Что такое S.M.A.R.T. жестких дисков
Новейшие накопители представлены интеллектуальными устройствами, способными анализировать свое состояние и своевременно информировать пользователя о неполадках. Для этого аппаратная часть включает оригинальную опцию S.M.A.R.T.
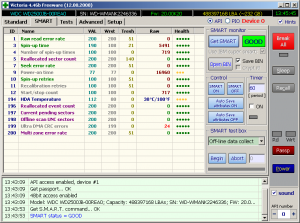
Назначение технологии SMART.
Львиная доля дисковых накопителей последних лет, функционирует с использованием технологии S.M.A.R.T. Сочетание расшифровывается как self-monitoring, analysis and reporting technology , что на русском звучит как механизм самоконтроля, анализа и отчетности. Ее первые разработки увидели свет в 1995 году и с тех пор технология постоянно совершенствуется.
С момента производства дисковый накопитель начинает считывать свое текущее состояние, определяя его с помощью специальных параметров или атрибутов. Они располагаются в служебной зоне накопителя, доступ к которой имеет лишь встроенная программа. Просмотреть параметры позволяет отдельное ПО, чаще всего представленное утилитами от разработчиков конкретного жесткого диска. Через них в накопитель подаются вводные, после чего в журнале статистики появится информация о текущем состоянии диска.
В процессе эксплуатации накопителя, данные представленные в рамках параметров значения постоянно меняются. Параметры проходят путь с максимальных показателей, гарантирующих высокую производительность и эффективность до минимальных значений, связанных с высокой вероятностью выхода накопителя из строя.
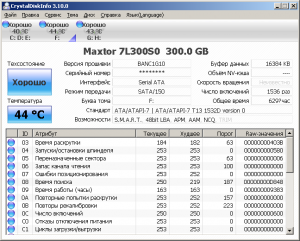
Все представленные в рамках технологии S.M.A.R.T атрибуты имеет цифровой идентификатор. Как правило, он общий для накопителей различных версий, однако имеют место исключения. В данном отношении выделяется цифра 7, демонстрирующая ошибки в размещении головок на дисковую поверхность. Для накопителей формата SSD цифровой идентификатор неактуален. В отличие от 7-ки, цифра 9, которая показывает общий период непосредственной работы накопителя за срок использования, ее поддерживают все типы дисков HDD и SSD.
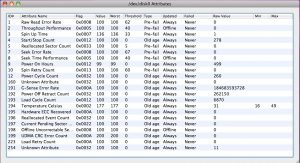
Структура параметров, представлена несколькими полями, демонстрирующих состояние диска и его разделов в конкретный период. Предназначенные для считывания информации утилиты выводят на экран следующие параметры:
- ID – идентификационный номер
- name – название атрибута
- VAL – его текущее состояние
- Wrst – наихудший показатель за период эксплуатации
- Thresh – минимальный порог работоспособности
Показатели S.M.A.R.T
Существует несколько самых распространенных параметров. Они, за редким исключением, объединяют накопители большинства производителей, итак:
- Raw Read Error Rate – показатель числа ошибок считывания
- Throughput Performance – рабочая эффективность. Ее снижение указывает на необходимость замены
- Spin Up Time – период развертывания накопителя в рабочее состояние. Рост параметра демонстрирует изношенность или недостаток питания
- Start/Stop Count – показатель количества моментов развертывания диска, которое изначально ограничено его механической структурой
- Reallocated Sectors Count – атрибут отражает число запасных участков. Туда при неполадках перенаправляется информация. В идеале количество подобных действий должно составлять 0
- Read Channel Margin – канальный резерв. В наше время накопители обходятся без него
- Seek Error Rate – Отражение механического состояния накопителя, в числе прочего демонстрирует излишнюю вибрацию и перегрев
- Seek Time Performance – уровень оперативных возможностей, актуален лишь для дисков HDD
- Power-on Time – прогноз продолжительности функционирования накопителя исходя из периода эксплуатации. Максимальные показатели составляют 100 и с течением времени снижаются до 0
- Spin-Up Retry Count – количество дублирующих операций запуска. Их увеличение говорит об ошибках в механической структуре
Эти и другие атрибуты, идущие красным фоном, говорят о его критическом состоянии накопителя, что предполагает скорую поломку. Конкретного стандарта, объединяющего показатели параметров от различных производителей, не существует. В каждом случае нормальные значения индивидуальны, отражаясь в виде фона или статуса, где
- Good – хороший показатель
- Bad – плохой показатель.
