Precision Boost Overdrive — что это в биосе? (PBO)
 Приветствую друзья. Разгон позволяет улучить производительность, однако не все знают как правильно разгонять.
Приветствую друзья. Разгон позволяет улучить производительность, однако не все знают как правильно разгонять.
Именно для таких людей компания AMD придумала собственную технологию авторазгона, главное чтобы пользователь не забыл о качественном охлаждении.
Precision Boost Overdrive — что это такое? (PBO)
PBO — сочетание стандартного разгона, при котором ускоряются все ядра, с возможностью повысить частоту на одном.
Алгоритмы PBO учитывают возможности конкретной платы по обеспечению питания процессора, тактовую частоту каждого ядра, энергопотребление и нагрев.
Впервые функция была представлена в Threadripper.
Данная функция обьединяет в себе две технологии — Precision Boost 2.0 и Extended Frequency Range 2.0, чтобы повышать производительность тогда, когда это нужно и настолько, насколько нужно. Для работа функции нужен процессор серии Ryzen X и материнка с чипсетом 400-той серии. Чипсет B350 тоже способен разгонять процессоры X-серии, но 400-тая серия с поддержкой PBO позволяет это делать куда эффективнее.
Чипсет X570 содержит более качественный VRM чем X470, поэтому разгонный потенциал выше.
Также стоит учитывать, что возможность использования функции зависит от версии AGESA.
Precision Boost Overdrive активируется также в фирменной утилите Ryzen Master.
Однако для полноценной работы функции необходимо хорошее охлаждение, желательно водяное.
Функция для процов 3000 серии может накинуть сверху 200 МГц по сравнению с тем, что написано на коробке.
Опция в биосе
Обычно присутствует в разделе AMD CBS, присутствует ручной режим Manual:

Ручной режим стоит использовать только, когда вы понимаете что делаете. По поводу лимитов нашел информацию:

По поводу этого режима. Как я понимаю — каждая строка позволяет вручную выставить ограничения. 1000 означает без ограничений.
Оказывается PBO можно использовать и в обратную сторону, например чтобы снизить потребление/нагрев процессора. Например взять процессор AMD Ryzen 9 3900X, если при ручной настройке в PPT выставить 61, то тепловыделение процессора снизиться до 45 Ватт. Формула по вычислению TPD примерно такая: желаемое TDP * 1.35 = получаем значение для PPT. Минимально значение PPT — 44, что соответствует 32,5 Ватт.
Да, конечно ограничение TDP повлияет на тактовые частоты, однако скорее всего частота одного или двух ядер при максимальной нагрузке будет близкой к исходной. Но если нагрузить все ядра, то частота уже будет низкой и примерно соответствовать TDP. Таким образом при желании вы можете собрать тихую и мощную систему даже с топовым процессором (правда смысла особого нет брать топ проц чтобы потом его урезать).
Функция PBO ориентирована исключительно на разгон. Она не включена по умолчанию, активация функции приводит к прекращению гарантии, как и разгон вручную. Автоматический разгон представляет собой аналог ручного разгона в определенных рамках.
В качестве примера AMD указывает процессор Ryzen, который работает на 4,55 ГГц с помощью Precision Boost. Через автоматический разгон частоту можно увеличить еще на 200 МГц до 4,75 ГГц (что очень даже неплохо).
Amd pbs что это в биосе
Precision Boost Overdrive — что это в биосе? (PBO)
Приветствую друзья. Разгон позволяет улучить производительность, однако не все знают как правильно разгонять.
Именно для таких людей компания AMD придумала собственную технологию авторазгона, главное чтобы пользователь не забыл о качественном охлаждении.
Precision Boost Overdrive — что это такое? (PBO)
PBO — сочетание стандартного разгона, при котором ускоряются все ядра, с возможностью повысить частоту на одном.
Алгоритмы PBO учитывают возможности конкретной платы по обеспечению питания процессора, тактовую частоту каждого ядра, энергопотребление и нагрев.
Впервые функция была представлена в Threadripper.
Данная функция обьединяет в себе две технологии — Precision Boost 2.0 и Extended Frequency Range 2.0, чтобы повышать производительность тогда, когда это нужно и настолько, насколько нужно. Для работа функции нужен процессор серии Ryzen X и материнка с чипсетом 400-той серии. Чипсет B350 тоже способен разгонять процессоры X-серии, но 400-тая серия с поддержкой PBO позволяет это делать куда эффективнее.
Чипсет X570 содержит более качественный VRM чем X470, поэтому разгонный потенциал выше.
Также стоит учитывать, что возможность использования функции зависит от версии AGESA.
Precision Boost Overdrive активируется также в фирменной утилите Ryzen Master.
Однако для полноценной работы функции необходимо хорошее охлаждение, желательно водяное.
Функция для процов 3000 серии может накинуть сверху 200 МГц по сравнению с тем, что написано на коробке.
Опция в биосе
Обычно присутствует в разделе AMD CBS, присутствует ручной режим Manual:
Ручной режим стоит использовать только, когда вы понимаете что делаете. По поводу лимитов нашел информацию:
По поводу этого режима. Как я понимаю — каждая строка позволяет вручную выставить ограничения. 1000 означает без ограничений.
Оказывается PBO можно использовать и в обратную сторону, например чтобы снизить потребление/нагрев процессора. Например взять процессор AMD Ryzen 9 3900X, если при ручной настройке в PPT выставить 61, то тепловыделение процессора снизиться до 45 Ватт. Формула по вычислению TPD примерно такая: желаемое TDP * 1.35 = получаем значение для PPT. Минимально значение PPT — 44, что соответствует 32,5 Ватт.
Да, конечно ограничение TDP повлияет на тактовые частоты, однако скорее всего частота одного или двух ядер при максимальной нагрузке будет близкой к исходной. Но если нагрузить все ядра, то частота уже будет низкой и примерно соответствовать TDP. Таким образом при желании вы можете собрать тихую и мощную систему даже с топовым процессором (правда смысла особого нет брать топ проц чтобы потом его урезать).
Функция PBO ориентирована исключительно на разгон. Она не включена по умолчанию, активация функции приводит к прекращению гарантии, как и разгон вручную. Автоматический разгон представляет собой аналог ручного разгона в определенных рамках.
В качестве примера AMD указывает процессор Ryzen, который работает на 4,55 ГГц с помощью Precision Boost. Через автоматический разгон частоту можно увеличить еще на 200 МГц до 4,75 ГГц (что очень даже неплохо).
ASRock
Мы используем «cookies» только для улучшения просмотра сайта. Просматривая этот сайт, вы соглашаетесь на использование наших «cookies». Если вы не хотите использовать «cookies» или хотите узнать об этом подробнее, ознакомьтесь с нашей Политикой приватности.
Вопросы-Ответы
Выберете одну из следующих категорий, если вы знаете, к какой из них относится ваш вопрос:
Результаты:
O:Следуйте этой инструкции: 
1. Зайдите в настройки BIOS
2. Выберите в качестве основого видеоадаптера встроенную графику
Путь: Advanced\AMD PBS\Primary Video Adapter\Int Graphics (IGD) 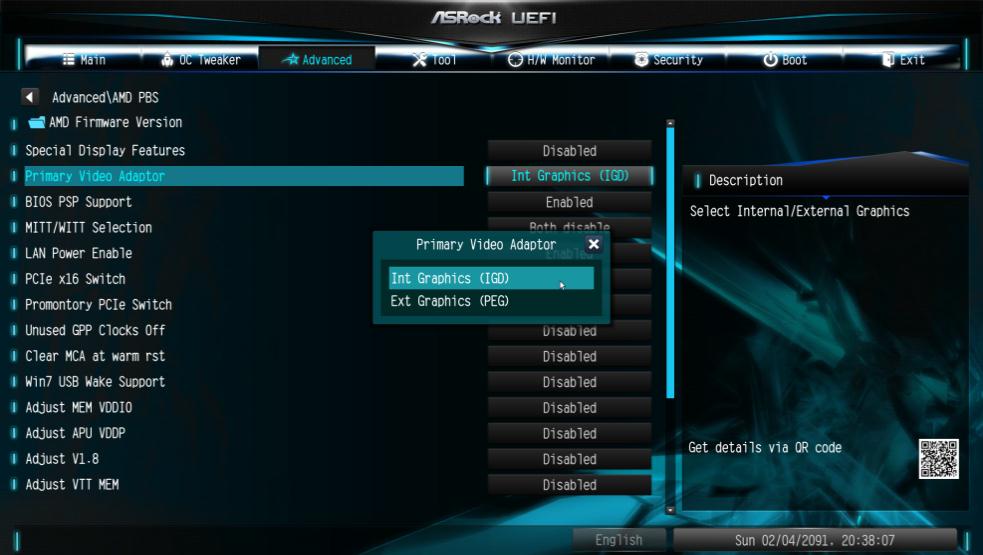
Нажмите «F10” для сохранения настроек.
