Б. Расчеты с использованием Мастера функций
Выше приведенные методы расчета статистических показателей неудобны, так как для каждого из них необходимо вручную прописывать формулы. Поэтому для удобства работы в программе Excel предусмотрен мастер функций, позволяющий вводить их в полуавтоматическом режиме и практически без ошибок. Многие статистические показатели выборки и параметры генеральной совокупности можно очень быстро определить с помощью функций, тем более что наименование большинства функций совпадает с наименованием статистических показателей.
В Листе 1 файла Книга1 в столбце введем, символ Х и значения глубины вспашки по 8-ми точкам. В ячейки с А10 по А17 впишем наименование статистических показателей, которые приведены в работе 1.
Для определения средней выборочной (средняя арифметическая) активизируем ячейку В10 (выделенная ячейка со знаком =), в этой ячейке будут отображаться результаты наших вычислений. Для вызова мастера функций необходимо нажать кнопкуВставка функциина стандартной панели инструментов или на строке формул нажать на «fx».

Появляется контекстное меню «Мастер функций – шаг 1 из 2, в категории выбрать «Статистические» (рис. 2.12. )

Рис.2.12. Лист с исходными данными и контекстным меню «Мастер функций»
После выбора категории « Статистические».в окне появляется перечень конкретных статистических функций, выбираемСРЗНАЧ, что означает среднюю по выборке (рис. 2.13 ).

Рис. 2.13. Выбор функции СРЗНАЧ
Далее открывается окно для выбора аргументов функции. В поле Число 1ставим курсор и мышкой выбираем диапазон значений глубины вспашкиВ2:В9, нажимаем клавишуОК, в строке формул автоматически появляется наименование функции и диапазон ячеек(=СРЗНАЧ(В2:В9), а в ячейкеВ10появляется в скобках этот же диапазон (рис. 2.14 )

Рис. 2.14. Диалоговое окно для выбора аргументов функции.
После нажатия клавиши ОКили щелчка мышки в ячейкеВ10появляется значение выборочной средней – средняя глубина вспашки –20,25 см. (рис. 2.15 )
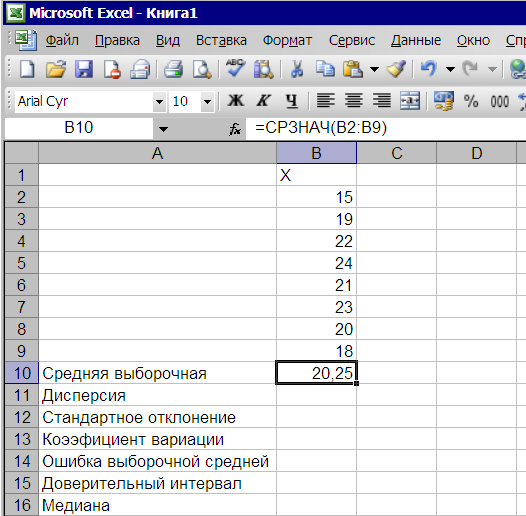
Рис.2.15. Средняя глубины вспашки – средняя выборочная – 20,25 см.
Находим объем выборки (n), который в Мастере функций называется счет (рис. 2.16)
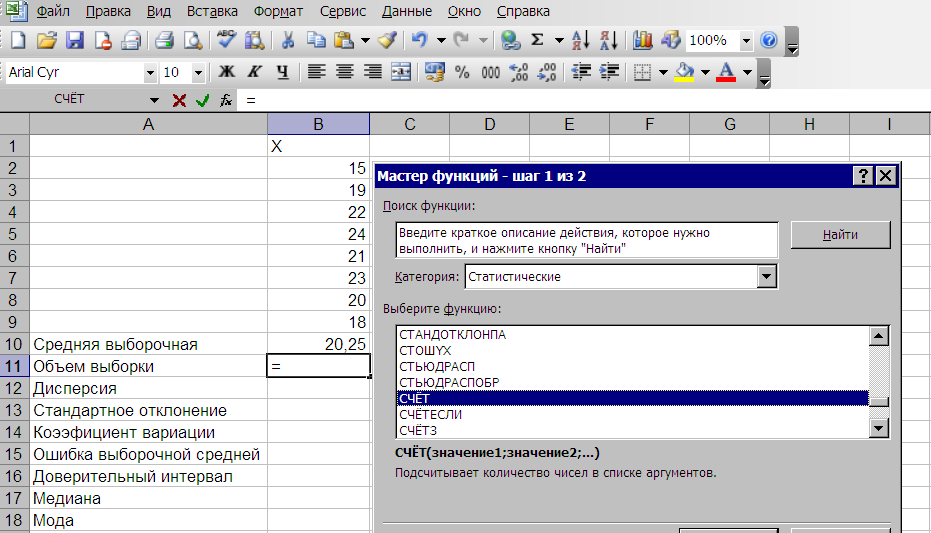
Рис.2.16. Диалоговое окно для нахождения объема выборки (счет)
Выбираем из списка функций ДИСП– дисперсия для выборки. Обратите внимание на то, что в списке имеетсяДИСПР – дисперсия для генеральной совокупности. При выборе конкретной дисперсии в подсказке указывается, что оценивает данная дисперсия (рис. 2.17 ).

