Утилиты для тестирования HDD SAS
Имею в серверном парке SAS диски Seagate и Hitachi. В боевую они работают через RAID контроллеры Adaptec или LSI.
Бывает такое, что появляется на диске на media error.
Если провести медиа сканирование с помощью, например, Adaptec Storage Manager, то эта media error в свойствах диска исчезает.
В smart-е показывает, что все ок — одной строчкой.
Маловато информации показывает этот софт.
Хотелось бы внимательно посмотреть на smart диска и провести дополнительное сканирование поверхности, перепрошить прошивку
Оставляю один Seagate диск на контроллере LSI 92618i, не конфигурирую его никак.
Seatool for DOS видит other контроллер, из пераметром диска только обьем, на диске можно сделать только диагностическое сканирование.
Seatool for windows видит диск MR9261-81, на диске можно сделать только диагностическое сканирование, прошивка обламывается
Seatool Enterprise не видит контроллер.
Пытался запустить DFT for dos c драйвером LSI 320x — не видит контроллер.
Поделитесь, пожалуйста, рабочими вариантами сочетания ПО и контроллеров.
С уважением,
Александр
Re: Утилиты для тестирования HDD SAS
- Предупредить
- Информация
- Цитата
Сообщение Лис » 24 мар 2013, 04:29
Re: Утилиты для тестирования HDD SAS
- Предупредить
- Информация
- Цитата
Сообщение shab2 » 25 мар 2013, 10:03
Stranger03 Сотрудник Тринити
Сообщения: 12979 Зарегистрирован: 14 ноя 2003, 16:25 Откуда: СПб, Екатеринбург Контактная информация:
Re: Утилиты для тестирования HDD SAS
- Предупредить
- Информация
- Цитата
Сообщение Stranger03 » 25 мар 2013, 10:21
Re: Утилиты для тестирования HDD SAS
- Предупредить
- Информация
- Цитата
Сообщение shab2 » 25 мар 2013, 11:07
Ответ на ты адресовался не Вам. Если Вы модератор, прошу дать ссылку на пункт правил, где запрещается обращение на ты.
По существу темы: Все использованные утилиты упомянуты. Если Вы знаете о других, скажите. Кроме контроллера LSI SAS 9261 использовался LSI SAS 8208XLP. Однако разницы в поведении программ не было. «Взять любой SAS HBA» — это платить деньги. Хотелось бы заранее знать модель с которой утилиты производителей умеют работать.
С уважением, Александр
Stranger03 Сотрудник Тринити
Сообщения: 12979 Зарегистрирован: 14 ноя 2003, 16:25 Откуда: СПб, Екатеринбург Контактная информация:
Re: Утилиты для тестирования HDD SAS
- Предупредить
- Информация
- Цитата
Сообщение Stranger03 » 26 мар 2013, 08:50
Re: Утилиты для тестирования HDD SAS
- Предупредить
- Информация
- Цитата
Сообщение shab2 » 26 мар 2013, 10:08
И уберите из подписи — «С уважением»
Re: Утилиты для тестирования HDD SAS
- Предупредить
- Информация
- Цитата
Сообщение Helium » 28 мар 2013, 00:08
Re: Утилиты для тестирования HDD SAS
- Предупредить
- Информация
- Цитата
Сообщение brass » 28 мар 2013, 10:02
Stranger03 Сотрудник Тринити
Сообщения: 12979 Зарегистрирован: 14 ноя 2003, 16:25 Откуда: СПб, Екатеринбург Контактная информация:
Re: Утилиты для тестирования HDD SAS
- Предупредить
- Информация
- Цитата
Сообщение Stranger03 » 28 мар 2013, 10:21
Re: Утилиты для тестирования HDD SAS
- Предупредить
- Информация
- Цитата
Сообщение Umlyaut » 31 мар 2013, 16:03
Геннадий, а Вы точно не перегибаете палку?
Да, по поводу подписи у shab2 вышло резко, возможно даже неуважительно резко — но всё же до хамства, на мой взгляд, никак не дотягивает (кстати, как давний и регулярный посетитель и участник данного форума я неоднократно замечал за Вами не менее резкие ответы, однако Вас никто не одёргивал и не банил).
Другое дело, что Вы, как мне кажется, вольно или невольно форсировали развитие довольно таки безобидной ситуации, доведя её до модераториала.
Ув.Лис обратился к ув.shab2 на «ты». Ув.shab2 мог проигнорировать (ответив на «Вы»), мог возмутиться (мол, я с Вами , сударь, на брудершафт не пил»). Однако он ответил в том же ключе (на «ты»), не заморачиваясь формой. Ситуация замкнулась «сам на сам».
Вы же не преминули сделать замечание (почему-то топикстартеру, а не первому «тыкнувшему»), притом что никто из них не возражал против такого обращения; ну а кроме того «принято»(на «Вы») <> «обязательно»(на «Вы») — в правилах форума нигде ничего такого действительно не регламентировано.
В этой связи непонятны причины, побудившие Вас сделать ув.shab2 замечание и пригрозить баном — его (развёрнутый) ответ Вам не выходит, как мне кажется, за рамки приличий. Да, без расшаркиваний, но по-большому счёту всё правильно — нет запрета, нет и повода для одёргиваний.
Ув.shab2 мне, конечно, не сват, не брат, однако не хотелось бы создания грустного прецедента типа «попала шлея под мантию» (никогда не знаешь, что и в какой момент придётся Вам не по вкусу).
Плюс к тому подобное реагирование с Вашей стороны может изрядно подпортить Ваше реноме. В конце концов, Ваши ответы по техническим вопросам неплохо характеризуют Вас как специалиста, тогда как подобные эксцессы могут создать о Вас впечатление уже как о человеке — и не самое благоприятное.
Про то, что кто-то может просто не захотеть лишний раз иметь дело с фирмой, сотрудники которой ведут себя как высокомерные снобы и самодуры, уж и упоминать-то неудобно.
Интерпретация результатов б/у SAS дисков
Так как информации по этим дискам через стандартный SMART очень мало, решил воспользоваться программой R.tester. Видно что программа может очень много, но страшно запускать то, что не понимаешь. Скажу сразу, что на дисках пока нет информации, поэтому могу запускать и те тесты, которые могут разрушать данные (если такие будут необходимы)
Выкладываю SMART, который получил при помощи R.tester и дампы.
Буду очень благодарен, если поможете в интерпретации.
линк на скачивание дампов (диска 2, дампа 4, потому что сделаны из разных мест программы, не знаю сильно ли они отличаются):
[url=https://app.box.com/s/w0quukpph8ha1syu4u3kz68b0aq4nsi9]https://app.box.com/s/w0quukpph8ha1syu4u3kz68b0aq4nsi9[/url]
Поправьте если не прав. Диски явно были откуда-то переставлены, не стояли они вместе в RAID. Разное количество циклов. Разное количество записаных данных. Но важно не это. Мне нужно понять можно ли эти диски использовать или они скоро посыпятся? Стоит ли их объединять в MIRROR или "не да бог" 🙂 в STRIPE. Или лучше по отдельности. Или в ведро?
0 G-LIST — это видимо хорошо. С ошибками записи мне менее понятно.
================================
; Model: WD WD6001BKHG-50D22
; Serial: WXU1E83NFCK9
; Firmware: SFX9
;
0 G-LIST Number of reallocated sectors (pCHS) ** GROWN **
1930 P-LIST Number of Primary defects (pCHS) ** FACTORY **
00-00 PFA Status: ** GOOD **
35'C T Current Temperature
35'C T Current Temperature
69'C T Reference Temperature
213 CSS Accumulated Start/Stop Cycles
453127 WRITE Error Corrected Without Substantial Delay
842 WRITE Error Corrected With Possible Delays
844 WRITE Total Error Corrected With Retries
453969 WRITE Total Error Corrected
842 WRITE Total Times Correction Algorithm Processed
24373917970432 WRITE Total Bytes Processed ( 22.17 Tb )
0 WRITE Total Uncorrected Errors
14695 READ Error Corrected Without Substantial Delay
26 READ Error Corrected With Possible Delays
57 READ Total Error Corrected With Retries
14721 READ Total Error Corrected
26 READ Total Times Correction Algorithm Processed
7845358983168 READ Total Bytes Processed ( 7.14 Tb )
0 READ Total Uncorrected Errors
0 VERIFY Error Corrected Without Substantial Delay
0 VERIFY Error Corrected With Possible Delays
0 VERIFY Total Error Corrected With Retries
0 VERIFY Total Error Corrected
0 VERIFY Total Times Correction Algorithm Processed
0 VERIFY Total Bytes Processed
0 VERIFY Total Uncorrected Errors
287616 — Recoverable Non-Medium Error Events
===========
; Model: SEAGATE ST600MM0006
; Serial: S0M1C2LJ
; Firmware: 6102
;
0 G-LIST Number of reallocated sectors (pCHS) ** GROWN **
1408 P-LIST Number of Primary defects (pCHS) ** FACTORY **
00-00 PFA Status: ** GOOD **
35'C T Current Temperature
68'C T Reference Temperature
225d 17h POH Power-On Time (325042 minutes)
35'C T Current Temperature
68'C T Reference Temperature
702 CSS Accumulated Start/Stop Cycles
0 WRITE Error Corrected With Possible Delays
0 WRITE Total Error Corrected With Retries
0 WRITE Total Error Corrected
0 WRITE Total Times Correction Algorithm Processed
3308097849856 WRITE Total Bytes Processed ( 3.01 Tb )
0 WRITE Total Uncorrected Errors
2079063422 READ Error Corrected Without Substantial Delay
0 READ Error Corrected With Possible Delays
0 READ Total Error Corrected With Retries
2079063422 READ Total Error Corrected
0 READ Total Times Correction Algorithm Processed
2018569198080 READ Total Bytes Processed ( 1.84 Tb )
0 READ Total Uncorrected Errors
0 VERIFY Error Corrected Without Substantial Delay
0 VERIFY Error Corrected With Possible Delays
0 VERIFY Total Error Corrected With Retries
0 VERIFY Total Error Corrected
0 VERIFY Total Times Correction Algorithm Processed
0 VERIFY Total Bytes Processed
0 VERIFY Total Uncorrected Errors
2228 — Recoverable Non-Medium Error Events
Как работать с SAS дисками на обычном, не серверном компьютере?

Вам нужен HBA-адаптер (кто-то называет HBA-контроллером).
Можно взять б/у на eBay, хламаде, или авито.
RAID-контроллер вам не только не нужен, но и противопоказан.
Ряд контроллеров могут нормально переключаться в HBA-режим, но многие могут отчаянно и неожиданно чудить — автоматом инициализировать диски и проделывать прочие подобные вещи.
Так что мы обычно рекомендуем избегать рэйд-плат для подобных задач.
S.M.A.R.T. (часть 1). Мониторинг SCSI дисков под LSI 2108 (megaraid) RAID контроллером
 Навожу короткую инструкция по мониторингу физических дисков под хардварным LSI 2108 RAID контроллером. Так же эта инструкция может пригодиться для мониторинга дисков под HP/Compaq Smart Array Controller, Areca SATA[/SAS] RAID controller и другими, используя инструмент smart в сочетании с специализированными программами. Перечень контроллеров, за которыми можно мониторить физические диски используя smartctl наведен здесь.
Навожу короткую инструкция по мониторингу физических дисков под хардварным LSI 2108 RAID контроллером. Так же эта инструкция может пригодиться для мониторинга дисков под HP/Compaq Smart Array Controller, Areca SATA[/SAS] RAID controller и другими, используя инструмент smart в сочетании с специализированными программами. Перечень контроллеров, за которыми можно мониторить физические диски используя smartctl наведен здесь.
Немного о HDD интерфейсах
Аббревиатуры:
SCSI— Small Computer System Interface
SAS— Serial Attached SCSI
SATA — Serial ATA
ATA — AT Attachment
Чтобы визуально понять как выглядят те, или иные интерфейсы навожу картинки.

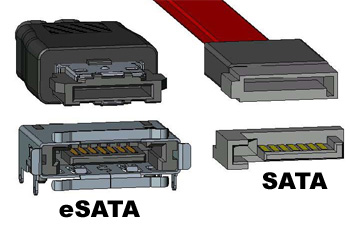

С интерфейсами все понятно, переходим к практике.
Мониторинг дисков используя megacli
Смотрим какие у нас есть диски.
SMC2108 — означает, что у нас Supermicro MC2108 контроллер. Так же можно убедиться, что у нас Megaraid контроллер используя эту команду.
Как видим, у нас LSI SAS MegaRAID контроллер, диски которого можно мониторить используя smartctl или же используя специализированную утилиту megacli. Для начала присмотримся к megacli. В стандартных репозиториях ее нет, но можно скачать с официального сайта и собрать с исходников. Но я рекомендую использовать специальный репозиторий (за который хочу сказать ОГРОМНОЕ спасибо) в котором есть почти весь набор специализированных утилиты под любой тип аппаратных рейдов.
Перечень всех доступных в репозитории утилит наведен здесь
Проверяем на ошибки физический диск megaraid используя megacli.
Как видим, на первом физическом диске есть «Media Error Count: 38». Это означает, что запасные(зарезервированные) сектора для remap(замены) битых секторов диска — закончились. И нужно проводить замену диска.
Так же нужно мониторить следующие параметры используя команду:
Теперь напишем маленький скрипт для мониторинга всех нужных параметров включая BBU.
Данный скрипт проверяет все диски на наличие проблем с прошивкой,состояние рейда,ошибки физических дисков и состояние батареи. Если есть проблема с батареей — код выхода скрипта будет больше 250, если проблемы с остальными устройствами, то будет выведено только количество ошибок. Скрипт запускается без аргументов. Если добавить аргумент log, будет выведено текст с указанием проблемного элемента. Проверяем работу скрипта:
Как видим у нас проблема с батареей (BBU) и ее нужно заменить.
По роботе с magacli есть целая книга-руководство.
Из полезных команд:
Мониторинг дисков используя smartctl
Для этого нам понадобиться тот же megacli, используя который, мы узнаем ID физических дисков и соответствующие им логические носители. Начнем.
Узнаем ID всех физических дисков за мегарейд контроллером ну и номера соответствующих логических дисков.
Расшифрую эту команду:
- -LdPdInfo — получить информацию(Info) по логическим (Ld) и физическим(Pd) устройствам …
- -aALL — … на всех адаптерах
Теперь видно, что у нас три логических(виртуальных) диска в которые входят по несколько физических дисков с соответствующими ID. Посмотрим на сервере, сколько у нас есть дисков:
Все верно, у нас три логических диска в системе. Проводим аналогию с выводом команды megacli:
-
Virtual Drive: 0 == /dev/sda и в него входит 4 физических диска с Drive: 1 == /dev/sdb и в него входит 2 физических диска с Drive: 2 == /dev/sdc и в него входит 6 физических дисков с >Теперь нам осталось запустить SMART проверку по каждому с дисков используя собранные данные.
К примеру возьмем первый диск.
Как видим у нас есть 60 ошибок с которыми не смогла справиться система исправления ошибок.
Немного расшифрую выводу ошибок:
Журнал ошибок (если он доступен) отображается в отдельных строках:
- write error counters — ошибки записи
- read error counters — ошибки считывания
- verify error counters (отображаются только когда не нулевое значение) — ошибки выполнения
- non-medium error counter (определенное число) — число восстанавливаемых ошибок отличных от ошибок записи/считывания/выполнения
Так же может выводиться детальное описание последних ошибок с кодом, если устройство его поддерживает(если нет поддержки — выводиться сообщение «Error Events logging not supported»). К примеру:
Каждая из ошибок имеет различные коды. Оригинал описания кодов взято из мануала по SCSI Seagate дискам:
Errors Corrected by ECC, fast [Errors corrected without substantial delay: 00h]. An error correction was applied to get perfect data (a.k.a. ECC on-the-fly). «Without substantial delay» means the correction did not postpone reading of later sectors (e.g. a revolution was not lost). The counter is incremented once for each logical block that requires correction. Two different blocks corrected during the same command are counted as two events.
Errors Corrected by ECC: delayed [Errors corrected with possible delays: 01h]. An error code or algorithm (e.g. ECC, checksum) is applied in order to get perfect data with substantial delay. «With possible delay» means the correction took longer than a sector time so that reading/writing of subsequent sectors was delayed (e.g. a lost revolution). The counter is incremented once for each logical block that requires correction. A block with a double error that is correctable counts as one event and two different blocks corrected during the same command count as two events.
Error corrected by rereads/rewrites [Total (e.g. rewrites and rereads): 02h]. This parameter code specifies the counter counting the number of errors that are corrected by applying retries. This counts errors recovered, not the number of retries. If five retries were required to recover one block of data, the counter increments by one, not five. The counter is incremented once for each logical block that is recovered using retries. If an error is not recoverable while applying retries and is recovered by ECC, it isn’t counted by this counter; it will be counted by the counter specified by parameter code 01h — Errors Corrected With Possible Delays.
Total errors corrected [Total errors corrected: 03h]. This counter counts the total of parameter code errors 00h, 01h and 02h (i.e. error corrected by ECC: fast and delayed plus errors corrected by rereads and rewrites). There is no «double counting» of data errors among these three counters. The sum of all correctable errors can be reached by adding parameter code 01h and 02h errors, not by using this total. [The author does not understand the previous sentence from the Seagate manual.]
Correction algorithm invocations [Total times correction algorithm processed: 04h]. This parameter code specifies the counter that counts the total number of retries, or «times the retry algorithm is invoked». If after five attempts a counter 02h type error is recovered, then five is added to this counter. If three retries are required to get stable ECC syndrome before a counter 01h type error is corrected, then those three retries are also counted here. The number of retries applied to unsuccessfully recover an error (counter 06h type error) are also counted by this counter.
Gigabytes processed [Total bytes processed: 05h]. This parameter code specifies the counter that counts the total number of bytes either successfully or unsuccessfully read, written or verified (depending on the log page) from the drive. If a transfer terminates early because of an unrecoverable error, only the logical blocks up to and including the one with the uncorrected data are counted. [smartmontools divides this counter by 10^9 before displaying it with three digits to the right of the decimal point. This makes this 64 bit counter easier to read.]
Total uncorrected errors [Total uncorrected errors: 06h]. This parameter code specifies the counter that contains the total number of blocks for which an uncorrected data error has occurred.
С всего этого нас интересует параметр Total uncorrected errors который показывает количество не исправленных ошибок. Если это число велико, то нужно запускать long тест и проверить, дополнительно, параметры физического диска в Megaraid контроллере.
Мониторинг дисков используя smartd
Предыдущие способы мониторинга дисков были ручными, т.е. нужно вручную запускать проверку дисков находясь на конкретном сервере, или же настроить систему мониторинга, которая будет использовать написанные выше скрипты для сбора информации о состоянии дисков. Но есть еще один способ мониторинга — это использование демона smartd, который будет отправлять нам письма о проблемных дисках. Детально о настройках демона smartd можно почитать здесь
Для начала добавим демон в автозагрузку.