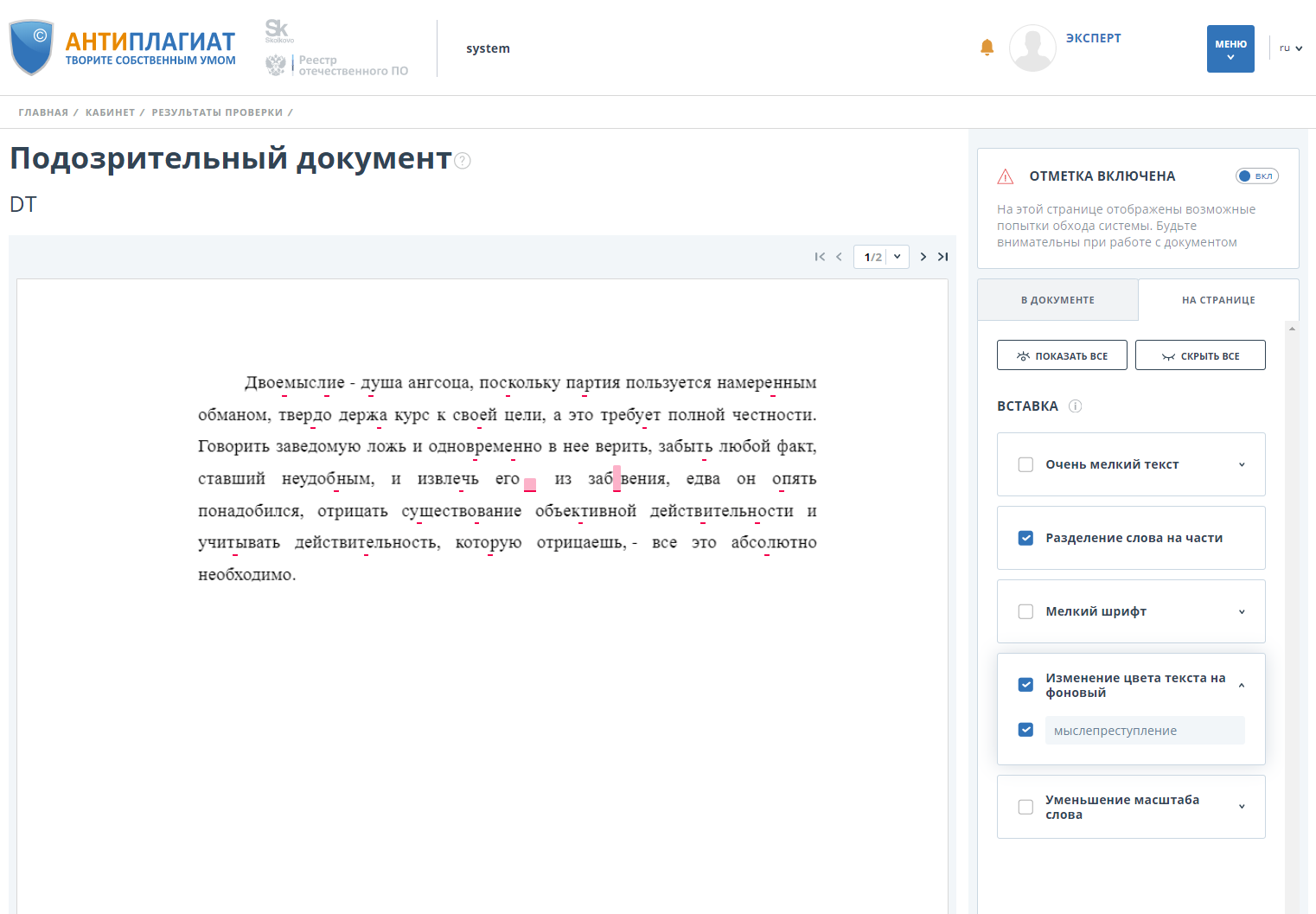
Кроме того, система помечает документ как «Подозрительный» и показывает пользователю, где и какие именно обходы были обнаружены:
Поскольку целью технических обходов является повышение оригинальности документа, интересно классифицировать их по тому, каким образом они влияют на проверку документа. Исходя из того, что основным элементом проверки документа на заимствования являются слова документа, обходы можно разделить на следующие типы по их влиянию на извлекаемые слова документа:
- Изменение слова (слово в извлеченном тексте отличается от слова, отображаемого в исходном документе);
- Добавление слова (слово не видимо в исходном документе, появляется в извлекаемом тексте документа);
- Удаление слова (слово видимо в исходном документе, отсутствует в извлекаемом тексте документа);
- Разбиение слова (в исходном документе слово отображается нормально, в излеченном тексте оно разбито на две или более части);
- Слияние слов (в исходном документе отображается несколько слов, в извлеченном тексте они слиты в одно слово).
