Парсинг нетабличных данных с сайтов
С загрузкой в Excel табличных данных из интернета проблем нет. Надстройка Power Query в Excel легко позволяет реализовать эту задачу буквально за секунды. Достаточно выбрать на вкладке Данные команду Из интернета (Data — From internet) , вставить адрес нужной веб-страницы (например, ключевых показателей ЦБ) и нажать ОК:
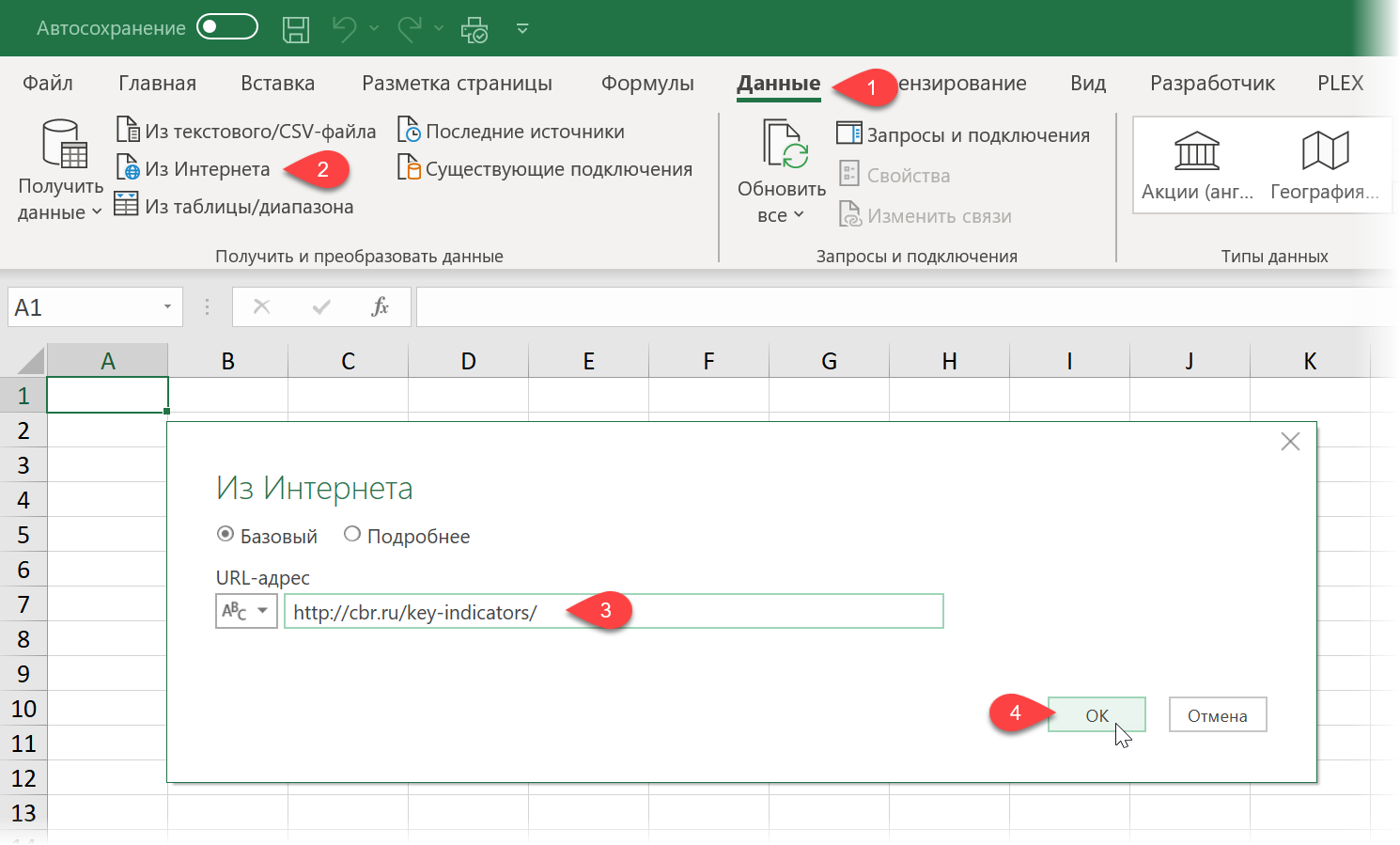
Power Query автоматически распознает все имеющиеся на веб-странице таблицы и выведет их список в окне Навигатора:
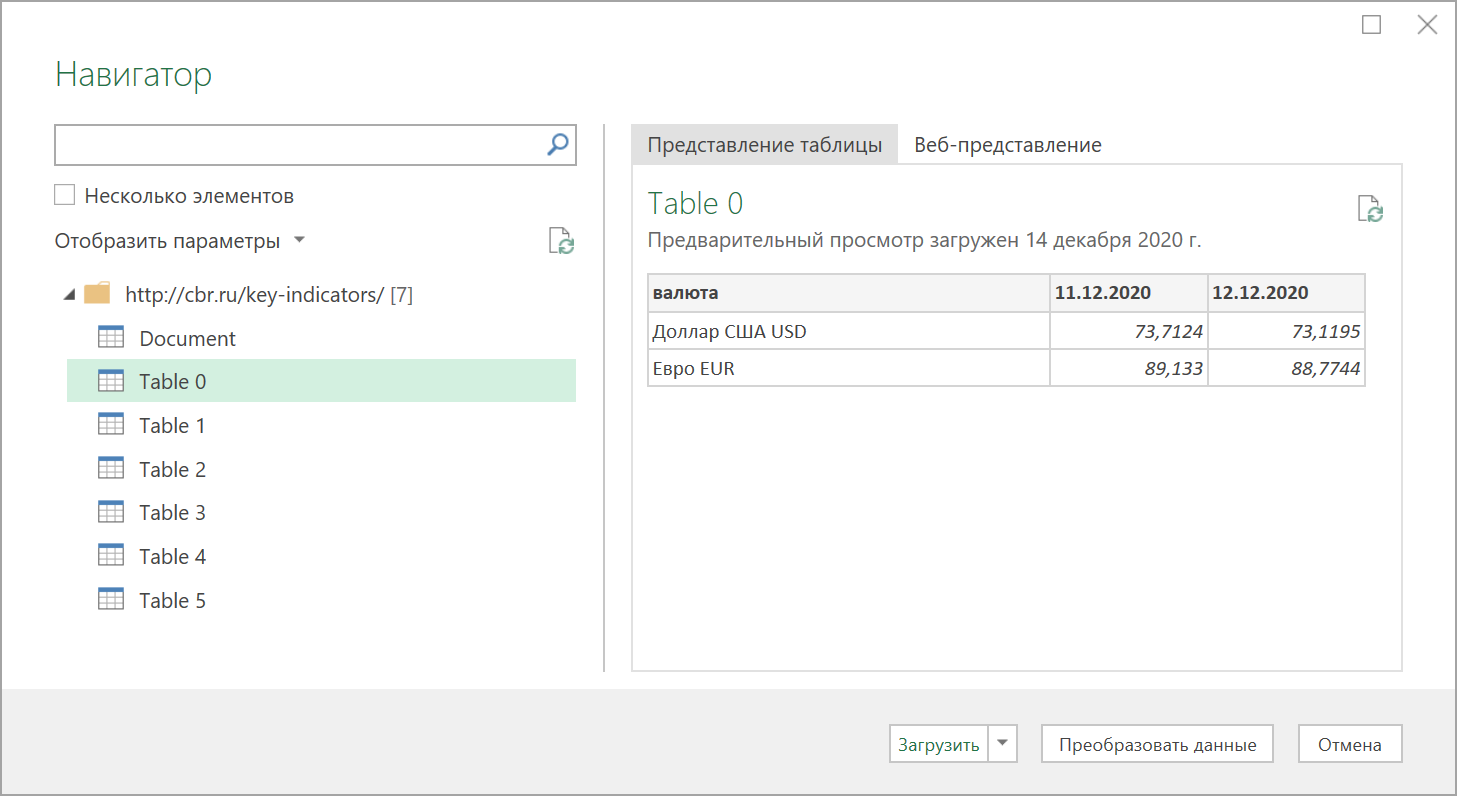
Дальше останется выбрать нужную таблицу методом тыка и загрузить её в Power Query для дальнейшей обработки (кнопка Преобразовать данные) или сразу на лист Excel (кнопка Загрузить).
