Свёрточная нейронная сеть (CNN)

Сверточная нейронная сеть (Convolutional Neural Networks, ConvNet) – класс Нейронных сетей (Neural Network), который специализируется на обработке данных, имеющих топологию в виде сетки, например изображений. Цифровое изображение – это двоичное представление визуальных данных. Он содержит серию пикселей, расположенных в виде сетки, где каждая ячейка содержит визуальные данные: яркость и цвет.
![]() Изображение как сетка пикселей
Изображение как сетка пикселей
Человеческий мозг обрабатывает огромное количество информации при просмотре изображения. Каждый нейрон работает в своем собственном рецептивном поле и связан с другими нейронами таким образом, что они покрывают все поле зрения. Подобно тому, как каждый нейрон реагирует на стимулы только в ограниченной области поля зрения, называемой рецептивным полем в системе биологического зрения, каждый нейрон в CNN также обрабатывает данные только в своем рецептивном поле. Слои расположены таким образом, что сначала они обнаруживают более простые узоры (линии, кривые и т. Д.), А затем более сложные узоры (лица, объекты и т. Д.). Используя CNN, можно обеспечить Компьютерное зрение (CV).
Архитектура
CNN обычно имеет три уровня: сверточный слой, слой объединения и полностью связанный слой:
 Архитектура CNN
Архитектура CNN
Сверточный слой
Сверточный слой является основным строительным блоком CNN. Он несет основную часть вычислительной нагрузки сети.
Этот уровень выполняет скалярное произведение между двумя матрицами, где одна матрица представляет собой набор обучаемых параметров, иначе называемых ядром, а другая матрица – ограниченной частью воспринимающего поля. Ядро пространственно меньше изображения, но имеет бо́льшую глубину. Это означает, что если изображение состоит из трех RGB-каналов, высота и ширина ядра будут пространственно малы, но глубина распространяется на все три канала:
Во время прямого прохода ядро скользит по высоте и ширине изображения, создавая представление изображения этой рецептивной области. Это создает двумерное представление изображения, известное как карта Активации (Activation), которая дает реакцию ядра в каждой пространственной позиции изображения. Скользящий размер ядра называется шагом.
Если у нас есть входные данные размером W x W x D и количество ядер с пространственным размером F с шагом S и количеством отступов P, то размер выходного слоя можно определить по следующей формуле:
Мы получим выходное разрешение Wout x Wout x Dout.
 Операция свертки
Операция свертки
Причины сворачивания
Свертка использует три важные идеи, которые мотивировали исследователей компьютерного зрения: разреженное взаимодействие, совместное использование параметров и эквивариантное (равноценное) представление. Опишем подробно каждую из них.
Тривиальные слои нейронной сети используют результат перемножения матрицы на матрицу параметров, описывающих взаимодействие между входом и выходом. Это означает, что каждый блок вывода взаимодействует с каждым блоком ввода. Однако свёрточные нейронные сети взаимодействуют разреженно. Это достигается за счет уменьшения размера ядра по сравнению с входными данными, например, изображение может иметь миллионы или тысячи пикселей, но при его обработке с использованием ядра мы можем обнаружить значимую информацию, состоящую из десятков или сотен пикселей. Это означает, что нам нужно хранить меньше параметров, что не только снижает потребность модели в памяти, но и повышает ее статистическую эффективность.
Если вычисление одного объекта в пространственной точке (x1, y1) полезно, то оно также должно быть полезно в какой-то другой пространственной точке, например (x2, y2). Это означает, что для одного двумерного среза, то есть для создания одной карты активации, нейроны вынуждены использовать один и тот же набор весов. В традиционной нейронной сети каждый элемент матрицы весов используется один раз, а затем никогда не пересматривается, в то время как сеть свертки имеет общие параметры, то веса, применяемые к одному входу, такие же, как веса, применяемый в другом.
Благодаря совместному использованию параметров слои сверточной нейронной сети будут иметь свойство эквивалентности трансляции: если мы каким-то образом изменили входные данные, выходные также изменятся.
Слой пулинга
Слой пулинга (объединения) заменяет выходные данные сети в определенных местах, получая сводную статистику ближайших выходов. Это помогает уменьшить пространственный размер представления, что уменьшает необходимое количество вычислений и весов. Операция объединения обрабатывается отдельно для каждого фрагмента представления.
Существует несколько функций объединения, таких как среднее значение прямоугольной окрестности, норма L2 для прямоугольной окрестности и средневзвешенное значение, основанное на расстоянии от центрального пикселя. Однако самый популярный процесс – это максимальный пулинг, которое сообщает о максимальном выходе из окружения.