Давайте посмотрим, с какими обходами мы сталкиваемся. Начнем от простых и пойдем в сторону наиболее интересных.
Текстовые обходы
Обходы данного типа никак не привязаны к формату документа, они меняют строковое значение слов таким образом, что те продолжают выглядеть идентично исходным словам.
Омоглифы
Одним из первых зафиксированных нами способов обхода является замена букв на омоглифы — на визуально схожие с исходными буквами символы, имеющими иное значение. Омоглифия применялась с самых ранних дней существования системы «Антиплагиат», и, несмотря на то, что она нами давно уже отлавливается, мы все еще встречаем подобные обходы в студенческих работах.
Омоглифы легко находить и очищать, когда известен язык каждого слова. Мы умеем достаточно качественно определять язык каждого слова текста, даже когда текст содержит несколько языков и большое количество «мусора» (омоглифов и прочих лишних символов). Как — это тема для отдельной статьи. Имея язык слова и список возможных омоглифов для языка, мы восстанавливаем буквы исходного языка и сохраняем информацию о найденных омоглифах.
Непечатные символы
Другим способом изменения строкового значения слов без существенного изменения их отображения является использование невидимых либо слабо видимых Unicode символов. Вставка таких символов в слово меняет строковое значение слова, при этом практически не меняя его отображение.
Много подобных символов находятся в Unicode категориях «Other, Control» и «Mark, Nonspacing».
Данные символы система просто удаляет и, при их большом количестве, оповещает пользователя о подозрительности документа, отображая очищенные непечатные символы в отчете.
Обходы в pdf
Как мы уже рассказывали ранее, ключевым форматом при обработке документов у нас является pdf. Все остальные типы документов мы конвертируем в pdf, благодаря чему основная логика обработки документов у нас становится унифицирована для всех поддерживаемых форматов. Таким образом, обходы, которые можно реализовать в pdf документах, для нас представляют особый интерес.
Мелкий текст
Способ обхода, который одним из первых приходит на ум — сделать что-то маленьким и невидимым. Полученный таким образом текст не виден при просмотре оригинального документа, однако извлекается системой. Реализация очень проста — выставить у текста минимальный размер шрифта, изменить цвет текста. Настолько же прост отлов обходов данного типа — просто проверяем размер шрифта текста и геометрические размеры отдельных слов. За счет маленьких размеров студенты часто добавляют целые абзацы такого скрытого текста на страницу:
Отображение обнаруженной попытки обхода:
Изменение цвета текста на фоновый
Несмотря на то, что данный способ часто применяется в комбинации с предыдущим, более интересно его независимое использование. Дело в том, что нам для обнаружения и очистки обхода достаточно определения того, что хотя бы один параметр слова/символа имеет «подозрительное» значение. И, если определение маленьких размеров слова тривиально, то определение текста, цвет которого совпадает с фоновым, является более сложной процедурой.
Обнаружения невидимого текста осложнено следующими обстоятельствами:
- Из pdf не всегда возможно получить цвет конкретного символа;
- Фон слова может быть не белым. Более того, слово может находиться на фоне изображения;
- Слова и символы могут наезжать друг на друга.