Если с нужного вам сайта данные грузятся по вышеописанному сценарию — считайте, что вам повезло.
К сожалению, сплошь и рядом встречаются сайты, где при попытке такой загрузки Power Query «не видит» таблиц с нужными данными, т.е. в окне Навигатора попросту нет этих Table 0,1,2. или же среди них нет таблицы с нужной нам информацией. Причин для этого может быть несколько, но чаще всего это происходит потому, что веб-дизайнер при создании таблицы использовал в HTML-коде страницы не стандартную конструкцию с тегом <TABLE>, а её аналог — вложенные друг в друга теги-контейнеры <DIV>. Это весьма распространённая техника при вёрстке веб-сайтов, но, к сожалению, Power Query пока не умеет распознавать такую разметку и загружать такие данные в Excel.
Тем не менее, есть способ обойти это ограничение 😉
В качестве тренировки, давайте попробуем загрузить цены и описания товаров с маркетплейса Wildberries — например, книг из раздела Детективы:
Загружаем HTML-код вместо веб-страницы
Сначала используем всё тот же подход — выбираем команду Из интернета на вкладке Данные (Data — From internet) и вводим адрес нужной нам страницы:
После нажатия на ОК появится окно Навигатора, где мы уже не увидим никаких полезных таблиц, кроме непонятной Document:
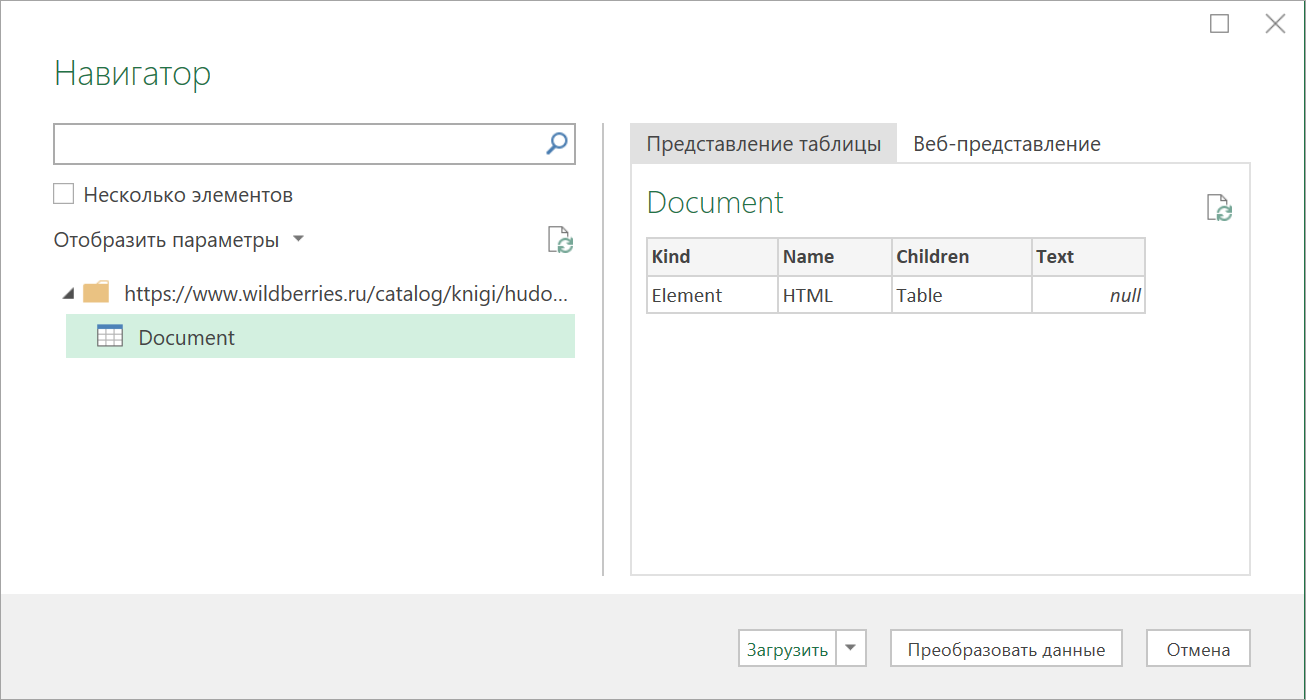
Дальше начинается самое интересное. Жмём на кнопку Преобразовать данные (Transform Data) , чтобы всё-таки загрузить содержимое таблицы Document в редактор запросов Power Query. В открывшемся окне удаляем шаг Навигация (Navigation) красным крестом:
. и затем щёлкаем по значку шестерёнки справа от шага Источник (Source) , чтобы открыть его параметры:
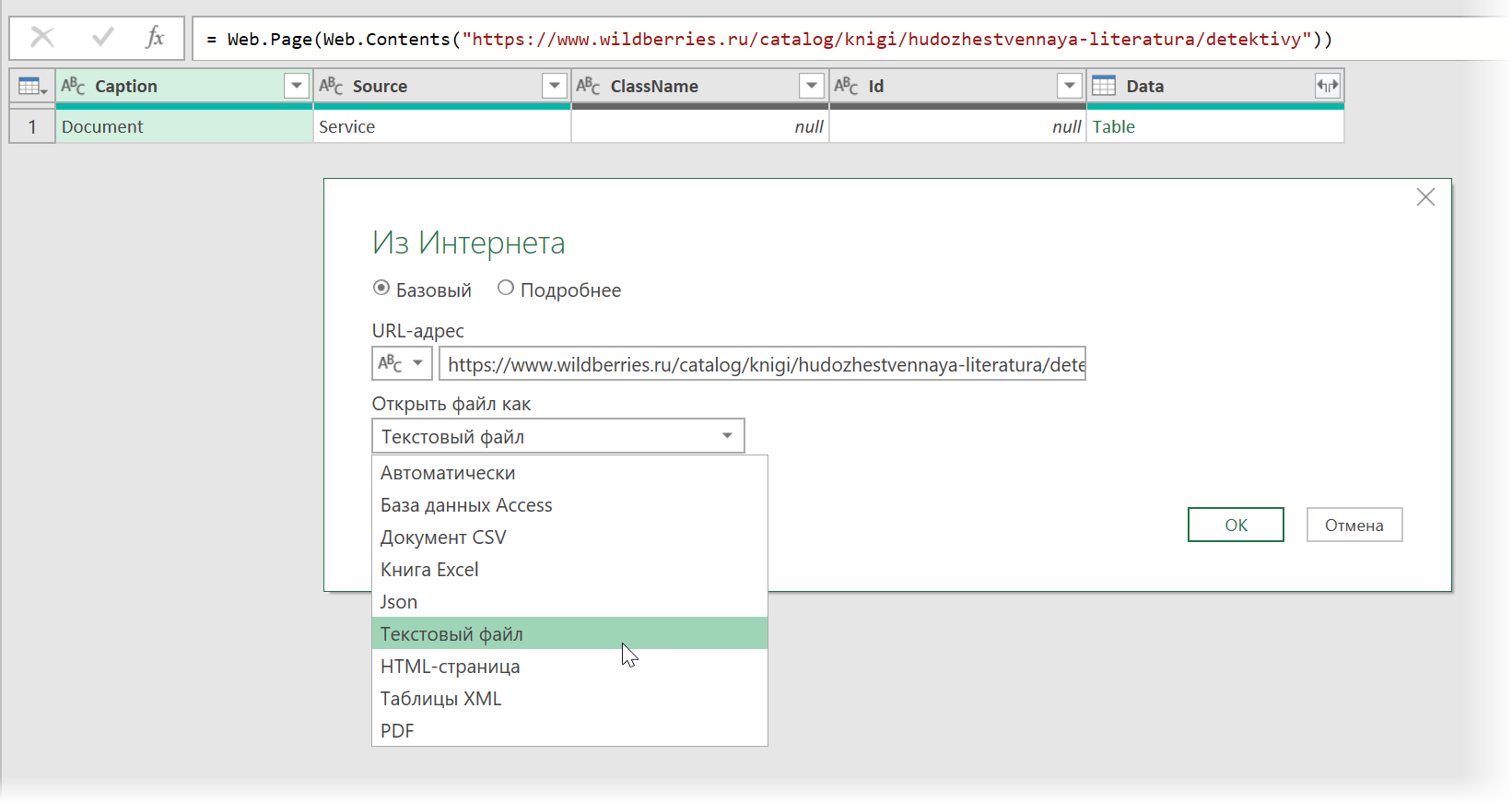
В выпадающием списке Открыть файл как (Open file as) вместо выбранной там по-умолчанию HTML-страницы выбираем Текстовый файл (Text file) . Это заставит Power Query интерпретировать загружаемые данные не как веб-страницу, а как простой текст, т.е. Power Query не будет пытаться распознавать HTML-теги и их атрибуты, ссылки, картинки, таблицы, а просто обработает исходный код страницы как текст.
