Как построить интегральную кривую в Excel?
Интегральная кривая — это график, который показывает изменение какой-либо величины (например, скорости, температуры) в зависимости от времени. Этот тип графика может быть полезен для анализа колебаний, среднего значения и динамики процессов.
В Excel есть несколько способов построить интегральную кривую. Рассмотрим два наиболее распространенных метода.
Метод численного интегрирования
В Excel создайте таблицу, в которой первый столбец соответствует времени, а второй столбец — величине, изменение которой вы хотите отслеживать.
Вычислите разницу между значениями во втором столбце для каждого временного интервала. Для этого можно использовать функцию Разность ( delta ).
В третьем столбце посчитайте сумму всех значений в столбце 2 для каждой строки, начиная с первой. Эти значения будут интегральной кривой.
Постройте график, используя два столбца: первый — время, второй — интегральная кривая.
Метод аппроксимации функцией
В Excel создайте таблицу, в которой первый столбец соответствует времени, а второй столбец — величине, изменение которой вы хотите отслеживать.
Найдите функцию, которая лучше всего аппроксимирует ваши данные. Это может быть полином, экспоненциальная функция, логарифмическая функция и т.д.
Постройте график вашей аппроксимирующей функции с помощью функции График .
В Excel есть функция Интеграл ( integral ), которая позволяет численно вычислить интеграл функции на заданном интервале. Используя эту функцию, вычислите значение интеграла на каждом временном интервале.
В третьем столбце создайте таблицу с суммой значений интеграла, начиная от начального времени до текущего времени. Это будут значения интегральной кривой.
Постройте график интегральной кривой, используя два столбца: первый — время, второй — интегральная кривая.
В результате вы получите график, который покажет, как величина изменяется со временем. Это может быть полезно для многих областей, таких как физика, химия, экономика и т.д.
Как сделать линейную калибровочную кривую в Excel
В Excel есть встроенные функции, которые можно использовать для отображения данных калибровки и расчета линии наилучшего соответствия. Это может быть полезно, когда вы пишете отчет о химической лаборатории или программируете поправочный коэффициент для единицы оборудования.
В этой статье мы рассмотрим, как с помощью Excel создать диаграмму, построить линейную калибровочную кривую, отобразить формулу калибровочной кривой, а затем настроить простые формулы с функциями НАКЛОН и ПЕРЕСЕЧЕНИЕ, чтобы использовать уравнение калибровки в Excel.
Что такое калибровочная кривая и чем полезен Excel при ее создании?
Чтобы выполнить калибровку, вы сравниваете показания устройства (например, температуру, отображаемую термометром) с известными значениями, называемыми стандартами (например, точки замерзания и кипения воды). Это позволяет вам создать серию пар данных, которые затем вы будете использовать для построения калибровочной кривой.
Двухточечная калибровка термометра с использованием точек замерзания и кипения воды будет иметь две пары данных: одну, когда термометр помещают в ледяную воду (32 ° F или 0 ° C), и одну в кипящую воду (212 ° F). или 100 ° C). Когда вы наносите эти две пары данных в виде точек и проводите линию между ними (калибровочная кривая), а затем, предполагая, что реакция термометра является линейной, вы можете выбрать любую точку на линии, которая соответствует значению, отображаемому термометром, и вы смог найти соответствующую «истинную» температуру.
Таким образом, линия по существу заполняет информацию между двумя известными точками для вас, чтобы вы могли быть достаточно уверены при оценке фактической температуры, когда термометр показывает 57,2 градуса, но когда вы никогда не измеряли «стандарт», который соответствует это чтение.
В Excel есть функции, которые позволяют графически отображать пары данных на диаграмме, добавлять линию тренда (калибровочную кривую) и отображать уравнение калибровочной кривой на диаграмме. Это полезно для визуального отображения, но вы также можете вычислить формулу линии, используя функции НАКЛОН и ПЕРЕСЕЧЕНИЕ Excel. Когда вы вводите эти значения в простые формулы, вы сможете автоматически рассчитать «истинное» значение на основе любого измерения.
Давайте посмотрим на пример
В этом примере мы построим калибровочную кривую из серии из десяти пар данных, каждая из которых состоит из значения X и значения Y. Значения X будут нашими «стандартами», и они могут представлять что угодно, от концентрации химического раствора, который мы измеряем с помощью научного инструмента, до входной переменной программы, которая управляет машиной для запуска мрамора.
Значения Y будут «откликами», и они будут представлять показания прибора, предоставленные при измерении каждого химического раствора, или измеренное расстояние, на котором от пусковой установки приземлился шарик с использованием каждого входного значения.
После того, как мы графически изобразим калибровочную кривую, мы будем использовать функции НАКЛОН и ПЕРЕСЕЧЕНИЕ, чтобы вычислить формулу калибровочной линии и определить концентрацию «неизвестного» химического раствора на основе показаний прибора или решить, какие входные данные мы должны дать программе, чтобы мрамор приземляется на определенном расстоянии от пусковой установки.
Шаг первый: создайте свою диаграмму
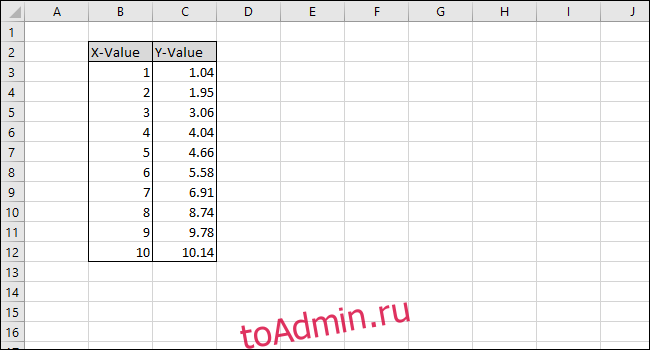
Наша простая таблица-пример состоит из двух столбцов: X-Value и Y-Value.
Начнем с выбора данных для отображения на диаграмме.
Сначала выберите ячейки столбца «X-Value».
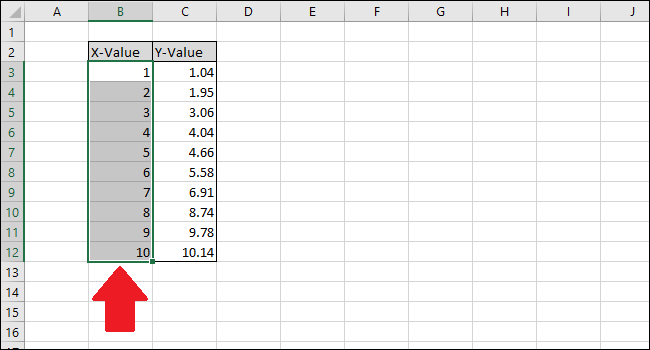
Теперь нажмите клавишу Ctrl и щелкните ячейки столбца Y-Value.
Перейдите на вкладку «Вставка».
Перейдите в меню «Графики» и выберите первую опцию в раскрывающемся списке «Точечный».
Выберите серию, щелкнув одну из синих точек. После выбора Excel обрисовывает в общих чертах точки.
Щелкните правой кнопкой мыши одну из точек и выберите параметр «Добавить линию тренда».
На графике появится прямая линия.
