Как разбить большой xml-файл на более мелкие?
Как большой текстовый файл разбить на n равных строк?
Помогите пожалуйста большой текстовый файл разбить на несколько равных строк(string).Видел пример.
Как разбить большой файл сохранив макросы во всех частях?
Есть необходимость разбить этот файл на несколько файлов (около 50), причём с сохранением в каждом.
Как разбить файл XML на 2 или несколько
Помогите, пожалуйста разбить 1 фаил XML на несколько таким образом, чтобы 1 столбец был обшим!Т.е.
 Разбить большой лог файл
Разбить большой лог файл
Ребят, всем доброго времени суток. Нужна помощь. Есть большой лог файл, его нужно разбить на 5.
Разбить XML файл на несколько частей.
Есть что-то готовое для резки XML (хотя с трудом представляю как. ) на части. Мне надо распилить файл где-то на 20 частей.

По каким критериям резать? Надо ли на выходе получать well-formed/valid XML?
Скорее всего, кури XPath и XSLT.

есть многое на свете, друг горацио, что и не снилось нашим мудрецам

xmllint —help | grep xpath; xslt
Надо ли на выходе получать well-formed/valid XML?
Да. Допустим порезать между тегами 2 уровня вложенности.

Подозреваю тебе прийдется сделать это «аналитически». Используя любую библиотеку считывать, зная формат определять в место разрыва (зная формат его можно определить), например если дерево двухуровневое, можно складывать
50% тегов в один файл и 50% в другой, дублируя корень. Не думаю что есть универсальный инструмент для такого. Это же как резать без рентгена.
Разделение больших файлов XML в Java
На прошлой неделе меня попросили написать что-то на Java, способное разбить один XML-файл размером 30 ГБ на более мелкие части настраиваемого размера файла. Потребителем файла будет промежуточное приложение, которое имеет проблемы с большим размером XML. Под капотом он использует какую-то технику синтаксического анализа DOM, из-за которой через некоторое время ему не хватает памяти. Так как это промежуточное ПО, основанное на поставщиках, мы не можем исправить это сами. Нашим лучшим вариантом является создание некоторого инструмента предварительной обработки, который сначала разбивает большой файл на несколько более мелких кусков, прежде чем они будут обработаны промежуточным программным обеспечением.
Файл XML поставляется с соответствующей схемой W3C, состоящей из обязательной части заголовка, за которой следует элемент содержимого, в который вложено несколько элементов данных 0 .. *. Для демонстрационного кода я заново создал схему в упрощенном виде:
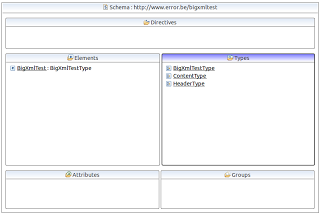

Заголовок ничтожен по размеру. Повторение одного элемента данных также довольно мало, скажем, менее 50 кБ. XML очень большой из-за количества повторений элемента данных. Требования таковы:
- Каждая часть разделенного XML должна быть синтаксически допустимым XML, и каждая часть также должна проверяться на соответствие исходной схеме
- Инструмент должен проверять XML в соответствии со схемой и сообщать о любых ошибках валидации. Валидация не должна быть блокирующей, а не валидирующие элементы или атрибуты не должны быть пропущены в выходных данных.
- Для заголовка решено, что вместо того, чтобы копировать его в каждый из новых выходных файлов, заголовок будет сгенерирован заново для каждого нового выходного файла с некоторой информацией об обработке и некоторыми значениями по умолчанию
Таким образом, об использовании инструментов бинарного разделения, таких как Unix Split, не может быть и речи. Это разделится после фиксированного количества байтов, оставляя XML поврежденным наверняка. Я не совсем уверен, но такие инструменты, как Split, также ничего не знают о кодировании. Таким образом, разделение после байта ‘x’ может привести не только к разделению в середине элемента XML (например), но даже в середине последовательности кодирования символов (при использовании Unicode, который, например, кодируется UTF8). Понятно, что нам нужно что-то более умное.