После нажатия на ОК мы этот HTML-код как раз и увидим (он может быть весьма объемным — не пугайтесь):
Ищем за что зацепиться
Теперь нужно понять на какие теги, атрибуты или метки в коде мы можем ориентироваться, чтобы извлечь из этой кучи текста нужные нам данные о товарах. Само-собой, тут всё зависит от конкретного сайта и веб-программиста, который его писал и вам придётся уже импровизировать.
В случае с Wildberries, промотав этот код вниз до товаров, можно легко нащупать простую логику:
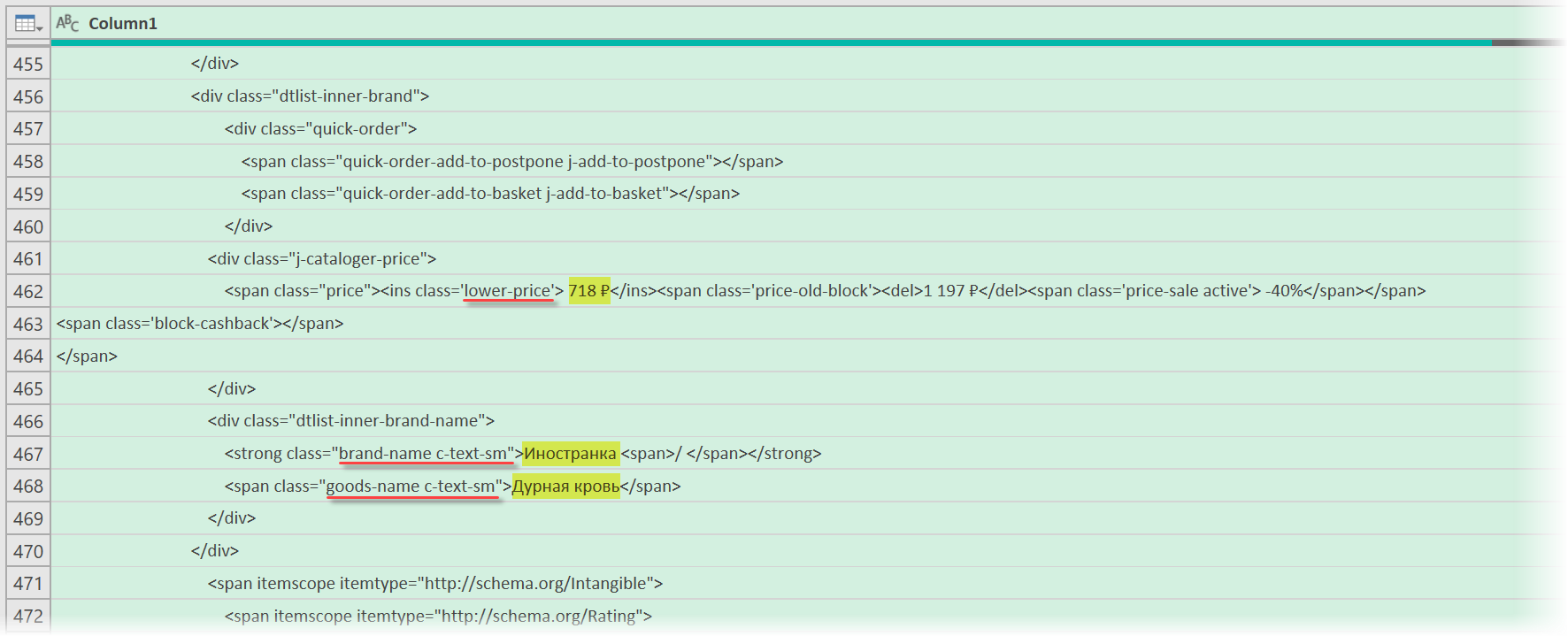
- Строчки с ценами всегда содержат метку lower-price
- Строчки с названием бренда — всегда с меткой brand-name c-text-sm
- Название товара можно найти по метке goods-name c-text-sm
Иногда процесс поиска можно существенно упростить, если воспользоваться инструментами отладки кода, которые сейчас есть в любом современном браузере. Щёлкнув правой кнопкой мыши по любому элементу веб-страницы (например, цене или описанию товара) можно выбрать из контекстного меню команду Инспектировать (Inspect) и затем просматривать код в удобном окошке непосредственно рядом с содержимым сайта:
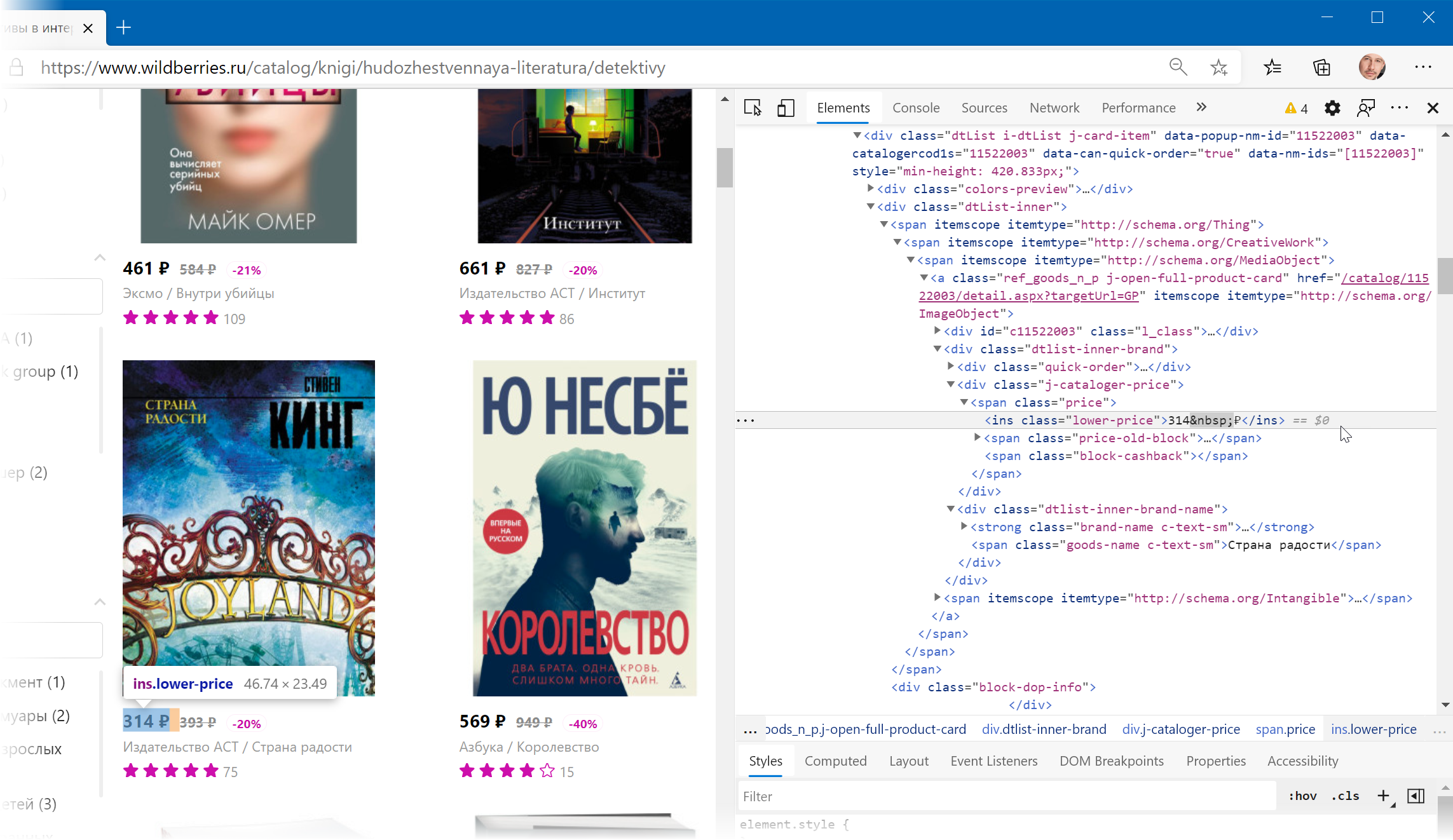
Фильтруем нужные данные
Теперь совершенно стандартным образом давайте отфильтруем в коде страницы нужные нам строки по обнаруженным меткам. Для этого выбираем в окне Power Query в фильтре [1] опцию Текстовые фильтры — Содержит (Text filters — Contains) , переключаемся в режим Подробнее (Advanced) [ 2] и вводим наши критерии:
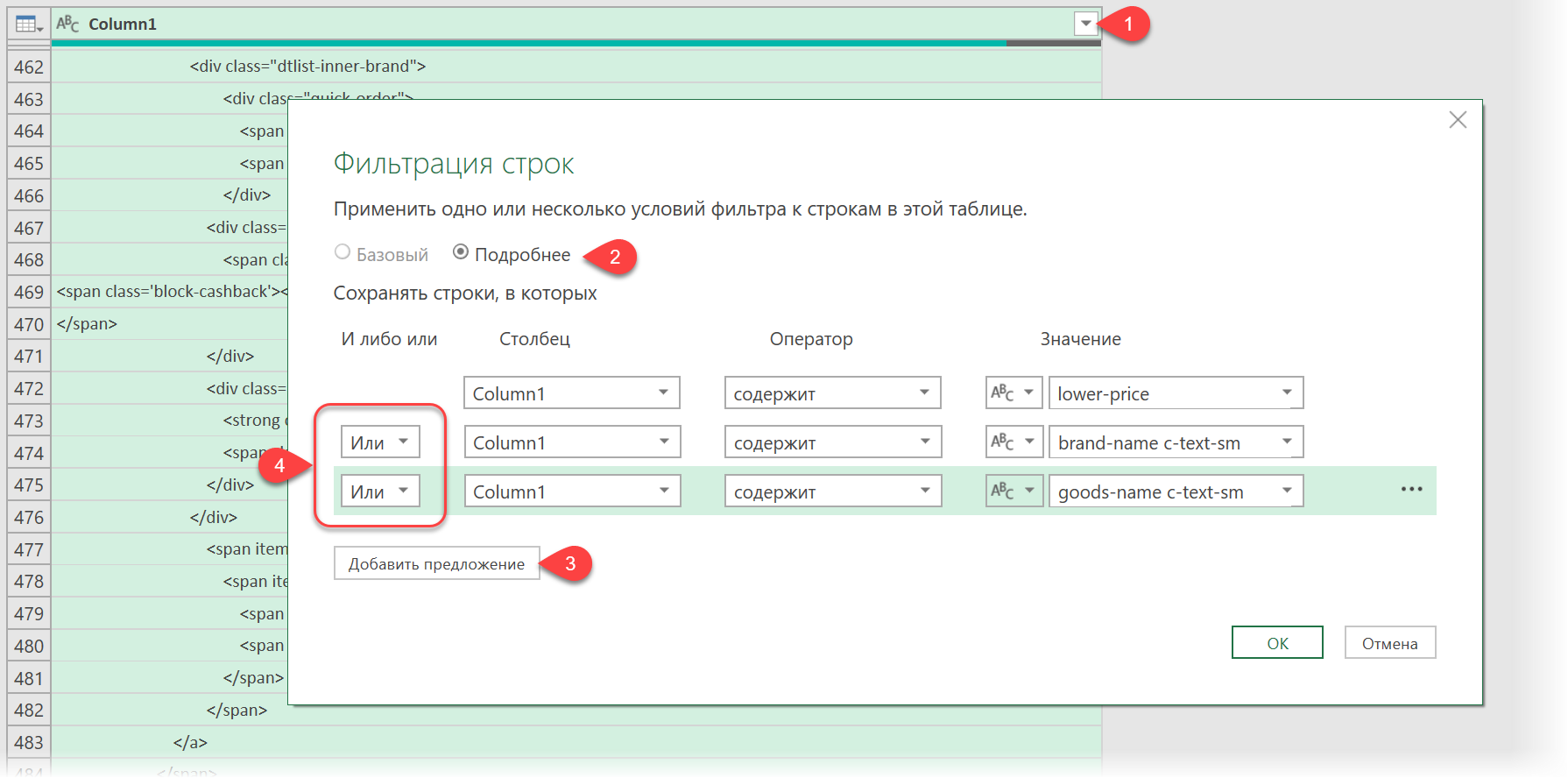
Добавление условий выполняется кнопкой со смешным названием Добавить предложение [ 3] . И не забудьте для всех условий выставить логическую связку Или (OR) вместо И (And) в выпадающих списках слева [4] — иначе фильтрация просто не сработает.
После нажатия на ОК на экране останутся только строки с нужной нам информацией:
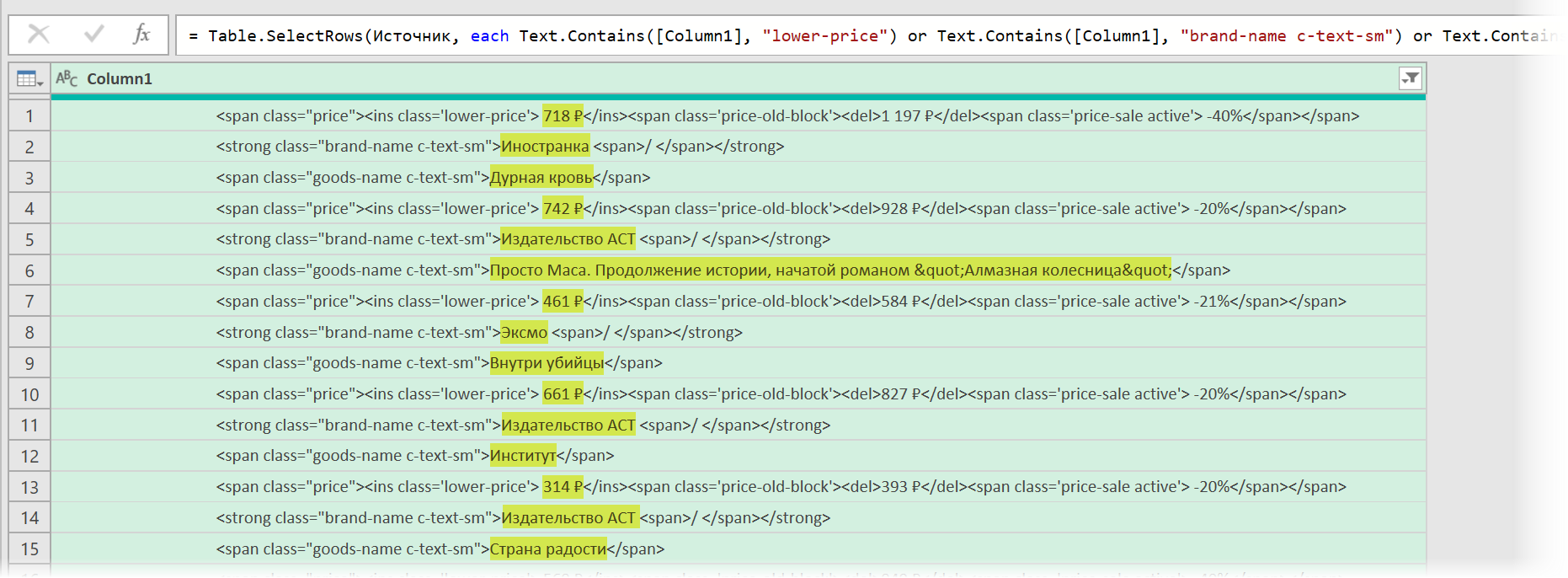
Чистим мусор
Останется почистить всё это от мусора любым подходящим и удобным лично вам способом (их много). Например, так:
- Удалить заменой на пустоту начальный тег: <span > через команду Главная — Замена значений (Home — Replace values) .