Если у нас есть карта активации размером W x W x D, объединяющее ядро пространственного размера F и шаг S, то размер выходного объема можно определить по следующей формуле:
Это позволит вычислить выходной объем размером Wout x Wout x D.
Во всех случаях объединение обеспечивает некоторую инвариантность трансляции, что означает, что объект будет узнаваемым независимо от того, где он появляется в кадре.
Полностью связанный слой
Нейроны в этом слое имеют полную связь со всеми нейронами предыдущего и последующего слоя, как это видно в обычном FCNN (Fully-Connected Convolutional Neural Network). Вот почему его можно вычислить как обычно, умножением матрицы с последующим эффектом смещения.
Полностью связанный cлой помогает сопоставить представление между данными на входе и выходе.
Нелинейные слои
Поскольку свертка – это линейная операция, а изображения далеки от линейности, нелинейные слои часто размещаются непосредственно после сверточного слоя, чтобы внести нелинейность в карту активации.
Существует несколько типов нелинейных операций, самые популярные из которых:
- Сигмоида. Сигмоидальная нелинейность берет Действительное число (Float Number) и «сжимает» его до диапазона от 0 до 1. Нежелательным свойством сигмоида является обнуление градиента, что когда активация происходит на любом из хвостов. Если локальный градиент становится очень маленьким, то при Обратном распространении (Back Propagation) он эффективно «убивает» градиент. Кроме того, если данные, поступающие в нейрон, всегда положительны, то на выходе сигмоида будут либо все положительные, либо все отрицательные значения, что приведет к зигзагообразной динамике обновления градиента для веса.
- Tanh
Tanh (гиперболический тангенс числа) сжимает действительное число до диапазона [-1, 1]. Как и с cигмоидой, активация «насыщается», но в отличие от сигмоидных нейронов, ее выход центрирован относительно нуля. - Функция активации выпрямителя (ReLU) стала очень популярной в последние несколько лет. У активации просто нулевой порог. По сравнению с сигмоидом и tanh, ReLU более надежен и ускоряет сходимость в шесть раз. К сожалению, минус в том, что ReLU может быть хрупким во время тренировки. Большой градиент, протекающий через него, может обновить его таким образом, что нейрон никогда не будет обновляться дальше. Однако мы можем работать с этим, установив надлежащую скорость обучения.
Cверточная нейронная сеть и TensorFlow
CNN удобно продемонстрировать с помощью фреймворка Google TensorFlow и датасета с изображениями животных и транспорта (CIFAR-10). Нам понадобится библиотека TensorFlow Keras – это модуль для построения моделей глубинного обучения, matplotlib – это известнейшая библиотека для визуализации двумерной графики. Мы будем с вами использовать такие методы как figure(), show() и imshow(). Мы будем создавать области построения графика, отображать графики и преобразовывать набор пикселей в изображения.
Мы импортируем два набора датасетов – это тренировочный, на котором будет производиться непосредственно обучение и проверочный, валидационный. Грубо говоря, мы используем одну и ту же базу данных, разобьем ее на 2 части. Все изображения, которые мы будем использовать, любезно промаркированы для нейросети, которую мы будем обучать, поэтому мы используем train_labels.
Что же такое CIFAR-10? Канадский институт перспективных исследований любезно подготовил обширную базу данных из 60 тысяч изображений объектов 10 видов. Мы сможем натренировать нашу нейронную сеть с помощью нескольких тысяч изображений лошадей, грузовиков, оленей, птиц и так далее. На самом деле, изображения размечены числами, а не словами. Это сделано для того, чтобы проще было создавать языковые версии нейронных сетей. К примеру, все изображения категории «олень» могут быть обозначены цифрой 7. Наши изображения будут описаны в цветовой модели RGB, состоящей из трех чисел в диапазоне от 0 до 255. Все пиксели изображения и мы будем описывать цветовой моделью RGB, которая обозначает цвета с помощью сочетания 3 цифр в диапазоне от 0 до 255 включительно. Для тренировки нейронной сети мы нормализуем эти числа и разделим каждый из трех значений этой цветовой модели каждого пикселя на 255. В результате мы получим набор значений от нуля до единицы. Это называется Нормализация (Normalization). С такими данными и нейронной сети будет проще взаимодействовать. Обратите внимание: знак равенства один, а операций присвоения производится две.
Как я и говорила, категории у нас обозначены числами, но мы для удобства собственного восприятия обозначим их снова словами. Зададим холст и с помощью параметра figsize обозначим его размер. Для начала отобразим двадцать пять картинок из этого датасета. Нейросеть будет действовать как фильтр. Изучив все тренировочные данные, она сможет категоризировать все последующие изображения. Создадим цикл for и отобразим двадцать пять картинок. Каждое из изображение будет «подграфиком», то есть частью большого холста графика. Цифры 5 и 5 обозначают количество строк и столбцов на графике для подграфиков. Мы отключим отображение координат x и y, чтобы избежать перегрузки на глаза, иначе каждое из изображений будет размечено размерами. Мы также отключим сетку с помощью метода imshow() отобразим первые 25 тренировочных изображений.Мы задали псевдонимы для всех численных обозначений категорий изображений и теперь используем их для подписи на графике. Построим график.
Даже в таком скромном качестве вы легко распознаете птицу, лошадь, грузовик, автомобиль, лягушку. Представьте, что кто-то никогда не виделэти объекты. Как он узнает, что есть что икак он отличит, например, оленя от коня?Ведь у них у обоих бывают каурый окрас, есть копыта. Мы-то с вами их можем различить друг от друга, потому что многоповидали на своем веку. Так что загрузим в компьютер большую базу изображений, чтобы он тоже научился отличать эти предметы друг от друга. Эти изображения мы будем раскладывать на многомерные тензоры. Каждое из этих изображений мы представимкак последовательностьпикселей, описываемых с помощью нормализованной модели RGB.