Или попробуйте другой метод:
1. Зайдите в настройки BIOS
2. Отключите CSM
Path: Boot/CSM/Disable 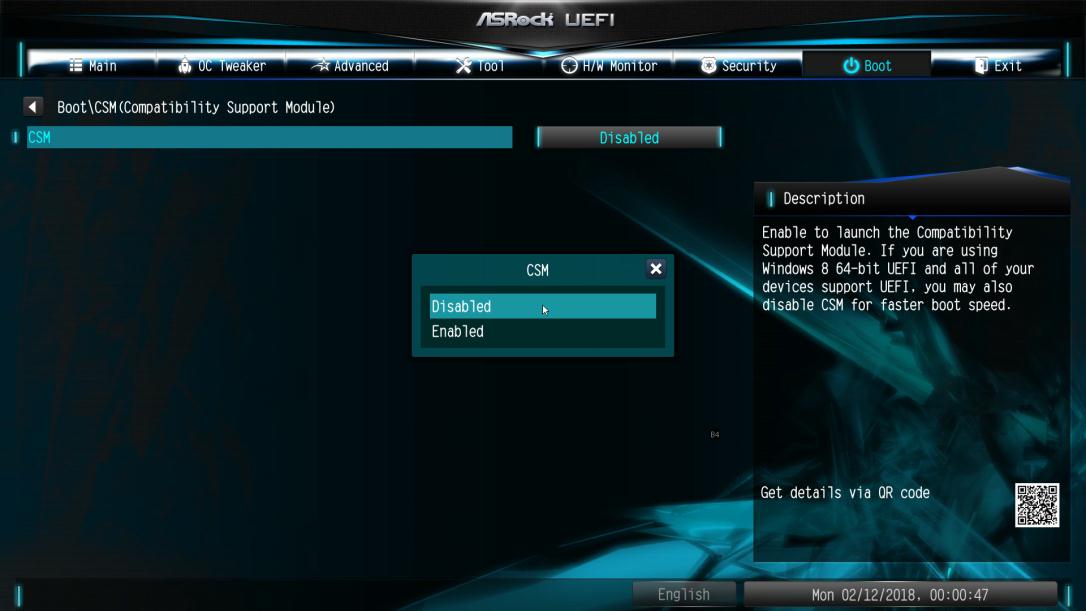
В BIOS процессоров AMD Ryzen 3000 Zen 2 замечены новые опции для разгона
В этом году AMD планирует выпустить процессоры Ryzen 3000 3 поколения, возможно рассказав о них больше в середине года на Computex 2019. Компания пообещала, что процессоры будут идти на сокете AM4 и будут полностью совместимы с вышедшими ранее материнскими платами с этим сокетом. После этих заявлений, производители плат, ASUS и MSI, выпустили обновления BIOS, в которых добавлена поддержка инженерных образцов чипов Zen 2.

На выставке CES 2019 AMD рассказала о технических характеристиках процессоров и показала прототип нового процессора Ryzen 3 поколения на сокете AM4. Компания подтвердила, что процессоры будут созданы по мультичиповой технологии, что означает, что процессор будет состоять из двух 7-нм чиплетов, которые будут работать на 14-нм I/O-хабе через Infinity Fabric.
Есть две причины по которой AMD решила делать процессоры мультичиповыми. Во-первых, это позволяет компании использовать две разные технологии производства для создания одного процессора. В AMD рассчитали, что дешевле будет делать 7-нм лишь те части процессоров, которые получат нехилый прирост производительности от такого уменьшения — к примеру, ядра. Создавать остальные 14-нм части процессоров намного дешевле, так как технология производства довольно старая, а следовательно — дешевая. 14-нм I/O хабы, в теории, компании может предоставить ее партнер — GlobalFoundries.
Второй причиной является проводимая AMD политика уменьшения затрат на производство. Компания планирует увеличить количество ядер в процессорах до цифры выше восьми, а ставить 12-16 ядер на один 7-нм чиплет невыгодно. Для процессоров с 8 ядрами или меньше (которые, кстати говоря, очень хорошо продаются) можно использовать как раз один чиплет. Так AMD не будет использовать свои ценные 7-нм пластины зазря.
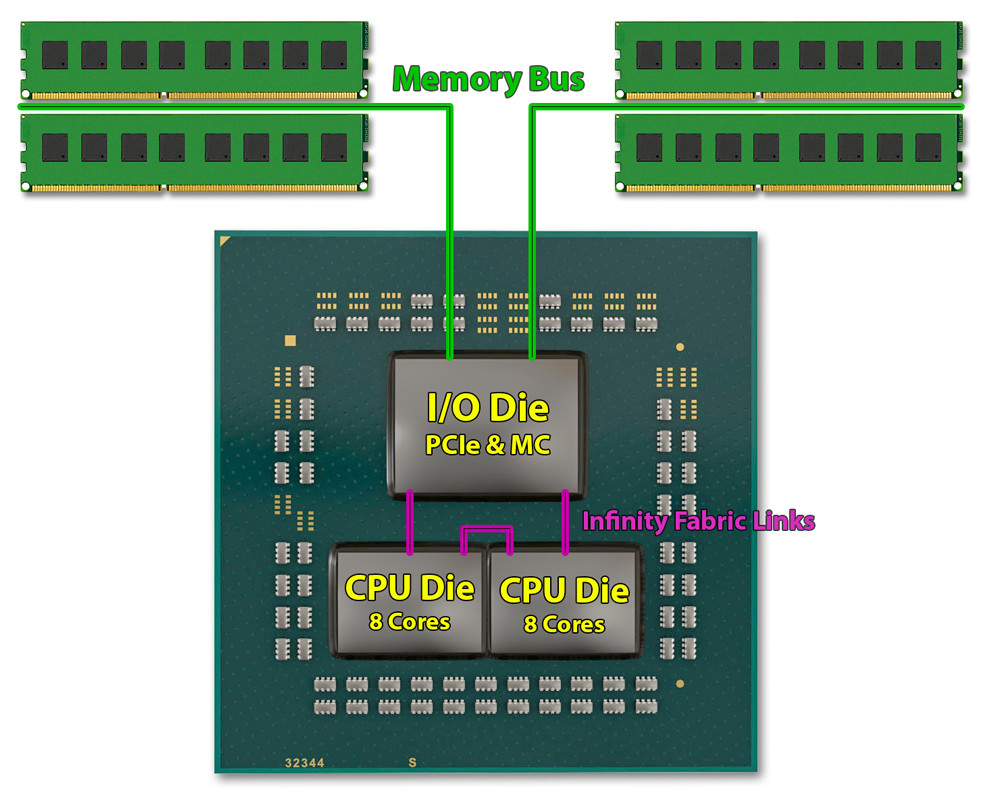
Главный минус этого метода заключается в том, что контроллер памяти физически не интегрирован в ядра процессора, в результате чего компании приходится использовать «интегрированно-дискретный» контроллер. Он расположен внутри процессора, но уже не на ядрах. AMD — не первая компания, кто провел такие хитрые манипуляции. Первое поколение процессоров Clarkdale от Intel было чем-то похожим — в них были раздельно работали ядра процессора и контроллер памяти с интегрированным графическим чипом.
«Промежуточным звеном» у Intel был революционный по тем временам интерфейс Quick Pack Interconnect. В процессорах AMD линеек Zen и Vega используется интерфейс Infinity Fabric с высокой пропускной способностью. А в новой серии процессоров Matisse будет использоваться новая версия Infinity Fabric с повышенной в два раза пропускной способностью — до 100 ГБ/с. Это нововведение — необходимость, так как каждый I/O хаб должен будет работать с двумя 8-ядерными платами, а в случае с серверными процессорами EPYC — с 64 ядрами.