XSLT как основная технология тоже не годится. С первого взгляда можно поддаться искушению: используя XSLT2.0, можно создать несколько выходных файлов из одного входного файла. Должна быть возможность проверки входного файла при преобразовании. Однако дьявол, как всегда, в деталях. В противном случае простые операции в Java, такие как запись ошибок проверки в отдельный файл или проверка размера текущего выходного файла, вероятно, потребуют пользовательский код Java. Это возможно с Xalan и Saxon, чтобы иметь такие расширения, но Xalan не является реализацией XSLT2.0, поэтому оставляет нас с Saxon. И последнее, но не менее важное: XSLT1.0 / 2.0 не являются потоковыми, что означает, что они будут считывать весь исходный документ в память, поэтому это явно исключает XSLT из возможностей.
Это оставляет нам синтаксический анализ Java XML в качестве единственного оставшегося варианта. Идеальным кандидатом в этом случае является, конечно, StAX. Я не буду здесь сравнивать SAX с StAX, факт в том, что StAX может проверять на соответствие схемам (по крайней мере, некоторые парсеры), а также может писать XML. Более того, API намного проще в использовании, чем SAX, потому что он основан на извлечении, он дает больший контроль над итерацией документа и работает более приятным, чем толчок SAX. Хорошо, что нам нужно:
- Реализация StAX, способная проверять XML
- Oracle JDK поставляется по умолчанию с SJSXP в качестве реализации StAX, но этот, однако, не проверяется; так что я закончил с использованием Woodstox. Насколько я мог найти, проверка с помощью Woodstox возможна только с использованием API курсора StAX.
- Ясно JAXB. Он поддерживает StAX, так что вы можете создать свою объектную модель и затем позволить ей напрямую записывать в выходной поток StAX.
Код немного велик, чтобы показать его здесь в целом. Доступны как исходные файлы, так и XSD и тестовый XML
здесь, на GitHub. В нем есть файл pom Maven, поэтому вы сможете импортировать его в выбранную вами среду IDE. Компилятор привязки JAXB автоматически скомпилирует схему и поместит сгенерированные источники в путь к классам.Первая строка создает наш потоковый ридер StAX, что означает, что мы используем курсор API. API итератора использует класс XMLEventReader. В имени класса также есть странная цифра «2», которая относится к функциям StAX 2 от Woodstox, одной из которых, вероятно, является поддержка валидации. От
здесь :“enableValidationHandling” можно увидеть в
Исходный файл, если хотите. Я выделю важные части. Сначала загрузите схему XML:Обратный вызов для записи возможных результатов проверки в выходной файл;
«OpenOutputFileAndWriteHeader» создаст XMLStreamWriter (который снова является частью API курсора, API итератора имеет XMLEventWriter), в который мы можем вывести или часть исходного файла XML. Он также будет использовать JAXB для создания нашего заголовка и позволит ему записать в вывод. Объекты JAXB генерируются по умолчанию с помощью компилятора Schema (xjc).
В строке 3 мы включаем «восстановление пространств имен». В спецификации есть это, чтобы сказать:
Из этого я понимаю, что он необходим для обработки пространств имен по умолчанию. Дело в том, что если оно не включено, пространство имен по умолчанию не записывается никоим образом. В строке 6 мы устанавливаем пространство имен по умолчанию. Установка его на самом деле не записывает его в поток. Следовательно, требуется writeDefaultNamespace (строка 9), но это можно сделать только после того, как начальный элемент был записан. Таким образом, вы должны определить пространство имен по умолчанию перед записью каких-либо элементов, но вам нужно написать пространство имен по умолчанию после записи первого элемента. Обоснование заключается в том, что StAX нужно знать, должен ли он генерировать префикс для корневого элемента, который вы собираетесь написать, да или нет.
В строке 8 мы пишем корневой элемент. Важно указать, к какому пространству имен принадлежит этот элемент. Если вы не укажете префикс, префикс будет сгенерирован для вас, или, в нашем случае, префикс вообще не будет сгенерирован, потому что StAX знает, что мы уже установили пространство имен по умолчанию. Если вы удалите указание пространства имен по умолчанию в строке 6, к корневому элементу будет добавлен префикс (со случайным префиксом), например: <wstxns1: BigXmlTest xmlns: wstxns1 = “http: // www… Далее мы напишем наше пространство имен по умолчанию, это будет записано в элемент, начатый ранее (кстати, для более глубокого понимания этого порядка см. эту прекрасную статью ). В строке 11-14 мы используем нашу сгенерированную модель JAXB для создания заголовка и позволяем нашему маршаллеру JAXB записать его непосредственно в наш StAX выходной поток.
