За последнюю неделю дважды объяснял людям как организована работа с памятью в х86, с целью чтобы не объяснять в третий раз написал эту статью.
И так, чтобы понять организацию памяти от вас потребуется знания некоторых базовых понятий, таких как регистры, стек и тд. Я по ходу попробую объяснить и это на пальцах, но очень кратко потому что это не тема для этой статьи. Итак начнем.
Как известно программист, когда пишет программы работает не с физическим адресом, а только с логическим. И то если он программирует на ассемблере. В том же Си ячейки памяти от программиста уже скрыты указателями, для его же удобства, но если грубо говорить указатель это другое представление логического адреса памяти, а в Java и указателей нет, совсем плохой язык. Однако грамотному программисту не помешают знания о том как организована память хотя бы на общем уровне. Меня вообще очень огорчают программисты, которые не знают как работает машина, обычно это программисты Java и прочие php-парни, с квалификацией ниже плинтуса.
Так ладно, хватит о печальном, переходим к делу. Рассмотрим адресное пространство программного режима 32 битного процессора (для 64 бит все по аналогии) Адресное пространство этого режима будет состоять из 2^32 ячеек памяти пронумерованных от 0 и до 2^32-1. Программист работает с этой памятью, если ему нужно определить переменную, он просто говорит ячейка памяти с адресом таким-то будет содержать такой-то тип данных, при этом сам програмист может и не знать какой номер у этой ячейки он просто напишет что-то вроде: int data = 10; компьютер поймет это так: нужно взять какую-то ячейку с номером стопицот и поместить в нее цело число 10. При том про адрес ячейки 18894 вы и не узнаете, он от вас будет скрыт.
Все бы хорошо, но возникает вопрос, а как компьютер ищет эту ячейку памяти, ведь память у нас может быть разная: 3 уровень кэша 2 уровень кэша 1 уровень кэша основная память жесткий диск
Это все разные памяти, но компьютер легко находит в какой из них лежит наша переменная int data. Этот вопрос решается операционной системой совместно с процессором. Вся дальнейшая статья будет посвящена разбору этого метода.
Архитектура х86 поддерживает стек.
Стек это непрерывная область оперативной памяти организованная по принципу стопки тарелок, вы не можете брать тарелки из середины стопки, можете только брать верхнюю и класть тарелку вы тоже можете только на верх стопки. В процессоре для работы со стеком организованны специальные машинные коды, ассемблерные мнемоники которых выглядят так:
push operand помещает операнд в стек
pop operand изымает из вершины стека значение и помещает его в свой операнд
Стек в памяти растет сверху вниз, это значит что при добавлении значения в него адрес вершины стека уменьшается, а когда вы извлекаете из него, то адрес вершины стека увеличивается.
Теперь кратко рассмотрим что такое регистры. Это ячейки памяти в самом процессоре. Это самый быстрый и самый дорогой тип памяти, когда процессор совершает какие-то операции со значением или с памятью, он берет эти значения непосредственно из регистров. В процессоре есть несколько наборов логик, каждая из которых имеет свои машинные коды и свои наборы регистров. Basic program registers (Основные программные регистры) Эти регистры используются всеми программами с их помощью выполняется обработка целочисленных данных. Floating Point Unit registers (FPU) Эти регистры работают с данными представленными в формате с плавающей точкой. Еще есть MMX и XMM registers эти регистры используются тогда, когда вам надо выполнить одну инструкцию над большим количеством операндов.
Рассмотрим подробнее основные программные регистры. К ним относятся восемь 32 битных регистров общего назначения: EAX, EBX, ECX, EDX, EBP, ESI, EDI, ESP Для того чтобы поместить в регистр данные, или для того чтобы изъять из регистра в ячейку памяти данные используется команда mov:
mov eax, 10 загружает число 10 в регистр eax.
mov data, ebx копирует число, содержащееся в регистре ebx в ячейку памяти data.
Регистр ESP содержит адрес вершины стека. Кроме регистров общего назначения, к основным программным регистрам относят шесть 16битных сегментных регистров: CS, DS, SS, ES, FS, GS, EFLAGS, EIP EFLAGS показывает биты, так называемые флаги, которые отражают состояние процессора или характеризуют ход выполнения предыдущих команд. В регистре EIP содержится адрес следующей команды, которая будет выполнятся процессором. Я не буду расписывать регистры FPU, так как они нам не понадобятся. Итак наше небольшое отступление про регистры и стек закончилось переходим обратно к организации памяти.
Как вы помните целью статьи является рассказ про преобразование логической памяти в физическую, на самом деле есть еще промежуточный этап и полная цепочка выглядит так:
Логический адрес —> Линейный (виртуальный)—> Физический
Все линейное адресное пространство разбито на сегменты. Адресное пространство каждого процесса имеет по крайней мере три сегмента: Сегмент кода. (содержит команды из нашей программы, которые будут исполнятся.) Сегмент данных. (Содержит данные, то бишь переменные) Сегмент стека, про который я писал выше. Линейный адрес вычисляется по формуле:
линейный адрес=Базовый адрес сегмента(на картинке это начало сегмента) + смещение
Сегмент кода
Сегмент данных
Сегмент стека
Используемый сегмент стека задается значением регистра SS. Смещение внутри этого сегмента представлено регистром ESP, который указывает на вершину стека, как вы помните. Сегменты в памяти могут друг друга перекрывать, мало того базовый адрес всех сегментов может совпадать например в нуле. Такой вырожденный случай называется линейным представлением памяти. В современных системах, память как правило так организована.
Теперь рассмотрим определение базовых адресов сегмента, я писал что они содержаться в регистрах SS, DS, CS, но это не совсем так, в них содержится некий 16 битный селектор, который указывает на некий дескриптор сегментов, в котором уже хранится необходимый адрес. Так выглядит селектор, в тринадцати его битах содержится индекс дескриптора в таблице дескрипторов. Не хитро посчитать будет что 2^13 = 8192 это максимальное количество дескрипторов в таблице. Вообще дескрипторных таблиц бывает два вида GDT и LDT Первая называется глобальная таблица дескрипторов, она в системе всегда только одна, ее начальный адрес, точнее адрес ее нулевого дескриптора хранится в 48 битном системном регистре GDTR. И с момента старта системы не меняется и в свопе не принимает участия. А вот значения дескрипторов могут меняться. Если в селекторе бит TI равен нулю, тогда процессор просто идет в GDT ищет по индексу нужный дескриптор с помощью которого осуществляет доступ к этому сегменту. Пока все просто было, но если TI равен 1 тогда это означает что использоваться будет LDT. Таблиц этих много, но использоваться в данный момент будет та селектор которой загружен в системный регистр LDTR, который в отличии от GDTR может меняться. Индекс селектора указывает на дескриптор, который указывает уже не на базовый адрес сегмента, а на память в котором хранится локальная таблица дескрипторов, точнее ее нулевой элемент. Ну а дальше все так же как и с GDT. Таким образом во время работы локальные таблицы могут создаваться и уничтожаться по мере необходимости. LDT не могут содержать дескрипторы на другие LDT. Итак мы знаем как процессор добирается до дескриптора, а что содержится в этом дескрипторе посмотрим на картинке: Дескрипторы состоит из 8 байт. Биты с 15-39 и 56-63 содержат линейный базовый адрес описываемым данным дескриптором сегмента. Напомню нашу формулу для нахождения линейного адреса:
линейный адрес = базовый адрес + смещение
[база; база+предел)
(база+предел; вершина]
Кстати интересно почему база и предел так рвано располагаются в дескрипторе. Дело в том что процессоры х86 развивались эволюционно и во времена 286х дескрипторы были по 8 бит всего, при этом старшие 2 байта были зарезервированы, ну а в последующих моделях процессоров с увеличением разрядности дескрипторы тоже выросли, но для сохранения обратной совместимости пришлось оставить структуру как есть. Значение адреса «вершина» зависит от 54го D бита, если он равен 0, тогда вершина равна 0xFFF(64кб-1), если D бит равен 1, тогда вершина равна 0xFFFFFFFF (4Гб-1) С 41-43 бит кодируется тип сегмента. 000 — сегмент данных, только считывание 001 — сегмент данных, считывание и запись 010 — сегмент стека, только считывание 011 — сегмент стека, считывание и запись 100 — сегмент кода, только выполнение 101- сегмент кода, считывание и выполнение 110 — подчиненный сегмент кода, только выполнение 111 — подчиненный сегмент кода, только выполнение и считывание
44 S бит если равен 1 тогда дескриптор описывает реальный сегмент оперативной памяти, иначе значение S бита равно 0.
Самым важным битом является 47-й P бит присутствия. Если бит равен 1 значит, что сегмент или локальная таблица дескрипторов загружена в оперативку, если этот бит равен 0, тогда это означает что данного сегмента в оперативке нет, он находится на жестком диске, случается прерывание, особый случай работы процессора запускается обработчик особого случая, который загружает нужный сегмент с жесткого диска в память, если P бит равен 0, тогда все поля дескриптора теряют смысл, и становятся свободными для сохранения в них служебной информации. После завершения работы обработчика, P бит устанавливается в значение 1, и производится повторное обращение к дескриптору, сегмент которого находится уже в памяти.