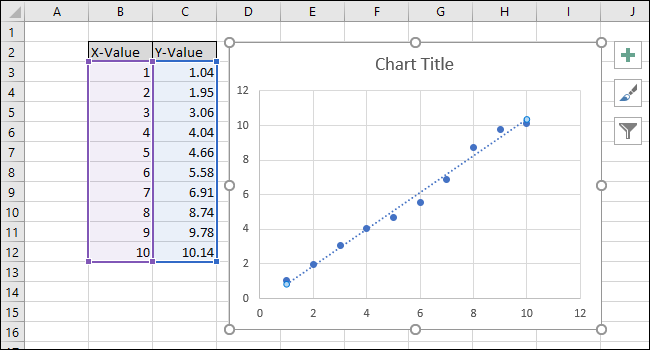
В правой части экрана появится меню «Форматировать линию тренда». Установите флажки рядом с «Отображать уравнение на диаграмме» и «Отображать значение R-квадрата на диаграмме». Значение R-квадрата — это статистика, которая показывает, насколько точно линия соответствует данным. Наилучшее значение R-квадрата составляет 1.000, что означает, что каждая точка данных касается линии. По мере того, как разница между точками данных и линией увеличивается, значение r-квадрата уменьшается, при этом 0,000 является наименьшим возможным значением.
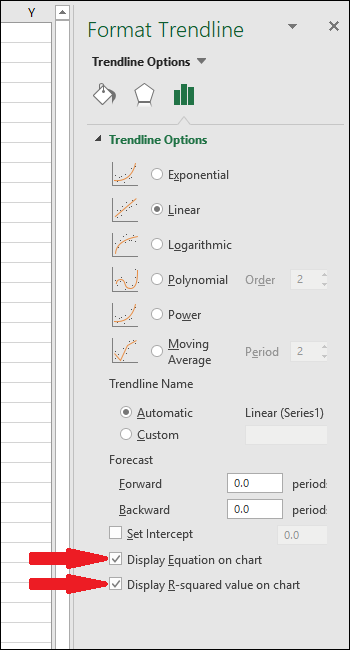
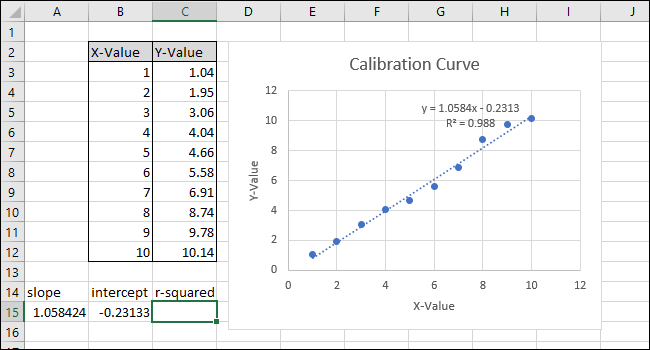
Уравнение и статистика R-квадрата линии тренда появятся на графике. Обратите внимание, что корреляция данных в нашем примере очень хорошая, со значением R-квадрат 0,988.
Уравнение имеет вид «Y = Mx + B», где M — наклон, а B — точка пересечения прямой линии с осью Y.
Теперь, когда калибровка завершена, давайте поработаем над настройкой диаграммы, отредактировав заголовок и добавив заголовки осей.
Чтобы изменить заголовок диаграммы, щелкните по нему, чтобы выделить текст.
Теперь введите новый заголовок, описывающий диаграмму.
Чтобы добавить заголовки к осям x и y, сначала перейдите в Инструменты диаграммы> Дизайн.
Теперь перейдите к Названиям осей> Первичный горизонтальный.
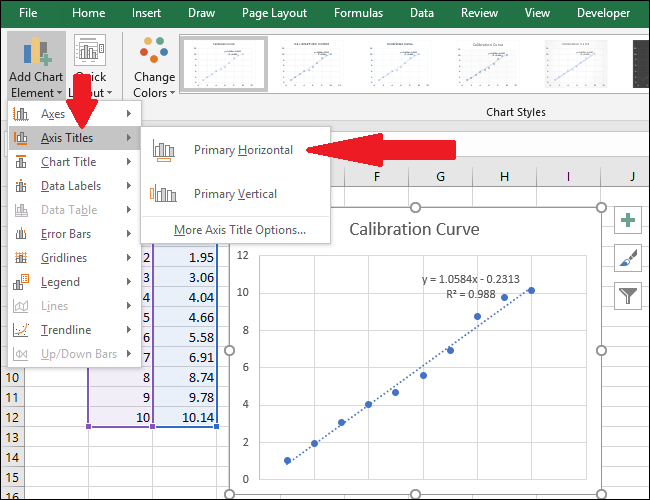 основная горизонтальная «ширина =» 650 «высота =» 500 «onload =» pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this); » onerror = ”this.onerror = null; pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);”>
основная горизонтальная «ширина =» 650 «высота =» 500 «onload =» pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this); » onerror = ”this.onerror = null; pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);”>
Появится заголовок оси.
Чтобы переименовать заголовок оси, сначала выберите текст, а затем введите новый заголовок.
Теперь перейдите в Названия осей> Основная вертикаль.
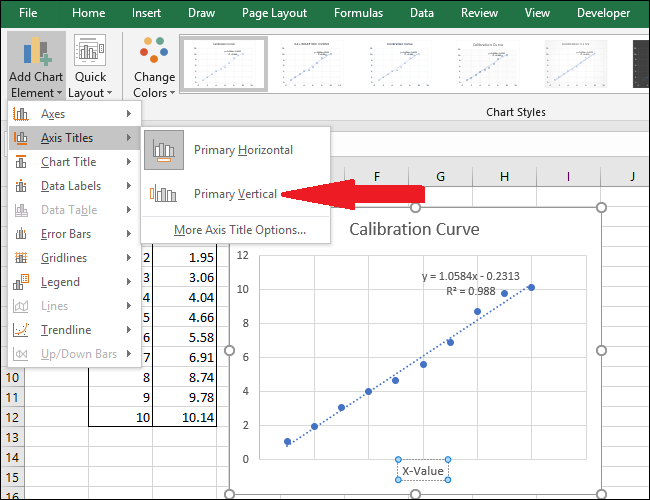
Появится название оси.
Переименуйте этот заголовок, выделив текст и введя новый заголовок.
Теперь ваша диаграмма завершена.
Шаг второй: вычислить линейное уравнение и статистику R-квадрат
Теперь давайте рассчитаем линейное уравнение и статистику R-квадрата, используя встроенные в Excel функции НАКЛОН, ПЕРЕСЕЧЕНИЕ и КОРРЕЛЬ.
К нашему листу (в строке 14) мы добавили заголовки для этих трех функций. Мы выполним фактические вычисления в ячейках под этими заголовками.
Сначала мы рассчитаем НАКЛОН. Выберите ячейку A15.