Мы решили подробнее рассмотреть ранее упомянутое новое обновление BIOS. В нем мы нашли несколько новых настроек, которые будут эксклюзивны для процессоров Matisse и, возможно, для процессоров Threadripper. Раздел CBS был переименован с «Zen Common Options» на «Valhalla Common Options». Мы довольно часто слышали «Valhalla» и «Zen 2» в одном предложении, поэтому справедливо будет предположить, что это — платформа, на которой работает процессор Matisse на сокете AM4 и материнская плата на чипсете 500 серии.
Во время серьезных тестирований разгона памяти, Infinity Fabric может не справляться с увеличенной частотой памяти. Все это потому, что Infinity Fabric работает на частоте вашей памяти. Например, при использовании памяти DDR-3200 (которая работает на частоте 1600 МГц), Infinity Fabric будет именно на ее частоте — 1600 МГц. Так было у Zen и Zen+ и останется у Zen 2. В новом BIOS также появились опции новые UCLK: «Авто», «UCLK==MEMCLK» и «UCLK==MEMCLK/2». Последние две ориентированы на стабильный разгон памяти ценой снижения пропускной способности Infinity Fabric.
Функция Precision Boost Overdrive также получит небольшое обновление, благодаря которому у нее появится больше опций. AMD добавила еще одну функция — Core Watchdog, которая перезагружает систему при обнаружении ошибок, которые могли бы дестабилизировать работу компьютера.
У пользователей процессоров Matisse появится улучшенный контроль над активными ядрами. Теперь можно будет отключить целый чиплет или уменьшить количество активных ядер. У 64-ядерных процессоров Threadripper можно будет отключать до 6 из 8 чиплетов.
Самую интересную функцию мы оставили напоследок — теперь можно переключить используемое поколение PCI-Express, вплоть до четвертого. Это значит, что некоторые материнские платы с чипсетом 400 серии могут получить поддержку PCI-Express поколения 4.0 (мы рассматривали именно такую плату). Но есть небольшая загвоздка — плату придется перепрограммировать, используя сторонние инструменты. В среднем на «обновление» должно уйти примерно 15-20$.
Одна из страниц BIOS названа «SoC Miscellaneous Control» и на ней расположены довольно уже довольно стандартные для современных материнских плат настройки:
- DRAM Address Command Parity Retry
- Max Parity Error Replay
- Write CRC Enable
- DRAM Write CRC Enable and Retry Limit
- Max Write CRC Error Replay
- Disable Memory Error Injection
- DRAM UECC Retry
- ACPI Settings:
- ACPI SRAT L3 Cache As NUMA Domain
- ACPI SLIT Distance Control
- ACPI SLIT remote relative distance
- ACPI SLIT virtual distance
- ACPI SLIT same socket distance
- ACPI SLIT remote socket distance
- ACPI SLIT local SLink distance
- ACPI SLIT remote SLink distance
- ACPI SLIT local inter-SLink distance
- ACPI SLIT remote inter-SLink distance
В целом, можно сказать, что AMD дала любителям разгона множество новых опций, позволяющих разогнать не только сам процессор, но и отдельные его части.
О безопасности UEFI, часть заключительная
 Вот и подошел к концу мой опус о безопасности UEFI. В этой заключительной части осталось поговорить о перспективных технологиях и планах на будущее, да пообщаться с читателями в комментариях.
Вот и подошел к концу мой опус о безопасности UEFI. В этой заключительной части осталось поговорить о перспективных технологиях и планах на будущее, да пообщаться с читателями в комментариях.Если вам интересно, чем безопасности прошивки могут помочь STM , SGX и PSP — жду вас под катом.
Желая показать бунтарский дух и наплевательство на традиции, ссылки на предыдущие части не даю — сами ищите их там.
Часть седьмая. Технологии будущего
Несмотря на то, что все описываемые далее технологии уже давно представлены официально, рассказывать о них я все равно буду как о возможностях завтрашнего дня, по весьма прозаической причине — даже в такой быстроразвивающейся среде как UEFI от представления какой-то технологии до ее внедрения могут пройти годы (достаточно вспомнить PFAT , появившуюся еще в Haswell, но не внедренную толком до сих пор).
Про SGX и STM я уже упоминал в конце третьей части, поэтому начну рассказ с PSP, которым теперь без вариантов комплектуются все новые AMD APU.
AMD Platform Security Processor
Наблюдая за успехами Intel Management Engine, которым последние 5 лет оборудован каждый чипсет и SoC Intel, в AMD тоже решили не отставать от прогресса и встроить в свои SoC’и чего-нибудь эдакого.
Еще бы — хочется иметь аппаратный корень доверия, хочется нормальный генератор случайных чисел, хочется криптоускоритель и эмулятор TPM 2.0, в общем — много всего хочется, и реализовать это все не трудно — купи IP Core у какого-нибудь поставщика, напиши к нему прошивку и навесь на него побольше системных функций, чтобы пользователь твоей платформы даже не вздумал отключить то, за что столько денег уплочено.
В итоге в качестве IP Core купили ядро ARM Cortex-A5 с поддержкой технологии TrustZone, для эмуляции TPM 2.0 приобрели у Trustonic код TEE , остальное реализовали сами и представили получившийся SoC-внутри-SoC’а в 2013 году на очередном UEFI Plugfest.

Оригинальная схема PSP, про эмуляцию TPM речи тогда еще не шло.Для обеспечения безопасности UEFI этот самый PSP предоставляет следующее: подсистему HVB, внутреннее хранилище для S3 BootScript, эмулятор TPM для реализации Measured Boot, генератор случайных чисел и ускоритель криптографических операций.
Hardware Validated Boot
Про эту технологию я уже рассказывал в первой части, теперь расскажу более подробно. Суть ее простая — PSP получает управление до старта BSP и проверяет, чтобы содержимое второй стадии его прошивки и стартового кода не было изменено, в случае успеха BSP стартует с ResetVector’а и машина загружается как обычно, а в случае неудачи пользователю показывают код ошибки на POST-кодере, а BSP крутит мертвый цикл до hard reset’а, после которого все повторяется заново.
HVB, таким образом, является аппаратным корнем доверия для системы, но защищает эта технология только PEI-том, проверка же всего остального — на совести авторов прошивки.

Оригинальная схема AMD HVBПо умолчанию HVB отключен на всех платформах и для включения необходима достаточно нетривиальное его конфигурирование, поэтому я пока и сам не испытывал технологию на практике (хотя непосредственно работаю с прошивками для второго поколения процессоров с PSP), и машин с включенным HVB на открытом рынке не видел.
Integrated TPM 2.0
К релизу Windows 10 рабочая группа TCG подготовила интересное нововведение: вместо использовавшегося ранее интерфейса TIS для взаимодействия с модулями TPM теперь можно использовать вызовы ACPI, что позволяет производителям процессоров реализовать TPM не на внешнем чипе, а прямо в чипсете, да еще и половину реализации сделать программной. Такое решение имеет как преимущества (заменить чипсет сложнее, чем чип TPM в корпусе SSOP-28), так и недостатки (vendor lock-in), но реализовали его на данный момент и Intel (в Skylake) и AMD (в APU с PSP). Стандарт TPM 2.0 поддерживается обоими решениями не целиком, а только настолько, чтобы система со встроенным TPM могла использовать BitLocker и получить сертификат Windows 10 Ready. Тем не менее, теперь полку пользователей TPM однозначно прибудет. Вместе с встроенным TPM появились также аппаратный ГСЧ и криптоускоритель, которые, при желании, можно использовать отдельно.
Secure S3 BootScript Storage
Еще одна фишка PSP — встроенный NVRAM, в котором можно безопасно хранить какие-то пользовательские данные. На данный момент AMD сохраняет туда S3 BootScript, что хорошо защищает систему от атак на него. При этом немного страдает время выхода из S3, но лишние 50-100 мс ради безопасности вполне можно терпеть.