На этом заканчивается преобразование логического адреса в линейный, и я думаю на этом стоит прерваться. В следующий раз я расскажу вторую часть преобразования из линейного в физический. А так же думаю стоит немного поговорить о передачи аргументов функции, и о размещении переменных в памяти, чтобы была какая-то связь с реальностью, потому размещение переменных в памяти это уже непосредственно, то с чем вам приходится сталкиваться в работе, а не просто какие-то теоретические измышления для системного программиста. Но без понимания, как устроена память невозможно понять как эти самые переменные хранятся в памяти. В общем надеюсь было интересно и до новых встреч.
Программирование процессоров Intel x86 в защищённом режиме Управление памятью: сегменты и дескрипторы
Для большинства прикладных программистов основные преимуществами защищённого режима (из тех, о которых они слышали…) это значительное увеличение объёма адресуемой памяти и возможность практически отказаться от сегментации. В частности, именно о такой модели памяти в 199?-x годах мечтал один мой знакомый, писавший аналог DOOM-а для MS-DOS.
Системные программисты видят ситуацию с несколько другой стороны. Погрузившись в защищённый режим глубже, они понимают, что сегменты размером 4 Гб и плоский (flat) режим адресации это, конечно, замечательно и очень полезно с практической точки зрения, но для ОС это далеко не главное. Куда важнее то, что памятью теперь действительно можно управлять.
ПРИМЕЧАНИЕ
В реальном режиме всё управление памятью сводилось к записи значения в сегментный регистр, ничего большего нельзя было сделать в принципе. В защищённом режиме возможности гораздо шире (в частности, можно организовать тот самый плоский режим).
Ну а, в качестве естественной компенсации, в защищённом режиме управлять памятью не только можно, но и необходимо, и, конечно же, это выливается в весьма ощутимые дополнительные усилия, как при изучении, так и при кодировании.
Управление памятью в защищённом режиме разбивается на две почти независимые части:
Сегментация (segmentation)
Страничная адресация (paging)
Необходимой является только сегментация, и именно она рассмотрена в этой главе.
Ликбез
Перед тем, как переходить к собственно управлению памятью, надо выяснить, что такое «память», и в каком виде она доступна программисту.
ПРИМЕЧАНИЕ
Скорее всего, вы знаете ответы на эти вопросы для реального режима, но в защищённом режиме будет немного иначе. Привыкайте, в нём почти всё немного иначе.
Адреса
В защищённом режиме существует три различных типа адресов и три соответствующих им адресных пространства (address space):
логическое (logical)
линейное (linear)
физическое (physical).
Логический адрес
Логическим адресом называется пара <сегмент>:<смещение>, на практике встречающаяся в виде <сегментный регистр>:<смещение>. Так как разрядность сегментного регистра 16, а смещения 32 бита, теоретически, таким образом можно было бы адресовать 2 48 байт (256 Тб). Но из-за некоторых особенностей сегментных регистров защищённого режима, это число уменьшается до 2 46 байт (64 Тб), что, конечно, тоже немало.
Линейный адрес
«Промежуточный» адрес, вводит дополнительный уровень абстракции, именно благодаря его существованию возможно использование страничной адресации (подробнее – в главе про виртуальную память). 32 разряда, плоское (несегментированное) адресное пространство размером 4 Гб.
Физический адрес
Физический адрес это число, выставляемое процессором на шину адреса. Разрядность зависит от модели процессора:
Intel386SX («облегчённая» версия Intel386 c 24-разрядной шиной адреса) – 24 бита (16 Мб)
До Intel Pentium Pro – 32 бита (4 Гб)
Intel Pentium Pro и старше – 36 бит (64 Гб)
Фактически, это множество адресов, к которым может обращаться процессор.
ПРИМЕЧАНИЕ
Физический адрес не обязательно является адресом в ОЗУ. Это может быть адрес в ПЗУ, в видеопамяти, регистр какого-либо устройства, адрес которому ничего не соответствует. Куда относится конкретный физический адрес зависит от «железа», причём далеко не только от процессора.
Преобразование адресов
Поскольку программист использует логические адреса, а процессор физические, необходимо преобразование. Оно происходит в два этапа: логический – линейный и линейный – физический. Первый этап выглядит так:
<линейный адрес> = <базовый адрес сегмента> + <смещение>
ПРИМЕЧАНИЕ
Обращаю внимание: сегменты могут перекрываться. Хуже того, скорее всего, они будут перекрываться. А как иначе вместить 64 логических терабайта в 4 линейных гигабайта?
Если страничная адресация не используется (наш случай), второй этап получается вырожденным:
<физический адрес> = <линейный адрес>
ПРИМЕЧАНИЕ
Таким образом, в отсутствии страничной адресации, даже при 36-ти битной шине адреса невозможно обратиться к памяти по адресам старше 4 Гб. Зато всё гораздо проще…
Сегменты
Для программиста, сегмент это адресуемый блок памяти с заданными свойствами. Подходя к вопросу чуть более формально, можно сказать, что сегмент описывается следующими параметрами:
Расположение блока памяти в линейном адресном пространстве
Размер блока памяти
Те самые свойства
Сегмент – логическое понятие. Физически есть:
— Некая структура, описывающая свойства сегмента (про неё ниже в этой же главе). Очевидно, что это не сегмент.
— Часть линейного адресного пространства, на которую проецируется сегмент. Во-первых, она не обладает никакими «заданными свойствами», во-вторых, на любую часть линейного адресного пространства могут проецироваться несколько сегментов. Поэтому и это не сегмент.
— Процессор, который связывает первое и второе. Естественно, он тоже не сегмент.
Базовый адрес и размер сегмента
Как уже было сказано, логический адрес <сегмент>:<смещение> преобразуется процессором в линейный адрес по формуле:
<линейный адрес> = <базовый адрес сегмента> + <смещение>
Поскольку смещение 32-х разрядное, таким образом можно адресовать область линейного адресного пространства, начинающуюся от базового адреса (base address) сегмента и имеющую размер 4 Гб. Но допустимые смещения ограничиваются вторым параметром – размером сегмента (segment size). Процессор считает, что к сегменту относится непрерывная область линейного адресного пространства, начинающаяся с базового адреса сегмента и содержащая количество байт, равное его размеру. Логические адреса со смещением, равным или превосходящим размер сегмента, выходят за пределы сегмента, обращение к таким адресам приводит к исключению #GP (General Protection Fault; подробнее об исключениях в соответствующей главе).
ПРИМЕЧАНИЕ
Размер сегмента имеет тот же смысл, что и размер массива в C. Например, размер массива
равен 100, но последний элемент массива – array[99]. Так же и с сегментами: смещение последнего адресуемого байта это размер сегмента – 1.
Взаимосвязь между всеми этими понятиями продемонстрирована на Рис.1.
Рисунок 1. Сегмент, размер сегмента, смешение байта.