Рис. 2.17. Диалоговое окно для выбора дисперсии
Для расчета дисперсии в поле Число 1ставим курсор и мышкой выбираем диапазон значений глубины вспашкиВ2:В9, нажимаем клавишуОК (рис.2.18)

Рис. 2.18. Выбор диапазона ячеек для определения дисперсии
Выбираем из списка функций СТАНДОТКЛОН– стандартное отклонение для выборки. Точно также как и для дисперсии в списке имеетсяСТАНДОТКЛОНП – стандартное отклонение для генеральной совокупности. При выборе конкретного стандартного отклонения в подсказке указывается, что оценивает данное стандартное отклонение (рис. 2.19 ).

Рис. 2.19. Диалоговое окно для выбора стандартного отклонения
В списке как математических, так и статистических функций нет такой функции с помощью, которой можно рассчитать коэффициент выборки (V), поэтому воспользуемся уже известной процедурой ручного набора формул.
Коэффициент вариации представляет собой отношение стандартного отклонения к выборочной средней, выраженной в %. Выделим ячейку для формулы коэффициента вариации В14, затем в строке формул пропишем формулу со ссылкой на ячейки, где находятся стандартное отклонение и выборочная средняя –(В13/В10*100)(рис. 2.20 )
В итоге получаем коэффициент вариации (V) = 14,3974%.

Рис. 2.20. Формула для определения коэффициента вариации
Расчет ошибки выборочной средней 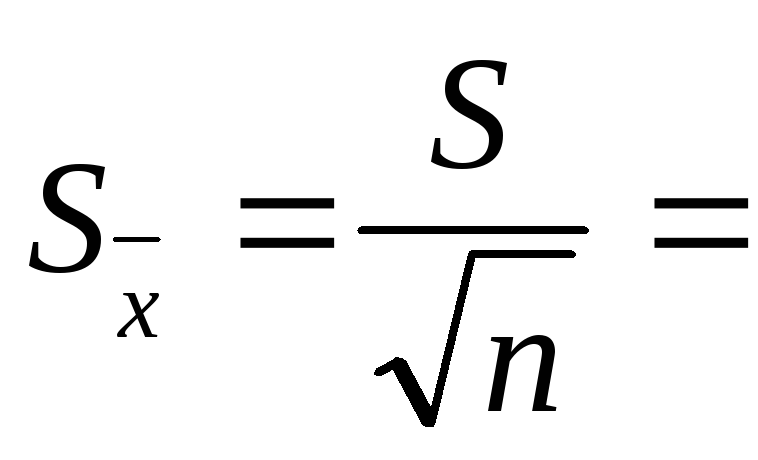
Так как в списке функций нет очень важного статистического показателя – ошибки выборочной средней (стандартная ошибка), рассчитаем этот важный показатель с помощью формул. Выделим ячейку для размещения формулы и получения готового результата В15 , затем в строке формул сначала вставим символ=и укажем следующую формулу:В13/КОРЕНЬ (В11). В ячейкеВ13 значение стандартного отклонения, в ячейкеВ11– объем выборки. После нажатия на клавишуEnter в ячейкеВ15получаем результат –1,0307764.(рис. 2.21)

Рис. 2.21. Расчет ошибки выборочной средней
Расчет предельной ошибки выборочной средней для нахождения доверительного интервала генеральной средней. Предельная ошибка выборочной средней представляет собой произведение критерия Стьюдента на ошибку выборочной средней (t 05*Sx). Значение критерия Стьюдента зависит от числа степеней свободы (n – 1) .
В Мастере функций для нахождения предельной ошибки средней выборочной имеется функция, которая имеет странное название ДОВЕРИТ. Поместим курсор в ячейкуВ16 . затем из списка статистических функций выберем функциюДОВЕРИТ (рис. 2.22 ), нажимаем ОК.

