Расчет частоты дискретизации для аудиофайла с шагом 0,00005 секунд: все, что нужно знать
Частота дискретизации — это количество сэмплов (или точек) аудиофайла, записанных в единицу времени. Она измеряется в герцах (Гц) и определяет качество аудиовоспроизведения. Если частота дискретизации недостаточно высока, то качество звучания будет низким из-за потери информации о звуковых волнах.
Как определить частоту дискретизации аудиофайла?
Для того, чтобы определить частоту дискретизации, необходимо знать длительность одного сэмпла и общее количество сэмплов в аудиофайле.
Допустим, что длительность одного сэмпла составляет 0,00005 секунд, тогда для определения частоты дискретизации необходимо выполнить следующие расчеты:
Зачем нужно знать частоту дискретизации?
Знание частоты дискретизации особенно важно при обработке и редактировании аудиофайлов. Если вы знаете частоту дискретизации, то вы можете выполнять редактирование без ущерба для качества звучания. Кроме того, при конвертации аудиоформатов необходимо учитывать частоту дискретизации, чтобы сохранить качество звучания.
Выводы
Частота дискретизации — важный параметр аудиофайлов. Ее определение необходимо для обработки, редактирования и конвертации аудиофайлов. Зная длительность одного сэмпла и общее количество сэмплов в файле, можно легко определить частоту дискретизации с помощью простых расчетов.
Можем ли мы угадывать музыкальные инструменты с помощью машинного обучения?

Музыка присутствует в нашей повседневной жизни, присутствует во всех культурах и постоянно развивается. Кто-то может возразить, что способность взаимодействовать с музыкой — это исключительно человеческое качество. Стриминговые гиганты, такие как Spotify и Apple (и это лишь некоторые из них), курируют свой контент и предлагают персональные рекомендации для своих пользователей. Для этого они обладают мощными инструментами, которые классифицируют записи по жанрам, инструментам и текстам.
Этим предприятиям действительно необходимо делать свои прогнозы правильно и без истощения своих ресурсов. Некоторые источники предполагают, что Spotify добавляет от 10 000 до 30 000 песен в день.
Мы собираемся изучить, как мы можем классифицировать музыкальные инструменты с помощью алгоритмов машинного обучения, написанных на питоне. Мы хотим предсказать инструмент с максимально возможной точностью, но мы также хотим достичь этого без особых усилий, останавливаясь, когда мы достигаем точки убывающей отдачи.
Идея далека от новаторства, есть несколько статей, опубликованных на эту тему, а также на более сложные темы, такие как создание музыки с помощью ИИ. Этот пост отличается тем, что основное внимание уделяется следующим критериям, которые компании используют для определения победителя среди алгоритмов:
- Точность
- Тренировочное время
- Эффективность
- Надежность
Набор данных
NSynth — это крупномасштабный и высококачественный набор данных аннотированных музыкальных нот, который можно бесплатно использовать благодаря Google Inc. Отсутствуют пропущенные значения, повторяющиеся записи, и каждое наблюдение правильно помечено. Это избавляет от необходимости выполнять подвиги по очистке данных.
Он также огромен: более 300 000 четырехсекундных звуковых фрагментов хранятся в виде волновых файлов (.wav). Около 95% данных предназначено для обучения, 4% — для проверки и ничтожный 1% — для тестирования.
Всего у нас есть 11 инструментов, обозначенных от 0 до 1, но, как мы узнаем позже, мы можем уменьшить это количество до 10:
- бас
- латунь
- флейта
- гитара
- клавиатура
- молоток
- орган
- тростник
- нить
- synth_lead
- вокал
Кроме того, это несбалансированный набор данных, что станет дополнительной проблемой в будущем. На графике ниже показано распределение классов инструментов в тестовом наборе данных, обратите внимание, что у нас есть более 60 КБ файлов баса и едва ли 5 КБ струнных инструментов.

У нас есть аналогичные проблемы с данными проверки и тестирования.


Обратите внимание на инструмент № 9 на двух графиках выше. Есть ли смысл тренироваться для того, чего мы, вероятно, не увидим? Инструмент №9 также недостаточно представлен в данных тестирования. Мы исключим его из данных тестирования, чтобы упростить анализ.
Понимание данных: анатомия волнового файла
Чтобы классифицировать инструменты, мы должны сначала понять, каковы характеристики волновых файлов, мы будем называть эти характеристики пространством функций.