ПРИМЕЧАНИЕ
Помимо обычных сегментов существуют expand down (переводится как «растущий вниз») сегменты, для которых ограничения задаются иначе. Их полезность в реальных программах представляется мне сомнительной, тем не менее, expand down сегменты кратко описаны в приложении.
Свойства сегмента
Свойства сегмента определяют его тип и правила использования (попытка использовать сегмент не по правилам обычно приводит к исключению #GP). Не вдаваясь в детали, можно выделить следующие типы сегментов:
Сегмент кода (code segment). Допустимо исполнение, может быть разрешено чтение.
Сегмент данных (data segment). Допустимо чтение, может быть разрешена запись.
Как видите, в списке нет сегментов стека. Вообще-то, специально для этого предназначены упомянутые выше expand down сегменты, но с точки зрения классификации они являются частным случаем сегмента данных. Кроме того, к сожалению, они обладают тремя недостатками:
не все программисты понимают их правильно 🙂
для того чтобы использовать их «правильно», нужно написать довольно много кода (подробнее об этом – в приложении). Использовать их «по простому» можно, но тогда и преимуществ не будет.
в большинстве случаев, те же задачи проще и красивее решаются при помощи страничной адресации.
К счастью, использование expand down сегментов не обязательно, сегментом стека может быть любой доступный для чтения и записи сегмент данных.
Дескрипторы сегментов кода/данных
Логически, дескриптор (descriptor) это структура, описывающая некую системную сущность. В частности, дескриптор сегмента (segment descriptor; сегментный дескриптор) описывает сегмент. Физически дескриптор занимает восемь байт и имеет вполне определённый формат, зависящий от типа дескриптора.
ПРИМЕЧАНИЕ
Форматы дескрипторов могут показаться вам несколько странными и даже нелогичными. Но будьте снисходительны к разработчикам, учтите, что им приходилось соблюдать обратную совместимость с 16-ти разрядным 80286. В 80286 дескрипторы занимали те же восемь байт, но вся «полезная нагрузка» была сосредоточена в шести младших байтах, а старшие два были зарезервированы на будущее. Вот в них-то и пришлось уложить всю 32-х разрядность.
Формат дескриптора сегмента кода/данных (code or data segment descriptor, это официальное название) таков:
ПРИМЕЧАНИЕ
Напоминаю, что в борьбе точности и грамотности победила точность. Биты и байты считаются от нуля, то есть нулевой, первый, второй и т.п.
Положение
Название
Краткое описание
Два младших байта (нулевой и первый)
Segment Limit (part 1)
Младшие 16 бит 20-ти битного поля Segment Limit. Поле Segment Limit используется для вычисления размера сегмента, содержит номер последнего блока (блоки нумеруются от 0, размер блока определяет флаг G, см. ниже), являющегося частью сегмента. Алгоритм вычисления размера сегмента подробно описан ниже.
Второй, третий, четвёртый байты
Base Address (part 1)
Младшие три байта 32-х битного поля Base Address. Поле Base Address содержит базовый адрес сегмента в линейном адресном пространстве.
0-й бит пятого байта
??
Пока неважно, устанавливайте в 0.
1-й бит пятого байта
R/W
Для сегмента кода называется R (Read enable), для сегмента данных – W (Write enable). В случае сегмента кода управляет возможностью чтения его содержимого, в случае сегмента данных управляет возможностью модификации. Если флаг установлен, то можно, если нет, то нельзя.
2-й бит пятого байта
??
Пока неважно, устанавливайте в 0.
3-й бит пятого байта
Code/Data
Если флаг установлен, дескриптор описывает сегмента кода, если сброшен – сегмент данных.
4-й – 7-й биты пятого байта
??
Пока неважно, устанавливайте в 1001b.
0-й – 3-й биты шестого байта
Segment Limit (part 2)
Старшие 4 бита поля Segment Limit.
4-й – 6-й биты шестого байта
??
Пока неважно, устанавливайте в 0.
7-й бит шестого байта
G
Granularity. Флаг гранулярности. Используется для вычисления размера сегмента, определяет, в каких единицах он указан. Если флаг сброшен, размер сегмента указан в байтах, если установлен – в 4096-ти байтных блоках (4096 == 1000h).
И обещанный алгоритм вычисления размера сегмента (на языке «псевдо-С»):
Если Segment Limit – 0, G – 0, то размер сегмента 1 байт.
Если Segment Limit – 0, G – 1, то размер сегмента 4096 байт.
Если Segment Limit – FFFFFh (максимальное 20-ти битное число), G – 0, то размер сегмента 100000h байт (1 Мб).
Если Segment Limit – FFFFFh, G – 1, то размер сегмента 100000000h байт (4 Гб).
Вся эта арифметика относится только к размеру сегмента! Базовый адрес сегмента всегда совпадает со значением поля Base Address.
Примеры
ПРЕДУПРЕЖДЕНИЕ
Относится ко всем встречающимся в курсе структурам, в том числе к дескрипторам! Поля, занимающие больше одного байта, находятся в стандартном для Intel x86 формате Little Endian, то есть в байте с младшим адресом расположена менее значимая часть числа (например, число 12345678h будет представлено последовательностью байт 78h 56h 34h 12h). Применительно к дескриптору сегмента кода/данных, это означает следующее:
— в нулевом байте – младшие 8 разрядов Segment Limit, в первом – от 8-го до 15-го.
— во втором байте – младшие 8 разрядов Base Address, в третьем – от 8-го до 15-го, в четвёртом – от 16-го до 23-го.
Дескриптор сегмента данных, размер сегмента 4 Гб, базовый адрес 0, Read/Write:
Дескриптор сегмента данных, размер сегмента 64 Кб, базовый адрес 0, Read/Write:
Дескриптор сегмента кода, размер сегмента 64 Кб, базовый адрес 12345678h, Execute/Read:
Как видите, определять дескрипторы таким образом вполне возможно и даже не слишком сложно. Но всё-таки, когда основной принцип уже понятен, удобнее использовать вот такую структуру:
Глобальная таблица дескрипторов
Если внимательно посмотреть на примеры дескрипторов, приведённые выше, несложно заметить, что это всего лишь объявления некоторых восьмибайтных структур. Но просто объявить в своей программе такую структуру и мысленно назвать её дескриптором совершенно недостаточно для того, чтобы начать использовать описываемый этим дескриптором сегмент. Потому что процессор читать мысли не умеет и задумку не поймёт. Для того чтобы процессор понял, дескриптор должен находиться в глобальной таблице дескрипторов (Global Descriptor Table, GDT).
ПРИМЕЧАНИЕ
А почему бы вместо этого не увеличить размер сегментных регистров до восьми байт, чтобы туда влезал дескриптор? Об этом ниже, в разделе «Селекторы и сегментные регистры».
Таблица дескрипторов состоит из двух частей:
Собственно таблица – область памяти, содержащая дескрипторы.
Специальный регистр, содержащий указатель на таблицу и объясняющий процессору, что это не просто какая-то «область памяти», а именно таблица дескрипторов.
Рассмотрим по частям.
Область памяти
Формат области памяти – массив дескрипторов, в котором нулевой дескриптор начинается со смещения 0, первый – 8, второй – 16 и т.п. Подобный массив, содержащий 3 дескриптора, мог бы выглядеть так (дескрипторы взяты из примера выше):
Регистр
Местоположение и размер GDT задаёт регистр GDTR (очевидно, от GDT Register; это не ключевое слово ассемблера, а условное название, которое применяется в документации для обозначения этого регистра), вот описание его формата:
Положение
Описание
Два младших байта
Смещение последнего байта таблицы дескрипторов. То есть размер таблицы в байтах минус 1. Так как дескрипторов должно быть целое число, размер должен делиться на 8 (размер дескриптора в байтах), а смещение последнего байта должно быть равно 8n-1.
Оставшиеся четыре байта
Линейный базовый адрес таблицы дескрипторов.
Таблица 2. Регистр GDTR
Рисунок 3. Регистр GDTR
Для загрузки регистра GDTR существует специальная команда lgdt
Здесь pointer_to_new_gdtr это указатель на шестибайтную структуру, повторяющую формат GDTR.