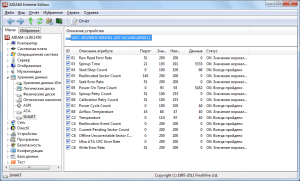
Наряду с уже упомянутыми атрибутами следует уделять внимание таким параметрам как:
SMART Parameters and Early Signs
of a Failing Hard Disk
![]()
This article talks about tools to use and parameters to check for to prevent accidental data loss due to hard drive failure. S.M.A.R.T. (or simply SMART) is a monitoring system built into most modern hard drives. S.M.A.R.T. stands for Self-Monitoring, Analysis and Reporting Technology. The technology helps detect various reliability problems at an early stage, giving warning signs well in advance before the hard drive fails. By reading (and interpreting) the indicators, the user can prevent data loss by replacing the disk before the crash occurs. But what S.M.A.R.T. flags should we look at? There are dozens available!
Contents:
- The Tools.
- Hard Drive S.M.A.R.T. Parameters.
The Tools
Before you begin, you’ll need a tool to read the many S.M.A.R.T. parameters available in your hard drive. There are many free tools that can display and decode the many available S.M.A.R.T. parameters.
Hard Drive S.M.A.R.T. Parameters
With so many different parameters available, which ones give a warning sign? This is not an easy question to answer, as different manufacturers support different subsets of reporting variables. In addition, raw values you see in the rightmost column are vendor-specific, meaning nothing before they are decoded. However, there are some parameters that are supported by most manufacturers (for example AData, PQI, Transcend).
Диагностика винчестера: теория и практика
Несмотря на то что стоимость жестких дисков постепенно снижается, зачастую ценность информации, которая на них хранится, очень высока. Вместе с тем, учитывая конструкцию и принцип работы HDD, они являются одними из наименее надежных составляющих компонентов ПК. Потому, если вам дороги ваши данные и в один момент вы не хотите лишиться всего накопленного за годы, можно воспользоваться простым методом экспресс-диагностики HDD, которая с большой вероятностью позволит избежать потерь информации.
Детям из Мариуполя нужно 120 ноутбуков для обучения — подари старое «железо», пусть оно работает на будущее Украины
 |
Производители жестких дисков достаточно давно осознали необходимость наличия системы раннего предупреждения о потенциальных проблемах в работе накопителей. Прежде всего это нужно для возможности резервирования информации, хранимой на винчестере. История подобных систем началась в 1992 году, когда IBM стала использовать в своих серверных накопителях технологию Predictive Failure Analysis (PFA). Позже компания Compaq совместно с Seagate, Quantum и Conner создала усовершенствованную технологию IntelliSafe, позволяющую отслеживать большее число параметров HDD. Именно эти наработки в итоге послужили основой для нового стандарта, получившего название S.M.A.R.T. (Self-Monitoring, Analysis, and Reporting Technology).
Главным предназначением S.M.A.R.T. является извещение пользователя о надвигающихся неприятностях с жестким диском. Большинство проблем с винчестерами связаны с механическими сбоями и повреждениями. Однако, как правило, окончательному выходу из строя накопителя предшествуют некоторые косвенные признаки, как то: заметное повышение температуры HDD, посторонние шумы, пощелкивания, проблемы с чтением/записью информации, появление нечитаемых секторов (bad-блоков).