Для анализа волновых файлов мы в значительной степени полагаемся на Librosa, пакет Python для анализа музыки и аудио. Мы случайным образом выбираем волновые файлы из данных и исследуем особенности образца. Загрузить файл в Librosa очень просто:
Мы определяем звук как вибрацию, распространяющуюся по воздуху. Каждый звук имеет частоту, определяемую как количество повторений повторяющегося события в единицу времени и измеряемую в герцах (Гц) или обратных секундах (с-1). Имея это в виду, мы можем запачкать руки данными и изучить некоторые функции.
Форма волны и частота дискретизации
Звук — это непрерывный временной сигнал, обычно представленный в виде формы волны; этот непрерывный сигнал дискретизируется и преобразуется в дискретный сигнал времени.
Частота дискретизации — это количество сэмплов звука, записываемых в секунду. Частота дискретизации определяет максимальную звуковую частоту, которая может быть воспроизведена.
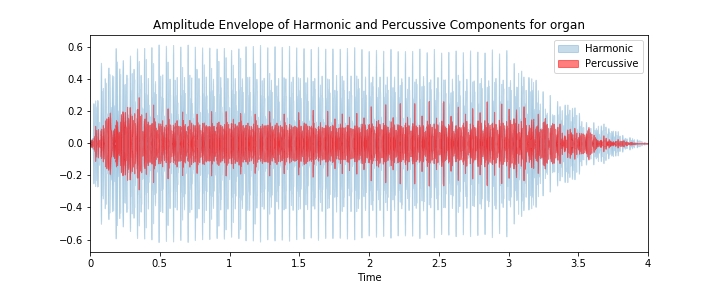
Гармонический звук — это звук, в котором основная частота каждого из них является целым кратным наименьшей основной частоты. Ударный инструмент — это любой предмет, по которому можно ударить.
Мы можем разложить волновые файлы на гармонические и ударные компоненты с помощью одной строчки кода:
Из графиков ниже мы можем начать различать инструменты и увидеть их ударные и гармонические качества.



Цветовая энергия
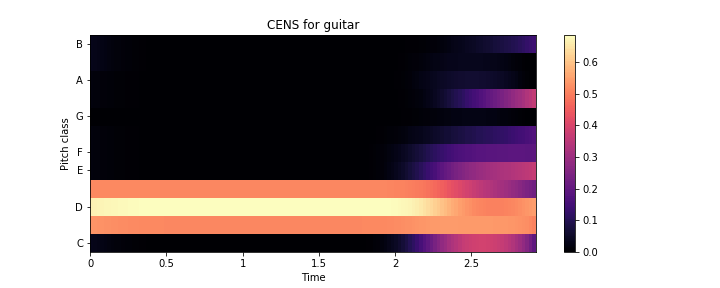
Высота — это качество звука, определяемое скоростью производящих его вибраций. Две высоты воспринимаются как похожие по цвету, если они отличаются на октаву. Основываясь на этом наблюдении, высоту тона можно разделить на две составляющие, которые называются высотой тона и цветностью.
Предполагая равномерно темперированный строй, цветность соответствует набору
Графики ниже отображают цветность в виде цветных полос. Каждая цветная полоса соответствует нотам, которые исполняет инструмент. Мы также замечаем, что некоторые ноты более активны, чем другие, а некоторые внезапно затухают.


Спектрограмма Мела
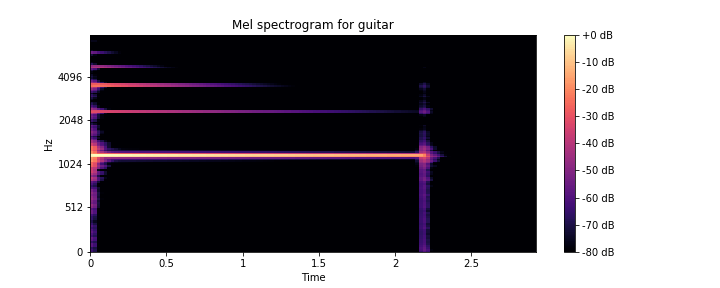
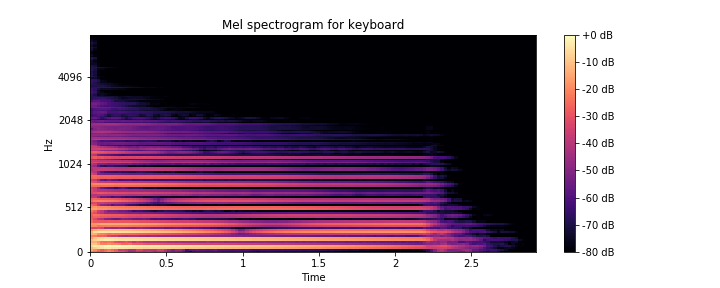
Спектрограмма — это основной инструмент спектрального анализа звука и других областей. Он широко применяется при анализе речи. Спектрограмму можно определить как график интенсивности (обычно в логарифмической шкале, такой как дБ) величины кратковременного преобразования Фурье (STFT).