Инициализация GDT может выглядеть так:
Опять же, для удобства можно определить структуру:
Селекторы и сегментные регистры
В реальном режиме сегменты похожи друг на друга как братья-близнецы, и для описания конкретного сегмента не нужно никаких «структур данных», достаточно знать адрес его начала, а для обращения к сегменту достаточно просто записать этот адрес в какой-нибудь сегментный регистр. Одним из следствий (это может быть как плюс, так и минус) такого подхода является то, что любое приложение достаточно легко получает доступ на чтение, запись или исполнение к любой области памяти, не зависимо от желания ОС или других приложений.
Защищённый режим позволяет разумной ОС более-менее контролировать этот процесс:
Сегменты описываются дескрипторами сегментов, которые расположены в GDT. GDT формируется ОС и пользовательские приложения не имеют к ней доступа (это должна обеспечить ОС, поместив GDT в недоступную для приложений область памяти).
ОС инициализирует GDT только такими дескрипторами сегментов, используя которые приложения никому не могут помешать (несколько упрощая…).
Приложение указывает выбранные дескрипторы при помощи селекторов (selector), хранящихся в сегментных регистрах. Использовать какие-то другие дескрипторы сегментов, кроме предложенных ОС, оно не в состоянии.
Резонное возражение: но ведь пользовательские приложения могут сами вызвать lgtr и создать собственную, «альтернативную» GDT, через которую они получат доступ к любому участку памяти!
К счастью, разработчики процессора не забыли о такой возможности, нормальное приложение не сможет сделать ничего подобного, так как для того чтобы успешно использовать инструкцию lgdt оно должно уже взломать защиту ОС каким-то другим способом. Подробнее этот вопрос будет описан в главе, посвящённой защите.
Ещё несколько не менее резонных возражений обсуждается в конце главы.
Селекторы
Селектором называется 16-ти битная структура, используемая для ссылки на находящийся в GDT дескриптор. Формат селектора:
Положение
Название
Описание
0-й – 2-й биты
??
Пока неважно, устанавливайте в 0.
3-й – 15-й биты
Index
Номер дескриптора в GDT.
Таблица 3. Формат селектора.
Рисунок 4. Формат селектора
ПРИМЕЧАНИЕ
Как вы помните, максимальное смещение последнего байта, которое можно записать в GDTR это FFFFh, поэтому максимальный размер GDT – 2 16 . А, так как один дескриптор занимает 8 байт, GDT может содержать не более 2 13 дескрипторов, то есть как раз столько, сколько влезает в поле Index селектора.
ПРИМЕЧАНИЕ
Поскольку селектор ссылается на дескриптор, а уже дескриптор описывает сегмент, наверное, правильно было бы говорить «селектор дескриптора сегмента хххх» или даже «селектор, ссылающийся на дескриптор, описывающий сегмент хххх». Но вместо этого я буду употреблять просто «селектор сегмента ххх». Потому что так короче и понятнее…
Сегментные регистры
Как уже было сказано выше, при работе в защищённом режиме, процессор интерпретирует значения сегментных регистров как селекторы, а не как адреса начала сегментов. Но это не единственная новость 🙂
Начиная с 80286, сегментные регистры состоят из двух частей: видимой и скрытой (visible part, hidden part). Видимая часть это доступный для чтения/записи 16-ти разрядный регистр, скрытая часть недоступна никак, её наличие можно определить только по некоторым косвенным признакам и документации. Содержимое видимой части зависит от режима работы процессора, а вот в скрытой части регистра в обоих режимах находится некоторый аналог дескриптора, полностью описывающий сегмент. Работает это примерно так (для защищённого режима):
Во время загрузки селектора в сегментный регистр, процессор ищет соответствующий дескриптор (если не находит, выбрасывает исключение) и, после некоторых проверок (опять же, с возможным исключением), загружает этот дескриптор в скрытую часть сегментного регистра.
В дальнейшем, при использовании сегментного регистра, процессор не обращается к таблицам дескрипторов, а использует данные, сохранённые в скрытой части сегментного регистра.
В результате поиск дескриптора, его чтение, и проверка его корректности выполняется всего один раз, что значительно ускоряет обращения к памяти. Но появляются некоторые побочные эффекты:
(Документированный) Изменение значения дескриптора в таблице дескрипторов никак не повлияет на свойства сегмента, адресуемого сегментным регистром. Чтобы процессор «заметил» изменения, сегментный регистр надо перезаписать (можно тем же самым значением).
(Недокументированный) При переключении режимов (в обе стороны) скрытые части сегментных регистров не сбрасываются, то есть в защищённом режиме можно пользоваться сегментными регистрами, сохранившимися из реального режима, и наоборот.
Второй «побочный эффект» нуждается в нескольких комментариях:
Это не дыра, а особенность архитектуры, без которой переключение режимов было бы невозможно. Потому что между фактическим переключением (сброс/установка флага PE) и перезагрузкой сегментных регистров есть некоторое количество команд, которые находятся в сегменте кода старого режима. Конечно, можно было сделать исключение для CS, а остальные сбрасывать… Но, видимо, не захотели.
В примере из первой главы в защищённом режиме были использованы сегментные регистры из реального режима. Практической ценности этот трюк не имеет, но несколько упрощает написание примеров.
Использование в реальном режиме сегментных регистров из защищенного режима имеет огромную практическую ценность: таким образом можно получить в реальном режиме сегмент размером 4 Гб. Эта возможность довольно широко известна (в частности, она упоминается в [Гук 1999] и [Зубков 1999]), чаще всего её называют Unreal Mode (официального названия, естественно, нет). Самое интересное, что после переключения в реальный режим даже перезапись сегментного регистра не приведёт к сбросу его скрытой части и возврату к «нормальным» 64-х килобайтным сегментам. По каким-то причинам при перезаписи процессор меняет только базовый адрес сегмента, оставляя в неприкосновенности его флаги и размер.
Этот же приём позволяет не только увеличить размер сегментов, но и наоборот, уменьшить их. Правда, после этого стандартные программы реального режима, да и сам MS-DOS, скорее всего, откажутся работать. Особенно ярко это проявляется при уменьшении размера сегмента стека.
Повторюсь, это недокументированная особенность, теоретически поведение процессора может измениться (на данный момент – Pentium 4 – полёт нормальный, всё осталось, как было), поэтому в реальных программах её использования следует избегать.
Совместное существование
Есть несколько простых правил совместного использования селекторов и сегментных регистров, соблюдение которых убережёт вас от лишних исключений #GP и связанных с ними неприятностей.
Нулевой селектор
Селектор, указывающий на нулевой дескриптор GDT, отличается от прочих. Он имеет три особенности:
никогда не вызывает исключения при загрузке в сегментные регистры данных (DS, ES, FS, GS)
всегда вызовет исключение при попытке использовать такой сегментный регистр
всегда вызовет исключение при попытке загрузить его в CS или SS
Предназначение нулевого селектора – явно «пометить» сегментные регистры, использование которых не планируется. Если этого не сделать, случайное использование таких сегментных регистров может привести к непонятным и плохо воспроизводимым ошибкам.
ПРИМЕЧАНИЕ
Побочный эффект – реальное содержимое нулевого дескриптора GDT никогда не используется, так как к нему невозможно обратиться.
Регистр SS
Селектор, загруженный в SS, должен быть селектором сегмента данных, доступного для чтения/записи.
Регистр CS
Селектор, загруженный в CS, должен быть селектором сегмента кода.
Регистры DS, ES, FS, GS
Селектор, загруженный в любой из этих регистров, должен быть либо селектором сегмента данных, либо селектором сегмента кода, доступного для чтения, либо нулевым селектором.
Всё вместе
Итак, к данному моменту рассмотрены все основные понятия и артефакты, относящиеся к сегментации, осталось выяснить только две вопроса:
Как всё это работает вместе?
Как это инициализировать?
Получение линейного адреса
Для начала рассмотрим «концептуально чистый» случай. Пусть на входе логический адрес в виде пары <селектор>:<смещение>, а на выходе нужно получить соответствующий линейный адрес. Алгоритм работы процессора:
Если хранящийся в <селекторе> индекс дескриптора выходит за границы GDT (определяются по содержимому GDTR), выбрасывается исключение.