Итак, что же необходимо для того, чтобы проверить атрибуты S.M.A.R.T.? На нынешнем уровне развития технологии отслеживание всех параметров проводится автоматически, не требуя никаких дополнительных действий со стороны пользователя. Однако для того чтобы получить собранные накопителем сведения, нужно воспользоваться соответствующим программным обеспечением. Было бы вполне логично, чтобы функции мониторинга состояния S.M.A.R.T. брала на себя операционная система, но они не реализованы в современных ОС в явном виде. Потому для проверки используются самые разнообразные сторонние утилиты. Это могут быть как специализированные программы, единственной задачей которых является отслеживание необходимых параметров, так и универсальные инструменты, для которых просмотр атрибутов S.M.A.R.T. – это только одна из многочисленных обязанностей. Все, что нужно, – получить таблицу атрибутов. Для скрупулезного анализа данных требуются определенные знания и подготовка, однако для того чтобы понять, что с диском начало происходить что-то нехорошее, особых навыков не требуется.
К сожалению, технология S.M.A.R.T. не имеет четкого стандарта. Изготовители HDD могут по-своему интерпретировать различные параметры и даже использовать недокументированные. По этой причине при оценке S.M.A.R.T. можно наблюдать немало частных случаев, характерных не только для дисков различных производителей, но и для разных моделей одной линейки. Однако основные параметры в большинстве своем все же совпадают.
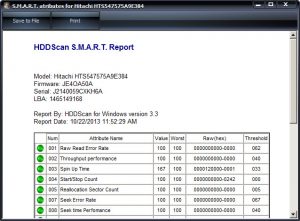
Что же можно увидеть в таблице S.M.A.R.T.? Это список параметров (как правило, 15–30), которые помимо названия имеют следующие поля: Value/Current – текущее значение атрибута, Worst – наихудший показатель за все время работы накопителя, Threshold – критическое минимальное значение. Все это относительные показатели, которые изменяются в диапазоне от 0 до 253. В течение периода эксплуатации HDD текущие показатели (Value) атрибутов могут уменьшаться. При достижении ими порогового значения (Threshold) вероятность сбоя в работе накопителя предельно высока. Фактически в подобном случае производитель не гарантирует работоспособности HDD. Многие диагностические утилиты позволяют посмотреть поле Raw/Data, отражающее количественный показатель измеряемого параметра, которое для удобства обычно автоматически переводится в десятичный формат.
Различные модели накопителей имеют свой перечень параметров S.M.A.R.T.. Отдельно отметим критически важные атрибуты, изменения которых должны насторожить в первую очередь.
Raw Read Error Rate. Появление ошибок при чтении данных с HDD, как правило, говорит о проблемах с поверхностью магнитного диска или головок чтения/записи.

Spin Up Time. Время, необходимое накопителю на раскрутку дисков до «крейсерской скорости». Изменение этого параметра может быть вызвано нарушениями в работе двигателя привода, что недопустимо, когда речь идет о столь точном механическом устройстве. При изменении данного атрибута стоит подумать о более качественном БП. Нередко пульсации и недостаточное/избыточное напряжение питания приводит к неприятным последствиям в работе HDD.
Reallocated Sector Count. Переназначенные секторы де-факто уже являются bad-блоками, информация откуда перенесена в резервную область (spare area). При увеличении секторов, которым понадобился remapрing, производительность накопителя может заметно снизиться.
Seek Error Rate. Ошибки позиционирования часто связаны с проблемами блока магнитных головок.
Ultra ATA CRC Error Rate. При возникновении ошибок при передаче данных по интерфейсу можно попробовать заменить кабель (SATA или IDE).
Мониторинг и проверка состояния SSD в Linux
И снова здравствуйте. Перевод следующей статьи подготовлен специально для студентов курса «Администратор Linux». Поехали!

Что такое S.M.A.R.T.?
S.M.A.R.T. (расшифровывается как Self-Monitoring, Analysis, and Reporting Technology) – это технология, вшитая в накопители, такие как жесткие диски или SSD. Ее основная задача – это мониторинг состояния.
На деле, S.M.A.R.T. контролирует несколько параметров во время обычной работы с диском. Он мониторит такие параметры как количество ошибок чтения, время запуска диска и даже состояние окружающей среды. Помимо этого, S.M.A.R.T. также может проводить тесты с использованием накопителя.
В идеале, S.M.A.R.T. позволит прогнозировать предсказуемые отказы, такие как отказы, вызванные механическим износом или ухудшением состояния поверхности диска, а также непредсказуемые отказы, вызванные каким-либо неожиданным дефектом. Поскольку обычно диски не выходят из строя внезапно, S.M.A.R.T. помогает операционной системе или системному администратору идентифицировать те диски, которые скоро выйдут из строя, чтобы их можно было заменить и избежать потери данных.
