Выбор и изменение кодировки в Microsoft Word

MS Word заслужено является самым популярным текстовым редактором. Следовательно, чаще всего можно столкнуться с документами в формате именно этой программы. Все, что может в них отличаться, это лишь версия Ворда и формат файла (DOC или DOCX). Однако, не смотря на общность, с открытием некоторых документов могут возникнуть проблемы.
Одно дело, если вордовский файл не открывается вовсе или запускается в режиме ограниченной функциональности, и совсем другое, когда он открывается, но большинство, а то и все символы в документе являются нечитабельными. То есть, вместо привычной и понятной кириллицы или латиницы, отображаются какие-то непонятные знаки (квадраты, точки, вопросительные знаки).
Если и вы столкнулись с аналогичной проблемой, вероятнее всего, виною тому неправильная кодировка файла, точнее, его текстового содержимого. В этой статье мы расскажем о том, как изменить кодировку текста в Word, тем самым сделав его пригодным для чтения. К слову, изменение кодировки может понадобиться еще и для того, чтобы сделать документ нечитабельным или, так сказать, чтобы “конвертировать” кодировку для дальнейшего использования текстового содержимого документа Ворд в других программах.
Примечание: Общепринятые стандарты кодировки текста в разных странах могут отличаться. Вполне возможно, что документ, созданный, к примеру, пользователем, проживающим в Азии, и сохраненный в местной кодировке, не будет корректно отображаться у пользователя в России, использующего на ПК и в Word стандартную кириллицу.
Что такое кодировка
Вся информация, которая отображается на экране компьютера в текстовом виде, на самом деле хранится в файле Ворд в виде числовых значений. Эти значения преобразовываются программой в отображаемые знаки, для чего и используется кодировка.
Кодировка — схема нумерации, в которой каждому текстовому символу из набора соответствует числовое значение. Сама же кодировка может содержать буквы, цифры, а также другие знаки и символы. Отдельно стоит сказать о том, что в разных языках довольно часто используются различные наборы символов, именно поэтому многие кодировки предназначены исключительно для отображения символов конкретных языков.
Выбор кодировки при открытии файла
Если текстовое содержимое файла отображается некорректно, например, с квадратами, вопросительными знаками и другими символами, значит, MS Word не удалось определить его кодировку. Для устранения этой проблемы необходимо указать правильную (подходящую) кодировку для декодирования (отображения) текста.
-
Откройте меню “Файл” (кнопка “MS Office” ранее).
Примечание: После того, как вы установите галочку напротив этого параметра, при каждом открытии в Ворде файла в формате, отличном от DOC, DOCX, DOCM, DOT, DOTM, DOTX, будет отображаться диалоговое окно “Преобразование файла”. Если же вам часто приходится работать с документами других форматов, но при этом не требуется менять их кодировку, снимите эту галочку в параметрах программы.
Совет: В окне “Образец” вы можете увидеть, как будет выглядеть текст в той или иной кодировке.
В случае, если весь текст, кодировку для которого вы выбираете, выглядит практически одинаков (например, в виде квадратов, точек, знаков вопроса), вероятнее всего, на вашем компьютере не установлен шрифт, используемый в документе, который вы пытаетесь открыть. О том, как установить сторонний шрифт в MS Word, вы можете прочесть в нашей статье.
Выбор кодировки при сохранении файла
Если вы не указываете (не выбираете) кодировку файла MS Word при сохранении, он автоматически сохраняется в кодировке Юникод, чего в большинстве случаев предостаточно. Данный тип кодировки поддерживает большую часть знаков и большинство языков.
В случае, если созданный в Ворде документ вы (или кто-то другой) планируете открывать в другой программе, не поддерживающей Юникод, вы всегда можете выбрать необходимую кодировку и сохранить файл именно в ней. Так, к примеру, на компьютере с русифицированной операционной системой вполне можно создать документ на традиционном китайском с применением Юникода.
Проблема лишь в том, что в случае, если данный документ будет открываться в программе, поддерживающей китайский, но не поддерживающей Юникод, куда правильнее будет сохранить файл в другой кодировке, например, “Китайская традиционная (Big5)”. В таком случае текстовое содержимое документа при открытии его в любой программе с поддержкой китайского языка, будет отображаться корректно.
