Python. Частота появления слов и букв независимо от их регистра в тексте который находиться в файле
Нужно написать программу, которая будет анализировать частоту с которой в тексте(в файле) будут встречаться отдельные буквы или слова независимо от их регистра и выводить в консоль потом записывать в новый файл.
Таким образом получаем текст из файла и убираем всё лишние из текста, а дальше как правильно сделать не понимаю.
![]()
Для слов
Для букв
Тоже самое, но для паттерна для модуля re использовать отдельные буквы. В зависимоти от того насколько большой текст, возможно, стоит отказаться для подсчета букв от данного модуля и использовать конструкцию
И использовать перебор по всем буквам алфавита
Запись организовать как указано выше
и так далее, для чисел, для знаков и прочее
Чтобы удалить все знаки препинания, тоже можно воспользоваться модулем re
Частотный анализ букв в тексте
Будет много картинок (с текстом) и текста. А как иначе?!
Хочу рассказать вам немного о криптографии, точнее, о криптоанализе.
И об шифровании текста, точнее о шифровании методом замены (как шифр Цезаря).
Криптография — это наука о методах обеспечения конфиденциальности, целостности и аутентификации. Или проще, шифровании информации от злоумышленника.
А криптоанализ, наоборот, наука о раскрытии зашифрованного сообщения.
Теперь ближе к практике, не хочу вас грузить. Сразу пример.
Есть некий текст, который зашифровали заменой одного символа на другой:
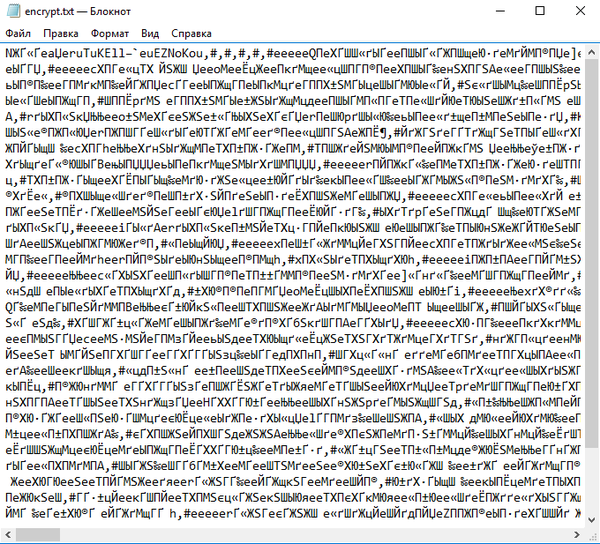
Чтобы его расшифровать я использую частотный анализ букв в тексте:
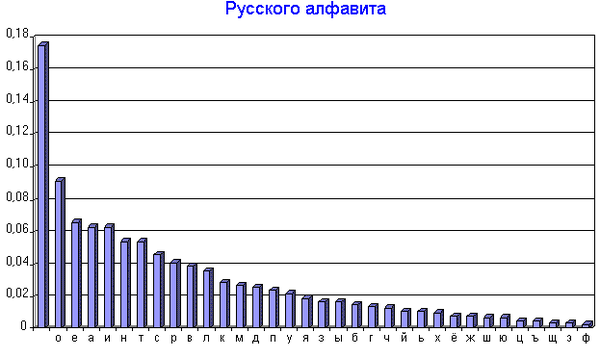
Если текст достаточно большой, то в нём всегда выполняется это правило.
Поэтому возьмём для подбора конкретной информации большой объём текста:

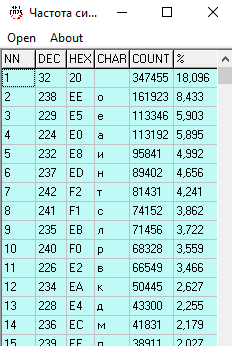
И сравним с зашифрованным текстом
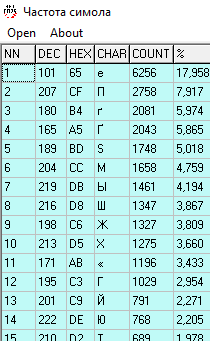
И дело за малым, заменим буквы в зашифрованном тексте, согласно частотам.
Сделать это можно, например, с помощью блокнота «Правка — Заменить»

В качестве и с музыкой
Заранее: Gesaffelstein — Destination
Надеюсь эта небольшая заметка, не несущая в себе много информации, заинтересует вас и привлечёт к изучению криптоанализу.
Планирую ещё несколько постов по информационной безопасности.
Цель как и всегда ранее: ради общения на эту тему развиваю эту тему

1.4K поста 25.3K подписчик
Правила сообщества
Обязательно к прочтению для авторов:
1. Если вы добавляете пост, утверждающий об утечке данных или наличии дыр в системе, предоставьте ссылку на источники или технически подкованное расследование. Посты из разряда «Какой-то банк слил данные, потому что мне звонили мошенники» будут выноситься в общую ленту.
2. Все вопросы «Как обезопасить сервер\приложение\устройство» — в лигу «Компьютер это просто».
Обязательно к прочтению для всех:
Добавление ссылки разрешено если она не содержит описание коммерческих (платных) продуктов и/или идентификаторов для отслеживания перехода и для доступа не нужен пароль или оплата в т.ч. интернет-ресурсы, каналы (от 3-х тематических видео), блоги, группы, сообщества, СМИ и т.д.
Запрещены политические holy wars.
По решению модератора или администратора сообщества пользователь будет забанен за:
1. Флуд и оскорбление пользователя, в т.ч. провокация спора, флуда, холивара (высказывание без аргументации о конкретной применимости конкретного решения в конкретной ситуации), требование уже данного ответа, распространение сведений порочащих честь и репутацию, принижающих квалификацию оппонента, переходы на личности.
2. Публикацию поста/комментария не соответствующего тематике сообщества, в том числе обсуждение администраторов и модераторов сообщества, для этого есть специальное сообщество.
Частотный анализ текста. Пример написания калькулятора
Немного о частотном анализе текста и рассказ о создании калькулятора.
В общем, есть такая тема — частотный анализ текста. Утверждается, что для данного языка частота встречаемости отдельных букв в осмысленном тексте есть устойчивая величина. Устойчивыми также являются комбинации двух, трех (биграммы, триграммы) и четырех букв.
Этот факт, в частности, использовался в криптографии для вскрытия шифров.
Я в криптографии не очень, и единственное, что приходит на ум, это вскрытие шифра прямой замены. Надо сказать, наиболее примитивного шифра, когда символы исходного алфавита, используемого в сообщении, преобразуются в другие символы по определенному правилу. Такие шифры, кстати сказать, можно было вскрывать и без применения статистического анализа (где для уменьшения погрешности, очевидно, требуется наличие довольно больших кусков текста), а просто догадываясь о некоторых словах — см. рассказ «Пляшущие человечки».
Вот тут, впрочем, интересная статья про историю криптографии.
На самом деле частота встречаемости букв также зависит от типа текста. Калькулятор ниже рассчитывает частоты букв для введенного пользователем текста и выводит для сравнения теоретические частоты букв для художественного русского текста. В качестве значения по умолчанию взят научный текст (начало определения дифференциального уравнения из Википедии), и сразу видно, как, например, различается частота встречаемости буквы Ф в художественном и научном текстах.
Частоты букв для художественного текста я взял отсюда, ну а по указанному адресу утверждают, что взяли их из книги «Яглом А. М., Яглом И. М., Вероятость и информация, М.: Наука, 1973».
Этот калькулятор был создан как пример, для того чтобы продолжить рассказ о том, как создавать калькуляторы на этом сайте, начатый здесь — Площадь четырехугольника. Пример написания калькулятора. В данном случае на примере этого калькулятора я расскажу о том, как писать калькуляторы, выводящие таблицы и строящие графики. Как обычно, все что нужно от автора — некоторое знание Javascript, ну или вообще любого алгоритмического языка программирования. Интересующиеся смотрят текст после самого калькулятора.
Частотный анализ текста онлайн
Частотный анализ – это один из методов криптоанализа, основывающийся на предположении о существовании нетривиального статистического распределения отдельных символов и их последовательностей как в открытом тексте, так и шифрованном тексте, которое с точностью до замены символов будет сохраняться в процессе шифрования и дешифрования.