Что не относится к S.M.A.R.T.?
Все это, конечно, круто. Однако S.M.A.R.T. – это не хрустальный шар. Он не может спрогнозировать отказ со стопроцентной вероятностью и не может гарантировать, что накопитель не выйдет из строя без предупреждения. В лучшем случае S.M.A.R.T. стоит использовать для оценки вероятности поломки.
Учитывая статистический характер прогнозирования отказов, технология S.M.A.R.T. особенно интересует компании, использующие большое количество устройств для хранения данных. Чтобы выяснить, насколько точно S.M.A.R.T. может прогнозировать отказы и сообщать о необходимости замены дисков в центрах обработки данных или серверных мейнфреймах, даже проводились специальные исследования.
В 2016 году Microsoft и университет штата Пенсильвания провели исследование, связанное с SSD.
Согласно этому исследованию, некоторые атрибуты S.M.A.R.T. считаются хорошими индикаторами неизбежности отказа. В особенности в статье упоминаются:
Счетчик переназначенных (Realloc) секторов:
Несмотря на то, что основополагающие технологии радикально отличаются, этот показатель остается востребованным как в мире SSD, так и в мире жестких дисков. Стоит отметить, что из-за особенностей алгоритмов балансировки износа, используемых в SSD, когда несколько секторов выходят из строя, то с большой вероятностью можно предположить, что скоро выйдут из строя еще больше.
Ошибки в цикле Program/Erase (P/E):
Это признак проблем с основным оборудованием флеш-памяти, связанных с тем, что диск не может удалить данные из блока или сохранить их там. Дело в том, что процесс производства несовершенен, поэтому появление таких ошибок вполне можно ожидать. Однако флеш-память имеет ограниченное число циклов записи/удаления. По этой причине внезапное увеличение числа событий может сигнализировать о том, что диск достигает своего предела, и вполне ожидаемо, что другие ячейки памяти также начнут выходить из строя.
CRC и неисправимые ошибки («Data Error ”):
События такого типа могут быть вызваны ошибками хранения, либо проблемами с внутренним каналом связи накопителя. Этот индикатор учитывает как исправленные ошибки (без проблем сообщенные хост-системе), так и неисправленные ошибки (из-за которых происходит блокировка диска, сообщившего хост-системе о невозможности чтения). Другими словами, исправляемые ошибки невидимы для операционной системы, тем не менее они влияют на производительность накопителя, увеличивая вероятность переназначения сектора.
SATA downshift count:
Из-за временных помех, проблем с каналом связи между накопителем и хостом или из-за внутренних проблем с накопителем, интерфейс SATA может переключиться на более низкую скорость передачи сигналов. Снижение скорости соединения ниже номинального уровня оказывает очевидное влияние на производительность диска. Таким образом, этот показатель является наиболее значимым, в особенности, когда он коррелирует с наличием одного или нескольких предыдущих показателей.
Согласно исследованию, 62% вышедших из строя SSD показали наличие как минимум одного из вышеприведенных симптомов. С другой стороны можно сказать, что 38% изученных накопителей сломались без индикации этих симптомов. В исследованиях не упоминалось, были ли какие-то еще сообщения об отказах от S. M. A. R. T. по другим «симптомам». По этой причине нельзя напрямую сопоставить эти значения с отказом без предупреждения в 36% случаев из статьи от Google.
В исследовании Microsoft и университета штата Пенсильвания не раскрывались модели исследуемых дисков, однако, по словам авторов, большинство дисков поступают от одного и того же поставщика в течение уже нескольких поколений.
В ходе исследования также были отмечены значительные различия в надёжности между различными моделями. Например, «худшая» изученная модель показывает двадцатипроцентную частоту отказов через 9 месяцев после первой ошибки переназначения и до 36-ти процентов отказов в течение 9 месяцев после первого появления ошибок данных. «Худшей» моделью было названо более старое поколение дисков, рассматриваемых в статье.