- Разделить получившийся столбец по первому разделителю » > » слева командой Главная — Разделить столбец — По разделителю (Home — Split column — By delimiter) и затем ещё раз разделить получившийся столбец по первому вхождению разделителя » < » слева, чтобы отделить полезные данные от тегов:
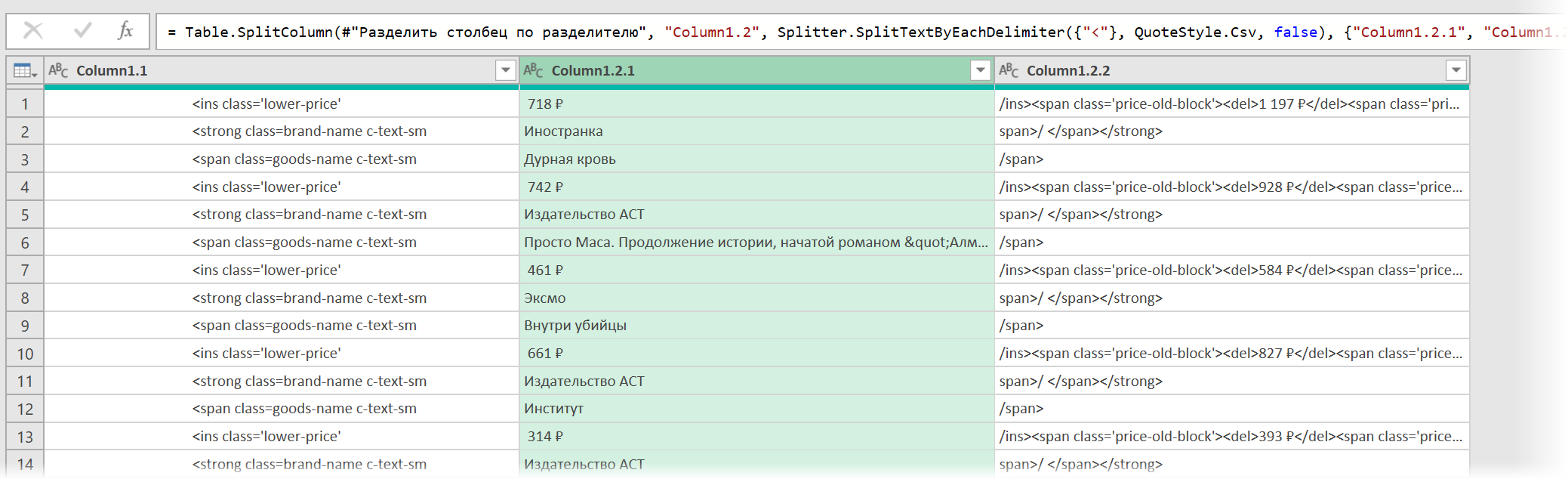
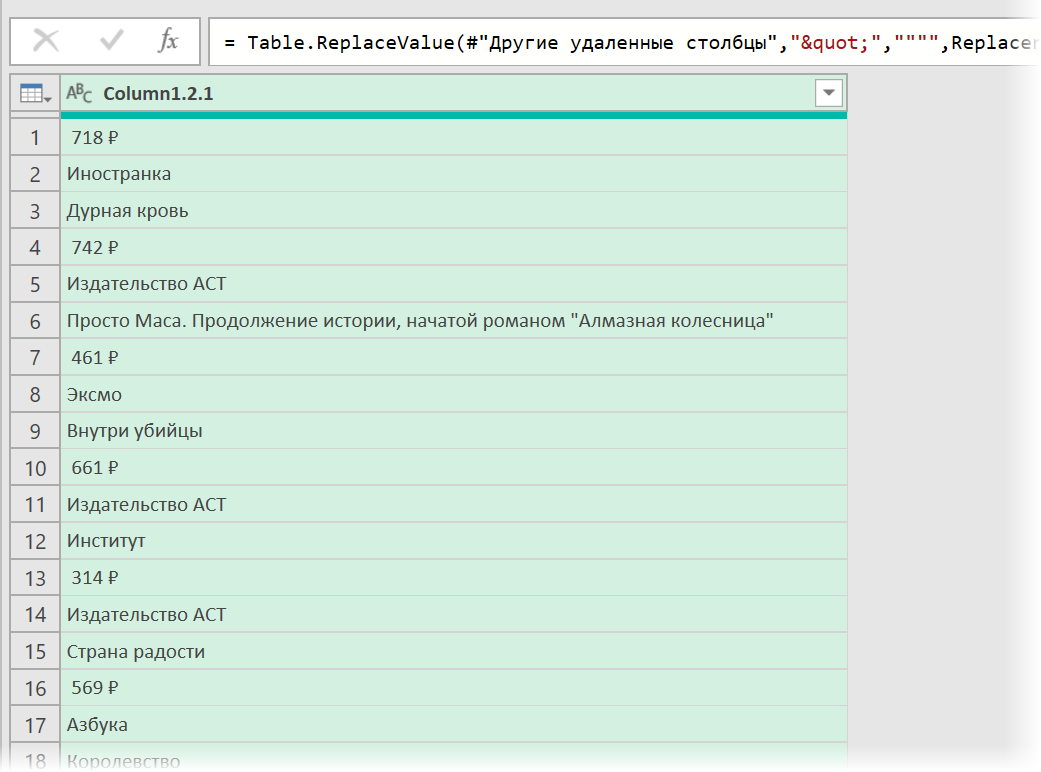
Разбираем блоки по столбцам
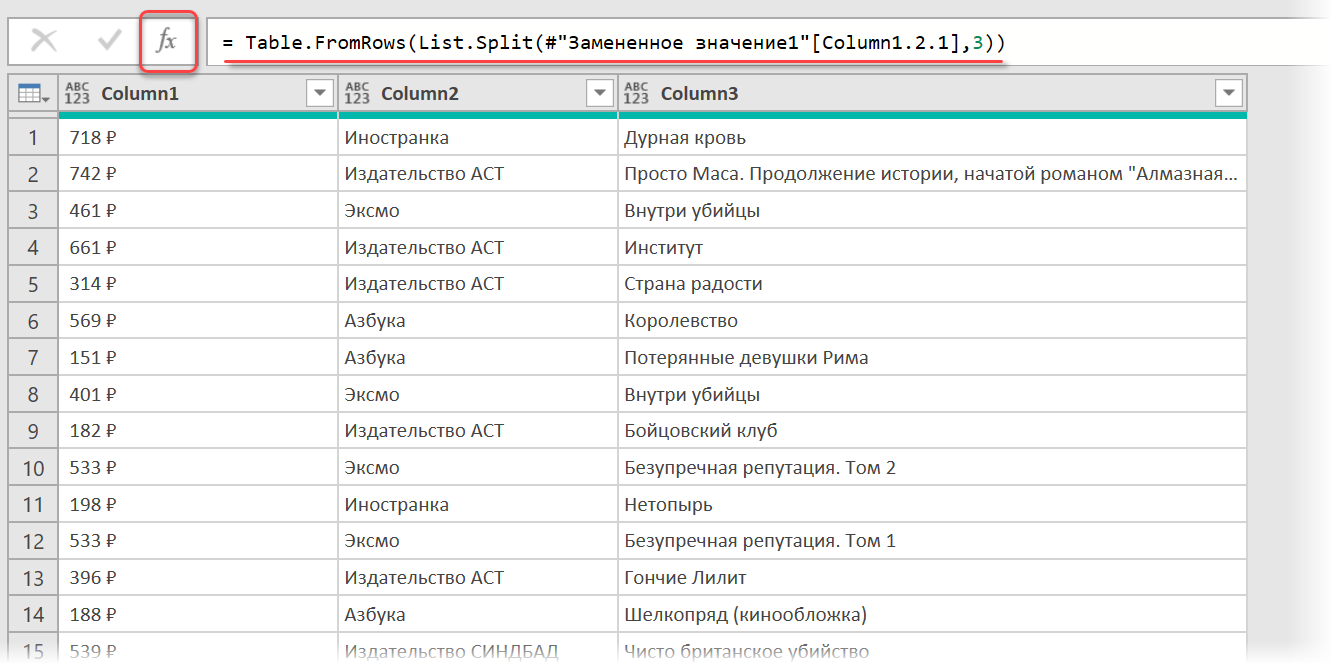
Если присмотреться, то информация о каждом отдельном товаре в получившемся списке сгруппирована в блоки по три ячейки. Само-собой, нам было бы гораздо удобнее работать с этой таблицей, если бы эти блоки превратились в отдельные столбцы: цена, бренд (издательство) и наименование.