STFT — это просто последовательность быстрых преобразований Фурье (БПФ) оконных сегментов данных, где окнам обычно разрешено перекрываться во времени, обычно на 25–50%. Это важное представление аудиоданных, потому что человеческий слух основан на своего рода спектрограмме в реальном времени, кодируемой улиткой внутреннего уха. Мы можем предсказать, что спектрограмма, вероятно, будет играть важную роль в предсказании.
Мел — единица измерения высоты звука. Шкала мела — это шкала высот, которую слушатели оценивают как равные по расстоянию друг от друга. Отметим, что шкала mel основана на эмпирических данных и не имеет теоретической основы.
Librosa снова оказывается здесь полезной и выводит спектрограмму с помощью одной строки кода:

Дополнительные возможности
Были оценены и другие характеристики, такие как частота спада спектра, спектральный контраст и коэффициенты мелкочастотного кепстра (MFCC). Однако мы не будем углубляться в их изучение.
Подготовка данных: борьба
Теперь у нас есть представление о том, из чего состоит волновой файл. Не имея категориальных переменных для кодирования, мы хотим извлечь следующие функции:
- Инструмент гармоничен?
- MFCC
- Спектрограмма
- Спектральный контраст
Первое препятствие — это данные, потому что их много, может быть, слишком много. Давайте сразу же сделаем упрощение и возьмем только 5000 образцов из каждого класса. Таким образом, мы перейдем от 290 000 сэмплов к 50 000. Помните о цели:
Сделайте как можно больше разумных упрощений, сэкономьте время и при этом добейтесь разумных результатов.
Мы можем выполнить эти шаги в функции ниже:
В приведенном выше блоке кода много чего происходит, и это может показаться пугающим. Однако ключевым выводом является следующее выражение:
Напомним, что спектрограмма показывает активированные частоты для каждого временного кадра. Как мы поместим массив m x n в таблицу? Решением является временное усреднение спектрограммы: на каждом временном шаге мы берем среднее значение частот.
Точность прогноза
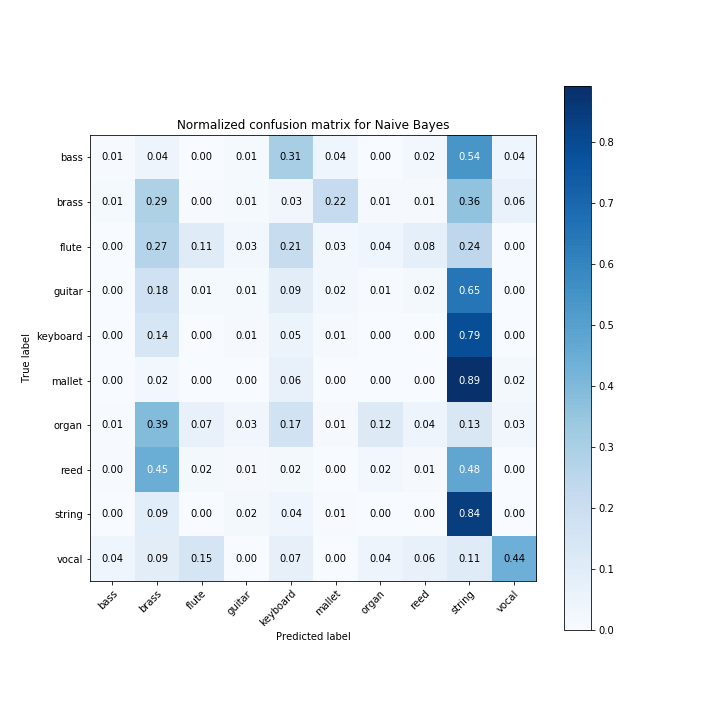
Наивный байесовский
Первое место в рейтинге прогнозов занял Наивный Байес (NB). Scikit-learn позволяет невероятно легко настроить прогноз независимо от алгоритма:
Результаты представлены в виде матрицы путаницы. Чем выше значения по диагонали, тем лучше наш прогноз. NB имеет точность 13%, что немного лучше, чем случайное предположение.
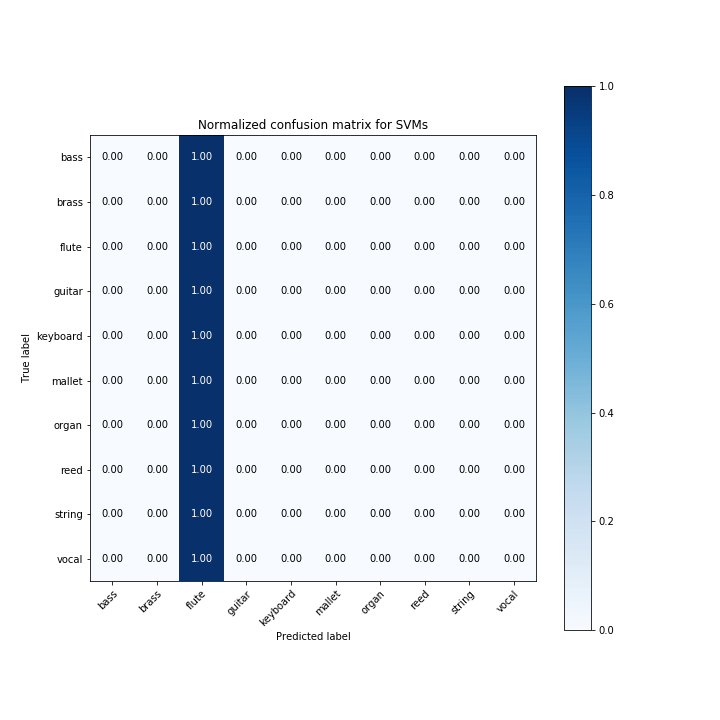
Машины опорных векторов
Машины опорных векторов — популярный алгоритм обучения с учителем. Однако по тому, как настроены наши функции и параметры, мы предсказываем, что все будет флейтой (неудачей).
Случайные леса
Леса случайных решений (RF) являются методом ансамблевого обучения и часто становятся победителями соревнований по машинному обучению. Мы получаем точность 65% после точной настройки некоторых параметров и явно превосходим два других.

Нейронные сети
Нейронные сети часто рассматриваются как святой Грааль искусственного интеллекта с заслуженной шумихой; для этого проекта мы используем сверточные нейронные сети (CNN). С Keras мы легко можем создать собственный CNN в стиле CIFAR-10.
Точность падает до 55%, и после определенных эпох обучения мы перестаем добиваться результатов. Рассматривая график ниже, начиная с 15-й эпохи обучения, мы можем видеть убывающую отдачу от данных проверки.

Время обучения и эффективность
Теперь у нас есть четыре конкурирующих алгоритма, так какой из них наиболее эффективен? Мы можем начать с отказа от NB и SVM из-за низкой точности. Остается RF и CNN.
CNN потребовалось около 15 часов обучения на экземпляре AWS GPU. Обучение в облаке не является бесплатным и может стать очень дорогостоящим, что ограничивает время, которое мы можем потратить на выполнение задачи.
С другой стороны, радиочастотное обучение занимает менее 3 часов, просто убедитесь, что ваша машина подключена к розетке. Кроме того, временная сложность RF равна O (f * s * log (f)), где f — количество функций, а s — количество выборок.
Надежность
К настоящему времени ясно, что РФ является победителем по всем трем показателям. Однако насколько надежны наши результаты? Можно ли ожидать стабильной работы? Мы проводим тест на чувствительность и используем еще один пакет обучающих данных того же размера, и вот и смотрите! точность теперь 85%!
Огромная разница в результатах говорит о том, что от нашей модели нельзя ожидать стабильных результатов. Есть еще много параметров, которые могут повлиять на производительность RF, таких как максимальная глубина дерева и количество оценщиков. Одна из идей реального ощущения надежности — это самозагрузка: случайная выборка данных с заменой и отчет о точности каждой партии.
Заключение
Мы обнаружили, что действительно можем классифицировать музыкальные инструменты без особых вычислительных усилий, и результаты намного превосходят результаты случайного предположения. Кроме того, самый модный алгоритм не всегда дает наилучшие результаты.
Этот пост основан на гораздо более крупном проекте, найденном в моем профиле GitHub, и поставляется с подробным отчетом, в котором шаг за шагом объясняется процесс машинного обучения.
Как узнать частоту звука?
Как менять частоту звука на STM32
Всем привет, на курсовую дали вот такое задание "Разработать МК устройство которое позволяет в.
Узнать из программы частоту процессора
Приветствую. Подскажите способ узнать из программы частоту процессора (ATMiko32, впрочем.
 Как узнать частоту звука без сторонних библиотек
Как узнать частоту звука без сторонних библиотек
кто нибудь знает как в работать со звуком без сторонних библиотек? мне нужно чтобы во время.
Как узнать частоту, амплетуду, длинну и т.д. звука в данный момент?
Здравствуйте! Как узнать частоту, амплетуду, длинну, скорость и т.д. звука в данный момент? ВОТ.
43 Гц. Ссылки на рабочие реализации FFT даны, на литературу тоже, даже FFTW либа имеет свой сайт с готовыми примерами, а вы обратились почему-то к вики. Вот и расхлебывайте.
А по сабжу, для повышения точности методов FFT используют несколько параллельно проводимых преобразований с разным количеством точек, так реализовано в некоторых цифровых осциллографах, что дает более четкую картинку спектрограммы и более высокую точность за счет совмещения нескольких спектров в единицу времени с разным разрешением по частоте. Вот так вот.
. причем тут примеры на Delphi? Библиотека fftw кроссплатформенна, если речь о примерах из моих статей, то уже давно разработана библиотека fftr для сторонних разработчиков.
Насчет гармоник баса, не понял. да, нотный частотный ряд делится определенным образом (см. выше), но причем тут FFT? ХОчется точности, увеличивайте размер буфера из отсчетов для анализа и количество задаваемых точек преобразования + метод вариации количества точек преобразования и даже частот дискретизации для перекрытия заданного нотного ряда и доли герца тут не нужны — обратитесь к таблице выше (на моей памяти есть тут тема, где берется fft с миллионом точек, только тут время, время).
Можно ли частоту уточнить интерполированием около максимума? влево и вправо по два или три значения учесть
Добавлено через 2 минуты
Пятая струна имеет частоту 110 герц, но при дёргании программа распознаёт её как 220 гц.
Ноты на шестой струне так же определяются не 81 гц, а 162 гц. То есть программа показывает не основную частоту, а более громкую гармонику
. правильно показывает. Тут есть тема, так и называется — определение частоты основного тона, возможно вам подойдет лучше.
В то же время, вам никто не мешает увеличить разрешение по частоте, сделать FFT, скажем на 4096 точек, и применить одну маленькую хитрость (кроме уже выше рекомендованных) — сетка частот у вас дискретна и постоянна в спектре и то, что оно вам покажет ту гармонику, которая ближе и попадает в сетку — верно, но ведь и вы данную сетку можете сравнивать с сеткой нот и подобрать ближайшую ноту. Ферштеен?
Получение частоты звука с микрофона
Есть задача получать частоту звука с микрофона для дальнейших преобразований на C#. Подобное уже делал на Python с numpy, но тут как то не клеится.
Это что на С# сделал. Сделано так, ибо так же было на Python. В конечном итоге работает, но неправильно — частота получается одна и та же (+- пара герц), но по идее там должны быть абсолютно другие частоты — передаем данные с помощью звука.
Помогите разобраться, что в коде может быть не так?
UPD
Вот что получилось в итоге. Спасибо товарищу @MSDN.WhiteKnight — натолкнул на правильные мысли. Плюс использовался проект вот отсюда
выкладываю только код, который несет смысл по вытаскиванию частот звука с микрофона(МОНО). Можно переделать на стерео — не особо сложно будет
что использовалось. NAudio — для получения потока звука с микрофона
ZedGraph — как переходник для работы с сигналом после преобразования Фурье — его можно убрать, но в моем случае был удобен.