С другой стороны, с теми же симптомами, что приведены выше, накопители нового поколения отказали в 3% и 20% в соответствии с теми же ошибками. Трудно сказать, можно ли объяснить эти цифры улучшением конструкции накопителя и производственного процесса, или здесь роль играет эффект устаревания накопителя.
Самое интересное, что упоминается в статье (я уже писал об этом ранее), так это то, что увеличение количества зарегистрированных ошибок может случить тревожным индикатором:
Другими словами, одна случайная ошибка, о которой сообщил S.M.A.R.T., определенно не должна рассматриваться как сигнал о неизбежном отказе. Однако, когда исправный SSD начинает сообщать о все большем количестве ошибок, следует ждать краткосрочного или среднесрочного сбоя.
Но как узнать, в каком состоянии сейчас ваш SSD? Для удовлетворения своего любопытства, либо из желания начать внимательно следить за своими накопителями, вы можете использовать инструмент мониторинга smartctl .
Использование smartctl для мониторинга состояния вашего SSD в Linux
Чтобы следить за S.M.A.R.T статусом вашего диска, я предлагаю использовать инструмент smartctl , который является частью пакета smartmontool (по крайней мере на Debian/Ubuntu).
smartctl – это инструмент командной строки, но это особенно помогает в случаях, когда вам нужно автоматизировать сбор данных, например, с ваших серверов.
Первый шаг в использовании smartctl – это проверка того, есть ли на вашем диске S.M.A.R.T. и поддерживается ли он инструментом:
Как видите, мой внутренний жесткий диск ноутбука действительно поддерживает S.M.A.R.T. и он включен. Итак, как теперь получить S.M.A.R.T статус? Есть ли какие-то зафиксированные ошибки?
Выдача отчета «о всей S.M.A.R.T. информации о диске» — это опция -a :
Понимание выходных данных команд smartctl
На выходе получается много информации, которую не всегда легко понять. Наиболее интересной, вероятно, является та часть, которая помечена как “Vendor Specific SMART Attributes with Thresholds”. Она сообщает различные статистические данные, собранные S.M.A.R.T. устройством, и позволяет сравнить эти значения (текущие или худшие за все время) с некоторым порогом, определенным поставщиком.
Например, вот мои отчеты о переназначенных секторах на диске:
Вы можете заметить атрибут «Pre-fail». Он означает, что значение является аномальным. Таким образом, если значение превышает пороговое, велика вероятность сбоя. Другая категория »Old_age» используется для атрибутов, отвечающих значениям «нормального износа».
Последнее поле (здесь со значением «3») соответствует исходному значению атрибута, которое сообщает диск. Обычно это число имеет физическое значение. Здесь это фактическое количество переназначенных секторов. Для других атрибутов это может быть температура в градусах Цельсия, время в часах или минутах или количество раз, когда для диска было выполнено определенное условие.
В дополнение к исходному значению, диск с поддержкой S.M.A.R.T. должен сообщать «нормализованные значения» (значения полей, самые худшие и пороговые). Эти значения нормируются в диапазоне 1-254 (0-255 для пороговых значений). Прошивка диска выполняет эту нормализацию с помощью некоторого внутреннего алгоритма. Кроме того, разные производители могут нормализовать один и тот же атрибут по-разному. Большинство значений представлены в процентах, причем чем выше, тем лучше, но так бывает не всегда. Когда параметр ниже или равен пороговому значению, указанному производителем, диск считается неисправным в терминах этого атрибута. Помня о всех указаниях из первой части статьи, когда атрибут, показывающий ранее значение “pre-fail” все-таки дал сбой, наиболее вероятно, что скоро диск выйдет из строя.
В качестве второго примера возьмем “seek error rate”:
На самом деле (и это основная проблема отчетности S.M.A.R.T.), точное значение полей каждого атрибута понимает только поставщик. В моем случае Seagate использует логарифмическую шкалу для нормализации значения. Таким образом, «71» означает примерно одну ошибку на 10 миллионов запросов (10 в степени 7,1). Забавно, что самым худшим показателем за все время была одна ошибка на 1 миллион запросов (10 в 6-й степени).