Важно: маршаллер JAXB инициализируется в режиме фрагмента, в противном случае он начнет добавлять декларацию XML, как это потребуется для автономных документов, и это, конечно, недопустимо в середине существующего документа:
Кстати, интеграция JAXB в данном примере не очень полезна, она создает больше сложности и требует больше строк кода, чем простое добавление элементов с использованием XMLStreamWriter. Однако, если у вас есть более сложная структура, которую вам нужно создать и объединить с документом, очень удобно иметь автоматическое сопоставление объектов.
Итак, у нас есть читатель, который включен для проверки. С того момента, как мы начнем перебирать исходный документ, он будет проверяться и анализироваться одновременно. Затем у нас есть наш писатель, у которого уже есть инициализированный документ и заголовок, и он готов принять больше данных. Наконец, мы должны перебрать исходный код и записать каждую часть в выходной файл. Если выходной файл станет большим, мы переключим его на новый:
Важным моментом является то, что мы продолжаем перебирать исходный документ и проверяем наличие начала элемента Data. Если это так, мы направляем соответствующий элемент и его элементы на выход. В нашем простом примере у нас нет братьев и сестер, только текстовое значение. Но если структура более сложная, все нижележащие узлы будут автоматически скопированы в выходные данные. Каждые два элемента данных мы будем циклически повторять наш выходной файл Модуль записи закрывается и инициализируется новый (эту проверку, конечно, можно заменить проверкой размера файла вместо% 2). Если средство записи закрыто, оно автоматически позаботится о закрытии открытых элементов и, наконец, о закрытии самого документа, нет необходимости делать это самостоятельно. Что касается механизма для потоковой передачи узлов от входа к выходу:
- Поскольку мы вынуждены использовать API курсора из-за проверки, мы должны использовать XSLT для передачи узла и его элементов в выходные данные. XSLT имеет несколько шаблонов по умолчанию, которые будут вызываться, если вы не укажете XSL специально. В этом случае он преобразует входной сигнал в заданный выходной.
- Необходим пользовательский FragmentXMLStreamWriterWrapper , я задокументировал это в JavaDoc. Эта оболочка снова обернута в AvoidDefaultNsPrefixStreamWriterWrapper . Причина последнего заключается в том, что шаблон XSLT по умолчанию не распознает пространство имен по умолчанию в нашем исходном документе. Подробнее об этом через минуту (или поиск AvoidDefaultNsPrefixStreamWriterWrapper).
- Используемый вами преобразователь должен быть внутренней версией Oracle JDK. Там, где мы инициализируем преобразователь, мы напрямую ссылаемся на экземпляр внутреннего TransformerFactory: com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl, который затем создает правильный преобразователь: transformer = new TransformerFactoryImpl (). NewTransformer (); Обычно вы будете использовать TransformerFactory.newInstance () и использовать преобразователь, доступный в пути к классам. Однако парсеры и преобразователи могут устанавливать себя, предоставляя сервисы META-INF /. Если другой преобразователь (например, Xalan по умолчанию, а не перепакованная версия JDK) окажется в пути к классам, преобразование завершится неудачно. Причина в том, что, по-видимому, только внутренняя версия JDK может преобразовывать StAXSource в StAXResult.
- Преобразователь фактически позволяет нашему XMLStreamReader продолжать работу в процессе итерации. Таким образом, после обработки элемента данных курсор считывателя теоретически будет готов к следующему элементу данных. В теории это так, поскольку следующий тип события может быть пробелом, если ваш XML отформатирован. Таким образом, все еще могут потребоваться некоторые итерации для xmlStreamReader.next () в нашем цикле while, прежде чем следующий элемент Data будет фактически готов.
В результате мы имеем 3 выходных файла, каждый из которых соответствует исходной схеме, каждый из которых имеет 2 элемента данных:
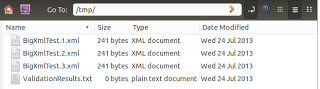
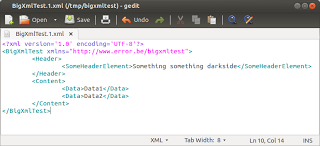
Чтобы разделить XML-файл размером30 ГБ (я говорю о моем исходном XML-назначении с более сложной структурой, а не о демонстрационном XSD, используемом здесь) на части
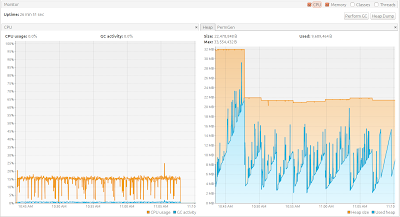
500 МБ с проверкой, это заняло около 25 минут. Чтобы проверить использование памяти, я намеренно установил Xmx на 32 МБ. Как вы можете видеть на графике, потребление памяти очень низкое и нет накладных расходов GV:
Жизнь хороша, но не полностью. Там, где я обнаружил некоторые неловкие вещи, о которых нужно быть осторожным.
В моем реальном сценарии входной XML не имел связанных с ним пространств имен, и я уверен, что никогда не будет. Вот почему я придерживаюсь этого решения. В демоверсии здесь есть единственное пространство имен, и это уже начинает делать настройку более хрупкой. Проблема не в StAX: обрабатывать пространства имен с помощью StAX довольно просто. Вы можете решить использовать пространство имен по умолчанию (при условии, что ваша Схема имеет значение elementFormDefault = qualified), соответствующее целевому пространству имен Схемы, и, возможно, объявить некоторые префиксные пространства имен для, возможно, других пространств имен, которые импортируются в Схеме. Проблемы начинаются (как вы уже могли заметить), когда XSLT начинает мешать выходному потоку. Очевидно, он не проверяет, какие пространства имен уже определены или что-то еще происходит.
В результате они серьезно загромождают документ, переопределяя существующие пространства имен с другими префиксами или сбрасывая пространство имен по умолчанию и другие ненужные вещи. Вероятно, нужен XSL, если вам нужно больше манипулировать пространством имен, чем шаблон по умолчанию. XSLT также будет вызывать исключения, если во входном документе используются пространства имен по умолчанию. Он попытается зарегистрировать префикс с именем “xmlns”. Это недопустимо, поскольку xmlns зарезервировано для указания пространства имен по умолчанию, которое нельзя использовать в качестве префикса. Исправление, которое я применил для этого теста, заключалось в том, чтобы игнорировать любой префикс, который является «xmlns», и игнорировать добавление целевого пространства имен в сочетании с префиксом xmlns (именно поэтому у нас есть AvoidDefaultNsPrefixStreamWriterWrapper). Префикс и пространство имен должны совпадать в AvoidDefaultNsPrefixStreamWriterWrapper, потому что если у вас будет входной документ без пространства имен по умолчанию, но с префиксами (например, <bigxml: BigXmlTest xmlns: bigxml = “http: //….”> <Bigxml: Header ….) Тогда вы не можете игнорировать добавление пространства имен (тогда комбинация будет целевым пространством имен с префиксом «bigxml»), поскольку это даст только префиксы для элементов данных без привязки к ним пространств имен, например:
XML Split of a Large file
I have a 15 GB XML file which I would want to split it .It has approximately 300 Million lines in it . It doesn’t have any top nodes which are interdependent .Is there any tool available which readily does this for me ?

10 Answers 10
QXMLEdit has a dedicated function for that: I used it successfully with a Wikipedia dump. The
2.7Gio file became a bunch of
1 400 000 files (one per page). It even allows you to dispatch them in subfolders.
XmlSplit — A Command-line Tool That Splits Large XML Files
xml_split — split huge XML documents into smaller chunks
Split that XML by bhayanakmaut (No source code and I could not get this one working)
I think you’ll have to split manually unless you are interested in doing it programmatically. Here’s a sample that does that, though it doesn’t mention the max size of handled XML files. When doing it manually, the first problem that arises is how to open the file itself.
I would recommend a very simple text editor — something like Vim. When handling such large files, it is always useful to turn off all forms of syntax highlighting and/or folding.
Other options worth considering:
EditPadPro — I’ve never tried it with anything this size, but if it’s anything like other JGSoft products, it should work like a breeze. Remember to turn off syntax highlighting.
VEdit — I’ve used this with files of 1GB in size, works as if it were nothing at all.