Как выполнить регрессионный анализ в Excel за 9 шагов (плюс советы)
Профессионалы в различных областях используют такие программы, как Excel, для выполнения расчетов, которые дают им полезную информацию о прибыли, тенденциях и любых других факторах, влияющих на успех их проектов. Одним из распространенных методов выявления взаимосвязей между переменными является выполнение регрессионного анализа, который создает линию регрессии, которая может сообщить вам о характере корреляции между переменными. Если вы заинтересованы в изучении взаимосвязей между различными факторами вашего бизнеса или отрасли, выполнение регрессионного анализа в Excel может дать представление о взаимосвязи между различными переменными.
В этой статье мы объясняем, что такое регрессионный анализ, обсуждаем наиболее распространенные регрессионные модели, описываем, когда регрессионный анализ может быть полезен, перечисляем шаги для проведения собственного регрессионного анализа в Microsoft Excel и даем советы, как максимально упростить этот процесс для любого пользователя. будущие расчеты.
Что такое регрессионный анализ?
Регрессионный анализ относится к математическим методам, которые позволяют исследователям выявлять тенденции в наборах данных. Вы можете использовать регрессионный анализ, чтобы определить взаимосвязь между различными переменными. Регрессионный анализ может облегчить предсказание будущих трендов переменных путем анализа траектории линии регрессии. Например, если вы проводили регрессионный анализ, чтобы понять взаимосвязь между переменной x и переменной y, направление линии регрессии может дать информацию о характере этой взаимосвязи. Вот три наиболее распространенных типа моделей регрессионного анализа:
Программы для Windows, мобильные приложения, игры — ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале — Подписывайтесь:)
Простая линейная регрессия
Простая линейная регрессия — это базовая модель регрессионного анализа, позволяющая определить взаимосвязь между зависимой и одиночной независимой переменной. Модель находит линейную функцию, представленную в виде невертикальной линии, которая может помочь предсказать результат зависимой переменной по отношению к независимой. В простой модели линейной регрессии используется следующее уравнение:
Y = зависимая (отклик) переменная
X = независимая (объясняющая) переменная
b = наклон (крутизна линии регрессии)
a = точка пересечения (где линия пересекает ось)
ϵ = остаток регрессии (ошибка)
Множественная линейная регрессия
Множественная линейная регрессия — это модель, которая может определить, как две или более независимые переменные могут предсказать результат зависимой переменной. Это распространенная модель для прогнозирования факторов, которые могут иметь прямое влияние на результаты бизнеса и других отраслей. Модель множественной линейной регрессии использует следующее уравнение:
Y = b0 + b1X1 + b1 + b2X2 +…+ bpXp
Y = зависимая (отклик) переменная
X1, X2, Xp… = независимые (объясняющие) переменные
b0 = Y, когда все независимые переменные равны 0
b1, b2, bp… = коэффициенты регрессии
Нелинейная регрессия
Нелинейный регрессионный анализ может быть полезен при попытке определить корреляцию между зависимыми и независимыми переменными, когда связь между ними определить непросто. Как правило, нелинейные регрессии используют более сложные наборы данных, чем наборы данных линейной модели. Из-за этого линия регрессии часто изгибается, чтобы сделать визуальное представление корреляции более точным.
Когда делать регрессионный анализ
Выполнение регрессионного анализа может предоставить вам полезную информацию о взаимосвязи между различными переменными, и, таким образом, это процесс, который профессионалы используют в различных сценариях и отраслях. Типичная причина проведения регрессионного анализа — определить, какие переменные оказывают наибольшее влияние на результат отношений. Это может предоставить много полезной информации о факторах, которые могут принести наибольшую прибыль, таких как различные продукты, время года, демографические данные и все остальное, что может повлиять на результат зависимой переменной.
Например, если производитель одежды хочет определить, какие продукты приносят наибольшую прибыль летом, он может провести множественный линейный регрессионный анализ. Они могут использовать программу, например Microsoft Excel, для ввода информации, представляющей зависимую переменную (продажи летом) и независимые переменные (различные предметы одежды для продажи). Создавая линию регрессии, производитель может определить, какие товары наиболее тесно связаны с увеличением продаж, и сосредоточиться на производстве и маркетинге этих товаров в течение будущих летних сезонов.
Как сделать регрессионный анализ в Excel
Если вы хотите провести регрессионный анализ, один из самых доступных способов сделать это — использовать приложение Microsoft Excel на вашем компьютере. Вот несколько шагов, которые вы можете выполнить при выполнении собственного регрессионного анализа с помощью Excel:
1. Введите свои данные в Excel
Первый шаг к выполнению вашего регрессионного анализа в Excel включает в себя ввод ваших наборов данных в приложение Excel. Для этого откройте приложение Excel и введите свои данные в разные столбцы, которые вы можете пометить, чтобы они соответствовали вашим переменным. На эти данные вы можете ссылаться при выполнении расчетов регрессионного анализа на последующих этапах процесса.
2. Установите плагин Data Analysis ToolPak
Следующий шаг — убедиться, что на вашем компьютере установлено бесплатное программное обеспечение Data Analysis ToolPak. Эта программа предоставляет необходимые инструменты для расчета широкого спектра статистических запросов, включая регрессионный анализ. Чтобы проверить, есть ли у вас пакет инструментов анализа данных, откройте приложение Excel и перейдите на верхнюю панель на вкладку «Данные» и посмотрите, заполняется ли вкладка «Анализ данных». Если это не так, нажмите «Инструменты анализа», а затем «Пакет инструментов анализа данных», чтобы установить.
3. Откройте «Анализ данных», чтобы открыть диалоговое окно.
После того, как вы успешно загрузили подключаемый модуль Data Analysis ToolPak, вы можете начать свои расчеты. Для этого откройте приложение Excel и щелкните вкладку «Данные» на верхней панели и перейдите к кнопке «Анализ данных», чтобы открыть диалоговое окно. Когда поле заполнится, выберите «Регрессия» и нажмите «ОК», чтобы начать ввод переменных данных.
4. Введите переменные данные
Чтобы начать регрессионный анализ, щелкните поле «Входной диапазон Y» и введите диапазон, в котором вы хотите произвести расчет. Например, если вы пытаетесь вычислить зависимую переменную, и она находится в столбце C с числами, начинающимися после третьей строки и заканчивающимися 20-й строкой, вы должны ввести $C$3:$C$20. Выполните те же шаги при вводе данных независимой переменной, настраивая различные метки столбцов.
5. Выберите параметры вывода
Следующим шагом является выбор параметров вывода, чтобы определить, как вы хотите, чтобы Excel отображал результаты после их расчета. После ввода входных данных установите флажок «Ярлыки» и перейдите вниз к разделу «Параметры вывода». Выберите всплывающее окно «Диапазон вывода» и введите столбец и строку, в которые вы хотите заполнить сводку. Затем установите флажок «Остатки» и нажмите «ОК», чтобы запустить расчет.
6. Проанализируйте свои результаты
Следующим шагом в проведении регрессионного анализа является интерпретация результатов ваших вычислений. Итоговый вывод даст несколько значений, особенно показательным из которых является значение R2, которое может измерять пропорцию вариаций между зависимыми и независимыми переменными, а также то, подходит ли используемая вами модель регрессии для ваших данных. Значения R2 варьируются от нуля до единицы, при этом более высокое значение соответствует лучшему соответствию модели. Значение p может информировать вас о корреляции между независимыми и зависимыми переменными, при этом меньшее значение указывает на корреляцию.
7. Создайте точечный график
Чтобы превратить ваши значения регрессии в наглядную диаграмму, начните с выделения столбцов данных, включая их заголовки, и нажмите «Вставить» на верхней панели. Перейдите к «Рекомендуемым диаграммам» и нажмите на точечную диаграмму. После того, как вы выберете параметр рассеяния, Excel создаст точечную диаграмму ваших данных на вашем листе.