К сожалению, у AMD с открытой документацией на PSP очень грустно, поэтому дать полезных ссылок не могу, все, что мог рассказать без нарушения NDA — уже рассказал.
Intel Software Guard Extensions
Вернемся теперь к технологиям Intel. Об SGX начали говорить около года назад, но для конечного пользователя она стала доступна всего несколько недель назад, когда Intel включила ее для процессоров Skylake в очередном обновлении микрокода. SGX — это новый набор инструкций, позволяющих приложениям создавать т.н. «анклавы», т.е. регионы памяти для кода и данных, аппаратно защищенные от доступа извне, даже если этот доступ производится из более привилегированных режимов исполнения вроде ring 0 и SMM.
Технология достаточно сложная для понимания и использования (почти 200 страниц Programming Reference), но потенциально очень мощная, поэтому Intel начала заниматься ее продвижением.

Принципиальная схема работы SGX, один из более 200 слайдов вот этой презентации, она же в виде 80-минутного видео.Intel называет SGX «обратной песочницей», т.е вместо того, чтобы пытаться изолировать потенциально вредоносное или недоверенное ПО, при помощи SGX программа может изолировать себя от всего остального мира. Идея сходна с ARM TrustZone, но если у ARM мир делится на обычный и доверенный и они выполняются на разных ядрах, взаимодействуя только через вызов инструкции SMC , то у Intel ядро одно и то же, зато память делится обычную и безопасную:

Безопасный анклав посреди обычной памяти.Мое отношение к этой технологии пока еще не сформировалось — я ее просто еще не пробовал, т.к. не работаю над Skylake в данный момент. Тем не менее, стараюсь не отставать от прогресса слишком уж сильно, поэтому читаю краем уха все, что пишут про SGX, к примеру:
Портал об SGX на сайте Intel.
Обзорная лекция об SGX с сайта Дармштадтского Технического Университета.
Обзорная статья NccGroup с кучей интересных ссылок.
Открытая платформа для написания своего кода для SGX.
И вообще, весь раздел про SGX на firmwaresecury.com.Intel SMI Transfer Monitor
Вторая технология Intel, о которой я уже упоминал — STM. Первые упоминания о нем датированы 2009 годом, и после 6 лет разработки технология наконец-то была представлена в августе 2015. Суть ее простая: вместо диспетчера SMM в SMRAM запускается гипервизор, и все обработчики SMI выполняются в виртуализованном окружении, что позволяет запретить им вредоносные действия вроде изменения данных в памяти ядра и тому подобные.

Слайд из презентации STM на IDF2015.Технология позволяет значительно уменьшить как «поверхность атаки» на обработчики SMM, так и разрушительность последствий взлома обработчиков SMI. К примеру, запретив доступ к MMIO чипсета для всех обработчиков, кроме используемого для обновления прошивки, можно защитить ее от остальных обработчиков, путь даже они взломаны атакующим и он имеет возможность выполнить в них произвольный код.
Самое главное преимущество — неприхотливость, для работы STM нужны только включенные VT-x/AMDV и правильные настройки уровней доступа. На данный момент предварительная поддержка STM реализована в EDK2 только для тестовой платы MinnowBoard Max, но в ближайшие полгода-год IBV адаптируют ее для своих платформ, и взлома SMM можно будет опасаться гораздо меньше. Понятно, что бесплатной безопасности не бывает, и STM вносит дополнительную сложность в итак не самый простой процесс инициализации SMM, плюс обработка SMI занимает больше времени (страшнее, на самом деле, то, что оно занимает еще более неопределенное время, опять страдают пользователи жестких ОСРВ), плюс виртуализацию незнающий пользователь платформы может отключить и STM не получится использовать в таких условиях. Тем не менее, я потыкал в STM веткой на MinnowBoard и могу сказать: чем скорее IBV внедрят её — тем лучше.Заключение
Ну вот и подошел к концу этот цикл статей, надеюсь читателю было интересно.
Технологии развиваются быстро, и если завтра появится какая-то прорывная технология (или найдут зияющую дыру в существующих) — постараюсь о них написать.В следующей статье будем укрощать SecureBoot — сгенерируем свои ключ PK и KEK, а параноики смогут запретить загрузку любых вещей, не подписанных их ключами. Спасибо за внимание.
Зачем нужна технология ASUS PBO Enhancement (Precision Boost Overdrive) и как активировать ее в UEFI BIOS?

Процессоры AMD Ryzen серии 7000 динамически используют доступный тепловой запас для достижения высоких тактовых частот. В материнских платах ASUS есть специальная опция PBO Enhancement, упрощающая поиск баланса между температурой и производительностью CPU. Она создана для того, чтобы быстро (буквально двумя кликами мыши) снизить температуру камня, повысить вычислительную мощность ЦП и уменьшить уровень шума вентилятора. Напоминаем, что встроенная в процессоры Ryzen 7000 система защиты автоматически ограничивает максимальную температуру CPU (95 градусов).
PBO Enhancement не только устанавливает предел температуры, но и активирует оптимизацию напряжения.
Для ручной оптимизации рабочих показателей с помощью опции PBO Enhancement необходимо в первую очередь обновить BIOS материнской платы.
С технологией совместимы практически все устройства от ASUS на базе чипсетов X670 и B650 (в планах добавить поддержку и в решения, основой которых являются наборы логики X670E, X670, B650E и B650).
Список совместимых с функцией PBO Enhancement материнских плат:
- ROG Crosshair X670E Extreme
- ROG Crosshair X670E Hero
- ROG Crosshair X670E Gene
- ROG Strix X670E-E Gaming WiFi
- ROG Strix X670E-F Gaming WiFi
- ROG Strix X670E-A Gaming WiFi
- ROG Strix X670E-I Gaming WiFi
- ProArt X670E-Creator WiFi
- TUF Gaming X670E-Plus WiFi
- TUF Gaming X670E-Plus
- Prime X760E-Pro WiFi
- Prime X670-P WiFi
- Prime X670-P
- ROG Strix B650E-E Gaming WiFi
- ROG Strix B650E-F Gaming WiFi
- ROG Strix B650-A Gaming WiFi
- ROG Strix B650E-I Gaming WiFi
- ProArt B650-Creator
- TUF Gaming B650-Plus WiFi
- TUF Gaming B650-Plus
- TUF Gaming B650M-Plus WiFi
- TUF Gaming B650M-Plus
- Prime B650-Plus
- Prime B650M-A AX
- Prime B650M-A WiFi
- Prime B650M-A
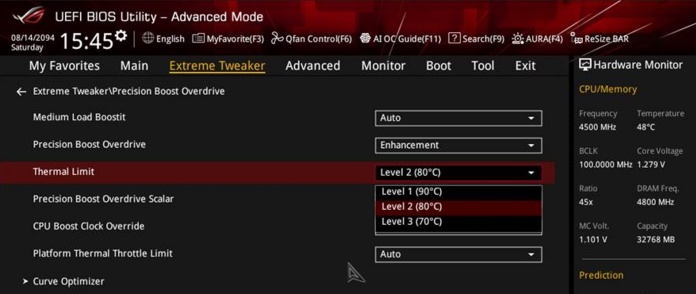
После обновления прошивки заходим в UEFI BIOS и переключаемся на вкладку расширенных настроек (Extreme Tweaker, пункт Precision Boost Overdrive). В профильном пункте выбираем «Enhancement» и в выпадающем списке отдаем предпочтение одному из трех вариантов:
- Level 1 установит максимальную целевую температуру на уровне 90°
- Level 2 установит максимальную целевую температуру на уровне 80°
- Level 3 установит максимальную целевую температуру на уровне 70°
Как изменится производительность процессора после активации PBO Enhancement?
Это зависит от нескольких факторов. В первую очередь на результаты влияет модель CPU и материнской платы, а также система охлаждения и температура окружающей среды.
Чтобы дать вам представление о том, чего ожидать от PBO Enhancement, мы провели тестирование четырех разных процессоров AMD Ryzen. Каждый чип тестировался с использованием 280 мм СВО AIO. Мы также протестировали каждый чип с настройками PBO по умолчанию.