Кратко говоря, частотный анализ предполагает, что частота появления заданной буквы алфавита в достаточно длинных текстах одна и та же для разных текстов одного языка. При этом в случае моно алфавитного шифрования, если в шифрованном тексте будет символ с аналогичной вероятностью появления, то можно предположить, что он и является указанной зашифрованной буквой. Аналогичные рассуждения применяются к биграммам (двухбуквенным последовательностям), триграммам в случае поли алфавитных шифров.
Метод частотного анализа известен с еще IX-го века и связан и именем Ал-Кинди. Но наиболее известным случаем применения такого анализа является дешифровка египетских иероглифов Ж.-Ф. Шампольоном в 1822 году.
Данный вид анализа основывается на том, что текст состоит из слов, а слова из букв. Количество различных букв в каждом языке ограничено и буквы могут быть просто перечислены. Важными характеристиками текста являются повторяемость букв, пар букв (биграмм) и вообще m-ок (m-грамм), сочетаемость букв друг с другом, чередование гласных и согласных и некоторые другие.
Идея состоит в подсчете чисел вхождений каждой nm возможных m-грамм в достаточно длинных открытых текстах T=t1t2…tl, составленных из букв алфавита
t1t2. tm, t2t3. tm+1, . ti-m+1tl-m+2. tl.
Если – число появлений m-граммы ai1ai2. aim в тексте T, а L – общее число подсчитанных m-грамм, то опыт показывает, что при достаточно больших L частоты
для данной m-граммы мало отличаются друг от друга.
В силу этого, относительную частоту считают приближением вероятности P (ai1ai2. aim) появления данной m-граммы в случайно выбранном месте текста (такой подход принят при статистическом определении вероятности).
В представленной ниже таблице приводятся частоты встречаемости букв в русском языке (в процентах):
| Буква алфавита | Показатель частоты встречаемости | Буква алфавита | Показатель частоты встречаемости |
|---|---|---|---|
| А | 0,062 | Р | 0,04 |
| В | 0,038 | Т | 0,053 |
| Д | 0,025 | Ф | 0,002 |
| Ж | 0,007 | Ц | 0,004 |
| И | 0,062 | Ш | 0,006 |
| К | 0,028 | Ъ, Ь | 0,014 |
| М | 0,026 | Э | 0,003 |
| О | 0,09 | Я | 0,018 |
Имеется мнемоническое правило запоминания десяти наиболее частых букв русского алфавита. Эти буквы составляют слово СЕНОВАЛИТР.
Устойчивыми являются также частотные характеристики биграмм, триграмм и четырехграмм осмысленных текстов. Существуют специальные таблицы с указанием частоты биграмм некоторых алфавитов. По результатам исследований с помощью таких таблиц ученые определили наиболее часто встречаемые биграммы и триграммы для русского алфавита:
СТ, НО, ЕН, ТО, НА, ОВ, НИ, РА, ВО, КО, СТО, ЕНО, НОВ, ТОВ, ОВО, ОВА.
Из таблиц биграмм можно также легко извлечь информацию о сочетаемости букв, т.е. о предпочтительных связях букв друг с другом.
Результатом таких исследований является таблица, в которой слева и справа от каждой буквы расположены наиболее предпочтительные «соседи» (в порядке убывания частоты соответствующих биграмм). В таких таблицах обычно указывается также доля гласных и согласных букв (в процентах), предшествующих (или следующих за) данной букве.