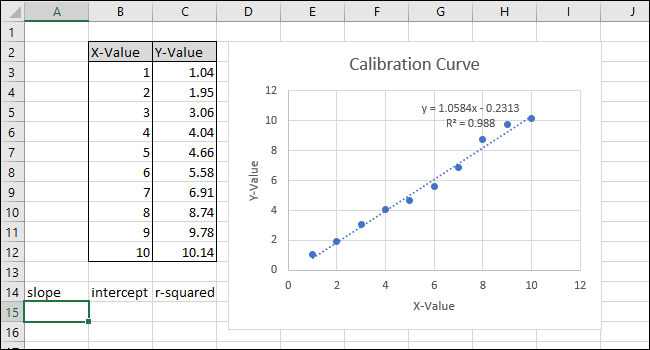
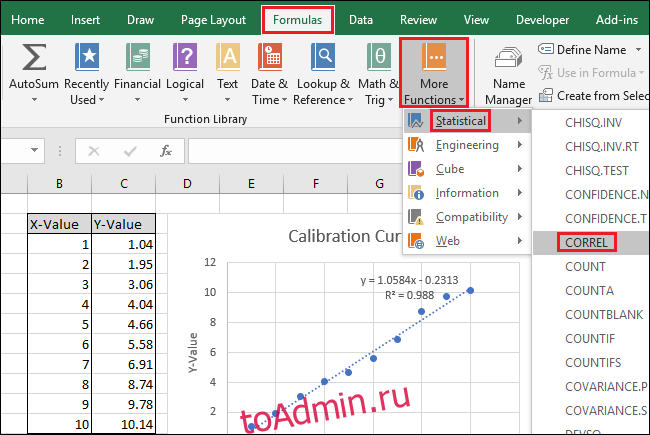
Перейдите к формулам> Дополнительные функции> Статистические данные> НАКЛОН.
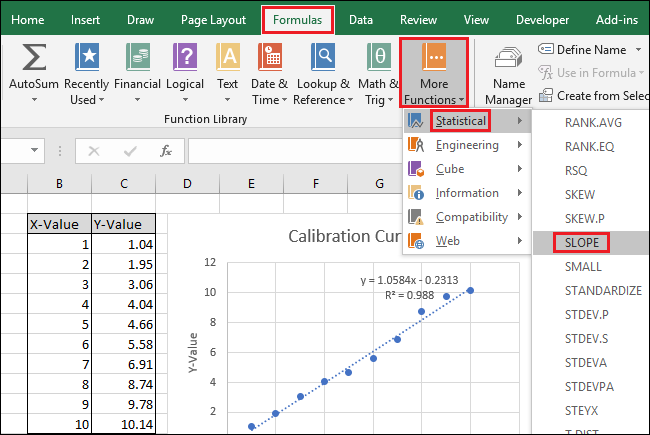
В поле «Known_xs» выберите или введите значения в ячейках столбца X-Value. Порядок полей Known_ys и Known_xs имеет значение в функции SLOPE.
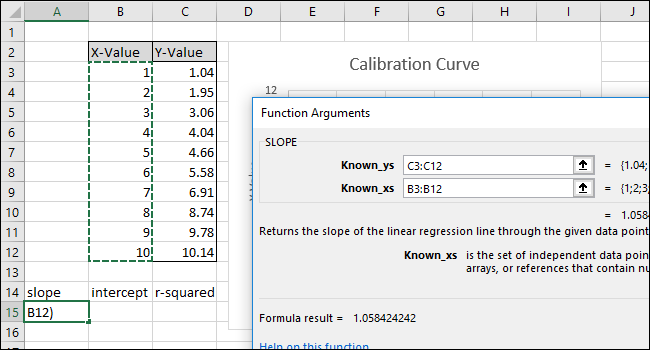
Нажмите «ОК». Окончательная формула в строке формул должна выглядеть так:
= НАКЛОН (C3: C12; B3: B12)
Обратите внимание, что значение, возвращаемое функцией НАКЛОН в ячейке A15, соответствует значению, отображаемому на диаграмме.
Затем выберите ячейку B15 и перейдите в раздел Формулы> Дополнительные функции> Статистические данные> ПЕРЕСЕЧЕНИЕ.
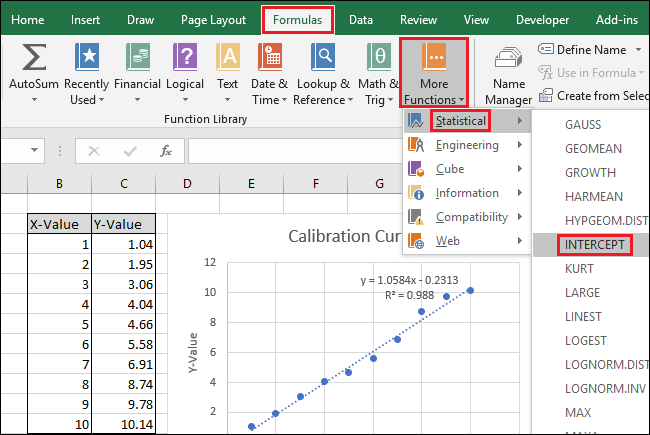
Выберите или введите ячейки столбца X-Value для поля «Known_xs». Порядок полей «Known_ys» и «Known_xs» также имеет значение в функции INTERCEPT.
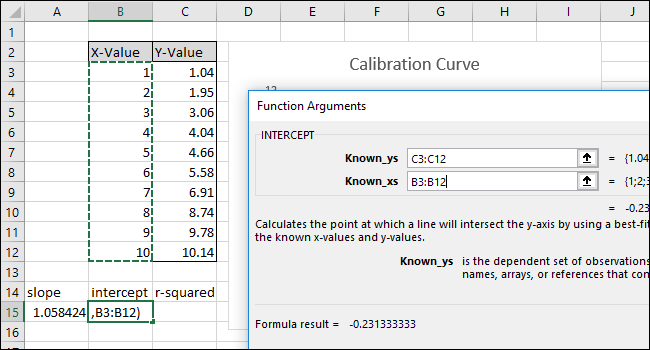
Нажмите «ОК». Окончательная формула в строке формул должна выглядеть так:
= ПЕРЕСЕЧЕНИЕ (C3: C12; B3: B12)
Обратите внимание, что значение, возвращаемое функцией ПЕРЕСЕЧЕНИЕ, совпадает с точкой пересечения оси Y, отображаемой на диаграмме.
Затем выберите ячейку C15 и перейдите в раздел Формулы> Дополнительные функции> Статистические данные> CORREL.
Выберите или введите другой из двух диапазонов ячеек для поля «Массив2».
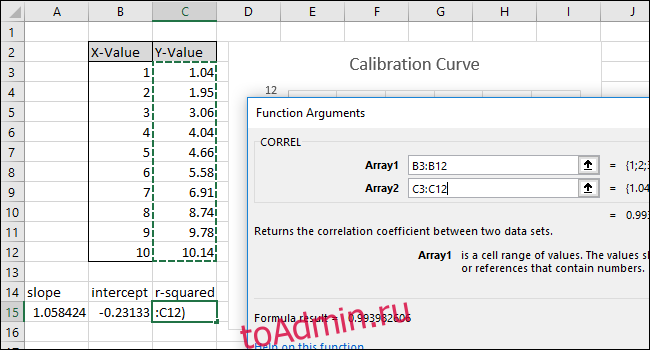
Нажмите «ОК». Формула в строке формул должна выглядеть так:
= КОРРЕЛ (B3: B12; C3: C12)
Обратите внимание, что значение, возвращаемое функцией CORREL, не соответствует значению «r-квадрат» на диаграмме. Функция КОРРЕЛ возвращает «R», поэтому мы должны возвести его в квадрат, чтобы вычислить «R-квадрат».
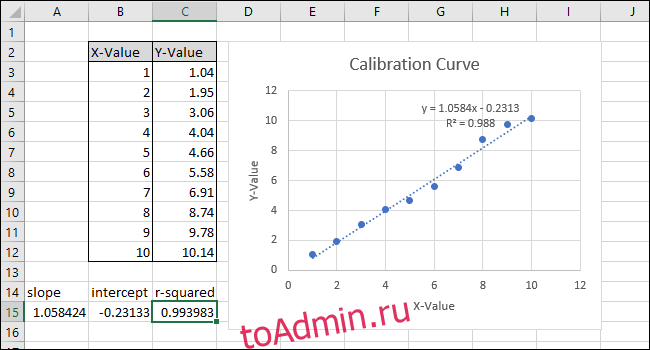
Щелкните внутри функциональной панели и добавьте «^ 2» в конец формулы, чтобы возвести в квадрат значение, возвращаемое функцией CORREL. Заполненная формула должна теперь выглядеть так:
= КОРРЕЛ (B3: B12; C3: C12) ^ 2
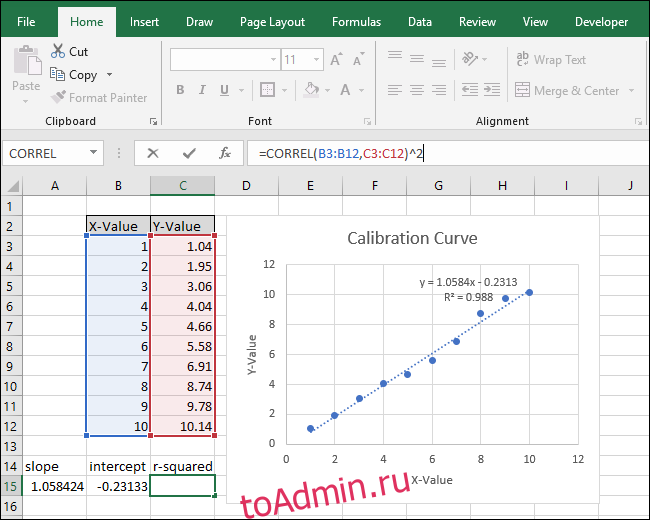
После изменения формулы значение «R-квадрат» теперь соответствует значению, отображаемому на диаграмме.
Шаг третий: настройте формулы для быстрого расчета значений
Теперь мы можем использовать эти значения в простых формулах, чтобы определить концентрацию этого «неизвестного» раствора или какие входные данные мы должны ввести в код, чтобы шарик пролетел определенное расстояние.
На этих этапах будут созданы формулы, необходимые для того, чтобы вы могли ввести значение X или Y и получить соответствующее значение на основе калибровочной кривой.
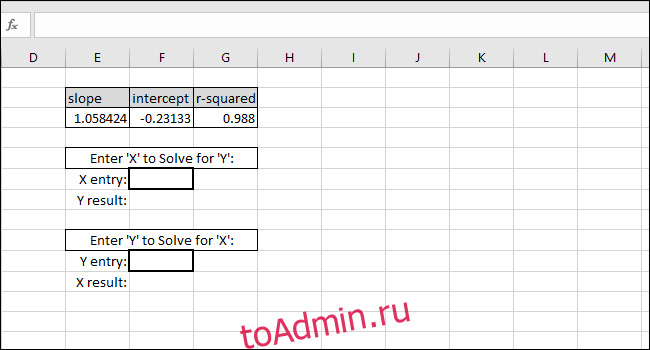
Уравнение линии наилучшего соответствия имеет форму «Значение Y = НАКЛОН * значение X + ПЕРЕСЕЧЕНИЕ», поэтому решение для «значения Y» выполняется путем умножения значения X и НАКЛОНА, а затем добавление ПЕРЕСЕЧЕНИЯ.
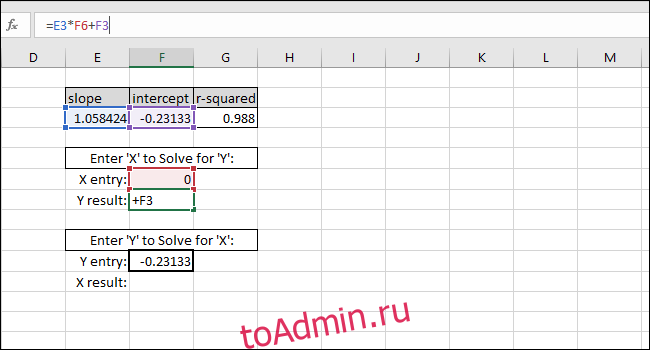
В качестве примера мы добавляем ноль в качестве значения X. Возвращаемое значение Y должно быть равно ПЕРЕСЕЧЕНИЮ линии наилучшего соответствия. Он совпадает, поэтому мы знаем, что формула работает правильно.
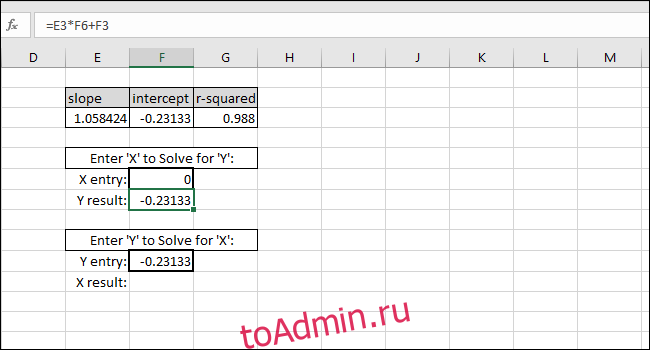
Решение для значения X на основе значения Y выполняется путем вычитания ПЕРЕСЕЧЕНИЯ из значения Y и деления результата на НАКЛОН:
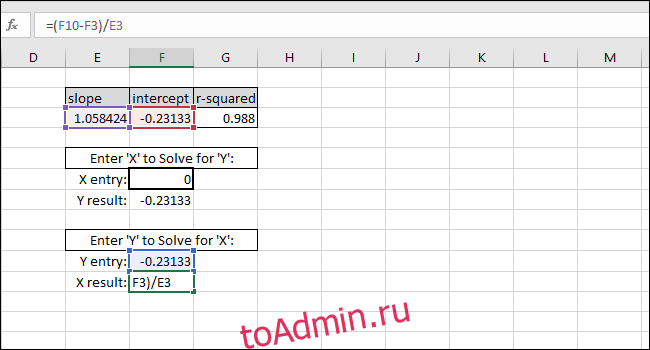
В качестве примера мы использовали ПЕРЕСЕЧЕНИЕ как Y-значение. Возвращаемое значение X должно быть равно нулю, но возвращаемое значение — 3.14934E-06. Возвращенное значение не равно нулю, потому что мы непреднамеренно усекли результат INTERCEPT при вводе значения. Однако формула работает правильно, потому что результат формулы равен 0,00000314934, что по существу равно нулю.
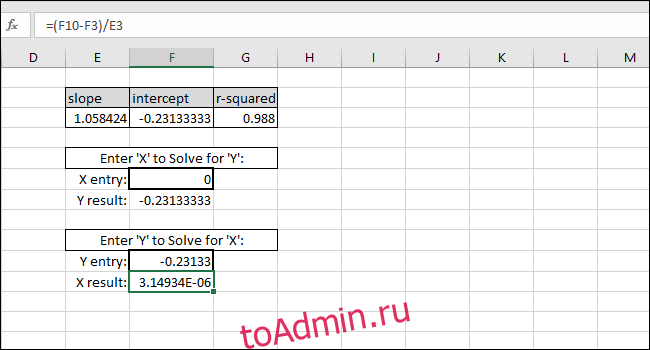
Вы можете ввести любое желаемое значение X в первую ячейку с толстой рамкой, и Excel автоматически вычислит соответствующее значение Y.
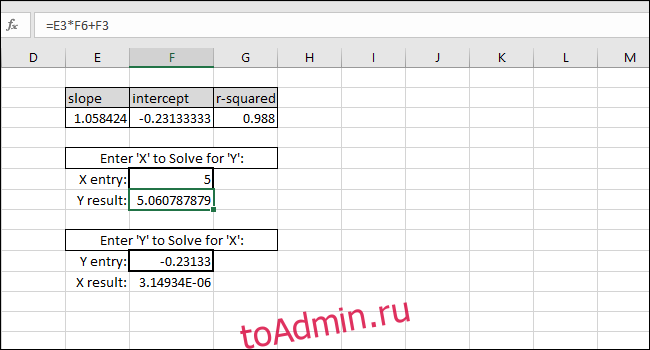
Ввод любого значения Y во вторую ячейку с толстой рамкой даст соответствующее значение X. Эта формула — то, что вы использовали бы для расчета концентрации этого раствора или того, какие входные данные необходимы для запуска шарика на определенное расстояние.
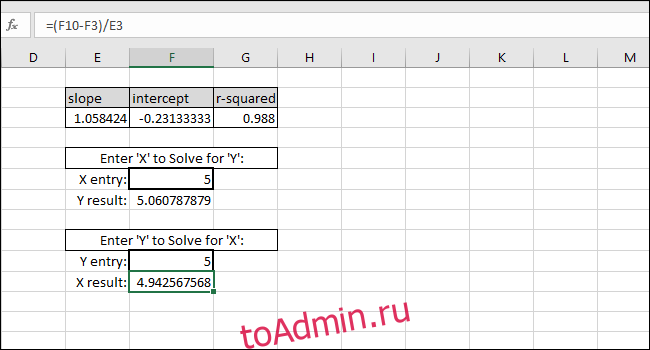
В этом случае прибор показывает «5», поэтому калибровка предполагает концентрацию 4,94, или мы хотим, чтобы шарик прошел пять единиц расстояния, поэтому калибровка предлагает ввести 4,94 в качестве входной переменной для программы, управляющей гранатометом. Мы можем быть достаточно уверены в этих результатах из-за высокого значения R-квадрата в этом примере.
Построение кривой Лоренца в Microsoft Excel

Для оценки уровня неравенства между различными слоями населения общества часто используют кривую Лоренца и производный от неё показатель – коэффициент Джинни. С помощью них можно определить, насколько велик социальный разрыв в обществе между самыми богатыми и наиболее бедными слоями населения. С помощью инструментов приложения Excel можно значительно облегчить процедуру построения кривой Лоренца. Давайте, разберемся, как в среде Эксель это можно осуществить на практике.
Использование кривой Лоренца
Кривая Лоренца представляет собой типичную функцию распределения, отображенную графически. По оси X данной функции располагается количество населения в процентном соотношении по нарастающей, а по оси Y — общее количество национального дохода. Собственно, сама кривая Лоренца состоит из точек, каждая из которых соответствует процентному соотношению уровня дохода определенной части общества. Чем больше изогнута линия Лоренца, тем больше в обществе уровень неравенства.
В идеальной ситуации, при которой отсутствует общественное неравенство, каждая группа населения имеет уровень дохода прямо пропорциональный её численности. Линия, характеризующая такую ситуацию, называется кривой равенства, хотя она и представляет собой прямую. Чем больше площадь фигуры, ограниченной кривой Лоренца и кривой равенства, тем выше уровень неравенства в обществе.
Кривая Лоренца может использоваться не только для определения ситуации имущественного расслоения в мире, в конкретной стране или в обществе, но и для сравнения в данном аспекте отдельных домохозяйств.
Вертикальная прямая, которая соединяет линию равенства и наиболее удаленную от неё точку кривой Лоренца, называется индексом Гувера или Робин Гуда. Данный отрезок показывает, какую величину дохода нужно перераспределить в обществе, чтобы достичь полного равенства.
Уровень неравенства в обществе определяется с помощью индекса Джинни, который может варьироваться от 0 до 1. Он ещё называется коэффициентом концентрации доходов.
Построение линии равенства
Теперь давайте на конкретном примере посмотрим, как создать линию равенства и кривую Лоренца в Экселе. Для этого используем таблицу количества населения разбитого на пять равных групп (по 20%), которые суммируются в таблице по нарастающей. Во второй колонке этой таблицы представлена величина национального дохода в процентном соотношении, которая соответствует определенной группе населения.
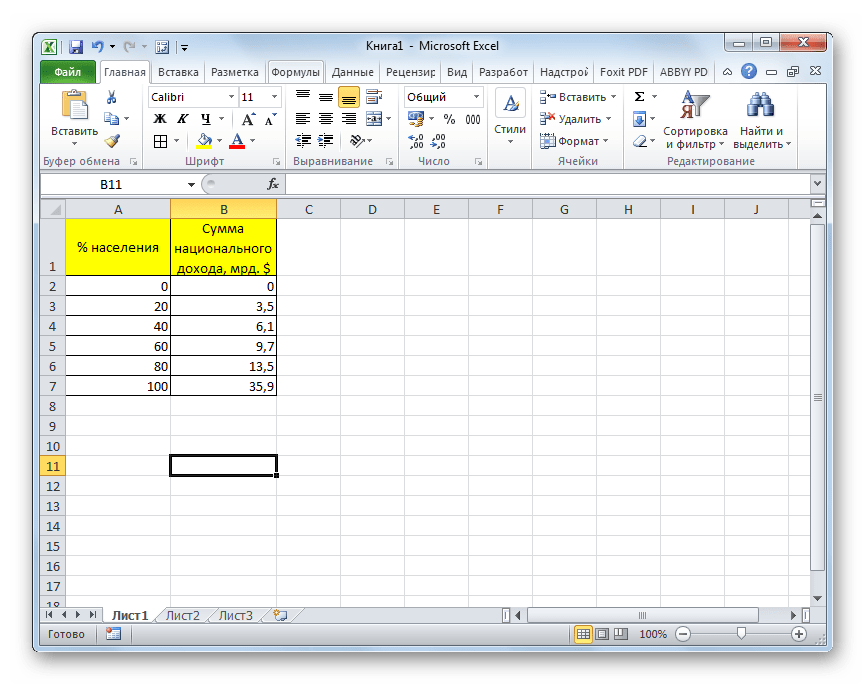
Для начала построим линию абсолютного равенства. Она будет состоять из двух точек – нулевой и точки суммарного национального дохода для 100% населения.
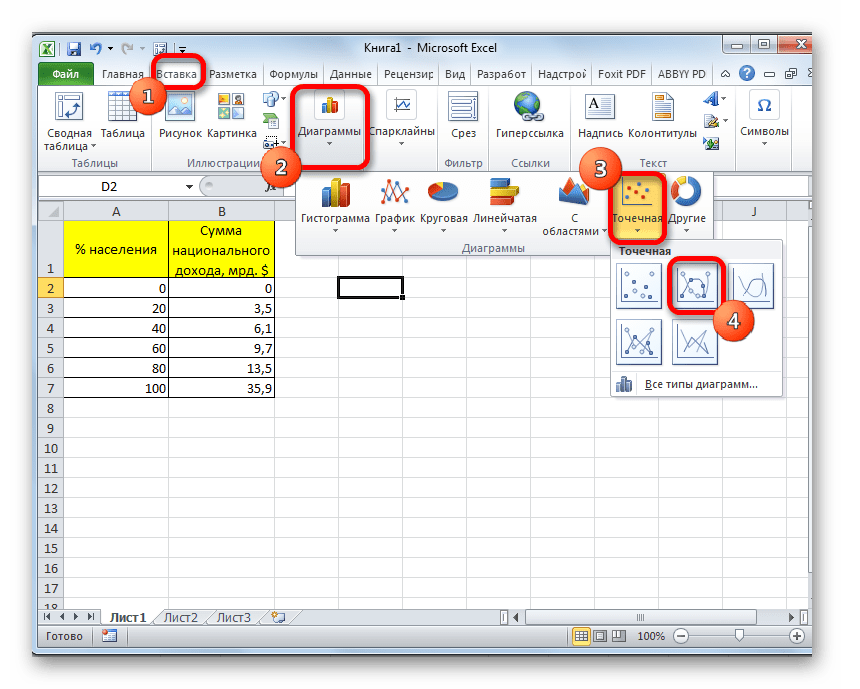
-
Переходим во вкладку «Вставка». На линии в блоке инструментов «Диаграммы» жмем на кнопку «Точечная». Именно данный тип диаграмм подойдет для нашей задачи. Далее открывается список подвидов диаграмм. Выбираем «Точечная с гладкими кривыми и маркерами».
В поле «Значения X» следует указать координаты точек диаграммы по оси X. Как мы помним, их будет всего две: 0 и 100. Записываем данные значения через точку с запятой в данном поле.
В поле «Значения Y» следует записать координаты точек по оси Y. Их тоже будет две: 0 и 35,9. Последняя точка, как мы можем видеть по графику, соответствует совокупному национальному доходу 100% населения. Итак, записываем значения «0;35,9» без кавычек.
Создание кривой Лоренца
Теперь нам предстоит непосредственно построить кривую Лоренца, опираясь на табличные данные.
- Кликаем правой кнопкой мыши по области диаграммы, на которой уже расположена линия равенства. В запустившемся меню снова останавливаем выбор на пункте «Выбрать данные…».
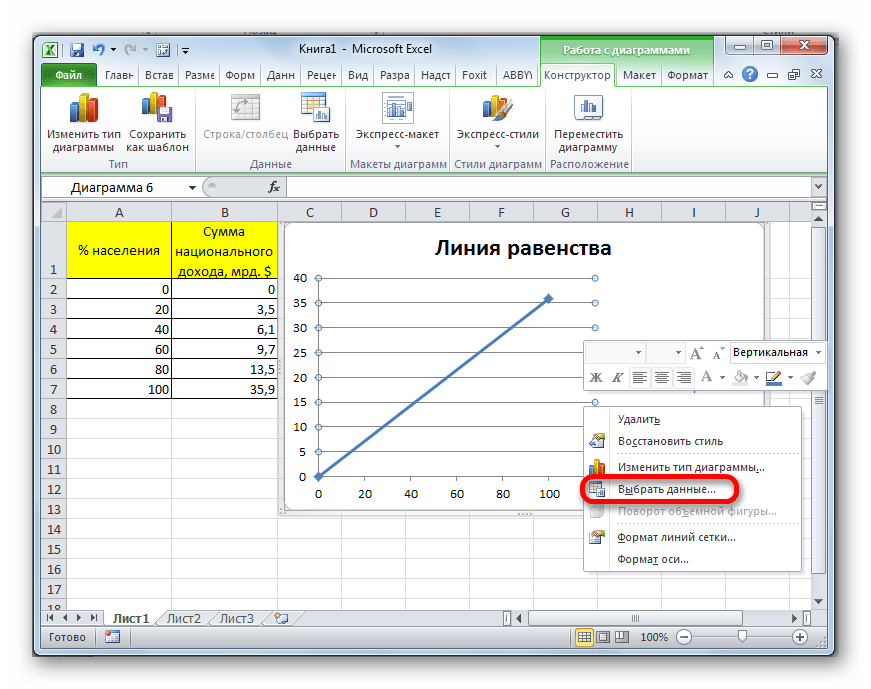
- Опять открывается окно выбора данных. Как видим, среди элементов уже представлено наименование «Линия равенства», но нам нужно внести ещё одну диаграмму. Поэтому жмем на кнопку «Добавить».
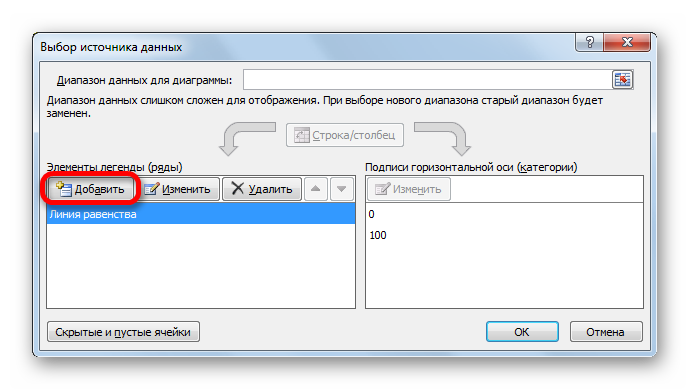
- Снова открывается окно изменения ряда. Поле «Имя ряда», как и в прошлый раз, заполняем вручную. Сюда можно вписать наименование «Кривая Лоренца».
В поле «Значения X» следует занести все данные столбца «% населения» нашей таблицы. Для этого устанавливаем курсор в область поля. Далее зажимаем левую кнопку мыши и выделяем соответствующий столбец на листе. Координаты тут же будут отображены в окне изменения ряда.
В поле «Значения Y» заносим координаты ячеек столбца «Сумма национального дохода». Делаем это по той же методике, по которой вносили данные в предыдущее поле.
Построение кривой Лоренца и линии равенства в Экселе производится на тех же принципах, что и построение любого другого вида диаграмм в этой программе. Поэтому для пользователей, которые овладели умением строить диаграммы и графики в Excel, данная задача не должна вызвать больших проблем.
Нормальное распределение. Непрерывные распределения в EXCEL
Рассмотрим Нормальное распределение. С помощью функции MS EXCEL НОРМ.РАСП() построим графики функции распределения и плотности вероятности. Сгенерируем массив случайных чисел, распределенных по нормальному закону, произведем оценку параметров распределения, среднего значения и стандартного отклонения .
Нормальное распределение (также называется распределением Гаусса) является самым важным как в теории, так в приложениях системы контроля качества. Важность значения Нормального распределения (англ. Normal distribution ) во многих областях науки вытекает из Центральной предельной теоремы теории вероятностей.
Определение : Случайная величина x распределена по нормальному закону , если она имеет плотность распределения :
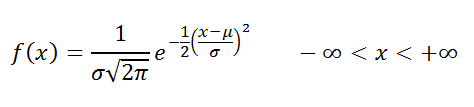
СОВЕТ : Подробнее о Функции распределения и Плотности вероятности см. статью Функция распределения и плотность вероятности в MS EXCEL .
Нормальное распределение зависит от двух параметров: μ (мю) — является математическим ожиданием (средним значением случайной величины) , и σ ( сигма) — является стандартным отклонением (среднеквадратичным отклонением). Параметр μ определяет положение центра плотности вероятности нормального распределения , а σ — разброс относительно центра (среднего).
Примечание : О влиянии параметров μ и σ на форму распределения изложено в статье про Гауссову кривую , а в файле примера на листе Влияние параметров можно с помощью элементов управления Счетчик понаблюдать за изменением формы кривой.
Нормальное распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для Нормального распределения имеется функция НОРМ.РАСП() , английское название — NORM.DIST(), которая позволяет вычислить плотность вероятности (см. формулу выше) и интегральную функцию распределения (вероятность, что случайная величина X, распределенная по нормальному закону , примет значение меньше или равное x). Вычисления в последнем случае производятся по следующей формуле:
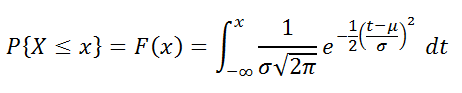
Вышеуказанное распределение имеет обозначение N (μ; σ). Так же часто используют обозначение через дисперсию N (μ; σ 2 ).
Примечание : До MS EXCEL 2010 в EXCEL была только функция НОРМРАСП() , которая также позволяет вычислить функцию распределения и плотность вероятности. НОРМРАСП() оставлена в MS EXCEL 2010 для совместимости.
Стандартное нормальное распределение
Стандартным нормальным распределением называется нормальное распределение с математическим ожиданием μ=0 и дисперсией σ=1. Вышеуказанное распределение имеет обозначение N (0;1).
Примечание : В литературе для случайной величины, распределенной по стандартному нормальному закону, закреплено специальное обозначение z.
Любое нормальное распределение можно преобразовать в стандартное через замену переменной z =( x -μ)/σ . Этот процесс преобразования называется стандартизацией .
Примечание : В MS EXCEL имеется функция НОРМАЛИЗАЦИЯ() , которая выполняет вышеуказанное преобразование. Хотя в MS EXCEL это преобразование называется почему-то нормализацией . Формулы =(x-μ)/σ и =НОРМАЛИЗАЦИЯ(х;μ;σ) вернут одинаковый результат.
В MS EXCEL 2010 для стандартного нормального распределения имеется специальная функция НОРМ.СТ.РАСП() и ее устаревший вариант НОРМСТРАСП() , выполняющий аналогичные вычисления.
Продемонстрируем, как в MS EXCEL осуществляется процесс стандартизации нормального распределения N (1,5; 2).
Для этого вычислим вероятность, что случайная величина, распределенная по нормальному закону N(1,5; 2) , меньше или равна 2,5. Формула выглядит так: =НОРМ.РАСП(2,5; 1,5; 2; ИСТИНА) =0,691462. Сделав замену переменной z =(2,5-1,5)/2=0,5 , запишем формулу для вычисления Стандартного нормального распределения: =НОРМ.СТ.РАСП(0,5; ИСТИНА) =0,691462.
Естественно, обе формулы дают одинаковые результаты (см. файл примера лист Пример ).
Обратите внимание, что стандартизация относится только к интегральной функции распределения (аргумент интегральная равен ИСТИНА), а не к плотности вероятности .
Примечание : В литературе для функции, вычисляющей вероятности случайной величины, распределенной по стандартному нормальному закону, закреплено специальное обозначение Ф(z). В MS EXCEL эта функция вычисляется по формуле =НОРМ.СТ.РАСП(z;ИСТИНА) . Вычисления производятся по формуле
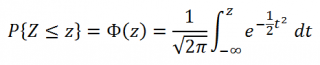
В силу четности функции плотности стандартного нормального распределения f(x), а именно f(x)=f(-х), функция стандартного нормального распределения обладает свойством Ф(-x)=1-Ф(x).
Обратные функции
Функция НОРМ.СТ.РАСП(x;ИСТИНА) вычисляет вероятность P, что случайная величина Х примет значение меньше или равное х. Но часто требуется провести обратное вычисление: зная вероятность P, требуется вычислить значение х. Вычисленное значение х называется квантилем стандартного нормального распределения .
В MS EXCEL для вычисления квантилей используют функцию НОРМ.СТ.ОБР() и НОРМ.ОБР() .
Графики функций
В файле примера приведены графики плотности распределения вероятности и интегральной функции распределения .
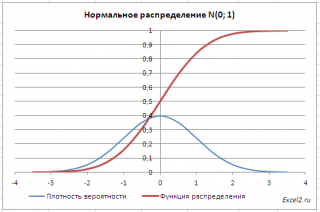
Как известно, около 68% значений, выбранных из совокупности, имеющей нормальное распределение , находятся в пределах 1 стандартного отклонения (σ) от μ(среднего или математического ожидания); около 95% — в пределах 2-х σ, а в пределах 3-х σ находятся уже 99% значений. Убедиться в этом для стандартного нормального распределения можно записав формулу:
которая вернет значение 68,2689% — именно такой процент значений находятся в пределах +/-1 стандартного отклонения от среднего (см. лист График в файле примера ).
В силу четности функции плотности стандартного нормального распределения: f ( x )= f (-х) , функция стандартного нормального распределения обладает свойством F(-x)=1-F(x). Поэтому, вышеуказанную формулу можно упростить:
Для произвольной функции нормального распределения N(μ; σ) аналогичные вычисления нужно производить по формуле:
Вышеуказанные расчеты вероятности требуются для построения доверительных интервалов .
Примечание : Для построения функции распределения и плотности вероятности можно использовать диаграмму типа График или Точечная (со сглаженными линиями и без точек). Подробнее о построении диаграмм читайте статью Основные типы диаграмм .
Примечание : Для удобства написания формул в файле примера созданы Имена для параметров распределения: μ и σ.
Генерация случайных чисел
С помощью надстройки Пакет анализа можно сгенерировать случайные числа, распределенные по нормальному закону .
СОВЕТ : О надстройке Пакет анализа можно прочитать в статье Надстройка Пакет анализа MS EXCEL .
Сгенерируем 3 массива по 100 чисел с различными μ и σ. Для этого в окне Генерация случайных чисел установим следующие значения для каждой пары параметров:
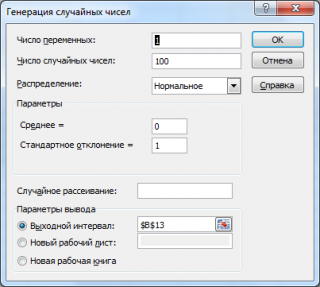
Примечание : Если установить опцию Случайное рассеивание ( Random Seed ), то можно выбрать определенный случайный набор сгенерированных чисел. Например, установив эту опцию равной 25, можно сгенерировать на разных компьютерах одни и те же наборы случайных чисел (если, конечно, другие параметры распределения совпадают). Значение опции может принимать целые значения от 1 до 32 767. Название опции Случайное рассеивание может запутать. Лучше было бы ее перевести как Номер набора со случайными числами .
В итоге будем иметь 3 столбца чисел, на основании которых можно, оценить параметры распределения, из которого была произведена выборка: μ и σ . Оценку для μ можно сделать с использованием функции СРЗНАЧ() , а для σ – с использованием функции СТАНДОТКЛОН.В() , см. файл примера лист Генерация .
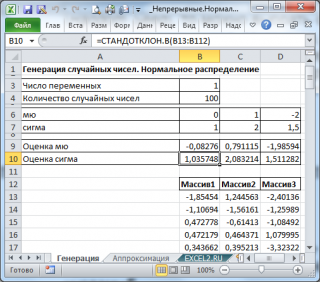
Примечание : Для генерирования массива чисел, распределенных по нормальному закону , можно использовать формулу =НОРМ.ОБР(СЛЧИС();μ;σ) . Функция СЛЧИС() генерирует непрерывное равномерное распределение от 0 до 1, что как раз соответствует диапазону изменения вероятности (см. файл примера лист Генерация ).
Задачи
Задача1 . Компания изготавливает нейлоновые нити со средней прочностью 41 МПа и стандартным отклонением 2 МПа. Потребитель хочет приобрести нити с прочностью не менее 36 МПа. Рассчитайте вероятность, что партии нити, изготовленные компанией для потребителя, будут соответствовать требованиям или превышать их. Решение1 : = 1-НОРМ.РАСП(36;41;2;ИСТИНА)
Задача2 . Предприятие изготавливает трубы, средний внешний диаметр которых равен 20,20 мм, а стандартное отклонение равно 0,25мм. Согласно техническим условиям, трубы признаются годными, если диаметр находится в пределах 20,00+/- 0,40 мм. Какая доля изготовленных труб соответствует ТУ? Решение2 : = НОРМ.РАСП(20,00+0,40;20,20;0,25;ИСТИНА)- НОРМ.РАСП(20,00-0,40;20,20;0,25) На рисунке ниже, выделена область значений диаметров, которая удовлетворяет требованиям спецификации.
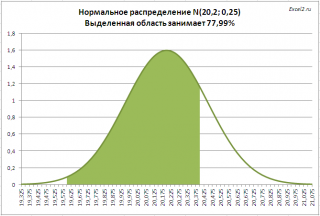
Решение приведено в файле примера лист Задачи .
Задача3 . Предприятие изготавливает трубы, средний внешний диаметр которых равен 20,20 мм, а стандартное отклонение равно 0,25мм. Внешний диаметр не должен превышать определенное значение (предполагается, что нижняя граница не важна). Какую верхнюю границу в технических условиях необходимо установить, чтобы ей соответствовало 97,5% всех изготавливаемых изделий? Решение3 : = НОРМ.ОБР(0,975; 20,20; 0,25) =20,6899 или = НОРМ.СТ.ОБР(0,975)*0,25+20,2 (произведена «дестандартизация», см. выше)
Задача 4 . Нахождение параметров нормального распределения по значениям 2-х квантилей (или процентилей ). Предположим, известно, что случайная величина имеет нормальное распределение, но не известны его параметры, а только 2-я процентиля (например, 0,5- процентиль , т.е. медиана и 0,95-я процентиль ). Т.к. известна медиана , то мы знаем среднее , т.е. μ. Чтобы найти стандартное отклонение нужно использовать Поиск решения . Решение приведено в файле примера лист Задачи .
Примечание : До MS EXCEL 2010 в EXCEL были функции НОРМОБР() и НОРМСТОБР() , которые эквивалентны НОРМ.ОБР() и НОРМ.СТ.ОБР() . НОРМОБР() и НОРМСТОБР() оставлены в MS EXCEL 2010 и выше только для совместимости.
Линейные комбинации нормально распределенных случайных величин
Известно, что линейная комбинация нормально распределённых случайных величин x ( i ) с параметрами μ ( i ) и σ ( i ) также распределена нормально. Например, если случайная величина Y=x(1)+x(2), то Y будет иметь распределение с параметрами μ (1)+ μ(2) и КОРЕНЬ(σ(1)^2+ σ(2)^2). Убедимся в этом с помощью MS EXCEL.
С помощью надстройки Пакет анализа сгенерируем 2 массива по 100 чисел с различными μ и σ.
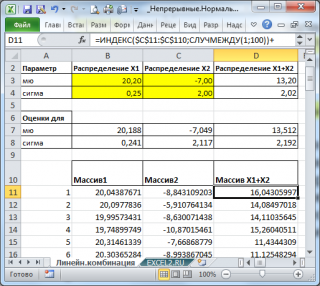
Теперь сформируем массив, каждый элемент которого является суммой 2-х значений, взятых из каждого массива.
С помощью функций СРЗНАЧ() и СТАНДОТКЛОН.В() вычислим среднее и дисперсию получившейся выборки и сравним их с расчетными.
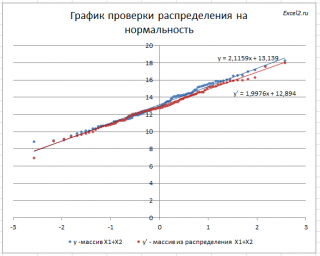
Кроме того, построим График проверки распределения на нормальность ( Normal Probability Plot ), чтобы убедиться, что наш массив соответствует выборке из нормального распределения .
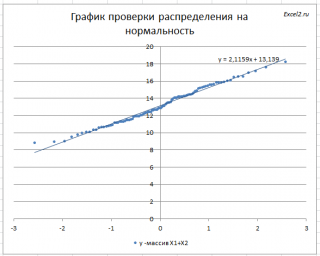
Прямая линия, аппроксимирующая полученный график, имеет уравнение y=ax+b. Наклон кривой (параметр а) может служить оценкой стандартного отклонения , а пересечение с осью y (параметр b) – среднего значения.
Для сравнения сгенерируем массив напрямую из распределения N (μ(1)+ μ(2); КОРЕНЬ(σ(1)^2+ σ(2)^2) ).
Как видно на рисунке ниже, обе аппроксимирующие кривые достаточно близки.
В качестве примера можно провести следующую задачу.
Задача . Завод изготавливает болты и гайки, которые упаковываются в ящики парами. Пусть известно, что вес каждого из изделий является нормальной случайной величиной. Для болтов средний вес составляет 50г, стандартное отклонение 1,5г, а для гаек 20г и 1,2г. В ящик фасуется 100 пар болтов и гаек. Вычислить какой процент ящиков будет тяжелее 7,2 кг. Решение . Сначала переформулируем вопрос задачи: Вычислить какой процент пар болт-гайка будет тяжелее 7,2кг/100=72г. Учитывая, что вес пары представляет собой случайную величину = Вес(болта) + Вес(гайки) со средним весом (50+20)г, и стандартным отклонением =КОРЕНЬ(СУММКВ(1,5;1,2)) , запишем решение = 1-НОРМ.РАСП(72; 50+20; КОРЕНЬ(СУММКВ(1,5;1,2));ИСТИНА) Ответ : 15% (см. файл примера лист Линейн.комбинация )
Аппроксимация Биномиального распределения Нормальным распределением
Если параметры Биномиального распределения B(n;p) находятся в пределах 0,1 10, то Биномиальное распределение можно аппроксимировать Нормальным распределением .
При значениях λ >15 , Распределение Пуассона хорошо аппроксимируется Нормальным распределением с параметрами: μ =λ , σ 2 = λ .
Подробнее о связи этих распределений, можно прочитать в статье Взаимосвязь некоторых распределений друг с другом в MS EXCEL . Там же приведены примеры аппроксимации, и пояснены условия, когда она возможна и с какой точностью.
СОВЕТ : О других распределениях MS EXCEL можно прочитать в статье Распределения случайной величины в MS EXCEL .