Если я правильно понимаю, то это значит, что головки моего диска сейчас расположены точнее, чем раньше. Я не следил за этим диском внимательно, поэтому анализирую полученные данные весьма субъективно. Возможно накопитель просто надо было немного «обкатать» с тех пор как он был введен в эксплуатацию? Или может быть это следствие механического износа деталей и, следовательно, теперь имеет место меньшая сила трения? В любом случае, какова бы ни была причина, это значение является скорее показателем производительности, чем ранним предупреждением об ошибке. Так что меня оно не сильно беспокоит.
Помимо вышеприведенного и трех крайне подозрительных ошибок, записанных около шести месяцев назад, этот диск находится в удивительно хорошем состоянии (по данным S.M.A.R.T.) для стокового диска ноутбука, проработавшего более 1100 дней (26423 часа).
Из любопытства я провел этот же тест на гораздо более новом ноутбуке, оснащенном SSD:
Первое, что бросается в глаза, так это то, что несмотря на наличие S.M.A.R.T., устройства нет в базе данных smartctl . Но это не помешает инструменту собирать данные с SSD, однако он не сможет сообщить точные значения различных атрибутов, специфичных для поставщика:
Выше вы видите выходные данные абсолютно нового SSD. Данные понятны даже в случае отсутствия нормализации или метаинформации для данных конкретного поставщика, как в моем случае с “Unknown_SSD_Attribute.” Я могу только надеяться, что в последующих версиях smartctl в базе данных появятся данные об этой модели диска, и я смогу лучше определять потенциальные проблемы.
Проверьте свой SSD в Linux с помощью smartctl
До сих пор мы рассматривали данные, собранные во время нормальной работы накопителя. Однако протокол S.M.A.R.T. также поддерживает несколько команд для автономного тестирования для запуска диагностики по требованию.
Автономное тестирование может проводиться во время обычных операций с диском, если не было указано иное. Поскольку тест и запросы ввода-вывода хоста будут конкурировать, производительность диска упадет на время теста. Спецификация S.M.A.R.T. определяет несколько видов автономного тестирования:
Короткое автономное тестирование ( -t short )
Такой тест проверит электрическую и механическую, производительность, а также производительность чтения диска. Короткое автономное тестирование обычно занимает всего несколько минут (обычно от 2 до 10).
Расширенное автономное тестирование ( -t long )
Этот тест занимает почти в два раза больше времени. Как правило, это просто более детальная версия короткого автономного тестирования. Кроме того, этот тест будет сканировать всю поверхность диска на наличие ошибок данных без ограничения по времени. Продолжительность теста будет пропорциональна размеру диска.
Транспортировочное автономное тестирование ( -t conveyance )
Этот тестовый набор предложен в качестве сравнительно быстрого способа проверки на возможные повреждения, возникшие во время транспортировки устройства.
Вот примеры, взятые с тех же дисков, что были выше. Я предлагаю вам угадать, где какой:
Сейчас производится проверка. Давайте дождемся завершения, чтобы посмотреть результат:
Проведем тот же тест на другом диске:
И еще раз, отправим в сон на две минуты и посмотрим результат:
Интересно, что в этом случае мы видим, что производители диска и компьютера, похоже, уже тестировали диск (на времени жизни в 0 часов и 12 часов). Я сам определенно был гораздо менее озабочен состоянием диска, чем они. Итак, поскольку я уже показал быстрые тесты, то и расширенный тоже запущу, чтобы посмотреть как это происходит.
Судя по всему на этот раз ждать придется гораздо дольше, чем при проведении короткого теста. Так что давайте посмотрим:
В последнем тесте обратите внимание на различие в результатах, полученных с помощью короткого и расширенного теста, даже если они были выполнены один за другим. Ну, возможно, этот диск не в таком уж и хорошем состоянии! Отмечу, что тест остановился после первой ошибки чтения. Поэтому, если вы хотите получить исчерпывающую информацию обо всех ошибках чтения, вам придется продолжать тест после каждой ошибки. Я призываю вас взглянуть на одну очень хорошо написанную страницу руководства smartctl(8) для получения дополнительной информации о параметрах -t select , N-max и -t select , чтобы уметь делать так: