Удаление неявных дубликатов Series
Добрый день! В спойлере список названий населенных пунктов. Подскажите пожалуйста как можно грамотно подойти к вопросу удаления неявных дубликатов в этом наборе? Есть поселок Рябово и поселок городского типа Рябово. И это одно и тоже название. Ну и возможно есть другие сходства. Естественно букву ё везде заменил на е и привел всё к нижнему регистру. NaN заменил на ‘unknown’.
Удаление дубликатов в массиве
Мне надо вывести массив без повторений с самого правого вхождения. входные данные 6 1 5 5 1 6 1.
Удаление дубликатов из массива словарей
Всем добрый день! Пытаюсь удалить дубликаты по name и gender в словаре l l= for i in.
Поиск в папке дубликатов и их удаление
Добрый день! Пишу программу, целью которой является поиск в папке дубликатов и их удаление.
 Удаление из строки пробелов и дубликатов
Удаление из строки пробелов и дубликатов
Задача: Вводится строка. Требуется удалить из нее повторяющиеся символы и все пробелы. Без.
Удаление дубликатов строк из файла
есть два списка доменов list1 и list2 list1 — список на 10+ млн list2 — каждый раз новый нужно.
Python: поиск и удаление дубликатов используя pandas
Рассмотрим поиск и удаление дубликатов в следующем наборе данных:
Преобразуем данную структуру данных в датафрейм используюя библиотеку pandas.
Поиск дубликатов в датафрейме
В pandas есть встроенная функция duplicated() для поиска дубликатов в датафрейме.
Вариант «по-умолчанию» предполагает, что поиск дубликатов будет осуществлен построчно, где для каждой строки будут проверяться совпадения во всех ее колонках. На выходе вы получите срез датафрейма, где для каждого индекса будет проставлен в формате bool признак о найденном совпадении:
Как видите, каждая следующая запись, определенная как дубликат, помечается флагом True . Но бывают задачи, в которых требуется считать последнюю найденную запись как «оригинал», а все совпадения которые были до нее считать как «дубликат».
Передача доп. параметра keep=’last’ дает возможность не считать дубликатом только последнюю найденную запись:
А передача доп. параметра keep=False дает возможность отметить дубликатами все записи имеющие совпадения.
Также есть возможность делать проверку на дубликаты при совпадении значений не во всех колонках, а только в определенных, указав их явно при помощи параметра subset . Причем, данный параметр можно указывать совместно с keep .
Как отфильтровать данные без учета дубликатов
Для этого нужно применить стандартный механизм фильтрации данных в датафрейме на основе его признаков. В данном случае признак у нас один — это флаг наличия дубликата в соответствии с индексом наших данных, т.е. то выражение которое мы разбирали выше. Его мы и передадим в датайрейм, поставив перед ним знак
, что означает отфильтровать все записи, которые не являются True (т.е не являются дубликатами). Если же не указать
ЛР / ЛР1 / Лабораторная работа 1
Цель работы: осуществить предварительную обработку данных csv-файла, выявить и устранить проблемы в этих данных.
Краткий теоретический материал
Подготовка данных для анализа называется предобработкой. Аналитик ищет проблемы в данных, оценивает их масштаб и пробует устранить.
Сложности с данными бывают двух видов:
• данные содержат мусор;
• данные корректны, но представлены в такой форме, что малопригодны для анализа.
Принцип GIGO означает буквально «мусор на входе — мусор на выходе (от англ. garbage in — garbage out,»), то есть данные должны быть обработаны.
Какие ошибки могут быть:
— некорректные названия столбцов
— дубликаты в данных
— скрытые повторы (например, одна и та же категория может быть записана по-разному – Фильм или movie, либо семья и СЕМЬЯ).
— аномалии (данные, которые не отражают действительность), например отрицательный возраст
— несоответствие типов данных действительности
Некорректные имена столбцов могут содержать:
— Пробелы в названиях ( Как и в именах переменных, названия столбцов лучше писать без пробелов, в «змеином_регистре»)
— В названиях используют разные языки (буквы легко спутать)
— Слишком непонятные названия столбцов, которые не отражают суть столбца.
Для переименования столбцов вызывают метод датафреймов rename().
У него один параметр columns — это словарь, в котором
• ключи — названия столбцов, которые вы хотите заменить (старые названия столбцов);
• значения — новые названия столбцов.