Рис. 2.22. Выбор в меню функции ДОВЕРИТ (предельная ошибка средней)
В появившемся диалоговом окне вводим:
— в поле Альфа введем уровень значимости –0,05,
— в поле Станд_откл. – ссылку на ячейку, где находится стандартное отклонение или готовое значение (2,915),
— в поле Размер – объем выборки (8)
После нажатия на клавишу ОК получаем результат – предельная ошибка выборочной средней равна2,019 (рис. 2.23)
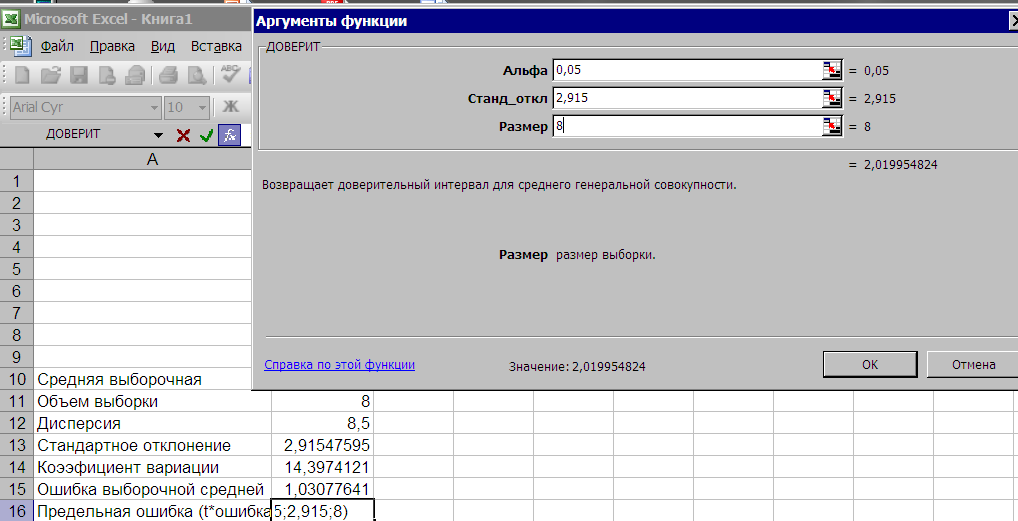
Рис. 2.23. Расчет предельной ошибки выборочной средней
95%-й доверительный интервал (ДИ) для генеральной средней ():

В ячейке А17вводим текст «Доверительный интервал», в ячейкуВ17 записываем значения ДИ следующим образом:20,25 ± 2.02(рис. 2.24 )
Для вычисления медианы – ячейка В18 выбираем функциюМЕДИАНА, в следующем окне указываем диапазонВ2:В9 и в итоге получаем значение –20,5

На рис. 2.24 показаны результаты расчета основных статистических показателей 50 клубней картофеля по массе, г. (Работа 2)

Рис. 2.24. Основные статистические показатели выборки — 50 клубней картофеля
Определение объема выборки
Ранее мы рассмотрели методы построения доверительного интервала для математического ожидания генеральной совокупности. В каждом из рассмотренных случаев мы заранее фиксировали объем выборки, не учитывая ширину доверительного интервала. В реальных задачах определить объем выборки довольно сложно. Это зависит от наличия финансовых ресурсов, времени и легкости создания выборки. [1] Например, если нам необходимо оценить среднюю сумму накладных или долю ошибочных накладных в информационной системе компании, сначала следует выяснить, насколько точной должна быть оценка. Иначе говоря, следует задать ошибку выборочного исследования, допускаемую при оценке каждого из параметров. Кроме того, необходимо заранее определить доверительный уровень оценки истинного параметра генеральной совокупности.
Определение объема выборки для оценки математического ожидания
Чтобы определить объем выборки, необходимый для оценки математического ожидания генеральной совокупности, следует учесть величину ошибки выборочного исследования и доверительный уровень. Кроме того, необходима дополнительная информация о величине стандартного отклонения. Для того чтобы вывести формулу, позволяющую вычислить объем выборки, начнем с формулы (1) (о происхождении этой формулы см. Построение доверительного интервала для математического ожидания генеральной совокупности):

где  – среднее значение выборки, Z — значение стандартизованной нормально распределенной случайной величины, соответствующее интегральной вероятности, равной 1 – α/2, σ — стандартное отклонение генеральной совокупности, n – объем выборки
– среднее значение выборки, Z — значение стандартизованной нормально распределенной случайной величины, соответствующее интегральной вероятности, равной 1 – α/2, σ — стандартное отклонение генеральной совокупности, n – объем выборки
Скачать заметку в формате Word или pdf, примеры в формате Excel2013
В этой формуле величина, добавляемая и вычитаемая из равна половине длины интервала. Она определяет меру неточности оценки, возникающей вследствие ошибки выборочного исследования, которая обозначается символом е и вычисляется по формуле

Решив уравнение (2) относительно n, получим:

Таким образом, для определения объема выборки необходимо знать три параметра:
- Требуемый доверительный уровень, который влияет на величину Z, являющуюся критическим значением стандартизованного нормального распределения; [2]
- Приемлемую ошибку выборочного исследования е;
- Стандартное отклонение σ.
На практике вычислить эти величины непросто. Как определить доверительный уровень и ошибку выборочного исследования? Обычно ответить на этот вопрос могут лишь эксперты в предметной области (т.е. люди, понимающие смысл оцениваемых величин). Как правило, доверительный уровень равен 95% (в этом случае Z = 1,96). [3] Если требуется поднять доверительный уровень, обычно выбирают величину, равную 99%. Если можно ограничиться более низким доверительным уровнем, выбирают 90%. Определяя ошибку выборочного исследования, не стоит думать о ее величине (в принципе, любая ошибка нежелательна). Следует задать такую ошибку, чтобы полученные результаты допускали разумную интерпретацию.
Кроме доверительного уровня и ошибки выборочного исследования, необходимо знать стандартное отклонение генеральной совокупности. К сожалению, этот параметр почти никогда не известен. В некоторых случаях стандартное отклонение генеральной совокупности можно оценить на основе предшествующих исследований. В других ситуациях эксперт может учесть размах выборки и распределение случайной переменной. Например, если генеральная совокупность имеет нормальное распределение, ее размах приближенно равен 6σ (т.е. ±3σ в окрестности математического ожидания). Следовательно, стандартное отклонение приближенно равно одной шестой части диапазона. Если величину σ невозможно оценить таким способом, необходимо выполнить пилотный проект и вычислить стандартное отклонение по результатам.
Пример 1. Вернемся к задаче об аудиторской проверке. Предположим, что из информационной системы извлечена выборка, состоящая из 100 накладных, заполненных в течение последнего месяца. Компания желает построить интервал, содержащий математическое ожидание генеральной совокупности, доверительный уровень которого равен 95%. Как был определен объем выборки? Следует ли его уточнить?
Допустим, что после консультаций с экспертами, работающими в компании, статистики установили допустимую ошибку выборочного исследования равной ±5 долл., а доверительный уровень — 95%. Результаты предшествующих исследований свидетельствуют, что стандартное отклонение генеральной совокупности приближенно равно 25 долл. Таким образом, е = 5, σ = 25 и Z = 1,96 (что соответствует 95%-ному доверительному уровню). По формуле (3) получаем:

Следовательно, n = 96. Таким образом, объем выборки, равный 100, был выбран удачно и вполне соответствует требованиям, выдвинутым компанией.
Пример 2. Некая промышленная компания на Среднем Западе производит электрические изоляторы. Если во время работы изолятор выходит из строя, происходит короткое замыкание. Чтобы проверить прочность изолятора, компания проводит испытания, в ходе которых определяется максимальная сила, необходимая для разрушения изолятора. Сила измеряется в фунтах нагрузки, приводящей к разрушению изолятора (рис. 1, столбец А). Предположим, что нам необходимо оценить среднюю силу разрушения изолятора с точностью +25 фунтов при 95%-ном доверительном интервале для этой величины. Данные, полученные в предыдущем исследовании, свидетельствуют, что стандартное отклонение равно 100 фунтов. Определите требуемый объем выборки.
Решение. Итак, е = 25, σ =100, доверительный уровень 95% (т.е. Z = 1,96) (рис. 1).