Выполнить такое преобразование можно очень легко — с помощью, буквально, одной строчки кода на встроенном в Power Query языке М. Для этого щёлкаем по кнопке fx в строке формул (если у вас её не видно, то включите её на вкладке Просмотр (View) ) и вводим следующую конструкцию:
= Table.FromRows(List.Split( #»Замененное значение1″ [Column1.2.1] , 3 ))
Здесь функция List.Split разбивает столбец с именем Column1.2.1 из нашей таблицы с предыдущего шага #»Замененное значение1″ на кусочки по 3 ячейки, а потом функция Table.FromRows конвертирует получившиеся вложенные списки обратно в таблицу — уже из трёх столбцов:
Ну, а дальше уже дело техники — настроить числовые форматы столбцов, переименовать их и разместить в нужном порядке. И выгрузить получившуюся красоту обратно на лист Excel командой Главная — Закрыть и загрузить (Home — Close & Load. )
Scraping Data from Website to Excel (Tutorial 2022)
![]()
Whether a digital native or immigrant, you probably know the basic functions of Excel inside out. With Excel, it is easy to accomplish simple tasks like sorting, filtering and outlining data and making charts based on them. When the data are highly structured, we can even perform advanced data analysis using pivot and regression models in Excel. But the problem is, how can we extract scalable data and put them into Excel efficiently? This would be an extremely tedious task if done manually by repetitive typing, searching, copying, and pasting. So how can we achieve automated data extraction and scraping from websites to excel?
In this article, I will introduce several ways to save your time and energy to extract data from websites to excel through web scraping.
Disclaimer:
There are many ways to scrape data from websites using programming languages like PHP, Python, Perl, Ruby and etc. But here we’ll just talk about how to scrape data from websites into excel for non-coders.
Getting web data using Excel Web Queries
Except for transforming data from a web page manually by copying and pasting, Excel Web Queries is used to quickly retrieve data from a standard web page into an Excel worksheet. It can automatically detect tables embedded in the web page’s HTML. Excel Web queries can also be used in situations where a standard ODBC (Open Database Connectivity) connection gets hard to create or maintain. You can directly scrape a table from any website using Excel Web Queries.
Парсинг сайта с помощью Excel
На первый взгляд Excel и парсинг понятия несовместимые. Как с помощью табличного редактора можно получать информацию из сети? И ведь многие недооценивают Excel, а это вполне посильная задача для него. При этом все делается стандартными методами без необходимости дополнительно что-то устанавливать/настраивать.
Разберем на конкретном примере по получению информации с сайта Минюста, а именно, нам необходим перечень действующих адвокатов Российской Федерации. Кнопки «выгрузить списочно всех адвокатов» — конечно же, нет. На официальном сайте http://lawyers.minjust.ru/ выводится по 20 адвокатов на 1 странице, всего 74 754 страниц, итого на выходе мы должны получить чуть меньше 150 тыс. адвокатов.
Для начала открываем VBA и создаем объект InternetExplorer, посредством которого будем получать данные.
Затем надо определить, как будем переходить между страницами на сайте – для этого просматриваем элемент перехода на следующую страницу. Ссылка между станицами отличается значением в конце и соответствует номеру страницы – 1.
Имея информацию о ссылке страницы — осуществляем их перебор, загружаем в InternetExplorer и забираем все данные со страницы.
В коде страницы представлена структура таблицы со всеми столбцами, которые нам необходимы: реестровый номер, ФИО адвоката, субъект РФ, номер удостоверения, текущий статус.
Для получения этой информации с помощью ключевых слов осуществляем поиск по тегам и забираем требуемые данные.
В итоге получаем список всех адвокатов в таблицу Excel для дальнейшей обработки.
Парсер сайтов и файлов (парсинг данных с сайта в Excel)

Надстройка Parser для Excel — простое и удобное решение для парсинга любых сайтов (интернет-магазинов, соцсетей, площадок объявлений) с выводом данных в таблицу Excel (формата XLS* или CSV), а также скачивания файлов.
Особенность программы — очень гибкая настройка постобработки полученных данных (множество текстовых функций, всевозможные фильтры, перекодировки, работа с переменными, разбиение значения на массив и обработка каждого элемента в отдельности, вывод характеристик в отдельные столбцы, автоматический поиск цены товара на странице, поддержка форматов JSON и XML).
В парсере сайтов поддерживается авторизация на сайтах, выбор региона, GET и POST запросы, приём и отправка Cookies и заголовков запроса, получение исходных данных для парсинга с листа Excel, многопоточность (до 200 потоков), распознавание капчи через сервис RuCaptcha.com, работа через браузер (IE), кеширование, рекурсивный поиск страниц на сайте, сохранение загруженных изображений товара под заданными именами в одну или несколько папок, и многое другое.
Поиск нужных данных на страницах сайта выполняется в парсере путем поиска тегов и/или атрибутов тегов (по любому свойству и его значению). Специализированные функции для работы с HTML позволяют разными способами преобразовывать HTML-таблицы в текст (или пары вида название-значение), автоматически находить ссылки пейджера, чистить HTML от лишних данных.
За счёт тесной интеграции с Excel, надстройка Parser может считывать любые данные из файлов Excel, создавать отдельные листы и файлы, динамически формировать столбцы для вывода, а также использовать всю мощь встроенных в Excel возможностей.
Поддерживается также сбор данных из текстовых файлов (формата Word, XML, TXT) из заданной пользователем папки, а также преобразование файлов Excel из одного формата таблицы в другой (обработка и разбиение данных на отдельные столбцы)
В программе «Парсер сайтов» можно настроить обработку нескольких сайтов. Перед запуском парсинга (кнопкой на панели инструментов Excel) можно выбрать ранее настроенный сайт из выпадающего списка.