Для устранения первых двух сложностей «невидимость» текста мы определяем посредством анализа отрендеренного изображения страницы документа:
- Определяем область страницы, содержащую слово;
- Вычисляем дисперсию полученной области. Если дисперсия ниже определенного порога — в анализируемой области имеем однородный цвет, никаких букв не видно. Следовательно, налицо попытка обхода системы.
Слова и символы, спрятанные друг за другом
Невидимые символы невозможно обнаружить посредством анализа области, в которой они находятся, если эти символы скрыты за другими «видимыми» символами. Поэтому для обнаружения подобных «спрятанных» символов у нас существует отдельная процедура, анализирующая пересечение областей символов и помечающая те символы, которые в значительной степени перекрываются другими.
Текст в виде изображений
Что будет, если взять и заменить часть текста изображениями, содержащими этот текст? При должной аккуратности внешне все будет выглядеть так, будто ничего в документе не изменилось, однако при извлечении текстового слоя, естественно, слова с картинок не извлекутся. Для закрытия данной бреши мы применяем оптическое распознавание текста.
Обходы, использующие особенности конвертации docx в pdf
Конвертация документов в pdf — нетривиальная задача. О том, как мы выбирали наиболее подходящее нам решение, можно почитать тут. К сожалению, даже наилучший из проанализированных нами вариантов неидеально конвертирует документы в pdf. Некоторые «особенности» конвертации активно используются при попытках обхода системы.
Формулы
Формулы и ряд других объектов, содержащих текст, «теряются» после конвертации в pdf. Таким образом можно попытаться скрыть целый абзац текста, или, например, каждое второе слово в тексте:
При конвертации в pdf получаем следующий результат:

Для обнаружения и очистки этого и других обходов, заточенных на особенности конвертации docx в pdf, мы анализируем и вычищаем исходный docx файл. В частности, при обнаружении существенного количества формул в документе мы их заменяем на простой текст, который сохранится при конвертации документа в pdf. Более того, мы запоминаем позиции формул, которые мы обработали, и при необходимости сообщаем пользователю о подозрительности проверяемого документа и подсвечиваем текст, который мы восстановили из формул.
Масштаб, маленькое межсимвольное/междустрочное расстояние
При конвертации в pdf не учитывается ряд свойств текста: масштаб, межсимвольное и междустрочное расстояния. Это позволяет добавлять невидимый в исходном документе текст (например, у него выставляется очень маленький масштаб), который в pdf становится нормальным, ничем не выделяющимся текстом. Реализация обхода (docx):
Результат конвертации в pdf (цвет мы меняли сами):

Единственная возможность отловить данный текст — найти его в docx и сохранить информацию о нем. Если мы обнаружили много такого текста в документе — помечаем документ подозрительным и показываем пользователю, где мы нашли в документе текст с подозрительными атрибутами.
Разбиение слова на части
Интересный частный случай применения свойств, описанных в предыдущем пункте — добавить в слово пробел и скрыть его. В исходном документе слово будет выглядеть нормальным, слитным, а после конвертации документа в pdf разобьется на две части, так как пробел станет полноразмерным. Отлавливаем подобный финт ушами примерно так же, как и в предыдущем пункте. Реализация обхода (docx):
Результат конвертации в pdf:

Отображение обнаруженного обхода:

Под старым каштаном, при свете дня, я предал тебя, а ты меня.
Мы рассказали об основных, но далеко не обо всех технических способах реализации обходов. Конечно, нам вряд ли когда-либо удастся сделать защиту абсолютной. Тем не менее, мы постоянно совершенствуем нашу систему, оставляя все меньше и меньше возможностей ее «обмануть». В сессию мы стараемся закрывать обнаруживаемые лазейки особенно оперативно — часто с момента обнаружения бреши до ее закрытия на проде проходит всего несколько дней. Именно поэтому немного смешно и, одновременно, грустно читать рекламные «обещания» компаний, готовых помочь студентам поднять оригинальность их работ и дающих гарантию на свою работу, порой достигающую 30 дней. Студент, тебя предадут! В лучшем случае эта «гарантия» может вернуть тебе стоимость услуг компании-обходчика, но она никак не поможет с проваленным дипломом и потенциальным отчислением из вуза.