Рис. 1. Определение объема выборки
Таким образом, n = 62 (дробные результаты, как правило, округляют с избытком до ближайшего целого).
Определение объема выборки для оценки доли признака в генеральной совокупности
Выше мы рассмотрели способ определения объема выборки для оценки математического ожидания генеральной совокупности. Предположим теперь, что нам необходимо определить долю накладных, не соответствующих правилам, принятым компанией (начальные условия см. пример 1 выше). Сколько накладных следует извлечь из информационной системы, чтобы построенный интервал имел заданный доверительный уровень? Для ответа на этот вопрос применим тот же подход, что и при определении объема выборки для оценки математического ожидания.
Ошибка выборочного исследования определяется по формуле (2). При оценке доли признака величину σ следует заменить на величину . Таким образом, формула для ошибки выборочного исследования принимает следующий вид:
. Таким образом, формула для ошибки выборочного исследования принимает следующий вид:

Выражая n через остальные величины, получаем следующую формулу:

Таким образом, для определения объема выборки необходимо знать три параметра:
- Требуемый доверительный уровень, по которому определяется величина Z.
- Допустимую ошибку выборочного исследования е.
- Истинную долю успехов р.
На практике вычислить эти величины нелегко. Если известен доверительный уровень, можно вычислить критическое значение стандартизованного нормального распределения Z. Ошибка выборочного исследования е определяет точность, с которой оценивается доля успехов в генеральной совокупности. Третий параметр — доля успехов в генеральной совокупности р — это именно тот параметр, который нам необходимо оценить. Итак, как оценить диапазон изменения величины р по его выборочным значениям?
Существуют два способа. Во-первых, во многих ситуациях для оценки величины р можно использовать результаты предыдущих исследований. Во-вторых, если данные о предыдущих исследованиях недоступны, можно попытаться оценить параметр р так, чтобы исключить недооценку объема выборки. Обратите внимание на то, что в формуле (5) величина р(1 – р) стоит в числителе. Следовательно, необходимо найти максимальное значение этой величины. Очевидно, что оно достигается при р = 0,5.
Таким образом, если доля признака в генеральной совокупности р заранее неизвестна, для определения объема выборки следует задать р = 0,5. В этом случае объем выборки будет переоценен, что приведет к дополнительным затратам на ее создание. Если истинная доля успехов в генеральной совокупности сильно отличается от 0,5, доверительный интервал окажется значительно уже, чем требовалось. Оценка параметра р в этом случае будет весьма точной, однако за это придется заплатить дополнительными временными и финансовыми ресурсами.
Вернемся к задаче об аудиторской проверке. Предположим, аудитор желает построить интервал, содержащий долю ошибочных накладных, доверительный уровень которого равен 95%. Допустимая точность равна ±0,07. Результаты предыдущих проверок свидетельствуют, что доля ошибочных накладных не превышает 0,15. Таким образом, е = 0,07, р = 0,15 и Z = 1,96 (что соответствует 95%-ному доверительному уровню). По формуле (5) получаем:

Таким образом, объем выборки, равный 100, был выбран совершенно правильно и вполне соответствует требованиям, выдвинутым компанией.
Определение объема выборки, извлекаемой из конечной генеральной совокупности
Для определения объема выборки, извлеченной из конечной генеральной совокупности без возвращения, необходимо использовать поправочный коэффициент. Например, при оценке математического ожидания выборочная ошибка вычисляется по следующей формуле:

При оценке доли признака ошибка выборочного исследования равна:

Чтобы вычислить объем выборки для оценки математического ожидания или доли признака, применяются формулы:

где n0 — объем выборки без учета поправочного коэффициента для конечной генеральной совокупности. Применение поправочного коэффициента приводит к следующей формуле:

[1] Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 471–476
[2] Для определения размера выборки используется величина Z, а не t, поскольку для вычисления критического значения t размер выборки необходимо знать заранее. В большинстве случаев размеры выборки позволяют хорошо аппроксимировать t-распределение стандартизованным нормальным распределением.
[3] Интервал c доверительным уровнем 95% делится на две равные части. Первая часть лежит слева от математического ожидания генеральной совокупности, а вторая — справа. Значение величины Z, соответствующей вероятности 2,5% (площади 0,025), равно –1,96, а значение величины Z, соответствующей суммарной площади 0,975, равно +1,96. Для расчета удобно воспользоваться функцией Excel Z=НОРМ.СТ.ОБР(р), где р – вероятность, подставляя значения р1 = 2,5% и р2 = 97,5%
13 комментариев для “Определение объема выборки”
Предположим, суммарная стоимость всех элементов (счетов-фактур, объектов основных средств, запасов и т. д.) составляет 200 000 тыс. тенге. Суммарное денежное выражение элементов наибольшей стоимости — 4 000 тыс. тенге. Суммарное денежное выражение ключевых элементов — 6 000 тыс. тенге. Уровень существенности — 5 000 тыс. тенге. Аудиторский риск составляет 10%, соответственно, уровень надежности — 90%.
1. Найти объем выборки
По какой формуле определяется объем выборки, если заранее известны генеральная совокупность и распределение оценок&
Света, обратитесь к примерам 1 и 2 настоящей заметки. Откройте Excel-файл, в нем есть формулы. Если останутся вопросы, пришлите в личку исходные данные.
Добрый день!
Перерыла весь интернет, так и не смогла вспомнить, как решить следующую задачу:
Недавно нанятый менеджер Яндекса должен посчитать, какая доля пользователей из России имеет доход больше 40 000 руб. в месяц. Для этого он через специальную форму на странице http://www.yandex.ru может анонимно опрашивать пользователей об их доходе. Специалисты из поиска считают, что такие опросы мешают пользователям и тем самым портят качество сервиса. Какое минимальное количество людей менеджер должен опросить, чтобы посчитать долю с точностью в пределах одного процентного пункта на уровне доверия 95 %? Дисперсию оценки искомой доли следует считать максимальной, а квантиль 0.975 нормального распределения —приблизительно равной двум.
Ну что вы, что вы. неужели так сложно самому цифры подставить, али вы гуманитарий совсем?
Помоги пожалуйста решить: Оценить объем репрезентативной выборочной совокупности с ошибкой не более 10%, если в качестве генеральной совокупности выступает население города от 100 до 120 тысяч человек.
Каким должен быть объем выборки при случайном повторном отборе, чтобы ошибка определения среднего (среднее квадратичное отклонение оценки от истинного среднего) составляла не более 10% от среднего квадратичного отклонения в генеральной совокупности? Помогите, пожалуйста
Для определения среднего значения АД у женщин г. Астаны возраста 63 года и старше (по состоянию на 2014 год stat.gov.kz)) планировались выборочные исследования. Какова должна быть величина минимального объема выборки, если из литературных данных известно, что дисперсия АД=560 (мм.рт.ст.)2. Ошибка выборки была принята на уровне 5%, уровень значимости 5%.
срочно нужен ответ на задачу, пожалуйста
Для определения среднего значения АД у женщин г. Астаны возраста 63 года и старше (по состоянию на 2014 год stat.gov.kz)) планировались выборочные исследования. Какова должна быть величина минимального объема выборки, если из литературных данных известно, что дисперсия АД=560 (мм.рт.ст.)2. Ошибка выборки была принята на уровне 5%, уровень значимости 5%.
Таким образом, е = 0,07, р = 0,15 и Z = 1,96 (что соответствует 95%-ному доверительному уровню). По формуле (5) получаем: 99,96 — ошибка? Получается 775
Как определить требуемый объем выборки для исследования среднего возраста сотрудников при условии, что среднее квадратическое отклонение составляет 4 года, а максимально допустимая ошибка выборки не должна превышать 5%.? Объясните, пожалуйста
Поясните пожалуйста, последний вариант «Определение объема выборки, извлекаемой из конечной генеральной совокупности» Для определения объема выборки, извлеченной из конечной генеральной совокупности без возвращения, необходимо использовать поправочный коэффициент.
Чем отличается от предыдущих? Мы же в предыдущих, тоже исходили из предположения конечности генеральной совокупности и то же без возвращения, т.е. формировали выборку один раз?
Может есть пример бизнес-задачи, когда это применяется?
Инструменты Excel для вычисления числовых характеристик выборки
Процедура «Описательные статистики » пакета «Анализ данных.