| Г | С | Слева | Справа | Г | С | |
|---|---|---|---|---|---|---|
| 3 | 97 | л, д, к, т, в, р, н | А | л, н, с, т, р, в, к, м | 12 | 88 |
| 80 | 20 | я, е, у, и, а, о | Б | о, ы, е, а, р, у | 81 | 19 |
| 68 | 32 | я, т, а, е, и, о | В | о, а, и, ы, с, н, л, р | 60 | 40 |
| 78 | 22 | р, у, а, и, е, о | Г | о, а, р, л, и, в | 69 | 31 |
| 72 | 28 | р, я, у, а, и, е, о | Д | е, а, и, о, н, у, р, в | 68 | 32 |
| 19 | 81 | м, и, л, д, т, р, н | Е | н, т, р, с, л, в, м, и | 12 | 88 |
| 83 | 17 | р, е, и, а, у, о | Ж | е, и, д, а, н | 71 | 29 |
| 89 | 11 | о, е, а, и | З | а, н, в, о, м, д | 51 | 49 |
| 27 | 73 | р, т, м, и, о, л, н | И | с, н, в, и, е, м, к, з | 25 | 75 |
| 55 | 45 | ь, в, е, о, а, и, с | К | о, а, и, р, у, т, л, е | 73 | 27 |
| 77 | 23 | г, в, ы, и, е, о, а | Л | и, е, о, а, ь, я, ю, у | 75 | 25 |
| 80 | 20 | я, ы, а, и, е, о | М | и, е, о, у, а, н, п, ы | 73 | 27 |
| 55 | 45 | д, ь, н, о | Н | о, а, и, е, ы, н, у | 80 | 20 |
| 11 | 89 | р, п, к, в, т, н | О | в, с, т, р, и, д, н, м | 15 | 85 |
| 65 | 35 | в, с, у, а, и, е, о | П | о, р, е, а, у, и, л | 68 | 32 |
| 55 | 45 | и, к, т, а, п, о, е | Р | а, е, о, и, у, я, ы, н | 80 | 20 |
| 69 | 31 | с, т, в, а, е, и, о | С | т, к, о, я, е, ь, с, н | 32 | 68 |
| 57 | 43 | ч, у, и, а, е, о, с | Т | о, а, е, и, ь, в, р, с | 63 | 37 |
| 15 | 85 | п, т, к, д, н, м, р | У | т, п, с, д, н, ю, ж | 16 | 84 |
| 70 | 30 | н, а, е, о, и | Ф | и, е, о, а, е, о, а | 81 | 19 |
| 90 | 10 | у, е, о, а, ы, и | Х | о, и, с, н, в, п, р | 43 | 57 |
| 69 | 31 | е, ю, н, а, и | Ц | и, е, а, ы | 93 | 7 |
| 82 | 18 | е, а, у, и, о | Ч | е, и, т, н | 66 | 34 |
| 67 | 33 | ь, у, ы, е, о, а, и, в | Ш | е, и, н, а, о, л | 68 | 32 |
| 84 | 16 | е, б, а, я, ю | Щ | е, и, а | 97 | 3 |
| 0 | 100 | м, р, т, с, б, в, н | Ы | л, х, е, м, и, в, с, н | 56 | 44 |
| 0 | 100 | н, с, т, л | Ь | н, к, в, п, с, е, о, и | 24 | 76 |
| 14 | 86 | с, ы, м, л, д, т,, р, н | Э | н, т, р, с, к | 0 | 100 |
| 58 | 42 | ь, о, а, и, л, у | Ю | д, т, щ, ц, н, п | 11 | 89 |
| 43 | 57 | о, н, р, л, а, и, с | Я | в, с, т, п, д, к, м, л | 16 | 84 |
Пример: Проведем анализ текста следующего содержания
«СОКРАТ из Афин (469–399 до н.э.) – знаменитый античный философ, учитель Платона, воплощенный идеал истинного мудреца в исторической памяти человечества. С именем Сократа связано первое фундаментальное деление истории античной философии на до- и после-Сократовскую («Досократики»), отражающее интерес ранних философов VI–V вв. к натурфилософии, а последующего поколения софистов V в. – к этико-политическим темам, главная из которых – воспитание добродетельного человека и гражданина. Сократу был близок софистическому движению. Учение Сократа было устным; все свободное время он проводил в беседах с приезжими софистами и местными гражданами, политиками и обывателями, друзьями и незнакомыми на темы, ставшими традиционными для софистической практики: что есть добро и что – зло, что прекрасно, а что безобразно, что добродетель и что порок, можно ли научиться быть хорошим и как приобретается знание. Об этих беседах мы знаем в основном благодаря ученикам Сократа – Ксенофонту и Платону. Кроме их сочинений, имеются также фрагменты и свидетельства о содержании «сократических диалогов» других сократиков, пародийное изображение Сократа в комедии Аристофана Облака и ряд замечаний о Сократе у Аристотеля. Проблема достоверности изображения личности Сократа в сохранившихся произведениях – ключевой вопрос всех исследований о нем.»