Начнем с AMD Ryzen 9 7950X. В номинале он набирает 37811 баллов в Cinebench R23. Активация PBO Enhancement Level 1 снижает температуру на 5° и увеличивает производительность CPU. Как такое возможно? Это связано с тем, что PBO Enhancement не только устанавливает предел температуры, но и активирует оптимизацию напряжения.
Установка PBO Enhancement на Level 3 снижает производительность камня всего на 3,5%, при этом максимальная температура снижается аж на 25 градусов. На такой компромисс почти наверняка пойдут многие энтузиасты.
Преимущества PBO Enhancement более очевидны, если вы используете AMD Ryzen 5 7600X. Установка PBO Enhancement на Level 3 снижает температуру ЦП на 20° и никак не влияет на производительность.
Amd pbs что это в биосе
Мы используем «cookies» только для улучшения просмотра сайта. Просматривая этот сайт, вы соглашаетесь на использование наших «cookies». Если вы не хотите использовать «cookies» или хотите узнать об этом подробнее, ознакомьтесь с нашей Политикой приватности.
Вопросы-Ответы
Выберете одну из следующих категорий, если вы знаете, к какой из них относится ваш вопрос:
Результаты:
O:Следуйте этой инструкции:
1. Зайдите в настройки BIOS
2. Выберите в качестве основого видеоадаптера встроенную графику
Путь: Advanced\AMD PBS\Primary Video Adapter\Int Graphics (IGD)Нажмите «F10” для сохранения настроек.
Или попробуйте другой метод:
1. Зайдите в настройки BIOS
2. Отключите CSM
Path: Boot/CSM/DisableAmd pbs что это в биосе
В BIOS процессоров AMD Ryzen 3000 Zen 2 замечены новые опции для разгона
В этом году AMD планирует выпустить процессоры Ryzen 3000 3 поколения, возможно рассказав о них больше в середине года на Computex 2019. Компания пообещала, что процессоры будут идти на сокете AM4 и будут полностью совместимы с вышедшими ранее материнскими платами с этим сокетом. После этих заявлений, производители плат, ASUS и MSI, выпустили обновления BIOS, в которых добавлена поддержка инженерных образцов чипов Zen 2.
На выставке CES 2019 AMD рассказала о технических характеристиках процессоров и показала прототип нового процессора Ryzen 3 поколения на сокете AM4. Компания подтвердила, что процессоры будут созданы по мультичиповой технологии, что означает, что процессор будет состоять из двух 7-нм чиплетов, которые будут работать на 14-нм I/O-хабе через Infinity Fabric.
Второй причиной является проводимая AMD политика уменьшения затрат на производство. Компания планирует увеличить количество ядер в процессорах до цифры выше восьми, а ставить 12-16 ядер на один 7-нм чиплет невыгодно. Для процессоров с 8 ядрами или меньше (которые, кстати говоря, очень хорошо продаются) можно использовать как раз один чиплет. Так AMD не будет использовать свои ценные 7-нм пластины зазря.
У пользователей процессоров Matisse появится улучшенный контроль над активными ядрами. Теперь можно будет отключить целый чиплет или уменьшить количество активных ядер. У 64-ядерных процессоров Threadripper можно будет отключать до 6 из 8 чиплетов.
Одна из страниц BIOS названа «SoC Miscellaneous Control» и на ней расположены довольно уже довольно стандартные для современных материнских плат настройки:
В целом, можно сказать, что AMD дала любителям разгона множество новых опций, позволяющих разогнать не только сам процессор, но и отдельные его части.
Улучшаем Boost процессоров AMD микроархитектуры Zen 2. Community Update #2: Let’s Talk от 1usmus
В этой статье я поделюсь с вами индивидуальным планом электропитания для Windows, который должен оказать существенное влияние на поведение boost процессоров Ryzen 3-го поколения, способность использовать предпочтительные ядра, что даст в итоге более высокие частоты, чем вы имеете сейчас (разумеется, если вы испытываете проблему), а так же улучшит фреймрейт-динамику в играх.

Процессоры AMD 3-го поколения Ryzen являются самыми передовыми настольными процессорами на рынке, которые вы можете купить. Также эти процессоры являются уникальными из-за технологии CPPC2 (Collaborative Power and Performance Control 2), которая является интерфейсом-посредником для управления питанием и частотой между процессором и операционной системой. Цифра 2 означает, что это взаимодействие существенно возросло и составляет 1 мс, а не 15 мс как было раньше. Теперь процессор гораздо быстрее реагирует на ту или иную нагрузку и тем самым более тонко настраивает частоту, чтобы система имела максимальную энергоэффективность.
В прошлом я уже писал другие материалы, связанные с архитектурой Zen 2 и оптимизацией памяти Ryzen. Сегодня я представляю вам «1usmus Ryzen Universal» для процессоров Ryzen 3-го поколения. Это измения взаимодействия планировщика Windows и процессора в зависимости от запросов производительности. Этот план питания должен быть особенно полезен для пользователей чипов серии Ryzen 9, таких как Ryzen 9 3900X, Ryzen 9 3950X и, конечно же, Ryzen Threadripper 3-го поколения на сокете TRX4. Разумеется, это актуально для пользователей всей линейки процессоров, основанных на архитектуре Zen 2.
Предпосылки
В отличие от приложений для бенчмаркинга, которые порождают кучу одинаковых потоков, выполняющих одинаковый код на различных фрагментах данных, современные игры очень разнородны. Каждый поток выполняет свой собственный код, который полностью отличается от других потоков и работает с данными в разном количестве, генерируя нагрузки, которые различаются между потоками. Данные, создаваемые одним потоком, часто используются другим, что приводит к задержкам и может даже передавать свои данные другому ожидающему потоку. Также существует концепция «пула потоков», где каждый рабочий поток выбирает любое задание любого типа, работающее с любыми данными, независимо от того, что готово для запуска. Это означает, что поток данных совершенно хаотичен, что генерирует много трафика между CCX, когда некоторые потоки находятся на одном CCX, а другие — на другом.
Это поведение дополнительно усиливается современными графическими API, такими как DirectX 12 и Vulkan, которые поощряют подачу команд рендеринга многопоточным способом. Возможно, вы заметили, как некоторые игры демонстрируют снижение производительности на Ryzen (по сравнению с Intel), когда используется более новый Vulkan или DX12 API. Windows любит балансировать загрузку ЦП между несколькими ядрами, перемещая потоки из занятых ядер в свободные. Это нормальное, ожидаемое поведение для современного планировщика процессов с поддержкой SMP, но Windows на самом деле довольно глупа.
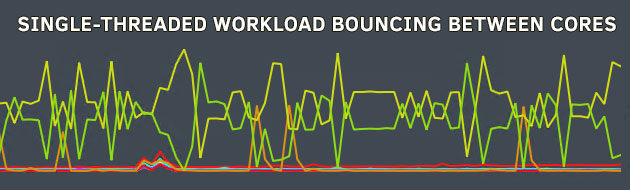
Windows считает ядро «занятым», даже если его использует только один поток, и перемещает этот же поток в свободное ядро, если оно доступно! Кроме того, планировщик процессов Windows не делает различий между физическим и виртуальным ядрами, а также между CCX с их отдельными кэшами. В сравнительно недавних версиях Windows (по крайней мере, начиная с Windows 7) эта тенденция к миграции сдерживается системой «базовой парковки». Если ядро припарковано, планировщик процессов не переносит в него потоки, что позволяет ему переходить в состояние глубокого простоя для экономии энергии. Кроме того, алгоритм парковки ядра отвечает за поддержание выключения второго виртуального ядра каждого физического ядра с поддержкой HT/SMT, если это не требуется, что максимизирует производительность на поток в сценариях с легкой многопоточностью.