В процедуре автоматически вычисляются следующие числовые характеристики выборки:
- среднее –
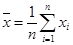 ;
; - стандартная ошибка среднего –
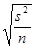 ;
; - медиана – решение уравнения
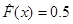 , где
, где  – эмпирическая функция распределения;
– эмпирическая функция распределения; - мода – чаще всего встречающееся в выборке значение;
- выборочная дисперсия –
 ;
; - стандартное отклонение –
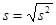 ;
; - эксцесс –
 ;
; - коэффициент асимметрии –
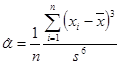 ;
; - размах варьирования –
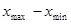 ;
; - наибольшее значение –
 ;
; - наименьшее значение –
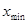 ;
; - объём выборки –
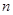 .
.
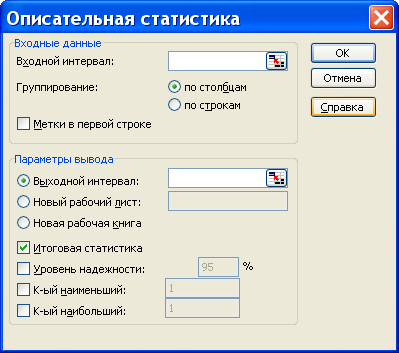
Для того чтобы выполнить вычисления, вводим в поле «Водной интервал» адреса ячеек, в которых записаны выборочные значения;
помечаем «Выходной интервал» и вводим в поле адрес первой ячейки, начиная с которой в листе Excel будет отображён резгультат; помечаем «Итоговая статистика»:
Как найти объем выборки в excel
Использование Excel для расчета статистических характеристик случайной величины
Разделы: Математика
- Совершенствование умений и навыков нахождения статистических характеристик случайной величины, работа с расчетами в Excel;
- применение информационно коммутативных технологий для анализа данных; работа с различными информационными носителями.
- Сегодня на уроке мы научимся рассчитывать статистические характеристики для больших по объему выборок, используя возможности современных компьютерных технологий.
- Для начала вспомним:
– что называется случайной величиной? (Случайной величиной называют переменную величину, которая в зависимости от исхода испытания принимает одно значение из множества возможных значений.)
– Какие виды случайных величин мы знаем? (Дискретные, непрерывные.)
– Приведите примеры непрерывных случайных величин (рост дерева), дискретных случайных величин (количество учеников в классе).
– Какие статистические характеристики случайных величин мы знаем (мода, медиана, среднее выборочное значение, размах ряда).
– Какие приемы используются для наглядного представления статистических характеристик случайной величины (полигон частот, круговые и столбчатые диаграммы, гистограммы).
- Рассмотрим, применение инструментов Excel для решения статистических задач на конкретном примере.
Пример. Проведена проверка в 100 компаниях. Даны значения количества работающих в компании (чел.):
1. Занести данные в EXCEL, каждое число в отдельную ячейку.
| 23 | 25 | 24 | 25 | 30 | 24 | 30 | 26 | 28 | 26 |
| 32 | 33 | 31 | 31 | 25 | 33 | 25 | 29 | 30 | 28 |
| 23 | 30 | 29 | 24 | 33 | 30 | 30 | 28 | 26 | 25 |
| 26 | 29 | 27 | 29 | 26 | 28 | 27 | 26 | 29 | 28 |
| 29 | 30 | 27 | 30 | 28 | 32 | 28 | 26 | 30 | 26 |
| 31 | 27 | 30 | 27 | 33 | 28 | 26 | 30 | 31 | 29 |
| 27 | 30 | 30 | 29 | 27 | 26 | 28 | 31 | 29 | 28 |
| 33 | 27 | 30 | 33 | 26 | 31 | 34 | 28 | 32 | 22 |
| 29 | 30 | 27 | 29 | 34 | 29 | 32 | 29 | 29 | 30 |
| 29 | 29 | 36 | 29 | 29 | 34 | 23 | 28 | 24 | 28 |
2. Для расчета числовых характеристик используем опцию Вставка – Функция. И в появившемся окне в строке категория выберем — статистические, в списке: МОДА
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили Мо = 29 (чел) – Фирм у которых в штате 29 человек больше всего.
Используя тот же путь вычисляем медиану.
Вставка – Функция – Статистические – Медиана.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили Ме = 29 (чел) – среднее значение сотрудников в фирме.