Примечание: Так как Юникод является самым популярным, да и просто обширным стандартном среди кодировок, при сохранении текста в других кодировках возможно некорректное, неполное, а то и вовсе отсутствующее отображение некоторых файлов. На этапе выбора кодировки для сохранения файла знаки и символы, которые не поддерживаются, отображаются красным цветом, дополнительно высвечивается уведомление с информацией о причине.
- Откройте файл, кодировку которого вам необходимо изменить.
- Откройте меню “Файл” (кнопка “MS Office” ранее) и выберите пункт “Сохранить как”. Если это необходимо, задайте имя файла.

- В разделе “Тип файла” выберите параметр “Обычный текст”.
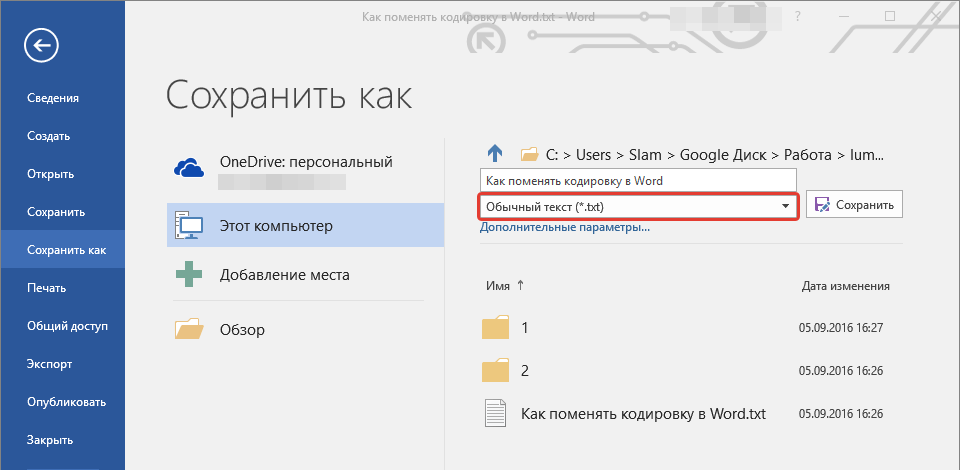
- Нажмите кнопку “Сохранить”. Перед вами появится окно “Преобразование файла».
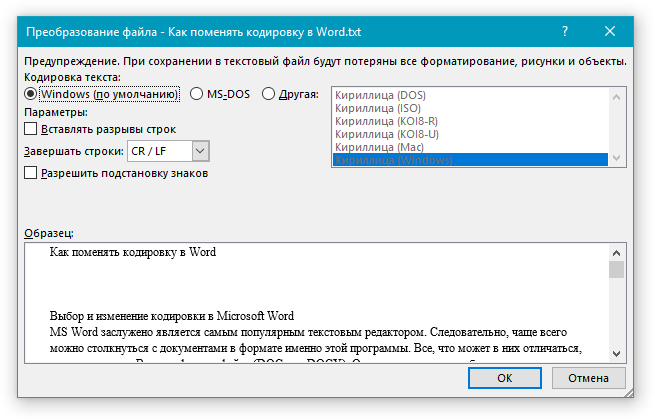
- Выполните одно из следующих действий:
- Для использования стандартной кодировки, установленной по умолчанию, установите маркер напротив параметра “Windows (по умолчанию)”;
- Для выбора кодировки “MS-DOS” установите маркер напротив соответствующего пункта;
- Для выбора любой другой кодировки, установите маркер напротив пункта “Другая”, окно с перечнем доступных кодировок станет активным, после чего вы сможете выбрать необходимую кодировку в списке.
