Кластерный анализ Excel
Один из действенных инструментов решения экономических и статистических задач является кластерный анализ.
Один из действенных инструментов решения экономических и статистических задач является кластерный анализ. Он представляет собой разделение на группы разного рода объектов, на основании важных критериев. Полученные путем кластеризации группы поддаются анализу. Простым примером может стать прилавок в продуктовом. Здесь ассортимент продуктов проходит кластеризацию и разделяется на группы: «бакалея», «рыба», «молочные продукты» и т.д. При переносе кластеризации на потребителя получается выделить группы, которые так или иначе реагируют на рекламу, с определенной периодичностью покупают тот или иной товар или вовсе отказываются от его потребления и т.д. Проведение кластерного анализа можно осуществлять с использованием различного программного обеспечения, в том числе и стандартного Excel, с которым умеет работать большое количество пользователей.
Процесс кластеризации
На основании выбранного метода меняется сам процесс кластеризации. Практически всегда он является итеративным – многократно повторяющимся. Для объединения разных элементов в один кластер требуется постоянно добавлять в него, расширять близкие, схожие по типу какому-то критерию объекты. В процессе кластеризации можно проводить большое количество экспериментов, в которых один и тот же массив данных разделяется по разным критериям. Несмотря на то, что эксперименты сами по себе могут быть интересными, они – не самоцель. Кластеризация должна выполняться для получения содержательных сведений о структуре данных, которые исследуются. На основании полученных кластеров проводятся исследования свойств и характеристик объектов для формирования точного описания полученных групп.
Когда применяется кластерный анализ
Посредством кластерного анализа можно разделять массив на основании изучаемых характеристик. Разделение большого массива данных на обобщенные группы с близкими характеристиками. Критерием группировки выступает парный коэффициент корреляции или эвклидово расстояние между объектами. При этом близкие друг другу значения группируются вместе.
Область применения кластеризации – обширна. Среди наиболее простых примеров:
- Биология – разделение животных на виды, на основании их признаков.
- Медицина – применяется с целью классифицировать заболевания по симптоматике, способам лечения.
- Психология – для анализа поведения разных групп людей в определенных ситуациях.
- Экономика – изучение экономических изменений, составление прогнозов.
- Маркетинг – проведение исследований для продвижения продукции.
- Возможность анализировать данные практически любой природы;
- Обработка больших объемов информации путем ее сжатия, компоновки;
- Простая наглядная демонстрация данных;
- Может выполняться циклически и проводиться до тех пор, пока не будет получен необходимый результат. При этом каждый цикл может значительно изменять направление дальнейшего анализа.
- Состав и число кластеров напрямую связаны с выбранными критериями кластеризации;
- Преобразование первоначальных данных, сбор и их группировка может исказить отдельные объекты, лишить их своей индивидуальности;
- Часть данных, присущих конкретному кластеру, может просто игнорироваться в рамках анализируемой совокупности.
- Player ID – номер присваиваемый игрокам баскетбольной команды. В нашей выборке будет 20 игроков.
- Team – обозначение команд. Двадцать игроков разделены на 5 команд.
- Points – набранные игроками очки.
- Rebounds – количество подборов каждого игрока.
- Пол.
- Возраст.
- Уровень образования.
- Доходы.
- Ручная проверка;
- Определение контрольных точек и проверка полученных кластеров через них;
- Определение стабильности выполненной кластеризации с помощью добавления в модель дополнительных переменных;
- Кластеризация с помощью разных методов: K средних, иерархическая агломеративная DBSCAN. Разные методы могут привести к получению разных кластеров. В целом, это нормально, но если кластеры, полученные разными методами, схожи, то это указывает, в первую очередь, на правильность кластеризации.
- Загружаем консоль кластера с PelicanHPC GNU Linux Live CD

- Через некоторое время повяляется следующий запрос:
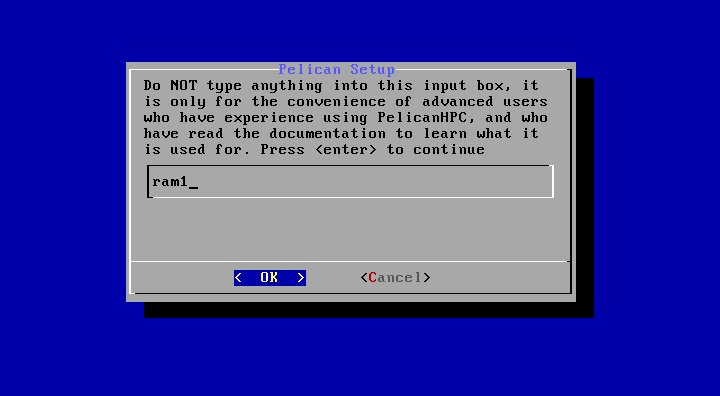
Здесь вы должны будете указать устройство, на котором будет располагаться пользовательский каталог. То есть ваш рабочий каталог, где будут храниться ваши программы, исходники и файлы данных. По умолчанию вам предложен раздел на виртуальном диске, расположенном в оперативной памяти. Это самый простой вариант, однако не самый удобный в том смысле, что после выключения компьютера все данные на этом диске будут уничтожены. В этом случае вам придется каждый раз перед выключением сохранять ваши данные на внешний носитель, например на флешку. Более удобным будет, если вы выделите на винчестере компьютера отдельный раздел для ваших данных. Как вариант может рассматриваться подключение внешнего носителя (флешки либо USB-винчестера). В таком случае вместо предложенного ram1 вы должны будуте указать что-то типа hda7, sda5, sdb1 и т.д. в зависимости от конфигурации вашей машины и выбранного варианта. - Следующий вопрос, который будет вам задан, выглядит так:
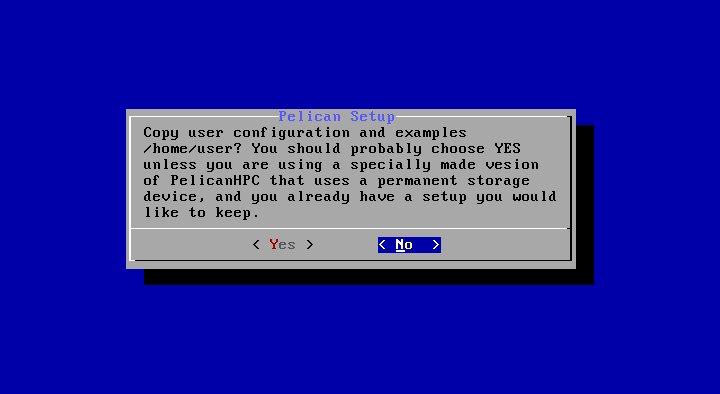
Система спрашивает, будет ли выполнена начальная конфигурация пользовательского каталога. В случае, когда вы используете в качестве пользовательского каталога виртуальный диск ram1, всегда отвечайте «Yes». Если же вы выбрали в качестве месторасположения пользовательского каталога постянный носитель (раздел винчестера компьютера, флешку или внешний USB-винчестер), тогда ответ «Yes» вы должны будете выбрать только в самый первый раз. Во все последующие загрузки кластера необходимо выбрать ответ «No». - На следующем шаге вы должны будете указать пароль пользователя, с которым вы будете подключаться в систему:
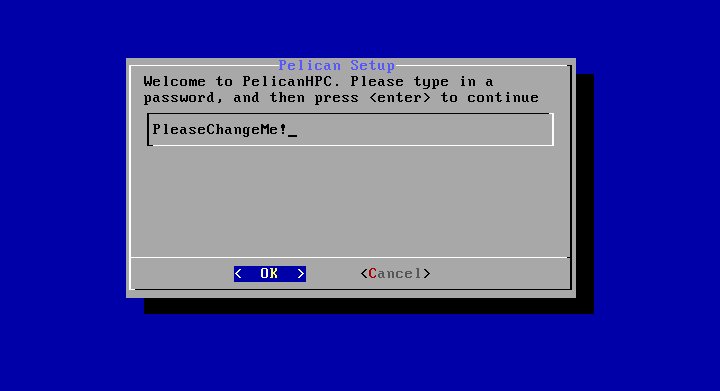
- После задания пароля вам будет предложен стандартный экран входа в систему:
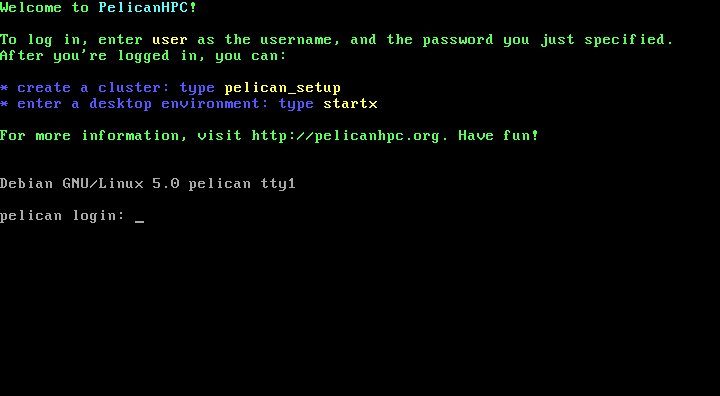
Для входа в систему вы можете использовать логин «user» и пароль, который вы определили на предыдущем шаге. - Итак, мы вошли в систему консоли кластера. Теперь нам необходимо подключить к класетру все наши вычислительные узлы. Для этого запустим команду конфигурации кластера pelican_setup. Первое, что спросит эта команда — будем ли мы конфигурировать сетевую загрузку вычислительный узлов?
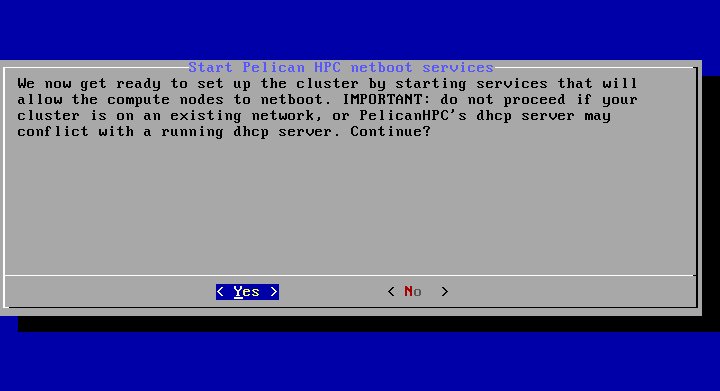
Естественно, мы говорим «Yes». - Сконфигурировав сервер сетевой загрузки, программа предложит нам выполнить загрузку всех стальных узлов кластера:
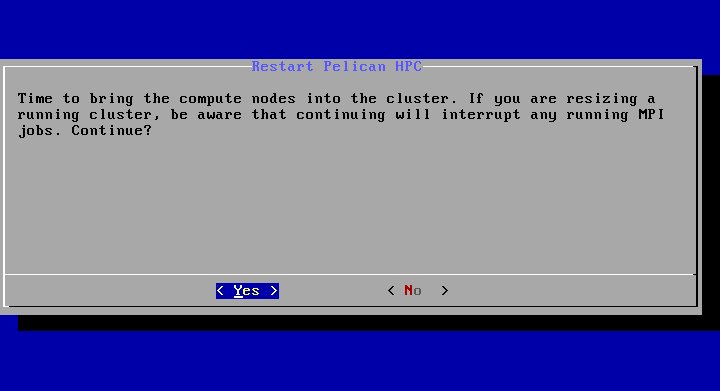
В этот момент мы должны включить все остальные компьютеры кластера, не забыв поправить настроики BIOS таким образом, чтобы они выполнили загрузку по сети. Вмешательства в процесс загрузки вычислительных узлов кластера не требуется. Надо просто дождаться, когда они все закончат процедуру загрузки, о чем будет свидетельствовать следующая картинка на экранах этих конмпьютеров: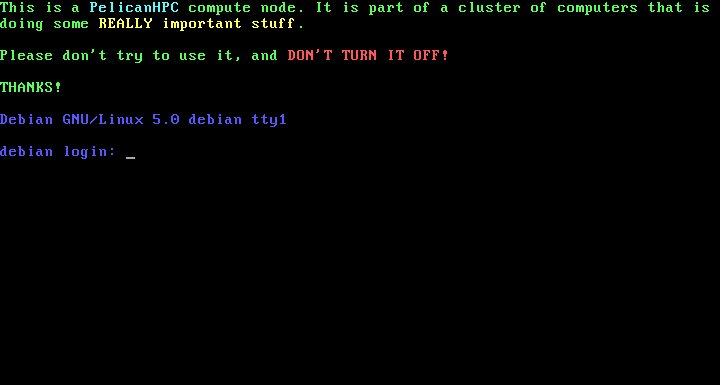
После того, как все компьютеры будут загружены, нажимаем кнопку «Yes». - Далее программа настройки попытается найти все загруженные компьютеры и включить их в конфигурацию кластера. После выполнения этого действия она выдаст на экран итоговый результат:
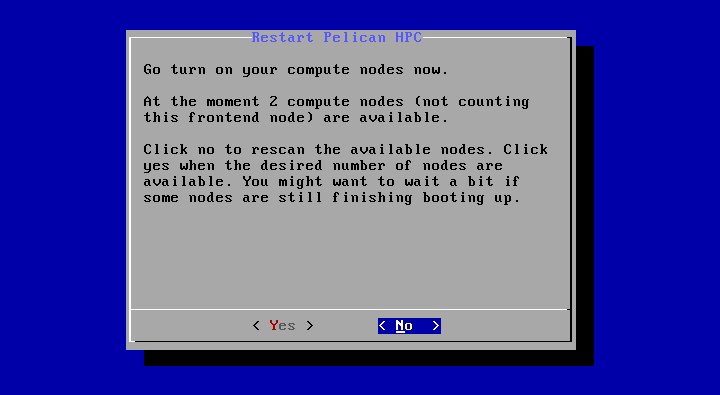
На этом экране программа сообщает нам, сколько было найдено вычислительных узлов (в данном случае два) кроме узла, который является консолью кластера. Если все нормально — нажимаем «Yes». - И, наконец, программа конфигурации кластера сообщает нам, что все настройки выполнены и кластер готов к эксплуатации:
Нам остается только завершить ее, нажав «ОК». - В некоторых случаях у меня конфигурация кластера завершалась с ошибкой, поэтому я рекомендую следующим шагом запустить скрипт реконфигурации: pelican_restart_hpc, тем самым повторив заново пункты 7-9.
- Компилируем программу в параллельной среде MPI с помощью команды mpif77 flops.f -o flops
- Запускаем программу на одном процессоре командой ./flops
- Запускаем программу на двух процессорах командой mpirun n2,0 ./flops
Когда требуется обработать большое количество данных, преобразовать информацию в простые группы, которые проще изучать – применяется кластерный анализ.
Преимущества и недостатки кластерного анализа
Использование такого типа анализа дает возможность разбить многомерный ряд на основании различных параметров. Среди главных преимуществ этого инструмента выделяются:
Недостатки представленного метода:
Пример выполнения кластерного анализа в Excel
Чтобы наглядно показать, как выполняется анализ, возьмем 6 объектов исследования. У каждого из них имеется 2 параметра, которые характеризуют их – X и Y.
Их мы будем использовать в примере, основанном на определения евклидова расстояния: =КОРЕНЬ((x2-x1)^2+(y2-y1)^2)
Результаты, которые были получены, занесем в матрицу расстояний.
Из полученных данных видно, что самыми близкими являются 4 и 5 объекты. Поэтому их можно сгруппировать, а при формировании новой матрицы расстояний остается значение, которое было меньшим из двух.
Новая матрица позволяет увидеть, что теперь ближайшими объектами являются кластер и объект 6. Повторяем предыдущий шаг – объединяем, оставляем меньшее значение и формируем новую матрицу.
Здесь ближайшими объектами стали 1 и 2. Повторяем формирование кластера.
Осталось исследовать последние 3 объекта. Минимальное расстояние получилось между кластером и объектом 3. Выполним еще раз их объединение.
В результате группировки с использованием метода «ближайшего соседа» удалось сгруппировать 6 объектов и разделить их на 2 кластера, расстояние между которыми – 7,07.
Применение инструмента кластерного анализа имеет большое значение в рамках анализа в экономике. С его помощью удается вычленять периоды, в которых параметры были максимально приближены, и динамика отличалась своей схожестью. Метод кластеризации в экономике позволяет исследовать товарную и общехозяйственную конъюнктуру.
Как сделать кластерную выборку в Excel: пошаговая инструкция
Выборка часто используется в статистике для анализа нескольких групп данных, которые являются частью массива. Выборка представляет собой разбивание всего объема данных на кластеры и использование определенной группы кластеров в выборке. В примере, описанном ниже, вы можете узнать, как сделать кластеризацию в Excel и превратить ее в кластерную выборку.
Шаг 1: Ввод данных
Для начала, необходимо ввести исходные данные в программу. Например, используем такие:
Выполнить кластеризацию всего массива представленных данных можно по разным критериям: разделить игроков по количеству очков, подборов или просто создать кластеры на основе их принадлежности к определенной команде.
Для создания случайно кластерной выборки самым простым способом станет случайный выбор двух команд и определение, какие игроки должны входить в окончательную выборку.
Шаг 2: поиск уникальных значений
Создание дополнительного массива, который будет содержать уникальные значения. За основу выбора уникальных значений берем столбец Team и создаем новый Unique, в который вводим следующую формулу Excel =UNIQUE(B2:B21).
Следующий столбец создается на основе ввода целого числа (начиная с 1) для каждого уникального названия команды, полученного путем ввода формулы:
Шаг 3: выбор случайных кластеров
Чтобы создать своего рода рандомайзер, используем такую формулу: =СЛУЧМЕЖДУ(G2, G6). Это позволит случайным образом выбирать одно из полученных целых чисел, которыми мы обозначили команды.
При нажатии на клавиши ENTER сгенерируется случайное значение. У нас высветилось 5. Команда, которая взаимосвязана с этим значением – Е. Она будет выполнять роль первой команды, участвующей в окончательной выборке.
Для того чтобы получить второе значение, необходимо снова нажать на ячейку I2 и ENTER. Новое число опять будет выбрано из записанной нами функции =СЛУЧМЕЖДУ(G2, G6) .
Во второй раз рандомайзер выбрал значение 3. Команда, которая соответствует этому значению – С. Она станет второй командой, представленной в окончательной выборке.
Шаг 4: Фильтрование окончательного образца
В состав окончательной выборки будут входить все игроки, которые принадлежат к команде С или команде Е. Для фильтрации только этих команд необходимо выделить все изначальные данные в столбцах A, B, C, D. После этого необходимо нажать на вкладку «Данные» в верхнем меню Excel, а далее – «Фильтр», которая располагается в группе «Сортировка и фильтр».
После того как Excel сформирует фильтр над каждым столбцом, останется нажать на стрелку, расположенную в столбце «Team». После этого оставить галочки только для команд C и E.
После нажатия на подтверждение («ОК») данные будут отфильтрованы и в таблице будут отображаться только игроки, принадлежащие к команде С или к команде Е.
Этот образец – окончательная случайная выборка из всего массива данных. В него включены все игроки по критерию «Команда».
На основании полученных данных можно выбрать, например, самого результативного игрока из двух этих команд или рассчитать среднее количество очков, заработанных каждым из них. Конечно, в представленном массиве в целом и в кластере в частности указано совсем немного информации, но и ее уже можно использовать.
Как кластерный анализ применяется в маркетинговых исследованиях
Маркетологи часто используют этот инструмент в качестве способа изучения различных данных о товарах, потребителях, нишах и т.д. Оно требуется как для проведения теоретических изысканий, так и маркетологам, занимающимся практической работой. Чаще всего они решают вопросы, связанные с объединением в группы различных объектов: клиентов, товаров, услуг и т.д.
Так, одна из важнейших задач, которая решается при помощи кластерного анализа, является изучение потребительского поведения. Метод позволяет выполнить группировку всех потребителей в однородные массы. Она позволяет не только получить максимально подробное представление о том, как клиент из каждой группы себя ведет, но и определить факторы, которые влияют на то или иное поведение. Кластеризация в маркетинговых исследованиях может выполняться по разным критериям.
Одной из важнейших задач, которая решается путем применения в качестве рабочего инструмента кластерного анализа, – позиционирование. С его помощью выявляется ниша, в которой лучше всего позиционировать новую продукцию.
Применение такого анализа позволяет построить карту, на основании которой определяется уровень конкуренции в разных сегментах рынка, оценить параметры товара, позволяющие попадать в определенный сегмент. Проведение анализа полученной карты поможет определить новые, незанятые ниши на рынке, в которых разрешено предлагать уже созданные товары или разрабатывать инновационные продукты.
Кроме того, инструмент может пригодиться в случаях, когда необходимо изучить клиентов компании. В этой ситуации клиенты разделяются на группы, и для каждого образовавшегося кластера разрабатывается индивидуальная политика взаимодействия. Разделение на кластеры позволяет не только сократить количество объектов, которые нужно анализировать, но и одновременно подобрать подход для каждой клиентской базы.
Как оценить качество кластеризации
Чтобы проверить качество выполненной кластеризации, можно воспользоваться такими процедурами, как:
Не стоит пренебрегать проверками, в противном случае все исследование на фоне неправильной кластеризации может стать ошибочным.
Заключение
Алгоритм применения инструмента кластерного анализа упрощается с использованием возможностей Excel. Конечно, требуется проработать различные варианты взаимодействия с массивом данных на основании использования программных возможностей. Программное обеспечение позволяет не только фильтровать данные, но и сортировать объекты, выполнять различные расчеты. Кроме того, с помощью ее средств можно выполнить упрощение восприятия информации путем составления диаграмм, полученных, например, в результате создания конкретной выборки. Этот инструмент незаменим в маркетинге, он позволяет оптимизировать продвижение продукции, оптимально расходовать ресурсы для отдельных групп потребителей.



Нажимая кнопку «Войти», Вы принимаете условия
Политики конфиденциальности
Как сделать кластер на компьютере
Юрий Сбитнев
Родился в 1965 г. в Волгограде.
Образование высшее: Волгоградский государственный университет, физический факультет, специальность — теоретическая физика.
С 1987 по 1997 г. — системный программист ВЦ ВолГУ, старший преподаватель кафедры радиофизики физического факультета ВолГУ.

 Как быстро построить кластер?
Как быстро построить кластер?
Вполне представима ситуация, когда по каким-либо причинам развернуть стационарный кластер не представляется возможным. Ну, например, когда компьютерный класс, который вы собираетесь использовать в качестве вычислительного кластера, по каким-то причинам обязательно должен работать под операционной системой Windows. Ничего страшного! С помощью специализированного дистрибутива PelicanHPC GNU Linux вы в любой момент, например после окончания рабочего дня и занятий в компьютерном классе, можете запустить кластер и на приведение его в боевую готовность потребуется не более пяти минут. Причем исходная операционная система, программное обеспечение и данные на используемых в качестве кластера компьютерах не будет модифицировано. После выключения кластера компьютеры придут в то состояние, которое было до начала работы кластера.
Для развертывания такого виртуального кластера вам потребуется один компакт-диск с последней версией дистрибутива PelicanHPC GNU Linux, iso-образ которого вы можете взять отсюда. С этого диска вы загружаете операционную систему кластера (не устанавливая ее на винчестер) на компьютере, который будет играть роль консоли кластера, то есть того компьютера, непосредсвенно за которым вы будете работать, компилируя и запуская ваши параллельные программы.
Остальные узлы кластера будут загружаться по сети. Для загрузки ОС вычислительных узлов кластера по сети необходимо, чтобы сетевые карты этих компьютеров умели выполнять загрузку по сети. Большинство современных карт, в том числе встроенных, это делать умеют. Если же вам не повезло, то вы всегда можете сделать загрузочный CD из образа gpxe.iso и загрузить ваши вычислительные узлы с этого CD. Если же вам совсем не повезло и на предполагаемых вычислительных узлах отсутствуют и возможность загрузки по сети и CD-приводы, то и в этом случае отчаиваться не стоит. Посетите ресурс www.rom-o-matic.net, сгенерируйте и запишите на дискету загрузочный floppy-образ, соответствующий вашим сетевым картам. С этой дискеты и выполните загрузку ОС на остальных узлах кластера.
Теперь посмотрим, как на практике выполняется загрузка кластера.
Теперь кластер работоспособен. проверим его работу на тестовой программе. Возьмем в качестве пример программу вычисления числа flops.f. Каким-либо способом копируем исходник этой программы в пользовательский каталог на консоли кластера. Далее выполняем следующие действия:
Как видно из результатов работы программы 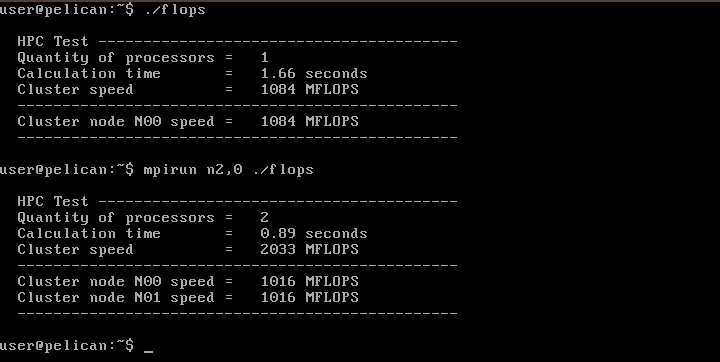
скорость вычисления на двух процессорах примерно в два раза больше, чем на одном. То есть кластер делает именно то, что мы и ожидали.
Важное замечание. По каким-то причинам конфигурация кластера оформляется таким образом, что в списке вычислительных узлов консоль кластера прописывается последней. Однако логично ожидать, что вывод программы будет идти на монитор той машины, с которой она запущена, то есть на консоль. В то же время параллельные программы обычно пишут таким образом, что весь вывод идет в процессе, который работает на самом первом узле. Поэтому при запуске программы приходится явно указывать последовательность узлов, на которых она будет выполнятся. И первым в этом списке должна быть именно консоль кластера. В нашем примере кластер состоял из трех машин. Нумерация их начинается с нуля. То есть 0, 1, 2. Поэтому мы явно указали, что первая машина — это машина номер 2 (последняя в конфигурационном списке). Указали мы это параметром n2,0, то есть программа запускалась на машине N2 и машине N0.
Если бы мы сделали кластер например из 16 машин, то их номера были бы 0, 1, 2, . 14, 15. Для запуска нашей тестовой программы на таком кластере надо было бы использовать команду
mpirun n15,0,1,2,3,4,5,6,7,8,9,10,11,12,13,14 ./flops
или в сокращенном варианте
mpirun n15,0-14 ./flops
Как сделать кластер Windows 10?
Запустите диспетчер серверов. В меню Сервис выберите Диспетчер отказоустойчивости кластеров. В области Диспетчер отказоустойчивости кластеров в разделе Управлениевыберите создать кластер. Откроется мастер создания кластеров.Apr 2, 2022
Как объединить два сервера в кластер?
Перед объединением Серверов в кластер необходимо выполнить следующие действия:Установить на оба Сервера Windows Server одной из следующих редакций: . Оба сервера обязательно добавить в один домен.При помощи Мастера добавления ролей и компонентов добавить на оба сервера компонент Отказоустойчивая Кластеризация.
Как работает отказоустойчивый кластер?
Отказоустойчивый кластер — это группа независимых компьютеров, которые работают совместно в целях повышения доступности и масштабируемости кластерных ролей (ранее называемых кластерными приложениями и службами). Кластерные серверы (называемые «узлы») соединены физическими кабелями и программным обеспечением.
Что такое кластер в компьютере?
Кластер (англ. cluster) — в некоторых типах файловых систем — логическая единица хранения данных в таблице размещения файлов, объединяющая группу секторов. Например, на дисках с размером секторов в 512 байт, 512-байтный кластер содержит один сектор, тогда как 4-килобайтный кластер содержит восемь секторов.
Создание кластера для расчета в OpenFOAM
В статье я расскажу, как можно (при необходимости) быстро и дешево собрать кластер Beowulf на основе домашних компьютеров. Выполню я это с помощью компьютеров находящихся в аудитории университета, используя существующую локальную сеть. Используемые программные инструменты: средства численного моделирования механики сплошных сред OpenFOAM, сетевого протокола прикладного уровня SSH и распределенного протокола файловой системы NFS. Все выполнялось под управлением операционной системы ubuntu 20.04.
Предисловие
Я студент, и мне в прошлом полугодии необходимо было произвести расчет аэродинамики крайне сложного аэродинамического изделия. Мой стационарный компьютер справился с этой задачей весьма долго, в связи с чем потребовалось объединение вычислительных мощностей нескольких компьютеров. Так что в этой статье будет рассмотрены только создание и тестовый запуск расчетов без визуализации массива данных с помощью программы ParaView.
Тут будет написана инструкция туториал для тех кто хочет повторить. По учебной деятельности я являюсь конструктором, в результате чего при описании команд могут возникать неточности.
Введение
Определение кластера
Кластер – группа компьютеров, объединенных в локальную вычислительную сеть (ЛВС) и способных работать в качестве единого вычислительного ресурса.
Предполагается, что для кластера обеспечивается более высокая надежность и эффективность, нежели для ЛВС, и существенно более низкая стоимость в сравнении с другими типами параллельных вычислительных систем (за счет использования типовых аппаратных и программных решений).
Кластер Beowulf

Общеизвестный кластер NASA
В настоящее время под кластером типа Beowulf понимается система, которая состоит из одного серверного узла и одного или более клиентских узлов, соединенных при помощи Ethernet или некоторой другой сети. Это система, построенная из готовых серийно выпускающихся промышленных компонентов, на которых может работать ОС Linux, стандартных адаптеров Ethernet и коммутаторов. Она не содержит специфических аппаратных компонентов и легко воспроизводима. Серверный узел управляет всем кластером и является файл-сервером для клиентских узлов. Он также является консолью кластера и шлюзом во внешнюю сеть. Большие системы Beowulf могут иметь более одного серверного узла, а также, возможно, специализированные узлы, например консоли или станции мониторинга. Они конфигурируются и управляются серверными узлами и выполняют только то, что предписано серверным узлом.
Вычислительная среда OpenFOAM
OpenFOAM — это бесплатное программное обеспечение CFD с открытым исходным кодом, разработанное, в основном, компанией OpenCFD Ltd с 2004 года. Оно имеет большую базу пользователей в большинстве областей техники и науки, как коммерческих, так и академических организаций. OpenFOAM имеет широкий набор функций для решения любых задач — от сложных потоков жидкости, включающих химические реакции, турбулентность и теплопередачу, до акустики, механики твердого тела и электромагнитных систем.
Настройка рабочей среды
Физическое соединение устройств
Два и более компьютера нужно соединить друг с другом. Самый простой способ это сделать — задействовать коммутатор и соединить их с помощью витой пары.
Выбор операционной системы
Решено использовать систему Linux, конкретный дистрибутив — Ubuntu 20.04, десктопной и серверной версии соответственно.
Это связано с тем, что по состоянию на 2022 год среда вычисления OpenFOAM, выбранная для расчётов, стабильно работает именно на этом дистрибутиве именно этой версии. Также система Linux, будучи системой с распространяемыми исходными кодами, является основой для кластера Beowulf.
Десктоп-версия
Десктоп-версия — это версия системы, имеющая графический интерфейс. Он нужен будет для удобного взаимодействия с файлами, а также для просмотра результатов расчёта. Десктоп-версия будет стоять на главном компьютере.
После того, как вы с загрузочного диска запустите установщик, следуйте серии шагов:
Выберите язык (предпочтителен English);
Нажимаем install ubuntu;
Выберите язык (предпочтителен English);
Не изменяем предустановленные программы;
Не изменяем типы инсталляторов;
Выбираем время системы;
Введите имя пользователя (в данном случае используется pisi), а также пароль. Пароли и имена серверов должны быть абсолютно одинаковы для всех компьютеров, связанных с кластером.
После перезагрузите систему (вам предложит это сделать система)
Серверная версия
Серверная же версия будет стоять на всех остальных компьютерах. На них не потребуется работать с файлами, или просматривать результаты. Все остальные компьютеры нужны исключительно, как дополнительные ресурсы для вычислений, и поэтому для них достаточно самой компактной системы с самым малым набором функций.
После того, как вы с загрузочного диска запустите установщик, следуйте серии шагов:
Выберите язык (предпочтителен English);
Не обновляйте установщик;
Не изменяйте настройки клавиатуры;
Не изменяйте настройки сети;
Используйте весь диск для установки и подтвердите его перезапись, если потребуется;
Не изменяйте настройки зеркала;
Не изменяйте настройки файловой системы;
Введите имя пользователя, сервера, а также пароль. Пароли и имена серверов должны быть абсолютно одинаковы для всех компьютеров, связанных с кластером.
Server Snaps оставьте без изменений;
После окончания установки извлеките загрузочный диск и перезагрузите компьютер.
Завершения установки
В обоих случаях, вам надо завершить установку, зайдя в директорию Home /home/<user>/, и создать папку OpenFOAM mkdir/OpenFOAM. Должен получиться путь: /home/<user>/OpenFOAM. <user> — это заданное вами имя пользователя (на изображениях в данном документе можно заметить имя «pisi»).
Наличие подкаталогов в текущем каталоге можно проверить с помощью команды ls.
Установка OpenFOAM
Установка OpenFOAM состоит так же из двух этапах и должна производиться всех компьютерах участвующих в объединении, это связано с тем, что OpenFOAM это не программа, а набор библиотек необходимых для произведения расчетов системы.
Для того чтобы установить OpenFOAM необходимо в терминале прописать следующую команду что представлена ниже.
Кратко опишем функционал команды.
curl — команда взаимодействия с интернетом.
-s –- сохранение скачанных фалов в систему.
url — ссылка на скачиваемый файл.
bash — дает возможность создания скриптов.
Примечание: если по каким то причинам не оказалось команды curl, то введите следующую команду в терминал: sudo apt install curl и убедиться что установлена правильная версия системы.
Далее необходимо распаковать и скомпилировать выше установленный набор библиотек. Для этого необходимо выполнить команду, приведенную ниже.
Примечания: так как это набор библиотек, то нет практического способа проверить правильность действий, то необходимо проверить их наличие в файловой системе операционной системы.
Для этого необходимо выполнить следующую команду в терминале.
Кратко опишем функционал команды.
cd — это переход в папку по пути.
далее идет путь.
Если в результате выполнения команды не появилось ошибок, то все действия выполнены правильно, в противном случае выполните последовательность действий начиная с скачивания OpenFOAM.
Если проверка прошла успешно, то выполняем команду cd.
Установка и настройка SSH
SSH — это защищенный протокол для удаленного управления операционной системой. Он пригодится для безопасного соединения компьютеров друг с другом.
Десктоп-версия
Десктоп-версия по-умолчанию не имеет встроенного SSH, поэтому его нужно установить, это продемонстрировано на примере ниже.
Других отличий нет. Выполняйте все те шаги, что описаны ниже, для серверной версии.
Серверная версия
В отличие от версии с графическим интерфейсом, серверная версия по-умолчанию имеет в себе предустановленный пакет OpenSSH (точнее, эту опцию можно выбрать при установке), и здесь этап установки не требуется. В противном же случае повторите действия, предназначенные для десктоп-версии.
Следом выполните следующие шаги.
Создаёт директорию SSH. Может выдать ошибку, если директория уже есть.
Назначает права полного доступа для этой директории. Может потребоваться ввести вместе с sudo.
Создаёт новый ключ. Оставьте все поля по-умолчанию.
ssh-copy-id -i /home/<user>/.ssh/id_rsa.pub <user>@<ip>
Копирует ваш ключ на другой компьютер по IP-адресу. Это позволит вам позже входить на этот компьютер без пароля.
<user> — это имя вашего пользователя.
<ip> — это IP-адрес компьютера, куда вы передаёте ключ.
Проверка подключения (должна быть без пароля).
Настройте так все компьютеры. Ключи должны быть переданы каждому сателлиту от сервера, и наоборот.
Примечание: для проверки работоспособности SSH соединение необходимо проверить несколько условий:
Соединение должно работать от каждого устройства к каждому.
Все устройства должны производить соединения без пароля за исключением первого раза.
Главное, чтобы главный компьютер мог подключиться к серверу и наоборот без пароля.
Установка и настройка NFS
Установка NFS для Десктоп-версии
В командной строке необходимо прописать команду установки утилиты для создания общей сетевой папки среди всех компьютерах кластера.
Примечание: предварительно необходимо иметь папку в домашнем каталоге, если этого нет, то просмотрите пункт «Завершения установки».
Чтобы установить NFS, необходимо скачать его. Для этого пропишем в терминале следующую команду.
После установки системной утилиты необходимо указать права доступа к папке, которую необходимо синхронизировать. Для этого в терминале нужно прописать следующий набор команд.
Кратко опишем функционал команды.
chown — это изменение владельца файла или папки
nobody:nogroup — сообщает системе что папка не принадлежит не одному владельцу и группе
Предоставим права доступа для папки.
Кратко опишем функционал команды:
777 — это теговое значение прав доступа к последующей папке.
После необходимо внести изменения в файл exports, указав узлы связи, которые вы хотите подключить к ранее приписываемой папке.
Кратко опишем функционал команды:
nano — это встроенный редактор текста, основные команды которого являются: Ctrl+S (сохранение файла) и Ctrl+X (выход из редактора).
В самом редакторе необходимо в конце прописать следующую строку.
После вписывания в файл следующей команды, повторяем её со всеми компьютерами серверной версии операционной системы.
Примечание: для того чтобы узнать IP-адрес компьютера, в командной строке введите команду ip address, там вы сможете узнать узнать адрес конкретной системы.
После всех вышеописанных действий необходимо произвести монтирование сервера. Для этого пропишем в терминале команду.
Кратко опишем функционал команды:
exportfs — это изменяемый файл.
-a — то применения изменений к нему.
Следующим шагом необходимо произвести перезагрузку сервера с настроенными параметрами сетевой папки. Для этого пропишем команду в терминале, представленную ниже.
Кратко опишем функционал команды:
systemctl — системный диспетчер.
restart — рестарт сервера.
nfs-kernel-server.service — файл сервера .
Настройка утилиты NFS для серверной версии
Для этого необходимо произвести закачку программного пакета на устройства. Воспользуемся командной, вводимой в терминале.
После, по аналогии с десктоп-версией, необходимо изменить файлы настройки сетевой папки. Для этого воспользуемся командой.
После введем в редакторе кода одну строчку, относящуюся к десктоп-версии системы.
Примечание: Ctrl+S (сохранение файла) и Ctrl+X (выход из редактора).
Далее смонтируем точку для того, чтобы сообщить десктоп-версии, что сервер готов к общению.
Примечание: Тут могут возникнуть проблемы, это нормально, значит вы что то сделали не так, как было указано в инструкции, это связано с тем что в Ubuntu нет фиксации ошибок. Для этого необходимо произвести ряд проверок, чтобы определить где произошла ошибка.
Проверьте настройку SSH, произведя подключения со всех устройств ко всем командой: ssh
Проверьте отсутствие запрашиваемого пароля при SSH-соединение..
Проверьте правильность файлов, где прописываются IP-адреса.
Проверьте, чтобы не изменились IP-адреса во время настройки (такой случай возможен).
Проверьте опечатки местоположения синхронизируемой папки.
Проверьте одинаковость названий синхронизируемой папки.
Если все вышеперечисленные проверки прошли верно, однако система все равно не заработала, то сделайте все шаги заново, так как старые файлы не удаляются, есть шанс что вы случайно исправите ошибку (на практике это часто срабатывало).
Начало вычислений
Тест проверки ядер
Перед началом работы непосредственно с OpenFOAM стоит разработать программу, которая смогла бы проверить, отзываются ли ядра у всех компьютеров, которые надо будет использовать для последующих вычислений.
Программа написана на языке С. Исходный код этой программы компилируется в исполняемый файл, именуемый «mpi_hello» (тестовое наименование, наподобие «Hello World!»). Команда компиляции в терминале следующая.
Кратко опишем функционал команды:
mpicc — команда запуска компиляции.
mpi_hello.c — файл с исходным кодом.
-o mpi_hello — выходной файл.
Полный исходный код этой программы приведен в приложении 1, здесь описаны основные моменты её работы.
Данный фрагмент кода последовательно получает три параметра: количество ядер, ранг текущего процесса, и имя хоста. Затем эти данные выводятся в терминал.
Программу можно запустить с помощью команды, представленной ниже.
Кратко опишем функционал команды:
mpirun — запуск исполняемого файла.
./mpi_hello — исполняемый файл.
Результат выводится в консоль.
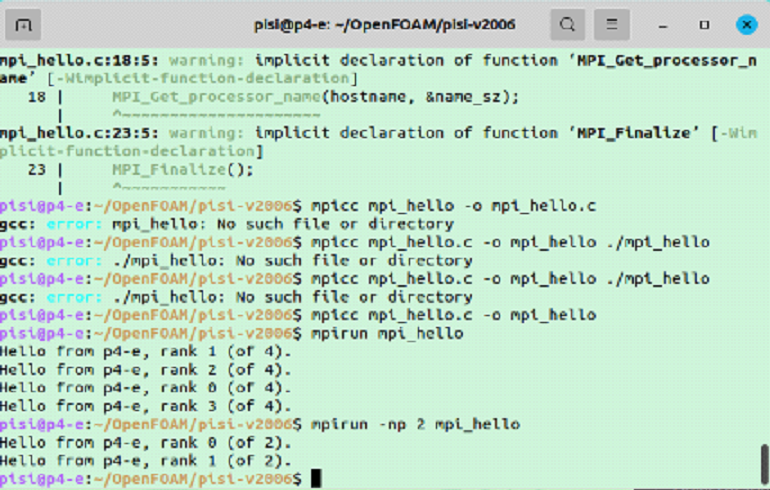
Результаты работы
Проверка работы программы на нескольких ядрах
Следующий этап — указание количества ядер. Для mpirun это возможно сделать с помощью аргумента «np».