По адресу начала GDT (расположен в GDTR) и индексу дескриптора определяется адрес начала дескриптора, дескриптор считывается.
Анализируется дескриптор и характер запроса с принципиальной точки зрения. На этом этапе отсекаются попытки использовать дескриптор способами, для которых он не предназначен, например, исполнять сегмент данных или читать/писать нечитаемый сегмент кода. Если проверка не проходится, генерируется исключение. Это уровень загрузки селектора в сегментный регистр: пока что не важно, как именно будет применяться этот регистр, есть только имя регистра и селектор.
Анализируется дескриптор и характер запроса с конкретной точки зрения. Если по каким-то причинам обращение невозможно (например, попытка записи в Read-Only сегмент или выход <смещения> за пределы сегмента) генерируется исключение.
Из дескриптора извлекается базовый адрес сегмента и складывается со <смещением>.
Нарисовать это можно так:
Рисунок 5. Алгоритм получения линейного адреса.
Более «правильный» алгоритм должен учитывать то, что селекторы «в свободном виде» встречаются только в командах загрузки адреса ( lds , les , lfs , lgs , lss ) и дальнего перехода, в остальных же случаях используется селектор, загруженный в сегментный регистр. А, поскольку во время загрузки сегментного регистра процессор уже проверил корректность селектора, нашёл соответствующий дескриптор и сохранил его в скрытой части сегментного регистра, то есть, фактически выполнил шаги (1), (2) и (3), алгоритм можно начинать сразу с (4).
ПРИМЕЧАНИЕ
При изучении схемы получения линейного адреса и сравнении её с «целями», описанными в первой главе, возникают естественные вопросы: Где же здесь раздельные адресные пространства? Где отделение кода/данных ОС от кода/данных пользователя? Да, пользователь не может обращаться куда угодно, но всё, что есть в GDT – в его распоряжении!
Вопросы хорошие, полные ответы на них можно получить, изучив курс полностью, но чтобы вы не мучались до последней главы, кратко отвечу сейчас.
Для разделения адресных пространств пользовательских приложений Intel предлагает использовать два механизма: локальную таблицу дескрипторов (Local Descriptor Table, LDT) и страничную адресацию. LDT не очень интересна и в курсе не рассматривается, а вот страничная адресация обязательно будет описана, но позже, в соответствующей главе.
Отделение кода/данных ОС от кода/данных пользователя реализуется при помощи одного из «пока неважных» полей дескриптора. Это поле и предоставляемые им возможности подробно рассмотрены в главе «Теоретическое введение в защиту».
Переключение режимов: инициализация системы управления памятью
С учётом существования дескрипторов сегментов и GDT, можно усложнить процедуру переключения режимов, немного приближаясь к эталону и, соответственно, получая больше возможностей.
Переключение из реального режима в защищённый:
Запретить маскируемые и немаскируемые прерывания.
Инициализировать GDT и загрузить её адрес в GDTR.
Установить флаг PE (младший бит регистра CR0).
Выполнить дальний переход (jmp или call) для перезагрузки регистра CS.
Перезагрузить все сегментные регистры.
Сделать текущим сегментом кода доступный для чтения сегмент с пределом FFFFh байт.
Загрузить во все сегментные регистры селекторы дескрипторов доступных для записи сегментов данных с пределом FFFFh.
Сбросить флаг PE
Выполнить дальний переход (jmp или call) для перезагрузки регистра CS.
Перезагрузить сегментные регистры.
Разрешить прерывания.
Приведённые ниже примеры выполняют эти требования по частям: первый пример демонстрирует работу с сегментом данных, второй – с сегментом кода.
Вентиль A20
Как известно, процессор 8086 имел 20-ти разрядную шину адреса, поэтому мог адресовать ровно 1 Мб памяти. 80286 имел уже 24-х битную шину адреса, что, теоретически, позволяло ему обращаться к 16 Мб памяти. Но, по замыслу разработчиков, вся эта «роскошь» должна была быть доступна программисту только из защищённого режима, в реальном режиме 80286 должен был полностью повторять 8086. Однако разработчики 80286 не учли, что механизм адресации памяти реального режима (<адрес> = <16-ти битный адрес сегмента> * 16 + <16-ти битный адрес смещения>) позволяет адресовать несколько больше, чем 1 Мб. Например, так:
FFFFh * 16 + 11h = FFFF0h + 11h = 100001h
В подобной ситуации 8086 будет обращаться к младшим байтам всё того же первого мегабайта, а 80286 – к младшим байтам второго. Отличие вызвано тем, что 8086 при всём желании не может выставить на свою 20-ти разрядную адресную шину 1 в 20-ом разряде (они тоже нумеруются от 0), а 80286 не только может, но и выставляет.
Программисты всего мира с восторгом приветствовали эту ошибку: ещё бы, почти 64 Кб дополнительной оперативной памяти! И, когда разработчики процессора спохватились, было поздно – ошибка уже широко использовалась. В результате ошибка стала «особенностью» (it is not a bug, it is a feature), а для полной совместимости с 8086 в процессор был добавлен вентиль A20 (gate A20), принудительно обнуляющий 20-й бит шины адреса.
По умолчанию вентиль A20 закрыт, поэтому перед работой с адресами старше 100000h его нужно открыть. Именно для этого предназначена следующая функция:
Примеры
Сегмент данных размером 4 Гб
Простая программка, переводящая процессор в защищенный режим, загружающая FS селектором 4-х гигабайтного сегмента данных и переключающаяся обратно в реальный режим.
После выполнения этой программы можно делать, например, такие вещи:
И оно будет работать! Примерно это и называется unreal-режимом.
Сегмент кода
С сегментом кода есть одна проблема: после переключения, выполнение должно продолжаться с того адреса, с которого нужно, а не с того, с которого получится. Проиллюстрировать проблему может следующий кусок псевдокода:
Поскольку программа загружается DOS по произвольному адресу, адрес next_command_PM не известен на этапе компиляции, и мы не можем просто прописать какие-то константы в качестве базового адреса сегмента и смещения. Есть два решения:
Зафиксировать смещение, во время выполнения вычислять и устанавливать базовый адрес сегмента кода.
Зафиксировать базовый адрес сегмента кода, во время выполнения вычислять и устанавливать смещение.
В примерах продемонстрированы оба варианта, первый в «практичном» примере, второй – в «пафосном».
ПРИМЕЧАНИЕ
Ещё один вариант – писать exe-программу, в этом случае загрузчик DOS самостоятельно пропишет вместо имени сегмента адрес его начала. Но, поскольку exe-программы несколько сложнее, да и не должен разработчик ОС рассчитывать на присутствие в памяти DOS и его умного загрузчика, этот вариант не рассматривается.
Кроме того, после возврата в реальный режим необходимо выполнить дальний переход, перезаписывающий CS, иначе в CS останется селектор сегмента, а не адрес. На первый взгляд, ничего страшного в этом нет, но при первом же прерывании содержимое CS будет сохранено в стеке, а при возврате из прерывания оно будет интерпретироваться уже не как селектор, а как адрес сегмента. И, естественно, возврат произойдёт не туда, куда хотелось бы.
[Пафосный вариант] Сегмент кода 4 Гб
Ограничение на размер сегмента данных уже успешно преодолено, осталось повторить это для сегмента кода.
ПРИМЕЧАНИЕ
Совместив эту программу с предыдущей, то есть, установив всем сегментам кода/данных базовый адрес в 0 и размер 4 Gb, можно получить «почти тот самый» плоский режим, используемый современными ОС. Чтобы получить «совсем тот самый» 32-разрядный плоский режим, надо прочитать в приложение о 32-х разрядных сегментах кода.
[Практичный вариант] Сегмент кода 64 Кб
4 Гб это, конечно, здорово, но, поскольку на протяжении курса мы не будем писать таких больших программ, нам нигде не потребуется сегмент кода размером более 64 Кб. Поэтому переключение сегмента кода можно упростить:
ПРИМЕЧАНИЕ
В приведённой ниже реализации, сегмент кода устанавливается практически таким же, какой был в реальном режиме, то есть базовые адреса совпадают, размер 64 Кб. Помимо того, что в результате упрощается переключение, имеется ещё один приятный побочный эффект: смещения команд при переключении сегментов останутся неизменными, а значит, вычисленные компоновщиком адреса останутся правильными. Это тоже упрощает программу.