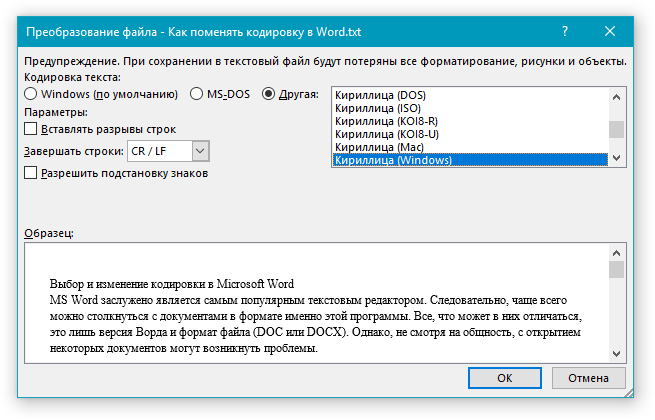
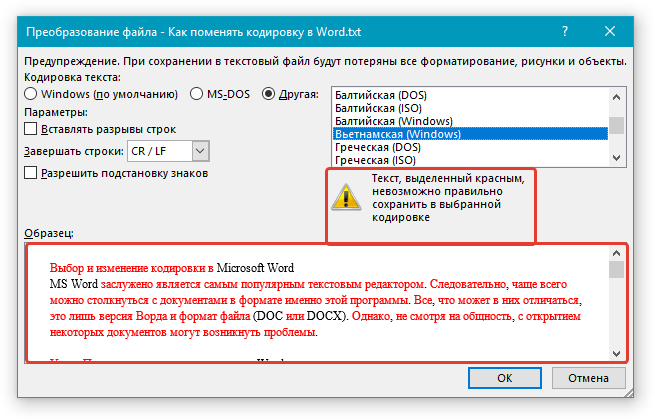
Примечание: Если при выборе той или иной (“Другой”) кодировки вы видите сообщение “Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке”, выберите другую кодировку (иначе содержимое файла будет отображаться некорректно) или же установите галочку напротив параметра “разрешить подстановку знаков”.
Если подстановка знаков разрешена, все те знаки, которые отобразить в выбранной кодировке невозможно, будут автоматически заменены на эквивалентные им символы. Например, многоточие может быть заменено на три точки, а угловые кавычки — на прямые.
На этом, собственно, и все, теперь вы знаете, как в Word сменить кодировку, а также знаете о том, как ее подобрать, если содержимое документа отображается некорректно.
Как преобразовать текст в кириллицу
Этот конвертер предназначен для удобного преобразования текста из латиницы (A, B, C, D и т.д.) в кириллицу (а, б, ц, д).
Введите текст латинского алфавита слева, а затем выберите вариант справа.
Для преобразования доступны три варианта:
- только кириллица без латинского текста
- Кириллический текст с оригинальным латинским алфавитом ниже
- Кириллический текст с оригинальными латинскими символами выше.
Например, "Учить русский — это весело" превращается в "(Леарнинг Руссиан ис фун".
Этот конвертер работает с более чем сотней строк текста и должен сохранять то же форматирование, абзацы и т.д., что и оригинальный текст.
Отдельно у нас есть онлайн-приложение для прямого ввода текста в кириллицу русский язык.
Как перекодировать latin1 в кириллицу
Мне каждый раз задают один и тот же вопрос, спрашивают об одном и том же: «Как перекодировать кракозябры из базы данных, хранящей строки в кодировке latin1 в нормальную кириллицу (windows-1251) или utf-8».
Ниже я постараюсь наиболее полно ответить на данный вопрос, а также приведу кусок кода на PHP, который однозначно решает проблему.
Во-первых, я никому не рекомендую продолжать работать в кодировке windows-1251. Эта однобайтовая кодировка уже не удовлетворяет требованиям современности. Поскорее переводите все проекты на utf-8. Чем быстрее это будет сделано, тем быстрее пропадут у вас проблемы с кракозябрами.
Теперь о latin1. Эта кодировка (также известна как windows-1252) повсеместно использовалась ранее в MySQL вплоть до версии 4. Символьная таблица кириллических букв находится в ней на месте арабских символов. Но поскольку она тоже однобайтовая, то при чтении данных в этой кодировке из этой таблицы и выводе их как windows-1251 не возникает никаких проблем, ведь коды в итоге те же самые (0xA0-0xFF). Но всё это будет работать только до тех пор, пока вы не установите MySQL 5+, работающий по дефолту в utf-8.
Что же делает MySQL 5+, передавая Вам такие данные? Перед передачей на сторону клиента он честно перекодирует все данные в utf-8, помещая арабские символы (а в latin1 ваша кириллица на самом деле является арабскими символами) в тот диапазон кодов utf-8, где они и должны быть. В результате если вы даже попытаетесь перекодировать полученную utf-8-строку обратно в кириллицу функцией iconv(‘utf-8’, ‘windows-1251’, $str), то у вас ничего не получится. iconv выдаст ошибку, либо вернёт пустую строку.
Первое, что делает программист — он пытается изменить кодировку таблицы latin1 на windows-1251 в phpMyAdmin. Но MySQL этого сделать не может (о чём он и пишет), ведь в кодировке windows-1251 нет соответствующих арабских символов. Второе, что приходит в голову — сконвертировать эту таблицу в utf-8. И это получается. Только вот тексты по-прежнему отображаются кракозябрами.
Как же быть? Как решить эту проблему ?
Решение тут довольно простое, но чтобы к нему прийти самостоятельно, надо чётко понимать — что такое кодировки и как они работают. В понимании поможет моя hand-made диаграмма.

А вот и алгоритм, которым я пользуюсь, чтобы привести кодировки в порядок.
- Перевожу все таблицы БД в кодировку utf-8. При этом якобы кириллические символы, хранящиеся в кодировке latin1, а поэтому на самом деле являющиеся арабскими, переводятся в utf-8 и занимают свои законные места в диапазоне кодов utf-8, предназначенном для арабских символов.
- Пишу микроутилиту на PHP, которая делает следующее с каждой символьной строкой:
- а) Переводит строку в кодировку windows-1252. Тут проблем быть не должно. Тем самым арабские буквы занимают диапазон кодов A0-FF.
- б) Переводит полученную однобайтовую строку в utf-8, но уже не как windows-1252, а как windows-1251, т.е. выдавая символы из диапазона A0-FF за кириллические. В итоге символы попадают в utf-8 в тот диапазон кодов, который предназначен для кириллических символов.
- Всё, теперь наша строка официально является кириллической строкой в utf-8. Её можно записать обратно в ту же ячейку БД, либо сразу выдать в выходной поток. Однако я всё же рекомендую выполнить однократное полное преобразование БД, и забыть о latin1 как о страшном сне.
Ниже привожу сэмпл кода на PHP, который переводит ФИО пользователей в нормальную кириллическую кодировку.
$q = ‘select id, fio from `users`’;
$res = mysql_query($q);
while (($row = mysql_fetch_assoc($res)) !== false) <
// Преобразуем fio из utf-8/latin1 в windows-1252
$s = iconv(‘utf-8’, ‘windows-1252’, $row[‘fio’]);
// Преобразуем строку из однобайтной кодировки обратно в utf-8, выдав её за windows-1251
$s = iconv(‘windows-1251’, ‘utf-8’, $s);
// Сохраняем назад в БД
$q = ‘update `users` set fio = «‘.addslashes($s).'» where id’];
mysql_query($q);
>
Как преобразовать текст в кириллицу
Если в письме электронной почты или сообщении ICQ вы видите непонятные символы и хотите раскодировать текст, то этот онлайн декодер кириллицы поможет вам прочитать иероглифы, подобрать кодировку и перекодировать текст.
Чтобы перевести иероглифы в нормальный текст, скопируйте кракозябры в поле и выберите одну из перечисленных ниже опций. Если фрагмент очень большой, будут захвачены только первые 20 000 символов.
В большинстве случаев декодер успешно справляется с любым закодированным текстом на русском языке, однако не любой текст может быть восстановлен или восстановлен полностью. В первую очередь, это связано с тем, что при копировании фрагмента через буфер обмена часть информации может быть утеряна. Тем не менее, декодер предложит вам варианты, даже если восстановить текст удалось лишь частично.
Декодер также распознаёт наиболее распространённые почтовые и веб-кодировки — base64, quoted-printable, urlencoded, и т.п.
Подбор
Декодер попытается автоматически расшифровать вашу абракадабру, преобразовав ее в читаемый кириллический текст. Если вы не уверены, как лучше раскодировать текст, — нажимайте кнопку «Подбор» .
Точно
Если вы знаете, в какой кодировке отображен фрагмент и его исходную кодировку, выберите их из списков и нажмите «Точно» .
Повтор
Если вам нужно раскодировать несколько фрагментов из одного источника (скажем, вы раскодировали небольшой фрагмент с помощью кнопки «Подбор» , и теперь хотите раскодировать весь текст целиком), выберите эту опцию. Декодер возьмет последние отображенные кодировки. Если в вашем браузере отключены cookies , эта кнопка будет не доступна.
Показать
Если вы нажали кнопку «Подбор» , вам будет предложено несколько вариантов раскодирования. Если вы не видите русский текст в поле результата, выберите другой вариант из списка и нажмите «Показать» .