Размах ряда чисел – разница между наименьшим и наибольшим возможным значением случайной величины. Для вычисления размаха ряда нужно найти наибольшее и наименьшее значения нашей выборки и вычислить их разность.
Вставка – Функция – Статистические – МАКС.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили наибольшее значение = 36.
Вставка – Функция – Статистические – МИН.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили наименьшее значение = 22.
36 – 22 = 14 (чел) – разница между фирмой с наибольшим штатом сотрудников и фирмой с наименьшим штатом сотрудников.
Для построения диаграммы и полигона частот необходимо задать закон распределения, т.е. составить таблицу значений случайной величины и соответствующих им частот. Мы ухе знаем, что наименьшее число сотрудников в фирме = 22, а наибольшее = 36. Составим таблицу, в которой значения xi случайной величины меняются от 22 до 36 включительно шагом 1.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni |
Чтобы сосчитать частоту каждого значения воспользуемся
Вставка – Функция – Статистические – СЧЕТЕСЛИ.
В окне Диапазон ставим курсор и выделяем нашу выборку, а в окне Критерий ставим число 22
Нажимаем клавишу ОК, получаем значение 1, т.е. число 22 в нашей выборке встречается 1 раз и его частота =1. Аналогичным образом заполняем всю таблицу.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni | 1 | 3 | 4 | 5 | 11 | 9 | 13 | 18 | 16 | 6 | 4 | 6 | 3 | 0 | 1 |
Для проверки вычисляем объем выборки, сумму частот (Вставка – Функция – Математические — СУММА). Должно получиться 100 (количество всех фирм).
Чтобы построить полигон частот выделяем таблицу – Вставка – Диаграмма – Стандартные – Точечная (точечная диаграмма на которой значения соединены отрезками)
Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы (Полигон частот), удаляем легенду, редактируем шкалу и характеристики диаграммы для наибольшей наглядности.
Для построения столбчатой и круговой диаграмм используем тот же путь (выбирая нужный нам тип диаграммы).
Диаграмма – Стандартные – Круговая.
Диаграмма – Стандартные – Гистограмма.
4. Сегодня на уроке мы научились применять компьютерные технологии для анализа и обработки статистической информации.
Как рассчитать размер выборки в Excel — Вокруг-Дом — 2021
Table of Contents:
Microsoft Excel имеет десять основных статистических формул, таких как размер выборки, среднее значение, медиана, стандартное отклонение, максимум и минимум. Размер выборки — это число наблюдений в наборе данных, например, если опрашивающая компания опрашивает 500 человек, то размер выборки данных составляет 500. После ввода набора данных в Excel формула = COUNT вычислит размер выборки. , Размер выборки полезен для вычислений, таких как стандартные ошибки и уровни достоверности. Использование Microsoft Excel позволит пользователю быстро рассчитать статистические формулы, поскольку статистические формулы, как правило, длиннее и сложнее, чем другие математические формулы.
Excel облегчает сложные статистические вычисления.
Шаг 1
Введите данные наблюдений в Excel, по одному наблюдению в каждой ячейке. Например, введите данные в ячейки с A1 по A24. Это обеспечит вертикальный столбец данных в столбце А.
Шаг 2
Введите "= COUNT (" в ячейку B1.
Шаг 3
Выделите диапазон ячеек данных или введите диапазон ячеек данных после «(», введенного на шаге 2 в ячейку B1, затем завершите формулу знаком «)». Диапазон ячеек — это любые ячейки, в которых есть данные. В этом примере диапазон ячеек от A1 до A24. Формула в примере — это "= COUNT (A1: A24)"
Шаг 4
Нажмите «Enter», и размер ячейки появится в ячейке с формулой. В нашем примере ячейка B1 будет отображать 24, поскольку размер выборки будет 24.