Компьютерная Энциклопедия
Вы здесь: Главная Память. Верхний уровень Трансляция адреса в защищенном режиме в проц-х x86 Трансляция адреса в защищенном режиме (сегментный механизм)
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
Арифметико логическое устройство (АЛУ)
Страничный механизм в процессорах 386+. Механизм трансляции страниц
Организация разделов на диске
Диск Picture CD
White Book/Super Video CD
Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
Карты PCMCIA: интерфейсы PC Card, CardBus
Таблица дескрипторов прерываний
Разъемы процессоров
Интерфейс Slot A
Память. Верхний уровень
Трансляция адреса в защищенном режиме (сегментный механизм)
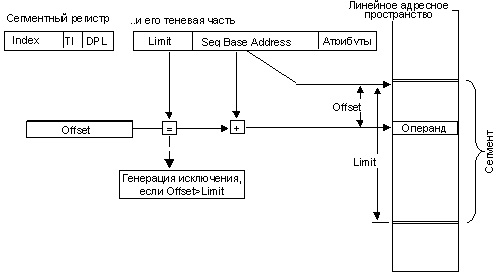
В защищенном режиме схема вычисления линейного адреса аналогична схеме реального режима в том отношении, что линейный адрес, как и в реальном режиме, получается сложением базового адреса сегмента и значения offset (см. рисунок ниже).
Разница состоит в следующем:
1) Базовый адрес каждого из шести сегментов хранится в не видимом программисту (теневом) «продолжении» соответствующего сегментного регистра и имеет длину 32 бита (4 байта). Теневая часть сегментного регистра имеет длину 8 байтов (64 бита).
2) Логический адрес (offset), как для кода, так и для данных, — имеет длину 32 бита (4 байта).
3) Диапазон значений линейных адресов определяется длиной линейного адреса, которая также составляет 32 бита. Таким образом, базовый адрес задает положение начала сегмента, которое может располагаться в любом месте диапазона линейных адресов.
4) Длина сегмента в защищенном режиме не фиксирована, а задается 20-битовым полем Limit (предел), которое вместе с базовым адресом находится в теневой части сегментного регистра. Длина сегмента может иметь величину от 1 байта до 4 Гбайтов.
5) При выполнении команды процессор сравнивает значение offset с длиной сегмента. Если величина offset превышает размер сегмента (т.е. программа пытается обратиться за границу сегмента), выполнение данной команды останавливается и генерируется прерывание по исключительной ситуации.
6) Если предел не превышен, то вычисляется линейный адрес, и выполнение команды продолжается (и завершается).
Схема использования теневой части сегментного регистра
Кроме базового адреса (32 бита) и длины сегмента (20 битов), в теневой части каждого сегментного регистра хранится еще ряд характеристик (атрибутов) данного сегмента. Они, в совокупности с базовым адресом и длиной, образуют дескриптор (описатель) сегмента.
Для работы одной программы необходимо определить хотя бы четыре сегмента:
•сегмент кода cs, •сегмент стека ss, •два сегмента данных ds и es.
Однако защищенный режим процессоров х86 предназначен для многозадачной работы, когда в памяти ЭВМ одновременно находятся и попеременно (во времени) выполняются несколько программ. Дескрипторы сегментов программ формируются операционной системой в специальных системных структурах данных (дескрипторных таблицах) при подготовке программы к выполнению. Дескрипторные таблицы постоянно хранятся в ОЗУ.
При загрузке ОС вначале работают программы реального режима, котрые создают дескрипторные таблицы и определяют дескрипторы для компонентов ОС, после чего процессор переводится в защищенный режим.
При последующей работе ОС для каждой загружаемой программы определяет несколько сегментов, для каждого сегмента заводит дескриптор и задает для сегмента длину и атрибуты. В ходе попеременной работы нескольких программ часть этих сегментов (или даже все) оказываются загруженными в ОЗУ. Для всех сегментов, загруженных в ОЗУ, операционная система определяет и записывает в дескриптор базовый адрес в линейном адресном пространстве.
Каждая задача, выполняемая на компьютере, может иметь собственную локальную дескрипторную таблицу (Local Descriptor Table, LDT), содержащую описания сегментов (а также и других объектов), доступных только этой задаче. Кроме того, имеется одна глобальная дескрипторная таблица (Global Descriptor Table, GDT), которая содержит описания сегментов, потенциально доступных любой задаче. Каждый из шести сегментных регистров содержит двоичное слово, называемое селектором сегмента (детали см. далее). Селектор сегмента однозначно задает дескриптор сегмента, который используется процессором в данный момент.
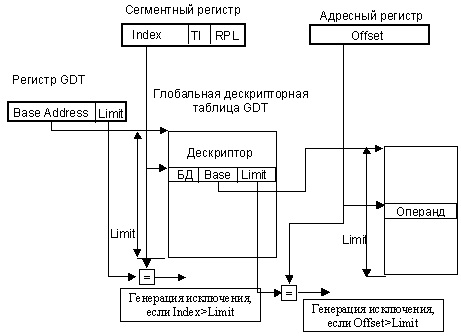
Схема трансляции адреса с использованием GDT приведена на рисунке ниже.
Схема трансляции адреса с использованием GDT
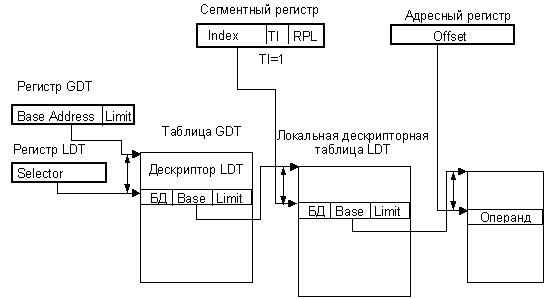
Схема трансляции адреса с использованием LDT приведена ниже.
Схема трансляции адреса с использованием LDT
Рассмотрим форматы отдельных элементов. Формат селектора сегмента представлен на рисунке ниже.
Формат селектора сегмента
Поле INDEX указывает номер дескриптора в таблице дескрипторов. Таблица дескрипторов также представляет собой сегмент размером до 64 Кбайт и может содержать до 8192 элементов.
Поле TI (Table Indicator) выбирает одну из двух дескрипторных таблиц: глобальную GDT или локальную LDT. Каждой задаче могут быть доступны две дескрипторные таблицы, а общее максимальное количество сегментов составляет 16384. (Следует помнить, что часть дескрипторов всегда занята под служебные нужды, сами дескрипторные таблицы тоже представляют собой сегменты, нулевой дескриптор в таблице не допускается использовать, и т.п.)
Двухбитовое поле RPL указывает запрошенный программой уровень привилегий (см. далее) и используется при защите памяти.
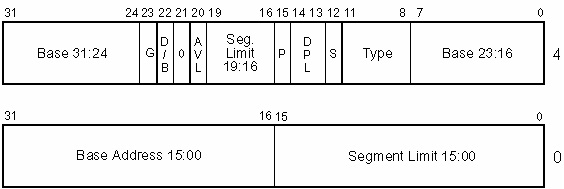
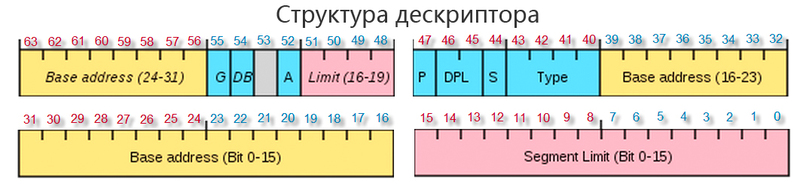
Рассмотрим подробнее формат дескриптора сегмента (см. рисунок ниже).
Формат дескриптора сегмента
32-битовое поле базового адреса используется при вычислении линейного адреса в соответствии с вышеприведенной схемой.