8. Добавьте линию тренда регрессии
Чтобы добавить линию тренда, щелкните правой кнопкой мыши любую точку на диаграмме рассеяния, чтобы открыть меню, в котором вы можете перейти к кнопке «Добавить линию тренда». Поле «Формат линии тренда» появится на правой панели экрана, где вы можете выбрать параметр «Линейный» в раскрывающемся списке «Параметры линии тренда». Затем прокрутите вниз и установите флажок рядом с параметром «Отображать уравнение на диаграмме», чтобы включить формулу регрессии в диаграмму.
9. Добавьте последние эстетические штрихи
Последним шагом при выполнении регрессионного анализа в Excel является настройка диаграммы в соответствии с вашими личными предпочтениями. Для этого вы можете выбрать вкладку «Заливка и линия», представленную ведром с краской, на панели «Формат линии тренда». Здесь вы можете настроить размер, цвет, прозрачность и ширину линии тренда. Другие эстетические настройки, которые вы можете внести, например, пометив свои оси, щелкнув «Элементы диаграммы» и «Названия осей» и перетащив уравнение туда, где вы предпочитаете, чтобы оно было на диаграмме.
Советы по проведению регрессионного анализа в Excel
Вот несколько советов, которым вы можете следовать при попытке запустить собственный регрессионный анализ с помощью Microsoft Excel:
Дважды проверьте свои данные. Чтобы убедиться, что ваш анализ данных максимально точен, попробуйте перепроверить свои данные до и после ввода их в Excel. Это может помочь вам определить потенциальные расхождения в ваших данных, которые вы можете заблаговременно исправить и использовать для получения полезного и информативного регрессионного анализа.
Отобразите значение R2 на диаграмме. Еще один совет при проведении регрессионного анализа — включить значение R2 в диаграмму, чтобы предоставить дополнительную информацию о силе взаимосвязи между переменными. Это полезно для тех, кто использует вашу диаграмму, чтобы сделать выводы относительно корреляции между зависимой и независимой переменной, не обращаясь к сводной выходной таблице.
Сохраните свои данные. Попробуйте сохранить все ваши входные данные, чтобы использовать их для будущего анализа, диаграмм или любых других расчетов, которые могут вам понадобиться при использовании Excel. Это может упростить поиск важных данных и обращение к ним без необходимости вводить их каждый раз, когда вы выполняете расчет или анализ.
Обратите внимание, что ни одна из компаний, упомянутых в этой статье, не связана с компанией Indeed.
Линейная парная регрессия на точечной диаграмме в MS Excel
Рассмотрим один из самых простых и быстрых способов получения статистической модели взаимосвязи между двумя случайными переменными в виде уравнения парной линейной регрессии. Для этого будем использовать точечную диаграмму и линию тренда в среде электронных таблиц MS Excel.
Уравнение линейной парной регрессии имеет вид:
![\[ y=a+bx+\varepsilon, \]](http://sinpix.ru/wp-content/ql-cache/quicklatex.com-2a06ef51179fb4950ddb83beba845eca_l3.png)
где  — моделируемая переменная,
— моделируемая переменная,
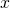 — переменная-фактор,
— переменная-фактор,
 — ошибка.
— ошибка.
Стандартной задачей является нахождение параметров  и
и  для конкретных статистических данных. Рассмотрим пример решения этой задачи простыми инструментами программы MS Excel.
для конкретных статистических данных. Рассмотрим пример решения этой задачи простыми инструментами программы MS Excel.
Пример. Изучается зависимость себестоимости единицы изделия (, тыс. руб.) от величины выпуска продукции (, тыс. шт.) по группам предприятий за отчетный период. Экономист обследовал  предприятий и получил следующие результаты:
предприятий и получил следующие результаты:
|
2 | 3 | 4 | 5 | 6 |
|
1,9 | 1,7 | 1,8 | 1,6 | 1,4 |
Найти уравнение линейной парной регрессии  .
.
Источник: Просветов Г.И. Эконометрика: задачи и решения: учебно-методическое пособие. — М.: Издательство «Альфа-пресс», 2008. — 192 с. (Пример 18, с.32)
Решение. Введем исходные данные в таблице MS Excel:

Выделим диапазон исходных данных:

В меню Вставка выбираем инструмент Точечная диаграмма (именно эта диаграмма позволяет строить точки по двум координатам):

Появляется диаграмма (в статистике этот график называют корреляционным полем):

Выполняем правый щелчок мыши по любой точке на диаграмме, появляется контекстное меню, в котором выбираем команду Добавить линию тренда :

Появляется окно диалога:

В окне диалога Формат линии тренда выбираем вид Линейная (обычно выбрано по умолчанию) и ставим флажок Показывать уравнение на диаграмме , нажимаем кнопку Закрыть . На точечной диаграмме появляется сглаживающая линия и ее уравнение, это и есть искомое уравнение регрессии:

Таким образом, уравнение регрессии имеет вид:
![\[y=-0,11x+2,12+\varepsilon\]](http://sinpix.ru/wp-content/ql-cache/quicklatex.com-8f8a7cfa8b7d65347d597eeabc6db0f4_l3.png)
Сделаем вывод: коэффициент регрессии  показывает, что при увеличении выпуска продукции на одну тысячу штук, себестоимость единицы продукции уменьшается в среднем на 0,11 тысяч рублей.
показывает, что при увеличении выпуска продукции на одну тысячу штук, себестоимость единицы продукции уменьшается в среднем на 0,11 тысяч рублей.
Задание на СР: Найти уравнение линейной парной регрессии, если — недельные объемы продаж, тыс. руб., — расходы на рекламу, тыс. руб.
|
5 | 8 | 6 | 5 | 3 | 9 | 12 | 4 | 3 | 10 |
|
72 | 76 | 78 | 70 | 68 | 80 | 82 | 65 | 62 | 90 |
Источник: Просветов Г.И. Эконометрика: задачи и решения: учебно-методическое пособие. — М.: Издательство «Альфа-пресс», 2008. — 192 с. (Задача 18, с.32)
Линейная регрессия в Excel — Как сделать линейную регрессию в Excel?

Линейная регрессия — это статистический метод / метод, используемый для изучения взаимосвязи между двумя непрерывными количественными переменными. В этом методе независимые переменные используются для прогнозирования значения зависимой переменной. Если существует только одна независимая переменная, то это простая линейная регрессия, а если число независимых переменных больше, чем одна, то это множественная линейная регрессия. Модели линейной регрессии имеют связь между зависимыми и независимыми переменными путем подгонки линейного уравнения к наблюдаемым данным. Линейный относится к тому факту, что мы используем линию, чтобы соответствовать нашим данным. Зависимые переменные, используемые в регрессионном анализе, также называют ответными или прогнозными переменными, а независимые переменные также называют объясняющими переменными или предикторами.
Линия линейной регрессии имеет уравнение вида: Y = a + bX;
- X — объясняющая переменная,
- Y является зависимой переменной,
- б — наклон линии,
- a является y-перехватом (то есть значением y, когда x = 0).
Метод наименьших квадратов обычно используется в линейной регрессии, которая рассчитывает линию наилучшего соответствия для наблюдаемых данных путем минимизации суммы квадратов отклонения точек данных от линии.
Методы использования линейной регрессии в Excel
В этом примере показано, как выполнить анализ линейной регрессии в Excel. Давайте посмотрим на несколько методов.
Вы можете скачать этот шаблон Excel с линейной регрессией здесь — Шаблон Excel с линейной регрессией
Метод № 1 — Точечная диаграмма с линией тренда
Допустим, у нас есть набор данных о некоторых людях с их возрастом, индексом биомассы (ИМТ) и суммой, потраченной ими на медицинские расходы за месяц. Теперь, имея представление о характеристиках людей, таких как возраст и ИМТ, мы хотим выяснить, как эти переменные влияют на медицинские расходы, и, следовательно, использовать их для проведения регрессии и оценки / прогнозирования средних медицинских расходов для некоторых конкретных людей. Давайте сначала посмотрим, как только возраст влияет на медицинские расходы. Давайте посмотрим на набор данных:

Сумма на медицинские расходы = б * возраст + а
- Выберите два столбца набора данных (x и y), включая заголовки.

- Нажмите «Вставить» и разверните раскрывающийся список «Диаграмма разброса» и выберите эскиз «Разброс» (первый)

- Теперь появится график рассеяния, и мы нарисуем на этом линию регрессии. Для этого щелкните правой кнопкой мыши любую точку данных и выберите «Добавить линию тренда».

- Теперь на панели «Format Trendline» справа выберите «Linear Trendline» и «Показать уравнение на графике».

- Выберите «Показать уравнение на графике».

Мы можем импровизировать диаграмму в соответствии с нашими требованиями, такими как добавление названий осей, изменение масштаба, цвета и типа линии.

После Импровизации диаграммы мы получаем вывод.

Примечание. В этом типе графика регрессии зависимая переменная всегда должна быть на оси y и не зависеть от оси x. Если график отображается в обратном порядке, либо переключите оси в диаграмме, либо поменяйте местами столбцы в наборе данных.
Метод № 2 — Анализ надстройки ToolPak Метод
Пакет инструментов анализа иногда не включен по умолчанию, и нам нужно сделать это вручную. Для этого:

- Нажмите на меню «Файл».

После этого нажмите «Опции».

- Выберите «Надстройки Excel» в поле «Управление» и нажмите «Перейти»

- Выберите «Пакет инструментов анализа» -> «ОК»

Это добавит инструменты «Анализ данных» на вкладку «Данные». Теперь запустим регрессионный анализ:
- Нажмите «Анализ данных» на вкладке «Данные»

- Выберите «Регрессия» -> «ОК».

- Откроется диалоговое окно регрессии. Выберите диапазон ввода Y и диапазон ввода X (медицинские расходы и возраст соответственно). В случае множественной линейной регрессии мы можем выбрать больше столбцов независимых переменных (например, если мы хотим увидеть влияние ИМТ также на медицинские расходы).
- Установите флажок «Метки», чтобы включить заголовки.
- Выберите желаемый вариант вывода.
- Установите флажок «Остатки» и нажмите «ОК».

Теперь результаты нашего регрессионного анализа будут созданы в новом рабочем листе с указанием статистики регрессии, ANOVA, остатков и коэффициентов.
Выходная интерпретация:
- Статистика регрессии показывает, насколько хорошо уравнение регрессии соответствует данным:

- Множество R — это коэффициент корреляции, который измеряет силу линейных отношений между двумя переменными. Он лежит в диапазоне от -1 до 1, и его абсолютное значение показывает силу отношения с большим значением, указывающим на более сильное отношение, низким значением, указывающим на отрицательное значение, и нулевым значением, указывающим на отсутствие отношения.
- Квадрат R — это коэффициент определения, используемый в качестве показателя качества соответствия. Он находится в диапазоне от 0 до 1, а значение, близкое к 1, указывает на то, что модель хорошо подходит. В этом случае 0, 57 = 57% значений y объясняются значениями x.
- Скорректированный квадрат R — это квадрат R, скорректированный на количество предикторов в случае множественной линейной регрессии.
- Стандартная ошибка отображает точность регрессионного анализа.
- Наблюдения отображают количество модельных наблюдений.
- Anova рассказывает об уровне изменчивости в рамках регрессионной модели.

Обычно это не используется для простой линейной регрессии. Однако «Значения F значимости» указывают на то, насколько надежны наши результаты, при этом значение больше 0, 05 предлагает выбрать другого предиктора.
- Коэффициенты являются наиболее важной частью, используемой для построения уравнения регрессии.

Итак, наше уравнение регрессии будет: у = 16, 891 х — 355, 32. Это то же самое, что сделано методом 1 (точечная диаграмма с линией тренда).
Теперь, если мы хотим предсказать средние медицинские расходы в возрасте 72 лет:
Итак, у = 16, 891 * 72 -355, 32 = 860, 832
Таким образом, мы можем предсказать значения y для любых других значений x.
- Остатки указывают на разницу между фактическими и прогнозируемыми значениями.

Последний метод регрессии используется не так часто и требует статистических функций, таких как slope (), intercept (), correl () и т. Д. Для проведения регрессионного анализа.
Что нужно помнить о линейной регрессии в Excel
- Регрессионный анализ обычно используется для определения статистически значимой взаимосвязи между двумя наборами переменных.
- Он используется для прогнозирования значения зависимой переменной на основе значений одной или нескольких независимых переменных.
- Всякий раз, когда мы хотим приспособить модель линейной регрессии к группе данных, следует тщательно соблюдать диапазон данных, как если бы мы использовали уравнение регрессии для прогнозирования любого значения за пределами этого диапазона (экстраполяция), тогда это может привести к неверным результатам.
Рекомендуемые статьи
Это руководство по линейной регрессии в Excel. Здесь мы обсудим, как сделать линейную регрессию в Excel вместе с практическими примерами и загружаемым шаблоном Excel. Вы также можете просмотреть наши другие предлагаемые статьи —
Построение уравнения множественной регрессии в Excel
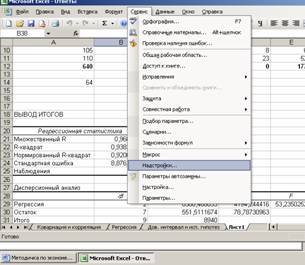
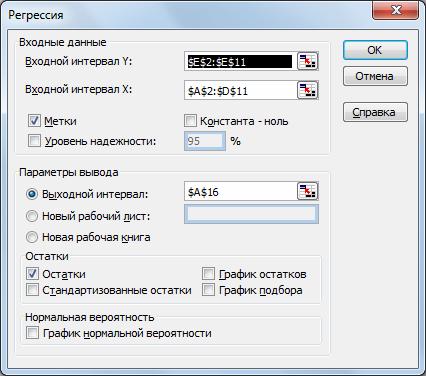
Для построения модели регрессии необходимо выбрать пункт Сервис\Анализ данных\Регрессия . (В Excel 2007 этот режим находится в блоке Данные/Анализ данных/Регрессия ) Появится диалоговое окно, которое нужно заполнить:
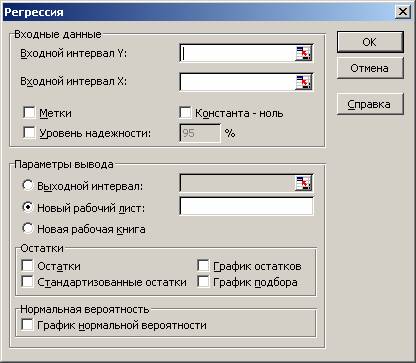
В результате выводится информация, содержащая все необходимые сведения и сгруппированная в три блока: Регрессионная статистика, Дисперсионный анализ, Вывод остатка. Рассмотрим их подробнее.
1. Регрессионная статистика:
множественный R определяется формулой ;
R-квадрат вычисляется по формуле ;
Нормированный R -квадрат вычисляется по формуле ;
Стандартная ошибка S вычисляется по формуле ;
Наблюдения — это количество данных n.
2. Дисперсионный анализ, строка Регрессия:
Параметр df равен m (количество наборов факторов x);
Параметр SS определяется формулой ;
Параметр MS определяется формулой ;
Статистика F определяется формулой ;
Значимость F. Если полученное число превышает α=1-p, то принимается гипотеза R 2 = 0 (нет линейной зависимости), иначе принимается гипотеза R 2 ≠0 (есть линейная зависимость).
3. Дисперсионный анализ, строка Остаток:
Параметр df равен n-m-1;
Параметр SS определяется формулой ;
Параметр MS определяется формулой .
4. Дисперсионный анализ, строка Итого содержит сумму первых двух столбцов.
5. Дисперсионный анализ, строка Y-пересечение содержит значение коэффициента a0 , стандартной ошибки Sb0 и t -статистики tb0.
P-значение — это значение уровней значимости, соответствующее вычисленным t-статистикам. Определяется функцией СТЬЮДРАСП( t -статистика; n-m-1). Если P -значение превышает α=1-p, то соответствующая переменная статистически незначима и ее можно исключить из модели.
Нижние 95% и Верхние 95% — это нижние и верхние границы 95-процентных доверительных интервалов для коэффициентов теоретического уравнения линейной регрессии. Если в блоке ввода данных значение доверительной вероятности было оставлено по умолчанию, то последние два столбца будут дублировать предыдущие. Если пользователь ввел свое значение доверительной вероятности, то последние два столбца содержат значения нижней и верхней границы для указанной доверительной вероятности.
6. Дисперсионный анализ, строки x1, x2. xm содержат значения коэффициентов, стандартных ошибок, t-статистик, P-значений и доверительных интервалов для соответствующих xi.
Блок Вывод остатка содержит значения предсказанного y (в наших обозначениях это ) и остатки .
Алгоритм работы
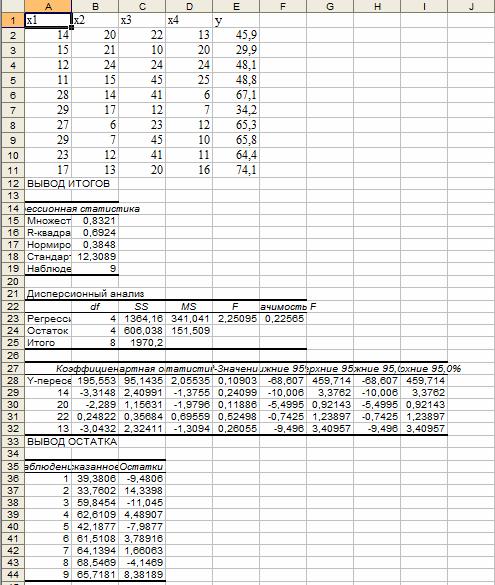