Переименовать можно как все столбцы датафрейма, так и только отдельные:
Дубликаты в данных Поиск явных дубликатов
Метод duplicated() ищет дубликаты. По умолчанию он признаёт дубликатами те строки, которые полностью повторяют уже встречавшиеся в датасете. Метод возвращает Series со значением True для таких строк.
Чтобы избавиться от таких дубликатов, вызовем метод drop_duplicates():
После удаления строчек лучше обновить индексацию: чтобы в ней не осталось пропусков. Для этого вызовем метод reset_index() . Он создаст новый датафрейм, где:
индексы исходного датафрейма станут новой колонкой с
все строки получат обычные индексы, уже без пропусков.
Поиск неявных дубликатов
Неявные дубликаты можно найти методом unique(). Он возвращает
перечень уникальных значений в столбце: print(df[col1].unique())
Среди уникальных значений ищут неявные дубликаты:
• альтернативные написания одного и того же значения.
Удаление неявных дубликатов
Неправильные и альтернативные написания значений исправляют методом replace() . В первом аргументе ему передают нежелательное значение из таблицы. Во втором — новое значение, которое должно заменить дубликат:
df[‘col1’] = df[‘col1’].replace(‘футбо’, ‘футбол’)
Поиск пропущенных значений
Специальный метод isna() найдёт все пропуски в таблице. Если значение отсутствует, он вернёт True, иначе — False.
Чтобы посчитать пропуски, результат работы isna() передадим методу sum():
В зависимости от целей исследования с пропусками можно обойтись поразному:
• Строки таблицы удаляют полностью , если они потеряли смысл из-за пропущенных значений. Иногда приходится признать, что часть данных бесполезна из-за пропусков — тогда от таких строк остаётся только избавиться.
• Иногда пропуски заполняют другими значениями . Это допустимо,
когда пропущенные значения неважны для целей исследования, но в тех же строках или столбцах остаются ценные данные.
Чтобы не лишиться строк с важными данными, заполним значения NaN в столбце imported_cases нулями.
Для этого вызывают специальный метод fillna(). Он вернёт копию исходного столбца, заменяя все NaN на значение из аргумента:
Метод dropna() удаляет строку или колонку, в которой встречается NaN (хотя бы один пропуск). Его поведением управляют два параметра:
• axis — ось, по которой будет ориентироваться метод. Если передать параметру значение ‘columns’, метод удалит столбцы, в которых встречается NaN. Если не указывать этот аргумент, метод удалит строки, в которых встречается NaN.
• subset — список с названиями столбцов, в которых метод должен искать NaN.
# удаление строк , в которых в столбцах total_cases, deaths или case_fatality_rate встречается NaN
df = df.dropna(subset=[‘total_cases’, ‘deaths’, ‘case_fatality_rate’])
# удаление столбцов , в которых в столбцах total_cases, deaths или case_fatality_rate встречается NaN
df = df.dropna(subset=[‘total_cases’, ‘deaths’, ‘case_fatality_rate’], axis=’columns’)
Категориальные и количественные переменные
Способ работы с пропущенными значениями зависит от их типа. В датафрейме pandas могут содержаться категориальные или количественные данные:
• Категориальная переменная принимает одно значение из ограниченного набора.
• Количественная — любое числовое значение в диапазоне.
В Pandas есть стандартный метод Pandas — to_numeric() , который превращает значения столбца в числовой тип float64 (вещественное число).
Поиск неявных дублей
Неявными дублями называются любые 2 фразы, состоящие из одного набора слов, расположенных в разном порядке.
Инструмент поиска неявных дублей среди фраз в проекте расположен на вкладке «Данные».

Поиск поддерживается в формозависимом или формонезависимом режимах.
Можно указать список исключений (слов, которые будут пропускаться при сравнении фраз), список синонимов (слова или словосочетания, которые будут считаться эквивалентными), а также некоторые другие параметры.
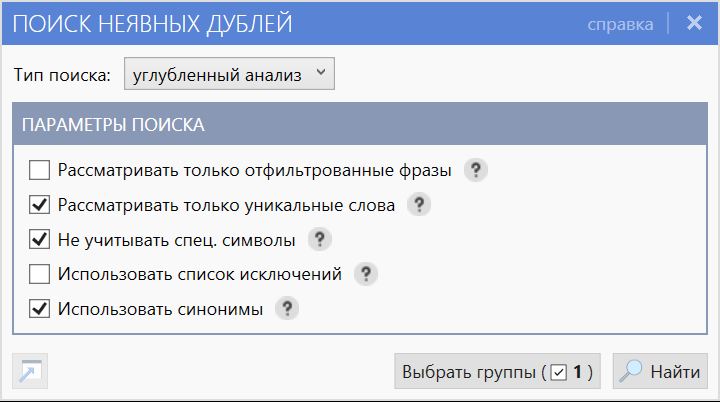
Окно поиска неявных дублей
После завершения поиска отобразятся результаты:
- На главной рабочей области появится новая вкладка «Неявные дубли».
- Внутри этой вкладки отобразится таблица с результатами поиска. В ней будут продублированы все видимые колонки из основной таблицы данных, а также добавлена колонка принадлежности фраз к родительской группе.
- В панели состояния появится блок счетчиков, относящихся к таблице в п.2: кол-во найденных неявных дублей, кол-во отмеченных фраз в таблице и кол-во выделенных фраз.
- В ленте инструментов добавится контекстная вкладка «Неявные дубли — Результаты» с инструментами обработки результатов поиска.
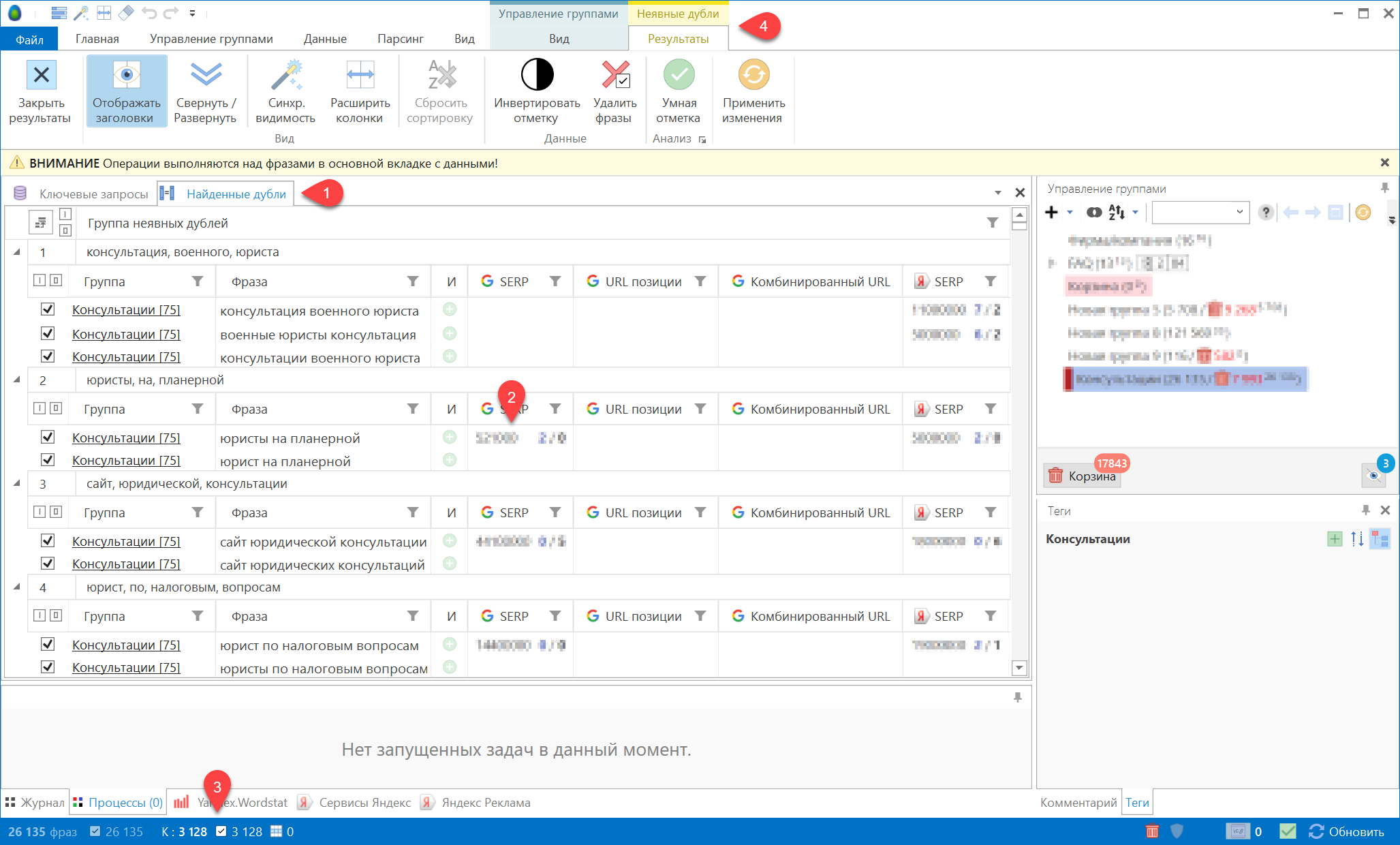
Здесь вы можете просмотреть найденные дубли. При работе с большими списками можно пользоваться фильтрами, а также настраивать внешний вид таблицы.
Далее вы можете отметить неудачные варианты написания фраз и удалить их. Для массовой отметки фраз предусмотрена функция «Умной отметки».
Умная отметка
Функция позволяет выполнить автоматическую отметку фраз в группах неявных дублей на основе заданного списка правил. Для открытия окна настроек нажмите кнопку  в блоке «Анализ».
в блоке «Анализ».

Поддерживаются несколько режимов работы функции, и каждый из них может применяться либо ко всем фразам в блоке дублей, либо для каждой подгруппы фраз в блоке дублей по признаку родительской группы.
Отметить все фразы кроме одной в каждой подгруппе (случайный выбор)
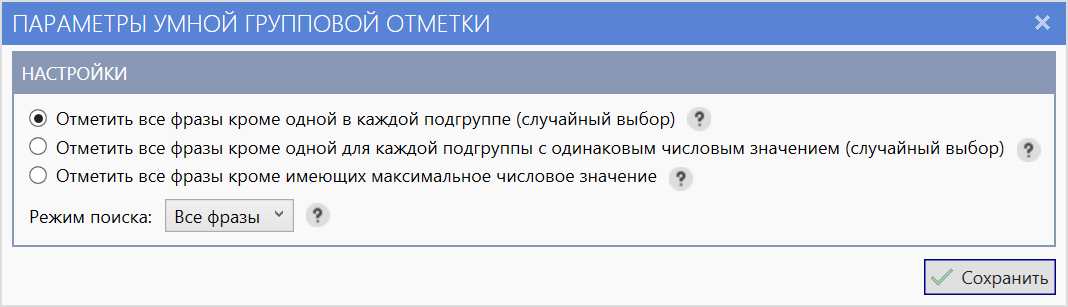
В каждой подгруппе найденных неявных дублей будут отмечены все фразы кроме одной, случайным образом выбранной.
| Фраза | Результат |
|---|---|
| рецепты творожного пирога | Снять отметку (случайный выбор фразы) |
| творожный пирог рецепт | Отметить |
| рецепты пирога творожного | Отметить |
Этот режим может использоваться в случаях, если для вас не важно, какой из вариантов вы бы хотели оставить.
Случайный выбор в подгруппах значений
Отметить все фразы кроме одной для каждой подгруппы с одинаковым числовым значением (случайный выбор)
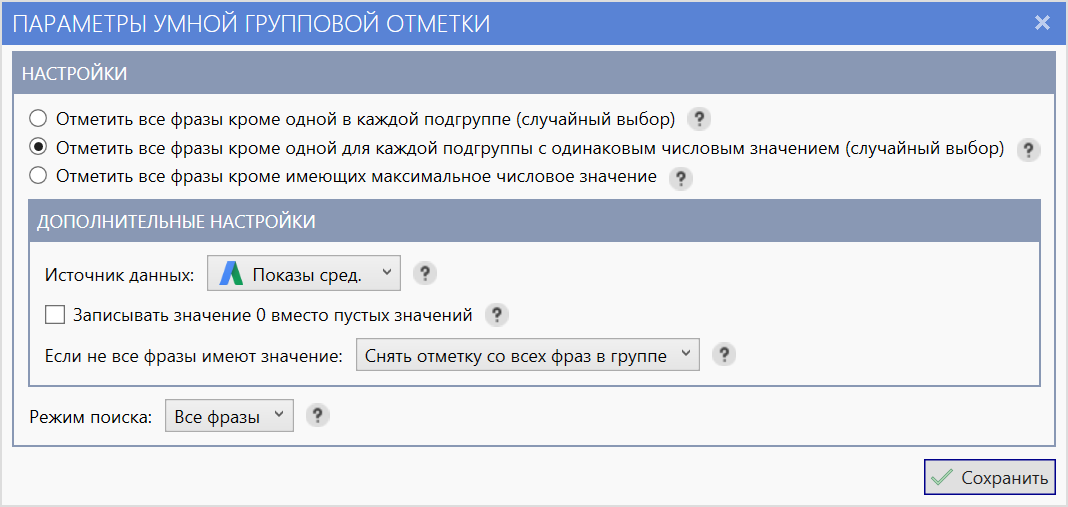
Фразы в каждой подгруппе найденных неявных дублей группируются по приоритетному значению выбранной колонки-источника. Далее в каждой такой подгруппе по значению отмечаются все фразы кроме одной, случайным образом выбранной.
| Фраза | Выбранное значение | Результат |
|---|---|---|
| рецепты творожного пирога | 3500 | Снять отметку (случайный выбор фразы) |
| творожный пирог рецепт | 2400 | Отметить |
| рецепты пирога творожного | 3500 | Отметить |
| творожный рецепт пирог | 2400 | Снять отметку (случайный выбор фразы) |
Основным отличием этого режима от предыдущего является то, что он работает только для равных по выбранному значению колонки-источника фраз.
Выбор минимальных значений
Отметить все фразы кроме имеющих максимальное числовое значение
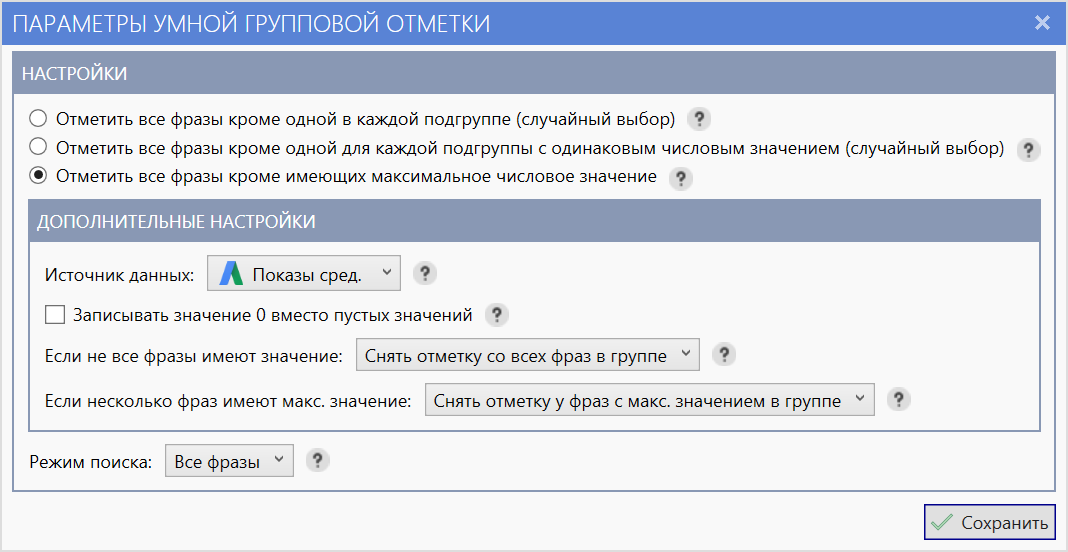
Отмечаются все фразы в каждой подгруппе найденных неявных дублей кроме тех, которые имеют максимальное приоритетное значение по выбранной колонке-источнику.
| Фраза | Выбранное значение | Результат |
|---|---|---|
| рецепты творожного пирога | 3500 | Снять отметку (макс. значение) |
| творожный пирог рецепт | 2400 | Отметить |
| рецепты пирога творожного | 3500 | Снять отметку (макс. значение) |
| творожный рецепт пирог | 2400 | Отметить |
Режим используется в случае, когда нужно удалить наиболее «слабые» варианты фраз и оставить только самые «сильные».
Применение изменений
После выполнения отметки и удаления фраз необходимо зафиксировать изменения в проекте.
До тех пор пока вы не нажмете кнопку «Применить изменения», выставленный статус отметки для фраз не запишется в проект, а удаленные фразы не удалятся из реальных групп в проекте.
Анализ групп
Пришло время познакомиться с мощным инструментом анализа групп, который позволяет автоматически сгруппировать фразы и создать структуру.