Кратко опишем функционал команды:
-np — указания количества ядер.
Результат работы представлен ниже.
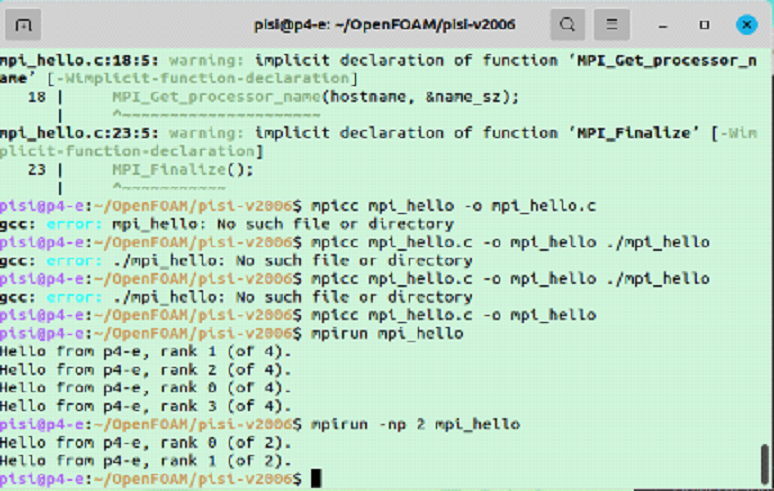
Отчет работы программы по нескольким ядрам
Проверка работы на нескольких компьютерах
С помощью команды “mpirun” в терминале можно также послать скомпилированную программу на несколько компьютеров.
Количество процессоров –- общее для всех компьютеров, а имя файла — это имя файла, где перечислены IP-адреса и количество ядер, которое будет у него использоваться.
Параметр slots отвечает за количество ядер.
Первый адрес, 127.0.0.1, — это локальный адрес компьютера (localhost), с него всегда начинается основная работа. Другие IP-адреса — это IP-адреса других компьютеров.
Примечание. Данную команду не надо выполнять на компьютере-сателлите, так как локальный адрес будет совпадать с одним из ниже перечисленных, что приведёт к путанице с распределением и последующей ошибке.
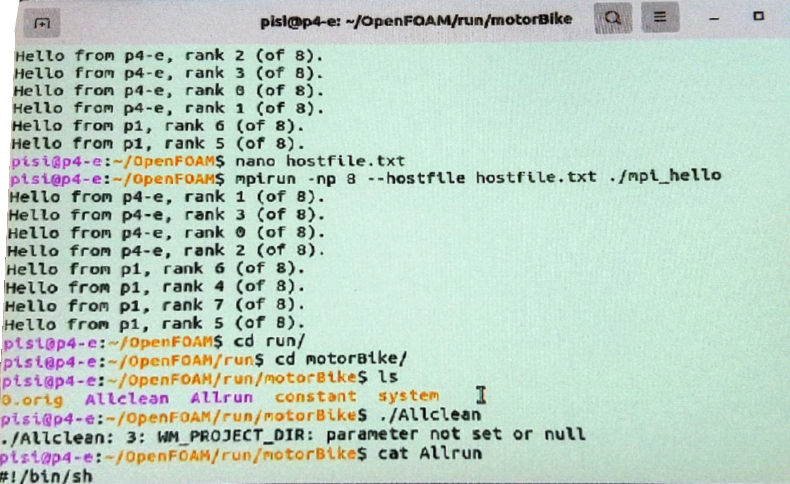
Отчет программы после работы на нескольких компах
Проверка концепции ускорения (уменьшение времени) скорости вычислений общей задачи. Для этого воспользуемся стандартной задачей предложенной openfoam на головной странице. Так что первоначально копируем пример из домашней директории OpenFOAM в папку, синхронизируемую ранее (сетевую папку).
Примечание: предварительно необходимо создать папку
Далее, после того, как в соответствующий каталог скопируются файлы, необходимо будет запустить утилиту создания служебных файлов, находясь в импортированной папке.
После необходимо распаковать файл геометрии мотоцикла, для этого воспользуемся командой, описанной ниже, при использовании встроенного разархиватора.
Далее необходимо создать сетку на компьютере, так как необходимые файлы были экспортированы и распакованы выше. Для того, чтобы выполнить расчет сетки, необходимо прописать в консоли команду.
Примечание: этот процесс занимает крайне много времени и требует большой объем оперативной памяти. В нашем случае — около 80 ГБ на 3 компьютера. Чтобы не устанавливать дорогостоящую память в компьютер, необходимо увеличить файл подкачки на SSD-диске. Для этого необходимо выполнить команду.
Примечание: все промежуточные значения прописываются в файле log ,и если что то пошло не так, то подробности можно узнать там.
Далее, после просчета сетки, можно приступить к запуску самого расчета задачи. Для этого вставим в командную строку текст.
ЗАКЛЮЧЕНИЕ
В результате проведения стресс тестов кластера на расчет были выявлены закономерности, приведенные в таблицах ниже с выводами. Так же приводятся казусы, которые не решились, или частично были решены в ходе выполнения работы.
Примечание: точность выводов основана на субъективной оценке в связи с невозможностью составления прогноза работы и скорости вычислений.
Мы провели два теста, на машине из 4-х ядер и одном компьютере и машине из 12 ядер и трех компьютеров. Расчет времени выполнения производился автоматически с записью в файл log, это нужно было для отладки работоспособности кластера, но этот процесс занимает определенное время, которое посчитать не удалось. Однако, так как геометрия была одинаковой и файлы log аналогичные, следовательно приобретенное время в двух тестах было одинаковым и в сравнении друг с другом не будут вносить ошибку. Далее приведена таблица с характеристиками двух тестов, которые мы посчитали уместным.