Поскольку наше изображение размером 32 на 32 пикселя, то это будет 1024 пикселя 60 тысяч изображений. Для таких длинных последовательностей тензоров нам понадобится Keras. Этот высокоуровневый интерфейс как нельзя лучше подходит для подобных последовательностей. Мы будем использовать объект Sequential() этого API, который позволит нам привести данные к формату Keras. Создадим модель. используя метод Sequential() ,не принимающий аргументов, добавим модель слой свёрточной нейронной двумерной сети. Смотрите, как происходит добавление слоя. модель мы добавляем функции-фильтры, на самом деле их 128 в данном примере, которые будут вычислять собственные параметры автоматически на базе тренировочных изображений. Эти функции в конечном итоге будут производить категоризацию валидационных изображений, чтобы очистить тензоры от нецветовых значений, которые не удалось нормализовать, то есть привести к размеру от 0 до 255 и используется параметр reLU – это метод активации, который просто отсечёт часть тендзора, которая не является числом в диапазоне от нуля до единицы. Так мы получим набор только цветовых обозначений пикселов и с помощью параметра input_shape мы определяем, какого размера наше изображение, с помощью какой цветовой модели она обозначается. Для уменьшения объемов выходных данных мы будем использовать пулинг и метод MaxPooling2D() : так последовательно мы добавляем фильтр, на сей раз их 64; прочие параметры остаются теми же. И последний этап добавления функции фильтров, на сей раз их 128 с такими же параметрами активации.
Запросим сводку модели:
Пока числа не очень информативны; в ходе дальнейших преобразований мы увидим, как меняется число параметров каждого их 6 слоев.
Теперь преобразуем набор пикселей изображения размером 32 на 32 в двумерный массив, выстроим их как бы в ряд. В этом нам поможет метод Flatten() , не принимающий аргументов. К тому моменту как мы выстроили все пиксели изображения в одномерный массив, нейросеть содержит два полносвязных слоя. Каждый узел содержит оценку, указывающую вероятность принадлежностей изображений к одному из 10 классов.
Мы добавили полносвязные слои с таким же методом активации, снова изучим сводку.
Слои, добавленные на предыдущем этапе, остались неизменными; добавились уплощенный и плотные слои.
Количество параметров увеличилось. Соберем модель, для этого нам понадобится функция-оптимизатор и функция потери. Первое: поскольку нейросеть инициализируется со случайными значениями, то функция-оптимизатор переопределяет параметры тех самых 128 функций-фильтраторов, и с помощью функции потери измеряется точность распознавания тестовых изображений. Эй-ди-эй-эм (Adam) – это такой метод оптимизации, погружаться не будем в него. Параметр metrics позволит нам определить как часто нейронная сеть правильно категоризирует изображение относительно их настоящих Ярлыков (Label). Cоздадим объект history и скормим нейронной сети датасет учебных изображений в 10 этапов, чтобы улучшить точность. Мы условно делим этот процесс на 10 этапов, чтобы улучшить качество обучения.
Придется немного подождать:
Точность совсем низкая для начала, но она потом подрастет. Ура! Как вы видите, если параметры loss и accuracy характеризуют процесс обучения, то validation_loss и validaion_accuracy – потери и точность при проверке. Конечный результат – это 60 процентов точности, нормальный результат для первой попытки. Отобразим график, характеризующий скорость и качество обучения. Для этого мы метрику accuracy и вводили. Зададим название осей x и y, пограничные значения осей координат, чтобы график был более наглядным; легенду мы отправим вправо вниз. В топ-3 самых распространенных картинок, которая помогает понять нейронной сети, входит эта диаграмма со слоями.
Практика как всегда отличается от теории: точность при валидации существенно ниже:

Посмотрим, как изменилась точность классификации:
К счастью, эффективность модели подросла на целых 10%:
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Многоголовое внимание
Не так-то просто заставить работать внимание на скалярном произведении (dot product attention). Неудачная инициализация случайными значениями может дестабилизировать процесс обучения. С этим справляются, одновременно вычисляя внимание сразу несколькими «головами» (attention heads) и склеивая (конкатенируя) результаты (при этом у каждой «головы» свои обучающиеся веса):

где Qf’ 1 ,К к ’‘ ,V k, ‘ — обучаемые веса к -й «головы» внимания;
Q 1 — это проекция, чтобы размерности h’ +l и соответствовали по всем слоям.
В сущности, несколько «голов» позволяют механизму внимания «сделать сразу несколько ставок», давая возможность смотреть на разные преобразования или аспекты признаков с предыдущего слоя (рис. 11.8).
Рис. 11.8. Многоголовое внимание

Проблемы масштабирования и «подслой» прямого распространения.
Ключевая проблема, из-за которой архитектура трансформеров устроена именно так, как устроена, заключается в следующем. Значения признаков для каждого слова после применения механизма внимания могут быть очень разными по величине.
Во-первых. Это может быть из-за слишком «острых пиков» или, напротив, равномерности в распределении внимания.
Во-вторых. Для каждого слова необходимо склеить выходы нескольких голов, и они также могут быть очень разными по «масштабу». Поэтому в итоговом векторе разброс значения может быть большим. По принятым в машинном обучении практикам, здесь в цепочку вычислений есть смысл добавить нормализующий слой (normalization layer).
Проблему (2) трансформеры решают с помощью LayerNorm, который нормализует и выучивает аффинное преобразование на уровне признаков. Кроме того, деление внимания на скалярном произведении на квадратный корень из размерности помогает противодействовать проблеме (1).
Чтобы справиться с проблемой масштабирования, можно также значения на каждой позиции преобразовывают двухслойным перцептроном с особой структурой. После применения многоголового внимания они проецируют на (абсурдно) высокую размерность с помощью обучаемых весов, где затем происходит преобразование нелинейной функцией активации ReLU, а потом значения проецируют в исходную размерность, за которой происходит очередная нормализация: /z /+1 = LN^MLP^LN^ 1 ^ .
Так выглядит слой энкодера без упрощений (рис. 11.9).

Рис. 11.9. Слой энкодера
Входная матрица разбивается на три (Q, К, V), проходит через внимание, а результат (мы называли его Z) складывается со входной матрицей X и нормализуется через функцию LayerNorm: эта операция помогает быстрее тренировать нейросеть. Стрелка вокруг слоя внимания, ведущая к нормализации, называется residual connection, она есть в каждом слое энкодера и декодера. Она означает, что нормализуется не просто Z, a (Z + X). Нормализация появляется после каждого «внимания» и каждой нейросети с прямой связью и в энкодере, и в декодере. Вот иллюстрация, заглядывающая в нормализацию поглубже (рис. 11.10).

Рис. 11.10. Энкодер с позиционированием
На рисунке 11.10 перед слоем энкодера добавился новый элемент — позиционное кодирование. Оно не входит в энкодер, а производится до него.
Что такое многоголовая модель? А что такое голова в модели?
Единственное объяснение, которое я нашел до сих пор, это следующее: Каждую модель можно рассматривать как основу плюс голова, и если вы предварительно натренируете позвоночник и поставите случайную головку, вы можете точно настроить ее, и это хорошая идея.
Может кто-нибудь предоставить более подробное объяснение.
2 ответа
Вы нашли правильное объяснение. В зависимости от того, что вы хотите прогнозировать по своим данным, вам потребуется соответствующая магистральная сеть и определенное количество прогнозирующих головок .
Например, для базовой классификационной сети вы можете рассматривать ResNet, AlexNet, VGGNet, Inception, . как опорную сеть, а полностью подключенный уровень как единственную точку прогнозирования.
Хорошим примером проблемы, когда вам нужно несколько головок, является локализация, когда вы хотите не только классифицировать то, что находится на изображении, но также хотите локализовать объект (найти координаты ограничивающей рамки вокруг него).
На изображении ниже показана общая архитектура
Магистральная сеть («свертка и объединение») отвечает за извлечение карты характеристик из изображения, которое содержит обобщенную информацию более высокого уровня. Каждая голова использует эту карту характеристик в качестве входных данных для прогнозирования желаемого результата.
Потери, которые вы оптимизируете во время обучения, обычно представляют собой взвешенную сумму индивидуальных потерь для каждой прогнозируемой головы.
Максимальное объединение в сверточной нейронной сети (CNN)
Max Pooling помогает уменьшить карту признаков, чтобы сделать классификацию более точной. Давайте рассмотрим пример, чтобы лучше понять эту тему.
Пример. Рассмотрим изображение «гепард».

Вы можете снять видео с разных сторон разных «гепардов».

Но мы хотим, чтобы машина понимала таким же образом, то есть извлечение общего признака из уже извлеченной карты признаков, что помогает классифицировать данное животное как «гепарда».
Эта концепция известна как Максимальное объединение.
Как работает Max Pooling?
Предположим, есть карта признаков,
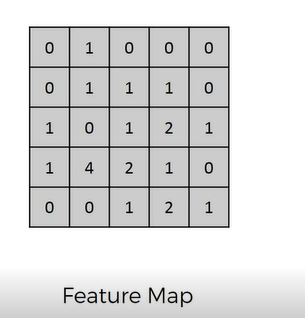
Теперь мы делаем объединение вышеуказанной функции.

Теперь сведем карту объектов в объединенную карту объектов. Составьте матрицу 2*2 и возьмите максимум из матрицы 2*2.

Опять же, сопоставление объединенной функции

Делайте это сопоставление до конца.

Заполните объединенную карту объектов до конца.

Теперь к каждой из карт объектов мы применяем максимальное объединение, чтобы получить объединенную карту объектов.

Таким образом, в реальном приложении мы пытаемся визуализировать, как объединение применяется в задней части сверточной нейронной сети (CNN)?.