Обход антиплагиата с «невидимым символом» и его обнаружение
Я, помнится, уже писал, что работаю техническим редактором в научном журнале. Причем одно из требований к материалам, которые мы принимаем — это оригинальность. На самом деле статьи проходят довольно сложную проверку, однако один из начальных ее рубежей — это известная многим система Антиплагиат. Мы уже сталкивались с попытками эту систему обмануть, я писал об этом в статье О попытке обхода системы Антиплагиат. Ну а это, выходит, вторая часть.
На этот раз был использован более хитрый (но такой же очевидный) способ. Однако шансы на успех у него, возможно, даже и были. Ибо статья прошла предварительную проверку, верстку (а прошлую попытку, как мы помним, удалось заметить именно на верстке), и была изобличена уже в последний момент, попав ко мне.
Что же натолкнуло меня на мысль о том, что требуется дополнительная проверка? На самом деле, существует масса косвенных признаков того, что текст не оригинальный.
Поначалу все было вообще хорошо и красиво, однако после того, как я придал заголовку нужное форматирование (в частности — размер шрифта 18), он стал выглядеть примерно так:
![]()
Если вы еще не поняли, что меня насторожило, внесу конкретику:

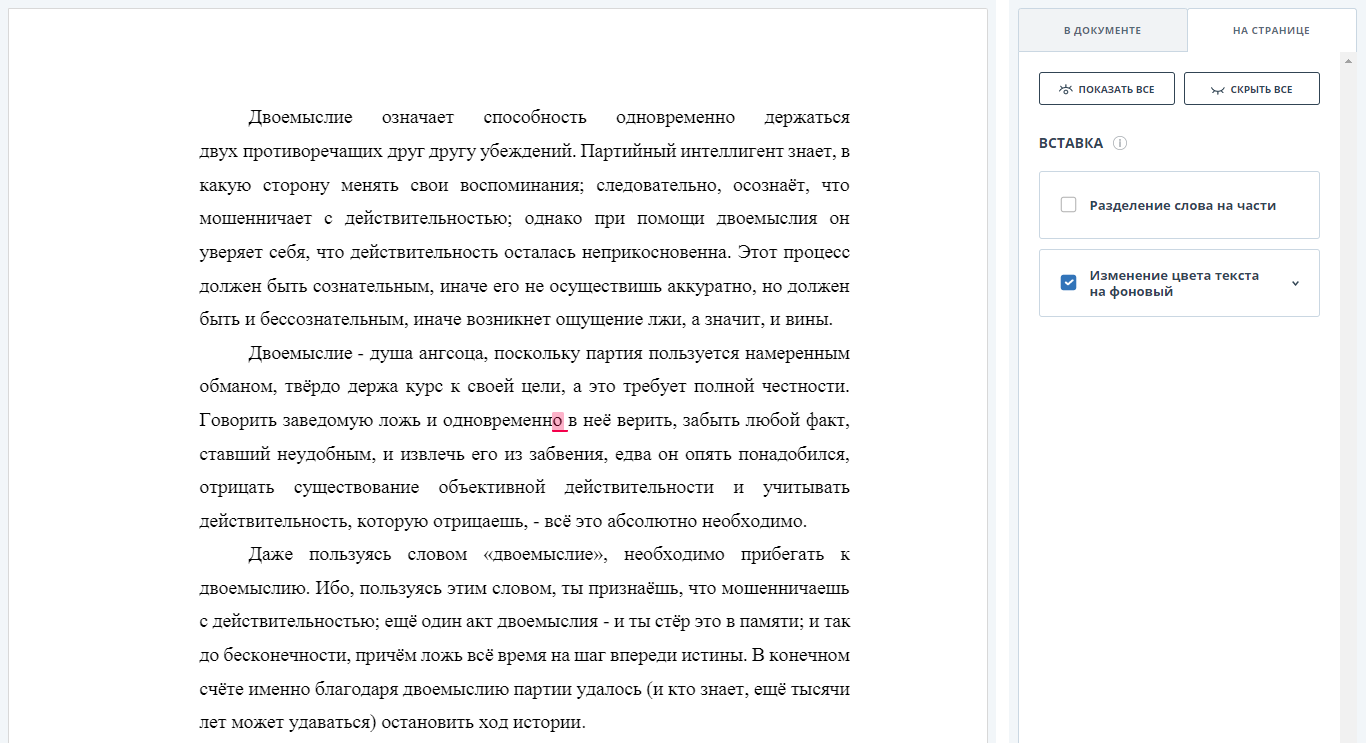
Да. Вот эти вот интервалы. Мелочь, казалось бы, но когда в день через твои руки проходит по нескольку статей, всякие необычности становятся особенно заметны. Поигравшись с продвинутыми настройками шрифта, от интервалов я не избавился, и стал копать дальше. Начал я с того, что скопировал заголовок в блокнот. Вышло вот что:
Ну вот, казалось бы и все ясно. Пробелы. Так-то оно так, да не так. Путем нехитрых манипуляций довольно быстро удалось установить, что это не пробелы. Для начала я выделил этот символ в Word. И он выделился:
![]()
При этом Word в статусбаре выдал такой вот интересный вердикт:
![]()
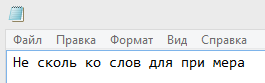
Мда. Не знаю, производственная ли это необходимость, или юмор тех, кто придумал этот способ (речь об албанском языке). Но между тем… Разумеется, следующее что я сделал, это попробовал «покрасить» символ в черный цвет, в надежде на то, что сейчас он белый, а после применения цвета станет видим. Однако это мне благополучно не удалось. Он так и остался невидимым. Поэтому пришлось взяться за скальпель инструмент поиска и замены. Скопировав паразитный символ в буфер обмена, я вставил его в строку «найти» этого инструмента. В строку «заменить на» я забил сочетание символов, которое вряд ли встретится в статье. Не мудрствуя лукаво — qweqwe.
Получилось вот так:
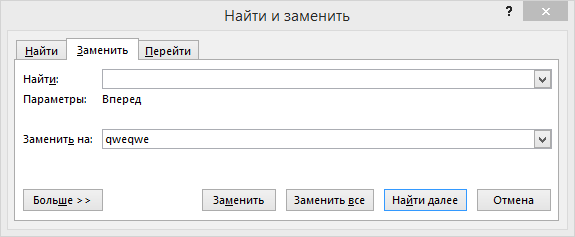
Пусть Вас не смущает, что верхняя строка пуста. Символ там есть. Если установить в нее курсор, и подвигать стрелочками, это станет очевидно. Ну а добавит уверенности нажатие кнопки «Заменить все»:
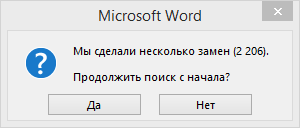
Ого! Да эти символы, похоже, были чуть ли не в каждом втором слове! После проведения экзекуции, заголовок стал выглядеть так:
![]()
Ну что же, выведем его на чистую воду! Выделяю весь текст, устанавливаю цвет шрифта черный и размер — 18. Получается вот что:
![]()
Вот так. Наши qweqwe появились во многих словах по всему тексту. Не удивительно, что Антиплагиат оценил текст как на 100% оригинальный. Почему? Да потому, что для системы невидимый паразитный символ все равно существует, разделяя слова. И при сравнении с базами данных, Антиплагиат бодро рапортует, что текст оригинальный. Конечно оригинальный — ведь в базе данных сохранен нормальный текст, без невидимых символов.
Прибегнем снова к инструменту поиска и замены, только по-другому. В верхнюю строку мы скопируем нашего албанского героя, а нижнюю просто оставим пустой. Совсем пустой. После нажатия кнопки «Заменить все» — лишние символы будут удалены. И мы сможем-таки узнать оригинальный результат предложенного текста при проверке через Антиплагиат. В нашем случае он составил 58%. Большой впрос — стоила ли игра свеч? Ведь для публикации в журнале надо хотя бы 70 — не такая уж и великая разница. Изменив немного текст, можно было добиться нужного результата.
На этом, казалось бы, можно и закончить, однако я хочу обратить внимание на некоторые интересные особенности этого метода. Начнем с простого. Обратите внимание, заголовок (а скриншоты сделаны в Word), не подчеркнут красным. Мы с Вами отлично знаем, что если в слово вставить лишнюю букву или пробел, это непременно произойдет, если только проверка орфографии включена. Я пока еще не разобрался, как добиться такого эффекта. Все оказалось совсем просто. Помните, я упоминал албанский язык? Если поменять язык документа на такой, средства проверки орфографии для которого не установлены, то и характерных подчеркиваний не будет.
Далее. Если вы читали первую статью, то помните, что ту попытку обхода системы можно было раскусить, просто открыв текст прямо на «Антиплагиате». Припрятанный уникальный, но бессмысленный кусок текста там был виден. Здесь же все более серьезно. Не видно не только сам символ, но и даже пробел вместо него, как мы с Вами наблюдали это в блокноте.
Ну а теперь возьмемся за скальпель и полезем в XML. Если кто не в курсе — для того, чтобы добраться до внутренностей вордовского файла, надо изменить его расширение на zip, и получившийся архив разархивировать. Внутри будет несколько папок, содержащих различные объекты, имеющиеся в файле, и собственно текст в формате XML, где и можно увидеть что-нибудь занятное в такой ситуации. Поехали:

Вот он, наш герой. Если честно, я надеялся найти нечто более конкретное, поэтому полез еще глубже, то есть в шестнадцатеричный код:
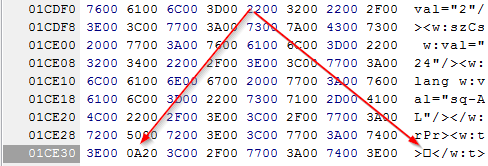
Где и удалось узнать, что загадочному символу соответствует код 0A20 в таблице Unicode. Символ какого-то мудреного алфавита, которого, видимо, просто-напросто нет в тех шрифтах, которые мы используем. Кстати, по ссылке этот символ в Unicode от 1993 года. В современной таблице кода 0A20 нет вообще. Вот все и встало на свои места. То есть с точки зрения большинства программ… Символ как бы есть, но в то же время, его как бы и нет.
Хитро, кончено, что сказать… Я отлично понимаю, что все мы одарены разными талантами. И вот так взять и написать полтора десятка страниц уникального текста — некоторым сложно. Если вы относитесь к таковым — попробуйте вот это. Не бесплатно конечно. Зато честно. Ну, почти.
Закончить статью, как и предыдущую, я хочу мыслями собственно об «Антиплагиате». Да, система не совершенна, однако же, приятно видеть, что она не стоит на месте. Статья, о которой идет речь выше, попала к нам около месяца назад, и тогда «Антиплагиат» ее проглотил запросто. Теперь же, после загрузки, рядом с ней загорается восклицательный знак — «подозрительный документ». Уже ради интереса я попробовал загрузить туда текст из первой статьи и получил такой же результат. Уже неплохо.
Только вот… Многие ли докопаются до таких тонкостей, даже получив предупреждение? Боюсь, что нет.
PS. Комментарии к этой записи отключены ввиду большого количество желающих порекламировать свои услуги по обходу антиплагиата. Статья-то вроде как о том, как это дело обнаружить.
Если Вам ну очень хочется донести что-то до автора — пишите на мыло.
PS. PS. Не пишите мне, чтобы я выслал «волшебный символ». Я с другой стороны баррикад ��