20-битовое поле предела (Segment Limit) содержит размер сегмента. В зависимости от значения бита G (Granularity), этот размер может быть указан в байтах (при G=0 — максимальный размер сегмента 1Мбайт), либо в 4К-страницах (при G=1 — максимальный размер сегмента 2 12 2 20 = 4Гбайт). Таким образом, размер сегмента может быть задан в пределах от 1 байта до 4 Гбайт (в отличие от реального режима, где размер сегмента равен 216 байт и фиксирован).
Однобитовый признак размера операнда D/B задает размер операнда по умолчанию, используемого командой при обращении к данному сегменту.
Двухбитовое поле уровень привилегий сегмента DPL (Descriptor Privilege Level) используется механизмом защиты памяти.
Бит присутствия P (Segment Present). Бит присутствия может быть установлен либо сброшен программно, аппаратно только анализируется его состояние. Нулевое значение этого бита при обращении к сегменту вызывает прерывание по исключительной ситуации. Этот бит может быть использован разработчиком операционной системы для «маркировки» сегментов, загруженных в данный момент в физическую память. Этот бит, в частности, может быть использован для органиации виртуальной памяти на уровне замены сегментов.
Бит S равен 0 в дескрипторах сегментов, содержащих код или данные и равен 1 для системных дескрипторов (описывающих сегменты, содержащие дескрипторные таблицы, а также еще ряда других, которые будут рассмотрены позже).
Поле TYPE в дескрипторах системных сегментов обозначает один из 12 возможных типов, а в дескрипторах сегментов кода или данных на этом месте содержатся дополнительные битовые поля, которые будут далее рассмотрены.
Байт, включающий поля P, DPL, S, TYPE носит название байт доступа. Бит 21 старшего слова дескриптора имеет предопределенное значение 0, а бит AVL может использоваться системным ПО как флаг общего назначения.
При рассмотрении механизма формирования линейного адреса при трансляции сегмента возникают следующие вопросы:
1) Откуда берутся дескрипторные таблицы и конкретные значения полей в дескрипторах?
2) Базовые адреса сегментов хранятся в дескрипторах, находящихся в дескрипторной таблице в основной памяти. Если в ходе трансляции сегментов при выполнении каждой команды требуется (возможно неоднократно) обращаться за значениями базовых адресов в основную память, команды в защищенном режиме должны выполняться гораздо медленнее, нежели в реальном. Так ли это?
Ответим на эти вопросы.
Дескрипторные таблицы создаются и заполняются при инициализации операционной среды компонентами операционной системы. Это означает, что, если в реальном режиме процессор способен немедленно после включения выбирать (fetch) и выполнять команды, то для того, чтобы выполнить хотя бы одну команду в защищенном режиме, должна быть создана хотя бы одна дескрипторная таблица (GDT), содержащая хотя бы один дескриптор, описывающий сегмент с кодом программы, а, если в программе содержатся команды обращения к памяти, то требуется наличие еще одного дескриптора, описывающего сегмент данных.
Для ускорения процедуры трансляции сегментов, как уже было отмечено, дескрипторы сегментов, селекторы которых загружены в сегментные регистры, скопированы в невидимые «теневые» 8-байтовые «продолжения» сегментных регистров. Именно из теневых частей (быстро !) извлекается значение базового адреса при трансляции сегмента (см. рисунок ниже).
Теневые части сегментных регистров
Когда происходит загрузка дескриптора в теневой регистр? Это происходит при выполнении команд, изменяющих содержимое «обычных» сегментных регистров (команды mov seg_reg, reg; lds; les; lfs, lgs, lss, jmp far, call far, int n,…). При выполнении подобных команд в защищенном режиме, процессор не только помещает новое значение (селектор сегмента) в видимую часть сегментного регистра, но и загружает из соответствующей дескрипторной таблицы восьмибайтовый дескриптор в теневую часть сегментного регистра. Вследствие этого команды, изменяющие содержимое сегментных регистров в защищенном режиме выполняются значительно дольше, чем в реальном.
Как процессор находит дескриптор? Для этого ему надо знать адрес начала (базовый адрес) дескрипторной таблицы и расположение в ней нужного дескриптора (смещение). Индекс дескриптора содержится в селекторе, загружаемом в сегментный регистр. Для хранения базовых адресов дескрипторных таблиц в архитектуру процессоров 386+ было введено несколько новых регистров GDTR, LDTR, IDTR, TR (см. рисунок ниже). Рассмотрим их назначение.
Системные адресные регистры
Глобальная дескрипторная таблица хранится в отдельном сегменте памяти. 32-битовый базовый адрес этого сегмента и его 16-битовая длина хранятся в регистре GDTR (Global Descriptor Table Register). Таким образом, максимальная длина таблицы составляет 64 Кбайт, в ней может максимально содержаться 8192 дескриптора.
Локальные дескрипторные таблицы могут создаваться индивидуально для каждой задач. Каждая локальная дескрипторная таблица также хранится в отдельном сегменте, который описывается дескриптором, хранимым в GDT. При запуске данной задачи ее локальная дескрипторная таблица активизируется путем записи селектора ее дескриптора в 16-битовый регистр LDTR (Local Descriptor Table Register). При этом автоматически загружается теневая часть этого регистра, куда переносятся из GDT базовый адрес LDT и ее предел, а также битовые поля атрибутов сегмента.
Регистр IDTR (Interrupt Descriptor Table Register) хранит базовый адрес и длину сегмента, содержащего таблицу дескрипторов прерываний. Дескриптор прерывания выполняет в защищенном режиме те же функции, что вектор прерывания в реальном режиме.
Наконец, регистр задачи TR (Task Register) содержит селектор сегмента задачи TSS (Task State Segment). Его назначение рассматривается в разделе, посвященном поддержке многозадачности.
Рассмотрим более подробно схему обращения к памяти в защищенном режиме.
1) После получения команды на запуск программы операционная система загружает в память первый сегмент кода программы, заполняет в соответствующем дескрипторе поля базы и предела, устанавливает в 1 бит присутствия, а затем передает управление на первую команду программы. При этом перезагружается новым значением селектора сегментный регистр cs. Используя поле index этого селектора, процессор находит в дескрипторной таблице дескриптор соответствующего сегмента кода и переносит его в теневую часть регистра cs.
2) Положение объекта (команды или элемента данных) в памяти задается парой значений seg:offset. Значение seg — селектор сегмента — находится в сегментном регистре. Значение offset для выборки команды берется из счетчика команд, а для элемента данных аппаратно вычисляется процессором в соотвествии с используемым способом адресации. При обращении к памяти, процессор вычисляет линейный адрес. Для этого он складывает значение базового адреса сегмента (из теневой части сегментного регистра) со значением offset и производит обращение к памяти.
3) Если при выполнении команды оказывается, что сегмент, индекс которого используется в команде, отстутствует в памяти (процессор «узнает» об этом, проверяя значение бита присутствия), происходит прерывание по исключительной ситуации. Управление передается операционной системе, и она переносит недостающий сегмент в память с диска, заполняет поля базы и предела в дескрипторе, устанавливает в 1 бит присутствия, а затем (возвратом из прерывания) возвращает управление на ту же команду. Теперь эта команда может выполниться до конца.
4) При выполнении каждой команды аппаратура процессора проверяет выполнение ряда условий (наличие сегмента в памяти — одно из этих условий). Если условие не выполняется, то выполнение команды прекращается и происходит прерывание по исключительной ситуации — это общий принцип срабатывания механизмов защиты.
Сегментный механизм можно использовать для организации виртуальной памяти. Однако это оказалось очень неудобным, так как обычно сегменты имеют разный размер и располагаются в памяти с произвольного адреса. При свопинге (замене) сегментов пространство памяти вследствие этого фрагментируется и, тем самым, расходуется нерационально. Сегментный механизм появился в семействе х86, начиная с модели i80286. Однако работоспособной ОС с виртуальной памятью на базе этого процессора, которая стала бы сколько-нибудь популярной, так и не было разработано. В процессорах 386+ в дополнение к сегментному механизму был разработан страничный механизм трансляции адресов (см далее).