Просто для пояснения: планировщик Windows не поддерживает SMT, только алгоритм парковки ядра осведомлен о SMT. Почему это важно? Потому что в режиме высокой производительности система основной парковки отключена. Каждое отдельное ядро отключено, и поэтому планировщик процессов весело мигрирует потоки через каждое физическое и виртуальное ядро в системе (если все ядра не заняты, например, многопоточной рабочей нагрузкой). Это означает, что даже однопоточная рабочая нагрузка заканчивается перемещением между CCX или даже CCD, и ей приходится перетаскивать все данные, с которыми она работает, за ним, примерно в среднем каждые 5–40 миллисекунд в зависимости от используемого SMU и сборки ОС. В игре умножьте это на количество эффективных потоков, которые игра запускает и в результате вы получите фризы или низкий 1% фреймрейт. Не только это, но и потоки разделяют физическое ядро гораздо чаще. Linux справляется с этим гораздо лучше: он активно предпочитает хранить потоки на одном и том же ядре до тех пор, пока на этом ядре нет конфликтов планирования. Таким образом, однопоточная рабочая нагрузка в Linux обычно будет оставаться на одном и том же ядре в течение нескольких секунд, если не дольше. Это не только позволяет избежать накладных расходов при миграции потока, но также позволяет избежать пропусков кэша и трафика между CCX, который может возникнуть в результате такой миграции. Такое поведение не является специфичным для Ryzen, но было стандартным на всех компьютерах SMP/SMT/CMT, работающих под управлением Linux, в течение нескольких лет.
Неделю назад Microsoft выпустила обновление для Windows 10 (1909), которое дает планировщику ОС возможность определять приоритеты потоков. Я протестировал предварительную сборку этой версии и не заметил значительных улучшений. Довольно часто планировщик использовал более высокий приоритет для фоновых процессов. Я думаю, вы представляете, что происходит, если Windows отдает приоритет такому процессу, а не вашей текущей запущенной игре.
Мой подход к устранению этого недостатка в планировщике Windows заключается в использовании настраиваемого профиля электропитания, который обеспечивает лучшее управление планировщиком по распределению нагрузок между ядрами. Сперва будут вовлечены, по возможности, лучшие ядра, что приведет более высокому и плавному fps. Если лучшие ядра будут заняты — нагрузка распределится по ядрам с меньшим рангом.
P-States и C-States
Существует два механизма управления для снижения энергопотребления процессора.
C-States описывают различные возможности простоя (энергосбережения). Прежде чем подсистему можно отключить, она должна бездействовать. Таким образом, C-States x (или Cx) означает, что одна или несколько подсистем ЦП находятся в режиме ожидания и не функционируют.
С другой стороны, P-States выполняют переключение в определенные (энергосберегающие) состояния. Подсистема фактически работает, но не требует полной производительности, поэтому напряжение и/или частота, на которой она работает, снижается. P-States x (или Px) означает, что подсистема, к которой оно относится (например, ядро ЦП), работает на определенной паре «частота и напряжение».
Поскольку большинство современных процессоров имеют несколько ядер в одном модуле (CCX или CCD), C-States далее делятся на C-States ядра (CC-States) и C-States модуля (PC-States). Причина PC-States состоит в том, что в процессоре есть другие (общие) компоненты, которые также могут быть отключены после того, как все ядра, использующие их, выключены (например, общий кэш). Однако, как пользователь или программист, мы не можем управлять ими, поскольку мы не взаимодействуем напрямую с модулем, а скорее с отдельными ядрами. Тогда мы можем напрямую воздействовать только на СС-States; PC-States косвенно влияют на основе CC-States ядер.
Состояния нумеруются, начиная с нуля, как C0, C1. и P0, P1. Чем выше число, тем больше энергии сохраняется. C0 означает отсутствие энергосбережения при выключении чего-либо, поэтому все включено. P0 означает максимальную производительность, то есть максимальную частоту, напряжение и используемую мощность.
Инструкция по установке кастомного профиля питания
Для корректной работы этого обновленного плана электропитания в UEFI необходимо настроить определенные параметры. Хотя большинство производителей материнских плат используют правильные значения по умолчанию, я все же перечислю здесь все варианты для полноты, и для вас, чтобы проверить в случае использования других значений по умолчанию.
Вы должны установить следующее в вашем UEFI, под «CPU Features» или «AMD_CBS»:
Если вы не можете найти определенные настройки, такие как «AMD Cool’n’Quiet» или «PPC Adjustment», не беспокойтесь, они имеют второстепенное значение. Некоторые производители материнских плат просто скрывают их.
Профиль питания поставляется в ZIP-архиве, который вы можете скачать, перейдя по ссылке выше (обратите внимание, что профиль питания распространяют только известные интернет-ресурсы). Извлеките содержимое этого архива.

Теперь запустите пакетный файл install.bat.
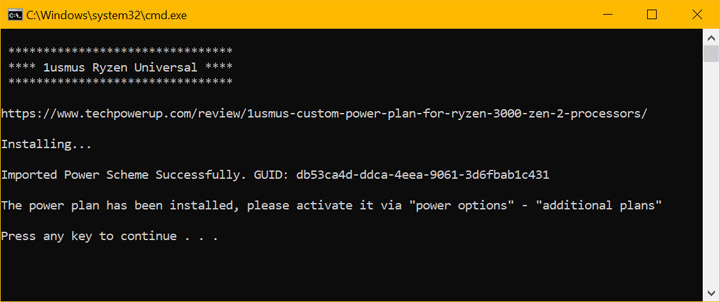
После завершения установки вы должны увидеть новый план питания в настройках под названием «1usmus Ryzen Universal». Ищите его в «дополнительных схемах питания», если вы не видите это сразу. Активируйте его, перезагрузите систему, и все готово. Возможно, вам придется щелкнуть разделитель «Показать дополнительные схемы электропитания», чтобы открыть список дополнительных схем электропитания в системе.
Результаты
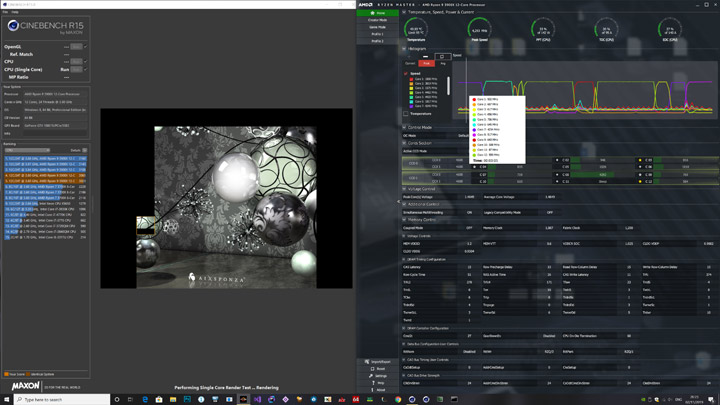

Взглянув на тактовую частоту во время этого тестового прогона, мы можем видеть, что процессор работает на более высоких тактовых частотах — в среднем на 200 МГц выше. Большинство ядер, на которых нет нагрузки, спят, а так же задействованы только лучшие ядра.
Тестовый стенд
Технические характеристики тестовой системы:
Clocking Stretching
Еще одним нюансом мониторинга реальной частоты является Adaptive Clocking Stretching. Технология адаптивного тактирования, которая динамически регулирует время цикла (например, уменьшение частоты), чтобы выдерживать падение напряжения без увеличения напряжения.
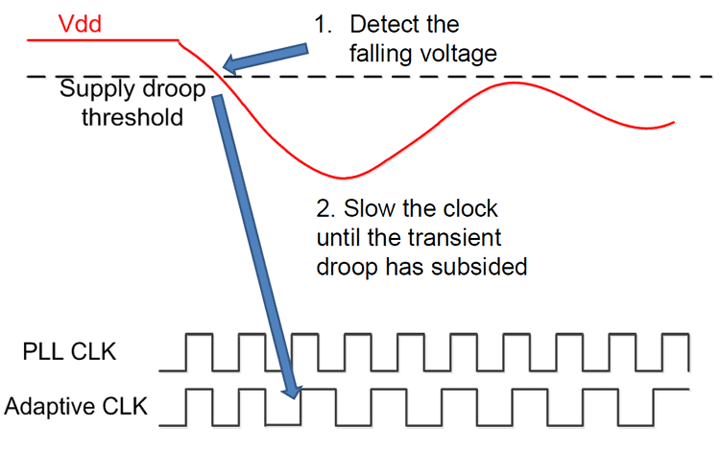
Как только спад обнаружен и величина определена, схема растяжения тактового сигнала увеличивает тактовый период (то есть, уменьшая частоту) для компенсации. Более конкретных данных я предоставить вам, к сожалению, не могу из-за NDA, но могу привести пример поколения Steamroller. Порог спада составлял 2,5%, а увеличение такта 7% обеспечивало правильный баланс между поддержанием высоких частот и улучшением Vmin. И последним интересным моментом этой технологии является настройка рястежения циклов. Как только спад обнаружен и величина определена, схема растяжения тактового сигнала увеличивает тактовый период (то есть, уменьшая частоту) для компенсации. То есть процессор может «проглотить» просадку напряжения на определенном количестве циклов, прежде чем задействует Stretching.
В связи с этим всем описанным я не решил травмировать психику моей любимой публики результатами, которые будут серьезно отличаться от обзоров и материалов моих коллег. Но безусловно за этим будущее.
Подводя итоги, хочу сказать, что мы имеем дело с невероятно сложными и технологическими процессорами, балансировка которых порой требует дополнительного времени, и я рад, что мое взаимодействие с AMD позволит вам получить дополнительную производительность и улучить ваш игровой комфорт. В ближайшее время я надеюсь, вы получите обновление UEFI, которые решат все проблемы. Так же я подготовил некоторые советы, которые помогут в будущем избежать некоторых проблем.
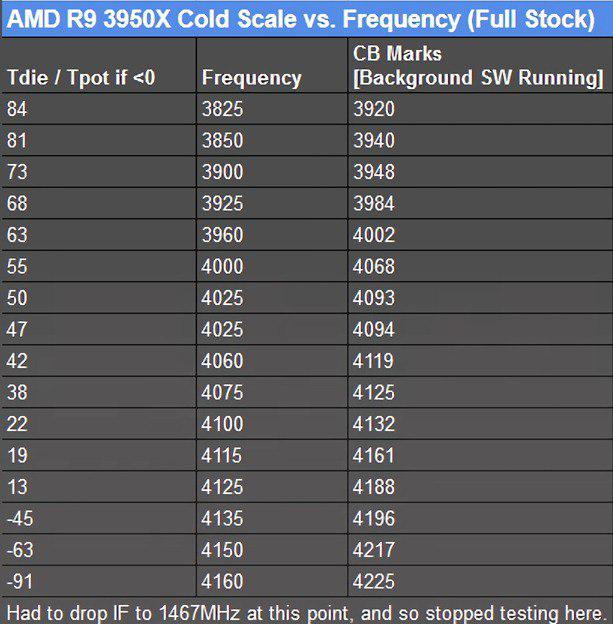
То есть вы можете потерять до 150 МГц из-за системы охлаждения. Что касается меня, то я в своих экспериментах использую продукцию EKWB.
Ранжирование ядер и хорошие новости от Роберта Халлок
Как упоминалось ранее, Zen 2 — единственный продукт на рынке, который использует функцию ACPI под названием CPPC2.
AMD использует интерфейс CPPC2 для передачи операционной системе характеристик и конфигураций управления частотой и энергопотреблением ОС и концепции «предпочтительных ядер», которые могут достигать более высоких частот, чем их соседи по CCX.
Многих энтузиастов смутило то обстоятельство, что ранги ядер в журнале ОС могут сильно отличаться от того, что отображается в Ryzen Master. То есть возник вопрос, не является ли это причиной недостаточного boost.

В моем случае этот нюанс тоже имел место быть. Чтобы развеять собственные сомнения, я проверил качество каждого ядра. Результат был положительным, заводские метки ядер были довольно точными.
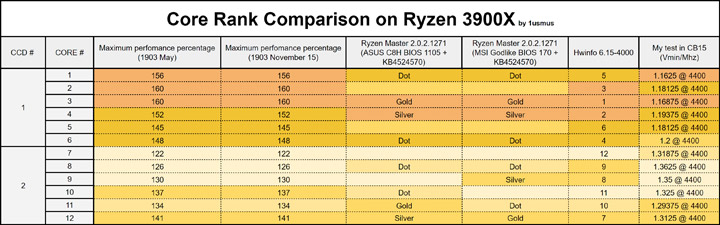
21 ноября Роберт Халлок, занимающий пост главы технического маркетинга, опубликовал статью на Reddit, в которой он объяснил многие технические детали о boost и ранжировании ядер. Давайте познакомимся с этой информацией:
«1. Прошивка (FW) поддерживает относительный рейтинг ядер. Список поддерживается путем считывания характеристик напряжения/частоты, генерируемых ядрами во время окончательного испытания и сборки.
2. И Windows, и Ryzen Master читают этот рейтинг, сгенерированный FW, чтобы определить самое быстрое ядро в системе.
3. Если вы проверяете ранжирование ядер с помощью команды «sysfs» в Linux, некоторые заметили, что наши ядра ранжируются с шагом, равным примерно в 3%. Это не означает, что одно ядро на 3% быстрее другого.
4. Вместо этого вам нужно знать, что CPPC2 (он же «предпочтительное ядро» или «самое быстрое ядро») представляет собой «непрерывную, абстрактную, не зависящую от единицы шкалу производительности» (спецификация ACPI, раздел 8.4.7). Для перевода: рейтинг ничего не значит, кроме утверждения, какие ядра являются самыми быстрыми. Бывает, что произвольное ранжирование ядер с интервалом
3% идеально подходит для передачи ранжирования в ОС, не оставляя места для ошибок округления, когда этот произвольный масштаб интерпретируется для установки целевого показателя производительности ЦП.
5. Теперь мы находимся в передаче обслуживания ОС. Здесь все становится сложнее. Windows выбирает и устанавливает приоритеты для самого быстрого ядра в прошивке с дополнительным критерием, что в том же CCX должно быть второе ядро, которое почти так же быстро. Планировщик вращается между ними, чтобы одно ядро не выполняло всю однопоточную работу все время (вот почему вы иногда будете видеть, как задача «одного потока» перемещается назад и вперед между двумя различными ядрами). Кроме того, я считаю, что в этом сообществе теперь глубоко понимают, что распределение рабочих нагрузок в CCX, когда это возможно, является оптимальным для Zen 2. Windows 10 May 2019 Update также учитывает это. Таким образом, если Windows собирается выбрать и использовать самое быстрое ядро, ей нужен партнер в том же CCX, чтобы обеспечить соответствие всем критериям для оптимальной производительности. Это наиболее эффективная конфигурация для сценариев 1T и легкопоточных.
6. Ryzen Master, используя те же показания прошивки, выбирает единственную наилучшую кривую напряжение/частота во всем процессоре с точки зрения разгона. Когда вы видите золотую звезду, это строго означает, что это одно ядро с лучшим разгонным потенциалом. Как мы объяснили во время запуска второго поколения Ryzen, мы подумали, что это может быть полезно для людей, пытающихся сделать записи частоты на Ryzen. Чтобы быть кристально чистым: это ядро не может быть оптимальным для повышения производительности, оно не имеет отношения к быстрому выбору ядра ОС, и оно может не соответствовать другим техническим критериям, связанным с выбором оптимальных ядер для автоматического планирования.
7. Поэтому: и Windows, и Ryzen Master подходят для своих нужд, используя один и тот же общий набор информации, предписанный прошивкой. Основной выбор работает так, как задумано и спроектировано, но мы определенно видим и понимаем, что это может быть яснее. Мы надеемся, что этот пост начнет прояснять ситуацию, и. »
Также хочу обратить внимание на самый важный момент, который в будущем должен полностью избавить пользователей от ситуации, когда ядра среднего качества используются для однопоточных задач:
«8. В качестве следующего шага: мы обновим Ryzen Master, чтобы пометить самые быстрые ядра таким же образом, как Windows, чтобы не было путаницы. Пара ядер, помеченная Ryzen Master, будет той же парой, которая была выбрана для лучшей автономной работы.»
То есть, подводя итоги, компания AMD решила перестраховаться от дальнейшего развития материалов о недоброкачественном boost. Но тем не менее за кадром осталось несколько нюансов, о которых вы должны знать ибо они были затронуты вскользь с небольшой порцией дезинформации:
1. Роберт в своей заметке указывает об активном использовании «duty cycle» (дежурная езда на велосипеде между двумя ядрами) во время любой однопоточной нагрузке. При этом максимальный boost априори не может быть максимальным, так как в системе не существует двух одинаковых ядер. Например, у моего экземпляра лучшее ядро достигает 4590 МГц, а его собрат по задачам только 4550 МГц (речь про эффективную частоту). То есть средняя частота будет равняться
4570 МГц. Это действительно наблюдается на последних прошивках, но при этом в профиле питания Ryzen Balanced режим «duty cycle» запрещен по умолчанию. Так от куда же он берется?
Несколько глав назад я вам демонстрировал скриншот работы UEFI с прошивкой SMU 46.24/46.34, в данной прошивке процессор работает без «duty cycle», то есть однопоточная задача полностью, 100% своего времени удерживается лучшим ядром. Это безусловно круто, но по мнению AMD это может привести к точечному перегреву кристалла. И это действительно так, температура выше в среднем на 2–3 градуса, но она отнюдь очень и очень далеко до температуры троттлинга. В моем понимание на данный момент баг SMU или Windows (поверьте, найти крайнего в этом случае очень сложно) представлен публике как крутая особенность.
2. Оба метода оценки ядер по-своему верны. При этом ПО с фирменным API, которое в теории должен знать лучшее свои ядра, знает эти ядра хуже. В следующем обновлении Ryzen Master пользователи получат ранги ядер которые находятся в таблицах ACPI от Windows.
Текущее положение вещей
Любой скандал всегда имеет последствия, как для того, кто его устраивает, так и для компаний, которые хотят его замять, или даже пытаются в интервью опровергнуть проблему. В нашем случае случилось следующее.
AMD рассмотрела проблемы, описанные в статье, и после расследования выяснилось, что основной причиной такого странного поведения повышения boost был планировщик Windows. К счастью, Microsoft выпустила обновление KB4524570, которое своевременно включает исправление для планировщика Windows и значительно улучшило поведение и частоты повышения boost.
Вторая часть проблемы связана с уровнем UEFI, в частности с настройками параметров CPPC и C-State, которые по умолчанию должны находиться в режиме «Включен». Комментируя мой Power Plan, глава технического маркетинга AMD для процессоров Роберт Халлок в интервью PC World подтвердил наши открытия о CPPC и C-State, заявив, что эти функции включены по умолчанию, что, к сожалению, не отражает реальность.
За исключением энтузиастов и опытных пользователей, большинство людей не склонны перепроверять свои настройки UEFI, и могут использовать свой процессор не на полную мощность, просто потому что некоторые производители материнских плат, похоже, не знают, насколько важны эти настройки для повышения производительности процессора. В этой статье я публикую второй план питания для Ryzen, который помогает даже пользователям с последними обновлениями Windows.
Далее я приведу хронологию событий, которая не может не удивить.
И собственно что же изменилось после исправления UEFI и KB4524570. Поехали.
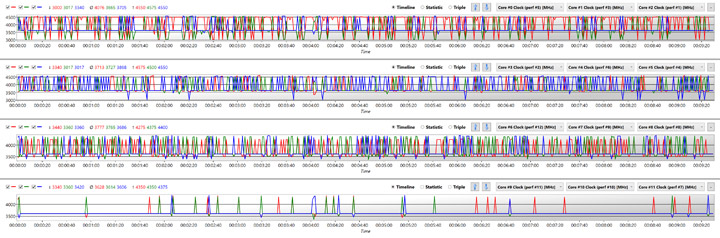
UEFI v160, 1903 без KB4524570, Ryzen Balanced
Этот график отображает состояние системы до обновления прошивки материнской платы и кумулятивного обновления Microsoft от 15 ноября. На нем продемонстрирована однопоточная нагрузка на чистой операционной системе без фоновой активности программ, но при этом задействовано 9 из 12 ядер и наблюдаются явные проблемы с работой CPPC. При этом при каждом перезапуске теста имели boost разные ядра.
Каждое ядро, которое не спит — это автоматический минус для boost, так как для n-поточных нагрузок определен свой лимит по EDC, напряжению и температуре (другие факторы работы AVFS мы не будем рассматривать в этом материале). Напомню, что для игр подобное переключение контекста и прогоны данных между ССX означают статтеры (и, в частности, сниженный фреймрейт в 1% событиях), которые, в свою очередь, влияют на ваш игровой комфорт.
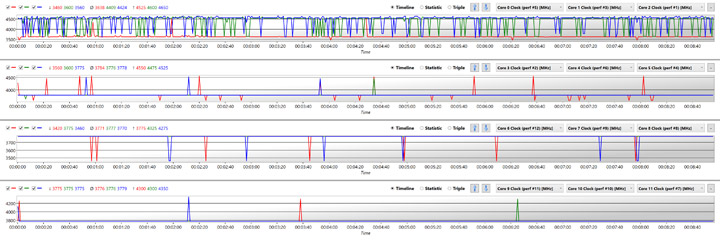
UEFI v170, 1903 с KB4524570, 1usmus Ryzen Universal
Изменения очень серьезные:

Mod Bios by me v130 + SMU 46.24.00, 1903, Ryzen Balanced
Следовательно, необходимо использовать новый подход, называемый эффективными частотами. Этот метод основан на возможности аппаратного обеспечения определять фактическое состояние частот (все их уровни) в течение определенного интервала, включая спящие (остановленные) состояния. Затем программное обеспечение запрашивает счетчик в течение определенного периода опроса, который предоставляет среднее значение всех состояний частот, которые произошли в данном интервале. HWiNFO v6.13-3955 Beta представляет отчеты об этих частотах.
Многие пользователи могут быть удивлены, насколько эти частоты отличаются от традиционных значений. Но, пожалуйста, обратите внимание, что это эффективное значение — это средние частоты за интервал опроса, используемый в HWiNFO.
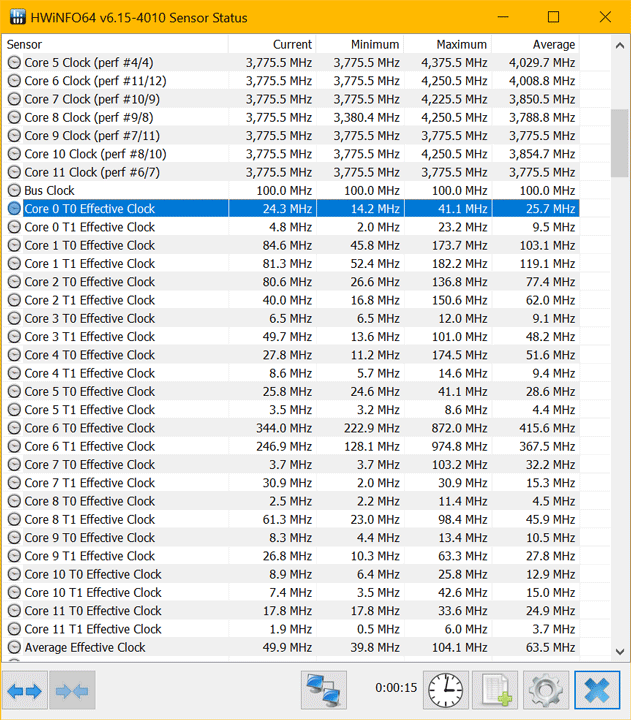
Я очень благодарен Martin, разработчику HWiNFO за этот вклад.
Также хотел бы поблагодарить Oleg Kasumov и @Kromaatikse за помощь в открытиях, описанным в этом материале.
Выводы
Удивительно, как такой простой программный мод может оказать столь заметное влияние на процессор, и мы даже не разгоняем его. Кастомный план управления питанием универсален, он совместим с любой версией Windows 10 и любым UEFI. Малопоточные рабочие нагрузки теперь распределяется на меньшее количество ядер, которые, как известно, лучше на физическом уровне (более удачные ядра, бининг, ядра с высоким рангом) и которые повышают тактовые частоты лучше других, обеспечивая повышенную энергоэффективность и производительность. Не обделены 2-, 3- и 4-поточные вычисления, теперь нагрузка будет распределяться только среди лучших ядер в CCX, которые имеют более высокий ранг, нежели соседи.
Я бы посоветовал всем пользователям поделиться своим опытом использования этого плана электропитания в комментариях к этой статье. Так же я буду рад ответить на все ваши вопросы.