На видео рассказывается о работе с программой, и показан процесс настройки парсера интернет-магазина:
Дополнительные видеоинструкции, а также подробное описание функционала, можно найти в разделе Справка по программе
В программе можно настроить несколько парсеров (обработчиков сайтов).
Любой из парсеров настраивается и работает независимо от других.
Настройка программы, — дело не самое простое (для этого, надо хоть немного разбираться в HTML)
Если вам нужен готовый парсер, но вы не хотите разбираться с настройкой,
— закажите настройку парсера разработчику программы. Стоимость настройки под конкретный сайт — от 2000 рублей.
(настройка под заказ выполняется только при условии приобретения лицензии на надстройку «Парсер» (3300 руб)
Программа не привязана к конкретному файлу Excel.
Вы в настройках задаёте столбец с исходными данными (ссылками или артикулами),
настраиваете формирование ссылок и подстановку данных с сайта в нужные столбцы,
нажимаете кнопку, — и ваша таблица заполняется данными с сайта.
Программа «Парсер сайтов» может быть полезна для формирования каталога товаров интернет-магазинов,
поиска и загрузки фотографий товара по артикулам (если для получения ссылки на фото, необходимо анализировать страницу товара),
загрузки актуальных данных (цен и наличия) с сайтов поставщиков, и т.д. и т.п.
Можно попробовать разобраться с работой программы на примерах настроенных парсеров
Как скачать и протестировать программу
Для загрузки надстройки Parser воспользуйтесь кнопкой Скачать программу
Если не удаётся скачать надстройку, читайте инструкцию про антивирус
Если скачали файл, но он не запускается, читайте почему не появляется панель инструментов
Это полнофункциональная пробная (TRIAL) версия, у вас есть 10 дней ,
в течение которых вы можете протестировать работу программы.
Этого вполне достаточно, чтобы всё настроить и проверить, используя раздел Справка по программе
Если вам понравится, как работает программа, вы можете Купить лицензию
Лицензия (для постоянного использования) стоит 3300 рублей .
В эту стоимость входит активация на 2 компьютера (вы сможете пользоваться программой и на работе, и дома).
Если нужны будут дополнительные активации, их можно будет в любой момент приобрести по 800 рублей за каждый дополнительный компьютер.
- 819722 просмотра
Комментарии
Да, парсер может работать и с сайтами с кириллическим доменом.
Просто на этом конкретном сайте есть защита от роботов, и нужно использовать для загрузки браузер Chrome (способ загрузки = Browser)
Здравствуйте, ратриваю возможность приобретения лицензии на парсер сайтов. По видеоинструкции повторил за Вами — на сайте Одиссей, книжный магизин — все работает. Мне же нужно парсить с сайта, название которого на русском. И вот в данном случае не работает парсер — на начальном этапе загрузки страницы грузит ее , но в каком то другом коде, в котором нет информации по ссылкам, тегам и т.д. К примеру я искал в загруженном в парсер коде русские буквы — не нашел. Вопрос — а парсер может работать с сайтами нахвание которых на русском? При копировании ссылки на сайт получается вот такая вот абра кадабра: https://xn--80az8a.xn--d1aqf.xn--p1ai/%D1%81%D0%B5%D1%80%D0%B2%D0%B8%D1%.
Здравствуйте, Ирина.
Не понятен ваш вопрос.
Как вывести — не знаю. Это вы должны придумать сами, в каком виде вам нужен результат на листе Excel.
Как настроить — тут можно как угодно сделать (парсер гибко настраивается). Могу настроить под заказ.
а как парсить почты, если их несколько, в отдельные ячейки, но сохранять при этом в другой имя организации?
Например тут https://amikta.ru/kontakty/ есть несколько почт, но организация и телефон — одна
Обновление надстройки Parser (версия 4.2.0 от 4 мая 2023)
+ добавлено новое действие «Траспонировать таблицу»
+ в действии «HTML: замена / изменение тегов» теперь можно вычислять новое содержимое тега вызовом набора действий
+ возможность задавать форматирование ячеек (полужирный шрифт, размер шрифта, формат ячеек)
+ переделано действие «Регулярные выражения»
+ доработки по интерфейсу списка действий (можно упорядочить список изобранных действий, некоторые действия получили более понятные имена)
Обновление надстройки Parser (версия 4.1.10 от 3 мая 2023)
+ добавлено действие «Информация о файле» (дата создания / изменения файла, размер файла, и т.п.)
+ теперь можно включать / отключать приём Cookies в действиях для POST запроса и загрузки страницы
+ добавлена возможность задавать минимальную и максимальную высоту строк при выводе на лист
+ при экспорте содержимого файла Word в формат HTML, теперь в результат (HTML) выводятся и ссылки на файлы картинок
+ мелкие исправления по интерфейсу
Здравствуйте.
Пересмотрите видеоинструкцию по программе.
На этапе тестирования нужно подставлять ссылку (из любой ячейки) в поле ИСХОДНОЕ ЗНАЧЕНИЕ в окне тестирования
(а не в параметр URL действия!)
В ходе работы (после запуска парсера), значения будут браться автоматически из ячеек.
А для теста нужно вручную подставлять исходную ссылку.
Здравствуйте, сейчас тестирую ваш парсер.
Возник вопрос при режиме парсера «брать данные с листа, из заданного столбца». Задал столбец, перешел в редакцию списка действий и выбрал действие «Загрузить ИСХОДНЫЙ КОД веб-страницы». При тестировании не загружает, ведь по логике парсер должен исходить из заданного столбца, чего не происходит.
Подставил первое значение с заданного столбца в URL — выдал результаты по 1му значению, остальное пустое при выводе данных на лист. Изменял кодировку — не получается. На фазе тестирования ничего не происходит. Какое действие нужно производить вместо «Загрузить ИСХОДНЫЙ КОД веб-страницы» ?
Основная задача получить прямые ссылки с облака, в заданном столбце ссылки на облако.
Здравствуйте.
Да, можно, только там настройка посложнее, чем в случае с обычными сайтами (интернет-магазинами)
Иногда ссылку можно найти где-то в дебрях исходного кода загруженной страницы, иногда нужно сделать дополнительный POST запрос для получения этих ссылок.
Но ничего невозможного нет. Можем настроить под заказ.
Здравствуйте, можно ли при помощи этого парсера скачивать картинки с файлообменников? Для примера в экселе есть ссылки на 1 или несколько картинок, при помощи парсера я загружаю исходную страницу по ссылке с экселя, далее ищу тег картинки но не находит. в хтмл коде тег картинки указана как ссылка. пытался прогрузить эту ссылку в парсер, не получается. подскажите пожалуйста в чем может быть проблема