Оценим, каков максимальный размер логического адресного пространства, которым может обладать задача.
Задаче могут быть доступны две дескрипторные таблицы: GDT и LDT, каждая из которых может содержать до 8192 (2 13 ) дескрипторов сегментов. Каждый сегмент может иметь размер до 4 Гбайт (2 32 байт). Таким образом, ограничение сверху на размер логического адресного пространства составляет 2+2 13 +2 32 =2 46 байт.
Естественно, такой объем еще весьма долго не сможет целиком поместиться в физической памяти компьютера (для процессоров х86 ее размер ограничен величиной 2 32 байт). Однако при наличии виртуальной памяти ограничение размера физической памяти лишь замедлит выполнение очень большой программы (за счет потерь на обмен сегментов между памятью и диском).
ЧИТАТЬ КНИГУ ОНЛАЙН: Аппаратные интерфейсы ПК. Энциклопедия
Книга «Интерфейсы ПК. Справочник», вышедшая следом за первым изданием энциклопедии «Аппаратные средства IBM PC» (1998 г.), была благосклонно принята читателями и даже выпущена «пиратами» на компакт-диске (правда, без указания автора и, естественно, без его уведомления). Работа над вторым изданием энциклопедии породила гору материала, который не помещался в книгу разумного размера, — так созрела идея новой книги об интерфейсах, которая сейчас перед вами. В нее вошли все «обрезки» «слишком большой энциклопедии» и ряд новых материалов. Эта книга адресована специалистам, которые уже знают общее устройство компьютера и имеют представление о взаимодействии его составляющих, но нуждаются в справочной информации для разработки собственной аппаратуры и программного обеспечения, тесно связанного с «железом». Название «Аппаратные интерфейсы ПК» определяет круг освещаемых вопросов — от ножек интерфейсных разъемов до программной модели интерфейсных адаптеров.
Книга начинается с глав, посвященных универсальным внешним интерфейсам, начиная с долгожителей — портов LPT и СОМ — и кончая современными шинами USB, Fire Wire, SCSI и беспроводными интерфейсами IrDA и Bluetooth. Далее идет «погружение в недра» системного блока ПК — интерфейсы шин расширения с особо детальным описанием шин PCI и ISA, самых интересных на сегодняшний день (шину ISA списывать рано, она еще послужит во встраиваемых компьютерах в обычном виде или в виде PC/104). В главе, посвященной интерфейсам электронной памяти, подробно рассматриваются модули динамической памяти всех современных типов, а также микросхемы статической и энергонезависимой памяти (флэш, EEPROM), с которыми часто приходится иметь дело. Далее в книге описываются специализированные интерфейсы периферийных устройств — клавиатуры, мыши, дисплея (как традиционного, так и плоских панелей), принтеров, аудио- и видеоинтерфейсы, игровой порт. Отдельная глава посвящена интерфейсам устройств хранения — НГМД, ATA (включая новый интерфейс Serial ATA), а также интерфейсам твердотельных устройств хранения (различным флэш-картам). Из интерфейсов компьютерных сетей основное внимание уделяется технологии Ethernet, практически вытеснившей все остальные из локальных сетей и ведущей наступление и в глобальных приложениях. Также рассматривается интерфейс обычной аналоговой телефонной линии, через которую большинство домашних пользователей подключается к Сети. В главе о вспомогательных последовательных интерфейсах рассматриваются все вариации на тему I²C, а также интерфейсы SPI, MII и JTAG. Отдельная глава посвящена архитектурному окружению, в котором интерфейсы и их адаптеры (контроллеры) существуют в IBM PC-совместимом компьютере (пространство памяти, пространство ввода-вывода, прерывания), и нюансам, связанным с различными режимами работы процессоров x86. В этой же главе описываются сервисы и модули расширения BIOS, а также способы загрузки ПО, позволяющие собирать специализированные бездисковые контроллеры на базе универсальных компонентов. Как обычно, книгу завершает тема правильного питания и электробезопасности. Для удобства восприятия в книге принята система текстовых выделений. Курсивом выделены ключевые слова (например, первый раз встречающиеся определения), а также названия состояний , в которых могут пребывать некоторые объекты. В названиях электрических сигналов, например CSO# , символ « # » указывает на инверсность (низкий уровень сигнала отвечает активному состоянию). Названия команд, регистров и битов имеют иной вид — например, INSW (команда процессора), DR (регистр данных), АХ (регистр процессора). Подробные оглавление и предметный указатель помогут быстро найти необходимую информацию.
Я благодарен любознательным и внимательным читателям, присылающим свои замечания, вопросы и отзывы о моих книгах. Пользуясь случаем, еще раз обращаюсь к читателям — пишите письма! С вашей помощью исправляются многие ошибки, и я стараюсь поддерживать свои книги на личном сайте по адресу http://www.neva.ru/mgook, обновляя списки замеченных опечаток и публикуя статьи на смежные темы.
Как и все предыдущие, эта книга не смогла бы появиться без информационной поддержки коллектива RUSNet (http://www.neva.ru), обеспечивающего доступ к Сети в ЦНИИ РТК — «базовом лагере» автора. После выпуска второго издания «Энциклопедии» я снова погрузился в инженерную деятельность в НПО РТК. Это несколько притормаживает работу над книгами, но обогащает практический опыт, что выливается в дополнительные разъяснения актуальных вопросов.
Свои замечания и пожелания присылайте на адрес mgook@stu.neva.ru (автор) или comp@piter.com (издательство «Питер», редакция компьютерной литературы). Информацию по всем книгам можно получить на сайте издательства «Питер» www.piter.com.
Толковый словарь по вычислительным системам определяет понятие интерфейс (interface) как границу раздела двух систем, устройств или программ; элементы соединения и вспомогательные схемы управления, используемые для соединения устройств. Эта книга посвящена интерфейсам, позволяющим подключать к персональным (и не только) компьютерам разнообразные периферийные устройства (ПУ) и их контроллеры, а также соединять отдельные подсистемы компьютера. Рассмотрим вкратце основные свойства интерфейсов.
По способу передачи информации интерфейсы подразделяются на параллельные и последовательные. В параллельном интерфейсе все биты передаваемого слова (обычно байта) выставляются и передаются по соответствующим параллельно идущим проводам одновременно. В PC традиционно используется параллельный интерфейс Centronics, реализуемый LPT-портами, шины ATA, SCSI и все шины расширения. В последовательном интерфейсе биты передаются друг за другом, обычно по одной (возможно, и двухпроводной) линии. Эта линия может быть как однонаправленной (например, в RS- 232C, реализуемой СОМ-портом, шине Fire Wire, SPI, JTAG), так и двунаправленной (USB, I²C).
При рассмотрении интерфейсов важным параметром является пропускная способность. Технический прогресс приводит к неуклонному росту объемов передаваемой информации. Если раньше матричные принтеры, печатающие в символьном режиме, могли обходиться и СОМ-портом с невысокой пропускной способностью, то современным лазерным принтерам при высоком разрешении не хватает производительности даже самых быстрых LPT-портов. То же касается и сканеров. А передача «живого» видео, даже с применением компрессии, требует ранее немыслимой пропускной способности.
Вполне очевидно, что при одинаковом быстродействии приемопередающих цепей и пропускной способности соединительных линий по скорости передачи параллельный интерфейс должен превосходить последовательный. Однако повышение производительности за счет увеличения тактовой частоты передачи данных упирается в волновые свойства соединительных кабелей. В случае параллельного интерфейса начинают сказываться задержки сигналов при их прохождении по линиям кабеля и, что самое неприятное, задержки в разных линиях интерфейса могут быть различными вследствие неидентичности проводов и контактов разъемов. Для надежной передачи данных временные диаграммы обмена строятся с учетом возможного разброса времени прохождения сигналов, что является одним из факторов, сдерживающих рост пропускной способности параллельных интерфейсов. В последовательных интерфейсах, конечно же, есть свои проблемы повышения производительности, но поскольку в них используется меньшее число линий (в пределе — одна), повышение пропускной способности линий связи обходится дешевле.


 Компьютерная Энциклопедия
Компьютерная Энциклопедия