а) Коэффициенты уравнения соответствуют данным столбца Коэффициенты (следующий за столбцомY-пересечения) (блок Дисперсионный анализ).
б) Стандартная ошибка регрессии соответствует значению Стандартная ошибка блока Регрессионная статистика.
Стандартные ошибки коэффициентов соответствуют значениям столбца Стандартная ошибка блока Дисперсионный анализ.
в) Доверительные интервалы соответствуют интервалам Нижние %, Верхние %.
г) Статистическая значимость коэффициентов уравнения соответствует столбцу t -статистика. Граничная точка t(α; n-m-1) вычисляется с помощью функции СТЬЮДРАСПОБР(0,05;n-m-1) . Если i -ое значение P-значения меньше a, то i -ый коэффициент статистически значим и влияет на результативный признак.
д) Коэффициент детерминации R-квадрат в блоке Регрессионная статистика. Скорректированный (нормированный) коэффициент детерминации R2n. Это означает, что модель объясняет R2n*100% общего разброса значений результативного признака с учетом поправки на число степеней свободы.
Проверка гипотезы о статистической значимости коэффициента детерминации:
Проводим правостороннюю проверку. Граничная точка Fα;n-m-1 определяется с помощью функции FРАСПОБР(α;m;n-m-1) .
Статистика F (определяется из блока Дисперсионный анализ).
Если F> Fα;n-m-1, то гипотеза отвергается H0 и принимает гипотеза H1 на уровне значимости α%.
Этот вывод подтверждает число из столбца Значимость F, которое должно быть меньше значения a.
- Среднее значение: СРЗНАЧ(диапазон)
- Квадратическое отклонение: КВАДРОТКЛ(диапазон)
- Дисперсия: ДИСП(диапазон)
- Дисперсия для генеральной совокупности: ДИСПР(диапазон)
- Среднеквадратическое отклонение: СТАНДОТКЛОН(диапазон)
- Уравнение регрессии y = b1x1+b2x2+. bnxn+b0: ЛИНЕЙН(диапазон Y;диапазон X;1;1) .
- Выделите блок ячеек размером (n+1) столбцов и 5 строк.
Методические пояснения. 1. Для вычисления коэффициентов регрессии воспользуйтесь встроенной функцией ЛИНЕЙН (функция находится в категории «Статистические»), обратите внимание, что эта функция является функцией массива, поэтому ее использование подразумевает выполнение следующих шагов:
1) В свободном месте рабочего листа выделите область ячеек размером 5 строк и 2 столбца для вывода результатов;
2) В Мастере функций (категория «Статистические») выберите функцию ЛИНЕЙН .
3) Заполните поля аргументов функции:
Известные_значения_y — адреса ячеек, содержащих значения признака ;
Известные_значения_x — адреса ячеек, содержащих значения фактора ;
Константа — значение (логическое), указывающее на наличие свободного члена в уравнении регрессии: укажите в поле Константа значение 1, тогда свободный член рассчитывается обычным образом (если значение поля Константа равно 0, то свободный член полагается равным 0);
Статистика — значение (логическое), которое указывает на то, следует ли выводить дополнительную информацию по регрессионному анализу или нет: укажите в поле Статистика значение равное 1, тогда будет выводиться дополнительная регрессионная информация (если Статистика=0, то выводятся только оценки коэффициентов уравнения регрессии);
4) После того, как будут заполнены все аргументы функции, нажмите комбинацию клавиш <CTRL>+<SHIFT>+<ENTER> .
Результаты расчета параметров регрессионной модели будут выведены в виде следующей таблицы:
| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка mb коэффициента b | Стандартная ошибка ma коэффициента a |
| Коэффициент детерминации R 2 | Стандартное отклонение остатков Sост |
| Значение F—статистики | Число степеней свободы, равное n-2 |
| Регрессионная сумма квадратов | Остаточная сумма квадратов |
2. Табличные значения распределения Стьюдента определите с помощью функции СТЬЮДРАСПОБР. Аргументы этой функции:
Вероятность — уровень значимости α (можно принять равным 0,05, т.е. 5%);
Степени_свободы — число степеней свободы, для парной линейной регрессии равно n-2, где n — число наблюдений.
3. Табличное значение распределения Фишера определите с помощью функции FРАСПОБР. Аргументы этой функции:
Вероятность — уровень значимости α (можно принять равным 0,05, т.е. 5%);
Степени_свободы1 — число степеней свободы числителя, для парной регрессии равно 1 (т.к. один фактор);
Степени_свободы2 — число степеней свободы знаменателя, для парной регрессии равно n-2, где n — число наблюдений.
4. Коэффициент корреляции вычислите с помощью функции КОРРЕЛ. Аргументы функции:
Массив 1ш и Массив 2 — адреса ячеек, в которых содержатся значения величин, для которых вычисляется коэффициент корреляции.
5. Для вычисления (X T X) -1
1) Построите матрицу .
2) Постройте транспонированную к ней матрицу X T . Для построения матрицы X T необходимо воспользоваться функцией ТРАНСП (категория Ссылки и массивы).
3) матрицу X T необходимо умножить на матрицу X;
Произведение матриц вычисляется с помощью функции МУМНОЖ, аргументами которой являются перемножаемые матрицы. Перемножаемые матрицы должны удовлетворять условию соответствия размеров: матрица размера mxn может быть умножена справа на матрицу размера nxk, в результате получится матрица размера mxk.
В случае множественной регрессии с тремя факторами матрица X будет иметь размер nx4, матрица X T — размер 4xn, а их произведение X T X — размер 4×4.
Функция МУМНОЖ является функцией массива! Поэтому перед использованием функции МУМНОЖ необходимо выделить область размером mxk, в которой будет выведен результат, затем вставить функцию МУМНОЖ, указав ее аргументы. После этого в левой верхней ячейке выделенной области появится первый элемент результирующей матрицы. Для вывода всей матрицы нажмите комбинацию клавиш <CTRL>+<SHIFT>+<ENTER> .
4) найти обратную матрицу (X T X) -1 ;
Обратную матрицу (X T X) -1 вычислите с помощью функции МОБР . Функция МОБР также является функцией массива и ее использование аналогично функции МУМНОЖ: сначала необходимо выделить область ячеек, в которой будет получена обратная матрица, вставить функцию МОБР, затем <CTRL>+<SHIFT>+<ENTER> .
6. Коэффициенты множественной линейной регрессии вычисляются с помощью функции ЛИНЕЙН . Для того чтобы использовать эту функцию для вычисления параметров множественной регрессии необходимо
1) Сначала выделить на рабочем листе область размером 5x(k+1), где k — число объясняющих переменных.
2) Затем заполнить поля аргументов этой функции, которые имеют тот же смысл, что и в случае парной регрессии:
Известные_значения_y — адреса ячеек, содержащих значения признака y;
Известные_значения_x — адреса ячеек, содержащих значения всех объясняющих переменных.
Обратите внимание: выборочные значения факторов должны располагаться рядом друг с другом (в смежной области), причем предполагается, что в первом столбце (строке) содержатся значения первой объясняющей переменной, во втором столбце — второй и т.д.
Константа — значение (логическое), указывающее на наличие свободного члена в уравнении регрессии: укажите в поле Константа значение 1, тогда свободный член рассчитывается обычным образом (если значение поля Константа равно 0, то свободный член полагается равным 0);
Статистика — значение (логическое), которое указывает на то, следует ли выводить дополнительную информацию по регрессионному анализу или нет: укажите в поле Статистика значение равное 1, тогда будет выводиться дополнительная регрессионная информация (если Статистика=0, то выводятся только оценки коэффициентов уравнения регрессии);